
AI Compass前沿速覽:gemini-StorybookAI故事、gpt-oss推理模型開源、Qwen-Image文生圖、RedOne社交大模型、小米MiDashengLM
AI Compass前沿速覽:gemini-StorybookAI故事、gpt-oss推理模型開源、Qwen-Image文生圖、RedOne社交大模型、小米MiDashengLM
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
1.每周大新聞
谷歌Gemini上線AI故事書功能,為兒童提供圖文并茂的閱讀體驗
2025年8月6日,谷歌為AI聊天機器人Gemini推出“Storybook”功能,用戶輸入簡短描述就能自動生成10頁圖文書籍,有文字敘述、語音朗讀和配圖,還支持多種藝術風格選擇和上傳自定義圖片,全球范圍上線,兼容桌面和移動設備,覆蓋多語言環境。

核心功能
- 內容生成:根據簡短描述自動生成圖文故事書。
- 定制體驗:可選擇不同藝術風格,支持上傳自定義圖片生成對應故事。
- 語音朗讀:通過Gemini語音朗讀故事內容。
- 分享導出:提供分享、導出及打印選項。
技術原理
借助Gemini的自然語言處理能力理解用戶輸入的簡短描述,生成文字內容;利用圖像生成技術依據文字內容和用戶選擇的藝術風格繪制配圖;通過語音合成技術實現語音朗讀功能。
應用場景
- 兒童閱讀:為兒童提供個性化、圖文并茂的閱讀材料。
- 親子互動:家長和孩子一起創作故事書,增進親子關系。
- 教育教學:教師可利用該功能制作教學材料,輔助教學。
騰訊混元 0.5B、1.8B、4B、7B模型發布
騰訊混元發布四款開源小尺寸模型,參數分別為 0.5B、1.8B、4B、7B,消費級顯卡即可運行,適用于多種低功耗場景,還支持垂直領域低成本微調。
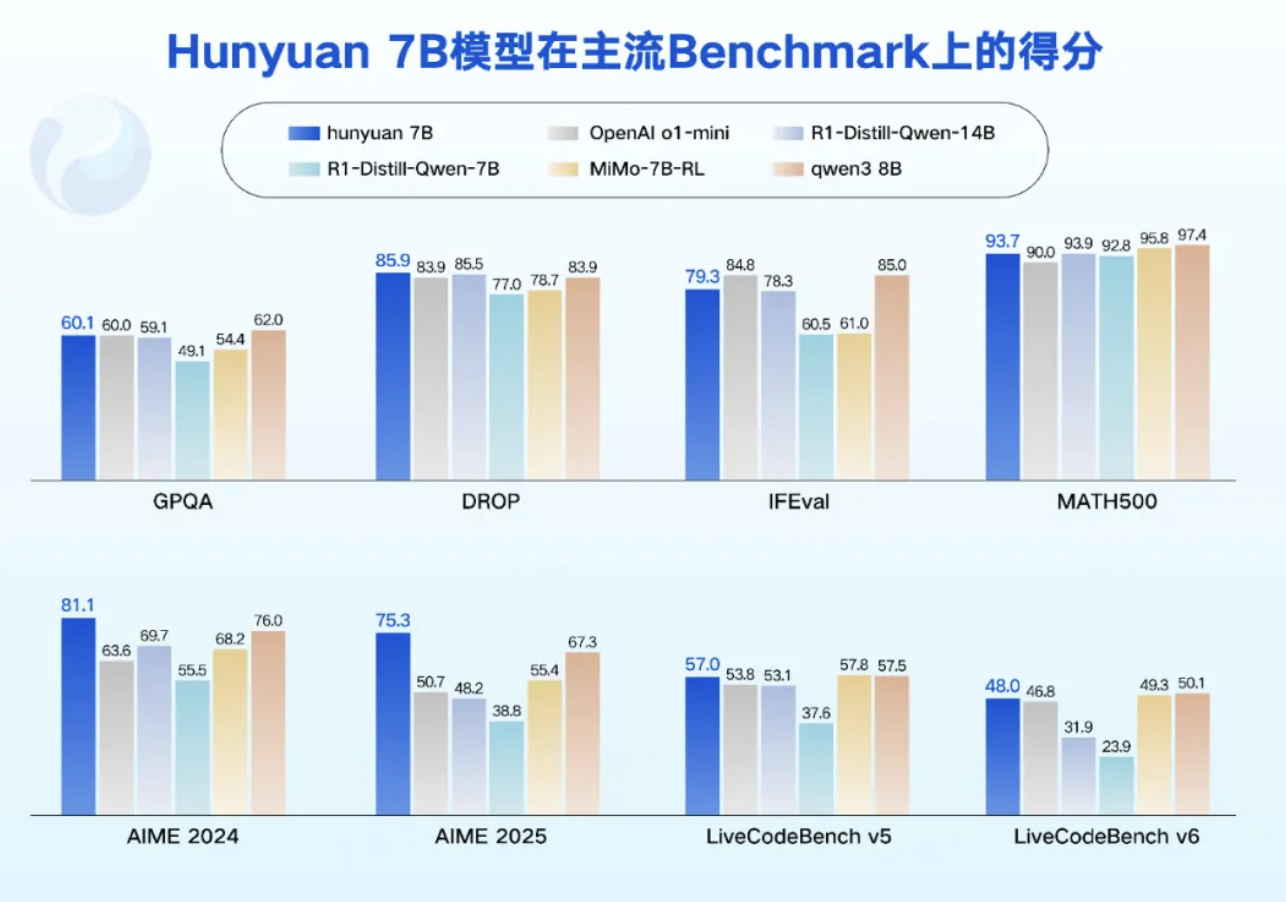
模型特點
- 推理模式靈活:屬于融合推理模型,用戶可依場景選 “快思考”(簡潔高效輸出)或 “慢思考”(處理復雜問題)模式。
- 性能表現出色:在語言理解、數學、推理等領域對標業界同尺寸模型,多個公開測試集得分領先。
- 具備特色能力:擁有 agent 和長文能力,原生長上下文窗口達 256k,能處理超長內容,勝任多種復雜任務。
- 部署簡便開放:只需單卡部署,部分 PC、手機等設備可直接接入,主流推理框架和多種量化格式均支持。
應用情況
已在騰訊多業務中應用,如騰訊會議 AI 小助手、微信讀書 AI 問書助手利用超長上下文能力理解處理長內容;騰訊手機管家提升垃圾短信識別準確率;騰訊智能座艙助手解決車載環境痛點等。
開源生態
模型在 Github 和 Huggingface 等開源社區上線,Arm、高通等多個消費級終端芯片平臺支持部署。騰訊混元持續推進開源,此前已開源多款模型,覆蓋多模態,未來還將推出更多模型,共建開源生態。
DragonV2.1 – 微軟推出的零樣本文本到語音模型
微軟推出最新零樣本文本到語音模型DragonV2.1,基于Transformer架構,支持多語言和零樣本語音克隆,在發音等方面顯著改進,與DragonV1相比單詞錯誤率平均降低12.8%,集成水印技術。
主要功能
支持100多種語言環境,可進行情感和口音適應、零樣本語音克隆,生成快速,支持發音和口音控制及自定義詞典,添加水印防濫用。
技術原理
基于Transformer架構,有多頭注意力機制,支持SSML。
應用場景
用于視頻創作、智能客服、教育、智能助手、企業品牌推廣等。
Jenova – 專為MCP打造的首款AI Agent
Jenova是先進的人工智能平臺,集成GPT - 4o、Claude和Gemini等多種AI模型,主要提供搜索、文件處理、圖像識別、語音轉文字等服務。
發展情況
資料未提及發展情況相關內容。
產品特點
能理解復雜查詢意圖,實時聯網獲取最新信息;支持多種文件格式的讀取分析和關鍵信息提取;支持網絡、YouTube、Reddit等多種搜索方式;具備圖像理解、語音轉文字功能;強調用戶隱私,不使用用戶數據訓練。
市場定位
面向學生、研究人員、企業和個人用戶,應用于文獻整理、資料收集、市場調研、報告生成、信息整理、圖像分析等場景。
2.每周項目推薦
gpt-oss – OpenAI開源的推理模型系列
GPT-OSS是由OpenAI推出的首個開源大語言模型系列,包含gpt-oss-120b和gpt-oss-20b兩個版本。這些模型采用開放權重(open-weight)形式,并遵循Apache 2.0許可協議發布,旨在以低成本提供高性能和強大的推理能力,支持本地部署和自定義微調。其發布代表了OpenAI在開源模型領域邁出的重要一步,以促進AI研究、創新和更透明的AI發展。
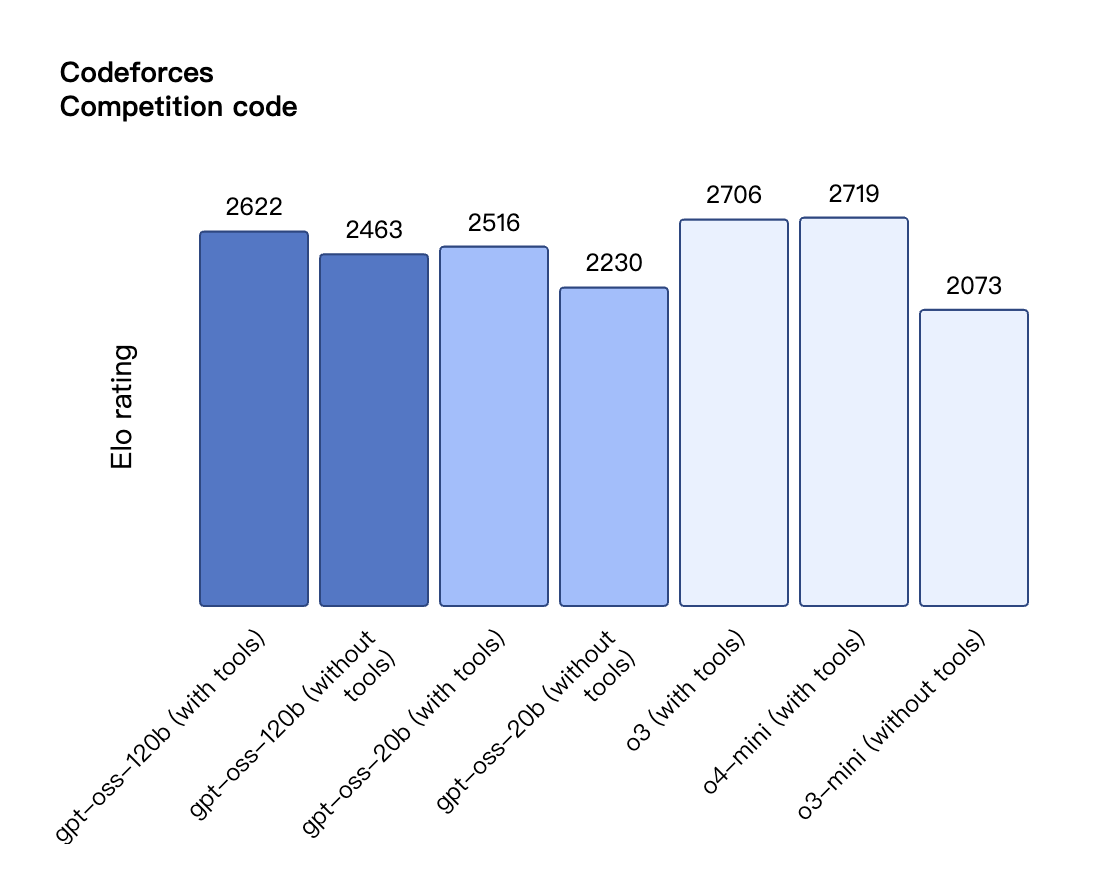
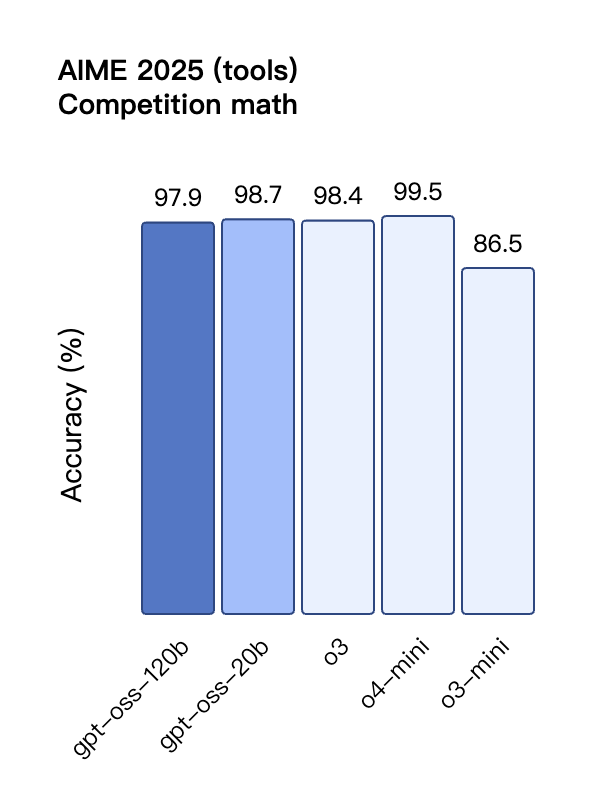
核心功能
GPT-OSS模型具備卓越的推理能力、工具使用能力和指令遵循能力。它們采用思維鏈(Chain-of-Thought, CoT)推理方法,能夠分步驟解答復雜問題,并支持瀏覽網頁、調用云端模型、執行代碼以及作為AI代理進行軟件導航等高級功能。這些模型是文本專用型,但針對消費級硬件進行了優化,以實現高效部署和低延遲推理。
技術原理
GPT-OSS模型是基于GPT-2和GPT-3架構的自回歸MoE(Mixture-of-Experts)Transformer模型。gpt-oss-120b包含36層(116.8B總參數),gpt-oss-20b包含24層(20.9B總參數)。模型在每個注意力塊和MoE塊之前應用均方根歸一化(RMS Norm),并采用Pre-LN(Layer Normalization)放置。訓練結合了強化學習和OpenAI內部先進技術,并進行了全面的安全訓練,包括預訓練階段的有害數據過濾(如CBRN相關),以及通過審慎對齊和指令層級機制來拒絕不安全提示和防御提示注入。
應用場景
GPT-OSS模型適用于加速前沿AI研究、促進AI技術創新以及實現更安全透明的AI開發。由于其支持本地部署和在消費級硬件上運行,開發者和企業可以獲得對延遲、成本和隱私的完全控制。這使得GPT-OSS非常適合需要高性能推理、精細化控制和私有化部署的各類場景,例如:開發定制化AI應用、模型微調、教育研究、探索AI代理能力以及需要避免API限制的場景。
gpt-oss的項目地址
- 項目官網:https://openai.com/zh-Hans-CN/index/introducing-gpt-oss/
- GitHub倉庫:https://github.com/openai/gpt-oss
- HuggingFace模型庫:https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4
- 在線體驗Demo:https://gpt-oss.com/
Qwen-Image – 阿里通義千問開源的文生圖模型
簡介
通義千問視覺基礎模型(Qwen-Image)是由阿里云QwenLM團隊開發的一款20億參數的MMDiT(Multi-Modal Diffusion Transformer)圖像基礎模型。該模型在復雜的文本渲染和精準的圖像編輯方面取得了顯著進展,旨在提供高質量的圖文生成與編輯能力。

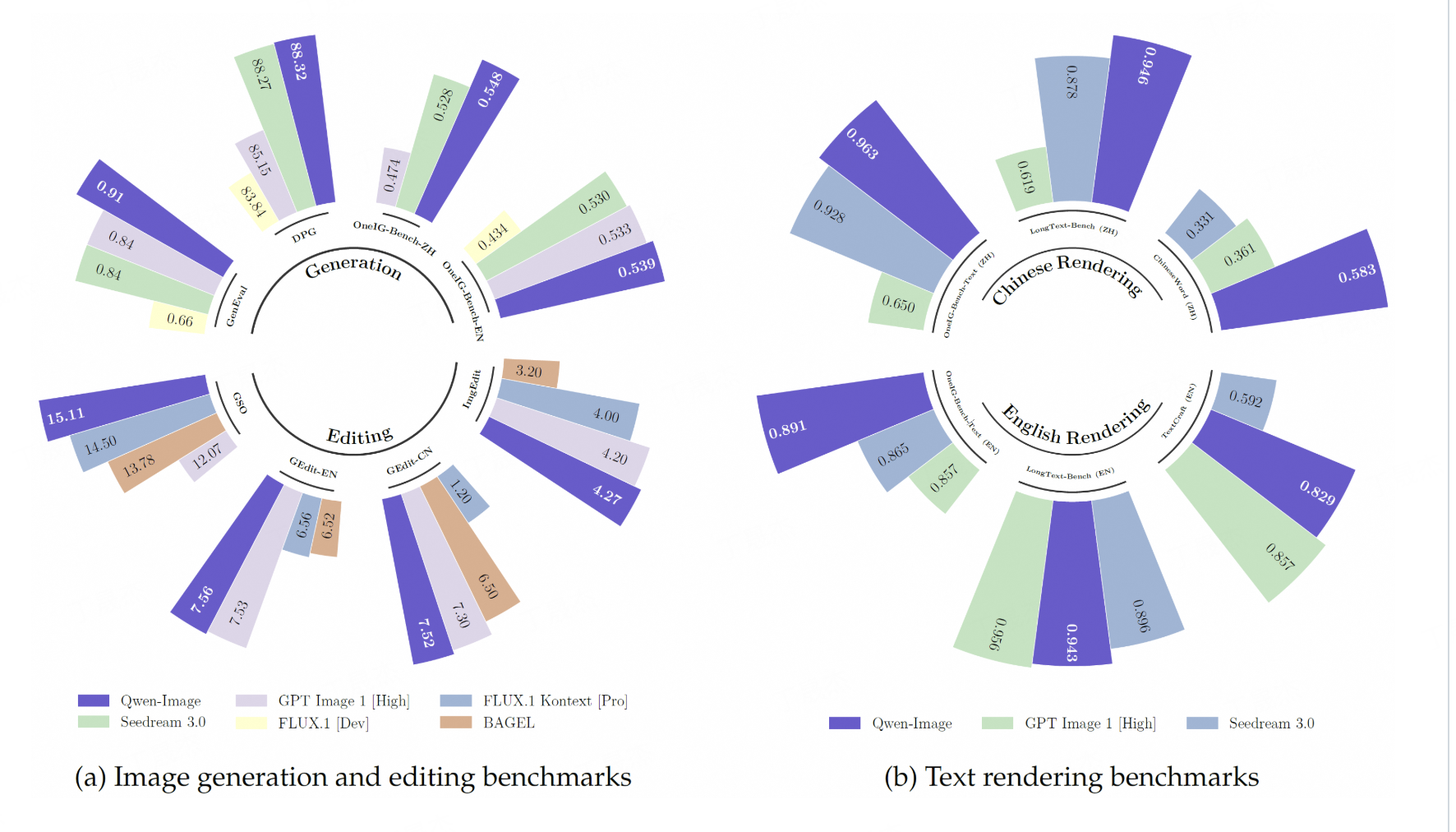
核心功能
- 高保真文本渲染: 能夠在生成的圖像中實現高精度的文本呈現,無論是英文字母還是中文字符,都能保持排版細節、布局一致性和上下文和諧性,實現文本與圖像的無縫融合。
- 精準圖像編輯: 提供強大的圖像編輯能力,包括但不限于圖像生成、內容估計、新視角合成和超分辨率等。
- 復雜場景生成: 支持根據復雜的文本描述生成視覺上連貫且高質量的圖像。
- 跨語言文本支持: 能夠處理并生成包含多種語言文本的圖像。
技術原理
Qwen-Image是一個基于MMDiT架構的20億參數基礎模型。MMDiT(Multi-Modal Diffusion Transformer)結合了擴散模型(Diffusion Model)的圖像生成能力和Transformer架構處理序列數據的優勢。其核心原理可能涉及:
- 多模態融合: 有效地將文本提示信息與視覺特征相結合,指導圖像生成和編輯過程。
- 擴散模型: 逐步去噪生成圖像,從而實現高保真和細節豐富的輸出。
- Transformer結構: 用于捕捉長距離依賴關系和處理復雜的語義信息,尤其在文本理解和圖像內容布局方面發揮關鍵作用。
- 參數量與訓練: 20億參數表明模型規模龐大,通過大規模數據集訓練,賦予其強大的泛化能力和對圖像復雜性的理解。
應用場景
- 創意內容生成: 廣泛應用于廣告、設計、媒體等領域,用于快速生成包含定制文本和視覺效果的圖片。
- 智能圖像編輯: 輔助專業設計師或普通用戶進行圖像的精細化修改、內容添加或修復。
- 多語言本地化: 幫助企業和創作者生成帶有不同語言文本的圖像,以適應全球市場需求。
- 自動化設計工具: 集成到自動化設計平臺中,實現文本到圖像的智能轉換,提高工作效率。
- 虛擬現實與游戲: 用于快速生成場景、道具或角色紋理,包含特定文字元素。
Qwen-Image的項目地址
- GitHub倉庫:https://github.com/QwenLM/Qwen-Image
- HuggingFace模型庫:https://huggingface.co/Qwen/Qwen-Image
- 技術論文:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf
- 在線體驗Demo:https://huggingface.co/spaces/Qwen/Qwen-Image
AudioGen-Omni – 快手推出的多模態音頻生成框架
簡介
AudioGen-Omni是快手推出的一款多模態音頻生成框架,能夠基于視頻、文本等多種輸入,高效生成高質量的音頻、語音和歌曲。它旨在提供一個統一的解決方案,以滿足不同形式的音頻內容創作需求。
核心功能
- 多模態輸入支持: 能夠接受視頻和文本作為輸入,生成相應的音頻內容。
- 高保真音頻生成: 可生成高質量的背景音樂、語音、環境音效以及完整歌曲。
- 統一生成能力: 框架實現了對不同類型音頻(如語音、音樂、音效)的統一生成,簡化了工作流程。
技術原理
AudioGen-Omni基于多模態擴散Transformer (MMDit) 架構,通過聯合訓練大規模的視頻-文本-音頻語料庫進行學習。其核心技術包括統一的歌詞-文本編碼器,以及用于相位對齊的先進機制(如AdaLN),確保生成音頻的連貫性和質量。這種架構使其能夠理解復雜的跨模態信息,并生成與輸入高度相關的音頻。
應用場景
- 短視頻及直播內容創作: 為視頻自動配樂、生成旁白或特效聲音,提升內容豐富度。
- 音樂制作與歌曲創作: 從文本歌詞或意圖描述生成歌曲旋律、伴奏及人聲。
- 智能語音助手與虛擬人: 生成自然流暢的語音對話,增強人機交互體驗。
- 多媒體內容編輯: 作為AI輔助工具,幫助用戶快速生成所需的音頻素材。
AudioGen-Omni的項目地址
Presenton – 開源AI演示文稿生成器
簡介
Presenton是一個開源的AI演示文稿生成器和API,旨在提供完全由用戶控制的AI演示工作流程。它允許用戶在本地設備上運行AI模型,生成高質量的演示文稿,并支持定制化體驗和數據隱私保護。Presenton被定位為Gamma等商業AI演示工具的開源替代方案。
核心功能
- AI驅動的演示文稿生成: 通過簡單的文本提示或用戶內容(文件、數據、網頁鏈接等)即時生成專業演示文稿。
- 本地運行能力: 應用程序可在用戶本地設備上運行,確保數據隱私和更高的控制度。
- 模型選擇與定制: 支持選擇不同的語言模型(如OpenAI、Gemini、Ollama等)和圖像生成服務(如DALL-E 3、Pexels),允許用戶根據需求進行定制。
- API集成: 提供API接口,方便開發者將其功能集成到其他應用中。
- 內容轉換: 能夠將現有文檔轉化為演示文稿。
- 模板與編輯: 提供模板選擇,并支持輕松編輯和協作。
技術原理
Presenton基于AI技術,利用大型語言模型(LLM)進行內容理解和文本生成,結合圖像生成模型創建視覺元素。其核心原理包括:
- 自然語言處理 (NLP):接收用戶輸入的文本提示,通過NLP技術理解意圖和內容需求。
- 生成式AI模型:集成多種生成式AI模型,如OpenAI(GPT系列)、Google Gemini以及基于Ollama的本地大型語言模型(如Llama3),用于生成演示文稿的文本內容、大綱和結構。
- 多模態生成: 結合文本生成與圖像生成技術(如DALL-E 3或通過Pexels API獲取圖像),實現演示文稿中文字和視覺內容的協同創作。
- 本地部署與容器化: 支持通過Docker容器化技術在用戶本地環境部署和運行,實現AI模型的私有化部署和離線使用。這允許用戶完全控制數據流,無需將敏感信息發送到云端服務。
- API接口: 提供標準的RESTful API接口,允許外部應用程序通過編程方式調用Presenton的生成功能。
應用場景
- 快速創建專業演示: 個人和企業用戶可快速將想法、研究報告、項目計劃等轉化為具有視覺吸引力的演示文稿,提高效率。
- 教育與培訓: 教師和培訓師可以利用AI快速生成課程幻燈片或培訓材料,節省準備時間。
- 數據隱私敏感型組織: 對于需要嚴格控制數據流的組織(如政府機構、金融機構等),本地部署能力使其成為理想的演示文稿生成解決方案。
- 開發者工具: 作為開放API,可集成到各種內容創作平臺、自動化工作流或定制化應用中,賦能更多AI驅動的功能。
- 內容創作者: 幫助博主、營銷人員和社交媒體管理者快速生成視覺內容和演示材料。
Presenton的官網地址
- 官網地址:https://presenton.ai/
- Github倉庫:https://github.com/presenton/presenton
Wuhr AI Ops – AI運維管理平臺,提供一站式運維解決方案
簡介
Wuhr AI Ops 是一款現代化的人工智能驅動智能運維管理平臺,旨在通過集成AI技術,簡化復雜的運維任務。它提供一站式運維解決方案,能夠賦能IT運維團隊,提升操作效率和管理水平。
核心功能
- 多模態AI助手: 集成AI助手,支持自然語言交互,能夠理解并執行運維命令。
- 跨系統命令切換: 能夠一鍵在K8s集群和Linux系統命令之間進行切換,簡化操作流程。
- 實時監控與日志分析: 提供實時的系統監控和深入的日志分析能力,幫助快速發現和診斷問題。
- CI/CD管理: 支持持續集成/持續部署(CI/CD)流程管理,促進開發與運維的協同。
- 用戶權限管理: 提供精細的用戶權限控制,確保平臺操作的安全性和合規性。
技術原理
Wuhr AI Ops 的核心技術原理是利用人工智能,特別是多模態AI和自然語言處理(NLP)技術,實現運維工作的智能化和自動化。它通過AI模型對運維數據(如日志、監控指標、用戶指令)進行深度學習和分析,從而實現智能決策、故障預測、根因分析以及自然語言交互式操作。平臺集成了智能決策引擎和自動化編排能力,將人工經驗轉化為可執行的自動化流程,提高運維效率和系統穩定性。
應用場景
- 大型企業IT運維: 適用于需要管理復雜IT基礎設施,包括混合云、多云環境的大型企業的日常運維。
- 云計算環境管理: 有效管理Kubernetes集群和Linux服務器,實現云原生應用的智能運維。
- 開發運維(DevOps)團隊: 幫助DevOps團隊實現CI/CD流程的自動化和智能化,加速軟件交付。
- 數據中心自動化: 在數據中心環境中,通過AI驅動的自動化,減少人工干預,提升運維響應速度和效率。
- AIOps實踐: 作為實施AIOps戰略的關鍵工具,將AI引入運維流程,實現預測性維護和智能故障恢復。
Wuhr AI Ops的項目地址
ScreenCoder – 開源的智能UI截圖生成前端代碼工具
簡介
ScreenCoder是一個開源的智能UI截圖轉代碼系統,旨在將任何UI設計截圖或設計稿快速轉換為整潔、可編輯的HTML/CSS前端代碼。它通過先進的AI處理框架,實現從視覺界面到可生產代碼的自動化生成,顯著提升前端開發效率。
核心功能
- UI截圖轉代碼: 將用戶界面截圖或設計稿一鍵轉換為高質量、可編輯的HTML/CSS代碼。
- 多格式支持: 支持處理各種設計截圖和UI原型圖。
- 代碼整潔度與可編輯性: 生成的代碼結構清晰,易于開發者后續修改和定制。
- 自動化前端生成: 旨在加速前端開發流程,減少手動編碼工作。
- 模塊化多智能體架構: 采用模塊化設計,結合多智能體協同工作,提升轉換的準確性和靈活性。
技術原理
ScreenCoder的核心技術基于模塊化多智能體架構(Modular Multimodal Agents),這使得系統能夠對輸入的UI截圖進行多維度AI處理。其流程通常包括:
- 視覺解析(Visual Parsing): 系統首先對輸入的UI截圖進行深度視覺分析,識別界面中的UI元素(如按鈕、文本框、圖片、布局結構等)及其層級關系和樣式屬性。這可能涉及到計算機視覺(Computer Vision)技術,例如目標檢測(Object Detection)、圖像分割(Image Segmentation)和布局分析(Layout Analysis)。
- 元素識別與歸類: 利用深度學習模型(Deep Learning Models)識別出具體的UI組件,并將其映射到對應的HTML語義標簽和CSS樣式屬性。
- 代碼生成(Code Generation): 基于識別出的UI元素及其布局,系統通過一個或多個生成式AI模型(Generative AI Models),如大型語言模型(LLM)或專門訓練的代碼生成模型(Code Generation Models),將視覺信息轉換為結構化的HTML和CSS代碼。模型會學習UI設計與代碼之間的對應關系,確保生成的代碼語義準確且符合前端開發規范。
- 優化與后處理: 生成的初步代碼可能會經過優化步驟,例如代碼格式化、冗余樣式剔除、響應式布局適應性調整等,以確保輸出的代碼是“干凈、可編輯”且“生產就緒”的。
- 模塊化設計: 不同的智能體可能負責不同的任務,例如一個智能體負責視覺解析,另一個智能體負責代碼生成,還有智能體負責代碼優化,通過協同合作完成整個轉換過程。
應用場景
- 快速原型開發: 設計師或產品經理可以快速將設計稿轉換為可交互的原型,進行早期驗證。
- 前端開發提效: 大幅減少前端工程師從設計圖手動編寫HTML/CSS代碼的工作量,提高開發效率。
- 非技術人員建站: 使得沒有編程經驗的用戶也能通過上傳UI截圖快速生成網頁基礎結構。
- 教育與學習: 作為輔助工具,幫助初學者理解UI設計與前端代碼之間的對應關系。
- 設計迭代: 支持快速迭代設計,每次修改設計稿后能迅速更新對應代碼,加速產品開發周期。
ScreenCoder的官網地址
- GitHub倉庫:https://github.com/leigest519/ScreenCoder
- arXiv技術論文:https://arxiv.org/pdf/2507.22827
- 在線體驗Demo:https://huggingface.co/spaces/Jimmyzheng-10/ScreenCoder
MiDashengLM – 小米開源的高效聲音理解大模型
簡介
MiDaShengLM-7B是小米研究(Xiaomi Research)開源的多模態語音AI模型,參數規模為70億,專注于音頻理解和推理。該模型旨在通過整合先進的音頻編碼器和大型語言模型,實現對語音、環境聲音和音樂元素的全面理解。它代表了小米在語音AI領域的重要進展,并已面向全球社區開放。
核心功能
- 通用音頻理解與推理: 能夠綜合理解和推理各種音頻內容,包括人類語音、環境聲音(如硬幣掉落、水滴聲)和音樂元素。
- 跨模態融合: 有效結合音頻輸入與文本提示,生成相關的文本響應,支持音頻到文本的理解。
- 高效推理: 相較于同類模型(如Qwen2.5-Omni-7B),展現出卓越的推理效率和更快的響應時間,即使在處理較長音頻輸入時也能保持性能。
- 情緒與音樂理解: 具備理解說話者情緒和音樂的能力,超越了傳統語音識別的范疇。
技術原理
MiDaShengLM-7B的核心技術原理是其獨特的集成架構:
- Dasheng音頻編碼器: 采用了小米自研的Dasheng開源音頻編碼器,該編碼器以其在通用音頻理解方面的先進性能而聞名。
- Qwen2.5-Omni-7B Thinker解碼器: 與阿里巴巴的Qwen2.5-Omni-7B Thinker解碼器進行集成,實現強大的語言理解和生成能力。
- 基于字幕的對齊策略(Caption-based Alignment Strategy): 模型采用獨特的基于字幕的對齊策略,利用通用音頻字幕來捕捉全面的音頻表示。這種方法不同于傳統的ASR驅動方法,能更有效地整合語音、環境聲音和音樂,形成統一的文本表示。
- 端到端自主信息檢索與多步推理: 結合了類似AI Agent的能力,使其能夠在復雜的音頻環境中進行主動感知、決策和行動,進行深度的信息檢索和多步推理。
應用場景
- 智能家居: 作為智能設備的核心語音交互模塊,實現更自然、智能的語音控制和環境感知。
- 汽車領域: 在智能駕駛艙中提供高級語音助手功能,包括語音命令識別、環境噪音過濾和情緒識別。
- 通用AI應用: 廣泛應用于需要音頻理解和跨模態交互的各種AI產品和框架中,如智能助手、內容創作、安防監控等。
- 音頻內容分析: 對播客、音樂、環境錄音等進行深度分析,提取關鍵信息和情感。
- 殘障輔助技術: 通過更準確地理解和響應音頻輸入,提升相關輔助設備的性能。
MiDashengLM的項目地址
- GitHub倉庫:https://github.com/xiaomi-research/dasheng-lm
- HuggingFace模型庫:https://huggingface.co/mispeech/midashenglm-7b
- 技術論文:https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- 在線體驗Demo:https://huggingface.co/spaces/mispeech/MiDashengLM-7B
Animated Drawings – Meta AI推出的AI手繪作品轉動畫工具
簡介
Animated Drawings 是 Meta AI (Facebook Research) 推出的一個開源項目和在線工具,旨在利用人工智能技術,將靜態的手繪人物畫作自動轉化為生動的動畫。該項目提供了一套完整的工具和算法,使用戶能夠輕松地將自己的創意草圖賦予生命。
核心功能
- 手繪人物動畫化: 將用戶上傳的單個人物手繪草圖轉化為動態動畫。
- 角色檢測與分割: 自動識別并精確分割畫作中的人物角色。
- 動畫骨骼生成: 為識別出的角色自動生成骨骼結構,支持多種預設動作或自定義動作。
- 簡便易用: 用戶只需上傳符合特定規范(如單一角色、肢體不重疊)的畫作即可進行操作,提供在線演示畫布。
技術原理
Animated Drawings 的核心技術原理是基于計算機視覺和AI算法對圖像進行處理和理解。
- 圖像識別與分割: 利用深度學習模型對上傳的畫作進行人物檢測和語義分割,精確提取出角色的輪廓。
- 姿態估計與骨骼綁定: 在分割出的角色上,通過姿態估計技術識別關鍵關節,并構建虛擬骨骼(Rigging),將二維圖像與三維動畫骨骼系統關聯起來。
- 形變與運動控制: 結合As-Rigid-As-Possible (ARAP) 等幾何形變算法,使得骨骼的運動能夠自然地驅動畫作相應部位的形變,從而實現流暢的人物動畫效果。
應用場景
- 兒童教育與娛樂: 激發兒童的繪畫興趣,將他們的涂鴉轉化為互動動畫,提升學習樂趣。
- 創意內容創作: 為藝術家、動畫愛好者和設計師提供快速制作動畫原型的工具,簡化動畫制作流程。
- 個人娛樂與分享: 用戶可以輕松制作個性化的動畫表情包、短視頻,并在社交媒體上分享。
- 研究與開發: 作為開源項目,為AI、圖形學和人機交互領域的研究人員提供基礎平臺,進行算法優化和新功能開發。
Animated Drawings的項目地址
- 項目官網:https://sketch.metademolab.com/canvas
- GitHub倉庫:https://github.com/facebookresearch/AnimatedDrawings
RedOne – 小紅書推出的社交大模型
簡介
根據提供的鏈接,ai-bot.cn 是一個創新型人工智能平臺,提供一系列AI驅動的工具和解決方案,旨在提升生產力、優化流程并提供數據分析。同時,arXiv.org 是一個開放獲取的學術論文預印本庫,涵蓋物理學、數學、計算機科學等多個領域,是研究人員分享最新研究成果的重要平臺,盡管其內容未經同行評審。
核心功能
- AI工具與服務提供: ai-bot.cn 提供AI驅動的生產力工具、流程自動化工具和數據分析服務,以及用于電子商務、客戶支持的AI代理(如WhatsApp、Facebook和Instagram機器人)。
- 學術研究成果共享: arXiv.org 作為一個免費的學術文獻分發服務和開放獲取檔案庫,其核心功能是提供物理學、數學、計算機科學等領域約240萬篇學術文章的存儲和訪問,促進前沿研究的快速傳播。
技術原理
ai-bot.cn 提供的AI服務很可能基于機器學習(ML) 和自然語言處理(NLP) 等技術,通過訓練模型實現自動化、數據分析和智能交互。其中可能涉及神經網絡結構設計、激活函數選擇、梯度優化技術以及損失函數構建等機器學習核心原理。針對特定應用,如聊天機器人,可能運用到對話管理系統和意圖識別等技術。雖然具體論文內容未直接獲取,但arXiv上相關的AI研究廣泛涉及梯度下降等優化算法,這是深度學習訓練的基礎。
應用場景
-
商業運營與效率提升: 企業可以通過 ai-bot.cn 的AI工具集成AI,以提高運營效率,如自動化銷售、優化客戶服務(電商AI客服機器人),進行數據驅動的決策分析。
-
個人項目與創新: 個人用戶可以利用 ai-bot.cn 的AI技術實現其項目目標。
-
學術研究與教育: arXiv.org 作為學術資料庫,為物理學、數學、計算機科學(包括機器學習、機器人技術、多智能體系統)、定量生物學、統計學等領域的學者和學生提供最新的研究論文,支持學術交流、前沿探索和教育學習。
-
arXiv技術論文:https://www.arxiv.org/pdf/2507.10605
Skywork MindLink – 昆侖萬維開源的推理大模型
簡介
MindLink是由昆侖萬維(Kunlun Inc.)SkyworkAI團隊開發的一系列大型語言模型。這些模型基于Qwen架構,并融合了最新的后訓練技術,旨在提供在多種AI場景中表現卓越的通用能力。MindLink系列模型目前包含32B和72B等不同參數規模的版本,支持長達128K的上下文長度。
核心功能
- 多領域通用性能: 在各類常見基準測試中展現出強大的性能,適用于廣泛的AI應用場景。
- 長上下文處理能力: 支持128K的超長上下文窗口,能夠處理和理解大量的輸入信息。
- API訪問: 提供API接口供開發者進行模型探索和測試,便于集成到各類應用中。
- 持續優化與迭代: 團隊致力于模型的持續優化和改進,歡迎用戶反饋以推動模型演進。
技術原理
MindLink模型基于Qwen架構進行開發,并在此基礎上集成了SkyworkAI團隊在后訓練(Post-training)方面的最新進展。這意味著模型在基礎預訓練之后,通過特定的微調、指令跟隨或強化學習等技術進一步提升了其性能和泛化能力。其支持的128K上下文長度表明模型采用了高效的注意力機制或位置編碼技術,使其能夠處理遠超傳統模型的長序列輸入,從而更好地理解復雜語境和長文本信息。模型在Hugging Face上提供不同量化版本的下載,暗示其在部署和效率方面也進行了優化,以適應不同的硬件環境。
應用場景
- 通用AI任務處理: 適用于多種AI場景,包括但不限于內容生成、智能問答、文本摘要、翻譯等。
- 學術研究與開發: 作為基礎模型,可供研究人員進行二次開發、模型微調以及新算法的驗證。
- 企業級應用集成: 通過提供的API接口,企業可將其集成到智能客服、自動化辦公、數據分析等內部系統中。
- 長文本理解與生成: 憑借其超長上下文能力,特別適用于需要深入理解長篇文檔或生成長篇內容的場景,例如報告撰寫、法律文書分析、代碼生成等。
Skywork MindLink的項目地址
- Github倉庫:https://github.com/SkyworkAI/MindLink
- 技術論文:https://github.com/SkyworkAI/MindLink/blob/main/mindlink.pdf
- HuggingFace模型庫:
- MindLink-32B:https://huggingface.co/Skywork/MindLink-32B-0801
- MindLink-72B:https://huggingface.co/Skywork/MindLink-72B-0801
3. AI-Compass
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
?? 核心模塊架構:
- ?? 基礎知識模塊:涵蓋AI導航工具、Prompt工程、LLM測評、語言模型、多模態模型等核心理論基礎
- ?? 技術框架模塊:包含Embedding模型、訓練框架、推理部署、評估框架、RLHF等技術棧
- ?? 應用實踐模塊:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿應用架構
- ??? 產品與工具模塊:整合AI應用、AI產品、競賽資源等實戰內容
- ?? 企業開源模塊:匯集華為、騰訊、阿里、百度飛槳、Datawhale等企業級開源資源
- ?? 社區與平臺模塊:提供學習平臺、技術文章、社區論壇等生態資源
?? 適用人群:
- AI初學者:提供系統化的學習路徑和基礎知識體系,快速建立AI技術認知框架
- 技術開發者:深度技術資源和工程實踐指南,提升AI項目開發和部署能力
- 產品經理:AI產品設計方法論和市場案例分析,掌握AI產品化策略
- 研究人員:前沿技術趨勢和學術資源,拓展AI應用研究邊界
- 企業團隊:完整的AI技術選型和落地方案,加速企業AI轉型進程
- 求職者:全面的面試準備資源和項目實戰經驗,提升AI領域競爭力

 浙公網安備 33010602011771號
浙公網安備 33010602011771號