
AI Compass前沿速覽:RynnVLA視覺-語言-動作模型、GLM-4.5V 、DreamVVT虛擬換衣、 WeKnora框架、GitMCP、NeuralAgent桌面AI助手
AI Compass前沿速覽:RynnVLA視覺-語言-動作模型、GLM-4.5V 、DreamVVT虛擬換衣、 WeKnora框架、GitMCP、NeuralAgent桌面AI助手
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態(tài),通過六大核心模塊的系統(tǒng)化組織,為不同層次的學習者和開發(fā)者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
1.每周大新聞
SkyReels-A3 – 昆侖萬維推出的數(shù)字人視頻生成模型
昆侖萬維推出數(shù)字人視頻生成模型SkyReels - A3,基于DiT視頻擴散架構,結合多項技術,通過音頻驅動讓照片或視頻人物“激活”。
主要功能
具備照片激活、視頻創(chuàng)作、視頻臺詞修改、動作交互、運鏡控制、長視頻生成等功能。
技術原理
采用DiT架構、3D - VAE編碼、插幀與延展、強化學習優(yōu)化、運鏡控制模塊和多模態(tài)輸入。
應用場景
涵蓋廣告營銷、電商直播、影視娛樂、教育培訓、新聞媒體及個人創(chuàng)作娛樂等領域。
項目信息
已上線SkyReels平臺,項目官網(wǎng)為https://www.skyreels.ai/home
Baichuan-M2 – 百川開源醫(yī)療大模型
百川智能推出開源醫(yī)療增強大模型Baichuan - M2。它在HealthBench評測中登頂,可在RTX 4090單卡部署,成本降低,MTP版本token速度提升,核心性能增強,更貼合真實醫(yī)療場景與中國臨床需求。其技術涉及AI患者模擬器、強化學習等,應用于醫(yī)療診斷輔助、多學科會診等場景。
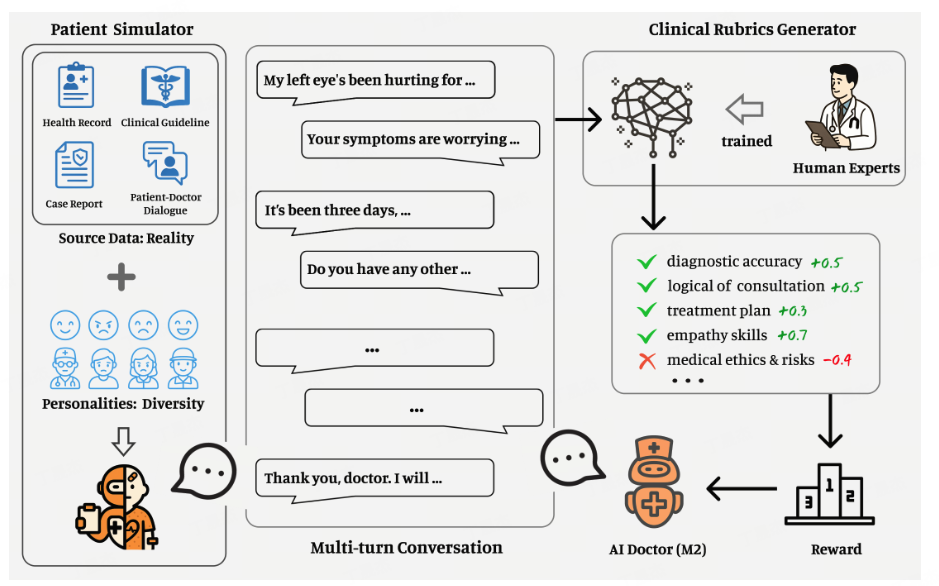
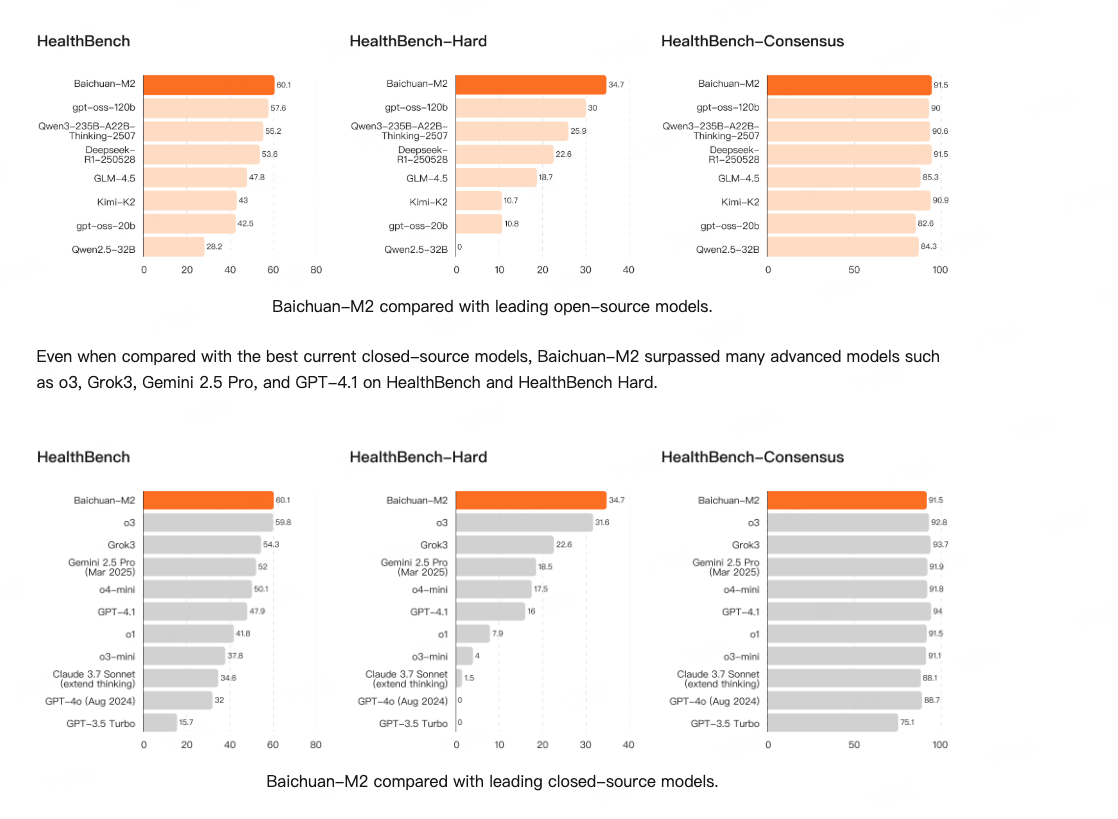
影響意義
在醫(yī)療領域表現(xiàn)卓越,為醫(yī)療診斷和治療提供有力支持,降低硬件成本,適合中國醫(yī)療機構和醫(yī)生使用,還可用于臨床教學、患者教育等多方面。
- HuggingFace模型庫:https://huggingface.co/baichuan-inc/Baichuan-M2-32B
- 技術論文:https://www.baichuan-ai.com/blog/baichuan-M2
Sheet0 – Data Agent,將任意數(shù)據(jù)源轉為結構化數(shù)據(jù)表格
Sheet0是創(chuàng)新的L4級Data Agent產(chǎn)品,可將任意數(shù)據(jù)源轉為結構化數(shù)據(jù)表格。通過自然語言交互,將任意數(shù)據(jù)源(如網(wǎng)頁、文件、API)轉化為結構化的數(shù)據(jù)表格,實現(xiàn)“100% 準確,0 幻覺” 的數(shù)據(jù)交付
主要功能
具備數(shù)據(jù)收集與結構化、自然語言交互、高準確性與可靠性、實時數(shù)據(jù)交付、自動化任務執(zhí)行、動態(tài)優(yōu)化與自我修復等功能。
應用場景
涵蓋營銷與銷售、電商運營、知識工作、市場研究、內(nèi)容創(chuàng)作等領域。
- 官網(wǎng)地址:https://www.sheet0.com/
2.每周項目推薦
Voost – 創(chuàng)新的雙向虛擬試穿和試脫AI模型
Voost 是由 Seungyong Lee 和 Jeong-gi Kwak (來自 NXN Labs) 共同開發(fā)的一個統(tǒng)一且可擴展的擴散變換器 (Diffusion Transformer) 框架。它旨在解決虛擬試穿中服裝與身體對應關系建模的挑戰(zhàn),并首次將虛擬試穿 (Virtual Try-On) 和虛擬脫衣 (Virtual Try-Off) 功能整合到單一模型中,實現(xiàn)了雙向處理,顯著提高了虛擬服裝合成的真實性和泛化能力。
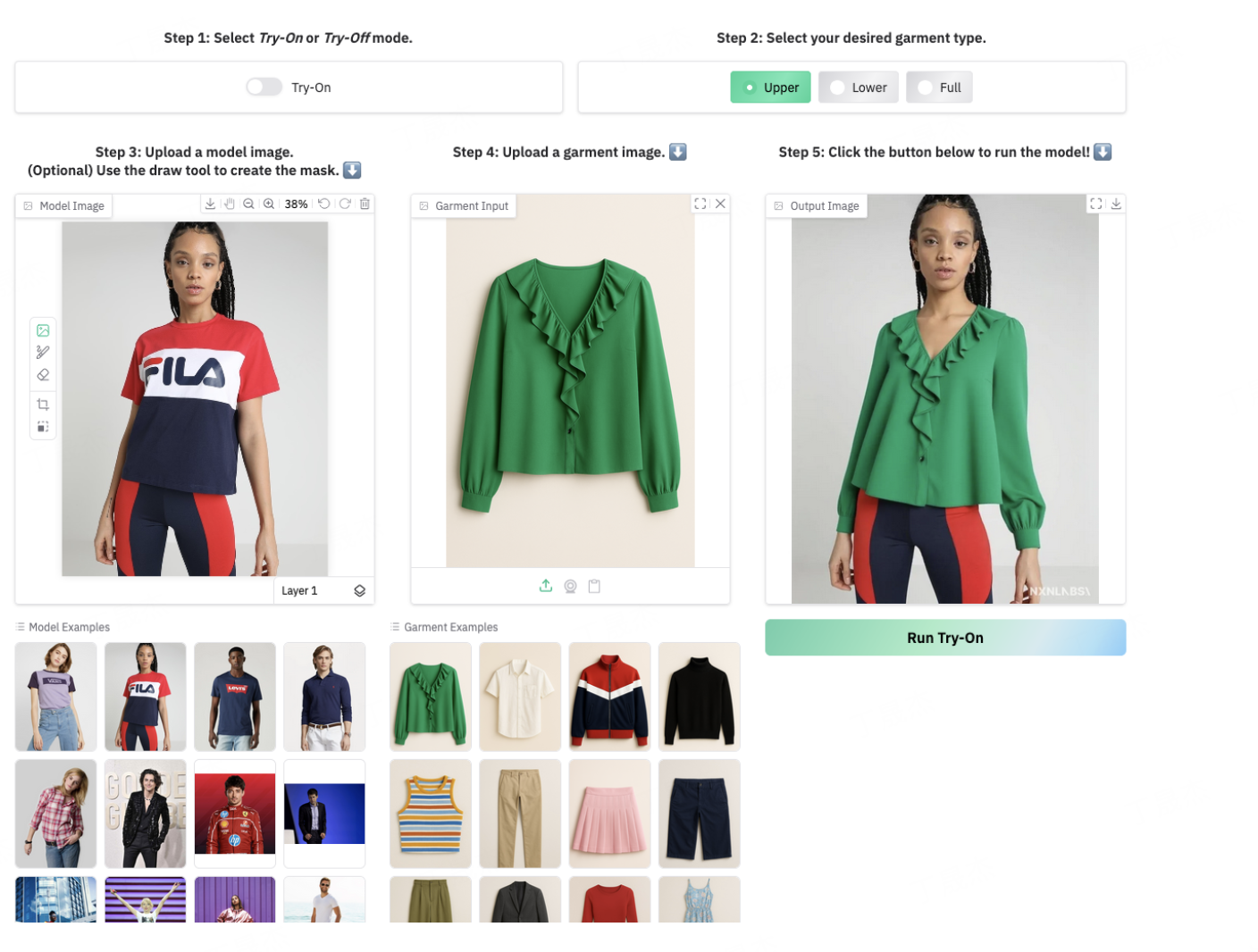

核心功能
- 統(tǒng)一的虛擬試穿與脫衣: 在一個模型中同時支持虛擬試穿(將服裝穿到人體上)和虛擬脫衣(將服裝從人體上移除)功能。
- 高保真圖像合成: 生成高度逼真的人體穿著或脫下目標服裝的圖像。
- 魯棒性: 能夠適應不同的人體姿態(tài)、服裝類別、背景、光照條件和圖像構圖,保持高質量輸出。
- 雙向監(jiān)督學習: 通過聯(lián)合建模試穿和脫衣任務,利用服裝-人體對在兩個方向上進行監(jiān)督,提高模型的準確性和靈活性。
- 可擴展性: 作為一個統(tǒng)一且可擴展的框架,具有良好的性能和應用潛力。
技術原理
Voost 的核心技術是其提出的“統(tǒng)一且可擴展的擴散變換器 (Unified and Scalable Diffusion Transformer)”。該模型利用擴散模型 (Diffusion Model) 在圖像生成方面的強大能力,結合變換器架構 (Transformer Architecture) 處理序列和長距離依賴的優(yōu)勢,以端到端的方式學習虛擬試穿和脫衣的復雜映射關系。通過一個單一的擴散變換器,Voost 能夠:
- 聯(lián)合學習: 同時編碼和解碼人體與服裝之間的復雜交互,實現(xiàn)試穿和脫衣任務的協(xié)同優(yōu)化。
- 細節(jié)建模: 擴散模型逐步去噪的特性使其能夠生成高分辨率且細節(jié)豐富的圖像,精確模擬服裝的褶皺、紋理和與身體的貼合。
- 變換器架構: 使得模型能夠捕捉圖像中不同區(qū)域(如人體姿態(tài)、服裝形狀、背景信息)之間的全局依賴關系,增強了模型處理復雜場景的能力和泛化性。
- 雙向流: 實現(xiàn)從服裝到人體的合成 (Try-On) 和從人體到服裝的逆向合成 (Try-Off),從而在訓練中提供更豐富的監(jiān)督信號,提升模型對服裝-身體對應關系的理解。
應用場景
-
在線虛擬試穿平臺: 消費者可以在線預覽服裝穿著效果,提高購物體驗和決策效率。
-
服裝設計與制造: 設計師快速驗證服裝設計在不同人體模型上的效果,加速設計迭代周期。
-
時尚內(nèi)容創(chuàng)作: 快速生成高質量的時尚宣傳圖片或視頻,用于廣告、社交媒體等。
-
虛擬現(xiàn)實/增強現(xiàn)實: 為元宇宙、虛擬形象和游戲中的服裝更換提供技術支持。
-
個性化推薦系統(tǒng): 結合用戶身體特征和偏好,推薦最適合的服裝并展示虛擬試穿效果。
-
項目官網(wǎng):https://nxnai.github.io/Voost/
-
Github倉庫:https://github.com/nxnai/Voost
-
arXiv技術論文:https://arxiv.org/pdf/2508.04825
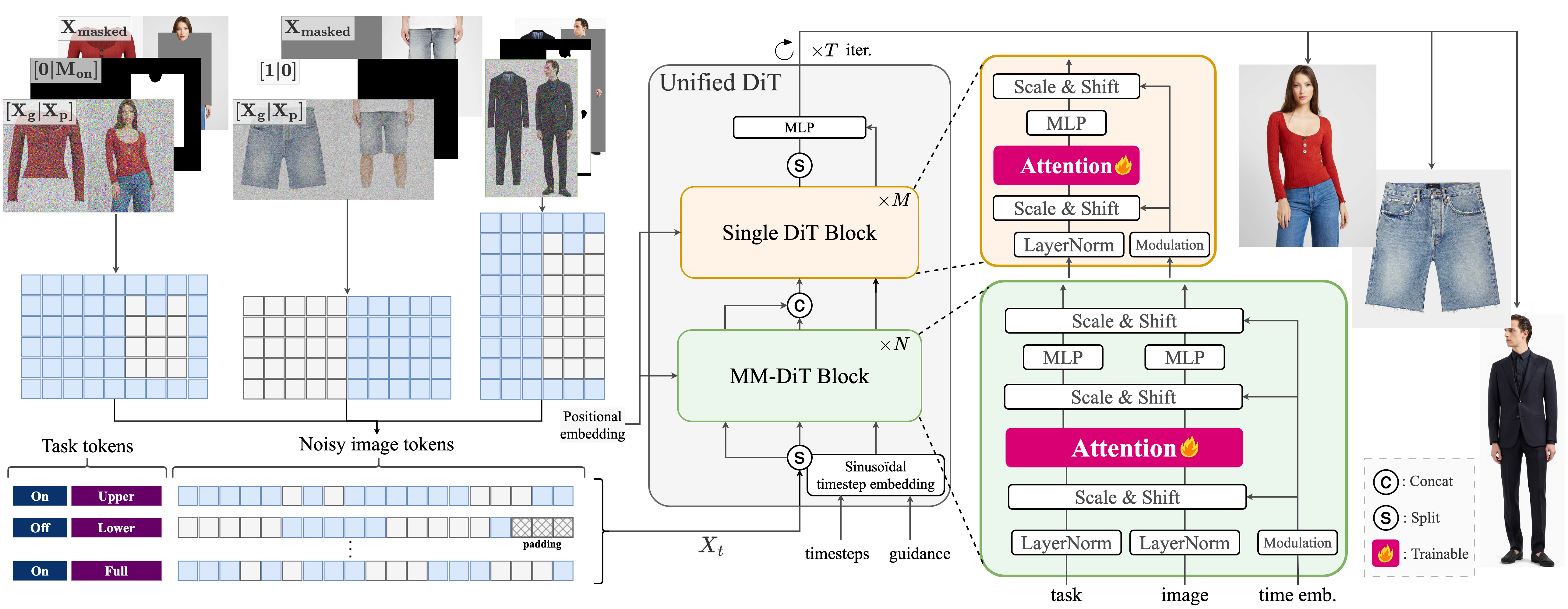
RynnVLA-001 – 阿里達摩院開源的視覺-語言-動作模型
RynnVLA-001是阿里巴巴達摩院開發(fā)的一種視覺-語言-動作(Vision-Language-Action, VLA)模型。該模型通過大規(guī)模第一人稱視角的視頻進行預訓練,旨在從人類示范中學習操作技能,并能夠將這些技能隱式地遷移到機器人手臂的控制中,使其能夠理解高層語言指令并執(zhí)行復雜的任務。

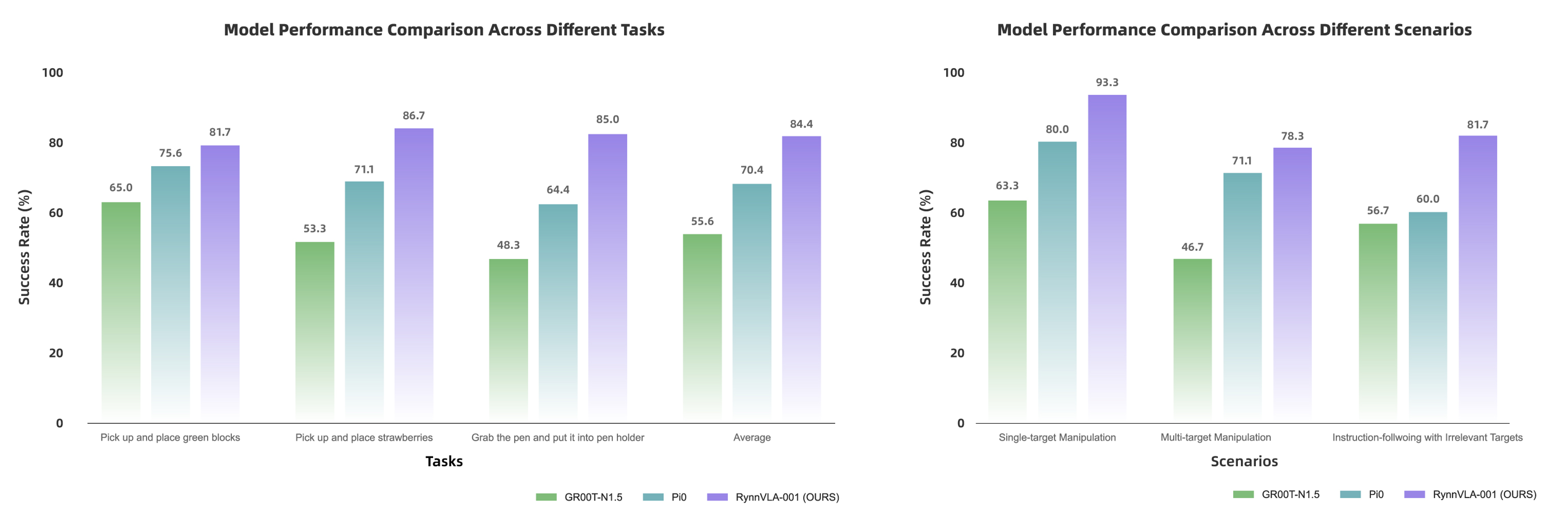
核心功能
- 視覺-語言理解與融合: 能夠理解視覺輸入和自然語言指令,并將兩者關聯(lián)起來。
- 技能學習與遷移: 從人類第一人稱視角的視頻示范中學習復雜的操作技能,并將其遷移到機器人平臺。
- 機器人操作控制: 使機器人手臂能夠精確執(zhí)行抓取-放置(pick-and-place)等復雜操作任務。
- 長程任務執(zhí)行: 支持機器人根據(jù)高級語言指令完成需要多步操作的長程任務。
技術原理
RynnVLA-001的核心技術原理是基于生成式先驗(generative priors)構建的。它是一個簡單而有效的VLA模型,其基礎是一個預訓練的視頻生成模型。具體流程包括:
- 第一階段:自我中心視頻生成模型(Ego-centric Video Generation Model): 利用大量第一人稱視頻數(shù)據(jù)訓練一個視頻生成模型,捕捉人類操作的視覺規(guī)律。
- 第二階段:機器人動作塊的VAE壓縮(VAE for Compressing Robot Action Chunks): 使用變分自編碼器(VAE)對機器人動作序列進行高效壓縮,提取核心動作特征。
- 第三階段:視覺-語言-動作模型構建(Vision-Language-Action Model): 將視頻生成模型和動作VAE結合,構建一個端到端的VLA模型,使其能夠從視覺和語言輸入中直接生成機器人動作。
應用場景
-
機器人工業(yè)自動化: 用于訓練工業(yè)機器人執(zhí)行精細裝配、分揀和搬運等任務,提高生產(chǎn)線自動化水平。
-
服務機器人: 賦予服務機器人更強的環(huán)境感知和人機交互能力,使其能更好地理解并執(zhí)行用戶指令,例如家庭助手、醫(yī)療輔助機器人。
-
人機協(xié)作: 促進機器人更自然地與人類協(xié)作,通過觀察人類操作學習新技能,提高協(xié)作效率。
-
智能家居: 應用于智能家電和自動化系統(tǒng)中,實現(xiàn)更智能、更人性化的設備控制和任務執(zhí)行。
-
教育與研究: 為機器人學習、多模態(tài)AI等領域提供一個強大的研究平臺和教學工具。
-
項目官網(wǎng):https://huggingface.co/blog/Alibaba-DAMO-Academy/rynnvla-001
-
GitHub倉庫:https://github.com/alibaba-damo-academy/RynnVLA-001
-
HuggingFace模型庫:https://huggingface.co/Alibaba-DAMO-Academy/RynnVLA-001-7B-Base
RynnEC – 阿里達摩院世界理解模型
RynnEC是阿里巴巴達摩院推出的一種世界理解模型(MLLM),專為具身認知任務設計。它旨在賦予人工智能系統(tǒng)對物理世界及其環(huán)境中物體深入的理解能力。
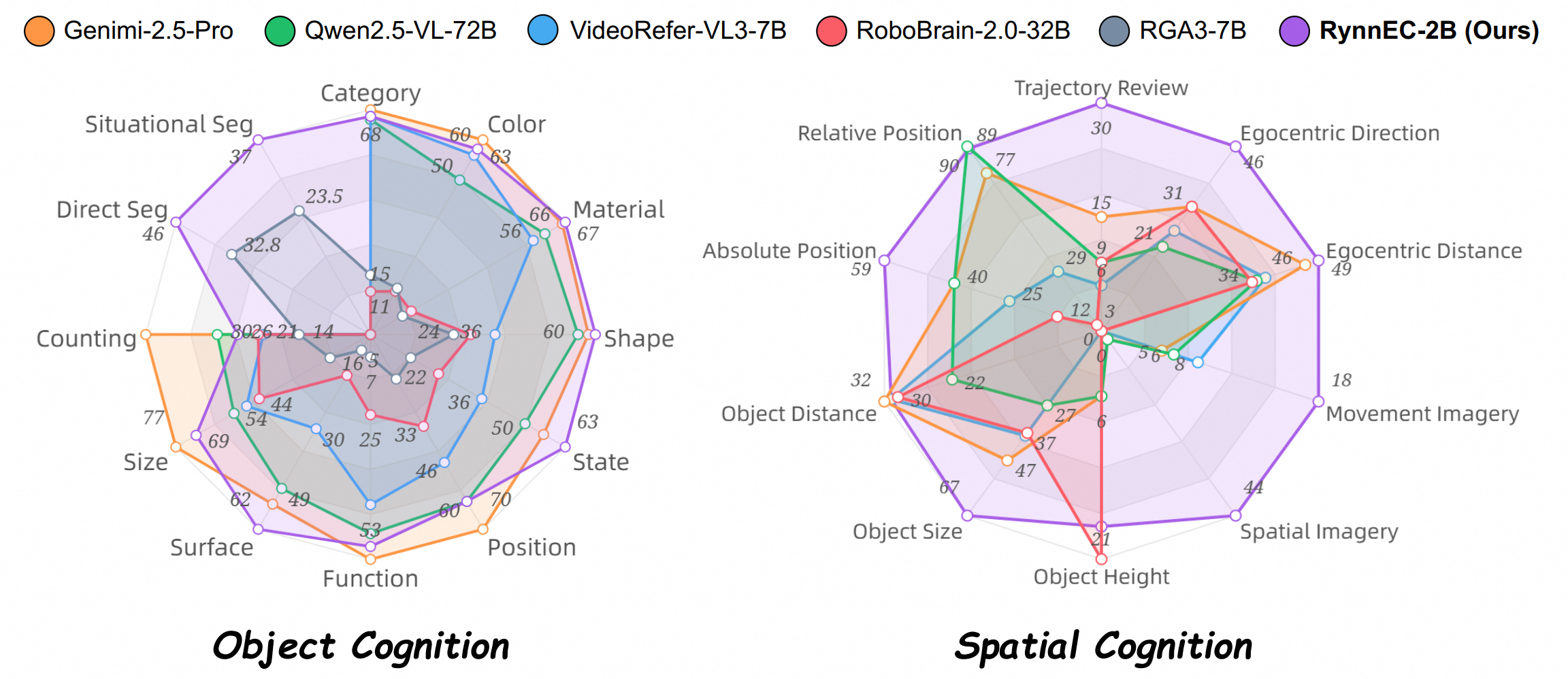
核心功能
RynnEC的核心功能在于能夠從多達11個維度全面解析場景中的物體,這些維度包括但不限于物體的位置、功能和數(shù)量。模型支持對物體的精確理解以及對空間關系的深入感知。
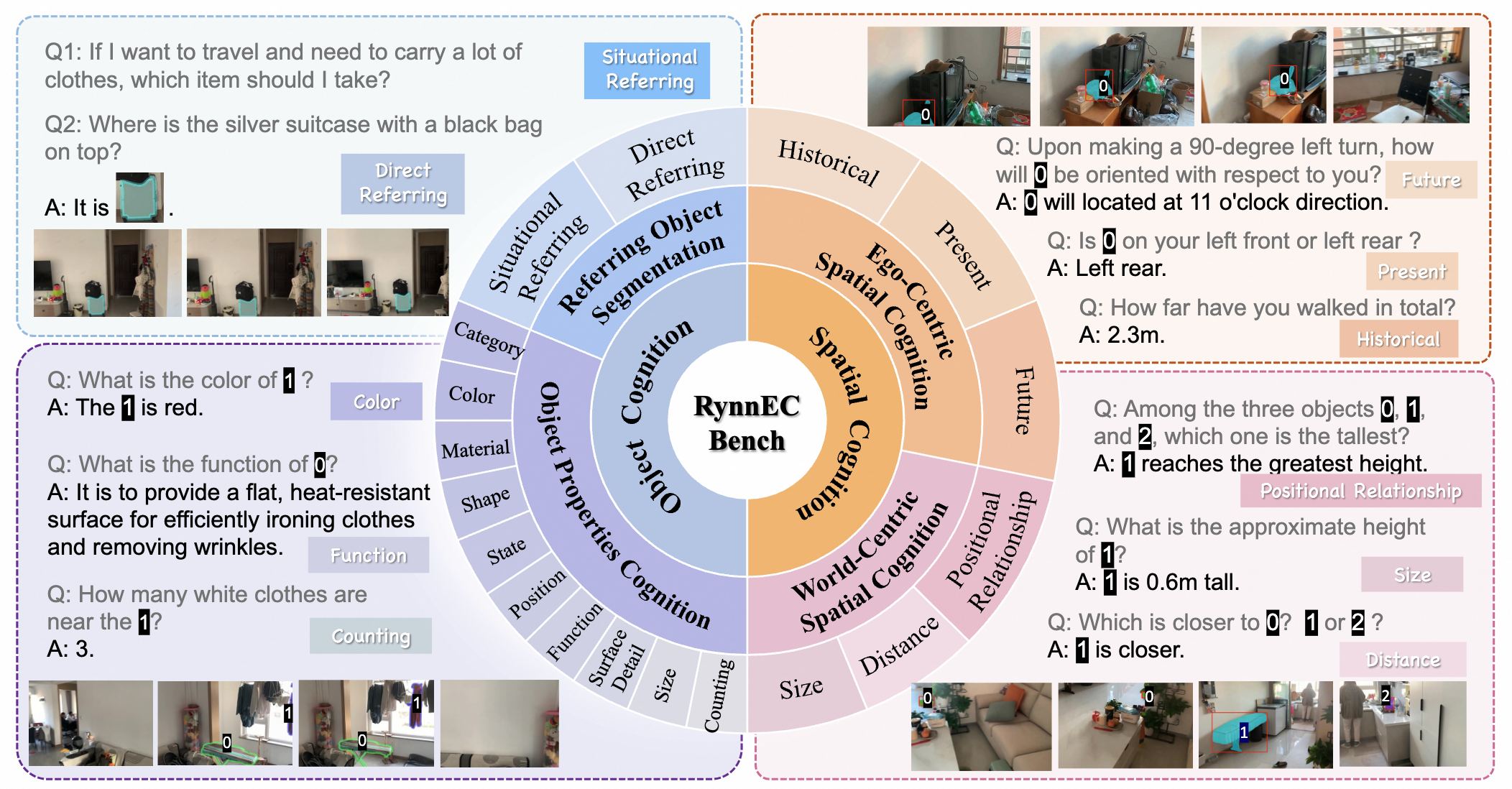
技術原理
RynnEC基于多模態(tài)大語言模型(MLLM)架構,其技術原理涉及融合視覺與語言信息,以構建對真實世界的豐富表征。通過對場景中物體在位置、功能、數(shù)量等多個維度進行精細化分析,RynnEC能夠實現(xiàn)高維度的場景理解和物體屬性識別,從而支持復雜的具身智能決策和交互。
應用場景
RynnEC主要應用于需要具身認知能力的領域,包括但不限于:
-
智能機器人與自動化: 幫助機器人在復雜環(huán)境中理解并操作物體,執(zhí)行抓取、導航等任務。
-
虛擬現(xiàn)實(VR)/增強現(xiàn)實(AR): 提升虛擬/增強環(huán)境中對現(xiàn)實物體的識別和交互能力,提供更真實的沉浸式體驗。
-
智能家居: 賦能智能設備更準確地感知和響應用戶指令及環(huán)境變化。
-
自動駕駛: 輔助車輛更好地理解道路環(huán)境、交通參與者和障礙物,提升決策安全性。
RynnRCP – 阿里達摩院機器人上下文協(xié)議
RynnRCP(Robotics Context Protocol)是阿里巴巴達摩院開源的一套機器人上下文協(xié)議及框架,旨在打通具身智能(Embodied Intelligence)的開發(fā)全流程,提供標準化的機器人服務協(xié)議和開發(fā)框架。
核心功能
- 標準化協(xié)議與框架: 提供一套完整的機器人服務協(xié)議和開發(fā)框架,促進具身智能開發(fā)流程的標準化。
- 模塊化組件: 主要由RCP框架和RobotMotion兩大核心模塊組成,分別負責協(xié)議定義與機器人運動控制。
- 全流程打通: 旨在整合具身智能從感知、認知到行動的開發(fā)鏈路,提升開發(fā)效率和兼容性。
技術原理
RynnRCP的核心技術原理基于機器人上下文協(xié)議(Robotics Context Protocol),該協(xié)議定義了機器人系統(tǒng)間進行任務、數(shù)據(jù)和狀態(tài)交互的標準化接口和規(guī)范。其內(nèi)部包含:
- RCP 框架: 負責定義具身智能任務的描述、分解、執(zhí)行狀態(tài)以及環(huán)境上下文信息的傳遞機制,確保不同模塊和設備間的協(xié)同工作。
- RobotMotion 模塊: 專注于機器人的運動控制,可能涉及高級運動規(guī)劃、力控、軌跡生成以及與機器人硬件接口的集成,實現(xiàn)精確且魯棒的物理世界操作。
- 具身智能理論: 結合AI與機器人技術,使機器人能夠像人類一樣感知環(huán)境、理解意圖、作出決策并在物理世界中執(zhí)行任務,強調實體與環(huán)境的交互。
應用場景
-
通用具身智能機器人開發(fā): 適用于各類服務機器人、工業(yè)機器人、物流機器人等具身智能設備的快速開發(fā)與部署。
-
機器人系統(tǒng)集成: 作為統(tǒng)一的通信和控制協(xié)議,便于集成不同廠商的機器人硬件、傳感器和執(zhí)行器。
-
智能工廠與自動化: 在工業(yè)自動化領域,用于實現(xiàn)機器人協(xié)同作業(yè)、產(chǎn)線柔性制造和智能巡檢。
-
智慧生活與服務: 在家庭、醫(yī)療、零售等服務場景中,支撐服務機器人的智能交互和任務執(zhí)行。
Skywork UniPic 2.0 – 昆侖萬維開源的統(tǒng)一多模態(tài)模型
簡介
Skywork UniPic 2.0 是昆侖萬維開源的高效多模態(tài)模型,致力于實現(xiàn)統(tǒng)一的圖像生成、編輯和理解能力。該模型旨在通過統(tǒng)一的架構處理視覺信息,提升多模態(tài)任務的效率和性能。
核心功能
- 圖像生成: 能夠根據(jù)文本描述或其他輸入生成高質量圖像。
- 圖像編輯: 提供對圖像內(nèi)容的編輯和修改能力。
- 圖像理解: 具備對圖像進行語義理解和分析的能力。
- 統(tǒng)一多模態(tài)處理: 將圖像生成、編輯和理解等功能集成在一個模型框架內(nèi),實現(xiàn)多任務處理。
技術原理
Skywork UniPic 2.0 基于2B參數(shù)的SD3.5-Medium架構(部分資料提及UniPic為1.5B參數(shù)的自回歸模型,但2.0版本主要強調SD3.5-Medium架構)。其核心技術原理包括:
- 自回歸模型(Autoregressive Model): 通過預測序列中的下一個元素來逐步生成內(nèi)容,尤其在圖像生成和理解中表現(xiàn)出強大能力。
- 多模態(tài)預訓練: 模型通過大規(guī)模多模態(tài)數(shù)據(jù)進行預訓練,學習圖像與文本之間的深層關聯(lián)。
- 漸進式雙向特征融合: 采用先進的特征融合技術,有效整合不同模態(tài)的信息,增強模型的跨模態(tài)理解與生成能力。
- 統(tǒng)一表示學習: 旨在學習一種統(tǒng)一的視覺和文本表示,使得模型能夠在一個共享的潛在空間中進行多模態(tài)任務處理。
應用場景
-
內(nèi)容創(chuàng)作: 輔助設計師、藝術家和營銷人員快速生成創(chuàng)意圖像、廣告素材等。
-
圖像處理與分析: 在圖像編輯軟件中集成,實現(xiàn)智能圖像修復、風格遷移或內(nèi)容修改;在安防、醫(yī)療等領域進行圖像識別和分析。
-
多模態(tài)交互系統(tǒng): 作為智能助手或聊天機器人的一部分,支持用戶通過自然語言進行圖像查詢、生成和編輯。
-
教育與研究: 為多模態(tài)AI領域的研究人員提供開源模型和工具,推動技術發(fā)展和創(chuàng)新應用。
-
項目官網(wǎng):https://unipic-v2.github.io/
-
GitHub倉庫:https://github.com/SkyworkAI/UniPic/tree/main/UniPic-2
-
HuggingFace模型庫:https://huggingface.co/collections/Skywork/skywork-unipic2-6899b9e1b038b24674d996fd
-
技術論文:https://github.com/SkyworkAI/UniPic/blob/main/UniPic-2/assets/pdf/UNIPIC2.pdf
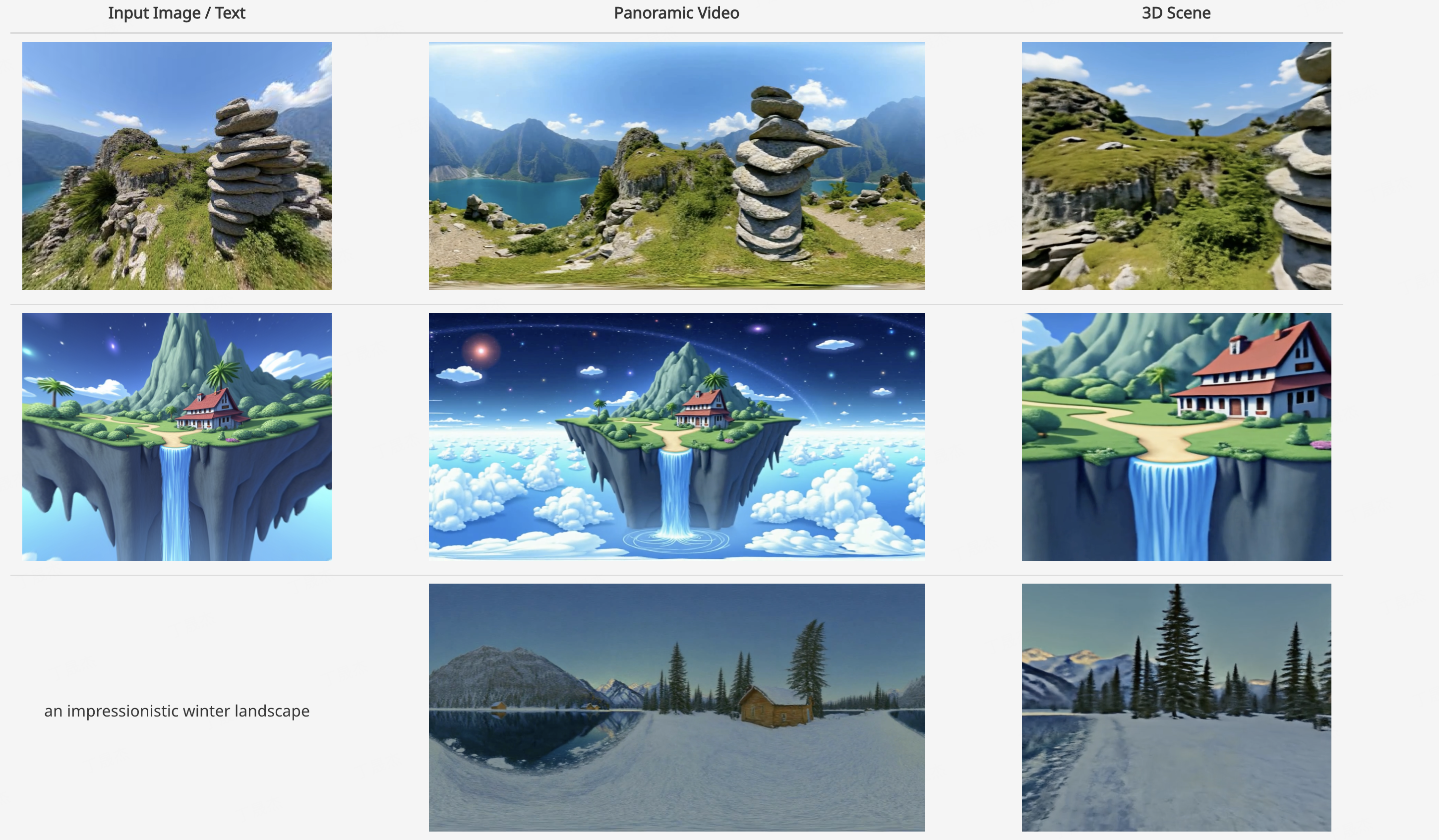
Matrix-3D – 昆侖萬維開源的3D世界模型
Matrix-3D是由昆侖萬維Skywork AI團隊開發(fā)的一個先進框架,旨在通過單張圖像或文本提示生成可探索的大規(guī)模全景3D世界。它結合了全景視頻生成與3D重建技術,旨在實現(xiàn)高保真、全向可探索的沉浸式3D場景。
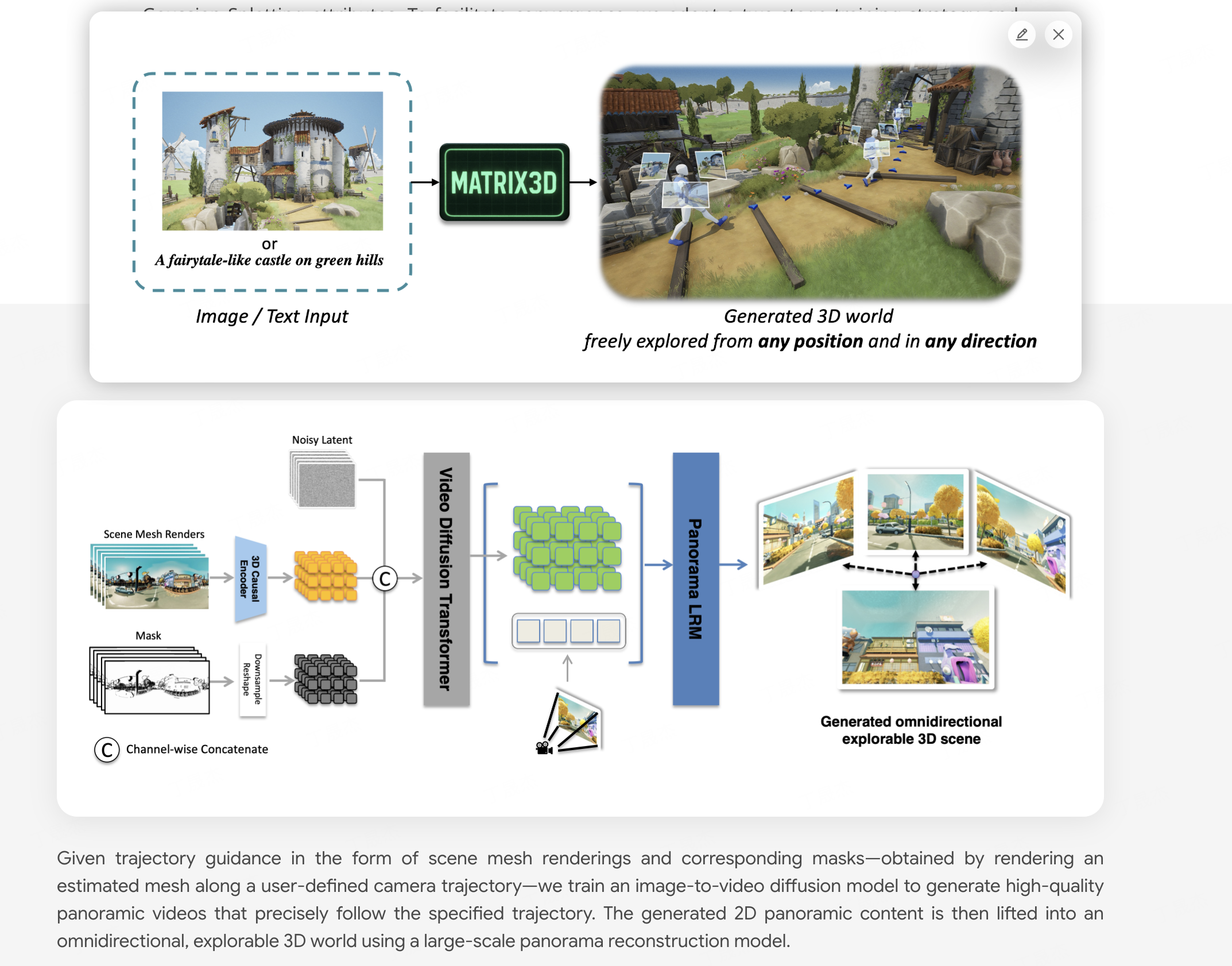
核心功能
- 全景3D世界生成: 能夠從單一圖像或文本提示生成廣闊且可探索的全景3D場景。
- 圖像/文本到3D場景轉換: 支持將輸入的圖像或文本描述直接轉化為對應的3D世界內(nèi)容。
- 條件視頻生成: 具備基于特定條件生成全景視頻的能力。
- 全景3D重建: 實現(xiàn)對全景圖像或視頻內(nèi)容的3D重建。
- 強大的泛化能力: 基于自研的3D數(shù)據(jù)和視頻模型先驗,能夠生成多樣化且高質量的3D場景。
技術原理
Matrix-3D的核心技術原理在于其對全景表示(panoramic representation)的利用,以實現(xiàn)廣覆蓋、全向可探索的3D世界生成。它融合了以下關鍵技術:
- 條件視頻生成(conditional video generation): 通過深度學習模型,根據(jù)輸入條件(如圖像或文本)生成符合要求的全景視頻序列。
- 全景3D重建(panoramic 3D reconstruction): 運用計算機視覺和圖形學技術,從全景圖像或視頻中恢復場景的幾何信息和結構。
- 3D數(shù)據(jù)和視頻模型先驗(3D data and video model priors): 模型在大量自研的3D數(shù)據(jù)和視頻數(shù)據(jù)上進行訓練,學習到豐富的場景結構和動態(tài)規(guī)律,從而增強了生成結果的真實感和多樣性。
應用場景
- 虛擬現(xiàn)實(VR)/增強現(xiàn)實(AR)內(nèi)容創(chuàng)作: 快速生成沉浸式的VR/AR環(huán)境,用于游戲、教育、旅游等領域。
- 元宇宙(Metaverse)構建: 為元宇宙平臺提供大規(guī)模、可探索的3D場景內(nèi)容生成能力。
- 影視動畫制作: 輔助制作人員快速生成復雜的3D場景背景或預覽。
- 虛擬漫游與規(guī)劃: 在房地產(chǎn)、城市規(guī)劃、室內(nèi)設計等領域,用于生成虛擬漫游體驗。
- 數(shù)字孿生(Digital Twin): 構建現(xiàn)實世界的虛擬副本,進行模擬和分析。
- 游戲開發(fā): 提升游戲場景的生成效率和多樣性,實現(xiàn)更加生動逼真的游戲世界。
Matrix-3D的項目地址
- 項目官網(wǎng):https://matrix-3d.github.io/
- GitHub倉庫:https://github.com/SkyworkAI/Matrix-3D
- HuggingFace模型庫:https://huggingface.co/Skywork/Matrix-3D
- 技術論文:https://github.com/SkyworkAI/Matrix-3D/blob/main/asset/report.pdf
Matrix-Game 2.0 – 昆侖萬維推出的自研世界模型
Matrix-Game 2.0是由昆侖萬維SkyWork AI發(fā)布的一款自研世界模型,被譽為業(yè)內(nèi)首個開源的通用場景實時長序列交互式生成模型。它旨在推動交互式世界模型領域的發(fā)展,能夠實現(xiàn)可控的游戲世界生成,并支持高質量、實時、長序列的視頻生成。

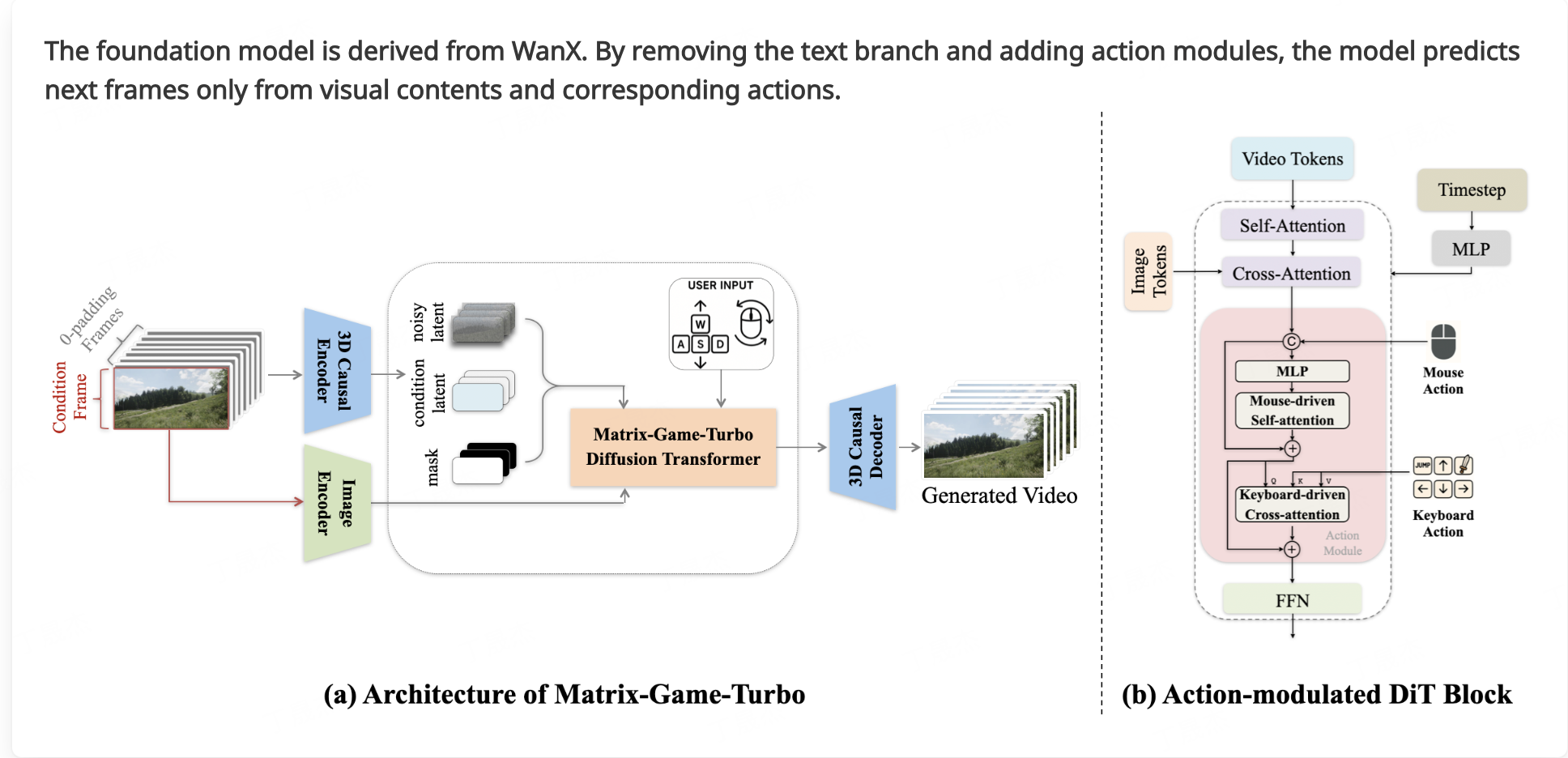
核心功能
- 交互式世界生成: 能夠根據(jù)指令生成和操控游戲世界,實現(xiàn)高度交互性。
- 實時長序列視頻生成: 以25 FPS的超高速率生成分鐘級的高質量視頻,支持多樣的場景。
- 基礎世界模型: 作為交互式世界的基礎模型,參數(shù)量達到17B,可用于構建復雜的虛擬環(huán)境。
- 全面開源: 提供模型權重和相關資源,促進社區(qū)共同發(fā)展和應用。
技術原理
- 生成對抗網(wǎng)絡 (GAN) 或擴散模型 (Diffusion Models): 用于高質量的圖像和視頻內(nèi)容生成。
- 序列建模: 采用Transformer等架構處理長序列的交互和狀態(tài)變化,以實現(xiàn)實時且連貫的世界演進。
- 強化學習 (Reinforcement Learning) 或模仿學習 (Imitation Learning): 用于訓練模型理解用戶意圖并生成可控的交互行為。
- 多模態(tài)融合: 結合視覺、文本、動作等多種模態(tài)信息,以構建更豐富的世界表征。
- 高效推理優(yōu)化: 實現(xiàn)25 FPS的實時生成速度,可能采用了量化、剪枝或并行計算等優(yōu)化技術。
應用場景
-
具身AI訓練: 為具身智能體提供逼真且可控的訓練環(huán)境。
-
虛擬現(xiàn)實/元宇宙構建: 快速生成和定制虛擬世界內(nèi)容,提升用戶體驗。
-
游戲開發(fā): 自動化游戲場景、角色行為和故事情節(jié)的生成,大幅提高開發(fā)效率。
-
數(shù)字孿生: 創(chuàng)建真實世界的虛擬復刻,用于模擬、預測和優(yōu)化。
-
內(nèi)容創(chuàng)作: 輔助藝術家和設計師進行概念設計、動畫制作和電影預可視化。
-
項目官網(wǎng):https://matrix-game-v2.github.io/
-
HuggingFace模型庫:https://huggingface.co/Skywork/Matrix-Game-2.0
-
技術報告:https://github.com/SkyworkAI/Matrix-Game/blob/main/Matrix-Game-2/assets/pdf/report.pdf
GLM-4.5V – 智譜開源的最新一代視覺推理模型
GLM-4.5V是由智譜AI開發(fā)并開源的領先視覺語言模型(VLM),它基于智譜AI新一代旗艦文本基座模型GLM-4.5-Air(總參數(shù)1060億,活躍參數(shù)120億)。該模型繼承并發(fā)展了GLM-4.1V-Thinking的技術路線,旨在提升多模態(tài)感知之上的高級推理能力,以解決復雜AI任務,并支持長上下文理解和多模態(tài)智能體應用。
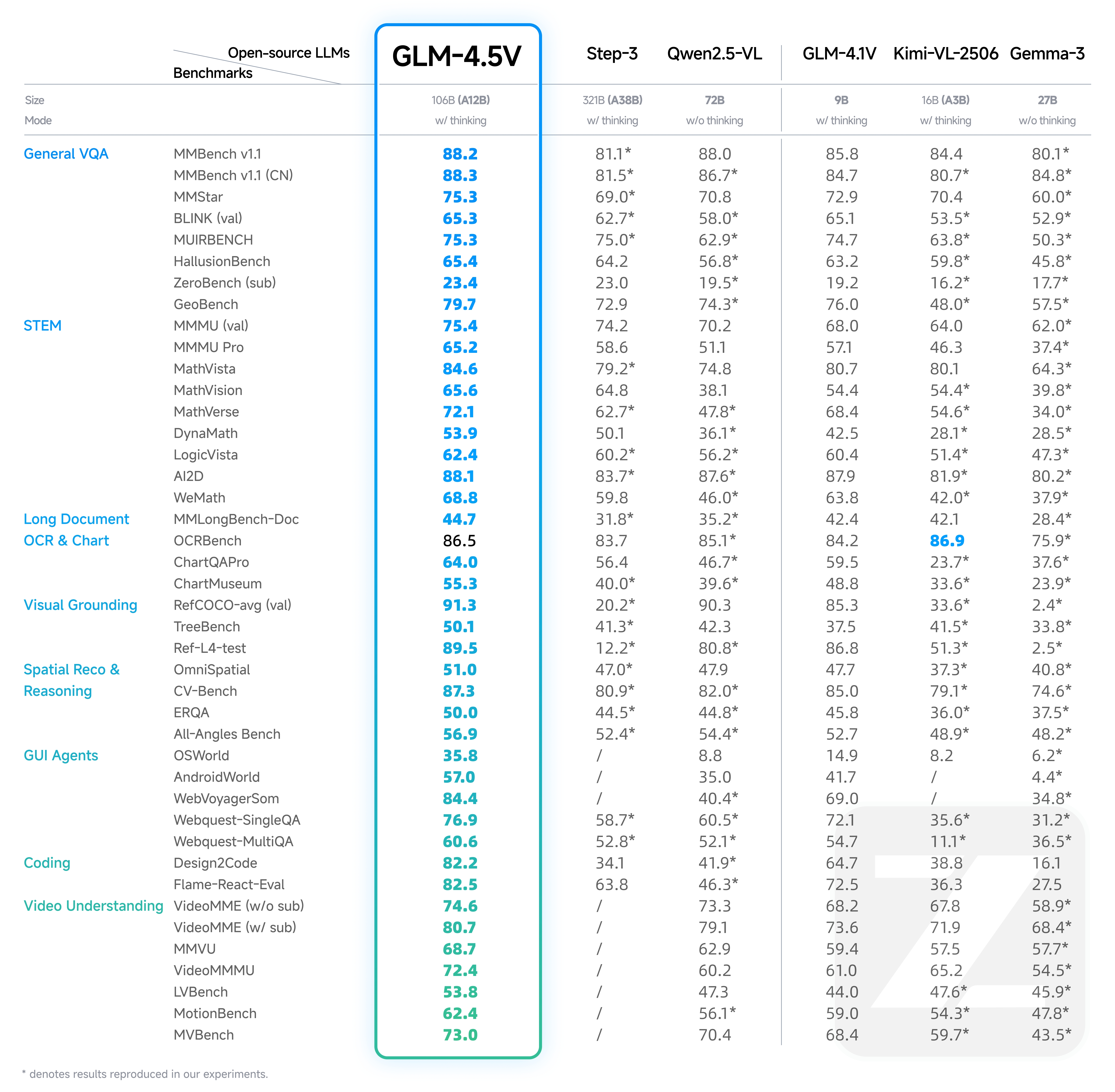
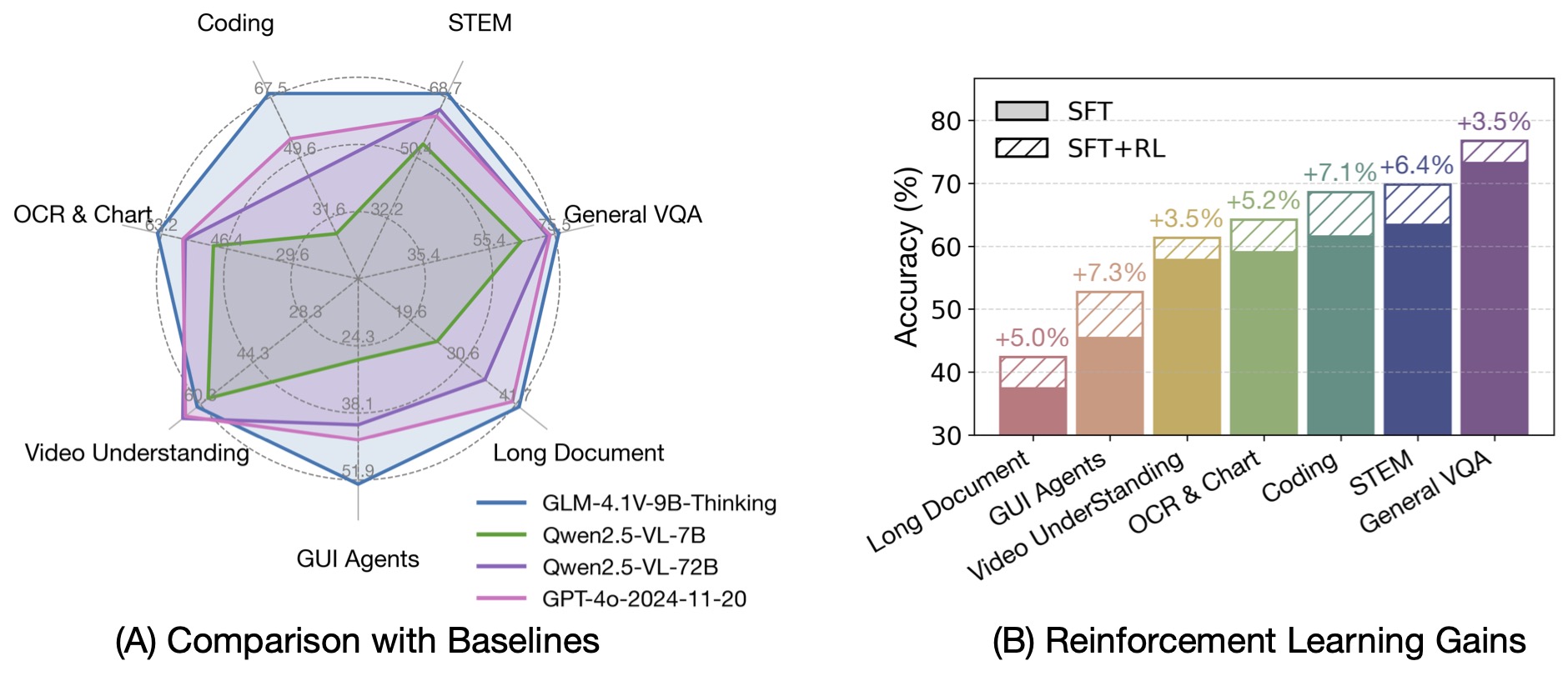
核心功能
- 多模態(tài)理解與感知: 能夠處理和理解圖像、視頻、文檔等多源異構數(shù)據(jù)。
- 高級推理能力: 具備強大的長上下文理解、科學問題解決(STEM Reasoning)和代理(Agentic)能力。
- 代碼與GUI操作: 支持代碼理解、生成以及圖形用戶界面(GUI)的自動化操作。
- 工具調用: 支持函數(shù)調用、知識庫檢索和網(wǎng)絡搜索等工具集成。
- 混合推理模式: 提供“思考模式”用于復雜推理和工具使用,以及“非思考模式”用于即時響應。
技術原理
GLM-4.5V的技術核心在于其 “思考模式”(Thinking Mode) 和 多模態(tài)強化學習(Multimodal Reinforcement Learning, RL)。它基于大規(guī)模Transformer架構,以GLM-4.5-Air作為其文本基礎模型。通過采用GLM-4.1V-Thinking的先進方法,模型在多模態(tài)數(shù)據(jù)上進行了大規(guī)模訓練,并結合可擴展的強化學習策略,顯著增強了其復雜問題解決、長上下文處理和多模態(tài)代理能力。模型響應中的邊界框(Bounding Box)坐標通過特殊標記<|begin_of_box|>和<|end_of_box|>表示,坐標值通常在0到1000之間歸一化,用于視覺定位。
應用場景
-
智能助理與Agent: 構建能夠執(zhí)行復雜多模態(tài)任務的智能代理,如內(nèi)容創(chuàng)作、信息檢索、自動化流程。
-
教育與研究: 輔助科學、技術、工程、數(shù)學(STEM)領域的復雜問題求解。
-
文檔處理與分析: 進行長文檔理解、內(nèi)容識別與提取。
-
自動化測試與操作: 實現(xiàn)基于GUI的應用程序自動化操作,如UI測試、任務執(zhí)行。
-
多媒體內(nèi)容分析: 應用于圖像和視頻內(nèi)容理解、分析與生成。
-
編碼輔助: 作為代碼助手,進行代碼理解和生成。
-
GitHub倉庫:https://github.com/zai-org/GLM-V/
-
HuggingFace模型庫:https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
-
技術論文:https://github.com/zai-org/GLM-V/tree/main/resources/GLM-4.5V_technical_report.pdf
-
桌面助手應用:https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
DreamVVT – 字節(jié)聯(lián)合清華推出的視頻虛擬試穿技術
DreamVVT是由字節(jié)跳動與清華大學(深圳)聯(lián)合推出的一項視頻虛擬試穿(Video Virtual Try-On, VVT)技術。該項目旨在通過先進的AI模型實現(xiàn)高保真、逼真的視頻虛擬服裝試穿效果,尤其強調在“野外”場景下(即非受控環(huán)境)的真實感和魯棒性。

核心功能
DreamVVT的核心功能是實現(xiàn)用戶在視頻中進行虛擬服裝試穿。具體包括:
- 高保真試穿效果:生成逼真、細節(jié)豐富的虛擬試穿視頻。
- 視頻流適配:支持在視頻內(nèi)容中進行動態(tài)、連續(xù)的服裝替換和試穿。
- “野外”場景適用性:能夠在復雜、非受控的真實視頻環(huán)境中穩(wěn)定運行,克服光照、姿態(tài)變化等挑戰(zhàn)。
- 服裝風格轉移:將目標服裝的樣式和紋理精確地應用到視頻中的人物身上。
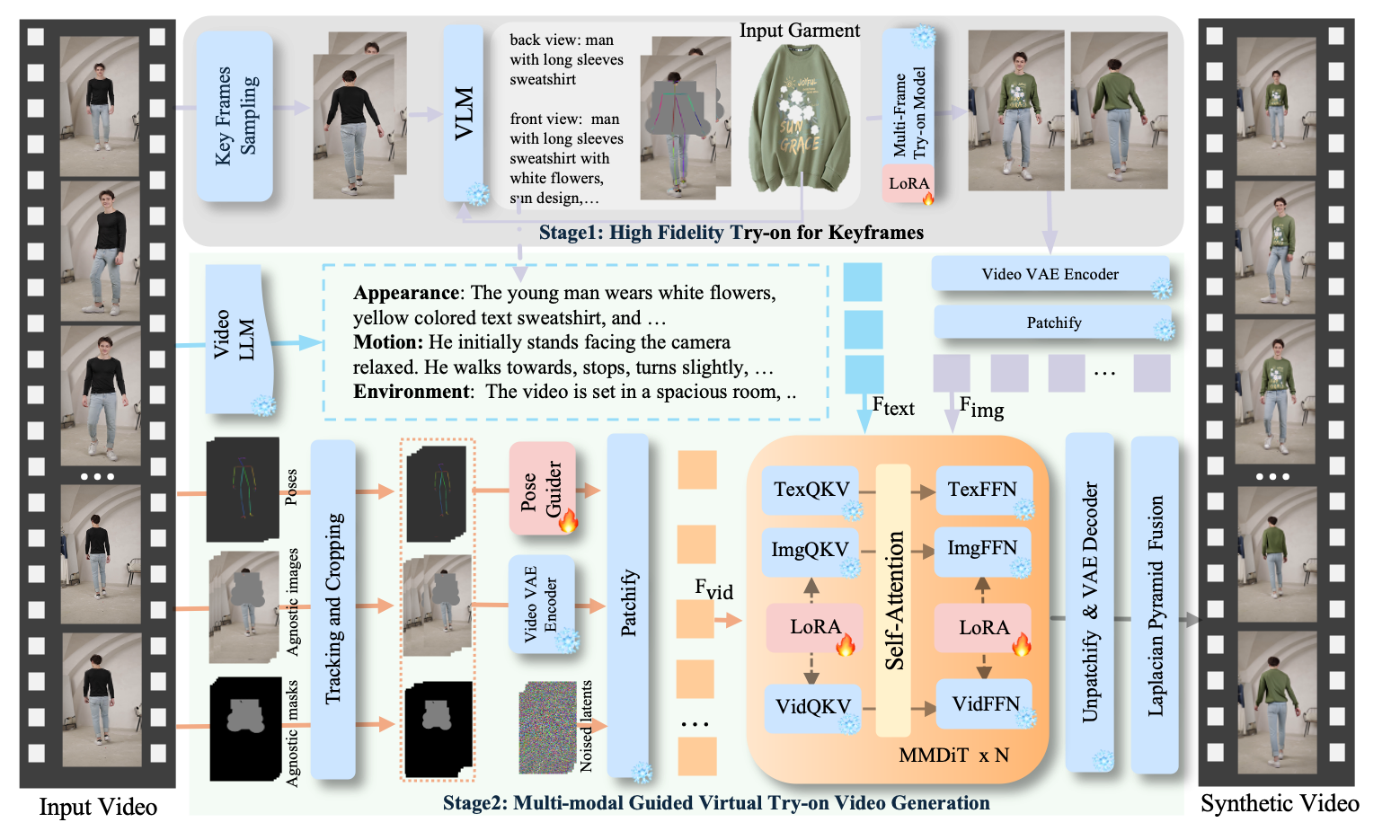
技術原理
DreamVVT技術基于擴散Transformer(DiTs)框架,并采用兩階段(或稱為分階段)方法實現(xiàn)。其主要技術原理包括:
- 擴散Transformer (DiTs):利用Transformer架構的強大建模能力處理擴散過程,以生成高質量的圖像和視頻內(nèi)容。擴散模型在生成逼真圖像方面表現(xiàn)出色,能夠逐步去噪生成目標圖像。
- 兩階段框架:通過分解任務為不同階段來提高生成質量和穩(wěn)定性。這可能包括初步的姿態(tài)對齊/服裝變形階段和隨后的高保真渲染階段。
- LoRA (Low-Rank Adaptation) 適配器:結合LoRA技術,以高效地微調預訓練模型,使其適應視頻虛擬試穿的特定任務,同時減少計算資源消耗和模型大小。
- 利用無配對數(shù)據(jù):該框架能夠有效利用無配對的人像和服裝數(shù)據(jù)進行訓練,這大大降低了數(shù)據(jù)采集的難度和成本,使其在實際應用中更具靈活性。
應用場景
DreamVVT技術在多個領域具有廣闊的應用前景,主要包括:
- 在線零售與電商:消費者可以在購買前通過視頻觀看服裝在自己身上的虛擬試穿效果,提升購物體驗和決策效率,減少退貨率。
- 時尚產(chǎn)業(yè):用于服裝設計、展示和營銷,設計師可以快速預覽設計效果,品牌可以制作更具吸引力的虛擬宣傳視頻。
- 影視制作與內(nèi)容創(chuàng)作:在電影、電視節(jié)目、廣告或短視頻中快速、高效地更換演員的服裝,節(jié)省后期制作成本。
- 虛擬形象與元宇宙:為虛擬形象和元宇宙中的用戶提供個性化的虛擬服裝試穿服務,增強沉浸感和互動性。
DreamVVT的項目地址
- 項目官網(wǎng):https://virtu-lab.github.io/
- Github倉庫:https://github.com/Virtu-Lab/DreamVVT
- arXiv技術論文:https://arxiv.org/pdf/2508.02807v1
AionUi – 將命令行體驗轉換為現(xiàn)代、高效的 AI 聊天界面
AionUi 是一個免費、本地、開源的圖形用戶界面(GUI)應用程序,旨在將強大的AI能力變得人人可及,通過友好的用戶界面簡化與AI代理的交互。它目前主要為Gemini命令行界面(CLI)提供增強的用戶體驗,并計劃發(fā)展成為一個通用的AI代理平臺,彌合AI復雜功能與日常易用性之間的鴻溝。
核心功能
- 增強型AI聊天體驗: 提供直觀的GUI界面,優(yōu)化與AI的交互過程。
- 多任務處理能力: 集成文件管理、代碼差異查看等功能,提升工作效率。
- 開發(fā)者工作流優(yōu)化: 簡化開發(fā)者與AI工具的交互,如與Gemini CLI的集成。
- 靈活的LLM綁定: 支持與多種大語言模型(LLM)進行綁定和交互。
- API及代理配置: 提供API認證和HTTP代理配置選項,以適應不同的網(wǎng)絡環(huán)境和認證需求。
技術原理
AionUi 采用Electron和React技術構建其跨平臺桌面應用程序,實現(xiàn)了直觀的用戶界面。其核心原理是通過GUI封裝并簡化對Gemini命令行界面(CLI)的操作,將復雜的命令轉化為圖形化交互。它支持多代理生態(tài)系統(tǒng)和靈活的LLM綁定機制,允許集成和切換不同的大語言模型。項目采用模塊化設計,結構清晰,易于維護和擴展。
應用場景
-
AI輔助開發(fā): 開發(fā)者可利用其增強的聊天、代碼管理和多任務功能,更高效地進行編程、調試和項目管理。
-
日常AI交互: 降低非技術用戶使用復雜AI代理的門檻,使AI功能像聊天一樣易于訪問和使用。
-
本地AI部署與管理: 為需要本地運行或管理AI模型和代理的用戶提供便捷的圖形化解決方案。
-
企業(yè)內(nèi)部AI工具: 可作為企業(yè)內(nèi)部集成AI代理、提升團隊工作效率的定制化工具。
-
AI學習與普及: 通過友好的界面,幫助更多人輕松探索和學習AI技術及應用。
-
GitHub倉庫:https://github.com/office-sec/AionUi
MiroThinker 針對深度研究和復雜工具使用場景進行開源Agent模型
MiroThinker 是一個開源的智能體模型系列,由 MiroMind AI 推出,專為深度研究、復雜問題解決和長期規(guī)劃設計。該模型致力于通過其先進的智能體能力,彌合人類智能與人工智能之間的鴻溝,旨在推動通用人工智能(AGI)的發(fā)展。MiroThinker 在大規(guī)模、高質量軌跡和偏好數(shù)據(jù)集上進行訓練,具有高性能表現(xiàn)。
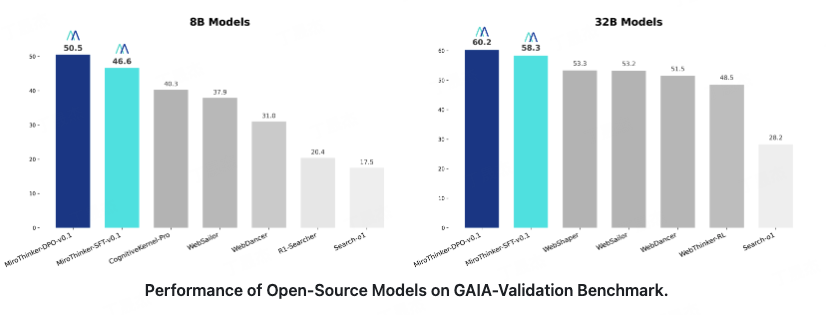
核心功能
- 深度研究與復雜問題解決: 能夠處理需要深入分析和多步驟推理的復雜任務。
- 多跳推理能力: 支持鏈式思維和逐步推理,以解決需要多階段思考的問題。
- 任務分解: 將復雜任務拆解成可管理的子任務。
- 檢索增強生成(RAG): 結合外部知識檢索,提高生成內(nèi)容的準確性和相關性。
- 代碼執(zhí)行: 具備執(zhí)行代碼的能力,支持與外部工具和環(huán)境的交互。
- 工具使用與調用: 高效利用各種工具來完成特定任務。
- 自我意識與長期記憶(MiroMind愿景): 作為MiroMind的核心研究方向,旨在通過長期記憶實現(xiàn)AI的自我意識覺醒。
技術原理
MiroThinker 模型系列基于 Qwen3 (通義千問3) 等先進的基礎模型進行構建。其核心技術原理包括:
- 大型語言模型(LLM)驅動的智能體架構: 利用強大的LLM作為核心,實現(xiàn)復雜的認知和決策過程。
- 軌跡與偏好數(shù)據(jù)訓練: 模型在 MiroVerse-v0.1 等大規(guī)模、高質量的軌跡和偏好數(shù)據(jù)集上進行訓練,通過監(jiān)督微調(SFT)和直接偏好優(yōu)化(DPO)等技術,提升模型的決策能力和行為表現(xiàn)。
- 強化學習與反饋機制: 通過從復雜任務執(zhí)行中獲取反饋,不斷優(yōu)化智能體的策略和表現(xiàn)。
- 多智能體系統(tǒng)框架(如MiroFlow): MiroFlow作為一個多智能體系統(tǒng)開發(fā)框架,為MiroThinker等模型生成高質量的智能體軌跡數(shù)據(jù),并支持高并發(fā)處理,提供強大的協(xié)同和管理能力。
應用場景
- 科學研究與發(fā)現(xiàn): 輔助科研人員進行深度文獻分析、實驗設計、數(shù)據(jù)解釋等。
- 復雜項目管理與規(guī)劃: 在工程、商業(yè)等領域進行長期、多階段的項目規(guī)劃和執(zhí)行。
- 智能決策支持系統(tǒng): 為企業(yè)或個人提供基于復雜數(shù)據(jù)分析的決策建議。
- 自動化問題解決: 在客服、技術支持、教育等領域實現(xiàn)高度自動化的疑難問題解答。
- Agent開發(fā)與研究: 為AI研究者和開發(fā)者提供一個高性能、開源的Agent模型基礎,用于探索更高級的AI智能體應用。
MiroThinker 的項目地址
- GitHub倉庫:https://github.com/MiroMindAI/MiroThinker
- HuggingFace模型庫:https://huggingface.co/collections/miromind-ai/mirothinker-v01-689301b6d0563321862d44a1
- 在線體驗Demo:https://dr.miromind.ai/
MiroFlow – 多Agent系統(tǒng)開發(fā)框架
MiroFlow是一個強大的多智能體系統(tǒng)開發(fā)框架,旨在簡化復雜、高性能AI智能體的構建、管理和擴展。它專注于為MiroThinker等模型生成高質量的智能體軌跡數(shù)據(jù),并提供對外部工具的無縫集成能力。
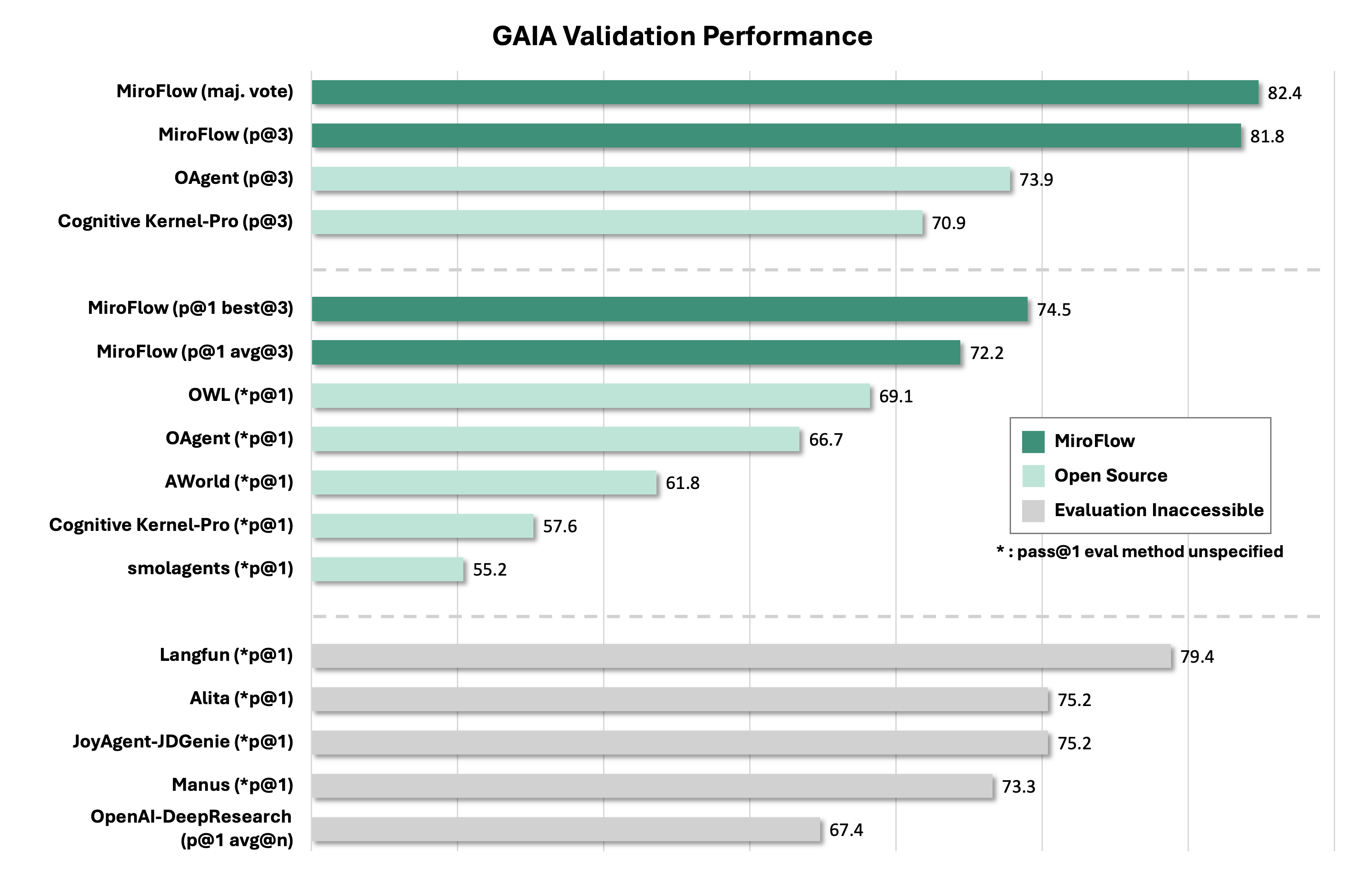
核心功能
- 智能體系統(tǒng)開發(fā)與管理: 提供構建、管理和擴展復雜多智能體系統(tǒng)的能力。
- 高并發(fā)處理: 支持處理高并發(fā)任務,確保系統(tǒng)的高效運行。
- 工具集成框架: 提供靈活的框架,支持與外部工具(如搜索引擎、代碼執(zhí)行環(huán)境)的無縫集成,以擴展AI模型的功能。
- 數(shù)據(jù)生成: 能夠為AI模型(如MiroThinker)生成高質量的智能體軌跡數(shù)據(jù)。
技術原理
MiroFlow作為一個多智能體系統(tǒng)開發(fā)框架,其核心技術原理在于提供一套結構化的機制來協(xié)調和管理多個AI智能體的行為與交互。它通過工具集成框架實現(xiàn)AI智能體與外部環(huán)境的連接與互動,擴展其感知和行動能力。框架設計著重于高并發(fā)處理,這意味著它內(nèi)部可能采用異步通信、任務調度或分布式處理等機制,以有效管理大量并行運行的智能體和其交互。同時,通過生成智能體軌跡數(shù)據(jù),它可能利用這些數(shù)據(jù)進行模型訓練、行為分析或系統(tǒng)優(yōu)化,以提升智能體的決策質量和協(xié)作效率。
應用場景
-
復雜AI系統(tǒng)構建: 適用于需要多個智能體協(xié)同工作以解決復雜問題的場景。
-
大規(guī)模智能體部署: 在需要部署和管理大量AI智能體的應用中,如智能客服集群、自動化交易系統(tǒng)。
-
AI模型訓練與優(yōu)化: 為MiroThinker等AI模型提供高質量的智能體交互數(shù)據(jù),用于模型訓練、微調及性能評估。
-
擴展AI能力: 通過集成外部工具,使AI智能體能夠執(zhí)行更廣泛的任務,例如信息檢索、代碼執(zhí)行、數(shù)據(jù)分析等。
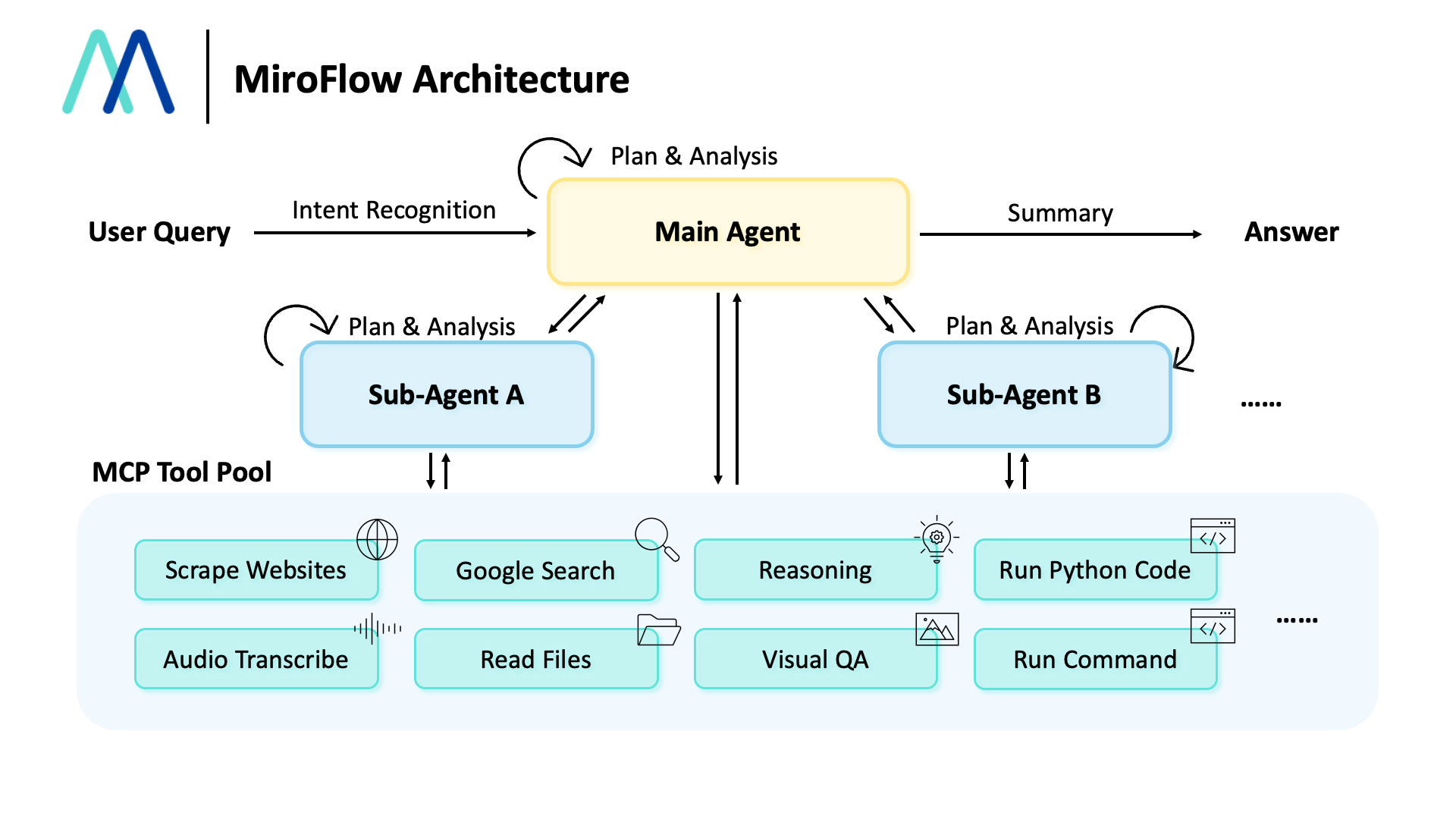
WeKnora – 騰訊開源的文檔理解與語義檢索框架
WeKnora是騰訊開源的一款基于大語言模型(LLM)的文檔理解與語義檢索框架。它專為處理結構復雜、內(nèi)容異構的文檔場景而設計,旨在提供智能問答解決方案,能夠快速從文檔中提取洞察并提供答案。
核心功能
- 多模態(tài)文檔解析: 支持對PDF、Word、圖片等多種格式文檔進行結構化內(nèi)容提取和解析。
- 文檔深度理解: 利用大語言模型對文檔內(nèi)容進行深入理解,捕捉復雜語義。
- 語義檢索: 能夠進行高效的語義檢索,找到與查詢最相關的文檔片段。
- 智能問答: 基于檢索到的信息,提供上下文感知的智能問答。
- 語義視圖構建: 統(tǒng)一構建文檔的語義視圖,便于后續(xù)處理和檢索。
- 模塊化設計: 框架采用模塊化架構,方便擴展和集成。
技術原理
WeKnora的核心技術原理是結合了大語言模型(LLM)和檢索增強生成(RAG)范式。它通過以下步驟實現(xiàn)其功能:
- 多模態(tài)預處理與解析: 對不同格式的文檔進行預處理,包括文本提取、圖像識別(OCR)等,并解析其結構。
- 內(nèi)容嵌入與向量化: 將解析后的文檔內(nèi)容轉換為高維向量表示(嵌入),以便進行語義匹配。
- 知識庫構建: 建立基于向量的知識庫,存儲所有文檔的語義信息。
- 檢索機制: 當用戶提出問題時,利用問題嵌入進行向量相似度搜索,從知識庫中檢索出最相關的文檔片段。
- LLM與RAG: 將檢索到的相關文檔片段作為上下文信息,結合用戶問題一同輸入到大語言模型中,通過RAG范式,引導LLM生成準確、相關的答案。
- 模塊化架構: 整個框架采用模塊化設計,使得各個組件(如解析器、檢索器、生成器)可以獨立開發(fā)、優(yōu)化和替換,提升了系統(tǒng)的靈活性和可維護性。
應用場景
- 企業(yè)知識庫管理: 幫助企業(yè)高效管理和利用內(nèi)部大量的非結構化和半結構化文檔,實現(xiàn)智能問答和知識檢索。
- 智能客服: 應用于客服系統(tǒng),快速從產(chǎn)品手冊、FAQ等文檔中獲取信息,為用戶提供即時準確的回復。
- 法律/金融文檔分析: 輔助分析復雜的法律條文、合同、財報等,快速定位關鍵信息并進行摘要或問答。
- 學術研究: 幫助研究人員快速查閱和理解大量的學術論文和研究報告。
- 教育領域: 用于構建智能學習系統(tǒng),學生可以通過提問快速獲取教材中的知識點。
- 多源異構信息處理: 適用于需要從不同來源、不同格式文檔中整合信息并進行智能處理的場景。
WeKnora的項目地址
- 項目官網(wǎng):https://weknora.weixin.qq.com/
- GitHub倉庫:https://github.com/Tencent/WeKnora
LandPPT – 開源AI PPT生成工具
LandPPT是一個開源的AI演示文稿生成平臺,旨在通過人工智能技術,將文檔內(nèi)容快速、高效地轉換為專業(yè)且高質量的PPT演示文稿,極大地簡化了傳統(tǒng)PPT制作流程。
核心功能
- 文檔內(nèi)容快速轉換: 能夠自動將用戶提供的文檔內(nèi)容轉化為演示文稿。
- 多AI模型支持: 集成并支持OpenAI、Claude、Gemini等多種主流AI模型,提供更靈活的生成能力。
- 模板與樣式選擇: 提供豐富的模板和樣式選項,幫助用戶創(chuàng)建符合需求的演示文稿。
- 智能化圖像處理: 具備智能圖像處理能力,優(yōu)化演示文稿的視覺效果。
技術原理
LandPPT的核心技術基于大語言模型(LLM)。它利用LLM的強大文本理解和生成能力,解析輸入的文檔內(nèi)容,并將其結構化、提煉成演示文稿的關鍵信息。通過集成不同的AI模型(如OpenAI、Claude、Gemini),平臺能夠根據(jù)內(nèi)容生成相應的演示文稿結構、文本內(nèi)容、甚至推薦圖片和排版,實現(xiàn)自動化和智能化的PPT制作。此外,可能還結合了自然語言處理(NLP)、計算機視覺(CV)技術進行文檔解析和圖像優(yōu)化。
應用場景
-
商務演示: 快速制作產(chǎn)品介紹、市場分析、項目報告等商務PPT。
-
學術交流: 將研究論文、學術報告等內(nèi)容快速轉換為演示文稿,用于會議或講座。
-
教育培訓: 教師或培訓師可利用其將教學大綱、課程內(nèi)容等轉換為PPT課件。
-
個人匯報: 適用于個人工作總結、技能展示等快速生成演示文稿。
-
內(nèi)容創(chuàng)作: 幫助內(nèi)容創(chuàng)作者將文章、博客等轉換為視覺化的演示材料。
-
GitHub倉庫:https://github.com/sligter/LandPPT
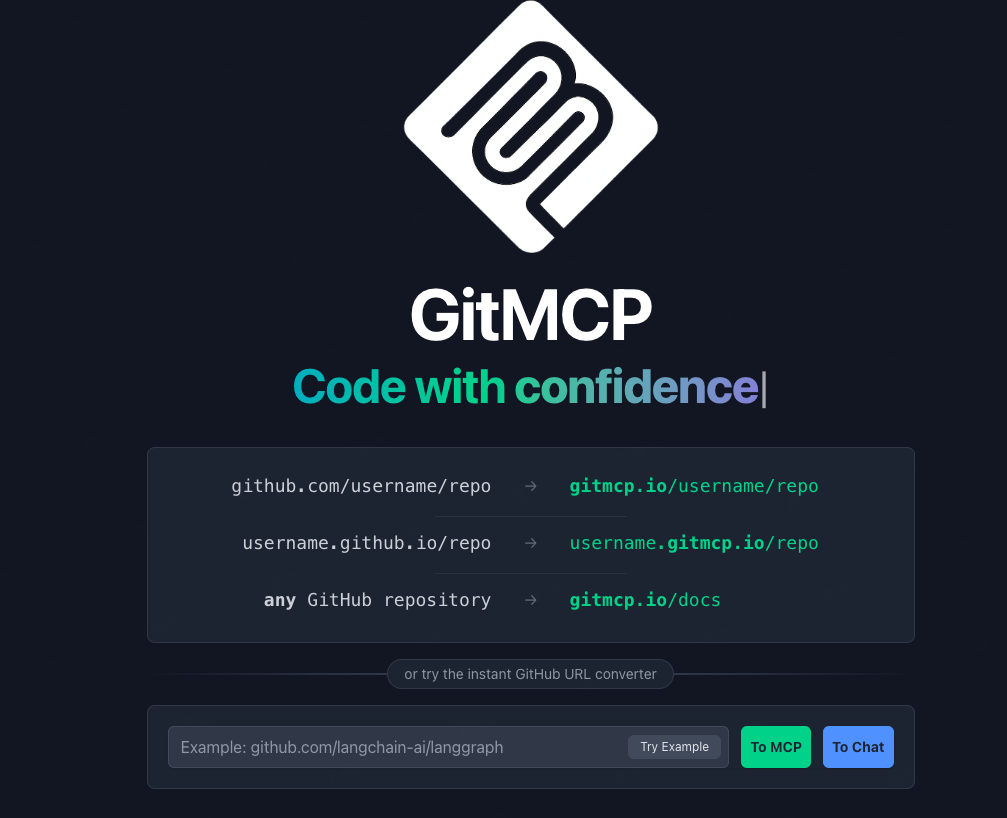
GitMCP
GitMCP 是一個免費、開源的遠程模型上下文協(xié)議(MCP)服務器,旨在將任何 GitHub 項目(包括倉庫和 GitHub Pages)轉換為文檔中心,并為 AI 工具提供即時、準確的項目上下文。它通過消除 AI 模型的“代碼幻覺”問題,使得 AI 能夠訪問最新的文檔和代碼,即使這些信息未包含在其訓練數(shù)據(jù)中。通過簡單地將 GitHub 倉庫 URL 中的 github.com 替換為 gitmcp.io,即可為該倉庫生成一個可供 AI 助手使用的 MCP 服務器。
核心功能
- 上下文提供: 為 AI 工具提供 GitHub 倉庫的實時、準確的文檔和代碼上下文。
- 消除幻覺: 解決 AI 模型在處理新項目或訓練數(shù)據(jù)之外的信息時可能出現(xiàn)的“代碼幻覺”問題。
- 文檔獲取:
fetch_documentation:檢索項目的主要文檔。 - 文檔搜索:
search_documentation:根據(jù)特定查詢在文檔中進行搜索。 - 代碼搜索:
search_code:在實際倉庫代碼中進行搜索。 - URL 內(nèi)容獲取:
fetch_url_content:檢索引用鏈接的內(nèi)容。
技術原理
GitMCP 的核心是實現(xiàn)了模型上下文協(xié)議(Model Context Protocol, MCP)。MCP 是一種標準,允許 AI 工具從外部源請求額外的上下文信息。其工作流程如下:
- 用戶在 AI 工具中將 GitMCP 配置為一個 MCP 服務器。
- 用戶向 AI 提出關于代碼或文檔的問題。
- AI 工具(在用戶批準后)向 GitMCP 發(fā)送請求。
- GitMCP 從相應的 GitHub 倉庫獲取相關信息。
- AI 接收到準確、最新的信息,并提供基于事實的回復。
它通過提供fetch和search等工具接口,使得 AI 能夠按需動態(tài)獲取并理解 GitHub 倉庫的內(nèi)容。
應用場景
- AI 輔助編程: 允許 AI 編程助手(如 Cursor)深度理解任何 GitHub 倉庫的內(nèi)部結構和文檔,從而提供更準確的代碼建議、bug 修復和問題解答。
- 知識庫查詢: AI 模型可以利用 GitMCP 訪問和檢索非其訓練集中的項目文檔,為用戶提供關于開源項目、庫或框架的最新信息。
- 開發(fā)效率提升: 開發(fā)者可以配置 AI 工具與 GitMCP 集成,快速獲取項目上下文,減少手動查閱大量文檔和代碼的時間。
- 教育與學習: AI 導師可以通過 GitMCP 訪問特定 GitHub 項目的詳細信息,幫助學生理解和學習新的技術棧。
GitMCP的項目地址
- 項目官網(wǎng):https://gitmcp.io/
- GitHub倉庫:https://github.com/idosal/git-mcp
NeuralAgent – 開源的桌面AI助手
NeuralAgent是一款開源的桌面AI個人助手,旨在通過自然語言指令自動化執(zhí)行計算機上的多種復雜任務。它作為一個本地AI智能體,能夠直接在用戶的操作系統(tǒng)上運行,像人類一樣與桌面環(huán)境進行交互。
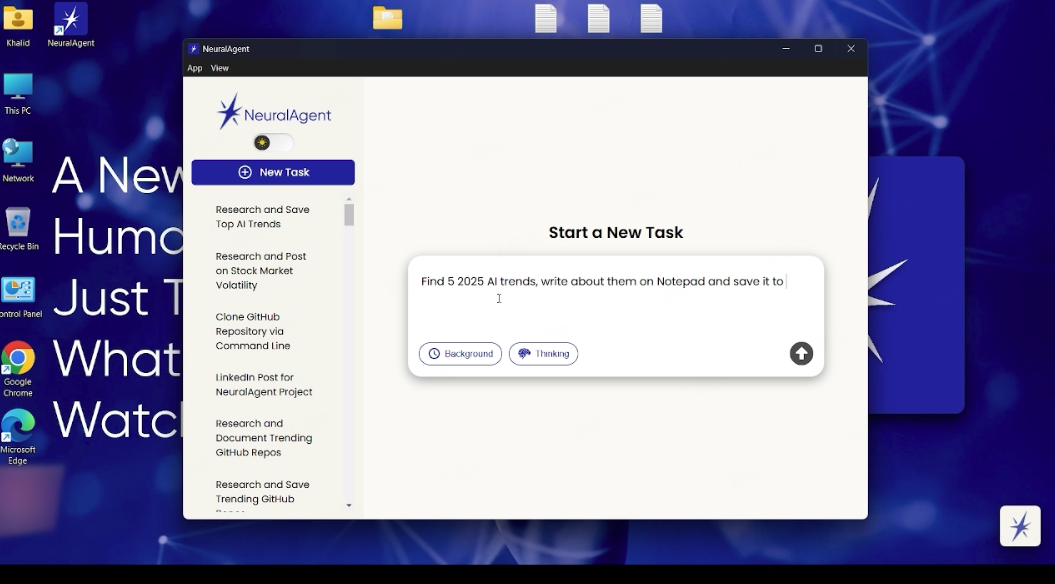
核心功能
- 桌面自動化操作: 模擬鍵盤輸入、鼠標點擊等,實現(xiàn)與桌面應用的無縫交互。
- 瀏覽器任務處理: 自動導航瀏覽器、填寫表單、發(fā)送郵件等。
- 跨應用和工作流自動化: 理解并執(zhí)行跨不同應用程序和工作流程的任務。
- 復雜任務執(zhí)行: 能夠自動化處理需要多步驟和多應用協(xié)作的復雜任務。
技術原理
NeuralAgent的核心技術在于其作為“操作系統(tǒng)級智能體”的能力。它利用先進的AI模型來解析用戶的自然語言指令,并將其轉化為對操作系統(tǒng)和應用程序的底層操作,例如:
- 自然語言處理 (NLP): 理解并解釋用戶的意圖和指令。
- 視覺感知與識別: 識別屏幕上的元素,如同人類用戶一般理解界面布局和內(nèi)容。
- 低級操作模擬: 通過模擬鍵盤/鼠標事件、調用系統(tǒng)API等方式,實現(xiàn)對操作系統(tǒng)和應用程序的精確控制。
- 任務規(guī)劃與執(zhí)行: 根據(jù)指令自動規(guī)劃執(zhí)行路徑,并在實時環(huán)境中完成任務。
- 本地化運行: 作為本地AI代理,直接在桌面環(huán)境運行,提高了數(shù)據(jù)安全性和響應速度。
應用場景
-
日常辦公自動化: 自動填寫表格、整理郵件、數(shù)據(jù)錄入、文檔處理等。
-
重復性任務: 自動化執(zhí)行網(wǎng)頁瀏覽、信息抓取、數(shù)據(jù)搬運等高重復性工作。
-
客戶服務與支持: 輔助處理常見問題、自動回復郵件或消息。
-
個人效率提升: 根據(jù)用戶指令自動管理文件、啟動應用程序、設置提醒等。
-
軟件測試與開發(fā): 自動化執(zhí)行測試用例,模擬用戶操作流程。
-
項目官網(wǎng):https://www.getneuralagent.com/
KittenTTS – KittenML開源的輕量級文本轉語音模型
KittenTTS是由KittenML團隊開發(fā)的一款輕量級開源文本轉語音(TTS)模型。該模型以其極小的體積(通常小于25MB,甚至僅1500萬參數(shù))和強大的CPU優(yōu)化能力為主要特點,使其無需圖形處理器(GPU)即可在低功耗設備上高效運行,旨在提供高質量、真實的語音合成。
核心功能
- 文本轉語音合成: 將輸入的文本內(nèi)容轉換為自然流暢的語音輸出。
- 輕量級部署: 模型文件體積小,易于集成到資源受限的設備或應用中。
- CPU優(yōu)化運行: 專為中央處理器(CPU)進行了深度優(yōu)化,無需依賴高性能GPU,降低了硬件成本和功耗。
- 高質量語音: 能夠生成清晰、逼真且具有表現(xiàn)力的語音。
- 多種預設聲音: 提供多種高質量的預設語音選擇。
技術原理
KittenTTS基于先進的深度學習技術實現(xiàn)文本到語音的轉換。其核心技術原理在于采用高效、緊湊的模型架構設計,顯著減少了模型的參數(shù)量(如15M參數(shù)),從而實現(xiàn)了超小的模型體積。同時,通過專門的算法和優(yōu)化策略,使得模型能夠在僅使用CPU的情況下,依然保持高效的推理速度和高質量的語音輸出,尤其適用于對計算資源和功耗有嚴格限制的邊緣計算和嵌入式系統(tǒng)。
應用場景
-
低功耗設備: 適用于智能音箱、物聯(lián)網(wǎng)設備、智能家電等對能耗和體積有嚴格要求的硬件平臺。
-
邊緣計算: 在不需要云端算力支持的邊緣設備上實現(xiàn)本地語音合成,提升響應速度和數(shù)據(jù)隱私性。
-
移動應用: 集成到手機應用或嵌入式系統(tǒng)中,為用戶提供語音播報、導航等功能。
-
教育領域: 可應用于編程教育平臺,為青少年提供交互式語音反饋。
-
個人及商業(yè)應用: 凡是需要高質量、低成本語音合成的場景,如內(nèi)容創(chuàng)作、有聲讀物、智能客服等。
3. AI-Compass
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態(tài),通過六大核心模塊的系統(tǒng)化組織,為不同層次的學習者和開發(fā)者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
?? 核心模塊架構:
- ?? 基礎知識模塊:涵蓋AI導航工具、Prompt工程、LLM測評、語言模型、多模態(tài)模型等核心理論基礎
- ?? 技術框架模塊:包含Embedding模型、訓練框架、推理部署、評估框架、RLHF等技術棧
- ?? 應用實踐模塊:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿應用架構
- ??? 產(chǎn)品與工具模塊:整合AI應用、AI產(chǎn)品、競賽資源等實戰(zhàn)內(nèi)容
- ?? 企業(yè)開源模塊:匯集華為、騰訊、阿里、百度飛槳、Datawhale等企業(yè)級開源資源
- ?? 社區(qū)與平臺模塊:提供學習平臺、技術文章、社區(qū)論壇等生態(tài)資源
?? 適用人群:
- AI初學者:提供系統(tǒng)化的學習路徑和基礎知識體系,快速建立AI技術認知框架
- 技術開發(fā)者:深度技術資源和工程實踐指南,提升AI項目開發(fā)和部署能力
- 產(chǎn)品經(jīng)理:AI產(chǎn)品設計方法論和市場案例分析,掌握AI產(chǎn)品化策略
- 研究人員:前沿技術趨勢和學術資源,拓展AI應用研究邊界
- 企業(yè)團隊:完整的AI技術選型和落地方案,加速企業(yè)AI轉型進程
- 求職者:全面的面試準備資源和項目實戰(zhàn)經(jīng)驗,提升AI領域競爭力

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號