從18w到1600w播放量,我的一點思考。
你好呀,我是歪歪。
前幾天我想要鞏固一下共識算法這個知識點。
(先聲明,這篇文章不深入討論共識算法本身)
于是我在 B 站大學上搜索了“共識算法”這個詞:
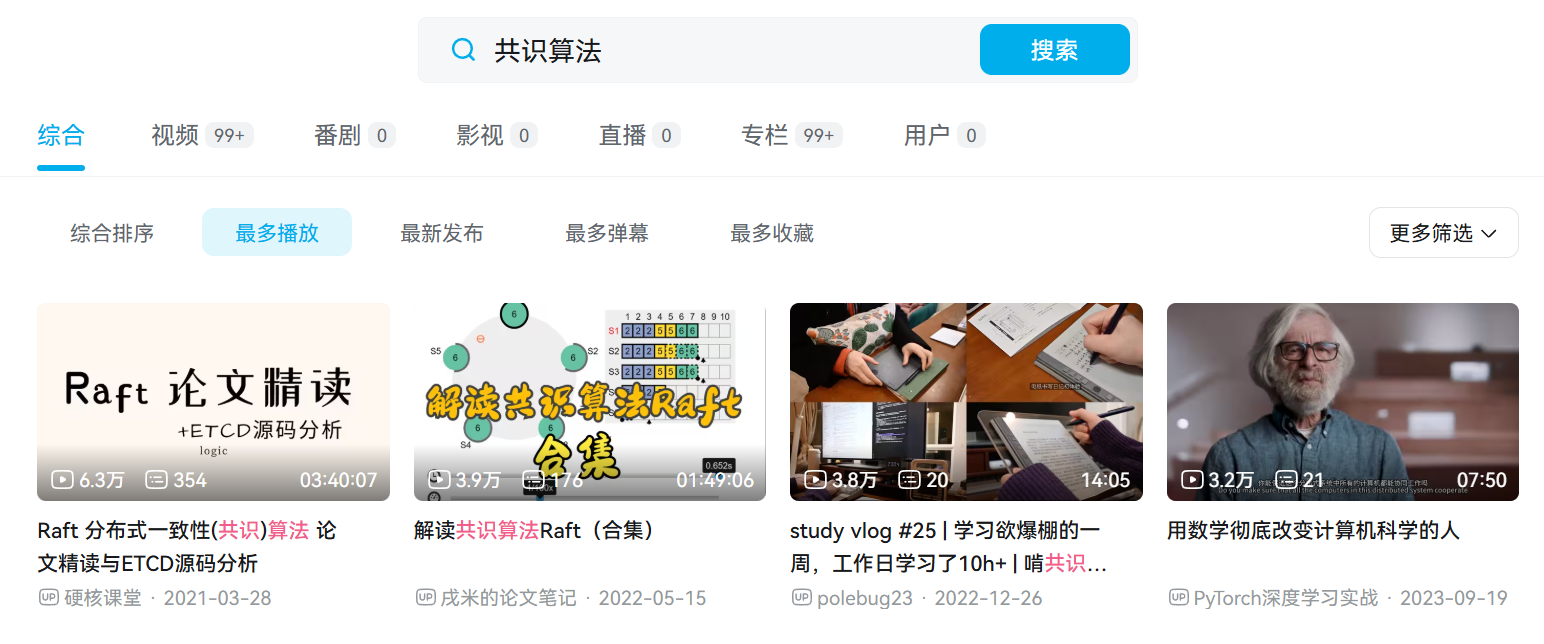
我還特意按照播放量排序了一下,準備先找個播放量高點的視頻隨隨便巴拉幾下。
排名第一的視頻,播放量只有 6.3w。
說實話,在搜索之前,我潛意識里覺得這種這個話題,頭部視頻最次最次也得有個 10w+ 的播放吧?
而實際情況是前四的視頻播放量,滿打滿算加起來,18w。
這個數字讓我瞬間把共識算法拋在腦后,冒出了另一個念頭:要不看看"微服務"這個關鍵詞的播放量?
你猜一下,這個用“微服務”這個關鍵詞,在 B 站搜索,然后按照播放量排序,播放量第一有多少,前四加起來又有多少?
...
...
不要太保守,往大了猜。
...
...
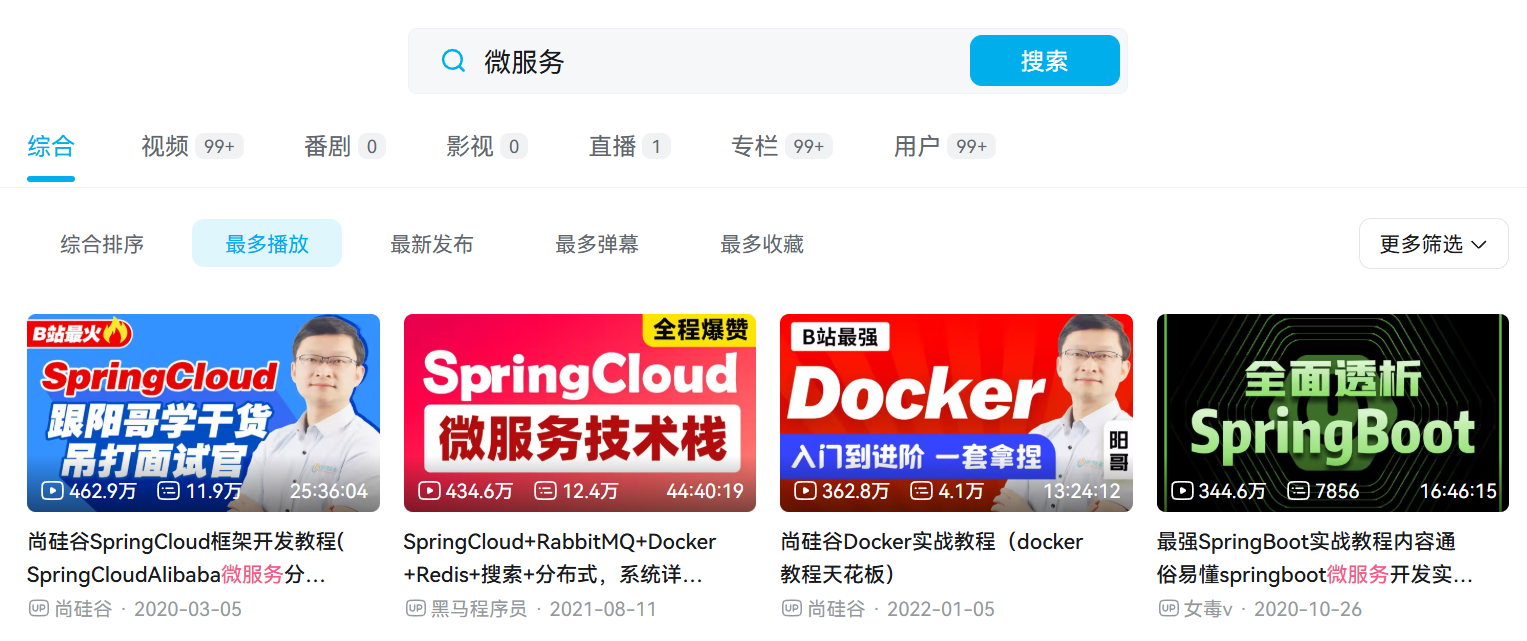
用“微服務”做關鍵詞,播放量第一 462w,前四加起來 1600w,就這我還抹掉了 5w 的“零頭”。
這個鮮明的對比,確實引發了我的一點思考。
從“共識算法”的 18w 到“微服務”的 1600w,近 90 倍的差距。看到這個數據,你大概能猜到我在想什么。
面對這個現象,我在思考的是:
共識問題可以說是微服務得以存在的理論基石。但是從這個數據上來看,我覺得知識體系在某個環節出現了非常嚴重的斷層。
當然了,我得先疊個甲。
我知道我用上面這個統計方式完全不準確,完全不科學,完全不正確。
但是“知識體系出現了斷層”這個結論,歪師傅覺得是正確的,而且也覺得這個是正常的現象。
只是讓我覺得詫異的是,我潛意識里面覺得差距不應該是十幾萬到一千六百萬,這種近 90 倍的數量級的差異。
這背后其實有一個值得探討的且是 IT 行業普遍存在的一個現象:“趕緊上手”和“底層原理”之間的權衡。
數據為什么是這樣的
首先,我思考了一下:數據為什么是這樣的?
我觀察了一下,"微服務"排名前四的都是培訓機構上傳的系統課程。
培訓機構嘛,大家也知道,這一類課程的主要目的就一個:趕緊上手。
底層邏輯是為“盡快找到工作”而服務。
本質上是將一個人在最短時間內打造成能滿足企業初級編碼崗位要求的合格“牛馬”。
在這個標準下,一切不能直接、快速為初級編碼崗位服務的知識,都會是“冗余”的。
所以,你看他們的課程:
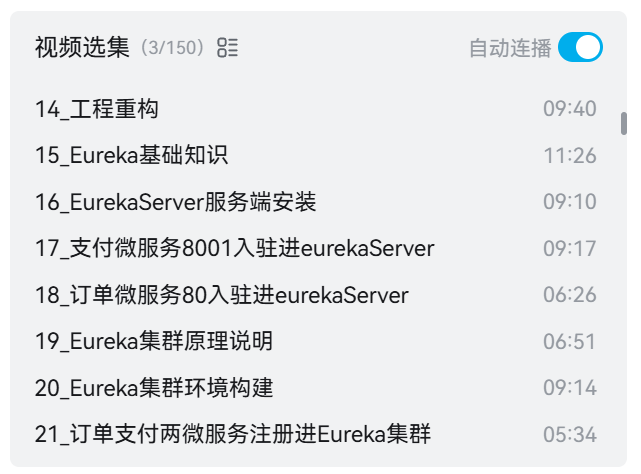
比如講到 Eureka 的時候,基本上都是在講怎么使用,代碼應該怎么去寫,寫完之后怎么跑起來。
我快速瀏覽了相關內容,完全沒有提到“共識算法”和 CAP 相關的點。
當然了,也有可能是我跳著看的,看的不仔細,其實講了但是我沒看到,但是這不重要。
總之,事實就是入門課程完全可以不講共識算法,甚至不提 CAP 理論。
這類入門課程的受眾面就是非常廣,播放量高也是非常自然的事情。
寫到此處,不得不再次疊個甲了:我也并不是在吐槽這種授課方式,我只是在稱述我認為的“數據為什么是這樣”的事實。
相反,我站在現在的視角去看,這樣的課程安排其實是合理的。
試想一下,對于一名剛剛從單體服務轉向分布式系統的初學者來說,還在給你鋪墊各個組件的功能,然后講到注冊中心的時候,直接就安排上了 CAP 和共識算法這套非常抽象、難以理解的絲滑小連招,應該是非常勸退的。
直接就是一個“從入門到放棄”的大動作。
這也與“盡快找到工作”這個核心出發點相違背。
在市場上,對于大多數初中級崗位,公司更看重的是你能否在現有的框架下完成業務開發。
如果公司使用的是 SpringCloud 全家桶來搞微服務,那你能夠正確、熟練地使用,已經能夠勝任百分之七八十的工作了。
至于共識算法什么的,最多也就是在面試的時候出現一下就了不得了。
更進一步
對于培訓機構和學習者來說,都需要“更進一步”
對于培訓機構來說,雖然這些都是入門課程,但是我覺得理想狀態應該是能在講解相關組件的時候,引出其背后的理論,但是一定要點到為止。
比如:
從“為什么要用服務注冊中心?”,引出服務發現的問題。 從“Eureka 和 Nacos 的區別?”,引出 CAP 理論。 從“分布式事務怎么實現?”, 引出數據一致性問題。 “從集群數據同步”,引出共識問題。
點到為止,只需要幫初學者建立一個宏觀的、模糊的認知就行了,相當于埋下一顆種子。
而對于學習者,你不能一邊自嘲著自己是“CRUD 工程師”,一邊又沒有足夠的理論基礎和自信的技術決策能力。
你得讓前面提到的種子長成一顆技能樹。
比如,當面對 CAP 權衡的時候,你能通過你的技能樹知道它不是一個選擇題,而是一個權衡題。
舉個簡單的例子。
站在 CAP 的角度,你得知道為什么 Eureka 客戶端要緩存服務列表?
因為在與注冊中心網絡分區 P 時,要保證服務的可用性 A,所以犧牲了部分一致性 C。
你也得知道為什么 ZooKeeper 不能像 Eureka 那樣允許節點間長時間失聯?
因為它要保證一致性 C,在出現分區 P 時,寧愿犧牲可用性 A。
從而要知道,在要求強一致性的金融場景下,底層設計要保證 CP ,而在追求高可用的電商場景下,要保證 AP。
再比如,當學習到 Seata 時,需要追問各種分布式事務模式的實現,什么 2PC、TCC、Saga 這些玩意在根本上是想說什么,是怎么和 ACID、BASE 理論以及最終一致性這些概念關聯上的。
我知道這些要求對于初學者來說,確實很高。
但是結合我自己親自走過的技術路線,我確實是先掌握了基礎的使用,然后在長達幾年的時間中逐步慢慢去理解上面這些東西的。
而我上面說的這么多,核心想要表達的是:首先你得有一顆種子,然后你得讓種子長成一顆樹。
有的人運氣比較好,得到種子的過程比較輕松,不需要花費大力氣,在這個維度確實有差異。
但是在如何讓種子長成樹的努力上,我覺得大家所需要付出的精力是大差不差的,而且這方面完全是勤能補拙的。
灌溉
讓種子成長為樹,你得用知識去灌溉。
比如,就具體到前面討論的這些問題。
寫的過程中我就想起我之前看過的一本書,《數據密集型應用系統設計》這本分布式領域的書,必讀,是非常好的“肥料”。
然后源碼也是上好的肥料,可以從一些相對簡單的項目開始讀。
比如讀一讀 Nacos 客戶端服務發現的流程,你會發現,理論在具體的代碼中是如何體現的。
也可以嘗試去閱讀一些別人梳理好了的論文導讀,比如前面提到的 Raft,相關的論文已經被很多人解讀過了,甚至網上已經有了非常清晰的解釋原理的可視化動畫,幫助你理解其核心思想。
這些都是我過去使用的比較"古老"的學習方式。
現在有了 AI 大模型的加持,學習新技術、尋找優質資料都變得更加方便了。
你可以讓 AI 幫你解釋復雜概念、推薦學習路徑、甚至模擬面試問答,這就大大降低了學習的門檻。
寫在最后
最后,我還想表達一個額外的點。
我們回到最開始的數據。
那 1600 萬播放量,代表了一條好走、明確且廣闊的道路。
那 6.3 萬播放量,則代表著一條更孤獨、更艱難、更崎嶇的通往山峰的路。
每個人都會在大路上走一段時間,但是有人走著走著路就不一樣了。
不論你選擇哪條路,道路都是清晰的,資源都是充沛的。選擇任何一條路,并堅定地走下去,都值得尊敬。
但是,你得自洽。
自洽是指,你不能一邊享受著這條“好走、明確且廣闊的道路”的快捷與輕松,自嘲著自己是“CRUD 工程師”,又下不了決心、沒有足夠的毅力往難走的路上走,還在心里嘲諷正在這條更難的路上努力往前的人。
其實工作的越久,我越發現,又是真正阻礙一部分技術人成長的,正是這種“既要、又要、還要”的擰巴心態。
而且,我也曾經在這種心態中沉淪過一段時間。
它讓你既無法安心享受當下的成就,又缺乏魄力去追尋更高的目標,最終把精力都耗在了自我消耗和無效的評判上。
想清楚自己想去哪兒,然后坦然地、專注地走你自己的路。
對你沒選擇的路保持尊重,對你選擇的路負起全責。
最重要的是,回頭再看的時候,不要用“假設”來美化你沒走過的那條路。
好了,以上就是我個人的一些主觀思考。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號