也是出息了,業務代碼里面也用上算法了。
你好呀,我是歪歪。
好消息,好消息,歪師傅最近寫業務代碼的時候,遇到一個可以優化的點。
然后,靈機一動,想到一個現成的算法可以拿來用。
業務代碼中能用到算法,雖然不是頭一遭,但是也真的是算難得了。
記錄一下,分享一波。
走起。

場景
場景是這樣的。
首先,我有一批數據要調用下游系統的一個統一的接口,去查詢數據狀態。
這一批數據,分屬于不同的平臺,所以調用下游查詢接口的時候,我會告訴它有的數據要去 A 平臺查詢,有的數據要去 B 平臺查詢...
大概就是這個意思:
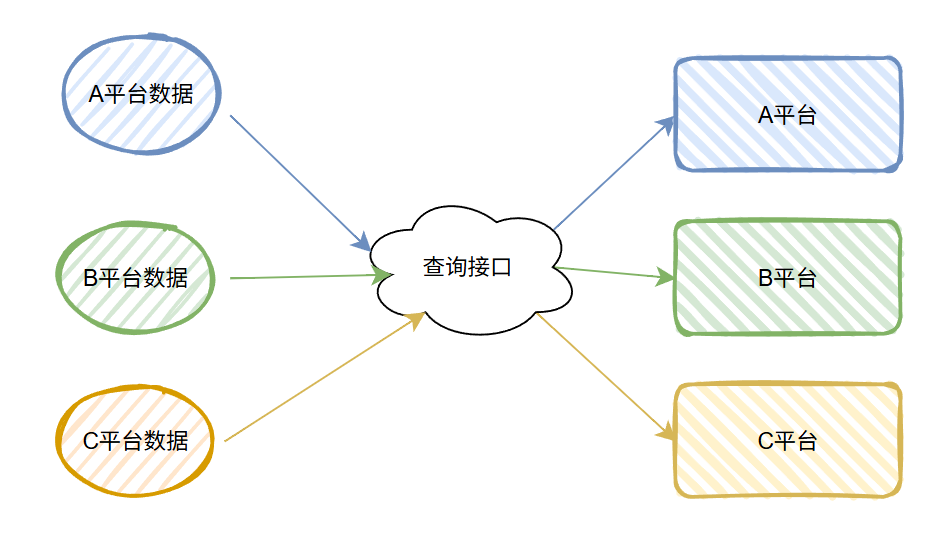
在這個場景下,我們還不用關心平臺方的同步返回結果,因為最終的結果平臺方會異步通知回來。
這樣看起來是一個非常簡單的場景對不對?
現在我們在這個基礎上加一個小小的變化。
由于這個下游系統是一個非常重要的系統,承擔著全公司所流量的出人口,可以說是咽喉要道。
所以,出于保護自身的目的,它對調用方的接口都做了限流。
對于我這個小卡拉米的、邊邊角角的查詢動作,它給的限流就是一秒最多一筆。
也就是說,我調用查詢接口的時候,線程池什么的就別想了,老老實實的排隊,然后一秒一個的發請求,
大概就是這個意思:
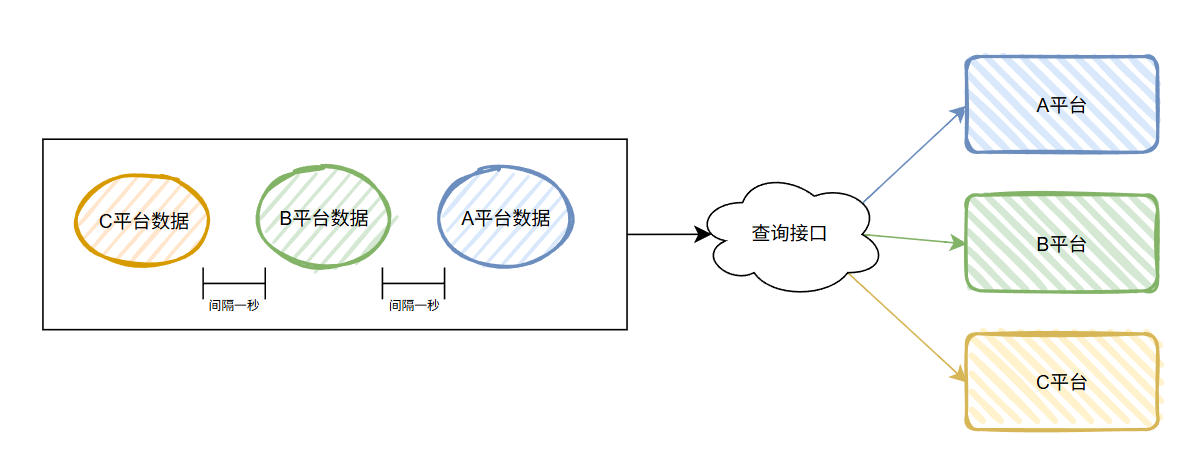
這樣看著也沒有問題,一秒一個控制起來還不簡單嗎?
優雅一點的,你就上個限流器,八股文翻出來一看,什么信號量、令牌桶、Guava RateLimiter 隨便掏一個出來用就行了。
糙一點的,你直接 for 循環里面 sleep 一秒也不是不可以。
我是一個糙人,所以我直接選擇 sleep,大道至簡。
偽代碼大概是這樣的:
// 偽代碼:從數據庫獲取某平臺數據后,在循環中每秒調用一次下游接口
public void processDataWithDelay() {
// 1. 從數據庫獲取數據(示例使用偽方法)
List<DataObject> dataList = database.fetchData("A"); // 假設返回數據列表
// 2. 遍歷每條數據
for (DataObject data : dataList) {
try {
// 3. 休眠1秒(1000毫秒)
Thread.sleep(1000);
// 4. 調用下游系統查詢接口
downstreamService.query(data.getId());
} catch (Exception e) {
}
}
}
整體來說就是先把一個平臺的數據全部處理完成后,再處理下一個平臺的數據。
用圖說話大概就是這樣的:
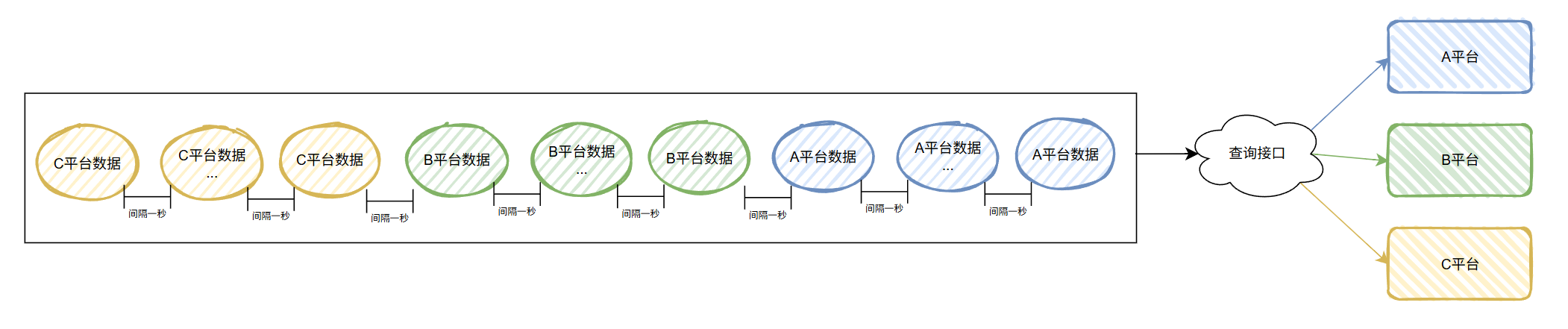
這樣看著也沒有毛病。
但是,有一天,A 平臺找過來說:哥們,你們這個查詢有點太快了,1s 一個查得我有點扛不住。能不能調一下,比如調成 6s 一次?
本來我想追問一下:就這么差勁兒嗎,一個查詢接口,一秒一個都扛不住?
但是本著程序員不難為程序員的原則,我還是忍住了。
6s 一次,這還不簡單嘛。
我把前面偽代碼中的 1000ms,修改成配置項,默認為 1000ms,如果某個平臺有個性化需求,我直接給對應平臺的配置一個專屬的間隔時間就行了:
// 偽代碼:從數據庫獲取某平臺數據后,在循環中每秒調用一次下游接口
public void processDataWithDelay() {
// 1. 從數據庫獲取A平臺數據(示例使用偽方法)
List<DataObject> dataList = database.fetchData("A平臺"); // 假設返回數據列表
// 2. 從數據庫獲取A平臺休眠時間配置(毫秒)
int sleepInterval = getSleepIntervalFromConfig("A平臺");
for (DataObject data : dataList) {
try {
// 3. 休眠
Thread.sleep(sleepInterval);
// 4. 調用下游系統查詢接口
downstreamService.query(data.getId());
} catch (Exception e) {
}
}
}
用圖說話就是這樣的:

是不是完美的解決了 A 平臺的問題?
但是,你想想這個調整之后,帶來的新問題是什么?
A 平臺假設 100 條數據,之前一秒一個,100 秒就發完了,然后 B、C 平臺的數據就能接著處理了。
現在 A 平臺的 100 條數據要發 600 秒,由于是排著隊串行執行,導致 B、C 平臺的數據,都因為 A 平臺處理慢了,得跟著慢。
整個數據處理的事件周期就長了。
而且實際情況是更長,因為每次處理的時候,A 平臺不止 100 條數據,基本上都是好幾千條。平臺也不只是 A、B、C 三家,而是有好幾家。
怎么辦?
遇到事情不要慌,三思而后行。
能不能不做? 能不能給別人做? 能不能晚點做?

我也三思了,具體是這樣的。
首先,能不能不做?
不能不做,因為已經有平臺已經問過來了,為什么數據發的比之前晚了,能不能早點?
然后,能不能給別人做?
給別人做就是找下游把接口限流放大一點,但是我這個小卡拉米的、邊邊角角的查詢動作,沒有充足的理由。可以說一秒一個都是別人看著可憐,施舍來的。再要多點,就不禮貌了。所以不能給別人做。
最后,能不能晚點做?
也不能晚點做,因為這個查詢動作背后有業務含義。業務說了,要盡快解決。技術是為了業務服務的,業務說了要盡快,就要盡快。
所以,只有自救。
思路
我們先捋一下當前的困難點。
第一個:下游系統限流,最多一秒一個卡的死死的。
第二個:有個平臺覺得一秒一個太快了。
第三個:調整了這個平臺的速率之后,影響到了其他平臺的數據處理。
現在你想想,應該怎么做?
我想到的破題之道,就是這樣的:
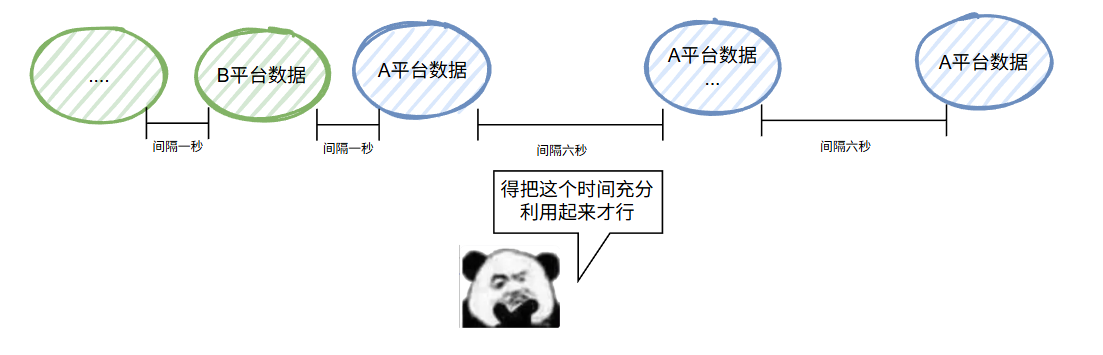
A 平臺的間隔時間調整了之后,時間其實是被白白的浪費了。
中間間隔的 6s 完全可以繼續按照一秒一個的頻率發其他平臺的數據嘛。
比如這樣的:
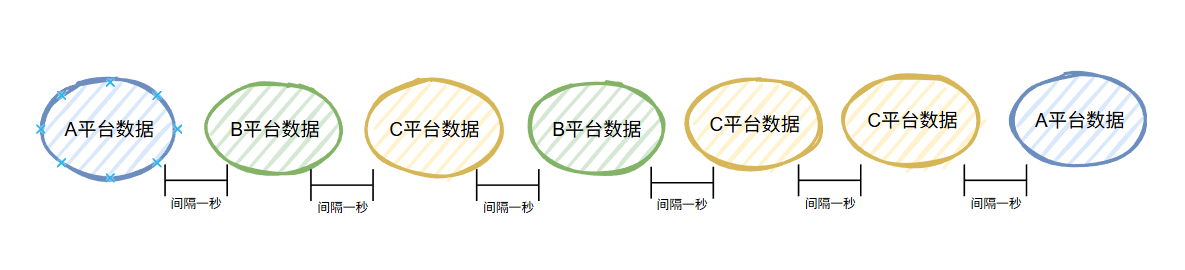
我們仔細看看上面這個圖片。
首先,一秒一個,不會觸發下游系統的限流。
然后兩個 A 平臺的數據調用間隔,也是 6s,符合要求。
中間穿插著其他平臺的數據,可以說是雨露均沾。
如果有一天 A 平臺說:6s 我也扛不住不,10s 行不行?
行啊,怎么不行。
按照這個思路,我只要把中間的 10s 充分利用起來就行。
怎么實現
思路有了,按照這個思路,我最先想到的一個實現方案就是:加權輪詢負載均衡策略算法。
如果你一時間關聯不起來這二者之間的聯系,那我給你捋一下我是怎么想的。
首先,之前是這樣的:
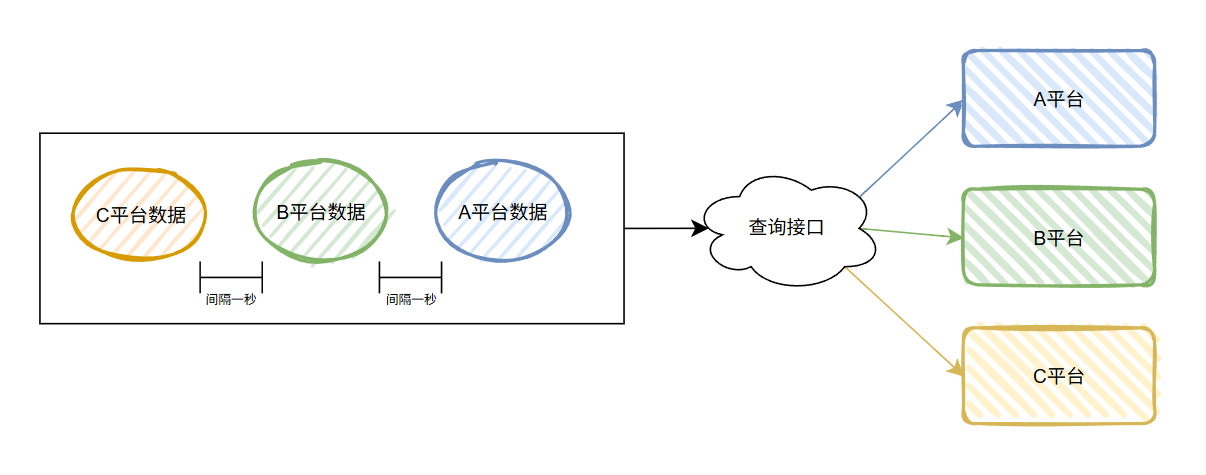
各個平臺的數據串起來,先把一個平臺的數據全部處理完成后,再處理下一個平臺的數據。
那我們是不是可以換一個思路,先獲取待處理數據的平臺集合,然后從平臺集合中每隔一秒選一個平臺出來,再獲取這個平臺的一條數據,調用查詢接口:
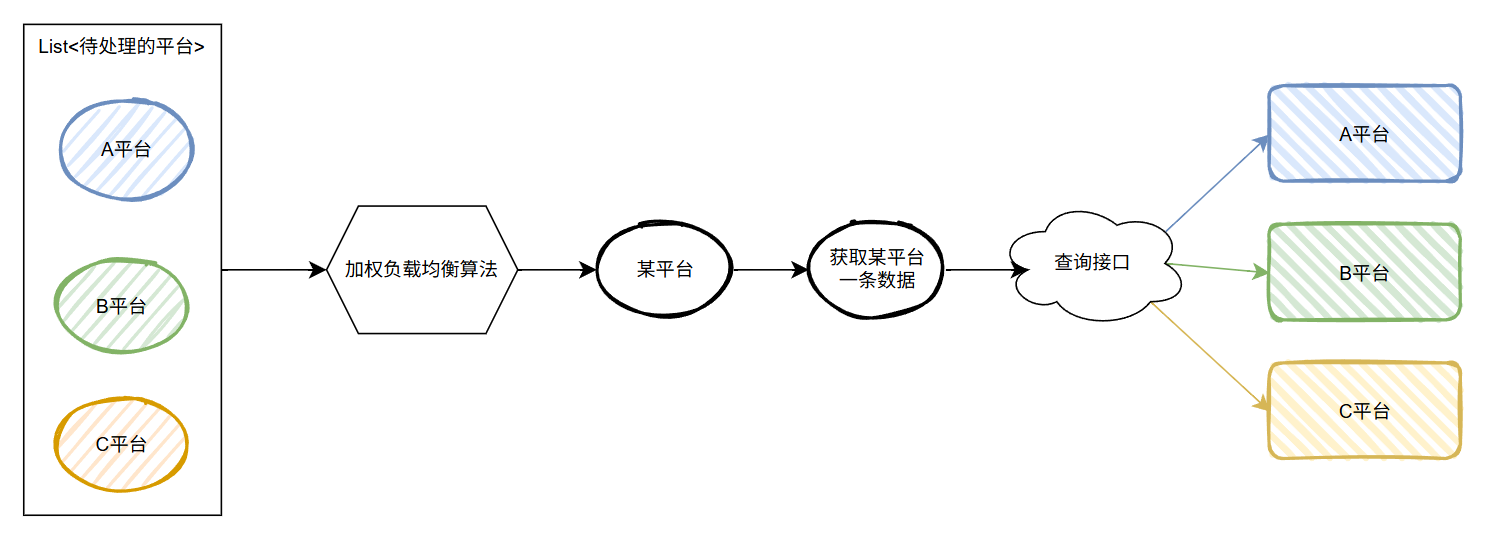
從集合中選一個出來執行,這個“選”的動作,不就和負載均衡策略非常像嗎?
然后,A 平臺要間隔 6s 才能發一條過去,其他平臺保持一秒一個。
說明什么?
說明 A 平臺處理數據的能力不行。
在負載均衡策略中,遇到性能不好的機器,怎么選擇算法?
是不是“加權輪詢策略”就呼之欲出了?
假設,就是 A、B、C 三個平臺,A 的服務水平差,它們的權重比是 A:B:C=1:2:3。
所以總權重為1 + 2 + 3 = 6。
加權輪詢負載均衡算法會根據權重比例分配請求,生成一個調用序列。
假設,我們一共調用 6 次,那么經過加權輪詢負載均衡算法,序列就是這樣的:
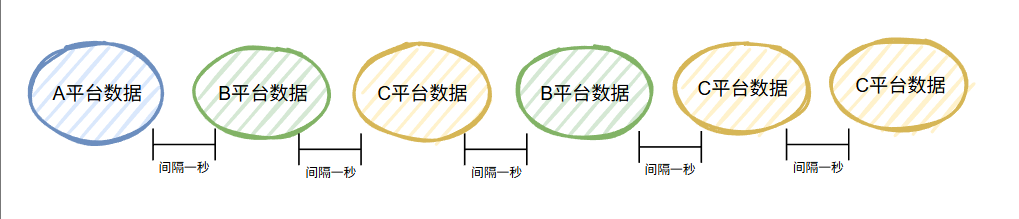
假設,我們一共調用 12 次,那么序列就是這樣的:

巧了,你看,兩次 A 平臺的數據之間剛好隔了 6s:
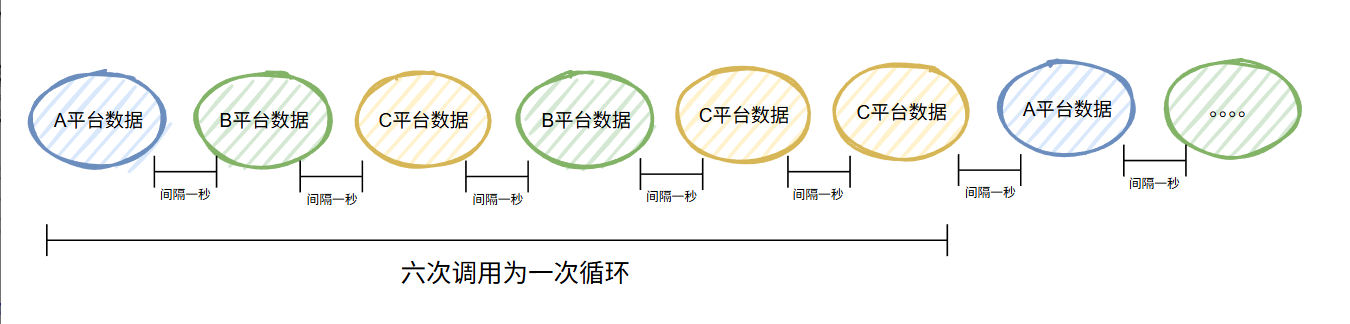
而在加權輪詢負載均衡算法的加持下,這 6s 也沒閑著,發了 5 個其他平臺的數據出去,也沒有觸發下游系統的限流。
雨露均沾,舒服了。
啥,你說你沒看懂?
那說明你不懂加權輪詢負載均衡策略的底層原理。
可以去考古一下這個文章,看看多年前歪師傅稚嫩的文筆:《加權輪詢負載均衡策略》
最后,在這里附上一個加權輪詢負載均衡策略的代碼實現,你粘過去就能跑:
public class WeightedRoundRobin {
private List<Server> servers = new ArrayList<>();
private int index = -1;
private int remaining = 0;
static class Server {
String name;
int weight;
int current;
Server(String name, int weight) {
this.name = name;
this.weight = weight;
this.current = weight;
}
}
public void addServer(String name, int weight) {
servers.add(new Server(name, weight));
remaining += weight;
}
public String getNext() {
if (remaining == 0) resetWeights();
while (true) {
index = (index + 1) % servers.size();
Server server = servers.get(index);
if (server.current > 0) {
server.current--;
remaining--;
return server.name;
}
}
}
private void resetWeights() {
for (Server s : servers) {
s.current = s.weight;
remaining += s.weight;
}
}
}
寫個 main 方法跑一跑:
public static void main(String[] args) {
WeightedRoundRobin wrr = new WeightedRoundRobin();
wrr.addServer("A平臺", 1);
wrr.addServer("B平臺", 2);
wrr.addServer("C平臺", 3);
for (int i = 0; i < 12; i++) {
System.out.println("Request " + (i+1) + " -> " + wrr.getNext());
}
}
從運行結果來看:
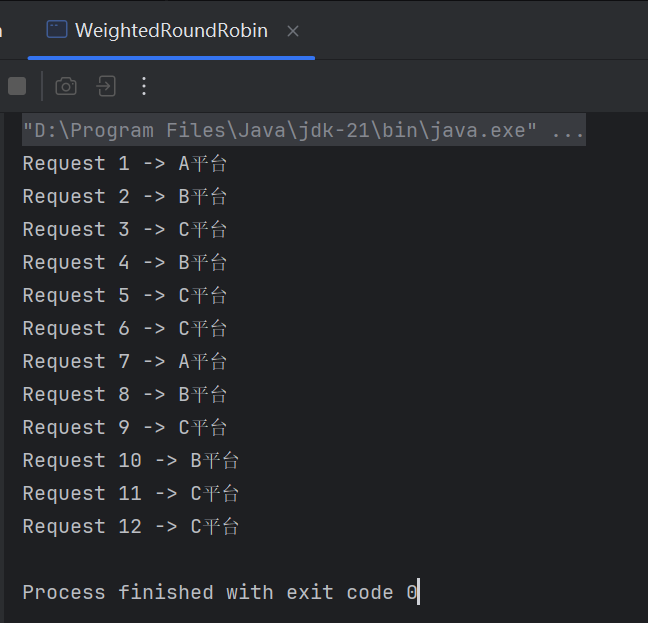
這個序列符合我們前面分析的這個序列:
兩次 A 平臺的數據之間剛好隔了 6s。
那么問題又來了,假設有一天,A 平臺繼續拉胯,說:能不能 10s 調用一次?
很簡單,只要保持總權重是 10,A 平臺的權重為 1,其他平臺的權重加起來是 9,就完事了。
比如這樣的:
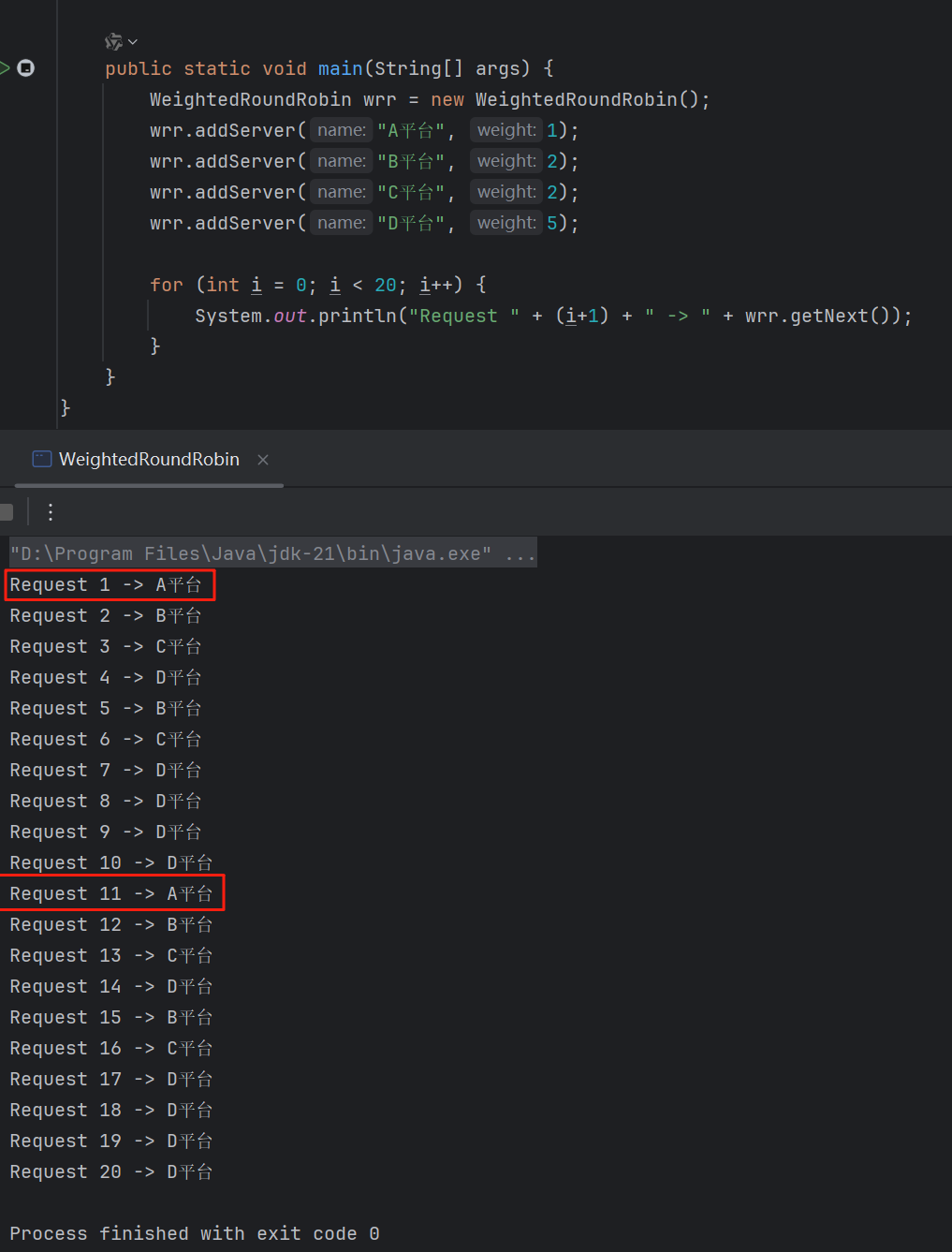
如果你足夠了解加權輪詢負載均衡策略,也許你會說:這個算法不夠平滑啊。
是的,一開口就知道是老“懂哥”了。
確實,不夠平滑。
但是,又怎樣呢?
我這個場景,又不是真正的服務器負載均衡場景,各個平臺之間完全獨立,互不影響。
當我們把負載均衡算法從服務器機房移植到我的這個場景中之后,不平滑就不平滑了。
當然,你也可以把平滑的加權輪詢負載均衡策略強加在這個場景下。
但是,殺雞焉用牛刀。
不要陷入技術完美主義的陷阱,卻忘記了所有算法都是特定語境的產物。
技術從不存在于真空之中,要結合實際場景,辯證的去看待問題。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號