
夜鶯監控的幾種架構模式詳解
對于 IT 的穩定性保障,越來越受到重視,據國外數據統計,監控、可觀測性相關的支出大概占總體 IT 支出的 5%~8% 左右。CNCF 作為知名基金會,旗下最有名的項目當屬 Kubernetes,其次兩個重點項目 OpenTelemetry 和 Prometheus 都與監控、可觀測性相關。
可觀測性領域通常講有三大支柱:Metrics、Logs、Traces,也就是三類數據。
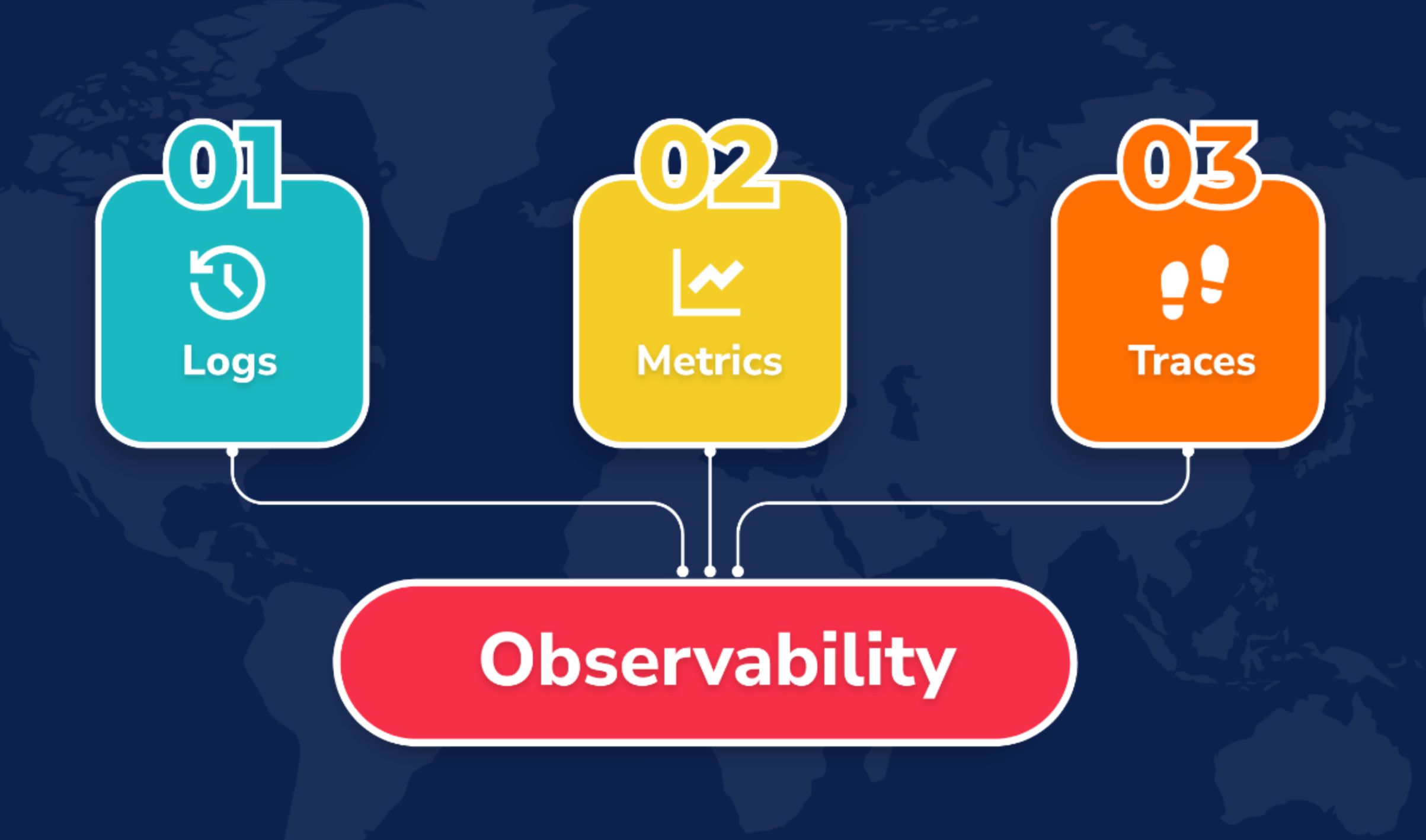
為了建設這些可觀測性數據基座,各個公司會建設各種零零散散的系統,比如:
- Metrics:Zabbix、Prometheus、VictoriaMetrics
- Logs:ELK、ClickHouse、OpenSearch、Splunk
- Traces:Jaeger、Skywalking、SigNoz
再加上公有云上的云監控、云日志等系統,隨便一個中型公司,其相關系統的數量都會超過 5 套。
于是,就衍生了一個自然而然的問題:
哪些能力是可以整合為一個系統的?不要這么分散,體驗不一致,體驗太差
其實是有的,開源社區的 Grafana 就是把看圖可視化能力給整合到一起了。存儲領域,ClickHouse 也有一統江湖的雄心,事件 On-call 領域則是 PagerDuty、FlashDuty 的戰場。
今天為大家介紹另一個開源項目:Nightingale,是在嘗試整合告警能力,支持對接常見數據源,讓用戶配置告警規則,周期性查詢這些數據源里的數據,對數據做異常判定進而生成告警事件。
夜鶯項目簡介
夜鶯監控(Nightingale)是一款側重告警的監控類開源項目。類似 Grafana 的數據源集成方式,夜鶯也是對接多種既有的數據源,不過 Grafana 側重在可視化,夜鶯是側重在告警引擎、告警事件的處理和分發。
夜鶯監控項目,最初由滴滴開發和開源,并于 2022 年 5 月 11 日,捐贈予中國計算機學會開源發展委員會(CCF ODC),為 CCF ODC 成立后接受捐贈的第一個開源項目。
其開源倉庫地址:
夜鶯架構介紹
夜鶯的職能就是做告警引擎,所以架構很簡單,當然,因為夜鶯也支持轉發指標數據、支持告警自愈、支持邊緣模式告警引擎,因為這些長尾需求讓架構上也變復雜了。但是長尾需求畢竟是長尾需求,用的人少,今天我們就介紹夜鶯最經典精簡的架構,這也是所有夜鶯用戶都應該了解的。
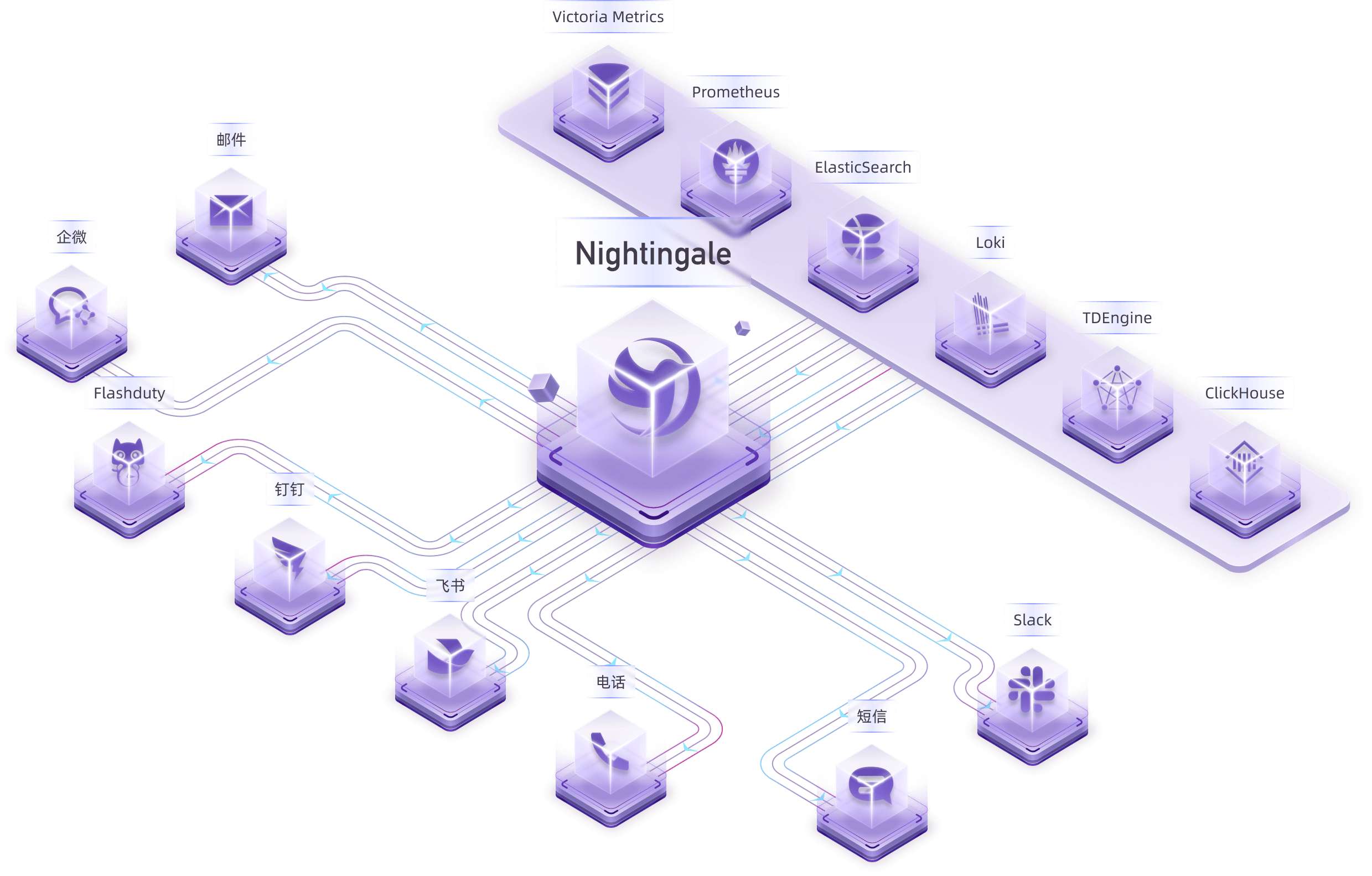
我畫了一張架構圖如下:

首先,夜鶯可以對接各類數據源(這個設計和 Grafana 很像),比如上圖下方的 Prometheus、VictoriaMetrics、ElasticSearch、MySQL、ClickHouse、Doris、OpenSearch、PostgreSQL 等等。
然后,夜鶯內置一個告警引擎,根據用戶配置的告警規則周期性查詢數據源并生成告警事件,生成的告警事件需要分發出去,也就是通過右側的 FlashDuty、Slack 等等通知媒介。
夜鶯要讓用戶配置告警規則、查看告警事件,需要需要一個 UI 和用戶交互,所以夜鶯內置一個 API 模塊。另外,夜鶯要把用戶配置的告警規則存入 MySQL,一些緩存數據需要用到 Redis,所以,夜鶯依賴 MySQL 和 Redis 兩個存儲。
Nightingale-Web-API 和 Nightingale-Alerting-Engine 都是夜鶯進程里的兩個職能,并非是兩個單獨的進程,這兩個職能都在一個 n9e 進程里。
上面的架構是夜鶯不介入數據采集和傳輸環節,需要你自行采集數據,夜鶯只是去查。如果你想讓夜鶯來采集數據行么?也行,不過僅限于指標數據。夜鶯本身其實沒有數據采集的能力,但是夜鶯可以和另一個開源項目 Categraf 協同,來采集 OS、數據庫、中間件、SNMP 等各類監控數據。
Categraf 會把采集的數據推送給夜鶯,不過夜鶯沒有內置時序數據的存儲(即 TSDB),所以夜鶯實際是把數據做了轉發,轉存到其他時序庫(比如 Prometheus、VictoriaMetrics)。
如果把數據采集和轉存的邏輯也畫到架構圖上,那新的架構就變成了:

上圖沒有畫出通知媒介,也沒有把夜鶯進程內部的兩個職能畫出來,是因為畫布太小,重點突出數據采集、轉存鏈路。
Categraf 需要部署在所有待監控機器上,因為 CPU、內存、磁盤、網絡、IO 等監控數據需要讀取本機的信息。然后,所有的 Categraf 把采集的監控數據推送給夜鶯,夜鶯轉存入 TSDB,上圖的話,是轉存到了 VictoriaMetrics,這是和 Prometheus 兼容的時序庫,性能更好而且有集群模式。
具體而言,是在夜鶯的配置文件里 config.toml 配置了一個 Pushgw.Writers 部分,指向了時序庫的 Remote Write 地址,夜鶯收到監控數據之后,就是轉發給了這個地址。
最后,我們再講一下邊緣架構模式。
邊緣架構模式
邊緣架構模式的起因是:
- 公司有多個機房,不同的機房之間網絡鏈路不太好,甚至是單向連通的
- 不同的機房可能單獨部署了時序庫、日志庫等數據源
- 希望在中心端的夜鶯 Web 上統一管理告警規則
- 但是告警引擎要頻繁訪問數據源,就需要單獨提取一個邊緣告警引擎的模塊,部署到邊緣機房,部署到邊緣數據源的旁邊,這樣性能好,不會因為網絡問題影響告警
于是,除了部署在中心端的 n9e,邊緣機房還可以部署 n9e-edge,引入了 n9e-edge 之后,架構變成了:

上圖為例,中心機房部署了夜鶯 n9e 進程,機房 A 和中心機房之間有良好的網絡質量,那就可以把中心機房的 Prometheus、VictoriaMetrics 都直接交給中心的 n9e 進程負責告警判定。
但是機房 B 和中心機房之間的網絡鏈路不好,而機房 B 內部也有 Prometheus、VictoriaMetrics,此時建議在機房 B 內部部署一個 n9e-edge 進程,負責機房 B 的兩個時序庫的告警判定。
n9e-edge 會從中心端 n9e 同步告警規則到內存里,這樣后面如果網絡斷了,頂多是告警規則短期不更新了,沒有其他太大的影響,n9e-edge 根據內存里的告警規則,周期性查詢本機房的時序庫,產生告警事件,通過外網出口,投遞給釘釘、飛書、Slack、FlashDuty 等外網通知媒介。
總結
本文通過幾張圖,試圖講清楚夜鶯監控的架構,更多信息請參考夜鶯的 官方文檔。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號