
先驗(yàn)分布:(三)Dirichlet分布的應(yīng)用——LDA模型
LDA(Latent Dirichlet Allocation)模型是Dirichlet分布的實(shí)際應(yīng)用。
在自然語(yǔ)言處理中,LDA模型及其許多延伸主要用于文本聚類、分類、信息抽取和情感分析等。
例如,我們要對(duì)許多新聞按主題進(jìn)行分類。目前用的比較多的方法是:假設(shè)每篇新聞都有一個(gè)主題,然后通過分析新聞的文本(即組成新聞的詞),推導(dǎo)出新聞屬于某些主題的可能性,這樣就可以按照可能性大小將新聞分類了。
而LDA模型,就是用于分析新聞文本,推導(dǎo)出新聞屬于某些主題可能性的這一過程。
為了做到這點(diǎn),LDA模型有如下假設(shè):
1、每個(gè)文本均有若干個(gè)主題,比如60%是體育、40%是娛樂;
2、每個(gè)主題都有一系列詞語(yǔ),這些詞語(yǔ)反映了該主題(或者說常用詞),比如在體育主題下,運(yùn)動(dòng)員、比賽、比分、冠軍等詞出現(xiàn)的頻率比較高;
3、每個(gè)文本的生成過程是:選取主題 → 從該主題下選取詞語(yǔ) → 詞語(yǔ)形成文本。
在實(shí)際應(yīng)用中,我們得到(或看到)的是由詞語(yǔ)形成的文本,為了將文本分類,我們必須根據(jù)文本倒推主題,即算出該文本下可能有什么主題。這跟文本的生成過程剛好是相反的。
現(xiàn)在假設(shè),一個(gè)文本共有N個(gè)詞:
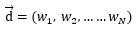
一共有K個(gè)主題:
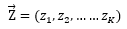
一共有V個(gè)詞語(yǔ)作為詞匯表(主題共用,只是不同主題中詞的出現(xiàn)機(jī)會(huì)不同):
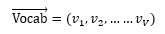
下面我們用剛才提到的文本生成過程來表示這個(gè)文本是怎樣形成的:

過程是這樣的:
1、先(通過某種方式)抽取位置1的詞(也就是文本的第一個(gè)詞)的主題,比如z2,即第二個(gè)主題;
2、該主題下有相應(yīng)的詞匯分布(即每個(gè)詞都有其出現(xiàn)機(jī)會(huì)),在該主題下(通過某種方式)抽取位置1的詞,比如抽到V3,即詞匯表中的第三個(gè)詞;
3、重復(fù)上述兩部,對(duì)位置2、位置3直到位置N的詞進(jìn)行抽取。這樣就形成了一個(gè)文本,比如上表的文本按順序從1到N的詞就是:
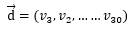
上述過程中的"通過某種方式"就是LDA模型的關(guān)鍵。由于我們事先不知道文本的主題分布,按照貝葉斯派的做法,我們只能先主觀或根據(jù)經(jīng)驗(yàn)人為設(shè)定文本的主題分布,比如體育60%,娛樂40%。這就涉及到之前文章所說的先驗(yàn)概率分布了。
同理,我們事先也不知道特定主題下詞匯的分布,不妨也先主觀或根據(jù)經(jīng)驗(yàn)人為設(shè)定該主題下詞匯的分布,即先驗(yàn)概率分布。
而這兩種先驗(yàn)概率,服從Dirichlet分布:
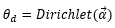
這是一個(gè)文本的主題的分布,也就是說,不同文本的主題分布不同,如果語(yǔ)料有M篇文本,則應(yīng)該有M個(gè)Dirichlet分布。其中:
α是文本主題先驗(yàn)分布的超參數(shù),是一個(gè)K維向量,對(duì)應(yīng)K個(gè)主題,可以將第k個(gè)分量看成是影響第k個(gè)主題出現(xiàn)概率的參數(shù)。
同理,某主題的詞的先驗(yàn)分布為:

這是一個(gè)主題的詞的分布,也就是說,不同主題的詞的分布不同,如果有K個(gè)主題,則應(yīng)該有K個(gè)Dirichlet分布。其中:
β是主題的詞的先驗(yàn)分布的超參數(shù),是一個(gè)V維向量,對(duì)應(yīng)V個(gè)詞匯,可以將第v個(gè)分量看成是影響第v個(gè)詞出現(xiàn)概率的參數(shù)。
我們的目的是通過現(xiàn)象(看到的文本),倒推各文本的主題分布和各主題的詞分布,根據(jù)這兩個(gè)結(jié)果就可以將文本分類了。倒推的原理和可行性在之前的文章已有討論,在此不表。
posted on 2019-05-14 22:24 tspeaking 閱讀(2058) 評(píng)論(0) 收藏 舉報(bào)


 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)