無意中在應(yīng)用層瞥見了一個微內(nèi)核的操作系統(tǒng)調(diào)度器
你好呀,我是歪歪。
最近遇到一個業(yè)務(wù)上的問題,在網(wǎng)上看到一個對應(yīng)場景下的解決方案,我感覺這個場景還挺有通用性的,分享一下。
以后遇到類似問題,或者當(dāng)它以面試場景題出現(xiàn)的時候,你可以拿去就用。

事情是這樣的。
程序里面有一條“線路”,這個“線路”是購買的外部服務(wù),使用起來是要收費的。
為了更好的理解這個“收費的線路”,你可以假設(shè)為這是一個付費的 AI 接口。
然后你可以把“線路”簡單的理解為一個 FIFO 的公共隊列,對應(yīng)著多個生產(chǎn)者。
也就是同時有很多人,即消費者,在使用這個“AI 接口”提問。
畫個示意圖是這樣的:
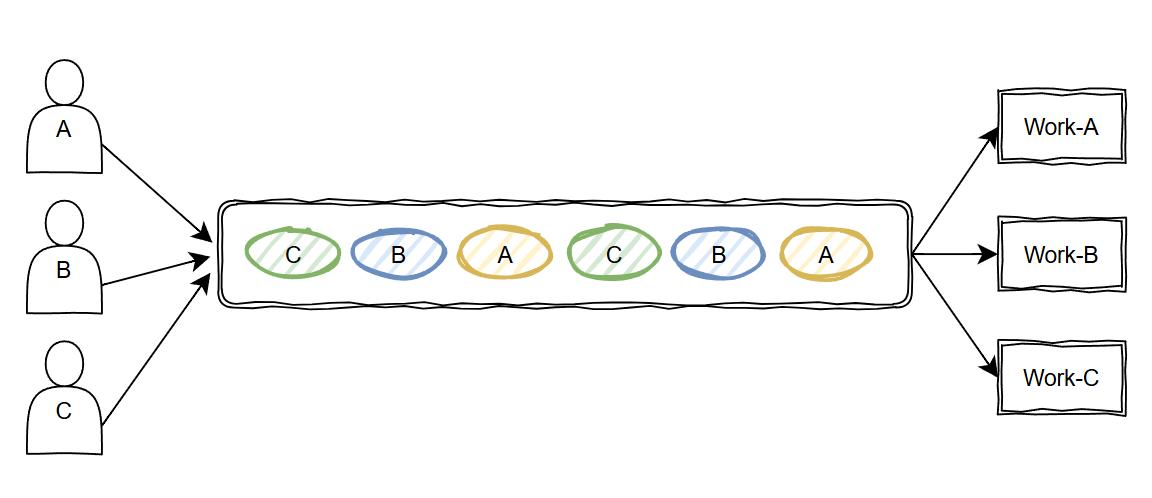
理想情況下,我們期望大家和和氣氣輪流用,你一個我一個,節(jié)奏均勻得像心跳。
但是,實際使用過程中,可能會出現(xiàn)一個卷王 A 生產(chǎn)者,突然快速的生產(chǎn)了大批量的數(shù)據(jù),導(dǎo)致 B、C 生產(chǎn)者產(chǎn)生的少量的數(shù)據(jù)排在隊列的最后面,等到天荒地老:
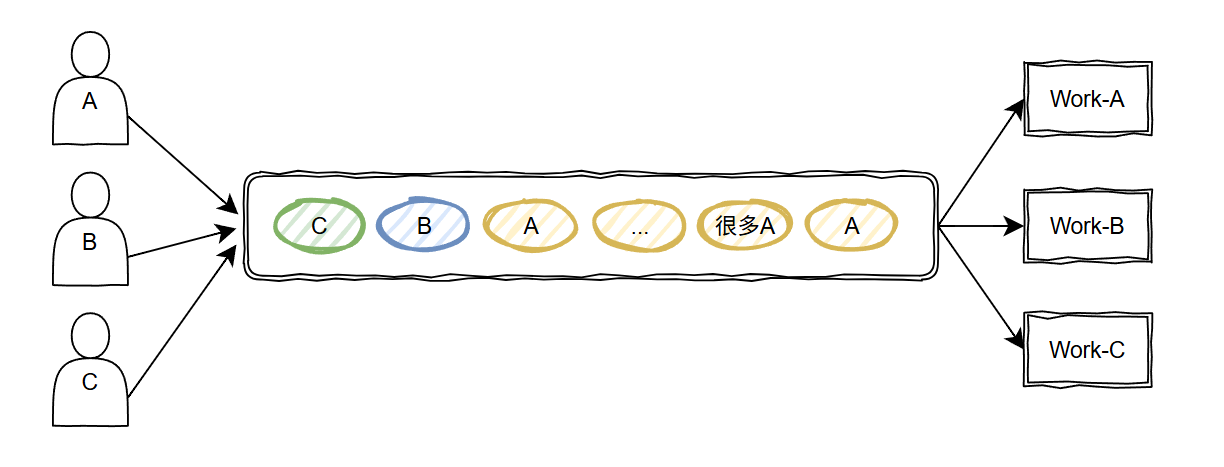
整個隊列呈現(xiàn)出的短時間內(nèi)只為 A 生產(chǎn)者服務(wù)的效果。
即 A 生產(chǎn)者“長時間霸占”了整個隊列。
很明顯,這樣對其他生產(chǎn)者不友好。
我在網(wǎng)上查詢了一下,這個現(xiàn)象還有一個專門的名詞,叫做吵鬧鄰居問題(Noisy Neighbor Problem)。
主要是指在多租戶環(huán)境中,單個用戶過度占用資源導(dǎo)致其他用戶服務(wù)質(zhì)量下降的現(xiàn)象。
常見的方案
針對這個問題,常見的方案一般有兩個。
第一個是把隊列,即“線路”分來,就像這樣:
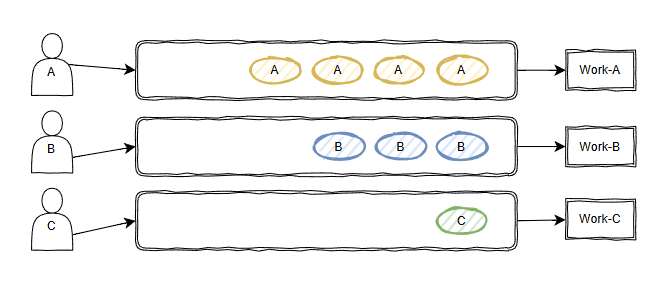
各玩兒各的,互不干擾。
沒有鄰居,也就不存在“吵鬧鄰居”的問題。
這樣可以解決問題,但是會帶來一個新的問題。
前面說了,這個“線路”是有購買成本的。
如果為每一個消費者都提供一個單獨的隊列,即上面說的“線路”,那成本就太高了。
那你可能會反駁一句:不需要為每個人提供單獨的隊列,只為高頻使用的人員提供就行了嘛。
是的,這樣也沒有毛病。
但是實際情況是,高頻使用的人, 也只是在某個小段時間內(nèi)高頻使用,隨后就是長期的閑置,浪費購買成本。
而且,在實際情況中,還會出現(xiàn)一個情況是,某個低頻使用的用戶,突然在某一段時間出現(xiàn)業(yè)務(wù)高峰。
那這種情況為了不影響其他用戶,還得緊急給業(yè)務(wù)高峰的用戶搞個專門的隊列。
運營成本太高。
所以,這個方案適用于長期穩(wěn)定都是高頻用戶的情況。
第二個方案是限制生產(chǎn)者的生產(chǎn)速度。
這個方案在解決問題的同時也帶來了新問題。
第一個問題是我需要實現(xiàn)一個限流功能,提升了基礎(chǔ)組件的復(fù)雜度。
第二個問題是由于下游有限流機制,那上游必然就要有重試機制,增加了整體系統(tǒng)的復(fù)雜度。
這兩個常見的方案,一個燒錢,一個燒腦。
我了解了之后,發(fā)現(xiàn)和我的場景都不太匹配,不能直接使用。
Amazon SQS
在我向大模型求助的時候,它給了我這樣一個關(guān)鍵詞:
智能調(diào)度算法:正如Amazon SQS所使用的公平隊列(Fair Queueing) 機制,在軟件層面確保資源被公平地分配給所有用戶,防止任何一個用戶壟斷資源。

于是我在網(wǎng)上找到了 Amazon 官方網(wǎng)站中這個文章:
https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-fair-queues.html

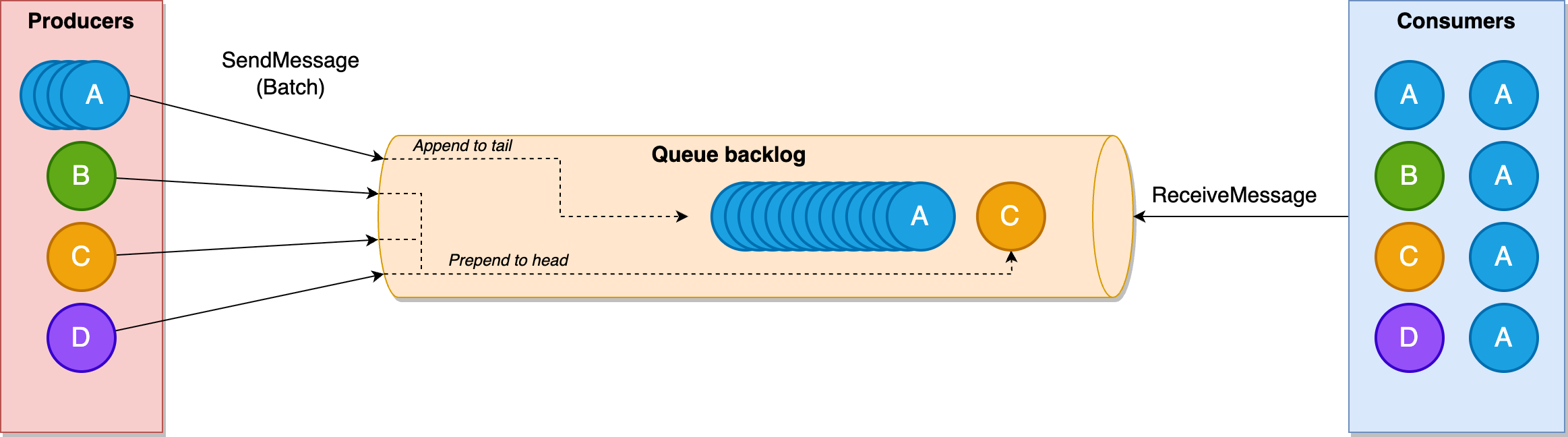
從文章中的描述看,它有一個識別誰是“吵鬧鄰居”的機制:

當(dāng)識別到 A 是一個“吵鬧鄰居”之后,Amazon SQS 會把其他租戶(B、C 和 D)的消息放在最前面。
這里的“租戶”,你可以認為就是我們前面提到的生產(chǎn)者。
這種優(yōu)先級有助于保持安靜租戶 B、C 和 D 的低停留時間,而租戶 A 的消息停留時間會延長,直到隊列積壓被消耗,而不會影響其他租戶:
看起來確實能解決我的問題。
于是追問了一下大模型關(guān)于它的問題,想要進一步了解一下底層原理:


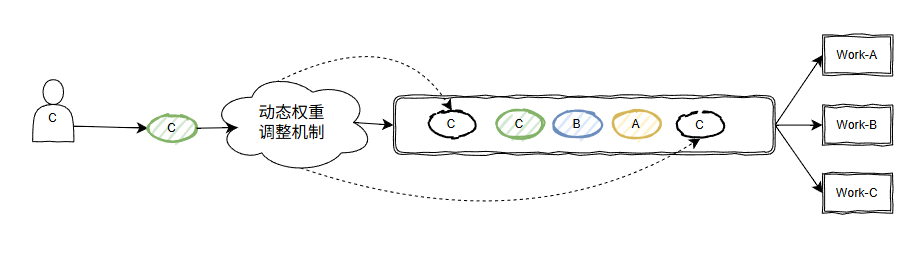
從大模型的回答來看,它核心邏輯是有一個“動態(tài)權(quán)重調(diào)整機制”。
“動態(tài)權(quán)重調(diào)整機制”的目的,我個人理解是為了給每個生產(chǎn)者一個合適的權(quán)重,從而決定這次生產(chǎn)的任務(wù)是應(yīng)該放在隊列的前面還是后面。
大概是這個意思:
初步了解之后,感覺它底層實現(xiàn)還有點復(fù)雜,我把握不住。
有一種殺雞用牛刀的感覺,所以我不打算使用它。
但是也不算白忙活,至少知道了 Amazon SQS 這個東西的存在。
換個思路
于是我在網(wǎng)上繼續(xù)搜索,找到了這篇文章,它描述的思路,完美解決了我的問題:
https://densumesh.dev/blog/fair-queue/
而且它的思路很簡單,簡單到讓我覺得如果讓我深入的思考一下,也許我也能想到這個方案。
它的核心思路,用文章中的這張圖就能說清楚:
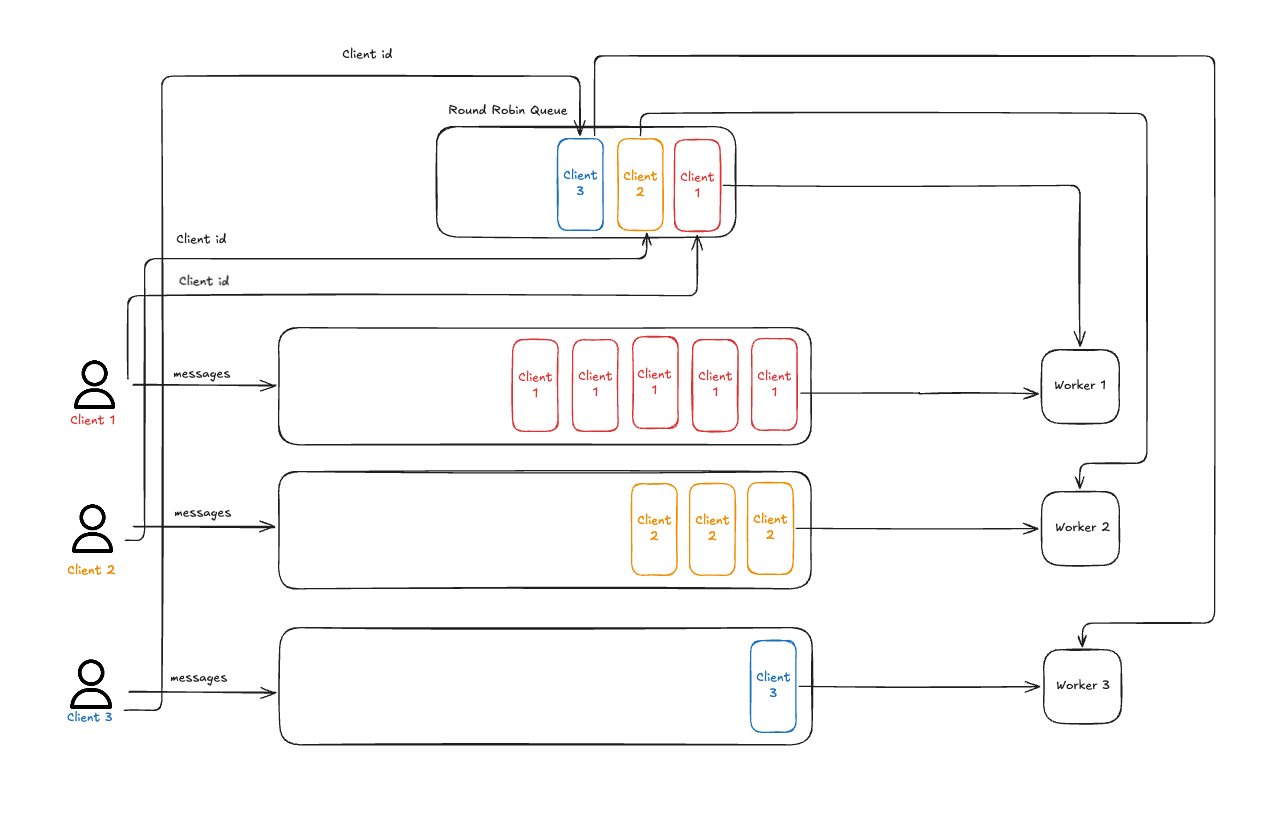
給每個生產(chǎn)者分配一個存放 messages 的隊列,同時給每個生產(chǎn)者分配一個 client id。
然后你注意看這里:
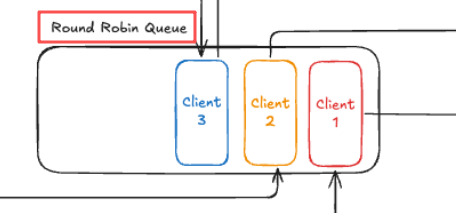
把 client id 放在一個 Round Robin Queue。
這是個什么玩意?
其實就是一個簡單的輪詢策略。
先從隊首取出 client id。
然后由選擇出的 client id 找到對應(yīng)的 work 去從對應(yīng)的隊列中取出消息來消費。
最后視情況而定,是否需要把這個 client id 放在隊尾。
由于輪詢機制,所以會確保各個生產(chǎn)者的消息是交替執(zhí)行。
作者使用 Rust 語言實現(xiàn)了上面的邏輯,并取名叫做:Broccoli。
翻譯過來是一個我不喜歡吃的蔬菜:西蘭花。
這是對應(yīng)的倉庫鏈接:
https://github.com/densumesh/broccoli
這個“西蘭花”的核心架構(gòu)非常簡單,主要有兩個主要組件:每個客戶端的專用隊列和單個輪轉(zhuǎn)調(diào)度器。
對于基礎(chǔ)組件來說,設(shè)計越簡單,就越可靠。
作者在文章中也介紹了核心邏輯的偽代碼:
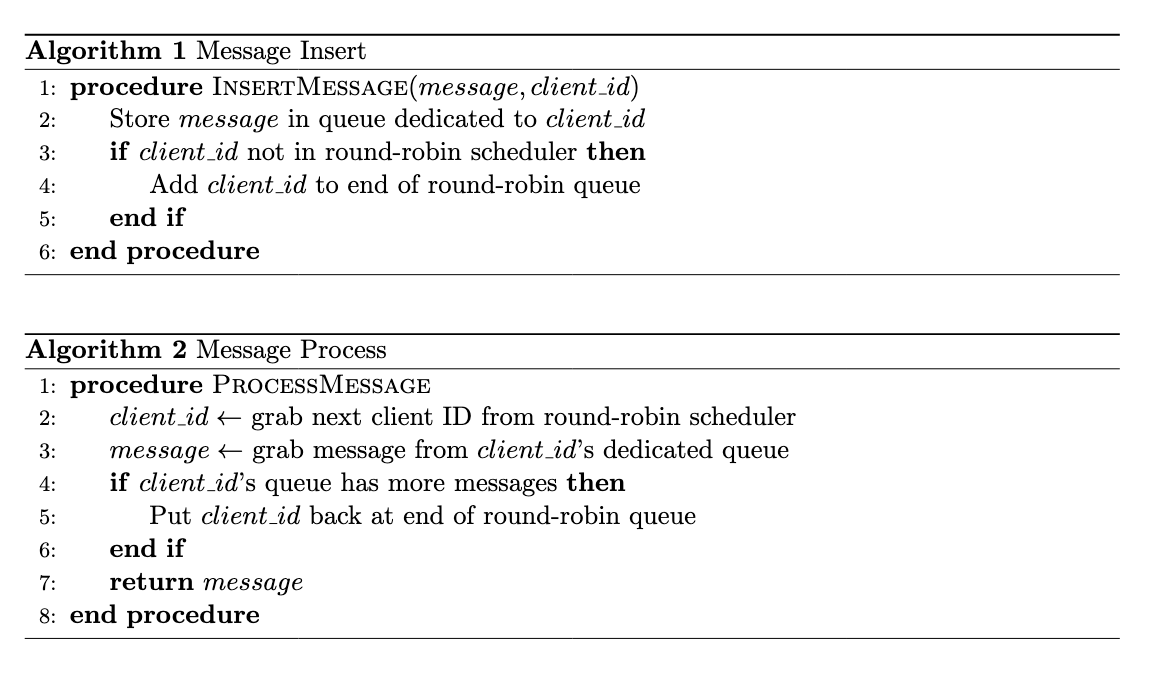
并不復(fù)雜,只有幾行代碼,我?guī)惚P一盤。
核心邏輯分為兩坨。
第一坨邏輯是產(chǎn)生新消息,對應(yīng)插入操作。
首先,將某個生產(chǎn)者新產(chǎn)生的消息存儲在一個專門的對應(yīng)生產(chǎn)者的隊列中。
然后,檢查這個生產(chǎn)者對應(yīng)的 client id 是否已經(jīng)在輪詢隊列中。
如果在,那就完事了。
如果不在,那就把這個 client id 加在輪詢隊列的末尾。
只要放到輪詢隊列里面去了,就只需要等著被調(diào)度就行了。
第二坨邏輯是消費消息。
首先,從輪詢隊列中獲取隊首的 client id。
然后,從這個 client id 的專屬隊列中獲取一條消息進行處理。
處理完畢后,檢查這個 client id 的專屬隊列是否還有消息。
如果專屬隊列空了,這個 client id 就不需要放回到輪詢隊列了。
如果專屬隊列還有消息,那把這個 client id 放回到輪詢隊列的隊尾,就完事了。
看起來邏輯確實非常簡單、清晰。
這個方法的優(yōu)點在于它完全能自我平衡。
“吵鬧的鄰居”會留在輪詢隊列中,“空閑的鄰居”會自動退出,并且無論他們排隊的工作量有多少,每個人都能公平地獲得處理時間。
看到這里有的小伙伴可能會產(chǎn)生一個疑問:前面不是說了如果為每一個消費者都提供一個單獨的隊列,即付費“線路”,成本太高了嗎?那為什么這里就可以一人一個呢?
我把上面的圖,再多畫一點出來,你就明白了:
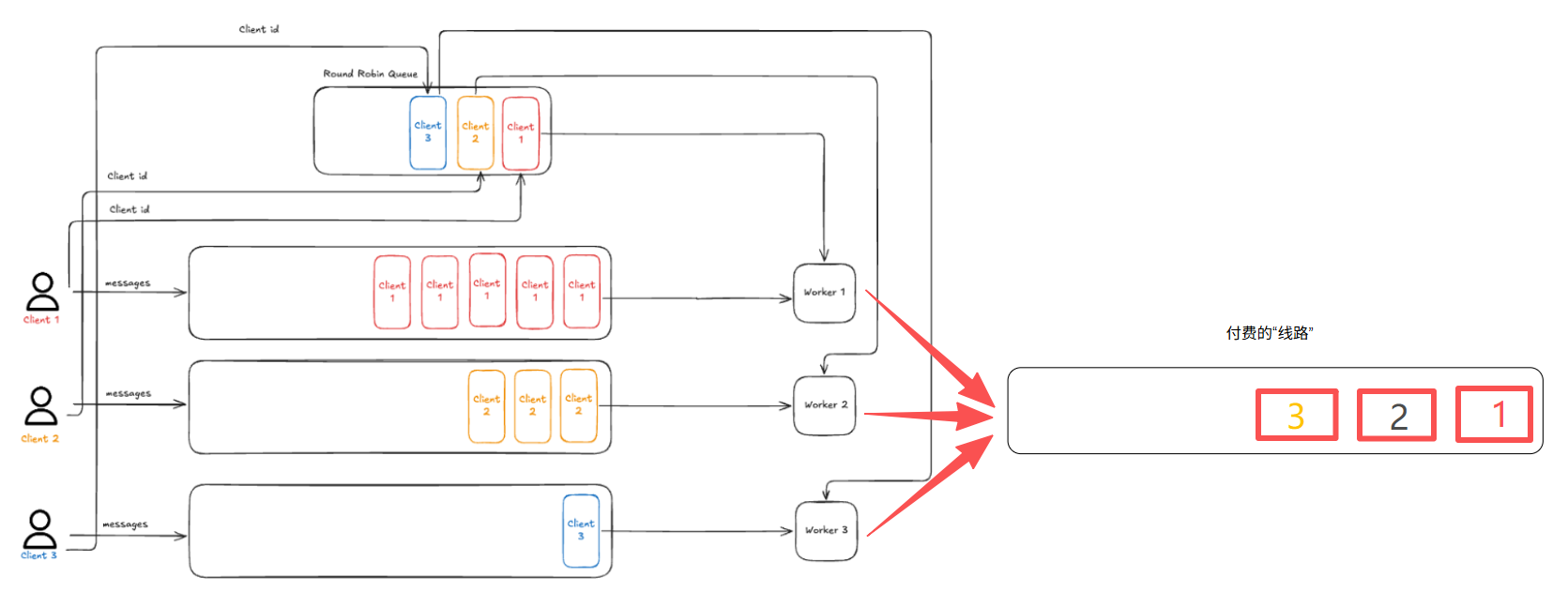
這里的“一人一個”是真的就一個隊列而已。
經(jīng)過這套邏輯之后,各個生產(chǎn)者的消息會呈現(xiàn)出交叉串行的形態(tài),再穿過真正的“付費線路”。
“付費線路”只有一條,并沒有產(chǎn)生額外的費用。
代碼
思路有了,代碼不是手到擒來的事兒嗎?
我這里也不給你粘代碼了,直接給你上個代碼截圖:
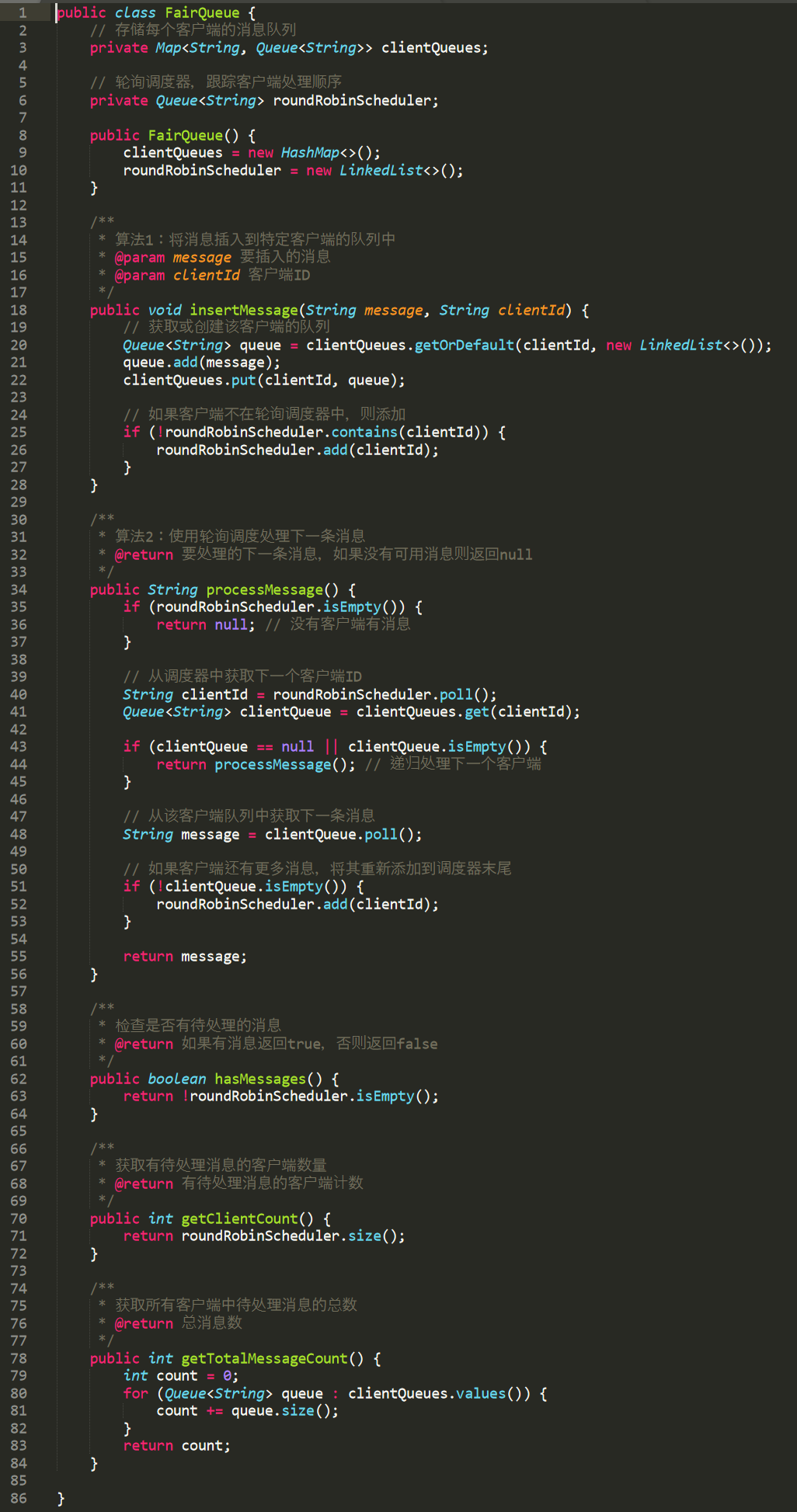
但是我可以告訴你怎么去獲取對應(yīng)的代碼實現(xiàn)。
去問大模型就行了。
我把流程示意圖和偽代碼描述直接扔給 DeepSeek:

讓它給我一份 Java 代碼,就行了:

如果你讓我按照上面的思路去敲代碼,我覺得我至少得寫 30 分鐘才能把初版寫好,而且這都算是快的。
現(xiàn)在,大模型會在一分鐘內(nèi)給你安排的明明白白:

你只需要最終檢查一下代碼邏輯就行了。
哎,我已經(jīng)忘記上次純古法手工敲代碼是什么時候的事兒了。
眼熟嗎?
另外,你有沒有發(fā)現(xiàn)這個“Broccoli”方案,有點眼熟?
這不就是操作系統(tǒng)的進程調(diào)度器玩了幾十年的經(jīng)典套路嗎?
早期的操作系統(tǒng)或某些簡單場景下,CPU 調(diào)度使用先來先服務(wù)(FCFS)策略。
先到的進程先獲得 CPU,執(zhí)行完了才輪到下一個。
如果一個“計算密集型”的進程(比如 A 用戶)拿到 CPU,它可能執(zhí)行很長時間(比如一個耗時循環(huán)),導(dǎo)致后面所有“交互密集型”的進程(比如 B、C 用戶的輕量任務(wù))都被阻塞,系統(tǒng)響應(yīng)速度急劇下降。
這不就是“吵鬧鄰居”問題的翻版嗎?
A 進程就是那個吵鬧鄰居。
為了解決 FCFS 的公平性問題,操作系統(tǒng)引入了時間片輪轉(zhuǎn)調(diào)度算法。
這幾乎和“Broccoli”的方案一模一樣。
核心思想是為每個進程分配一個固定的時間片。
進程在 CPU 上運行一個時間片后,就會被強制剝奪 CPU 使用權(quán),并排到就緒隊列的末尾,讓下一個進程運行。
對應(yīng)“西蘭花”來說:
CPU 時間片 ->你的調(diào)度器每次從用戶專屬隊列里取出一個任務(wù)進行處理。 就緒隊列 -> 你的 Round Robin Queue(輪詢隊列),里面放的是有任務(wù)待處理的用戶 ID。 剝奪 CPU 并排到隊尾 -> 處理完一個用戶的一個任務(wù)后,如果他還有任務(wù),就把他的用戶 ID 重新放回輪詢隊列的隊尾。
現(xiàn)在看這張圖,是不是感覺它就是一個微型的操作系統(tǒng)調(diào)度器?
而且,操作系統(tǒng)還有更高級的玩法——多級反饋隊列。
這可以給“西蘭花”未來的優(yōu)化提供方向:
多隊列:設(shè)置多個不同優(yōu)先級的隊列。新來的進程先進入最高優(yōu)先級隊列。 時間片不同:高優(yōu)先級隊列的時間片短(保證響應(yīng)快),低優(yōu)先級隊列的時間片長(提高吞吐量)。 反饋機制:如果一個進程在一個時間片內(nèi)用完了還沒結(jié)束,說明它可能是“長任務(wù)”,就把它降級到低優(yōu)先級隊列。如果一個進程在時間片用完前主動放棄 CPU(比如進行I/O操作),說明它可能是交互式的“短任務(wù)”,就讓它留在高優(yōu)先級隊列。
另外,操作系統(tǒng)調(diào)度磁盤 I/O 請求時,也會遇到一模一樣的問題。
如果完全按照 FIFO,某個進程的大量順序讀寫請求會霸占磁頭,導(dǎo)致其他進程的隨機讀寫請求饑餓。
解決方案之一就是電梯算法(SCAN) 或其變體,其核心也是將單個 FIFO 隊列拆解,重新排序請求,以在公平性和效率之間取得平衡。
這和我們前面的思路,可以說是同宗同源。
所以,恭喜你,無意中在應(yīng)用層瞥見了一個微內(nèi)核的操作系統(tǒng)調(diào)度器!
最后,在上個價值。
計算機科學(xué)中很多看似復(fù)雜的底層原理,其核心思想都具有極強的普適性。
真正優(yōu)秀的設(shè)計模式,會反復(fù)出現(xiàn)在從硬件到應(yīng)用、從底層到高層的各個層面。
下次再有人問你如何解決資源爭搶問題,你不僅可以甩出“西蘭花”方案,還可以淡定地補充一句:
這其實就是操作系統(tǒng)級的時間片輪轉(zhuǎn)調(diào)度算法在分布式系統(tǒng)中的應(yīng)用。我們不過是在業(yè)務(wù)層,用最低的成本,復(fù)刻了操作系統(tǒng)幾十年來驗證過的公平性智慧。

好了,就到這里了。
這個方案之前是別人的,后來變成了我的,現(xiàn)在是你的了。
不客氣,來個三連就行。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號