
夜鶯監控設計思考(二)邊緣機房架構思考
這將是一個系列,講解 夜鶯監控 的設計思考,可以理解為原理+最佳實踐+產品設計時的折中取舍。
本系列其他文章:
下面開始第2篇。
上一篇我們遺留了一個話題,就是如果貴司有多個數據中心,而且數據中心之間網絡鏈路較差,此時應該怎么辦?
夜鶯邊緣架構模式
舉個例子,假設有北京、上海、美東三個數據中心,北京和上海之間有良好的專線打通,而美東和國內網絡鏈路較差。
北京、上海、美東三地均部署了服務,指標和日志都選擇落在本地,而非傳輸到中心。假設指標使用 VictoriaMetrics 存儲,日志使用 ElasticSearch 存儲,整體示例如下:
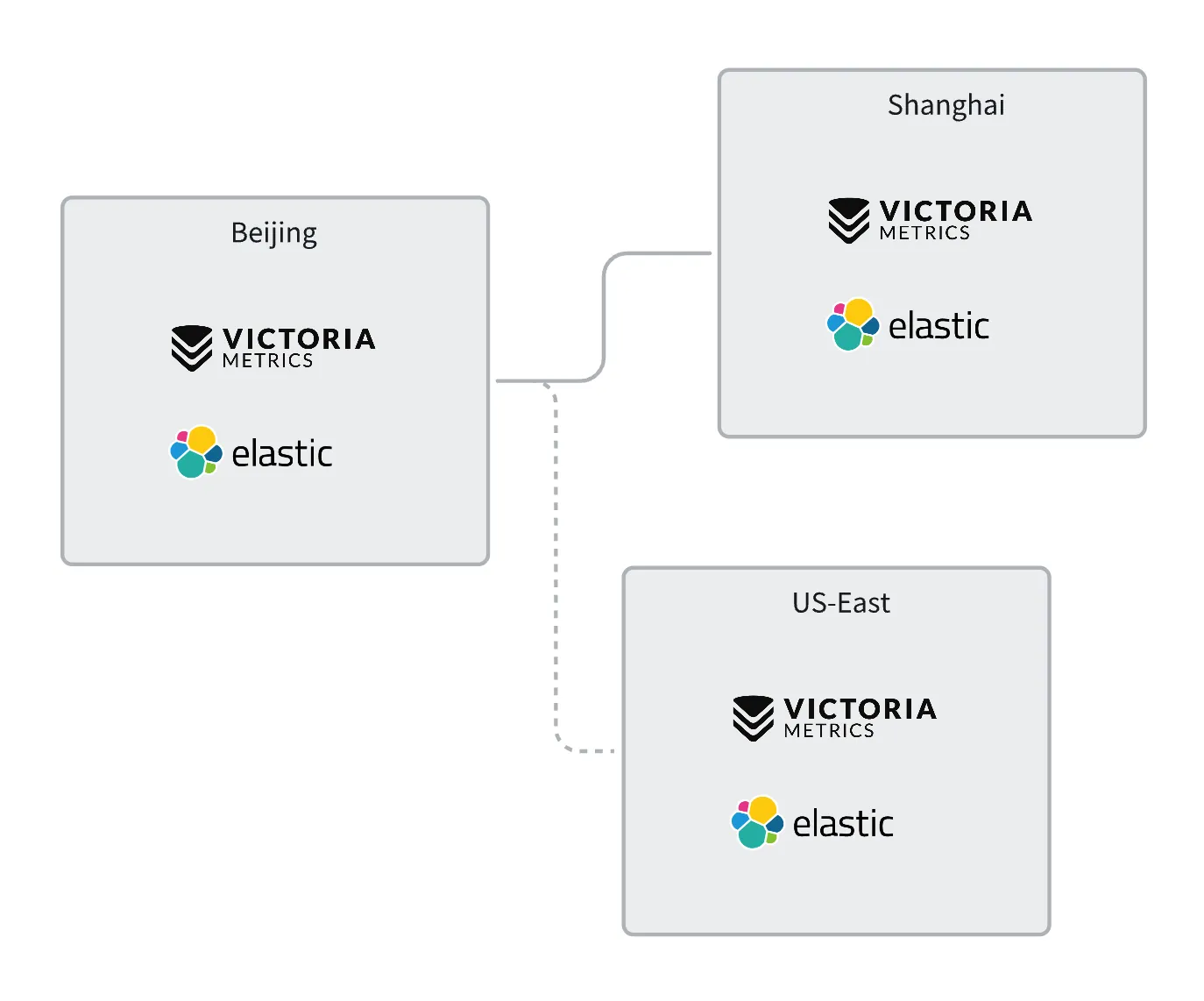
北京、上海機房既然網絡鏈路很好,姑且可以看做是同一個機房,用一套夜鶯統一處理,比如就把夜鶯部署在北京機房,讓夜鶯讀取北京、上海的數據源,做告警判定。那美東呢?讓北京機房的夜鶯讀取美東的數據源做告警是不行的,因為網絡鏈路不好,經常超時。
告警判定是周期性的,比如15秒一次,很頻繁,我們需要確保查詢時網絡鏈路是好的,最佳實踐就是把告警引擎直接部署到美東,這樣本機房查詢,就沒問題了。
所以,夜鶯引入了邊緣機房部署架構。可以把告警引擎抽離出來作為一個單獨的模塊,部署到美東。這個模塊可以從中心端夜鶯同步告警規則,把告警規則存在內存里,然后查詢本地數據源的數據,做告警判定。
架構示意圖:
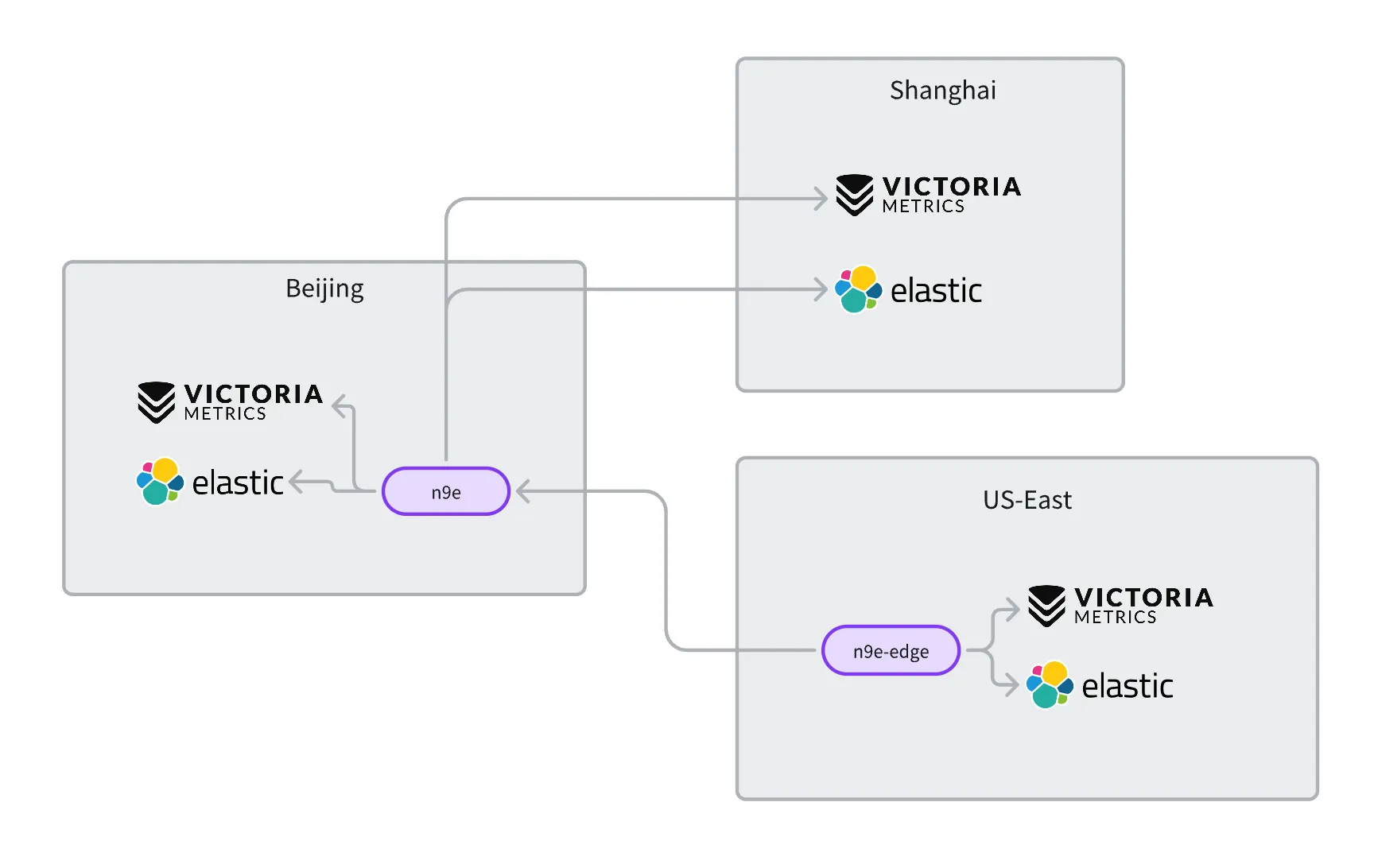
夜鶯中心端的進程叫 n9e,n9e 是 nightingale 的縮寫,邊緣機房(這里是指美東機房)單獨部署了一個 n9e-edge 進程。
n9e-edge 進程要連中心端的 n9e,所以你在 n9e-edge 的配置文件里,需要指定 n9e 的 HTTP 地址和認證信息(如需)。
如果美東和北京的網絡臨時中斷了,影響也不大,美東的 n9e-edge 沒法從北京的 n9e 同步告警規則了,不算太大的問題。另外 n9e-edge 產生的告警事件沒法寫到中心數據庫了,所以你在頁面上沒法看到相關的告警事件,但只要美東的外網出口沒問題,n9e-edge 產生的告警事件還是可以推送出去的,因為告警媒介都是走的外網,比如釘釘、企微、Slack,都是外網 SaaS 服務。
預告
本篇先到這里。下一篇預告:夜鶯沒有自研時序存儲,卻又提供了 agent,有點擰巴,到底是為啥?

 浙公網安備 33010602011771號
浙公網安備 33010602011771號