
Prometheus 監(jiān)控 Kubernetes Cluster 最新極簡(jiǎn)教程

Kubernetes 是在生產(chǎn)中運(yùn)行容器化工作負(fù)載的最流行的編排器。它為您提供了一套完整的工具,用于部署、擴(kuò)展和管理容器。
不過,僅靠 Kubernetes 不足以運(yùn)維應(yīng)用程序。您還需要了解集群利用率、性能和發(fā)生的任何錯(cuò)誤。 Prometheus 是一個(gè)開源監(jiān)控系統(tǒng),它收集時(shí)序指標(biāo)到 TSDB,讓您可以回答這些問題。
在本文中 ,您將學(xué)習(xí)如何在 Kubernetes 集群中設(shè)置和使用 Prometheus。我們將介紹安裝 Prometheus、查詢數(shù)據(jù)、設(shè)置可視化儀表板和管理警報(bào)規(guī)則的基礎(chǔ)知識(shí)。 在開始之前,您需要 Kubectl、Helm 和 Kubernetes 集群。
我們將涵蓋:
- 什么是 Prometheus
- 為什么使用 Prometheus 監(jiān)控 Kubernetes
- 什么是 kube-prometheus-stack
- 如何在 Kubernetes 集群設(shè)置 Prometheus 監(jiān)控
- Kubernetes Prometheus 最佳實(shí)踐
什么是 Prometheus
Prometheus 是 CNCF 旗下的開源監(jiān)控和警報(bào)工具包。它有一個(gè)強(qiáng)大的時(shí)間序列數(shù)據(jù)庫,旨在實(shí)現(xiàn)存儲(chǔ)和查詢指標(biāo)數(shù)據(jù)的最佳性能。
它采用基于拉取的指標(biāo)收集方法,定期主動(dòng)從應(yīng)用程序端點(diǎn)和服務(wù)器獲取數(shù)據(jù)。通過這種方式,它可以實(shí)時(shí)洞察被監(jiān)控系統(tǒng)的運(yùn)行狀況和性能,從而允許通過各種機(jī)制(例如 K8s 服務(wù)發(fā)現(xiàn))動(dòng)態(tài)發(fā)現(xiàn)目標(biāo)。
為什么使用 Prometheus 進(jìn)行 Kubernetes 監(jiān)控
使用 Prometheus 進(jìn)行 Kubernetes 監(jiān)控的原因有很多:
- 內(nèi)置對(duì) K8s 服務(wù)發(fā)現(xiàn)的支持 – 在 K8s 集群中部署和擴(kuò)展新服務(wù)和 Pod 時(shí)自動(dòng)發(fā)現(xiàn)和監(jiān)控它們
- 豐富的數(shù)據(jù)模型 – 根據(jù) Pod 標(biāo)簽、命名空間、服務(wù)名稱等各種屬性對(duì)指標(biāo)進(jìn)行精細(xì)分類和查詢
- 與可視化工具集成 – 與 Grafana 無縫集成,使用戶能夠創(chuàng)建自定義儀表板和可視化,以更深入地了解 K8s 指標(biāo)
- 可擴(kuò)展性和性能 – Prometheus 以最小的資源開銷處理大量數(shù)據(jù),使其成為 Kubernetes 的理想選擇
- 久經(jīng)考驗(yàn)的可靠性 – 它已被許多各種規(guī)模的組織用于監(jiān)控 Kubernetes 環(huán)境,可應(yīng)對(duì)不斷變化的 K8s 環(huán)境
- 社區(qū)支持 – Prometheus 和 Kubernetes 都是 CNCF 的一部分,CNCF 擁有龐大的社區(qū)以及強(qiáng)大的文檔和教程
- 開源 – Prometheus 是開源的,使其成為監(jiān)控 Kubernetes 的靈活選擇
什么是 kube-prometheus-stack
kube-prometheus-stack Helm chart 是在 Kubernetes 集群中啟動(dòng)完整 Prometheus 堆棧的最簡(jiǎn)單方法。它將多個(gè)不同的組件捆綁在一個(gè)自動(dòng)化部署中:
- Prometheus - Prometheus 是一個(gè)時(shí)間序列數(shù)據(jù)庫,用于抓取、存儲(chǔ)和公開 Kubernetes 環(huán)境及其應(yīng)用程序中的指標(biāo)。
- Node-Exporter - Prometheus 的工作原理是從稱為導(dǎo)出器的各種可配置來源抓取數(shù)據(jù) 。 Node-Exporter 是一個(gè)導(dǎo)出器,它從 Kubernetes 集群中的節(jié)點(diǎn)收集資源利用率數(shù)據(jù)。kube-prometheus-stack chart 會(huì)自動(dòng)部署此導(dǎo)出器,并配置您的 Prometheus 實(shí)例以抓取它。
- Kube-State-Metrics – Kube-State-Metrics 是另一個(gè)向 Prometheus 提供數(shù)據(jù)的導(dǎo)出器。它公開有關(guān) Kubernetes 集群中 API 對(duì)象的信息,例如 Pod 和容器。
- Grafana – 雖然您可以直接查詢 Prometheus,但這通常是乏味且重復(fù)的。 Grafana 是一個(gè)可觀測(cè)性平臺(tái),可與多個(gè)數(shù)據(jù)源配合使用,包括 Prometheus 數(shù)據(jù)庫。您可以使用它來創(chuàng)建顯示 Prometheus 數(shù)據(jù)的儀表板。
- Alertmanager – Alertmanager 是一個(gè)獨(dú)立的 Prometheus 組件,可在指標(biāo)發(fā)生變化時(shí)提供通知。例如,你可以使用它在 CPU 利用率飆升時(shí)接收電子郵件,或者在 Pod 被逐出時(shí)接收 Slack 通知。
單獨(dú)部署、配置和維護(hù)所有這些組件對(duì)管理員來說可能是負(fù)擔(dān)。Kube-Prometheus-Stack 提供了一個(gè)自動(dòng)化解決方案,可以為您執(zhí)行所有艱苦的工作。
如何在 Kubernetes 集群上設(shè)置 Prometheus 監(jiān)控
讓我們看看如何在實(shí)踐中將 Prometheus 與 Kubernetes 集群一起設(shè)置和使用。
1. 安裝 kube-prometheus-stack
首先,在 Helm 客戶端中注冊(cè) chart 存儲(chǔ)庫:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
接下來,更新存儲(chǔ)庫列表以發(fā)現(xiàn) chart:
$ helm repo update
現(xiàn)在,您可以運(yùn)行以下命令將 chart 部署到集群中的新命名空間中:
$ helm install kube-prometheus-stack \
--create-namespace \
--namespace kube-prometheus-stack \
prometheus-community/kube-prometheus-stack
NAME: kube-prometheus-stack
LAST DEPLOYED: Tue Jan 3 14:26:18 2023
NAMESPACE: kube-prometheus-stack
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace kube-prometheus-stack get pods -l "release=kube-prometheus-stack"
chart 的組件可能需要幾分鐘才能啟動(dòng)。運(yùn)行以下命令以檢查它們的進(jìn)度:
$ kubectl -n kube-prometheus-stack get pods
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 1 (66s ago) 83s
kube-prometheus-stack-grafana-5cd658f9b4-cln2c 3/3 Running 0 99s
kube-prometheus-stack-kube-state-metrics-b64cf5876-52j8l 1/1 Running 0 99s
kube-prometheus-stack-operator-754ff78899-669k6 1/1 Running 0 99s
kube-prometheus-stack-prometheus-node-exporter-vdgrg 1/1 Running 0 99s
prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 83s
一旦所有 Pod 都顯示為 Running, 您的監(jiān)控堆棧就可以使用了。導(dǎo)出器暴露的數(shù)據(jù)將被 Prometheus 自動(dòng)抓取。
現(xiàn)在,您可以開始查詢指標(biāo)了。
2. 查詢 Prometheus
Prometheus 包含一個(gè) Web UI,您可以使用它來查詢數(shù)據(jù)。這不會(huì)自動(dòng)公開。您可以使用 Kubectl 端口轉(zhuǎn)發(fā)將本地流量重定向到集群中的服務(wù)來訪問它:
$ kubectl port-forward -n kube-prometheus-stack svc/kube-prometheus-stack-prometheus 9090:9090
Forwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
此命令將流量重定向到 localhost:9090 到 Prometheus 服務(wù)。在 Web 瀏覽器中訪問此 URL 將顯示 Prometheus UI:

屏幕頂部的“表達(dá)式”輸入是將查詢作為 PromQL 表達(dá)式輸入的地方。開始輸入以顯示可用指標(biāo)的自動(dòng)提示。
嘗試選擇 node_memory_Active_bytes 指標(biāo),該指標(biāo)顯示集群中每個(gè)節(jié)點(diǎn)的內(nèi)存消耗。按“執(zhí)行”按鈕運(yùn)行查詢。結(jié)果將顯示在 Table 中:

大多數(shù)指標(biāo)使用 Graph 更容易查看。
切換到屏幕頂部的“Graph”選項(xiàng)卡,查看一段時(shí)間內(nèi)指標(biāo)的可視化效果。您可以使用圖表上方的控件來更改顯示的時(shí)間段。
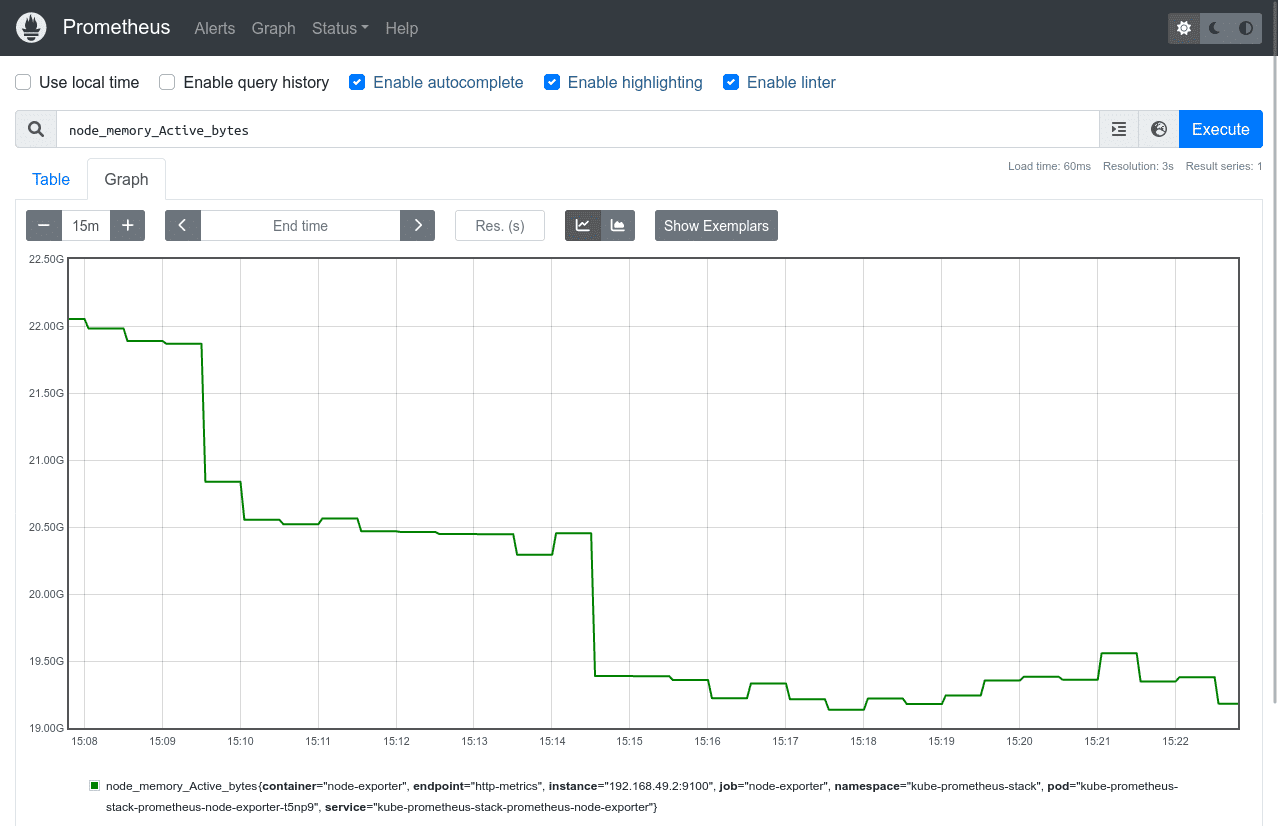
PromQL 查詢?cè)试S對(duì)您的數(shù)據(jù)進(jìn)行詳細(xì)查詢。然而,在 Prometheus UI 中手動(dòng)運(yùn)行單個(gè)查詢是一種低效的監(jiān)控形式。
接下來,讓我們使用 Grafana 在實(shí)時(shí)儀表板上方便地可視化指標(biāo)。
3. 使用 Grafana 儀表盤
啟動(dòng)新的 Kubectl 端口轉(zhuǎn)發(fā)會(huì)話以訪問 Grafana UI。使用端口 80 作為目標(biāo),因?yàn)檫@是 Grafana 服務(wù)綁定到的端口。
您可以在以下示例中將其映射到不同的本地端口,例如 8080:
$ kubectl port-forward -n kube-prometheus-stack svc/kube-prometheus-stack-grafana 8080:80
Forwarding from 127.0.0.1:8080 -> 3000
Forwarding from [::1]:8080 -> 3000
接下來,在瀏覽器中訪問 http://localhost:8080。您將看到 Grafana 登錄頁面。默認(rèn)用戶帳戶是 admin, 密碼為 prom-operator。
登錄后,您將首先進(jìn)入 Grafana 歡迎屏幕:
使用側(cè)邊欄切換到“儀表板”屏幕。它的圖標(biāo)是四個(gè)排列成類似玻璃板的正方形。在這里可以找到所有已保存的儀表板,包括 Kube-Prometheus-Stack 部署附帶的預(yù)構(gòu)建儀表板。

4. 探索 Grafana 預(yù)構(gòu)建的儀表板
包含幾個(gè)儀表板,其中包含從 Node-Exporter、Kube-State-Metrics 以及各種 Kubernetes 和 Prometheus 組件中抓取的指標(biāo)。以下是一些值得注意的:
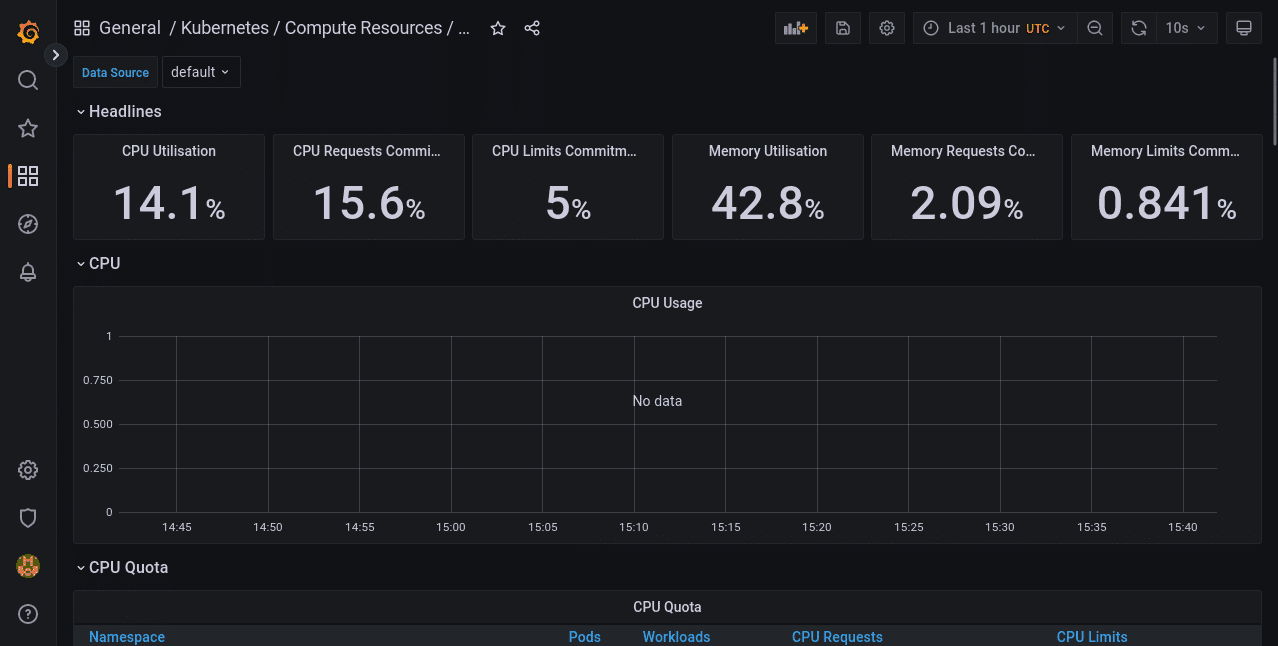
使用 Kubernetes / Compute Resources / Cluster 監(jiān)控集群利用率。
此儀表板概述了整個(gè)集群的資源利用率。標(biāo)題統(tǒng)計(jì)數(shù)據(jù)顯示在頂部,更詳細(xì)的信息顯示在下面的面板中。
使用 Node Exporter / Nodes 查看節(jié)點(diǎn)資源消耗。
Node-Exporter 收集的數(shù)據(jù)由此儀表板提供。它顯示了每個(gè)節(jié)點(diǎn)的詳細(xì)資源利用率信息。您可以使用儀表板頂部的“實(shí)例”下拉列表更改所選節(jié)點(diǎn)。

使用 Kubernetes / Compute Resources / Pod 查看單個(gè) Pod 的資源消耗。
此儀表板顯示單個(gè) Pod 的資源請(qǐng)求、限制、配額和利用率。你可以從屏幕頂部的下拉列表中選擇要查看的命名空間和 Pod。
可以使用屏幕右上角的控件在所有 Grafana 儀表板上自定義時(shí)間范圍。您可以使用時(shí)間范圍選擇器旁邊的按鈕刷新數(shù)據(jù)或更改自動(dòng)刷新間隔。
5.使用 Alertmanager 配置警報(bào)
監(jiān)控必須自動(dòng)化才能有效。當(dāng)重要指標(biāo)超出預(yù)期時(shí),例如當(dāng)內(nèi)存消耗出現(xiàn)峰值時(shí),您需要收到警報(bào)。否則,您必須不斷檢查儀表板或運(yùn)行查詢以確定是否需要采取措施。
Prometheus 包含 Alertmanager,可在指標(biāo)觸發(fā)警報(bào)時(shí)向您發(fā)送通知。Alertmanager 支持多個(gè)接收器,這些接收器充當(dāng)警報(bào)的目的地,例如電子郵件、Slack、消息應(yīng)用程序和您自己的 Webhook。
Kube-Prometheus-Stack 的捆綁 Alertmanager 是通過在使用 Helm 部署時(shí)合并自定義 chart values 來配置的。首先,準(zhǔn)備一個(gè) YAML 文件,該文件將 Alertmanager 設(shè)置嵌套在頂級(jí) alertmanager 鍵下。下面是一個(gè)將所有警報(bào)發(fā)送到 Webhook URL 的示例:
alertmanager:
config:
global:
resolve_timeout: 5m
route:
receiver: demo-webhook
group_wait: 5s
group_interval: 10s
repeat_interval: 1h
receivers:
- name: "null"
- name: demo-webhook
webhook_configs:
- url: http://example.com/webhook
send_resolved: true
路由部分指定警報(bào)應(yīng)定向到 demo-webhook 接收器。這配置為 在每次觸發(fā)或解決警報(bào)時(shí)向 http://example.com/webhook 發(fā)送 POST 請(qǐng)求。請(qǐng)求的有效負(fù)載在 Alertmanager 文檔中進(jìn)行了描述 。請(qǐng)注意,需要額外的 “null” 接收器是為了規(guī)避一些 Alertmanager 版本的 bug。
將 YAML 文件保存到工作目錄中的 alertmanager-config.yaml 中。接下來,運(yùn)行以下命令重新部署 Prometheus 堆棧并應(yīng)用您的 Alertmanager 設(shè)置:
$ helm upgrade --reuse-values \
-f alertmanager-config.yaml \
-n kube-prometheus-stack \
kube-prometheus-stack
prometheus-community/kube-prometheus-stack
別擔(dān)心 - 您不會(huì)丟失任何現(xiàn)有數(shù)據(jù)。該命令執(zhí)行部署的就地升級(jí)。
部署完成后,Alertmanager 可能需要幾分鐘才能重新加載其配置。然后,隨著警報(bào)的觸發(fā),您將開始接收對(duì) Webhook URL 的請(qǐng)求。
要發(fā)送測(cè)試警報(bào),請(qǐng)首先啟動(dòng)到 Alertmanager 實(shí)例的端口轉(zhuǎn)發(fā)會(huì)話:
$ kubectl port-forward -n kube-prometheus-stack svc/kube-prometheus-stack-alertmanager 9093:9093
接下來,運(yùn)行以下命令以模擬從特定命名空間中的 Kubernetes 服務(wù)觸發(fā)警報(bào):
$ curl -H 'Content-Type: application/json' -d '[{"labels":{"alertname":"alert-demo","namespace":"demo","service":"demo"}}]' http://127.0.0.1:9093/api/v1/alerts
片刻之后,您應(yīng)該會(huì)收到對(duì) Webhook URL 的請(qǐng)求。請(qǐng)求正文將描述警報(bào)的詳細(xì)信息。
Kubernetes Prometheus 最佳實(shí)踐
將 Prometheus 與 Kubernetes 一起使用時(shí),應(yīng)考慮以下事項(xiàng):
- 對(duì) K8s 使用 Prometheus operator
- 配置 service monitors
- 利用 K8s 標(biāo)簽和注釋
- 利用 Prometheus 的持久存儲(chǔ)
- 設(shè)置 Alertmanager
- 監(jiān)控 Prometheus 性能
- 保護(hù)您的 Prometheus 實(shí)例
- 定期更新
1. 對(duì) K8s 使用 Prometheus operator
使用 Prometheus operator 部署 Prometheus 將有助于自動(dòng)管理 Prometheus 實(shí)例及其配置。
這將允許您使用 K8s CRD 以聲明方式定義您的監(jiān)控要求。
2. 配置 service monitors
service monitors 用于根據(jù)標(biāo)簽和注釋動(dòng)態(tài)發(fā)現(xiàn)和配置 K8s 集群內(nèi)部的監(jiān)控目標(biāo)。
3. 利用 K8s 標(biāo)簽和注釋
標(biāo)簽和注釋是組織 K8s 集群內(nèi)資源的關(guān)鍵,可以更輕松地定義要監(jiān)控的內(nèi)容。為您的 K8s 資源使用有意義的標(biāo)簽,并將這些標(biāo)簽用于動(dòng)態(tài)和靈活的監(jiān)控設(shè)置,是使您的集成有價(jià)值的關(guān)鍵。
4. 利用 Prometheus 的持久存儲(chǔ)
Prometheus 使用時(shí)間序列數(shù)據(jù)庫來存儲(chǔ)您的數(shù)據(jù)。如果沒有持久存儲(chǔ),如果重新啟動(dòng) Prometheus Pod,則可能會(huì)丟失收集的所有數(shù)據(jù)。這里的最佳實(shí)踐是在 K8s 中使用持久卷 (PV),以確保您的 Prometheus 數(shù)據(jù)在重新啟動(dòng)后保留。
5. 設(shè)置 Alertmanager
Prometheus 的 Alertmanager 負(fù)責(zé)對(duì)客戶端應(yīng)用程序發(fā)送的警報(bào)進(jìn)行重復(fù)數(shù)據(jù)刪除、分組和路由。您應(yīng)該將其配置為有效管理警報(bào),還可以利用它根據(jù)警報(bào)的嚴(yán)重性或您定義的其他方面將這些警報(bào)發(fā)送到電子郵件、Slack 甚至其他通知渠道。
6. 監(jiān)控 Prometheus 性能
即使在這種情況下使用 Prometheus 來監(jiān)控與 K8s 集群相關(guān)的方面,監(jiān)控其性能也至關(guān)重要,以確保它不會(huì)成為瓶頸。如果您的目標(biāo)數(shù)量較多或指標(biāo)較高,請(qǐng)根據(jù)需要調(diào)整分配給 Prometheus 的資源。
7. 保護(hù)您的 Prometheus 實(shí)例
當(dāng)涉及到基礎(chǔ)設(shè)施組件時(shí),您應(yīng)該始終注意保護(hù)它們,Prometheus 也不例外。防止未經(jīng)授權(quán)訪問您的監(jiān)控?cái)?shù)據(jù)至關(guān)重要,因此您應(yīng)該使用 K8s RBAC 來控制訪問,并為 Prometheus 的端點(diǎn)和 Web 界面啟用 HTTPS。
8. 定期更新
使 Prometheus 和 Operator 保持最新狀態(tài)可確保您在 Prometheus 實(shí)例中擁有最新的安全補(bǔ)丁、功能和性能改進(jìn)。
要點(diǎn)
良好的可觀測(cè)性對(duì)于運(yùn)行生產(chǎn)工作負(fù)載的 Kubernetes 集群至關(guān)重要。你需要了解資源利用率,查看 Pod 的調(diào)度位置,并跟蹤應(yīng)用程序發(fā)出的錯(cuò)誤和日志。
Kube-Prometheus-Stack 是為集群設(shè)置監(jiān)控的便捷途徑。它為您配置 Prometheus、Grafana、Alertmanager 和重要指標(biāo)導(dǎo)出器,從而減少維護(hù)開銷。基本安裝附帶有用的預(yù)構(gòu)建儀表板,您可以使用從自己的應(yīng)用程序中抓取的自定義查詢和指標(biāo)進(jìn)行擴(kuò)展。為 Prometheus 檢測(cè)系統(tǒng)是一個(gè)復(fù)雜的主題,但您可以通過探索官方客戶端庫來開始,以從代碼中導(dǎo)出指標(biāo)。
作者:James Walker 是 Heron Web 的創(chuàng)始人,這是一家總部位于英國的軟件開發(fā)工作室,為中小企業(yè)提供定制解決方案。他擁有使用 DevOps、CI/CD、Docker 和 Kubernetes 管理完整的端到端 Web 開發(fā)工作流程的經(jīng)驗(yàn)。James 還是一名技術(shù)作家,撰寫了大量關(guān)于軟件開發(fā)生命周期、當(dāng)前行業(yè)趨勢(shì)以及 DevOps 概念和技術(shù)的文章。
原文鏈接:https://spacelift.io/blog/prometheus-kubernetes
譯者:巴輝特,開源監(jiān)控項(xiàng)目 Open-Falcon、Nightingale 創(chuàng)始人,極客時(shí)間專欄《運(yùn)維監(jiān)控系統(tǒng)實(shí)戰(zhàn)筆記》作者,快貓星云聯(lián)合創(chuàng)始人。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)