
AI-Compass GraphRAG技術生態:集成微軟GraphRAG、螞蟻KAG等主流框架,融合知識圖譜與大語言模型實現智能檢索生成
AI-Compass GraphRAG技術生態:集成微軟GraphRAG、螞蟻KAG等主流框架,融合知識圖譜與大語言模型實現智能檢索生成
AI-Compass 致力于構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??
?? 核心模塊架構:
- ?? 基礎知識模塊:涵蓋AI導航工具、Prompt工程、LLM測評、語言模型、多模態模型等核心理論基礎
- ?? 技術框架模塊:包含Embedding模型、訓練框架、推理部署、評估框架、RLHF等技術棧
- ?? 應用實踐模塊:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿應用架構
- ??? 產品與工具模塊:整合AI應用、AI產品、競賽資源等實戰內容
- ?? 企業開源模塊:匯集華為、騰訊、阿里、百度飛槳、Datawhale等企業級開源資源
- ?? 社區與平臺模塊:提供學習平臺、技術文章、社區論壇等生態資源
?? 適用人群:
- AI初學者:提供系統化的學習路徑和基礎知識體系,快速建立AI技術認知框架
- 技術開發者:深度技術資源和工程實踐指南,提升AI項目開發和部署能力
- 產品經理:AI產品設計方法論和市場案例分析,掌握AI產品化策略
- 研究人員:前沿技術趨勢和學術資源,拓展AI應用研究邊界
- 企業團隊:完整的AI技術選型和落地方案,加速企業AI轉型進程
- 求職者:全面的面試準備資源和項目實戰經驗,提升AI領域競爭力
GraphRAG模塊構建了涵蓋主流框架的圖檢索增強生成技術生態,將知識圖譜與大語言模型深度融合,實現結構化知識的智能檢索與生成。該模塊整合了微軟GraphRAG模塊化圖RAG系統、螞蟻KAG專業領域知識增強框架、港大LightRAG簡單快速檢索生成、CircleMind Fast-GraphRAG智能適應系統等核心技術,以及阿里OmniSearch多模態檢索、StructRAG混合信息結構化等前沿研究成果。技術棧包含了nano-graphrag輕量級實現、tiny-graphrag簡化版本、GraphRAG-Local-UI本地可視化界面、itext2kg增量知識圖譜構造器等專業組件,覆蓋了從原型開發到生產部署的全流程需求。
模塊深度集成了深度文檔理解、實體關系抽取、多跳推理查詢、子圖檢索優化等核心技術,支持動態VQA數據集、自適應規劃智能體、推理時混合信息結構化、多模態知識圖譜構建等高級功能。此外,還提供了OpenSPG語義增強可編程知識圖譜、KAG技術報告與實踐分享、LightRAG效率與準確性提升、GraphRAG本地LLM集成等理論與實踐指導,以及醫療診斷、金融分析、法律咨詢、科學研究等專業領域應用案例,幫助開發者構建基于圖結構知識的下一代智能問答系統,實現更加準確、全面、可解釋的知識服務。
目錄
- 0.Fast-graphrag
- 0.GraphRAG-微軟
- 0.KAG螞蟻
- 0.LightRAG
- 0.nano-graphrag
- 1.GraphRAG-Local-UI
- 1.OmniSearch 阿里多模態rag
- 1.StructRAG 阿里
- 2.tiny-graphrag
================================================================================
3.GraphRAG
0.Fast-graphrag
簡介
Fast GraphRAG 是一個流線型且可提示的快速圖檢索增強生成 (GraphRAG) 框架,旨在提供可解釋、高精度、代理驅動的檢索工作流。它致力于簡化高級 RAG(檢索增強生成)的實施,無需從頭構建復雜的代理工作流。
核心功能
- 智能適應性檢索: 能夠根據具體用例、數據和查詢智能地調整和優化信息檢索。
- 高精度RAG: 提供高性能的檢索增強生成能力,以獲得更準確的答案。
- 代理驅動工作流: 支持通過代理(Agent)驅動的檢索過程,提高工作效率和自動化水平。
- 簡化集成: 設計用于無縫集成到現有檢索管道中,降低使用門檻。
- 個性化Pagerank探索: 利用個性化PageRank算法在圖譜中探索并找到最相關的信息片段。
技術原理
Fast GraphRAG 的核心技術原理基于圖檢索增強生成 (GraphRAG) 范式。它通過構建和利用知識圖譜來組織和連接信息,從而實現更精確和上下文感知的檢索。具體來說,該框架利用個性化PageRank算法在圖結構數據中進行高效探索,根據查詢找到與用戶需求最相關的信息節點。結合代理驅動的工作流(Agentic Workflows),它能夠實現更智能、更動態的檢索過程,模擬人類推理和決策過程來優化信息獲取。這使得RAG系統不僅能夠檢索到信息,還能理解信息之間的關系,從而生成高質量、可解釋的輸出。
應用場景
- 智能問答系統: 構建能夠理解復雜查詢并從海量知識庫中提供精準答案的智能問答應用。
- 信息檢索與推薦: 在大型數據集中快速定位相關信息,或根據用戶興趣進行個性化內容推薦。
- 知識管理: 幫助企業或組織更好地組織、管理和利用其內部知識資產。
- 研究與分析: 加速研究人員從大量文獻或數據中提取關鍵信息,進行深入分析。
- 內容生成: 輔助大語言模型生成更準確、更具事實依據的內容,減少幻覺(hallucination)現象。
0.GraphRAG-微軟
簡介
GraphRAG是微軟研究院開發的一個模塊化、基于圖的檢索增強生成(RAG)系統。它旨在通過結合知識圖譜與大型語言模型(LLMs)的力量,從非結構化文本數據中提取有意義的結構化信息,并在此基礎上進行問答和內容生成。相較于傳統RAG方法,GraphRAG能夠提供更結構化的信息檢索和更全面的響應生成。
核心功能
- 結構化數據提取與轉化: 利用LLMs將非結構化文本轉化為結構化的圖數據。
- 增強型檢索: 基于構建的知識圖譜進行信息檢索,提高檢索的精準性和關聯性。
- 綜合性問答: 能夠對私有或此前未見的復雜數據集進行高效的問答。
- 信息整合與總結: 整合文本提取、網絡分析、LLM提示和總結等多個環節,實現對文本數據集的深度理解。
- 系統模塊化設計: 包含索引器(Indexer)、查詢器(Query)和提示調優(Prompt Tuning)等核心子系統。
技術原理
GraphRAG的核心技術原理在于其創新的圖-RAG范式。它首先通過自然語言處理(NLP)和大語言模型(LLM)對非結構化文本進行解析,識別實體、關系和事件,并將其轉換為知識圖譜(Knowledge Graph)結構。這一過程涉及信息提取(Information Extraction)和圖構建(Graph Construction)。在檢索階段,系統利用圖的拓撲結構和語義信息進行圖遍歷(Graph Traversal)和路徑發現(Path Finding),以獲取與查詢相關的上下文信息,而非僅僅依賴文本相似度。隨后,這些結構化和上下文化的信息被作為增強上下文(Augmented Context)輸入到LLM中,通過提示工程(Prompt Engineering)引導LLM生成更精準、更具邏輯性和連貫性的回答。這種方法有效解決了傳統RAG在處理復雜關系和多跳推理時的局限性,提升了回答的可解釋性(Interpretability)和溯源性(Traceability)。
應用場景
- 企業內部知識管理: 用于分析和查詢大量的非結構化企業文檔,如報告、合同、郵件等,實現高效的知識發現和問答。
- 科研數據分析: 輔助科學家從海量的科研論文、專利和實驗數據中提取關鍵信息和潛在關聯,加速研究進程。
- 智能客服與問答系統: 構建能夠理解復雜用戶意圖并提供精準、結構化回答的智能客服機器人。
- 情報分析: 從公開或私有數據源中識別實體、事件和關系,進行復雜的網絡分析,支持決策制定。
- 法律與合規領域: 分析法律文件、判例和法規,輔助律師進行案例研究和風險評估。
- microsoft/Graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system
- GraphRAG-文檔手冊
- Microsoft GraphRAG | 基于知識圖譜的RAG套件,構建更完善的知識庫_嗶哩嗶哩_bilibili
0.KAG螞蟻
簡介
KAG(知識增強生成)是一個由螞蟻集團與OpenKG聯合開發的,基于OpenSPG(語義增強可編程圖)框架的專業領域知識服務框架。它旨在通過雙向增強大型語言模型(LLM)與知識圖譜,克服傳統檢索增強生成(RAG)技術在專業知識服務落地中的不足,提供高效、準確的領域知識推理和問答解決方案。
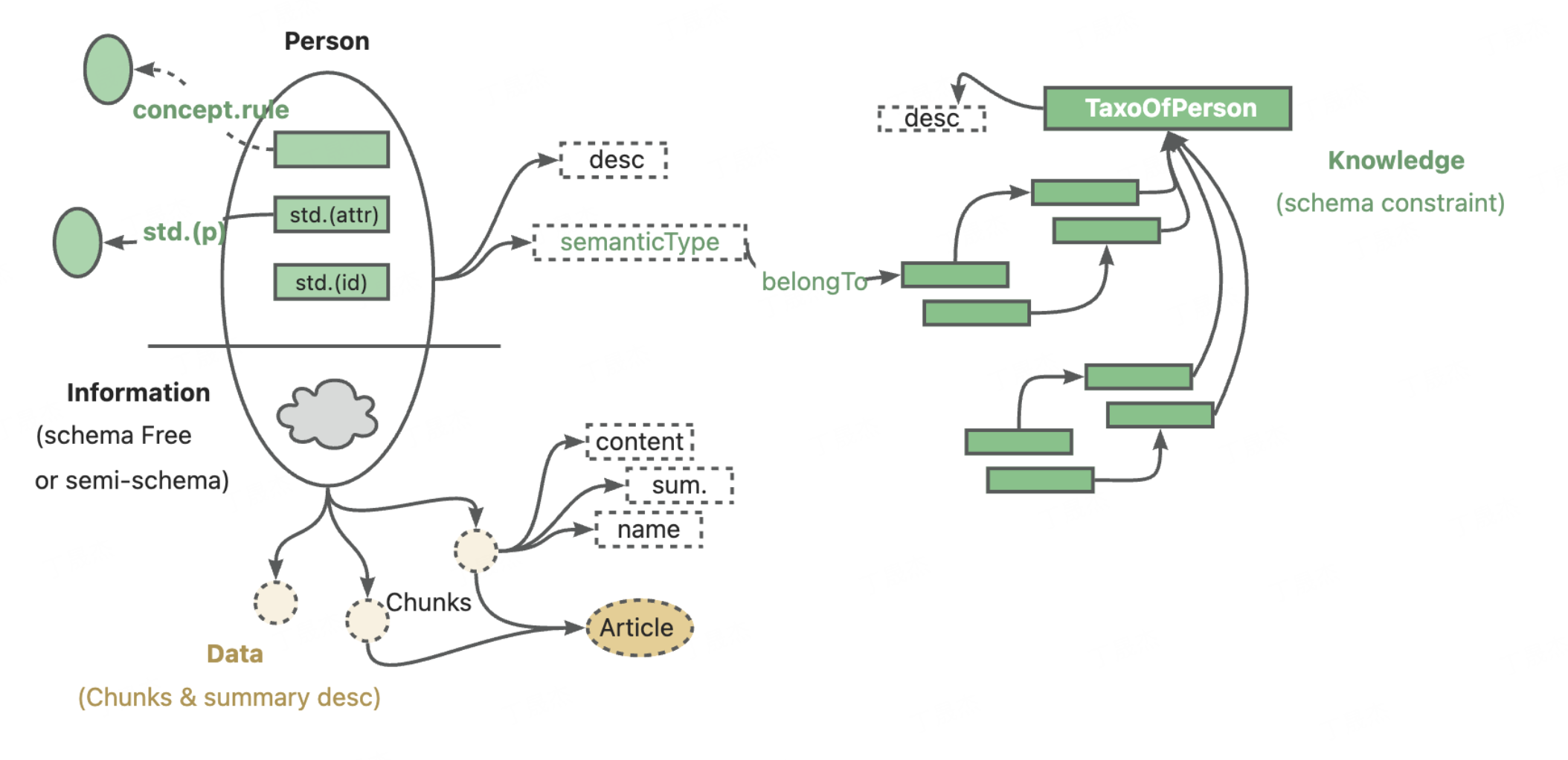
核心功能
- 知識建模與管理: 提供對LLM友好的語義化知識管理能力,支持領域模型約束下的知識建模,并實現事實與邏輯的融合表示。
- 混合推理引擎: 引入邏輯符號引導的混合求解和推理引擎,集成了規劃、推理和檢索三種操作符,能夠處理復雜多跳問題,結合圖譜推理、邏輯計算、Chunk檢索和LLM推理。
- 知識增強生成: 通過知識圖譜與原文片段的互索引以及基于語義推理的知識對齊,顯著提升大型語言模型在專業領域的知識準確性和一致性。
- 領域圖譜構建與問答: 支持基于KAG框架自主完成領域圖譜的構建,并提供針對專業領域知識庫的邏輯推理和事實問答能力。
技術原理
KAG框架的核心在于其“知識增強生成”范式,它通過以下關鍵技術實現:
- 語義增強可編程圖譜 (SPG): 作為底層知識基礎設施,SPG提供了強大的語義建模能力,將領域知識以結構化、可編程的方式進行組織和存儲,確保知識的精確性和可操作性。
- LLM與知識圖譜雙向增強:
- LLM友好語義化知識管理: 將知識圖譜轉化為LLM易于理解和利用的語義表示。
- 知識圖譜與原文片段互索引: 構建知識圖譜與非結構化文本之間的關聯,實現精準檢索和知識定位。
- 邏輯符號引導的混合推理引擎: 結合符號邏輯推理(如規則、計算)和統計推理(如LLM的生成能力),形成一種多模態、多步驟的推理鏈,將自然語言問題轉化為語言與符號結合的問題求解過程,提升推理的嚴謹性和可解釋性。
- 基于語義推理的知識對齊: 降低信息抽取噪聲,提升知識的準確性和一致性。
- KAG 三大組成部分: kg-builder (知識構建器), kg-solver (知識求解器), kag-model (模型部分,未來逐步開源),協同完成知識的獲取、組織、推理和應用。
應用場景
KAG框架主要應用于對專業知識精確性、可靠性和可解釋性要求高的領域,例如:
- 金融風控: 進行復雜的金融事件分析和風險評估。
- 醫療健康: 提供疾病診斷輔助、藥物研發知識問答。
- 法律咨詢: 進行法律條文檢索和案例推理。
- 智能客服: 構建具備深度領域知識的問答機器人,提供專業、精準的服務。
- 企業知識管理: 幫助企業構建和管理海量的內部專業知識,賦能決策支持和業務創新。
- 垂直領域大模型落地: 助力大模型在特定專業領域實現高性能、高準確率的知識應用。
- KAG/README_cn.md at master · OpenSPG/KAG
- 語義增強可編程知識圖譜
- OPENSPG用戶手冊
- 國內首個專業領域知識增強服務框架 KAG 技術報告,助力大模型落地垂直領域
- KAG 技術與實踐分享|基于 KAG 框架自主完成領域圖譜構建和知識問答
- 螞蟻 KAG 框架核心功能研讀
0.LightRAG
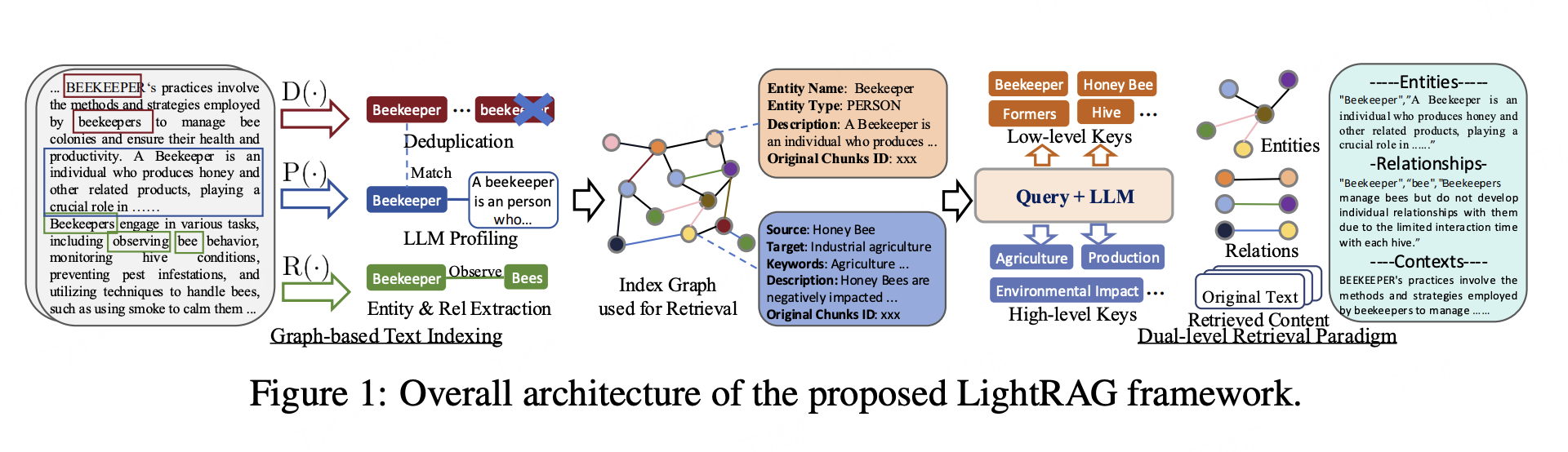
簡介
LightRAG是香港大學和北京郵電大學研究團隊推出的輕量級、高效檢索增強生成(RAG)方法。它將圖結構融入文本索引和檢索,采用雙層檢索系統,結合增量更新算法,能高效處理不同層次查詢,快速整合新信息,在生成速度和上下文相關性上表現出色,適合更多開發者和小型企業。
核心功能
- 圖增強文本索引:建立相關實體復雜關系,提升上下文理解能力。
- 雙層檢索系統:同時處理低層具體細節和高層抽象概念查詢。
- 增量更新算法:不重建數據索引,快速整合最新信息。
- 支持多類型存儲:提供多種存儲實現選項,如Neo4J、PostgreSQL等。
- 多模型集成:支持OpenAI、Hugging Face、Ollama等模型,以及與LlamaIndex集成。
- 對話歷史支持:支持多輪對話,考慮對話歷史進行查詢。
- 用戶提示定制:通過
user_prompt參數引導LLM處理檢索結果。 - 插入功能多樣:支持基本插入、批量插入,可關聯文件路徑實現溯源。
技術原理
- 基于圖的文本索引:將原始文本分割成小塊,利用大語言模型提取實體和關系,生成鍵值對,構建知識圖譜。
- 雙層檢索:詳細層面關注文檔具體小部分,實現精確信息檢索;抽象層面關注整體意義,理解不同部分廣泛連接。
- 存儲機制:使用四種類型存儲,每種有多種實現選項,初始化時可通過參數設置。
- 模型注入:初始化時需注入LLM和Embedding模型的調用方法,支持多種模型API。
應用場景
-
信息檢索:適用于回答具體和抽象問題,如文獻檢索、知識問答。
-
動態數據處理:用于新聞、實時分析等數據變化頻繁的場景。
-
智能客服:支持多輪對話,結合對話歷史提供準確回復。
-
小型企業應用:輕量化特性適合處理大規模知識庫,降低計算成本。
-
知識圖譜構建:建立相關實體復雜關系,提升系統上下文理解能力。
-
HKUDS/LightRAG: "LightRAG: Simple and Fast Retrieval-Augmented Generation"
0.nano-graphrag
簡介
nano-graphrag 是 GraphRAG 模型的一個簡化且易于訪問的實現,旨在從文本文檔中進行知識提取和問答。它提供了一個更易于用戶使用和修改的替代方案,解決了官方 GraphRAG 實現代碼量大、不易閱讀研究的痛點,其代碼量更小、運行更快。
核心功能
- 知識提取與問答: 能夠從文本數據中提取知識并支持問答功能。
- 簡化RAG操作: 提供簡化的RAG(檢索增強生成)插入和查詢功能,允許只返回圖譜中檢索到的上下文。
- 去重處理: 使用內容的MD5哈希作為鍵,避免了塊的重復存儲。
- 可定制性: 支持用戶自定義分塊方法,并允許替換存儲相關的組件。
- JSON格式輸出: 可以通過
best_model_func將輸出格式化為JSON對象。 - 高效社區處理: 不同于原始GraphRAG的Map-Reduce風格,nano-graphrag僅使用Top-K個重要且核心的社區(默認為512個社區)來填充上下文,從而優化了全局搜索。
技術原理
nano-graphrag 的核心在于對GraphRAG模型的輕量級重構與優化。它利用圖結構來組織和連接文本信息,將知識點及其關系構建成圖譜。在數據處理層面,通過對內容進行MD5哈希來確保數據塊的唯一性,避免重復存儲。在檢索過程中,它支持樸素RAG(Naive RAG)模式,能夠直接從構建的知識圖譜中檢索相關上下文。
與原始GraphRAG的一個主要區別在于全局搜索策略。原始實現采用Map-Reduce風格來填充上下文,而nano-graphrag則通過識別和選擇Top-K個最重要和中心的社區(Community Detection),將這些精選社區的信息作為上下文,極大地提高了檢索效率和相關性。這暗示其可能采用了某種圖算法(如中心性度量、社區發現算法)來評估社區的重要性。此外,它集成了語言模型(如DeepSeek)和嵌入功能(如GLM)來處理文本數據并生成嵌入向量,從而實現高效的知識存儲、檢索與查詢。
應用場景
- 輕量級知識庫構建: 適用于需要快速搭建小型或中型知識庫,進行高效知識管理和查詢的場景。
- 文檔智能問答系統: 可用于構建針對特定領域文檔的智能問答系統,例如企業內部文檔、技術手冊等。
- 研究與原型開發: 由于其代碼量小、易于修改,非常適合研究人員和開發者進行GraphRAG模型原理的理解、功能驗證及快速原型開發。
- 資源受限環境下的RAG部署: 相比于復雜的官方實現,nano-graphrag更適合在計算資源或存儲空間有限的環境中部署RAG應用。
- 定制化信息檢索: 適用于需要根據特定需求定制分塊、存儲或檢索邏輯的場景。
1.GraphRAG-Local-UI
簡介
GraphRAG-Local-UI是一個旨在成為終極的本地圖RAG(Retrieval-Augmented Generation,檢索增強生成)和知識圖譜(KG)本地大語言模型(LLM)應用的生態系統。它利用本地LLM,提供一個用戶友好的界面,用于管理和交互GraphRAG系統,尤其專注于對大型文本數據進行索引和查詢。目前該項目正處于向獨立的索引/提示調優和查詢/聊天應用過渡的階段,所有功能都圍繞一個強大的中心API構建。
核心功能
- 本地LLM集成: 支持配置和使用如Ollama等本地大語言模型。
- 索引與提示調優: 提供對文本數據進行索引和優化提示詞的功能。
- 查詢與聊天界面: 允許用戶通過直觀的UI進行內容查詢和交互式聊天。
- 數據可視化: 包含可視化功能,便于理解知識圖譜和RAG流程。
- API驅動架構: 所有核心功能通過一個健壯的中心API提供服務,支持多應用集成。
技術原理
該項目基于檢索增強生成(RAG)方法,結合本地大語言模型(LLM)與知識圖譜(KG)技術。其核心架構包括:
- GraphRAG系統: 作為主干,處理大型文本數據的索引和查詢。
- 本地LLM支持: 允許用戶利用本地部署的大模型進行生成式任務。
- API服務器: 基于FastAPI構建的強大后端服務器,處理所有核心操作。
- 向量存儲: 可能利用向量數據庫來存儲和檢索嵌入,以支持高效的語義搜索。
- Gradio界面: 用戶交互界面可能通過Gradio框架構建,提供友好的前端體驗。
應用場景
- 本地知識管理: 適用于希望在本地環境管理和查詢大量私有或敏感文本數據的用戶。
- 企業內部RAG系統: 構建基于企業文檔和知識庫的智能問答和內容生成系統。
- 研究與開發: 為研究人員和開發者提供一個實驗和優化GraphRAG模型與本地LLM交互的平臺。
- 教育與學習: 創建個性化的學習助手,通過知識圖譜和LLM提供定制化的信息檢索和解釋。
- 離線AI應用: 對于網絡受限或對數據隱私要求高的場景,提供離線的本地LLM解決方案。
1.OmniSearch 阿里多模態rag
簡介
圍繞多模態檢索增強生成(mRAG)展開。首先指出現有啟發式 mRAG 存在非自適應和過載檢索查詢問題,且當前 VQA 數據集無法充分反映。為此構建了 Dyn - VQA 數據集,包含三種動態問題類型。同時提出了首個自適應規劃代理 OmniSearch,能實時規劃檢索動作,大量實驗證明其有效性。
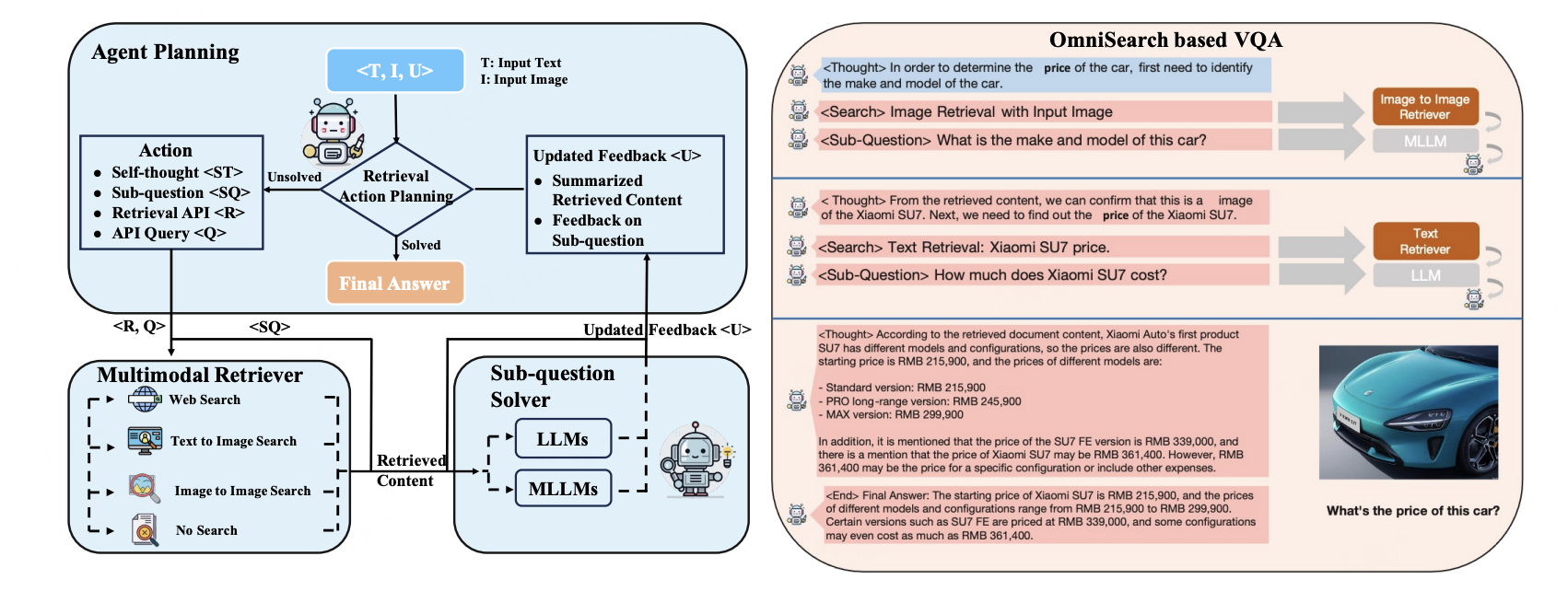
核心功能
- Dyn - VQA 數據集:評估 mRAG 方法處理動態知識檢索任務的表現,涵蓋多種領域和動態問題類型。
- OmniSearch:將復雜多模態問題分解為子問題鏈,根據問題解決狀態和檢索內容動態調整檢索策略,為 MLLMs 提供相關準確知識。
技術原理
- Dyn - VQA 數據集構建:通過文本問題寫作、多模態改寫、中英文翻譯與校對三步構建,確保問題質量和多樣性。
- OmniSearch 框架:由規劃 agent、檢索器、子問題求解器組成。規劃 agent 根據問題和反饋生成子問題、選擇檢索工具;檢索器執行檢索操作;子問題求解器解答子問題并反饋。
應用場景
-
實時信息查詢:如體育賽事結果、股票價格等實時變化信息的查詢。
-
多模態知識問答:結合圖像和文本信息進行推理的問答場景。
-
復雜問題推理:需要多步推理的問題,如人物職業推理等。
1.StructRAG 阿里
簡介
StructRAG 是中國科學院和阿里巴巴集團研究人員提出的新 RAG 框架。現有 RAG 方法處理知識密集型推理任務時,因信息分散難以準確識別關鍵信息和全局推理。StructRAG 借鑒人類處理復雜問題時將信息結構化的認知理論,采用混合信息結構化機制,根據任務需求構建和利用結構化知識,提升 LLMs 在知識密集型推理任務上的性能。
核心功能
- 混合結構路由器:根據輸入問題和文檔核心內容,選擇最合適的知識結構類型,如表格、圖形等,使用基于 DPO 的方法訓練。
- 分散知識結構化器:將原始文檔轉化為選定格式的結構化知識及知識描述,匯總成整體知識結構和總體描述。
- 結構化知識利用器:將復雜問題分解為簡單子問題,從結構化知識中提取精確知識,整合后生成最終答案。
技術原理
- 采用混合信息結構化機制,通過三個模塊依次完成任務。混合結構路由器基于問題和文檔核心內容確定最佳結構類型;分散知識結構化器利用 LLM 能力將原始文檔轉化為對應結構化知識;結構化知識利用器對問題分解和知識提取以進行準確推理。
- 訓練混合結構路由器時,使用合成 - 模擬 - 判斷方法構建偏好對,通過 DPO 算法訓練,使路由器能準確選擇結構類型。
應用場景
適用于各種知識密集型推理任務,如財務報告分析、多文檔信息比較、總結歸納、長鏈推理、規劃任務等,可有效解決任務中信息分散和噪音問題,提升推理準確性。
- Li-Z-Q/StructRAG: StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
- StructRAG:通過推理時混合信息結構化提升 LLMs 的知識密集型推理
- StructRAG論文
2.tiny-graphrag
簡介
Tiny GraphRAG 是一個輕量級、約1000行的GraphRAG(圖譜檢索增強生成)算法的Python實現。它旨在提供一個易于理解、可修改且不依賴任何框架的解決方案。該項目的一大特色是僅使用本地運行的語言模型,不依賴于OpenAI或任何商業大模型服務商,支持完全本地化部署和運行。
核心功能
- 本地化信息抽取與知識圖譜構建: 利用本地運行的語言模型從文本數據中提取實體和關系,并構建結構化的知識圖譜。
- 圖譜驅動的檢索增強: 基于構建的知識圖譜進行信息檢索,為語言模型提供更精準和豐富的上下文信息。
- 本地化大模型生成: 結合檢索到的圖譜信息,使用本地部署的大模型進行高質量的文本生成。
- 知識圖譜可視化: 提供知識圖譜的構建與查詢結果的可視化功能。
技術原理
Tiny GraphRAG的核心技術原理在于將知識圖譜與檢索增強生成(RAG)范式相結合,并特別強調本地化部署。
- 文本預處理與分塊: 輸入的文本數據被進行預處理和邏輯分塊。
- 實體與關系抽取: 利用預訓練的本地語言模型對文本分塊進行自然語言理解,從中識別關鍵實體及其相互之間的關系。
- 知識圖譜構建: 將抽取的實體和關系轉化為圖結構數據,存儲在圖數據庫中,形成知識圖譜(Knowledge Graph)。這通常涉及節點(實體)和邊(關系)的定義。
- 圖譜檢索: 當用戶提出查詢時,系統會基于查詢內容在知識圖譜中進行路徑查找或子圖匹配,檢索出與查詢最相關的圖譜信息(結構化上下文)。
- 本地大模型融合生成: 將檢索到的知識圖譜信息作為增強上下文,輸入到本地運行的語言模型中。語言模型結合這些結構化信息,生成更準確、更具上下文相關性的回答。整個過程不涉及外部API調用,保證數據隱私和運行效率。
應用場景
- 本地知識庫問答系統: 構建私有的、不依賴云服務的企業內部或個人知識庫問答系統,適用于對數據隱私要求高的場景。
- 離線智能助手: 在沒有互聯網連接或網絡環境不穩定的情況下,提供智能問答、信息檢索和內容生成服務。
- 輕量級RAG系統原型開發: 為研究人員和開發者提供一個簡潔、易于理解和修改的GraphRAG實現,用于快速驗證概念和功能。
- 資源受限環境下的AI應用: 在計算資源相對有限的環境中運行檢索增強生成任務,實現高效的信息處理。
- github地址:AI-Compass??:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass??:https://gitee.com/tingaicompass/ai-compass
?? 如果本項目對您有所幫助,請為我們點亮一顆星!??

 浙公網安備 33010602011771號
浙公網安備 33010602011771號