
AI Compass前沿速覽:DINOv3-Meta視覺基礎模型、DeepSeek-V3.1、Qwen-Image、Seed-OSS、CombatVLA-3D動作游戲模型、VeOmni訓練框架
AI Compass前沿速覽:DINOv3-Meta視覺基礎模型、DeepSeek-V3.1、Qwen-Image、Seed-OSS、CombatVLA-3D動作游戲模型、VeOmni訓練框架
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
1.每周大新聞
逗逗AI 1.0 –AI游戲伙伴
逗逗AI 1.0 是一款智能AI伙伴,旨在為用戶提供情感價值和實時互動支持。該AI能夠實時理解用戶所處的環境,特別是游戲畫面,并基于此提供個性化的互動和策略建議,同時支持多模態長期記憶功能。
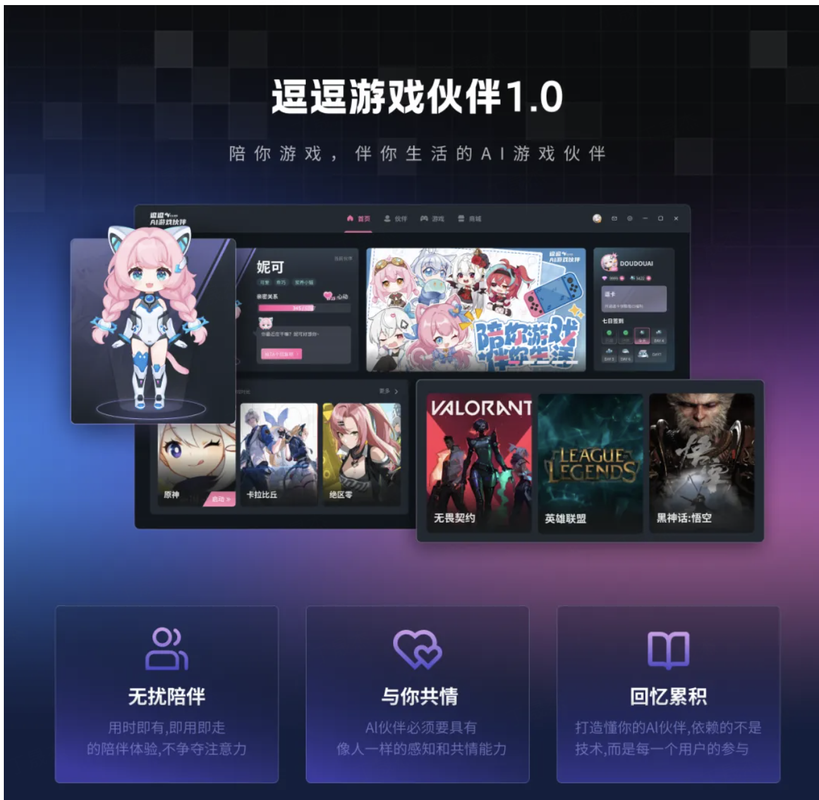
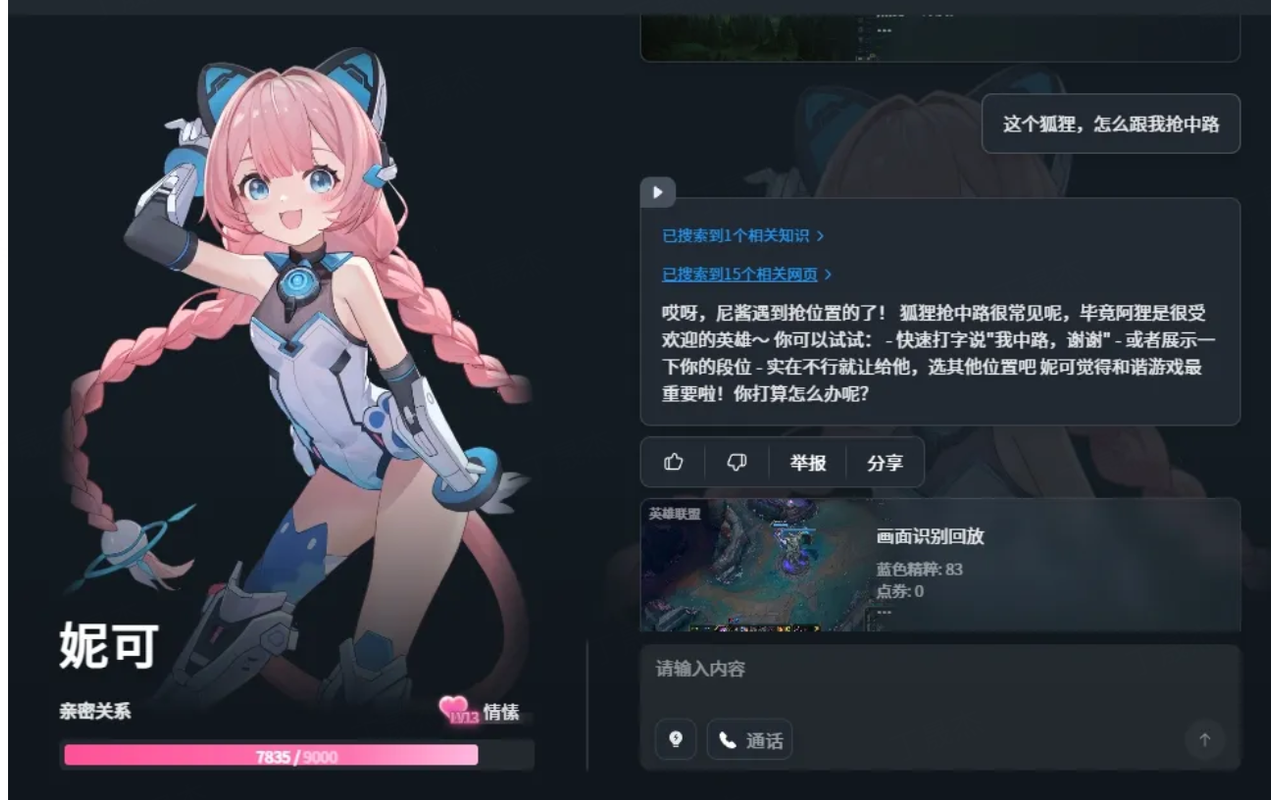
核心功能
- 實時畫面理解: 能夠即時分析并理解用戶屏幕上的內容,如游戲界面。
- 實時互動響應: 基于對畫面的理解和情境分析,與用戶進行即時對話和交流。
- 情緒價值提供: 通過智能互動,為用戶帶來情感上的陪伴與支持。
- 策略建議: 在特定場景(如游戲)中,根據實時情況提供專業的分析和戰術指導。
- 多模態長期記憶: 具備處理和存儲多種類型信息(如視覺、文本)并進行長期記憶的能力,以實現更深度的個性化服務。
技術原理
逗逗AI 1.0 的實現依賴于多項前沿AI技術:
- 計算機視覺 (CV): 用于實時識別、分析和理解游戲或屏幕畫面中的元素、狀態和上下文。
- 自然語言處理 (NLP): 支撐AI與用戶的實時互動,包括理解用戶指令、生成自然流暢的對話回應。
- 情感計算 (Affective Computing): 通過分析用戶行為或對話內容,識別用戶情緒并提供相應的情感反饋或支持。
- 多模態學習 (Multimodal Learning): 整合來自視覺和文本等不同模態的數據進行統一處理和理解。
- 記憶網絡/知識圖譜: 構建和維護長期記憶系統,使AI能夠記住歷史交互、用戶偏好和特定領域知識,從而提供更精準的個性化服務和策略。
- 決策支持系統/強化學習: 特別是在游戲策略建議方面,可能運用這些技術分析當前局勢,預測結果并給出最優決策。
應用場景
-
游戲輔助: 作為玩家的智能游戲伴侶,提供實時的戰術分析、角色推薦和策略建議(如英雄聯盟的BP環節)。
-
個性化互動陪伴: 在日常使用中提供情感支持,進行智能聊天,成為用戶的虛擬伙伴。
-
智能教育/學習輔助: 根據學習內容實時提供解釋、答疑或學習策略指導。
-
智能家居/辦公助手: 通過理解屏幕內容(如文檔、報表),提供實時數據分析或操作建議,提升工作效率。
DeepSeek V3.1
DeepSeek V3.1 是由 DeepSeek 公司推出的最新一代大型人工智能模型,作為 DeepSeek V3 的升級版本。它旨在提供更強大的智能對話和理解能力,通過擴展上下文窗口和優化模型架構,提升了處理長文本和復雜任務的效率和準確性。DeepSeek V3 系列模型是 DeepSeek 在大語言模型領域的最新研究成果,提供了多種規模版本以適應不同應用需求。
核心功能
DeepSeek V3.1 的核心功能主要體現在其強大的文本生成和理解能力。它支持生成高質量、連貫且富有邏輯的文本內容,包括但不限于問答、創作、總結、翻譯等。通過擴展至 128k 的上下文窗口,模型能夠處理更長的輸入,從而更好地理解復雜語境和進行深度推理,提供更精準的響應。此外,它支持多平臺API接入和應用部署,方便開發者集成使用。
技術原理
DeepSeek V3.1 在技術上采用了 Transformer 架構,并在 DeepSeek V3 的基礎上進行了多項優化。其核心技術亮點包括:
- 大上下文窗口: 將上下文窗口從 64k 擴展至 128k,顯著提升了模型處理長文本的能力,減少了信息丟失。
- 模型規模: DeepSeek V3 模型總大小達到 685B,包含 671B 的主模型權重和 14B 的多令牌預測(MTP)模塊權重,表明其龐大的參數量和強大的學習能力。
- 高效推理支持: 支持 BF16 和 FP8 等多種精度推理模式,并獲得 SGLang、vLLM 和 LMDeploy 等高性能推理框架的優化支持,實現了張量并行和流水線并行,確保在大規模部署時的效率。
- 多令牌預測(MTP): 引入 MTP 模塊,可能用于提高生成效率或預測準確性。
花生AI – B站推出AI視頻創作工具
花生AI是B站推出的AI視頻創作工具,幫助用戶快速生成視頻內容。用戶只需提供文案或錄制好的音頻,最快3分鐘即可生成完整視頻。工具提供兩種創作模式:智能匹配素材,根據文案自動匹配畫面素材;模板化制作,可快速生成標準化視頻。生成的視頻內容質量可媲美普通UP主作品,適用于歷史、娛樂、商業財經等領域。
- 極速生成視頻:用戶輸入文案或音頻后,最快3分鐘即可生成完整視頻,大大縮短創作時間。
- 智能匹配素材:AI能根據文案內容自動匹配合適的畫面素材,幫助創作者快速完成視頻制作。
- 模板化制作:提供多種預設模板,用戶可直接套用,適合快速生成標準化視頻,提升創作效率。
- 支持多種語言:基于B站自研的大語言模型Index,支持近10種語言的實時翻譯,準確率高達90%。
- 一鍵發布:生成的視頻可以直接上傳至B站,方便創作者快速分享作品,提升內容傳播效率。
BISHENG靈思 – 畢昇推出的開源通用AI Agent
BISHENG靈思是畢昇推出的一款開源通用AI Agent,旨在通過結合業務專家的知識與經驗,幫助用戶高效完成復雜任務。它同時也是一個開源的LLM應用開發平臺,專注于辦公場景,已被眾多行業頭部組織及世界500強企業廣泛使用。
核心功能
- 通用AI Agent能力: 作為通用型AI Agent,能夠輔助用戶處理各類復雜任務。
- 業務知識整合與應用: 結合領域專家的知識和經驗,提供專業化的任務處理能力。
- 高效任務自動化: 提升任務執行速度和效率,實現自動化流程。
- LLM應用開發支持: 提供平臺支持,便于開發和部署基于大型語言模型(LLM)的辦公應用。
技術原理
BISHENG靈思的核心技術創新在于提出了AGL(Agent指導語言)框架。該框架可能通過標準化指令集和協議,指導AI Agent理解和執行復雜的業務邏輯與任務流程。作為LLM應用開發平臺,其技術原理涉及大型語言模型的集成與微調、自然語言處理(NLP)技術、知識圖譜構建、以及通過API接口與各類企業系統進行數據交互和功能調用的能力,從而實現智能化決策與自動化操作。
應用場景
- 企業辦公自動化: 廣泛應用于各類辦公場景,如智能文檔處理、數據分析報告生成、會議紀要整理、郵件自動回復與分類等。
- 業務流程優化: 協助企業梳理、優化并自動化復雜的業務流程,提升運營效率和響應速度。
- 智能知識管理: 構建企業內部知識庫,提供智能問答、知識檢索和學習支持,加速信息流轉。
- 垂直行業解決方案: 可作為基礎平臺,針對金融、法律、人力資源等特定垂直行業開發定制化的AI Agent解決方案。
MuleRun – 全球首個AI Agent市場
MuleRun 是全球首個AI Agent市場,其模式類似于eBay,旨在提供一個平臺,集合并分發各種即插即用的AI工具,即Mule Agents。
核心功能
MuleRun 的核心功能是提供多樣化的AI Agent,這些Agent能夠執行多領域任務,包括但不限于游戲輔助、內容創作以及自動化任務處理等。用戶可以方便地選擇并使用這些預封裝的AI工具。
技術原理
MuleRun 的運作基于AI Agent技術和大模型技術,通過模塊化和標準化的方式集成各類AI能力,實現AI工具的“即插即用”。這通常涉及API接口、自動化工作流編排以及可能的多模態AI模型支持,以實現Agent的自主決策和任務執行。
應用場景
MuleRun 的AI Agent可廣泛應用于多個場景,包括:
- 游戲輔助: 提供游戲內的智能協助或自動化功能。
- 內容創作: 輔助文本、圖像、視頻等各種形式的內容生成與編輯。
- 自動化任務: 實現日常辦公、數據處理、流程管理等領域的自動化操作。
2.每周項目推薦
Qwen-Image-Edit
Qwen-Image-Edit 是由阿里通義(Qwen)團隊推出的全能圖像編輯模型,其核心構建于200億參數的Qwen-Image架構之上。該模型融合了語義與外觀層面的雙重編輯能力,旨在提供精確、高效的圖像內容修改。


核心功能
- 語義級圖像編輯: 能夠理解并修改圖像中的概念、對象或場景,實現高層次的內容調整。
- 外觀級圖像編輯: 支持對圖像的低層次視覺細節進行編輯,如添加、刪除元素或調整視覺風格。
- 雙語文本精準編輯: 具備對圖片內中英文文本進行精確修改的能力,同時保持原圖風格一致性。
技術原理
Qwen-Image-Edit 基于大型預訓練的視覺-語言模型(VLMs)——Qwen-Image,該模型擁有200億參數,使其具備強大的圖像理解與生成能力。其實現雙重編輯能力可能采用了多模態融合技術,結合擴散模型(Diffusion Models)進行高質量圖像生成與編輯,并通過條件控制機制(如文本提示、掩碼)來引導編輯過程。針對文本編輯,模型可能利用了其多語言理解能力,結合圖像內容上下文進行文本嵌入、渲染及融合,以確保編輯的自然性和風格保持。
應用場景
-
專業內容創作: 輔助設計師、營銷人員快速修改圖像素材,滿足廣告、社交媒體等需求。
-
個性化圖像處理: 用戶可以利用其進行高級的個人照片編輯,實現定制化效果。
-
電子商務與產品展示: 快速調整商品圖片,如修改產品標簽、文字說明或細節展示。
-
智能圖像輔助: 在辦公、教育等場景中,實現對圖片信息的快速修改與更新。
-
學術研究與開發: 作為圖像編輯領域的基礎模型,可用于進一步的算法研究與應用探索。
-
GitHub倉庫:https://github.com/QwenLM/Qwen-Image
-
HuggingFace模型庫:https://huggingface.co/Qwen/Qwen-Image-Edit
Seed-OSS – 字節開源大模型
Seed-OSS 是由字節跳動 Seed 團隊開發的一系列開源大型語言模型。該模型系列旨在提供強大的長上下文處理、推理、智能體和通用能力,并具備友好的開發者特性。盡管僅使用 12T tokens 進行訓練,Seed-OSS 在多項流行公開基準測試中展現出卓越性能,并以 Apache-2.0 許可證向開源社區發布,主要針對國際化(i18n)用例進行了優化。
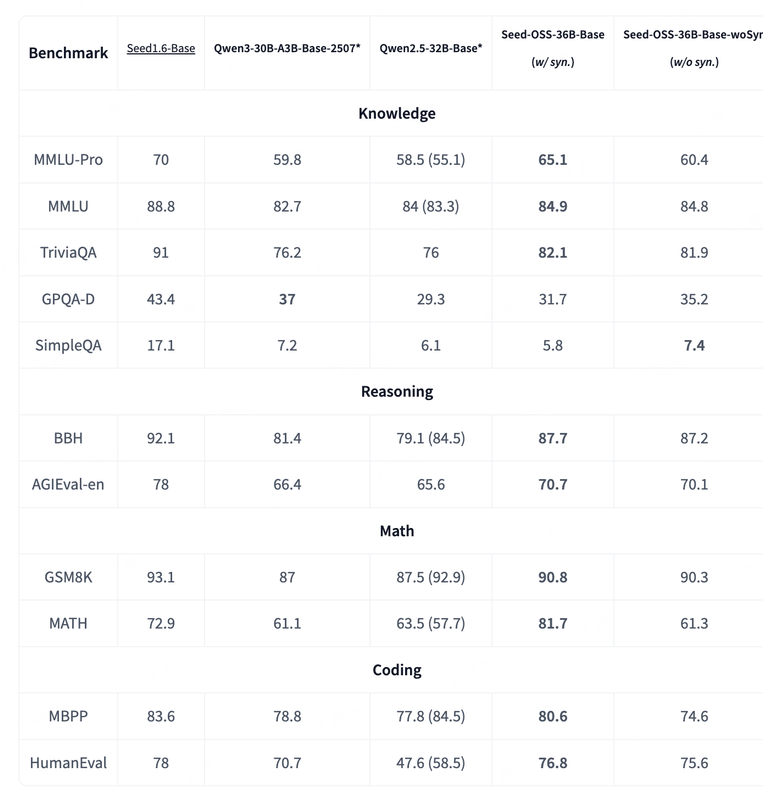
核心功能
- 原生長上下文支持: 模型能夠處理高達 512K 的長上下文輸入,顯著提升對長文本的理解和生成能力。
- 增強推理能力: 經過專門優化,在推理任務中表現出色,同時保持了均衡且卓越的通用能力。
- 智能體能力: 在工具使用和問題解決等智能體任務中表現非凡。
- 靈活的思維預算控制: 允許用戶根據需求動態調整推理長度,從而提高實際應用場景中的推理效率。
- 研究友好性: 發布了包含和不包含指令數據的預訓練模型,為研究社區提供更多樣化的選擇。
技術原理
Seed-OSS 采用流行的因果語言模型架構,并集成了多項先進技術以優化性能和效率:
- RoPE (Rotary Position Embeddings): 用于處理序列中的位置信息,增強模型對長距離依賴的理解。
- GQA (Grouped-Query Attention): 一種注意力機制優化,旨在減少內存占用和提高推理速度。
- RMSNorm (Root Mean Square Normalization): 一種歸一化技術,有助于穩定訓練過程。
- SwiGLU 激活函數: 提供更好的非線性轉換能力,提升模型表達力。
應用場景
-
長文本內容處理: 適用于需要理解和生成超長文本的應用,例如文檔摘要、長篇寫作輔助等。
-
復雜問題推理: 可應用于需要多步邏輯推理的場景,如智能問答、知識圖譜構建與查詢等。
-
智能體開發: 作為底層模型,支持開發具備工具調用、自主規劃和問題解決能力的AI智能體。
-
國際化多語言應用: 針對國際用例進行優化,可服務于跨語言交流、多語言內容創作等全球化場景。
-
前沿AI研究: 為學術界和研究機構提供高質量的開源模型,促進在長上下文、推理和Agent領域的研究與探索。
-
HuggingFace模型庫:https://huggingface.co/collections/ByteDance-Seed/seed-oss-68a609f4201e788db05b5dcd
ToonComposer – 騰訊聯合港中文、北大推出的AI動畫制作工具
ToonComposer是由騰訊ARC實驗室開發的一款生成式AI工具,旨在徹底改變和簡化傳統的卡通及動漫制作流程。它主要通過自動化關鍵幀之間的中間幀生成(inbetweening)工作,極大地提高了動畫制作效率,減少了人工工作量。
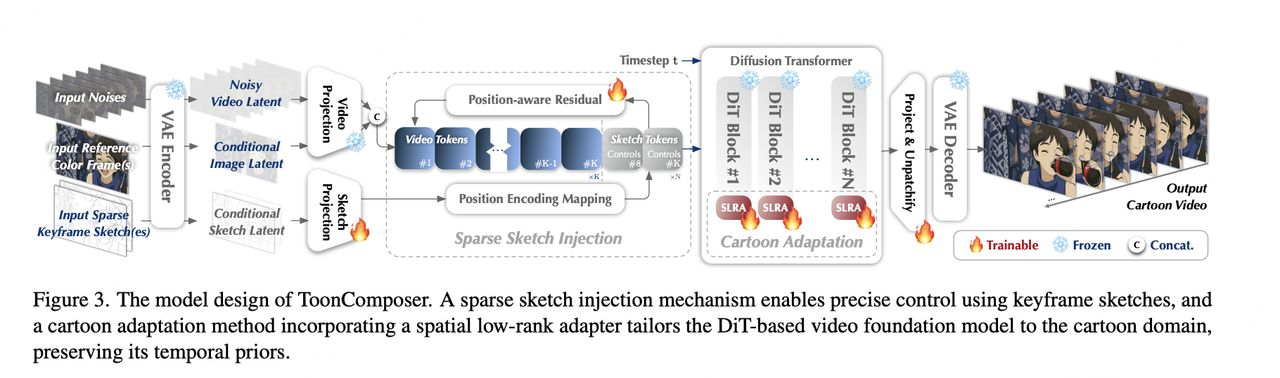

核心功能
- 自動化中間幀生成: 能夠根據用戶輸入的草圖關鍵幀,智能地生成完整的動畫幀序列,填補關鍵幀之間的空隙。
- 高效率與成本節約: 顯著節省約70%的人工工作量,加速動畫制作周期。
- 精確控制: 提供對草圖關鍵幀的精確控制能力,允許用戶精細調整動畫效果。
- 智能填充與區域控制: 支持智能圖像填充和特定區域的精細化控制,確保生成內容的質量和一致性。
技術原理
ToonComposer采用先進的生成式人工智能(Generative AI)技術,特別是通過“生成式關鍵幀后處理”(Generative Post-Keyframing)方法來驅動動畫幀的生成。其核心在于利用深度學習模型理解關鍵幀間的運動和形態變化,并自主合成中間幀,從而實現動畫的平滑過渡。這一技術統一了傳統的動畫插幀過程,擺脫了對每一幀手動繪制的依賴。
應用場景
- 卡通動畫制作: 廣泛應用于卡通片、動漫劇集的制作,特別是在需要大量中間幀的場景。
- 電影與游戲動畫: 可用于影視特效和游戲動畫的預制作或輔助制作,提高生產效率。
- 個人創作者與小型工作室: 賦能獨立動畫師和小型團隊,降低動畫制作的技術門檻和成本。
- 教育與研究: 作為AI在內容創作領域應用的案例,可用于相關領域的教學和研究。
ToonComposer的項目地址
- 項目官網:https://lg-li.github.io/project/tooncomposer/
- GitHub倉庫:https://github.com/TencentARC/ToonComposer
- HuggingFace模型庫:https://huggingface.co/TencentARC/ToonComposer
- arXiv技術論文:https://arxiv.org/pdf/2508.10881
- 在線體驗Demo:https://huggingface.co/spaces/TencentARC/ToonComposer
混元3D世界模型1.0推出Lite版本
騰訊混元世界模型1.0(Hunyuan World Model 1.0)是騰訊發布的一款基于AI的開源3D場景生成模型。它能夠將文本描述或單張圖片快速轉化為高質量、可探索、360度的沉浸式3D虛擬世界,極大地簡化了傳統3D內容創作的復雜流程,實現分鐘級生成。

核心功能
- 文本/圖像到3D場景生成: 能夠根據文字指令或圖片輸入,自動生成完整的3D場景。
- 360度可探索環境: 生成的場景支持360度全景視圖,并具有可探索性。
- 標準格式輸出: 生成的3D內容可導出為標準網格文件(如Mesh),兼容主流游戲引擎和CG軟件。
- 高生成質量: 在紋理細節、真實感、美學質量和指令遵循方面表現出色。
- 內容編輯能力: 支持對前景物體進行調整以及替換天空背景,滿足個性化創作需求。
技術原理
騰訊混元世界模型1.0的生成架構核心在于結合了多項先進技術:
- 全景代理生成: 實現全景圖像的合成。
- 語義分層: 對場景中的元素進行語義理解和分層處理。
- 分層3D重建: 通過分層結構對場景進行高精度3D重建,確保場景的深度和結構準確性。
- AIGC技術: 綜合運用人工智能生成內容技術,自動化復雜的3D建模過程。
應用場景
-
游戲開發: 快速生成游戲原型、關卡設計所需的3D場景、建筑、地形和植被等元素。
-
虛擬現實(VR)/元宇宙內容創作: 為VR體驗和虛擬世界構建提供沉浸式3D環境。
-
影視動畫制作: 作為輔助工具,加速場景的搭建和概念驗證。
-
數字藝術與設計: 幫助設計師和藝術家快速實現創意,無需專業的3D建模技能。
-
教育與模擬: 創建逼真的3D環境用于教學、訓練和模擬。
-
傳統CG工作流集成: 支持與現有計算機圖形工作流的無縫銜接,進行編輯和物理仿真。
-
Github 項目地址:https://github.com/Tencent-Hunyuan/HunyuanWorld-1.0
-
Hugging Face模型地址:https://huggingface.co/tencent/HunyuanWorld-1
MemU – 面向AI情感陪伴的開源AI記憶框架
MemU是一個開源的AI記憶框架,專為AI情感陪伴設計。它作為大型語言模型(LLM)應用的記憶層,旨在幫助AI真正理解用戶,并構建具有更高準確性、更快檢索速度和更低成本的AI記憶能力。
核心功能
- 對話記憶與關鍵信息提取: 能夠記住用戶與AI的每一次對話,并從中提取核心要點。
- 知識圖譜構建: 基于對話內容建立知識圖譜,實現AI對用戶的深度理解。
- 增強記憶性能: 提供高準確性、快速檢索和低成本的AI記憶解決方案。
- 持久化記憶能力: 使AI伙伴具備持續的、長期記憶的能力。
技術原理
MemU的核心是一個代理記憶層(agentic memory layer),它通過結構化地存儲和管理對話數據,將非結構化的對話內容轉化為可供AI理解和檢索的知識。其技術原理涉及:
- 自然語言處理 (NLP): 用于解析和理解用戶與AI的對話內容。
- 信息提取 (Information Extraction): 從對話中識別并提取關鍵信息和實體。
- 知識圖譜技術 (Knowledge Graph Technology): 將提取的信息組織成結構化的知識網絡,形成AI的長期記憶。
- 檢索增強生成 (Retrieval-Augmented Generation, RAG) 機制: 通過從記憶層中快速檢索相關信息來增強LLM的生成能力,提高回復的準確性和相關性。
- 數據存儲與管理: 托管模型、API和云存儲,確保記憶數據的有效存儲、管理和高效訪問。
應用場景
-
AI情感陪伴: 使得AI伴侶能夠記住用戶的偏好、歷史對話和個人信息,提供更加個性化和富有情感的互動。
-
個性化AI助手: 應用于各類AI助手,使其能夠根據用戶的長期互動歷史提供更精準的服務。
-
智能客服: 幫助客服AI記住客戶的服務歷史和問題細節,提升解決問題的效率和用戶滿意度。
-
教育輔導AI: 使教育AI能夠跟蹤學生的學習進度和知識掌握情況,提供定制化的學習體驗。
-
項目官網:https://memu.pro/
-
GitHub倉庫:https://github.com/NevaMind-AI/memU
VeOmni – 字節跳動開源的全模態PyTorch原生訓練框架
VeOmni 是字節跳動Seed團隊開源的一款全模態分布式訓練框架,基于PyTorch設計。它旨在以模型為中心,加速多模態大型語言模型(LLMs)的開發與訓練,并支持任意模態模型的無縫擴展,提供模塊化和高效的訓練能力。
核心功能
- 全模態訓練支持: 能夠高效地進行單模態和多模態模型的預訓練與后訓練。
- 分布式并行訓練: 靈活支持多種分布式并行策略的組合,優化大規模模型訓練效率。
- 模型計算與并行解耦: 將分布式并行邏輯與模型計算過程解耦,增強了框架的靈活性和可配置性。
- 高吞吐性能: 能夠以高吞吐量進行大規模模型訓練,例如可實現每GPU每秒2800+ tokens的MoE模型訓練。
- “積木式”配置: 提供直觀且易于配置的“積木式”訓練方案,簡化復雜分布式策略的部署。
技術原理
VeOmni 的核心技術原理是其模型中心化(Model-Centric)的設計理念和引入的分布式配方庫(Distributed Recipe Zoo)。該框架將底層分布式并行策略(如數據并行、模型并行、流水線并行、專家并行等)從上層模型計算邏輯中抽象并解耦。這種架構允許用戶像組裝積木一樣,靈活配置和組合不同的并行方案,以適應不同規模和模態(如文本、圖像、音頻等)的模型訓練需求。基于PyTorch生態,VeOmni能夠高效利用GPU資源,并通過優化并行策略,顯著提升大規模模型,尤其是全模態MoE模型的訓練吞吐量和擴展性。
應用場景
-
大規模多模態LLM訓練: 用于加速和擴展全模態大型語言模型(LLMs)的預訓練和微調。
-
多模態融合模型開發: 為研究人員和開發者提供高效平臺,探索和構建涉及圖像、文本、語音等多種模態融合的模型。
-
高性能計算集群應用: 適用于需要在大規模計算集群上進行高效分布式訓練的企業和研究機構。
-
前沿AI模型研究: 便于AI研究人員實驗和驗證復雜的分布式訓練策略對新型模型架構的性能影響。
-
arXiv技術論文:https://arxiv.org/pdf/2508.02317
Genie Envisioner – 智元機器人平臺
Genie Envisioner(GE)是智元(Zhiyuan Robotics / AgiBotTech)推出的首個面向真實世界機器人操控的統一世界模型開源平臺。它旨在通過一個統一的視頻生成框架,集成策略學習、評估和仿真功能,打破傳統機器人學習系統分階段開發的模式,從而實現更高效、更智能的機器人操作。
核心功能
- 統一世界模型構建: 通過視頻生成技術構建統一的機器人世界模型。
- 策略學習與生成: 支持機器人行為策略的自動化學習與生成。
- 評估與仿真: 提供功能強大的評估工具和仿真環境,用于測試和驗證機器人策略。
- 指令驅動操作: 實現可伸縮的、指令驅動的機器人操作。
- 開放平臺: 提供開源代碼庫和相關數據集,促進社區協作和研究。
技術原理
Genie Envisioner 的核心技術原理是構建一個統一的視頻生成世界模型(Unified Video-Generative World Model)。該平臺整合了策略學習(Policy Learning)、評估(Evaluation)和仿真(Simulation)機制,形成一個閉環系統(Closed-loop System)。它利用大規模數據集(如約3000小時的機器人操作數據)進行訓練,以學習和預測機器人與環境的交互。通過生成未來的視頻幀,該模型能夠模擬不同操作指令下的機器人行為和環境變化,從而支持強化學習(Reinforcement Learning)和模型預測控制(Model Predictive Control)等高級控制策略,最終實現指令到動作的精確轉化,并克服傳統感知-規劃-執行(Perception-Planning-Execution)范式的局限性。
應用場景
-
通用機器人操作: 適用于各種通用型機器人的精細操作和任務執行。
-
工業自動化: 在工廠、倉庫等場景中,提高機器人抓取、組裝、分揀等任務的效率和魯棒性。
-
家庭服務機器人: 為家庭服務機器人提供更強的環境感知和任務執行能力。
-
具身智能研究: 作為具身智能領域的研究平臺,推動機器人感知、決策和行動一體化的發展。
-
教育與科研: 為研究人員和學生提供一個開放、統一的實驗平臺,加速機器人技術創新。
-
arXiv技術論文:https://arxiv.org/pdf/2508.05635
DINOv3 – Meta開源的通用視覺基礎模型
DINOv3是Meta AI推出的一款通用、SOTA(State-of-the-Art)級視覺基礎模型,通過大規模自監督學習(SSL)進行訓練。它能夠從無標注數據中學習并生成高質量的高分辨率視覺特征,旨在提供強大的通用視覺骨干網絡,并在各種視覺任務和領域中實現突破性性能。DINOv3在DINOv2的基礎上進一步擴展了模型規模和訓練數據量,并支持商業許可。
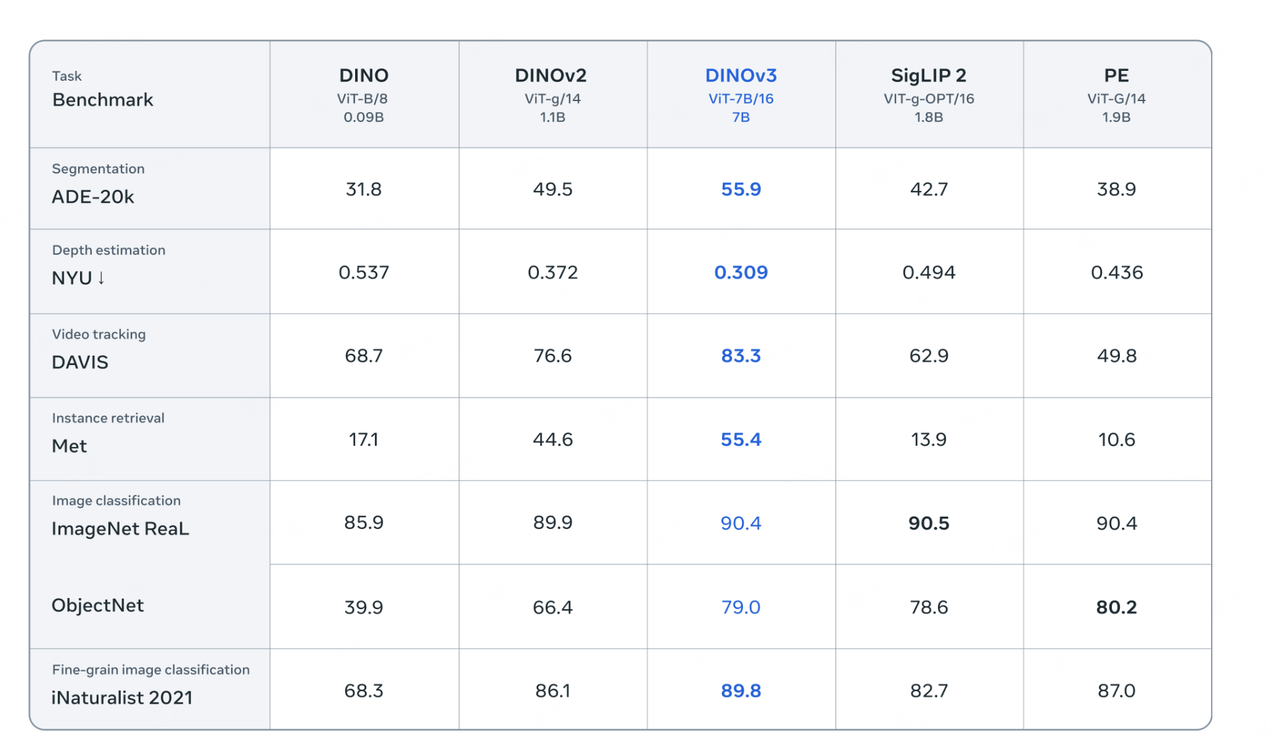
核心功能
- 高分辨率特征生成: 能夠產生高質量且分辨率高的圖像特征,適用于需要精細視覺信息的任務。
- 通用視覺骨干網絡: 提供一個強大的、適用于多種視覺任務的通用視覺骨干模型。
- 自監督學習能力: 利用海量無標注數據進行訓練,無需人工標注即可學習強大的視覺表征。
- 跨領域性能優越: 在圖像分類、語義分割、目標檢測、視頻目標跟蹤等多種探測任務上超越傳統弱監督模型。
- 適應性強: 預訓練的DINOv3模型可以通過輕量級適配器在少量標注數據上進行定制,實現更廣泛的應用。
- 部署靈活性: 包含蒸餾后的較小模型(如ViT-B、ViT-L)和ConvNeXt變體,便于在不同場景下部署。
技術原理
DINOv3的核心技術原理在于大規模自監督學習(SSL)。它在DINOv2的基礎上進行了顯著的擴展,模型參數量達到7B,訓練數據集規模達到1.7B圖像,但相比弱監督方法,所需的計算資源更少。
- 自監督訓練: 通過構建無需人工標注的任務來學習圖像的內在結構和特征,例如預測圖像不同視圖之間的關系。
- 視覺Transformer (ViT) 架構: 采用ViT作為其特征提取器,能夠有效處理高分辨率圖像并捕捉全局依賴關系。
- 模型與數據規模化: 通過將模型尺寸擴大6倍、訓練數據量擴大12倍,顯著提升了模型性能和泛化能力。
- 凍結骨干網絡: 在許多應用中,DINOv3的骨干網絡可以保持凍結狀態,無需額外微調即可應用于新任務,這得益于其強大的通用特征提取能力。
- 輕量級適配器: 對于特定任務,可以通過訓練一個輕量級適配器來微調模型,而非對整個大型模型進行重新訓練,從而提高效率。
應用場景
-
圖像分類: 對各種圖像進行準確的類別識別。
-
語義分割: 精確識別圖像中每個像素所屬的對象類別。
-
目標檢測: 在圖像中定位并識別出特定對象。
-
視頻目標跟蹤: 在視頻序列中持續追蹤特定目標。
-
醫學影像分析: 處理和理解醫學圖像,輔助診斷。
-
衛星圖像分析: 支持對衛星影像進行解析,例如冠層高度估計等。
-
遙感圖像處理: 應用于土地利用、環境監測等領域的遙感數據分析。
-
安防監控: 進行智能視頻監控中的行為識別與異常檢測。
-
自動駕駛: 用于環境感知和目標識別。
-
任何標注數據稀缺的視覺任務: 由于其強大的自監督學習能力,特別適用于缺乏大量標注數據的領域。
-
項目官網:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
-
HuggingFace模型庫:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
Shadow – 開源的AI編程Agent
Shadow 是一個開源的AI編程Agent,旨在幫助開發者理解、推理并貢獻現有代碼庫。它提供了一套全面的工具集,能夠集成GitHub倉庫,自動化生成拉取請求,管理代碼分支,并提供實時的任務狀態更新。該項目通過提供高級的代碼操作和搜索能力,提升開發效率和協作體驗。

核心功能
- 文件操作與管理: 支持文件的讀取、編輯、替換、刪除和目錄探索,能夠對代碼文件進行細粒度的控制和修改。
- 代碼智能搜索: 提供基于正則表達式的模式匹配(grep_search)、模糊文件名搜索(file_search)以及AI驅動的語義代碼搜索(semantic_search)。
- GitHub集成與自動化: 能夠與GitHub倉庫無縫集成,自動生成Pull Request并管理分支,簡化開發工作流。
- 實時任務狀態更新: 提供任務的實時狀態反饋,幫助開發者隨時掌握項目進展。
- 代理工具: 為AI Agent提供一套全面的工具,使其能夠執行復雜的編程任務。
技術原理
Shadow 的核心技術原理是利用人工智能代理(AI Agent)能力來理解和操作代碼庫。它結合了:
-
自然語言處理(NLP): 理解開發者意圖和代碼語義,進行智能化的代碼分析和搜索。
-
代碼分析與操作引擎: 通過
read_file、edit_file、search_replace等工具實現對代碼文件的精確讀寫和修改。 -
語義搜索技術: 運用先進的AI模型進行代碼的語義理解,實現比傳統關鍵詞搜索更深層次的代碼查找。
-
版本控制系統(VCS)集成: 利用GitHub API等接口,實現與Git倉庫的交互,包括分支管理、Pull Request的創建與更新。
-
任務狀態管理: 通過后端服務和前端界面,實現任務執行狀態的實時監控和反饋機制。
-
GitHub倉庫:https://github.com/ishaan1013/shadow
Klear-Reasoner – 快手開源的推理模型
Klear-Reasoner 是一個擁有80億參數的推理模型,旨在通過結合長鏈式思維監督微調和梯度保留裁剪策略優化(GPPO)來顯著提升模型的推理能力。它在數學和編程等復雜基準測試中展現出卓越的性能,能夠進行長距離、多步驟的深思熟慮式推理。
核心功能
- 高級推理: 在數學和編程領域執行復雜的長距離推理任務。
- 性能優化: 在AIME和LiveCodeBench等挑戰性基準測試中達到行業領先水平 (SOTA)。
- 問題解決: 能夠處理需要多步驟邏輯和深層思考的問題。
- 模型訓練優化: 引入GPPO機制,解決傳統強化學習裁剪機制的局限性,提升訓練效率和模型探索能力。
技術原理
Klear-Reasoner的核心技術在于其創新的訓練范式:
- 模型架構: 一個80億參數的推理模型。
- 梯度保留裁剪策略優化 (GPPO): 針對強化學習中的策略優化,GPPO旨在克服傳統裁剪機制在探索信號抑制和次優軌跡忽略方面的問題。它通過溫和地反向傳播來自裁剪區域的梯度,從而在保持策略更新穩定的同時,有效促進模型探索。
- 長鏈式思維監督微調 (Long Chain-of-Thought Supervised Fine-tuning, SFT): 采用以質量為中心的SFT策略,確保模型能夠一致地學習和復制準確的推理模式。
- 強化學習 (RL): 結合SFT與GPPO,進一步提升模型的推理性能。
- 輔助優化技術: 包括軟獎勵設計(soft reward design)、數據過濾(data filtering)和平衡SFT監督(balanced SFT supervision),共同增強強化學習的效率和推理效果。
應用場景
-
教育科技: 輔助學生解決復雜的數學問題和編程挑戰。
-
軟件開發: 自動生成、調試和優化代碼。
-
科學研究: 在需要復雜邏輯推理的領域(如物理、化學、生物)中進行問題求解和數據分析。
-
人工智能助理: 開發能夠進行多步驟決策和復雜任務規劃的智能助手。
-
HuggingFace模型庫:https://huggingface.co/Suu/Klear-Reasoner-8B
-
arXiv技術論文:https://arxiv.org/pdf/2508.07629
CombatVLA – 淘天3D動作游戲專用VLA模型
CombatVLA 是由淘天集團未來生活實驗室團隊開發的一種高效視覺-語言-動作(VLA)模型,專為3D動作角色扮演游戲(ARPG)中的戰斗任務設計。該模型旨在通過整合視覺感知、語言理解和動作控制,提升AI在復雜游戲環境中的表現。
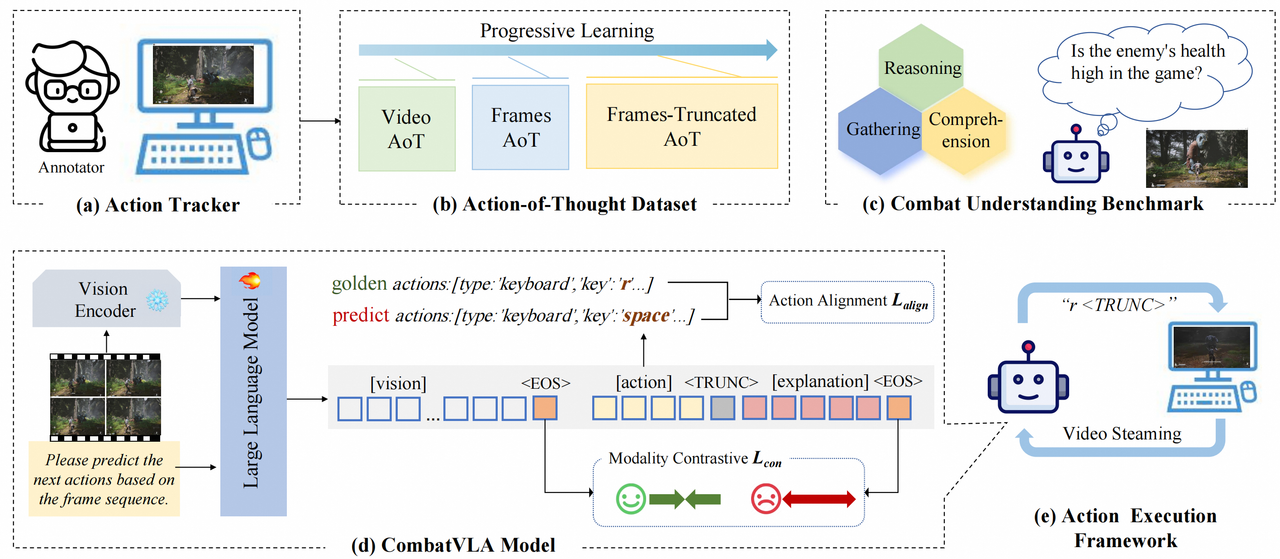
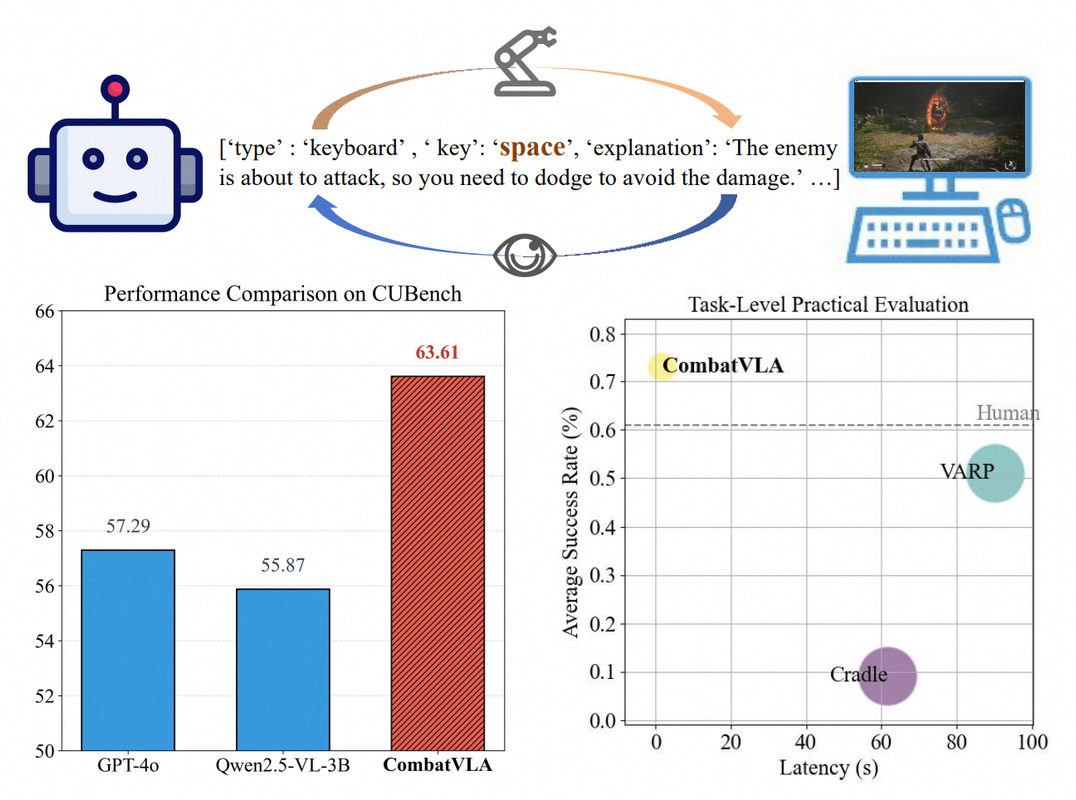
核心功能
CombatVLA 的核心功能在于對3D ARPG中戰斗任務的優化。它能夠:
- 戰斗理解與推理: 識別敵方位置,并進行動作推理。
- 高效執行: 相比現有基于VLM的游戲智能體,顯著提升執行速度。
- 多模態控制: 處理視覺輸入,并生成一系列操作指令(包括鍵盤和鼠標操作)來控制游戲。
- 性能超越: 在戰斗理解方面超越了GPT-4o和Qwen2.5-VL等現有模型,并在CUBench基準測試中取得了高分。
技術原理
CombatVLA 基于一個3B參數規模的VLA模型,其技術原理涉及:
- 視覺-語言-動作(VLA)集成: 模型將視覺信息、自然語言指令和游戲內的動作輸出進行統一學習。
- 高效推理設計: 專門設計以實現高效推理,大幅提升處理速度。
- 基準測試構建: 建立了名為CUBench的戰斗理解基準,通過VQA(視覺問答)格式評估模型在識別敵方位置和動作推理任務中的表現。
- 模型架構: 能夠處理視覺輸入并生成控制游戲動作的序列。
應用場景
CombatVLA 的主要應用場景集中在:
-
3D動作角色扮演游戲(ARPG): 尤其適用于其中復雜的戰斗任務,可以作為游戲AI或游戲測試工具。
-
智能體訓練: 為在復雜動作游戲環境中訓練多模態智能體提供新的見解和方向。
-
游戲開發: 有助于開發更智能、更具響應性的游戲內NPC或AI對手。
-
虛擬環境模擬: 可應用于其他需要視覺感知、語言理解和精準操作的虛擬環境。
-
arXiv技術論文:https://arxiv.org/pdf/2503.09527
NVIDIA Nemotron Nano 2 – 英偉達推出的高效推理模型
NVIDIA Nemotron Nano 2 是英偉達推出的一款高效、參數量為9B的推理模型,旨在提供卓越的性能和成本效益。該模型基于創新的混合Mamba-Transformer架構,并在海量數據上進行了預訓練,支持長上下文,并強調開放性,同時發布了模型和大部分訓練數據集。
核心功能
- 高效推理: 在相似規模下,推理速度比同類模型(如Qwen3-8B)快數倍(最高可達6倍),同時顯著降低推理成本(最高可節省60%)。
- 強大推理能力: 在復雜的推理基準測試中表現出色,通過支持“思考”預算控制,可在生成最終答案前先生成推理過程,有效提升復雜任務的準確性。
- 長上下文支持: 具備128k的上下文長度處理能力,使其能夠處理更長的輸入和輸出序列。
- 模型開放性: 英偉達首次開源了用于創建該模型的大部分高質量預訓練數據集,包括Nemotron-CC-v2、Nemotron-CC-Math-v1、Nemotron-Pretraining-Code-v1和Nemotron-Pretraining-SFT-v1,促進了研究和應用。
- 統一推理與非推理任務: 設計目標是兼顧推理與非推理任務,提供統一的模型解決方案。
技術原理
NVIDIA Nemotron Nano 2 采用了混合Mamba-Transformer架構,結合了Mamba模型的線性擴展能力和Transformer的強大建模優勢。其訓練過程包括:
- 預訓練階段: 模型在20萬億個token上進行預訓練,并使用FP8精度。通過分階段持續預訓練擴展長上下文能力,使其在保持高性能的同時達到128k上下文支持。
- 后訓練階段: 采用多策略結合進行后訓練,包括監督微調(SFT)、組相對策略優化(GRPO)、直接偏好優化(DPO)以及人類反饋強化學習(RLHF),以提升模型在指令遵循和推理控制上的表現。其中約5%的數據包含故意截斷的推理軌跡,以實現細粒度的“思考”預算控制。
- 模型壓縮: 基礎模型和對齊模型經過剪枝(Pruning)和蒸餾(Distillation)等壓縮技術優化,使其能夠在資源受限的設備(如單個NVIDIA A10G GPU)上高效部署和推理。
- 預訓練數據集構成: 預訓練數據集Nemotron-Pre-Training-Dataset-v1包含66萬億個token,涵蓋優質網絡爬取、數學、代碼、SFT和多語言問答數據,通過Lynx + LLM管線等方法精心處理,確保高質量和多樣性。
應用場景
-
邊緣設備AI部署: 憑借其緊湊的參數量和高效的推理性能,非常適合在智能手機、智能手表、IoT設備等算力有限的邊緣設備上部署生成式AI應用。
-
智能助理與Agentic AI: 可作為智能代理(agentic AI)任務的核心,用于實現復雜的邏輯推理、規劃和決策,例如高級問答系統、自動化工作流。
-
內容生成與代碼輔助: 利用其強大的生成和推理能力,可用于高質量文本生成、代碼自動補全、編程輔助、內容創作等。
-
教育與研究: 開放的訓練數據和技術報告使其成為學術研究和教育領域的寶貴資源,促進對高效大模型的理解和開發。
-
低成本推理服務: 對于需要高吞吐量且對成本敏感的企業級AI應用,Nemotron Nano 2 提供了一個經濟高效的解決方案。
-
項目官網:https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2/
-
HuggingFace模型庫:https://huggingface.co/collections/nvidia/nvidia-nemotron-689f6d6e6ead8e77dd641615
-
技術論文:https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-Nano-2-Technical-Report.pdf
-
在線體驗Demo:https://build.nvidia.com/nvidia/nvidia-nemotron-nano-9b-v2
譜樂AI – AI音樂生成
譜樂AI是一款AI驅動的音樂生成平臺,旨在通過人工智能技術革新音樂創作過程。它能夠接收多種形式的輸入,快速生成高質量的匹配音樂作品,為用戶提供便捷、個性化的音樂創作體驗。
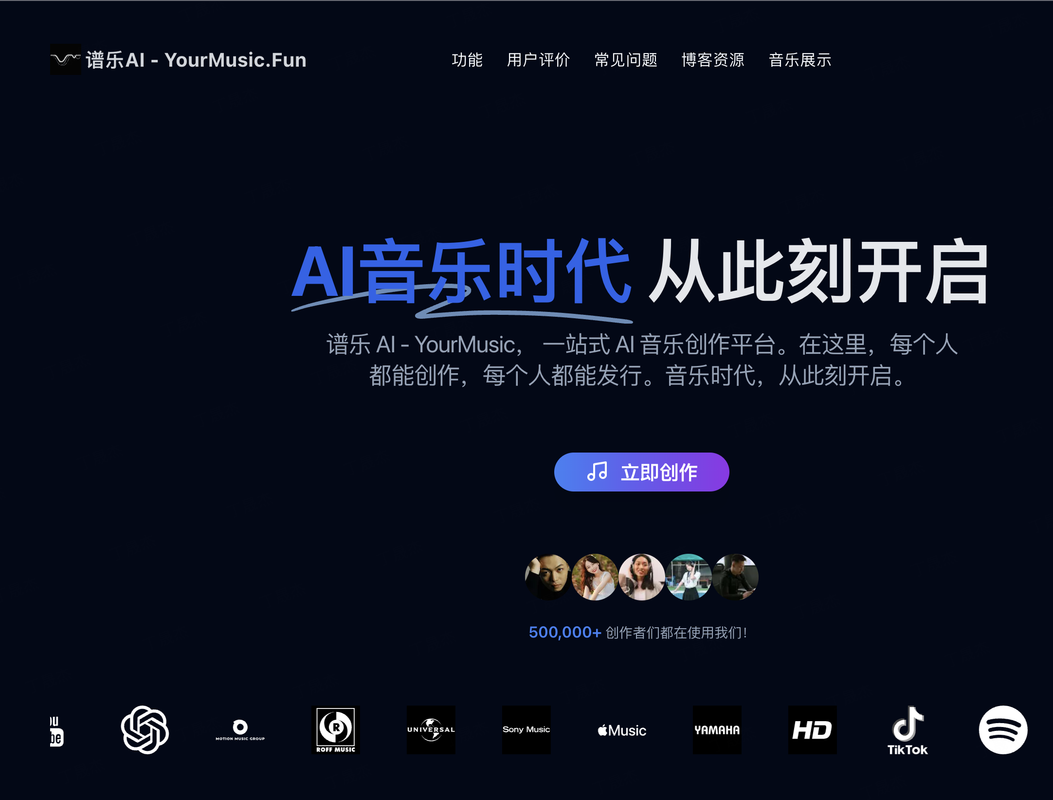
核心功能
- 多模態輸入支持: 支持文本、圖片、視頻等多種輸入方式,根據不同輸入內容智能生成對應的AI音樂。
- 快速音樂生成: 能夠依據用戶描述(如“溫暖的鋼琴曲”)在短時間內生成完整的音樂作品。
- 自定義歌曲創作: 協助用戶創作定制歌曲和歌詞,并生成器樂軌道。
- 創作輔助功能: 提供歌詞創作、流派選擇、節拍與速度建議以及音樂理論指導等輔助功能,幫助用戶進行音樂創作。
- 專屬音色模型訓練: 提供訓練專屬音色模型的能力,實現高度個性化的音樂輸出。
技術原理
譜樂AI的實現基于先進的深度學習和生成對抗網絡(GANs)或變分自編碼器(VAEs)等人工智能模型,可能還結合了Transformer架構處理序列數據(如音樂和歌詞)。其核心技術包括:
- 多模態融合技術: 將文本、圖像、視頻等不同模態的數據轉化為統一的特征表示,作為音樂生成模型的輸入。
- 音樂生成算法: 利用復雜的神經網絡模型學習音樂的結構、和聲、旋律、節奏等規律,并生成全新的、符合輸入描述的音樂序列。
- 音頻合成技術: 將生成的音樂序列轉換為可聽的音頻波形,可能涉及數字信號處理和高質量的音色庫。
- 個性化模型訓練: 通過遷移學習或小樣本學習技術,允許用戶訓練或微調特定音色模型,以適應個性化需求。
應用場景
- 音樂創作與制作: 為專業音樂人、業余愛好者提供創作靈感和快速制作工具,用于歌曲創作、伴奏制作等。
- 內容創作: 為視頻博主、游戲開發者、動畫制作人等提供快速定制背景音樂的解決方案。
- 教育與學習: 作為音樂理論學習的輔助工具,幫助學生理解和實踐音樂概念。
- 個性化娛樂: 滿足普通用戶對定制化音樂的需求,如為特定情緒或場景生成專屬音樂。
- 廣告與營銷: 快速生成符合品牌調性或產品主題的廣告配樂。
AutoCodeBench – 騰訊混元開源測評大模型代碼能力的數據集
AutoCodeBench是由騰訊混元團隊推出的一個大規模代碼生成基準測試集。它旨在全面評估大語言模型(LLMs)的代碼生成能力,包含3920個問題,均勻分布在20種編程語言中。該數據集以其高難度、實用性和多樣性為特點,為LLM在代碼領域的性能評估提供了一個高質量、可驗證的測試平臺。
核心功能
- 代碼能力測評: 提供一套標準化的測試題目,用于精確衡量大語言模型在不同編程語言下的代碼生成和理解能力。
- 多語言支持: 涵蓋20種主流編程語言,確保評估的廣泛性和全面性。
- 高質量數據集: 采用創新的數據合成策略,確保生成的問題具有高難度和實用性,并且可驗證。
- 基準測試: 作為評估不同LLM在代碼生成任務上性能的統一基準,支持對基礎模型和對話模型的測試。
技術原理
AutoCodeBench的核心技術原理在于其LLM-Sandbox交互自動化工作流。該工作流通過以下步驟實現高質量、可驗證的多語言代碼數據集的合成:
- 逆向問題合成: 不同于傳統的數據合成方法,AutoCodeBench基于已有的代碼解決方案和測試函數,逆向提示LLM生成準確的編程問題。
- 多語言沙盒驗證: 構建一個多語言的沙盒環境,LLM在此環境中生成測試輸入,并通過沙盒獲取測試輸出,從而確保生成的數據具有高度的可驗證性。
- 自動化生成與評估: 整個過程實現了自動化,從問題的生成到測試用例的創建,再到模型的評估,大大提高了基準測試的效率和可靠性。
應用場景
-
大語言模型代碼能力評估: 用于研究人員和開發者評估、比較和改進各種大語言模型的代碼生成、代碼補全、錯誤修復等能力。
-
AI編程助手研發: 為開發更智能、更準確的AI編程輔助工具提供測試數據和基準,從而提高開發者的編碼效率。
-
學術研究: 作為代碼生成領域的重要數據集,支持相關算法、模型和理論的深入研究。
-
模型訓練與優化: 通過對模型的測試結果進行分析,指導LLM的進一步訓練和架構優化,以提升其在編程任務上的表現。
-
GitHub倉庫:https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
-
HuggingFace模型庫:https://huggingface.co/datasets/tencent/AutoCodeBenchmark
-
arXiv技術論文:https://arxiv.org/pdf/2508.09101
3. AI-Compass
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
?? 核心模塊架構:
- ?? 基礎知識模塊:涵蓋AI導航工具、Prompt工程、LLM測評、語言模型、多模態模型等核心理論基礎
- ?? 技術框架模塊:包含Embedding模型、訓練框架、推理部署、評估框架、RLHF等技術棧
- ?? 應用實踐模塊:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿應用架構
- ??? 產品與工具模塊:整合AI應用、AI產品、競賽資源等實戰內容
- ?? 企業開源模塊:匯集華為、騰訊、阿里、百度飛槳、Datawhale等企業級開源資源
- ?? 社區與平臺模塊:提供學習平臺、技術文章、社區論壇等生態資源
?? 適用人群:
- AI初學者:提供系統化的學習路徑和基礎知識體系,快速建立AI技術認知框架
- 技術開發者:深度技術資源和工程實踐指南,提升AI項目開發和部署能力
- 產品經理:AI產品設計方法論和市場案例分析,掌握AI產品化策略
- 研究人員:前沿技術趨勢和學術資源,拓展AI應用研究邊界
- 企業團隊:完整的AI技術選型和落地方案,加速企業AI轉型進程
- 求職者:全面的面試準備資源和項目實戰經驗,提升AI領域競爭力

 浙公網安備 33010602011771號
浙公網安備 33010602011771號