
“思考更長(zhǎng)時(shí)間”而非“模型更大”是提升模型在復(fù)雜軟件工程任務(wù)中表現(xiàn)的有效途徑 | 學(xué)術(shù)研究系列
作者:明巍/臨城/水德
還在為部署動(dòng)輒數(shù)百 GB 顯存的龐大模型而煩惱嗎?還在擔(dān)心私有代碼庫(kù)的安全和成本問(wèn)題嗎?通義靈碼團(tuán)隊(duì)最新研究《Thinking Longer, Not Larger: Enhancing Software Engineering Agents via Scaling Test-Time Compute》探索了如何通過(guò)擴(kuò)展測(cè)試時(shí)計(jì)算(Test-Time Compute Scaling, TTS),讓個(gè)人可部署的開(kāi)源大模型(如僅需單卡運(yùn)行的 32B 模型),達(dá)到與頂級(jí)閉源模型(如 DeepSeek R1, OpenAI o1)相媲美的代碼推理和問(wèn)題解決能力。
核心亮點(diǎn):
-
性能飛躍:32B 模型在結(jié)合了兩種 Test Time Scaling 策略后,在 SWE-bench Verified 基準(zhǔn)上,成功解決了 46.0% 的真實(shí) GitHub Issue,與 DeepSeek R1 和 OpenAI o1 等更大規(guī)模的業(yè)界領(lǐng)先模型表現(xiàn)相當(dāng);
-
實(shí)證 TTS 現(xiàn)象:內(nèi)部 TTS (Internal TTS) 通過(guò)高質(zhì)量、多階段的合成開(kāi)發(fā)軌跡進(jìn)行訓(xùn)練,讓模型學(xué)會(huì)深度思考,模型在面對(duì)更有挑戰(zhàn)的問(wèn)題時(shí),會(huì)動(dòng)態(tài)地分配更多計(jì)算資源(輸出更多 Token),這驗(yàn)證了“思考更長(zhǎng)時(shí)間”確實(shí)能提升模型解決復(fù)雜任務(wù)的能力。
-
最優(yōu)開(kāi)發(fā)過(guò)程搜索:在軟件開(kāi)發(fā)的關(guān)鍵決策點(diǎn)(如倉(cāng)庫(kù)理解、故障定位)進(jìn)行干預(yù),利用過(guò)程獎(jiǎng)勵(lì)模型和結(jié)果獎(jiǎng)勵(lì)模型指導(dǎo)搜索,以更優(yōu)的計(jì)算效率找到最佳解決方案。同時(shí)利用更大的推理 budget 會(huì)產(chǎn)生更優(yōu)的性能。
方法:內(nèi)外兼修的 Test-time Scaling 策略
我們提出了一個(gè)統(tǒng)一的測(cè)試時(shí)計(jì)算(TTS)擴(kuò)展框架,包含兩種互補(bǔ)策略:
1. 內(nèi)部 TTS (Internal Test-Time Scaling): 內(nèi)化深度思考能力
-
高質(zhì)量軌跡合成 (High-Quality Trajectory Synthesis):
- 數(shù)據(jù)源: 從 GitHub 上篩選 超過(guò) 1000 星標(biāo) 的高質(zhì)量倉(cāng)庫(kù),收集真實(shí)的
<issue, pull-request, codebase>三元組數(shù)據(jù)。 - 初始過(guò)濾: 應(yīng)用啟發(fā)式規(guī)則過(guò)濾數(shù)據(jù),例如,保留描述足夠詳細(xì)的 issue (≥20 字符, ≤3 超鏈接),以及修改量適中 (1-5 個(gè)代碼文件, 非純測(cè)試文件修改) 的 PR。
- 環(huán)境構(gòu)建與驗(yàn)證: 利用
ExecutionAgent嘗試為每個(gè)倉(cāng)庫(kù)自動(dòng)構(gòu)建可執(zhí)行的測(cè)試環(huán)境,確保后續(xù)能夠進(jìn)行真實(shí)的補(bǔ)丁驗(yàn)證。無(wú)法成功構(gòu)建或運(yùn)行環(huán)境的倉(cāng)庫(kù)被排除,最終形成包含約 9000 個(gè) issue 和 300 個(gè)倉(cāng)庫(kù) 的高質(zhì)量數(shù)據(jù)集。
- 數(shù)據(jù)源: 從 GitHub 上篩選 超過(guò) 1000 星標(biāo) 的高質(zhì)量倉(cāng)庫(kù),收集真實(shí)的
-
軌跡引導(dǎo)與增強(qiáng) (Trajectory Bootstrapping):
-
基礎(chǔ)框架: 基于開(kāi)源的
SWE-SynInfer框架(包含倉(cāng)庫(kù)理解、故障定位、補(bǔ)丁生成三個(gè)階段),增加了補(bǔ)丁驗(yàn)證 (Patch Verification) 階段,形成SWE-SynInfer+框架。在此階段,模型需生成復(fù)現(xiàn)代碼來(lái)自動(dòng)驗(yàn)證補(bǔ)丁有效性,并在失敗時(shí)進(jìn)行迭代優(yōu)化。 -
引導(dǎo)模型: 使用開(kāi)源推理模型 DeepSeek R1作為教師模型,在其多次內(nèi)部推理迭代和優(yōu)化的能力下,生成詳盡的、包含多輪思考與修正的 長(zhǎng)思維鏈(Long CoT)軌跡。
-
開(kāi)發(fā)上下文的拒絕采樣 (Development-Contextualized Rejection Sampling):
- 多維質(zhì)量把關(guān): 對(duì)生成的軌跡進(jìn)行嚴(yán)格的多維度驗(yàn)證和過(guò)濾:
- 倉(cāng)庫(kù)理解準(zhǔn)確性: 檢查模型識(shí)別的待修改文件是否與開(kāi)發(fā)者實(shí)際修改的文件一致。
- 故障定位準(zhǔn)確性: 確認(rèn)模型生成的補(bǔ)丁是否作用于開(kāi)發(fā)者實(shí)際修改的代碼位置(類、函數(shù)、代碼塊)。
- Issue 復(fù)現(xiàn)代碼有效性: 驗(yàn)證生成的復(fù)現(xiàn)代碼能否在原始代碼上觸發(fā)問(wèn)題,在應(yīng)用開(kāi)發(fā)者補(bǔ)丁后問(wèn)題消失。
- 補(bǔ)丁正確性: 應(yīng)用模型補(bǔ)丁后,運(yùn)行其生成的復(fù)現(xiàn)代碼和倉(cāng)庫(kù)原有的單元測(cè)試,檢查問(wèn)題是否解決且無(wú)新問(wèn)題引入。
- 復(fù)雜性過(guò)濾: 篩除掉基礎(chǔ)模型(Qwen2.5 Coder 32B)無(wú)需復(fù)雜推理就能一次性解決的簡(jiǎn)單問(wèn)題,確保訓(xùn)練數(shù)據(jù)能有效激發(fā)模型的深度推理潛力。
- 保留有效中間步驟: 如果一個(gè)軌跡的補(bǔ)丁驗(yàn)證失敗,但之前的倉(cāng)庫(kù)理解、故障定位等步驟是正確的,保留這些正確的中間步驟數(shù)據(jù),避免浪費(fèi)有價(jià)值的推理過(guò)程信息。
- 多維質(zhì)量把關(guān): 對(duì)生成的軌跡進(jìn)行嚴(yán)格的多維度驗(yàn)證和過(guò)濾:
-
推理式訓(xùn)練 (Reasoning Training):
- 學(xué)習(xí)目標(biāo): 采用標(biāo)準(zhǔn)的監(jiān)督學(xué)習(xí),優(yōu)化模型生成正確推理動(dòng)作(包括思考過(guò)程和最終行動(dòng))的條件概率。損失函數(shù)同時(shí)計(jì)算軌跡中每個(gè)步驟的 “思考(think)”(規(guī)劃、反思、修正等)和 “回答(answer)”(最終輸出的 API 調(diào)用、代碼補(bǔ)丁等)部分,促使模型學(xué)習(xí)完整的決策過(guò)程。
- 歷史信息剪枝: 為提高多輪推理效率,借鑒 DeepSeek R1 的機(jī)制,在生成第
i步時(shí),歷史上下文中只保留第i-1步的answer部分,舍棄think部分,減少冗余信息。
2. 外部 TTS (External Test-Time Scaling): 優(yōu)化決策搜索路徑
-
基于開(kāi)發(fā)流程的搜索策略 (Development-Process-Based Search, Dev-Search):
- 核心思想: 軟件工程任務(wù)是長(zhǎng)鏈條決策過(guò)程,中間步驟的錯(cuò)誤會(huì)嚴(yán)重影響最終結(jié)果。我們摒棄僅在終點(diǎn)驗(yàn)證或?qū)γ恳徊蕉歼M(jìn)行低效驗(yàn)證的做法,選擇在 三個(gè)關(guān)鍵決策階段(倉(cāng)庫(kù)理解、故障定位、補(bǔ)丁生成)集中進(jìn)行搜索和評(píng)估,以高效利用計(jì)算預(yù)算。
-
過(guò)程獎(jiǎng)勵(lì)模型 (Process Reward Model, PRM) 引導(dǎo):
- 訓(xùn)練目標(biāo): 訓(xùn)練 PRM(基于基礎(chǔ)模型微調(diào))來(lái)判斷中間輸出的正確性(二元分類任務(wù))。例如,判斷識(shí)別的文件是否正確,定位的代碼位置是否準(zhǔn)確。
- 引導(dǎo)方式: 在每個(gè)階段生成 N 個(gè)候選輸出,使用 PRM 對(duì)其打分,保留 Top-k 的高分候選進(jìn)入下一階段,實(shí)現(xiàn)輕量級(jí)的、有指導(dǎo)的 Beam Search,有效剪枝低潛力路徑。
-
執(zhí)行驗(yàn)證與結(jié)果獎(jiǎng)勵(lì)模型 (Outcome Reward Model, ORM) 排序:
- 補(bǔ)丁驗(yàn)證: 在補(bǔ)丁生成階段,利用模型生成的復(fù)現(xiàn)代碼和倉(cāng)庫(kù)自帶的回歸測(cè)試,對(duì)候選補(bǔ)丁進(jìn)行執(zhí)行驗(yàn)證,確保其有效性且不破壞原有功能。
- 最終排序: 對(duì)于通過(guò)執(zhí)行驗(yàn)證的多個(gè)候選補(bǔ)丁(可能存在多個(gè)),使用 ORM 進(jìn)行最終排序。ORM 基于 DPO 進(jìn)行訓(xùn)練,學(xué)習(xí)偏好“通過(guò)所有測(cè)試”的補(bǔ)丁優(yōu)于“未通過(guò)測(cè)試”的補(bǔ)丁。重要的是,ORM 僅需 Issue 描述和候選補(bǔ)丁作為輸入,不依賴中間推理步驟,易于集成。
* 所有模型均基于開(kāi)源的Qwen2.5 Coder 32B模型進(jìn)行訓(xùn)練,該模型可在消費(fèi)級(jí)顯卡上進(jìn)行部署。
實(shí)驗(yàn)評(píng)估:
1. 整體性能 SOTA:
- 結(jié)果:訓(xùn)練的 SWE-Reasoner 32B 模型結(jié)合了內(nèi)部和外部 TTS (Unified TTC, budget=8) 后,達(dá)到了 46.0% 的 Issue 解決率。
- 對(duì)比:在 ≤100B 參數(shù)量級(jí)的模型中處于領(lǐng)先地位,超越了如 DeepSeek R1 671B (41.20%) 等更大的開(kāi)源模型,并且接近業(yè)界頂尖的閉源模型 Claude 3.5 Sonnet v2 (46.20%) 和 OpenAI o1 (45.60%) 。(詳見(jiàn)圖1和表1)
- 泛化性與獨(dú)特性: 該模型在 SWE-bench 覆蓋的 12 個(gè)不同 Python 倉(cāng)庫(kù) 上均表現(xiàn)出魯棒的性能,在多數(shù)倉(cāng)庫(kù)上媲美或超越 DeepSeek R1 671B(詳見(jiàn)圖2)。此外,通過(guò)與其他模型的解決實(shí)例對(duì)比,我們的方法能夠獨(dú)立解決 17 個(gè) 其他模型無(wú)法解決的 Issue,展現(xiàn)了獨(dú)特的解題能力。
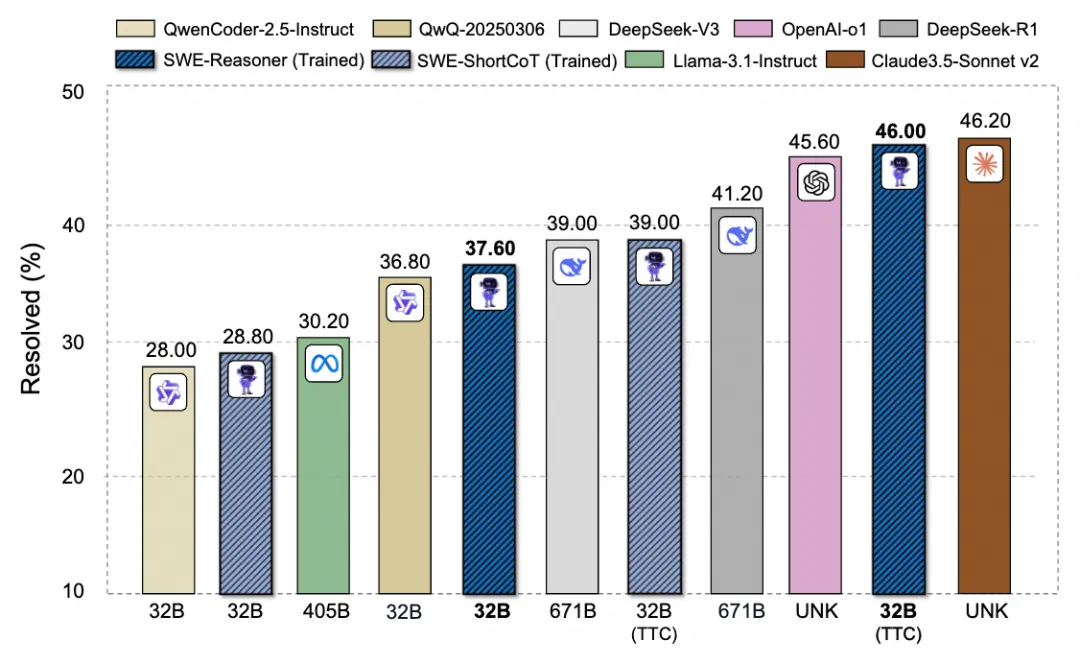
圖 1: 在 SWE-Bench Verified 上,對(duì)具有擴(kuò)展測(cè)試時(shí)間計(jì)算的較小 LLM 與較大模型的性能進(jìn)行比較
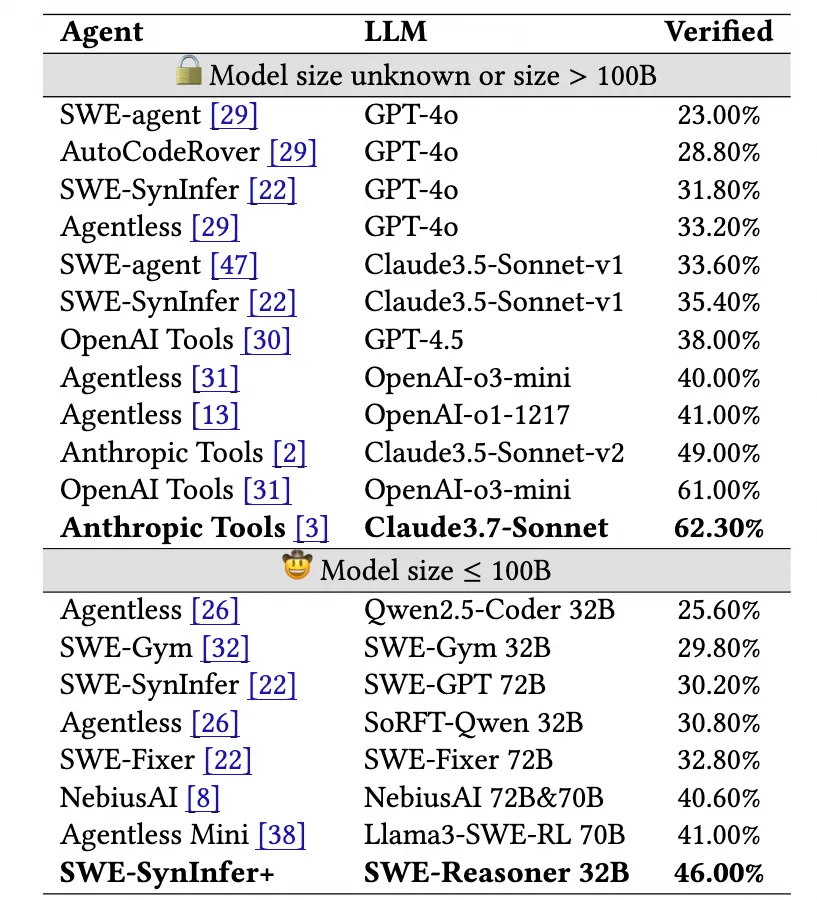
表 1: 與不同模型和框架在 SWE-bench Verified 基準(zhǔn)上的性能比較。
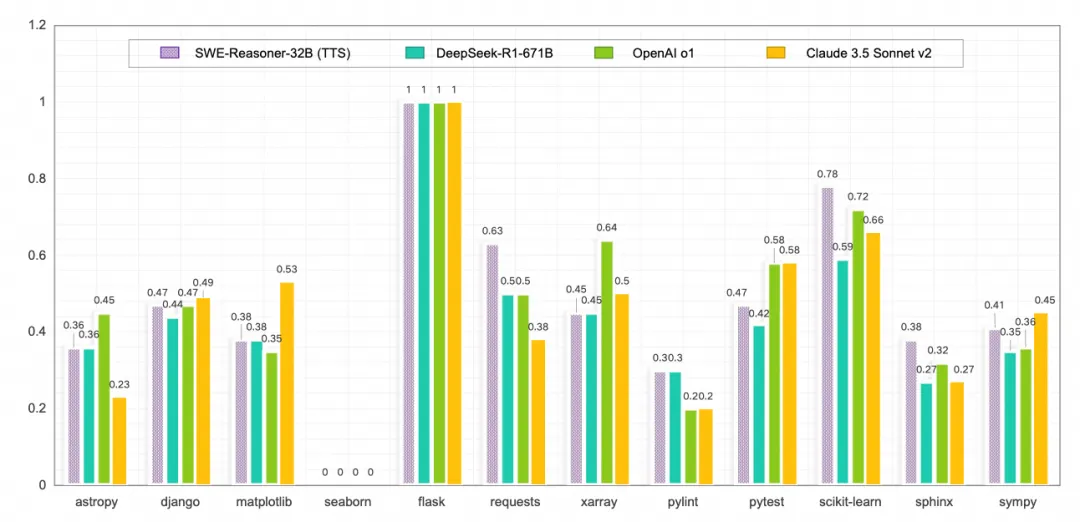
圖 2: 針對(duì)不同倉(cāng)庫(kù)的 issue 解決率比較
- 內(nèi)部 TTS 研究分析:
- 不同難度性能優(yōu)勢(shì):Long CoT 訓(xùn)練相比 Short CoT 訓(xùn)練在解決更難 issue 上提升明顯(基于社區(qū)解決頻率劃分的 Level 5,效果提升約 6 倍,詳見(jiàn)圖 3)。
- Test-Time Scaling 現(xiàn)象:Reasoning 模型在解決更難的問(wèn)題上會(huì)嘗試輸出更多 token,有明顯的 test-time scaling 現(xiàn)象(SWE-Reasoner 和 OpenAI o1),Claude 3.5 Sonnet 也有這個(gè) TTS 現(xiàn)象,但是整體輸出 token 較少。而 Short CoT 模型則沒(méi)有這種明顯的自適應(yīng)計(jì)算行為(詳見(jiàn)圖 4)。

圖 3: 在不同難度的 SWE-bench Verified 上的不同模型的解決率
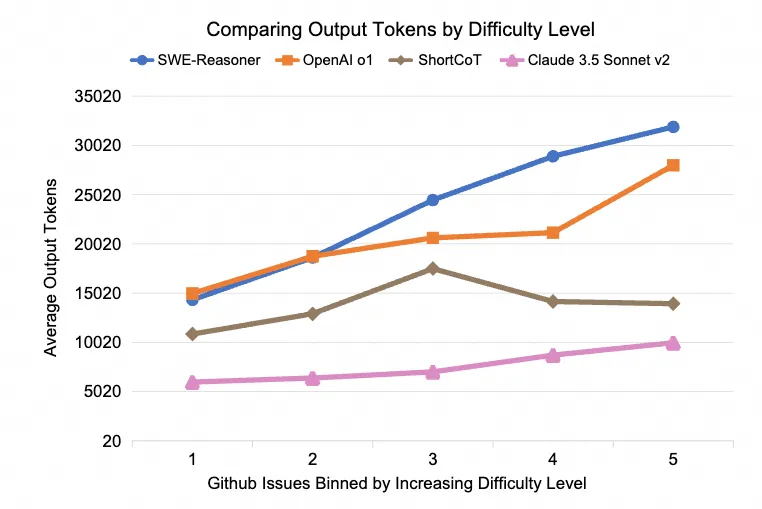
圖 4: 在不同難度的 SWE-bench Verified 上的不同模型的平均輸出 tokens 比較
- 外部 TTS 研究分析:
- Dev-Search 策略優(yōu)勢(shì),在控制相同推理預(yù)算(Rollout 次數(shù) 1, 2, 4, 8)的條件下,我們提出的 Dev-Search 策略始終優(yōu)于僅依賴執(zhí)行驗(yàn)證 (Exec)、執(zhí)行驗(yàn)證+ORM (ORM_Exec) 或投票 (Voting) 的基線方法。這證明了在關(guān)鍵開(kāi)發(fā)流程中進(jìn)行干預(yù)和指導(dǎo)能帶來(lái)更優(yōu)的搜索效率。(詳見(jiàn)圖 5)
- 預(yù)算與性能關(guān)系 (TTS): 增加推理預(yù)算(Generation Budget)通常能帶來(lái)性能的提升,再次驗(yàn)證了外部 TTS 的有效性。預(yù)算的增加對(duì)于解決簡(jiǎn)單和中等難度(Level 1-4)的問(wèn)題提升尤為明顯。
- 高難度任務(wù)瓶頸: 對(duì)于最高難度(Level 5)的問(wèn)題,過(guò)高的推理預(yù)算反而可能導(dǎo)致性能輕微下降。這暗示對(duì)于極其復(fù)雜的任務(wù),僅靠外部搜索擴(kuò)展可能已觸及模型內(nèi)在推理能力的瓶頸,需要內(nèi)部 TTS(想得更深)的共同作用或更強(qiáng)的基礎(chǔ)模型能力。(詳見(jiàn)圖 6)
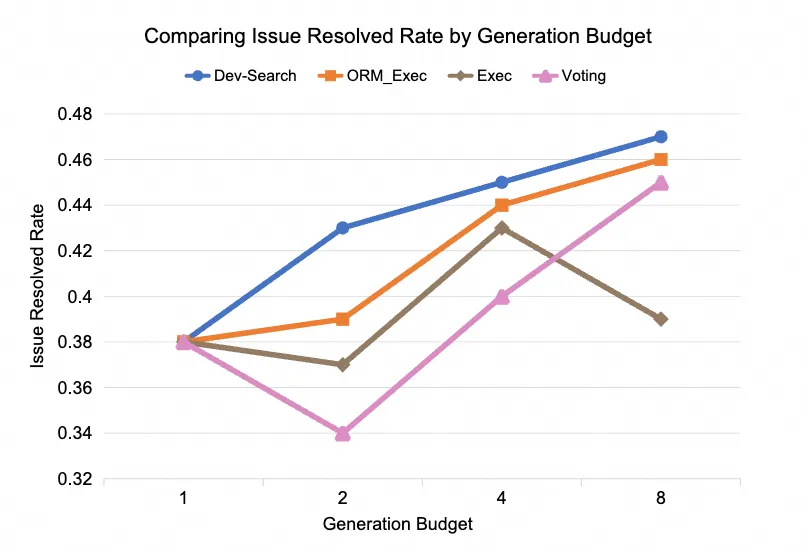
圖 5: 不同搜索方式在相同 budget 下的性能比較

圖 6: 在不同難度的 SWE-bench Verified 上使用不同 budget 的能力比較
結(jié)論
本研究成功展示了通過(guò)統(tǒng)一的測(cè)試時(shí)計(jì)算(TTS)擴(kuò)展框架,可以顯著增強(qiáng)個(gè)人可部署的開(kāi)源 SWE Agent 的代碼推理和問(wèn)題解決能力。我們證明了“思考更長(zhǎng)時(shí)間”(增加推理計(jì)算)而非“模型更大”(增加參數(shù))是提升模型在復(fù)雜軟件工程任務(wù)中表現(xiàn)的有效途徑。這項(xiàng)工作為在資源受限環(huán)境下(如私有部署)使用和發(fā)展高性能 SWE Agent 開(kāi)辟了新的可能性。
展望與思考:更智能更自適應(yīng)的 SWE Agent
- 自適應(yīng)計(jì)算: 未來(lái)可以研究如何讓模型根據(jù)任務(wù)難度動(dòng)態(tài)、自適應(yīng)地調(diào)整計(jì)算資源的投入,實(shí)現(xiàn)效率與效果的最佳平衡。
- 環(huán)境與驗(yàn)證: 提升自動(dòng)化測(cè)試環(huán)境構(gòu)建和解決方案驗(yàn)證的魯棒性與規(guī)模,是進(jìn)一步利用強(qiáng)化學(xué)習(xí) (RL) 釋放 SWE Agent 潛力的關(guān)鍵。
- 任務(wù)泛化: 將此 TTS 框架應(yīng)用到更廣泛的軟件工程任務(wù)中,如測(cè)試用例生成和代碼重構(gòu)等。
?? 詳細(xì)方案請(qǐng)參考論文:
arxiv??: https://arxiv.org/abs/2503.23803

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)