
根據druid將慢sql通過釘釘的方式進行告警功能記錄
想要借助接入的druid把日志里面輸入的慢sql通過釘釘的方式進行告警,由于項目里面之前接入了druid,格式大概如下:
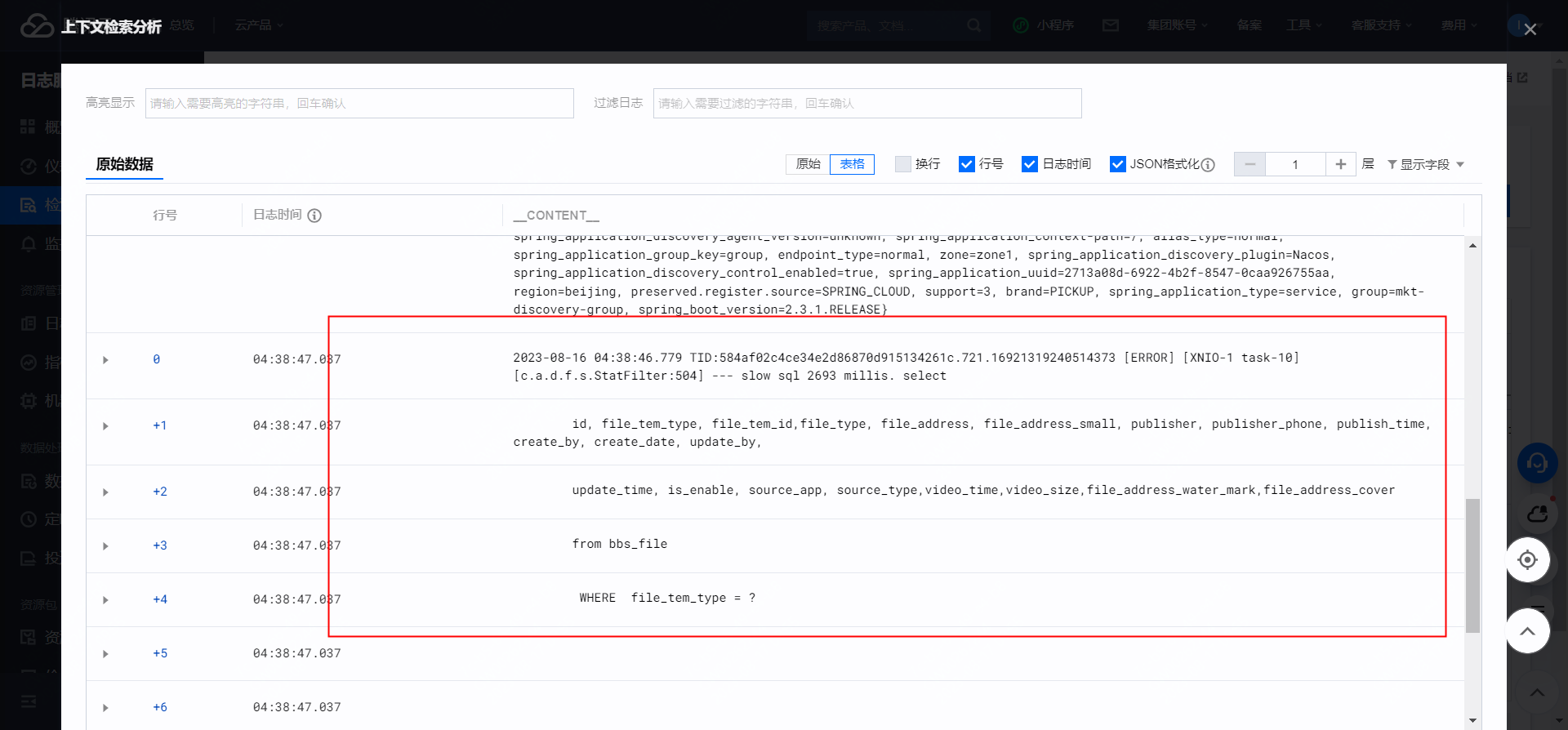
這個是接入druid并且配置了slow sql為true的情況下,日志里面打印的slow sql。剛開始我的想法是通過重寫log4j的日志來進行記錄,然后看了druid的源碼,看到這個日志是怎么打印的;最終發現不行,自己重寫子類發現dubug不進自己的重寫的方法里面;
然后又去github上面,看到有人在issue里面問這個問題,作者也給出了方式:參考(https://github.com/alibaba/druid/wiki/%E6%80%8E%E4%B9%88%E4%BF%9D%E5%AD%98Druid%E7%9A%84%E7%9B%91%E6%8E%A7%E8%AE%B0%E5%BD%95)
但是這個方法我試了,也不行。
剛開始因為對druid不是很熟悉,看到有人在issue里面提到一種方案是:通過獲取druid的日志,來定時輪詢分析里面的慢sql。獲取druid sql 日志 可以通過durid提供的接口來實現,其接口為:
List<Map<String, Object>> mapList = DruidStatManagerFacade.getInstance().getDataSourceStatDataList();
這個就是接入druid后在控制臺看到的那些sql信息,剛開始我以為是慢sql的記錄,就想如果能夠通過定時每次拉取這些慢sql,然后去定時告警不就行了? 但是如果每次都堆積慢sql,那隨著堆積越來越多,會有問題啊。于是這個方案自己給推翻了。
網上看到在druid里面可以設置一個屬性,timeBetweenLogStatsMillis。可以設置日志的刪除間隔時間,那么是不是可以通過設置該屬性,然后去定時獲取呢?
于是按照這個思路:定時去拉取里面的sql信息,對里面的sql進行解析;然后去進行告警打印。(次方案有問題,后文會再說)先把一些用到的代碼貼出來:
package com.gwm.marketing.filter.slowsql; @Data @Builder @AllArgsConstructor @NoArgsConstructor @ToString public class DruidSlowSqlDto { /**druid慢sql的id值*/ @JsonProperty(value = "ID") private Long id; /**慢sql語句*/ @JsonProperty(value = "SQL") private String sql; /**耗時分布直方圖,用于跟蹤查詢執行所花費的時間以及保持結果的時間 比如[0, 0, 2, 0, 0, 0, 0, 0], * 第一個索引位置表示小于1毫秒的時間范圍,第二個索引位置表示1毫秒到10毫秒的時間范圍,以此類推. * 這個表示2條時間范圍在10到100毫秒的數據*/ @JsonProperty(value = "ExecuteAndResultHoldTimeHistogram") private String[] executeAndResultHoldTimeHistogram; /**effectedRowCountHistogram表示查詢執行期間受影響的行數的直方圖。第一個索引位置表示受影響行數為1到10的查詢次數, * 第二個索引位置表示受影響行數為10到100的查詢次數,以此類推*/ @JsonProperty(value = "EffectedRowCountHistogram") private String[] effectedRowCountHistogram; /**Druid中表示從查詢結果中獲取的行數的直方圖,跟蹤查詢結果中行數的分布情況。第一個索引位置表示受影響行數為1到10的查詢次數, * 第二個索引位置表示受影響行數為10到100的查詢次數,以此類推*/ @JsonProperty(value = "FetchRowCountHistogram") private String[] fetchRowCountHistogram; /**耗時最久的sql執行的時間*/ @JsonProperty(value = "MaxTimespanOccurTime") private Long maxTimespanOccurTime; /**最近一次的慢sql執行時間*/ @JsonProperty(value = "LastTime") private Long lastTime; /**最后一次慢sql的where條件參數*/ @JsonProperty(value = "LastSlowParameters") private String lastSlowParameters; /**執行次數*/ @JsonProperty(value = "ExecuteCount") private Long executeCount; /**最大執行耗時 單位:毫秒*/ @JsonProperty(value = "MaxTimespan") private Long maxTimespan; /**當前并發數*/ @JsonProperty(value = "ConcurrentMax") private Long concurrentMax; /**正在執行的SQL數量*/ @JsonProperty(value = "RunningCount") private Long runningCount; /** * 根據id做分組統計次數 * @param id */ public DruidSlowSqlDto(Long id) { this.id = id; } }
package com.gwm.marketing.filter.slowsql; @Component public class SlowSqlBufferTrigger { private Logger logger = LoggerFactory.getLogger(this.getClass()); @Resource private SlowSqlConfig slowSqlConfig; private static String[] colors = { // 藍色 "#0000FF", // 紅色 "#FF0000", // 綠色 "#00FF00", // 紫色 "#FF00FF", // 青色 "#00FFFF", // 橙色 "#FFA500", // 粉色 "#FFC0CB", // 灰色 "#808080", // 黑色 "#000000" }; BufferTrigger<DruidSlowSqlDto> stringBufferTrigger = BufferTrigger.<DruidSlowSqlDto, List<DruidSlowSqlDto>>simple() .maxBufferCount(1000) .interval(50, TimeUnit.SECONDS) .setContainer(() -> synchronizedList(new ArrayList<>()), List::add) .consumer(this::slowSqlSendAlarm) .build(); private void slowSqlSendAlarm(List<DruidSlowSqlDto> list) { if (CollectionUtils.isNotEmpty(list)) { //根據druid ID做分組,統計每個慢sql次數 Map<DruidSlowSqlDto, Long> druidMap = list.stream().collect(Collectors.groupingBy(t -> t, Collectors.mapping(m -> new DruidSlowSqlDto(m.getId()), Collectors.counting()))); if (druidMap.size() > 0) { long sum = druidMap.values().stream().mapToLong(Long::longValue).sum(); String slowSqlStr = druidMap.entrySet().stream().map(m -> buildSql(m.getKey()) + "執行次數:" + m.getValue() + "次;").collect(Collectors.joining()); Tag tag = Tag.builder().applicationName(DingdingAlarmUtil.applicationName).env(DingdingAlarmUtil.env).ip(IpUtil.initIp()).build(); DingdingAlarmUtil.sendAlarm(slowSqlStr, tag, sum); } } } private String buildSql(DruidSlowSqlDto dto) { Random random = new Random(); String randomColor = colors[random.nextInt(colors.length)]; String randomTimeColor = colors[random.nextInt(colors.length)]; StringBuilder builder = new StringBuilder(); builder.append("").append("\n\n**sql語句:** <font color=").append(randomColor).append(" size=6>" + dto.getSql() + "</font>\n" + "\n\n**參數:**" + dto.getLastSlowParameters() + "\n" + "\n\n**maxTime <font color=" + randomTimeColor + " face=\"黑體\">**:" + dto.getMaxTimespan() + "毫秒</font>;\n"); return builder.toString(); } public void enqueue(DruidSlowSqlDto druidSlowSqlDto) { stringBufferTrigger.enqueue(druidSlowSqlDto); } /** * 定時掃描慢sql * * @param param * @return * @throws Exception */ @XxlJob("getSlowSqlEveryMinutesJobHandler") public ReturnT<String> getSlowSqlEveryMinutesJobHandler(String param) throws Exception { XxlJobLogger.log("get slow sql every minutes"); try { List<Map<String, Object>> mapList = DruidStatManagerFacade.getInstance().getDataSourceStatDataList(); if (mapList != null && mapList.size() > 0) { for (Map<String, Object> map : mapList) { Integer dataSourceId = (Integer) map.get("Identity"); List<Map<String, Object>> lists = DruidStatManagerFacade.getInstance().getSqlStatDataList(dataSourceId); if (lists != null && lists.size() > 0) { logger.info("存儲的sql數據量:" + lists.size() + "條"); lists.forEach(t -> { //todo 獲取ExecuteAndResultSetHoldTime當前sql的執行時間,只有sql時間大于慢sql時間在進行打印 if(t.get("MaxTimespan") != null && Long.valueOf(t.get("MaxTimespan").toString()) > slowSqlConfig.getSlowSqlMillis()){ logger.info("druid慢sql信息:" + JSONObject.toJSON(t)); DruidSlowSqlDto dto = new DruidSlowSqlDto(); try { ObjectMapper mapper = new ObjectMapper(); mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false); try { dto = mapper.readValue(JSONObject.toJSON(t).toString(), DruidSlowSqlDto.class); } catch (Exception e) { logger.error("轉換異常"); } this.enqueue(dto); } catch (Exception e) { logger.info("定時獲取慢sql異常", e); dto.setSql(t.get("SQL").toString()); dto.setLastSlowParameters(t.get("LastSlowParameters").toString()); this.enqueue(dto); } } }); } } } } catch (Exception e) { logger.error("定時獲取慢sql任務異常",e); } return ReturnT.SUCCESS; } }
其大概思路就是上文說的,通過xxljob定時拉取慢sql信息,然后將其放到內存中。(其實此處直接去進行釘釘告警就行了)。但是自己本機測試時候發現個問題:通過 DruidStatManagerFacade.getInstance().getSqlStatDataList(dataSourceId); 獲取的是
這段時間全量的sql,而不僅僅是慢sql。 那如果發到線上的話,會有問題的。段時間內大量的sql,直接給程序oom了。。。。
這樣想來想去,這個方案還是不行。這時候參考了知乎上看到別人寫的,重寫druid默認的過濾器不就行了(參考:druid集中監控所有SQL執行情況? - 羅愿的回答 - 知乎 https://www.zhihu.com/question/56749781/answer/2730085892)。durid默認的過濾器
是druid源碼自帶的statFilter.用處是在這里:
package com.gwm.marketing.config;
@Configuration
public class DruidMysqlConfig {
@Value("${spring.druid.slowSqlMillis}")
private Long slowSqlMillis;
@Value("${spring.datasource.druid.stat-view-servlet.login-username}")
private String druidUserName;
@Value("${spring.datasource.druid.stat-view-servlet.login-password}")
private String druidPassWord;
@Value("${spring.datasource.druid.timeBetweenLogStatsMillis}")
private Long timeBetweenLogStatsMillis;
/**
* 默認會掃描application.properties文件的以spring.druid開頭的數據注入;此處用的是spring的數據庫配置
* @return
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean(initMethod = "init",destroyMethod = "close")
public DruidDataSource dataSource(){
DruidDataSource dataSource = new DruidDataSource();
//todo使用自定義的攔截器,不使用默認的
// dataSource.setProxyFilters(Lists.newArrayList(statGwmFilter()));
dataSource.setProxyFilters(Collections.singletonList(slowSqlFilter()));
//設置druid的重置間隔
dataSource.setTimeBetweenLogStatsMillis(timeBetweenLogStatsMillis);
return dataSource;
}
/**
* alibaba監聽器 打印慢sql
* @return
*/
@Bean
public Filter statGwmFilter(){
StatFilter filter = new StatFilter();
filter.setSlowSqlMillis(slowSqlMillis);
filter.setLogSlowSql(true);
filter.setMergeSql(true);
return filter;
}
@Bean
public Filter slowSqlFilter(){
SqlMonitor sqlMonitor = new SqlMonitor();
return sqlMonitor;
}
/**
* 因為Springboot內置了servlet容器,所以沒有web.xml,替代方法就是將ServletRegistrationBean注冊進去
* 加入后臺監控.這里其實就相當于servlet的web.xml
* @return
*/
@Bean
public ServletRegistrationBean servletRegistrationBean(){
ServletRegistrationBean<StatViewServlet> druidServlet = new ServletRegistrationBean<StatViewServlet>(new StatViewServlet(),"/druid/*");
druidServlet.addUrlMappings();
//后臺需要有人登錄,進行配置
//設置一些初始化參數
Map<String, String> initParas = new HashMap<String, String>(8);
initParas.put("loginUsername", druidUserName);
initParas.put("loginPassword", druidPassWord);
//允許誰能訪問
initParas.put("allow", "");//這個值為空或沒有就允許所有人訪問,ip白名單
//initParas.put("allow","localhost");//只允許本機訪問,多個ip用逗號,隔開
//initParas.put("deny","");//ip黑名單,拒絕誰訪問 deny和allow同時存在優先deny
//禁用HTML頁面的Reset按鈕
initParas.put("resetEnable", "false");
druidServlet.setInitParameters(initParas);
return druidServlet;
}
}
直接重寫該filter,重寫后在這里指定使用自己的過濾器就行了。按照這個思路,重寫過濾器:
package com.gwm.marketing.filter.slowsql;
@Component
public class SqlMonitor extends FilterEventAdapter {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@Resource
private SlowSqlConfig slowSqlConfig;
@Resource
private SlowSqlBufferTrigger slowSqlBufferTrigger;
private static final String IGNORE_SQL = "SELECT 1";
@Override
protected void statementExecuteBefore(StatementProxy statement, String sql) {
super.statementExecuteBefore(statement, sql);
statement.setLastExecuteStartNano();
}
@Override
protected void statementExecuteAfter(StatementProxy statement, String sql, boolean result) {
if (IGNORE_SQL.equals(sql)) {
return;
}
final long nowNano = System.nanoTime();
final long nanos = nowNano - statement.getLastExecuteStartNano();
long millis = nanos / (1000 * 1000);
if (millis >= slowSqlConfig.getSlowSqlMillis()) {
String slowParameters = buildSlowParameters(statement);
DruidSlowSqlDto dto = DruidSlowSqlDto.builder()
.sql(sql).maxTimespan(millis).lastSlowParameters(slowParameters).build();
logger.info("slow sql " + millis + " millis. " + sql + "" + slowParameters);
slowSqlBufferTrigger.enqueue(dto);
}
}
@Override
protected void statementExecuteUpdateBefore(StatementProxy statement, String sql) {
super.statementExecuteUpdateBefore(statement, sql);
statement.setLastExecuteStartNano();
}
@Override
protected void statementExecuteBatchBefore(StatementProxy statement) {
super.statementExecuteBatchBefore(statement);
final String sql = statement.getBatchSql();
statement.setLastExecuteStartNano();
}
@Override
protected void statementExecuteBatchAfter(StatementProxy statement, int[] result) {
final long nowNano = System.nanoTime();
final long nanos = nowNano - statement.getLastExecuteStartNano();
long millis = nanos / (1000 * 1000);
if (millis >= slowSqlConfig.getSlowSqlMillis()) {
String batchSql = statement.getBatchSql();
String slowParameters = buildSlowParameters(statement);
DruidSlowSqlDto dto = DruidSlowSqlDto.builder()
.sql(batchSql).maxTimespan(millis).lastSlowParameters(slowParameters).build();
logger.info("slow sql " + millis + " millis. " + batchSql + "" + slowParameters);
slowSqlBufferTrigger.enqueue(dto);
}
}
@Override
protected void statementExecuteUpdateAfter(StatementProxy statement, String sql, int updateCount) {
if (IGNORE_SQL.equals(sql)) {
return;
}
final long nowNano = System.nanoTime();
final long nanos = nowNano - statement.getLastExecuteStartNano();
long millis = nanos / (1000 * 1000);
if (millis >= slowSqlConfig.getSlowSqlMillis()) {
String slowParameters = buildSlowParameters(statement);
DruidSlowSqlDto dto = DruidSlowSqlDto.builder()
.sql(sql).maxTimespan(millis).lastSlowParameters(slowParameters).build();
logger.info("slow sql " + millis + " millis. " + sql + "" + slowParameters);
slowSqlBufferTrigger.enqueue(dto);
}
}
@Override
protected void statementExecuteQueryBefore(StatementProxy statement, String sql) {
super.statementExecuteQueryBefore(statement, sql);
statement.setLastExecuteStartNano();
}
@Override
protected void statementExecuteQueryAfter(StatementProxy statement, String sql, ResultSetProxy resultSet) {
if (IGNORE_SQL.equals(sql)) {
return;
}
final long nowNano = System.nanoTime();
final long nanos = nowNano - statement.getLastExecuteStartNano();
long millis = nanos / (1000 * 1000);
if (millis >= slowSqlConfig.getSlowSqlMillis()) {
String slowParameters = buildSlowParameters(statement);
DruidSlowSqlDto dto = DruidSlowSqlDto.builder()
.sql(sql).maxTimespan(millis).lastSlowParameters(slowParameters).build();
logger.info("slow sql " + millis + " millis. " + sql + "" + slowParameters);
slowSqlBufferTrigger.enqueue(dto);
}
}
protected String buildSlowParameters(StatementProxy statement) {
JSONWriter out = new JSONWriter();
out.writeArrayStart();
for (int i = 0, parametersSize = statement.getParametersSize(); i < parametersSize; ++i) {
JdbcParameter parameter = statement.getParameter(i);
if (i != 0) {
out.writeComma();
}
if (parameter == null) {
continue;
}
Object value = parameter.getValue();
if (value == null) {
out.writeNull();
} else if (value instanceof String) {
String text = (String) value;
if (text.length() > 100) {
out.writeString(text.substring(0, 97) + "...");
} else {
out.writeString(text);
}
} else if (value instanceof Number) {
out.writeObject(value);
} else if (value instanceof java.util.Date) {
out.writeObject(value);
} else if (value instanceof Boolean) {
out.writeObject(value);
} else if (value instanceof InputStream) {
out.writeString("<InputStream>");
} else if (value instanceof NClob) {
out.writeString("<NClob>");
} else if (value instanceof Clob) {
out.writeString("<Clob>");
} else if (value instanceof Blob) {
out.writeString("<Blob>");
} else {
out.writeString('<' + value.getClass().getName() + '>');
}
}
out.writeArrayEnd();
return out.toString();
}
}
重寫的時候參考了druid的過濾器,然后在sql查詢執行前、更新執行前、批量查詢執行前等記錄當前時間,然后在查詢執行后、更新執行后、批量操作執行后又記錄執行后的時間,通過這個時間戳的差值計算執行的慢sql時間。如果sql時間大于設置的慢sql時間,則進行告警功能。
通過這樣的方式就不用每次輪訓了,而且也不用去定期刪除了。 這個其實就是自己剛開始想要通過重寫日志的方式來獲取原理是一樣的,重寫過濾器的方式來達到這種效果。 只是剛開始對druid這塊不熟悉。
針對告警這塊,自己總結:可以通過重寫日志(比如feign的日志)、也可以自定義一些過濾器或者監聽器來重寫,但是在重寫過濾器或者監聽器時候,要指定地方使用。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號