
多核及GPU程序設計1簡介
1 簡介
- 計算機設計的趨勢及其對軟件開發的影響。
- Flynn 分類法
- 評估多核/并行性能、加速比和效率的基本工具。
- 測量和報告性能的正確實驗程序。
- 阿姆達爾定律和古斯塔夫森-巴塞爾定律,并運用它們來預測并行程序的性能。
1.1 多核時代
自 20 世紀 80 年代以來,數字計算機一直是我們經歷的許多科技進步的基石。正如摩爾在 20 世紀 70 年代最初觀察到的那樣,它們處理信息的速度呈指數級增長,這使我們能夠解決越來越復雜的問題。
令人驚訝的是,摩爾定律甚至在今天仍然適用于描述行業趨勢,但需要澄清一個很容易被科普忽視的小問題:呈指數增長的是晶體管數量,而不是運行速度!這是一個很容易犯的錯誤,因為晶體管數量的增加伴隨著工作頻率(也稱為“時鐘”)的飛躍,這是電路小型化所適應的。然而,增加時鐘頻率會導致發熱量增加。芯片設計人員通過降低電子電路的工作電壓(目前運行電壓低至 1.29 V!)來應對,但這不足以解決問題。這不可避免地阻礙了時鐘頻率的增長,自 2000 年代中期以來,時鐘頻率一直保持在 2-5 GHz 范圍內。因此,滿足更多計算能力需求的唯一途徑是在芯片內塞入更多的計算邏輯和計算核心。自 IBM 于 2001 年推出首款雙核單芯片芯片 Power 4 以來,各種多核芯片相繼問世,既包括擁有大量內核的同構芯片,例如 64 核 Tilera TILE642,也包括為索尼Playstation 3 (PS3) 等游戲提供動力的 Cell BE 等異構芯片。

這些芯片是20世紀90年代中后期多路平臺(即可在獨立芯片上承載多個CPU的機器)的自然演進。然而,出乎意料的是GPGPU計算(General-Purpose computing on Graphics Processing Units :通用圖形處理器計算)的出現,這是一種使用圖形處理單元(GPU)進行通用計算的范例。雖然與當代CPU核心相比,單個GPU核心的性能不足,但GPU擁有大規模并行架構,擁有數百或數千個核心,并由高帶寬、高速RAM“驅動”。其結果是計算速度提高了幾個數量級!
在能源日益匱乏的今天,GPGPU還提供了一項獨特的優勢:它提供了卓越的GFlop/Watt性能,即單位能耗可以完成更多計算。這在服務器和云基礎設施領域尤為重要,因為在這些領域,CPU在其運行生命周期內消耗的能耗可能遠高于其實際價格。 GPGPU技術被認為是一項顛覆性技術,這體現在多個層面:
它能夠解決當代單核甚至多核CPU技術無法解決的問題,但它也需要新的軟件設計和開發工具及技術。預計在不久的將來,需要數百萬個線程才能掌握即將問世的下一代高性能計算硬件的計算能力!
多核芯片為我們帶來的所有這些性能并非無緣無故:它需要對算法進行明確的重新設計,而這些算法傳統上是基于單一確定性步驟序列運行的。
1.2 并行機的分類
通過利用多種資源來提升當代計算技術的性能并非新事物。早在20世紀60年代,這種探索就已開始,因此找到一種描述并行機架構特征的方法至關重要。邁克爾·弗林 (Michael Flynn) 于 1966 年提出了一種計算架構分類法,該分類法根據機器能夠同時處理的數據項數量以及能夠同時執行的不同指令數量對機器進行分類。這兩個標準的答案可以是單個,也可以是多個,這意味著它們的組合可以產生四種可能的結果:
- 單指令單數據 (SISD:Single instruction, single data):簡單的順序執行機器,每次執行一條指令,操作單個數據項。令人驚訝的是,絕大多數當代CPU并不屬于這一類。即使是如今的微控制器也提供多核配置。它們的每個核心都可以被視為SISD機器。
- 單指令多數據(SIMD:Single instruction, multiple data):每條指令應用于一組數據項的機器。矢量處理器是最早遵循這種范式的機器。GPU也遵循這種設計,例如NVidia的流式多處理器(SM)3和AMD的SIMD單元。
- 多指令單數據(MISD:Multiple instruction, single data):這種配置似乎有些奇怪。如何將多條指令應用于同一個數據項?在正常情況下,這沒有道理。但是,當系統需要容錯功能時(軍事或航空航天應用符合這種描述),數據可以由多臺機器處理,并根據多數原則做出決策。
- 多指令多數據 (MIMD:Multiple instruction, multiple data):用途最廣泛的機器類別。包括 GPU 在內的多核機器遵循此范式。GPU 由一系列 SM/SIMD 單元組成,每個單元都可以執行自己的程序。雖然每個 SM 都是一臺 SIMD 機器,但它們總體上表現得像一臺 MIMD 機器。
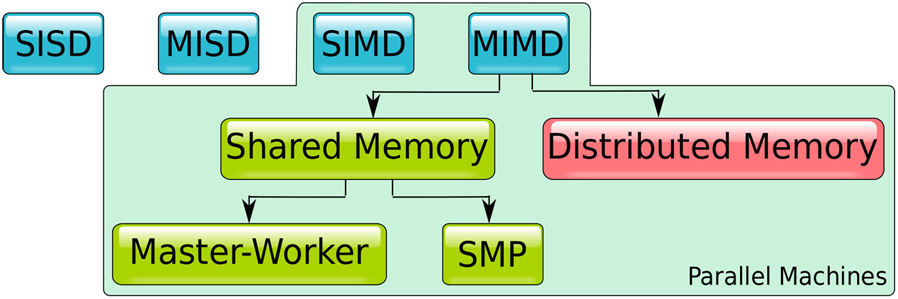
多年來,該分類法不斷完善,尤其是在 MIMD 領域增加了子類別:
MIMD 可分為兩大類:
- 共享內存MIMD
具有通用可訪問共享內存空間的機器架構。共享內存以最小的開銷簡化了 CPU 之間需要進行的所有事務,但它也構成了限制系統可擴展性的瓶頸。解決這個問題的一個方法是在CPU之間劃分內存,這樣每個CPU就“擁有”一部分內存。這樣,一個CPU可以更快地訪問其本地內存,但它仍然可以訪問其他CPU的非本地內存,盡管速度較慢。這種劃分不會影響通用的尋址方案。這種設計被稱為非均勻內存訪問 (NUMA:non-uniform memory access),它允許共享內存的機器擴展到幾十個CPU。
- 分布式內存或無共享多數據流多任務處理器 (MIMD):
由通過交換消息進行通信的處理器組成的機器。通信成本很高,但由于沒有單一的介質競爭,這種機器可以擴展,除了空間和能量限制外,沒有任何實際限制。
共享內存機器可以進一步細分為主從式和對稱多處理平臺。在后者中,所有參與的CPU都是相同的,并且能夠執行系統中的任何程序,包括系統和應用軟件。在主從架構中,一些處理器專用于執行特定軟件,也就是說,我們可以將它們視為協處理器。配備 GP的系統可以被視為屬于此類,盡管大多數高性能 GPU 平臺為 CP 和 GPU 提供了不同的內存空間。因此,它們并非共享內存平臺,盡管最近的驅動軟件進步隱藏了在兩個內存之間移動數據所涉及的大部分復雜性。
配備英特爾至強融核協處理器的機器也存在同樣的配置。英特爾至強融核協處理器的初始版本包含 61 個 Pentiu 核心,作為共享內存 MIMD 平臺運行。它安裝在 PCIe 卡上,盡管它與主機 CPU 位于同一機箱/底盤上,但組合 CPU/協處理器系統最合適的分類是分布式內存 MIMD 系統。
1.3 有影響力的計算機一瞥
當代計算機模糊了 Flynn 所列出的類別之間的界限。對更高性能的追求導致了機器既支持 MIMD 指令集,又支持 SIMD 指令集,具體取決于所處的測試級別。目前,利用微型化和半導體材料進步帶來的晶體管數量增加,主要有兩種趨勢:
-
- 增加片上核心數量,并結合增強的專用 SIM 指令集(例如 SSE 及其后續版本、MMX、AESNI、AVX 等)和更大的緩存。英特爾的 Xeon Phi 協處理器以及 AMD 的 Ryzen 和 Epyc 系列就是最好的例子。
-
- 將異構核心組合在同一封裝中,通常是 CPU 和 GPU 核心,每個核心針對不同類型的任務進行優化。AMD 的加速處理單元 (APU) 系列芯片就是最好的例子,這些芯片通常用于索尼的 PS4 和 PS5 以及微軟的 XBox One 等游戲主機。英特爾也在其集成顯卡的 CPU 系列中提供基于 OpenCL 的計算。
但是,為什么在同一塊芯片上同時配置 CPU 和 GPU 核心如此重要呢?讓我們先來討論一下 GPU 究竟能給游戲帶來什么!
GPU,也稱為圖形加速卡(graphics accelerator card),是為了在海量圖形數據被放入卡的顯示緩沖區之前對其進行快速處理而開發的。它們的設計范圍決定了其布局與傳統 CPU 的傳統布局截然不同。CPU 采用大型片上(有時是多個)內存緩存、少量復雜(例如流水線式)算術和邏輯處理單元 (ALU),以及復雜的指令解碼和預測硬件,以避免在等待數據從主內存到達時出現停頓(空閑)。相反,GPU 設計人員選擇了一條不同的路徑:小型片上緩存,以及一組能夠并行操作的簡單 ALU,因為對于圖形處理來說,數據重用率通常較低,而且程序相對簡單。為了給 GPU 上的多個核心提供數據,設計人員還專門設計了非常寬、快速的內存總線來從 GPU 的主內存中獲取數據。在 CPU 中,內存緩存占據了芯片的主導地位,而在 GPU 中,計算邏輯占據了主導地位。
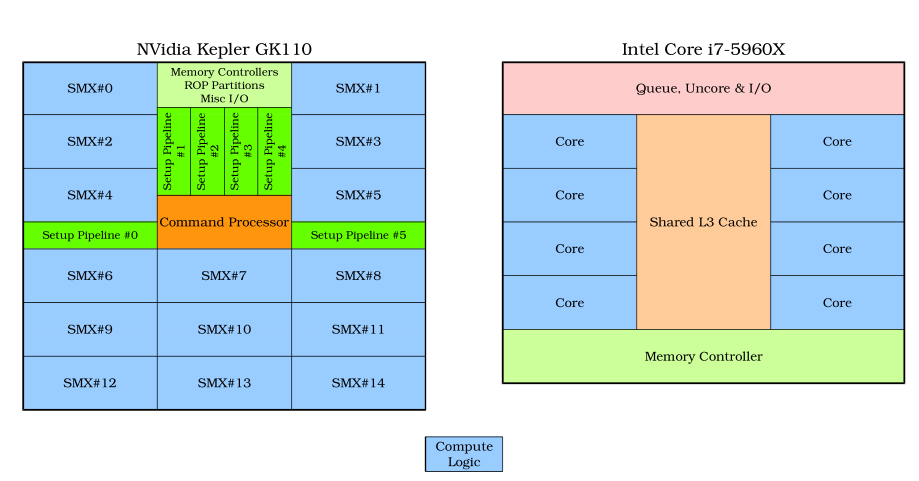
GPU 已被證明能夠提供前所未有的計算能力。然而,在系統中,它們以專用顯卡的形式使用,并通過 PCIe 等慢速總線與主 CPU 通信,這會影響其效率。原因是數據必須先在主計算機內存和 GPU 內存之間傳輸,然后 GPU 才能處理它們。這實際上創建了一個數據大小閾值,低于該閾值,GPU 就不是有效的工具。每個 SMX SIM 塊包含 192 個核心和 64 KiB 的緩存/共享內存。每個 i7 核心都包含其私有的 32 KiB 數據一級緩存和 32 KiB 指令一級緩存,以及 256 KiB 二級緩存。i7-5960X 中的共享三級緩存為 20 MiB。CPU 和 GPU 核心共享和訪問同一內存空間的重要性顯而易見。原則上,這種安排可以更好地整合計算資源,并可能帶來更高的性能,但只有時間才能給出答案。
1.3.1 Cell BE 處理器
Cell BE(寬帶引擎)處理器因驅動索尼的 PS3 游戲機而聞名,于 2007 年推出,是索尼東芝和 IBM 合資的成果。Cell 的設計遠遠超越了時代:一個主從異構 MIMD 芯片機器。PS3 游戲機配備的芯片版本包含以下內容:
- master是一個 64 位 PowerPC 核心(稱為 Power 處理單元 [PPE]),能夠運行兩個線程。它負責運行操作系統并管理工作單元。
- workers是八個 128 位矢量處理器(稱為協同處理單元 [SPE])。每個 SPE 都有自己專用的片上本地內存(而非緩存),稱為“本地存儲器”,用于保存正在運行的數據和代碼。

SPE 核心與 PPE 不二進制兼容:它們擁有專為 SIMD 操作設計的指令集。PPE 負責初始化并啟動其上的作業。SPE 通過稱為元素互連總線 (EIB) 的高速環形互連進行通信。SPE 無法直接訪問主內存,但它們可以在主內存和本地存儲之間執行 DMA 傳輸。
該硬件的設計目標是實現最高的計算效率,但卻犧牲了編程的簡易性。Cell 因其是最難編程的平臺之一而臭名昭著。
Cell 在推出時是市場上最強大的處理器之一,八個 SPE 合計的雙精度運算峰值性能高達 102.4 GFlops。它很快成為以 PS3 集群形式構建“廉價超級計算機”的組件。這些機器上運行的應用程序包括天體物理模擬、衛星成像和生物醫學應用。值得注意的是,IBM Roadrunne 超級計算機是 2008-2009 年間全球速度最快的超級計算機,它包含 12.24 臺 PowerXCell 8i 處理器和 6562 臺 AMD Opteron 處理器。PowerXCell 8i 是原始 Cell 的增強版,改進了雙精度浮點運算能力點性能。
Cell 處理器已停止開發,可能是由于其編程復雜性和 GPU 計算技術的進步。
1.3.2 NVidia 的 Amper
Ampere 是 NVidia 專為計算應用設計的第八個 GPU 架構。對于初學者來說,這種新架構和之前的架構一樣令人驚訝!只有當人們嘗試編寫這種設計的程序時,它與“傳統” SMP 芯片的區別才會變得顯而易見。在本節中,我們將了解使這款 GPU 和其他 GPU 成為強大計算機器的架構特性。
Ampere GPU 中的內核按稱為流多處理器 (SM: Streaming Multiprocessors) 的組排列。每個 Ampere SM 包含 64 個內核,這些內核以 SIMD 方式執行,即它們運行相同的指令序列,但處理不同的數據。不過,每個 SM 都可以運行自己的程序。SM 塊的總數是同一系列不同芯片之間的主要區別因素。目前,安培系列中最強大的芯片是 A100 GPU,它啟用了 108 個 SM,最多可啟用 128 個,以提高生產良率。這意味著每個 A100 GPU 總共配備 108·64=6912 個核心!這些核心的雙精度運算峰值性能為 9.7 TFlops,使用張量核心時可提升至 19.5 TFlops 。張量核心是一種專門用于快速執行乘法和累加運算的單元,以滿足人工智能 (AI) 應用程序的要求。張量核心首次出現在 NVidia 的 Volta 架構中。
GPU 用作協處理器,從主 CPU 分配工作項。在這種情況下,CPU 被稱為主機。如果讓代碼為這 6912 個核心分別生成一個線程,會顯得有些笨拙。相反,GPU 編程環境允許啟動稱為內核的特殊函數,這些函數使用不同的內部/內置變量運行。事實上,單個語句/內核啟動可以生成的線程數量高達數萬甚至數百萬。每個線程將輪流在 GPU 核心上運行。

該順序可以概括為主機 (a) 向 GPU 發送數據 (b) 啟動內核,以及 (c) 等待收集結果。
截至 2021 年 6 月,排名前九的最強大的超級計算機按其最大交付 TFlop/KW 比率降序排列如下:

為了加速線程執行,片上內存配置旨在將數據“靠近”核心。該片上內存子系統包含一個大型寄存器文件,每個線程可分配 255 個 32 位寄存器,并配備 40 MB 二級緩存以降低延遲。Ampere 與傳統 CPU 的最大區別在于其組合式一級緩存/共享內存。這是每個 S 獨有的,其分區可由主機通過編程控制。共享內存對應用程序而言并不像緩存那樣透明。它是可尋址內存,可以被視為一種用戶管理的緩存。
192 MB 的一級緩存/共享內存與不久前每個 SM 僅有 16 MB 共享內存的 GP 設計相比,是一個巨大的飛躍。多年來,我們在 GPU 設計中見證了更大、更復雜的緩存層級、更強大的核心(Kepler,2012 年的架構,每個 SM 擁有 192 個核心)以及專用硬件/指令集(張量核心)的加入。GPU 正變得越來越像 CPU,反之亦然!
GPU 的一個普遍特征是能夠以更少的資源實現更高的性能:以更少的能耗完成更多的計算。這在高性能計算 (HPC) 領域至關重要,因為該領域的能耗成本遠低于硬件本身的成本,這使得 GPU 成為數字運算的首選。
就 A100 而言,通過將設備內存與 GPU 連接在同一基板上,效率得到了進一步提升。GPU 與六個第二代高帶寬內存 (HBM2:second-generation high bandwidth memor) 模塊耦合,從而降低了與 GPU 之間數據傳輸所需的功耗。

1.3.3 從多核到眾核:TILERA 的 TILE-Gx8072 和英特爾的 Xeon Phi
GPU 十多年來一直承載著數百或數千個(雖然很簡單)計算核心。但它們可以在圖形工作負載等特殊情況下保持高效運行。對于通用計算平臺而言,實現同樣的性能能夠運行操作系統任務和應用軟件的 ose CPU 則完全是另一回事。兩種成功實現這一壯舉的設計都采用了硅片,這種眾所周知的網絡配置在過去幾十年中一直用于構建并行機器。這是一個小型化的成功案例。
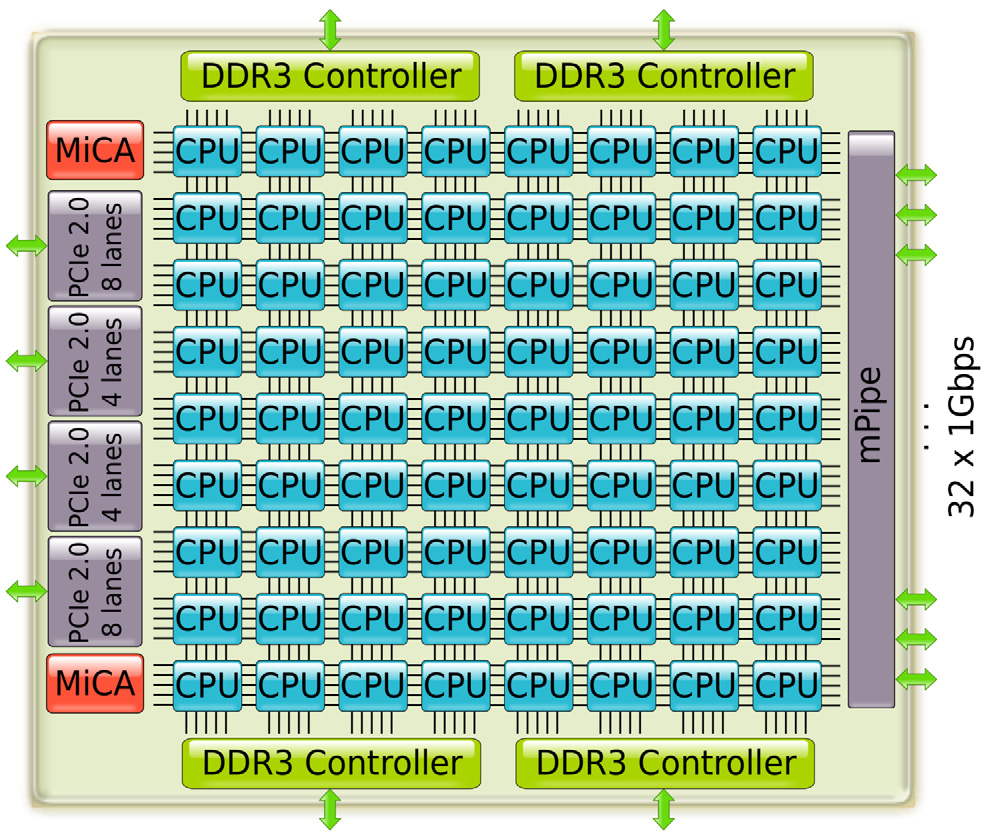
多核范式的首個體現是 TILERA 的 TILE64 協處理器,于 2007 年 8 月發布。TILE64 提供 64 個內核,以二維網格排列。TILERA 后來提供的設計采用了不同的配置,包括 9 核、16 核、36 核和 72 核。72 核版本(即 TILE-Gx8072,4)的框圖如圖。被稱為 iMesh Interconnect 的二維通信信道網格包含五個獨立的網狀網絡,可提供超過 110 Tbps 的總帶寬。通信通過無阻塞直通交換完成,每跳一個時鐘周期。每個核心擁有 32 KiB 數據和 32 KiB 指令一級緩存以及 256 KiB 二級緩存。核心之間共享 18 MiB 三級一致性緩存。通過四個 DDR3 控制器訪問主 RAM。
TILE-Gx8072 CPU 的目標應用是網絡(例如,過濾、節流)、多媒體(例如,轉碼)和云應用。網絡功能備受關注,其 32 個 1 Gbps 端口、8 個 10 Gbps XAUI 端口以及兩個專用壓縮和加密加速引擎 (MiCA) 就是明證。
與 GPU 一樣,TILERA 的芯片可以用作協處理器,從主 CPU/主機卸載繁重的計算任務。它提供四個多通道 PCIe 接口,可加速與主機之間的數據傳輸。它還可以用作獨立平臺,因為它運行Linux內核。TILERA提供其多核開發環境(MDE)作為其芯片的軟件開發平臺。MDE基于開源軟件(OSS)工具構建,例如GNU C/C++編譯器、Eclips IDE、Boost、線程構建塊(TBB)和其他庫。因此,它利用現有的多核開發工具,并與多種語言、編譯器和庫保持兼容。第3章和第8章介紹了適用于TILERA芯片軟件開發的工具和技術。
英特爾進入多核領域的時間要晚得多(2012 年),英特爾至強融核推出時,它是 Top50 榜單前 10 名超級計算機中的 2 臺的構建模塊。至強融核配備 61 個 x86 核心,這些核心是高度定制的奔騰核心。定制包括能夠同時處理四個線程以隱藏管道停頓或內存訪問延遲,以及一個特殊的 512 位寬矢量處理單元 (VPU),它以 SIMD 模式運行,每個時鐘周期處理 16 個單精度或 8 個雙精度浮點數。VPU 還具有擴展數學單元 (EMU),用于處理超越函數,例如矢量上的倒數、平方根和指數函數。每個核心配備 32 KiB 數據一級緩存和 32 KiB 指令一級緩存,以及 512 KiB 二級緩存一致性緩存。
這些核心通過另一種著名的通信架構連接,該架構也用于 Cell BE 芯片:環。該環是雙向的,實際上由六個獨立的環組成,每個方向三個。每個方向都有一個 64 字節寬的數據環和兩個較窄的環:一個地址環 (AD) 和一個確認環 (AK)。AD 環用于發送讀/寫命令和內存地址。AK 環用于保持二級緩存一致性。一致性由分布式標簽目錄 (TD) 管理,其中包含有關芯片上每個二級緩存行的信息。
當某個核心發生二級緩存未命中時,它會通過 AD 環向標簽目錄發送地址請求。如果請求的數據塊位于另一個核心的二級緩存中,則會通過 AD 環向該核心的二級緩存發送轉發請求,隨后請求的數據塊會通過數據環轉發。如果請求的數據不在芯片上,則內存地址會從標簽目錄發送到內存控制器。
冗余設計(即每種類型的環各有兩個)確保了可擴展性,因為測試表明,僅使用 AK 和 AD 類型的環會導致性能在 30 到 35 個核心左右時趨于平穩。GDDR5 內存控制器跨核心交錯排列,并通過這些環進行訪問。內存地址在各個控制器之間平均分配,以避免任何一個控制器成為瓶頸。
硬件性能令人印象深刻。但如何對 61 個核心進行編程呢?至強 Ph 協處理器以運行 Linux 的 PCIe 卡形式提供。特殊的設備驅動使 PCIe 總線作為網絡接口,這意味著協處理器在主機看來就像另一臺通過網絡連接的機器。用戶可以使用 SSH 登錄 Xeon Phi 主機!

應用程序可以在主機上運行,并將部分內容卸載到 Xeon Phi 卡上,也可以完全在協處理器上運行,在這種情況下,它們被稱為以“本機模式”運行。Xeon Phi 利用所有現有的共享和分布式內存工具的基礎設施。人們可以使用線程、OpenMP、Intel TBB、MPI 等為其構建應用程序。這也是多核架構相對于 GPU 的一大優勢,因為后者需要掌握新的工具和技術。
最后,值得注意的是所有承載多核的架構都有一個共同的特點:相對較低的時鐘頻率。 GPU(0.8-1.5 GHz)、TILE-Gx8072(1.2 GHz)和英特爾至強融核(1.2-1.3 GHz)均具備這一特性。這是在同一塊芯片上塞入數十億個晶體管所必須付出的代價,信號傳播延遲會增加。
英特爾于2017年停止了至強融核的開發。然而,為其開發的許多架構特性已經滲透到主流桌面和服務器計算處理器設計中。
1.3.4 AMD 的 Epyc Rome:利用更小的芯片進行擴展
在 CPU 或 GPU 芯片封裝內塞入越來越多的計算邏輯是該行業的驅動原則。這導致芯片的表面積變得巨大。盡管 7 納米工藝和即將推出的 5 納米節點工藝不斷發展。例如,英特爾 8086 CPU 是 20 世紀 80 年代微型計算機的熱門選擇,采用 3 微米(3000 納米)工藝制造,表面積為 16 平方毫米。相比之下,采用 10 納米工藝制造的集成顯卡的英特爾 Ice Lake CPU,表面積約為 122 平方毫米。反過來,更大的芯片往往會產生更多的制造缺陷,從而降低良率(生產的良品率與缺陷品率),并推高價格。
AMD 于 2017 年提出了解決這個問題的解決方案,即用于生產第一代 Epyc Naples CPU 的多芯片模塊 (MCM:multi-chip module)。MCM CP 不是將所有邏輯都集成在一塊硅芯片上的單片 CPU,而是由多個較小的芯片(小芯片)連接在一起,以提供預期的全部功能。由于芯片體積小,因此可以實現更高的良率。此外,它們還可以以不同的配置連接,從而構成不同功能和價位的 CPU。
2019 年底發布的第二代 Epyc CPU 令人耳目一新:7742 型號在單個封裝中集成 64 個核心和 256 MB 三級緩存,基本主頻為 2.25 GHz,最高可加速至 3.4 GHz。每個芯片的正式名稱是核心復合體 (CCD),它包含兩個核心復合體 (CCX) 部分。每個 CCX 包含四個 Zen2 核心、它們各自的專用二級緩存以及它們共享的三級緩存。
實際上,這種設計使用片上系統 (SoC) 來實現過去多路服務器平臺復雜且昂貴的電路。雖然從技術上講這是一個單 CPU 封裝,但存在不相交的 L3 緩存,這意味著數據緩存局部性是線程布局的重要決策因素。因此,該芯片可以在軟件中以四種不同的方式配置為 NUMA 平臺,從將整個 CPU 視為單個 NUMA 域(即,好像所有節點都以相同的成本訪問所有可用內存),到將其分成每個 CCX 一個 NUMA 域,總共 16 組四個核心。

1.3.5 富士通 A64FX:計算和內存集成
富士通的 A64FX 是一款基于 ARM 的處理器,為本文撰寫時世界上最強大的機器——日本的富岳(Fugaku)提供動力。 A64FX 通過以下方式實現如此高的性能:(a) 實現帶有 512 位可擴展矢量擴展指令集 (SIMD 指令,類似于英特爾的 AVX);更重要的是,(b) 將 CPU 與 32 GiB 的 HBM2 內存緊密集成,能夠為核心提供 1 TiB/秒的帶寬(每個 HBM2 模塊 256 GiB)。這種方法類似于 NVidia A100 加速器的內存連接方式,但這并非該 CPU 與當代 GPU 的唯一相似之處。A64FX 由四個核心內存組 (CMG) 組成,總共提供 52 個核心 [52]。每個 CMG 包含 12 個計算核心和一個輔助核心,后者負責執行操作系統任務(例如 I/O 等)。由于每個 CMG 直接連接到 HBM2 模塊,因此無需使用 L 緩存,從而節省了硅片空間和運行所需的能耗。四個 CMG 模塊通過網絡內部連接,其連接方式與之前的 Cell BE 和 Xeon Phi 類似。

內存和 CPU 共享多核意味著存儲器容量和速度不再是設計能力或關注點,而是在速度、能效、散熱和封裝方面具有巨大優勢,而這些因素都是惠普設備的關鍵因素。

1.4 性能指標
推動多核硬件和軟件開發的動機是提取更高的性能:更短的執行時間、更大的問題和數據集等。顯然,需要一個或多個客觀標準來評估這些努力的有效性或益處。
至少,并行程序應該能夠在執行時間方面勝過其順序程序(但這不是每次都能拿到銀行的東西)。執行時間的提升通常以加速比 (speedup) 來表示,其正式定義為以下比率:

其中,t-seq 是順序程序的執行時間,t-par 是并行程序的執行時間,用于解決同一問題實例。
tseq 和 tpar 均為實際時間,因此并非客觀數據。它們可能受以下因素影響:
- 編寫實現的程序員的技能 ?
- 編譯器的選擇(例如,GNU C++ 與 Intel C++) ?
- 編譯器開關(例如,打開/關閉優化) ?
- 操作系統
- 保存輸入數據的文件系統類型(例如,EXT4、NTFS 等) ?
- 時間(不同的工作負載、網絡流量等)。
為了對報告的加速比數據有一定程度的信心,應遵循以下規則:
- 所有程序(順序和并行)都應在相同的軟件和硬件平臺上,并在類似的條件下進行測試。
- 順序程序應是已知問題中最快的解決方案。
第二個要求是兩者中最不明顯的,但卻是一個至關重要的要求:并行算法與順序算法完全不同。事實上,順序算法可能沒有并行派生算法。甚至并行派生算法根本不可能被創建。第二個要求背后的原因是一個根本性的原因:實現并行程序所需的大量工作(就開發成本而言,高昂的工作量)只有在能夠帶來切實的收益時才是合理的。
對于給定數量的處理器,并行算法提供的加速比仍然會根據輸入數據而變化。因此,通常在對大量相同規模的輸入測試兩個程序后,報告其加速比的平均值,或者甚至報告觀察到的平均值、最大值和最小值。
加速比僅能說明部分問題:它可以告訴我們加速問題的求解是否可行,例如,加速比是否大于 1。它無法告訴我們是否可以高效地完成求解,即是否可以使用少量資源。為此目的采用的第二個指標是效率。效率的正式定義為以下比率:

其中,N 是用于執行并行程序的 CPU/核心數量。效率可以理解為并行執行期間節點被利用時間的平均百分比。如果效率等于 100%,則意味著加速比為 N,工作負載在 N 個處理器之間平均分配,這些處理器的利用率為 100%(執行期間從不空閑)。當加速比 = N 時,相應的并行程序表現出所謂的線性加速。
遺憾的是,這只是理想情況。當多個處理器共同努力實現某個目標時,它們需要花時間相互協調,無論是圖 1.1 (a) 加速比曲線,還是 (b) 效率曲線,它們都用于在多核 CPU 上通過可變數量的線程執行并行積分計算。每條曲線對應于 x 范圍的不同劃分數(如圖例所示)。(a) 中的理想加速比線衡量了性能下降,這是協調成本增加的一個常見問題。通過交換消息或處理共享資源。與活動相關的協調會占用 CPU 時間,最終導致加速比低于 N。
下圖展示了一個示例程序的加速比和效率曲線,該程序通過應用梯形規則算法計算函數的定積分。
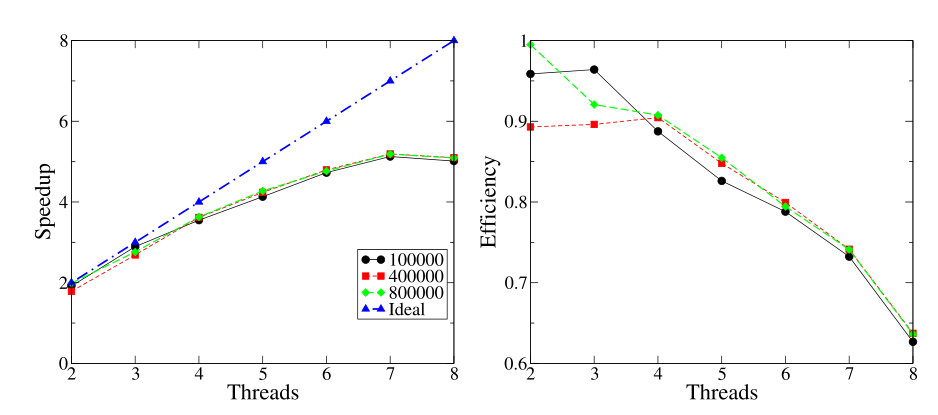
計算負載由計算中使用的梯形數量控制。結果是在 i7 950 四核 CP 上獲得的,并且是 10 次運行的平均值。對于謹慎的讀者來說,這里有一個矛盾之處:如果我們只有四核 CPU,如何測試和報告八個線程的加速比?i7 950 四核 CPU 支持一種稱為超線程的技術,6 該技術允許一個 CPU 內核通過復制CPU 硬件的各個部分。啟用此功能的 CPU 看起來擁有實際兩倍的物理核心數。遺憾的是,性能平均只提高了 30%,與建議的兩倍提升相差甚遠。因此,上圖報告的結果存在偏差,因為在給定平臺上,我們并沒有 8 個不同的物理 CPU 來運行 8 個線程。
然而,隨著線程數增加,效率下降并非偶然:這是并行應用程序的典型行為,盡管下降程度因應用程序而異。這一切都歸結于我們通常所說的協調成本,而這只有在更多參與方/CPU 相互通信時才會增加。超線程是英特爾創造的一個營銷術語,指的是所謂的硬件線程。
上圖有兩個用途:(a) 它展示了典型的速度和效率曲線;(b) 它提高了人們對正確實驗技術的認識。衡量性能應該涉及真實的硬件資源,而不是超線程提供的虛擬資源。
上圖中的理想加速曲線衡量了并行程序的成功程度。正如我們提到的,這是性能的上限。但并非總是如此!在某些情況下,加速比 > N,效率 > 1,這被稱為超線性加速場景。根據我們對效率的解釋,這似乎是不可能的。然而,我們應該記住,順序程序和并行程序以不同的方式處理其輸入數據,遵循不同的執行路徑。因此,如果程序的目標是在搜索空間中獲取某個對象,那么并行程序可能只需遵循不同的路徑即可比所用計算資源數量所暗示的更快地達到這一點。
加速比涵蓋了并行解決方案的有效性:它是否有用?效率是衡量資源利用率的標準:我們投入的計算資源所能提供的潛力有多少被實際利用?效率低表明設計不佳,或者至少需要進一步改進。
最后,我們想知道并行算法在計算資源和/或問題規模增加時的表現如何:它是否具有可擴展性?
通常,可擴展性是指(軟件或硬件)系統高效處理不斷增長的工作量的能力。在并行算法和/或平臺的背景下,可擴展性轉化為能夠 (a) 解決更大的問題和/或 (b) 整合更多的計算資源。
有兩個指標用于量化可擴展性:強擴展效率(與 (b) 相關)和弱擴展效率(與 (a) 相關)。強擴展效率的定義與公式 (1.2) 中定義的通用效率相同:

它是用于解決與單個處理器相同問題的處理器數量 N 的函數。
弱擴展效率同樣是用于解決處理器數量 N 的函數:

其中 t′par 是解決比單個機器解決時間 tseq 大 N 倍的問題所需的時間。
有許多當涉及 GPU 計算資源時,計算擴展效率時存在一些問題:應該使用多少 N 值?GPU 通常擁有數百或數千個核心,但將單個 GPU 核心上的執行時間報告為 tseq 會顯得笨拙或不科學。如果我們選擇將單個 CPU 核心的執行時間報告為 tseq,那么在計算效率時,我們是否應該將 GPU 核心總數作為 N?此外,GPU 是托管設備,即它需要一個 CPU 代表其執行 I/O。這個 CPU 算數嗎?
顯然,在這種情況下,效率可以通過多種不同的方式計算。為了避免爭議,我們僅報告涉及異構平臺的案例研究中的加速比數據。
參考資料
- 軟件測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 http://www.rzrgm.cn/testing-/p/17438558.html
- python八字排盤 https://github.com/china-testing/bazi
- 聯系方式:釘ding或V信: pythontesting
1.5 預測和測量并行程序性能
構建并行應用程序比構建其對應的順序應用程序更具挑戰性。程序員必須解決協調問題,例如如何正確訪問共享資源、負載平衡問題(即如何在可用計算資源之間分配工作負載以最小化執行時間)、終止問題(即以協調的方式暫停程序)等等。
只有當應用程序能夠通過加速問題解決方案真正受益時,才應該嘗試進行此類嘗試。開發成本決定了我們不能僅僅實現多個備選設計并進行測試以選出最佳方案,或者更糟的是,評估項目的可行性。對于最簡單的問題來說,這或許是可行的,但即使如此,如果我們能夠先驗地確定最佳的開發路線,那就更好了。
問題的并行解決方案的開發始于其串行變體的開發!這聽起來似乎自相矛盾,但請嘗試回答這些問題:如果我們沒有串行解決方案可以比較,我們如何知道并行解決方案的速度有多快?我們需要一個基準,而這只能通過順序解決方案獲得。此外,我們如何檢查并行程序生成的解決方案是否正確?順序程序的輸出并不能保證正確,但使其正確要容易得多。
順序算法和相關程序的開發也可以為并行化設計提供重要的參考。
這是一個實際問題,因為我們需要回答以下與并行程序的可行性和成本效益相關的問題:
- 程序中最耗時的部分是什么?這些部分應該是并行執行的主要候選。
- 一旦確定了這些部分并假設它們可以并行化,可以預期獲得多少性能提升?
這里需要澄清的是:所需的順序程序并非只是解決同一問題的任何順序程序。它必須是被并行化的同一算法的順序實現。例如,如果我們需要并行排序數據,那么適合并行實現的算法是桶排序。桶排序的順序實現可以幫助預測并行性能,并找出算法中最耗時的部分。快速排序的順序實現可以提供基準性能信息,但它無法解決上述兩個問題。
一旦實現了順序版本,我們就可以使用性能分析器來回答這些問題。性能分析器是一種工具,可以收集有關程序各部分調用頻率、調用持續時間以及內存使用量的信息。性能分析器使用多種不同的技術來執行其任務。最常用的技術是: - 儀表化:修改被分析程序的代碼,以便收集信息,例如,在執行任何指令之前增加一個特殊計數器。這會產生非常準確的信息,但同時也會大大增加執行時間。此技術需要重新編譯目標程序。
- 采樣:目標程序的執行會被定期中斷,以便查詢正在執行的函數。顯然,這種方法的準確性不如儀表化。雖然需要進行插樁,但程序不需要重新編譯,執行時間也僅會受到輕微影響
下圖為kcachegrind 的示例屏幕截圖,顯示了順序桶排序實現的分析結果,該實現在桶較小時會切換到快速排序。

valgrind 分析工具集合包含一個基于插樁的分析器。插樁在分析之前執行,這意味著無需用戶干預。這是一個調用示例:
$ valgrind --tool=callgrind ./bucketsort 1000000
其中 ./bucketsort 1000000 是待分析的程序及其參數。分析結果文件名為“callgrind.out”,其中包含分析結果。分析結果可以通過 kcachegrind 等前端程序進行可視化。
經驗和對問題領域的深入了解是寶貴的資源,它們可以幫助人們精準定位需要并行化的“熱點”,而無需對順序程序進行性能分析。
然而,性能分析器可以幫助我們回答上面提出的第二個問題,即我們可以從并行解決方案中獲得多少潛在性能。傳統上,這是通過近似數學模型來實現的,這些模型使我們能夠捕捉待執行計算的本質。這些模型的參數可以通過對順序應用程序進行性能分析來估算。在下一節中,我們將描述基于這種簡單模型的阿姆達爾定律。
無論數學模型的性能預測如何,出于兩個原因,必須對已實施的并行設計進行實際測試:正確性和性能。必須驗證并行實現的正確性。并行程序的行為可能具有不確定性,因為以未指定的順序發生的事件可能會影響計算結果。除非事先計劃,否則不確定性是一種不良特性,如果存在,必須根除。此外,測試還可以揭示原始設計的缺陷或需要解決的性能問題。
以下列表包含執行正確實驗程序的準則:
- 除非另有明確說明,否則應測量整個執行的持續時間。例如,如果僅要并行化程序的一部分,則只能針對執行時間線的特定部分計算速度和效率。然而,總體時間可以用來衡量并行解決方案的影響及其是否具有成本效益。例如,一個程序解決問題需要 100 秒,如果其中 10% 的部分以 100 倍的速度執行,仍然需要 90 多秒。
- 結果應以多次運行的平均值形式報告,可能包含標準差。運行次數因應用而異,例如,將一個持續 3 天的實驗重復 100 次,并且對于許多不同的場景來說,這是完全不現實的。然而,為了解決這個問題,三次運行的平均值只能產生不可靠的統計數據。因此,必須謹慎權衡。
- 異常值(即過大或過小的結果)應從平均值計算中排除,因為它們通常表示異常情況(例如,主內存耗盡或機器工作負載發生變化)。然而,應給出理由,以免不利結果被一筆帶過,而只加解釋。
- 可擴展性至關重要,因此應報告各種輸入規模(理想情況下涵蓋實際數據的大小和/或質量)和各種并行平臺規模的結果。
- 測試輸入應從非常小到非常大不等,但如果可以識別,則應始終包含生產環境中典型的問題規模。
- 當使用多核機器時,如果要計算效率,線程和/或進程的數量不應超過可用的硬件核心數量。超線程是一種特殊情況,因為這項技術使CPU在操作系統看來擁有實際核心數量的兩倍(或更多)。然而,這些邏輯核心與滿負荷核心的能力并不匹配。因此,盡管操作系統可能報告例如八個核心的可用性,但相應的硬件資源并不存在,這實際上損害了任何可擴展性分析。理想情況下,為了衡量可擴展性,應該禁用超線程,或者將線程數限制為硬件核心數。
在某些情況下,線程數多于核心數是有利的:如果某些線程因某種原因阻塞,其余線程仍然可以利用 CPU。但是,在計算效率時,N 應該是核心數,而不是線程/進程數。為了在不經歷昂貴的并行程序實現和測試步驟的情況下預測并行性能,提出了以下章節中描述的兩條定律。尤其是阿姆達爾定律,盡管已被證明存在缺陷,但仍然具有影響力。
1.5.1 阿姆達爾定律
1967 年,吉恩·阿姆達爾 (Gene Amdahl) 設計了一個簡單的思想實驗,用于推導并行程序可以預期的性能優勢。阿姆達爾假設:
- 順序應用程序,在單個 CPU 上執行需要 T 時間。
- 該應用程序由 0 ≤ α ≤ 1 個可并行的部分組成。剩余的 1 ? α 必須順序執行。
- 并行執行不會產生通信開銷,并且可并行化的部分可以在任意數量的 CPU 之間平均分配。此假設尤其適用于多核架構,因為這些架構中的內核可以訪問相同的共享內存。
基于上述假設,N 個節點獲得的加速比應該有上限:
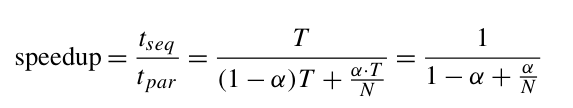
因為我們忽略了任何分區/通信/協調成本。如果我們獲得 N → ∞ 的極限,則等式 (1.5) 也可以給出最大可能的加速比:

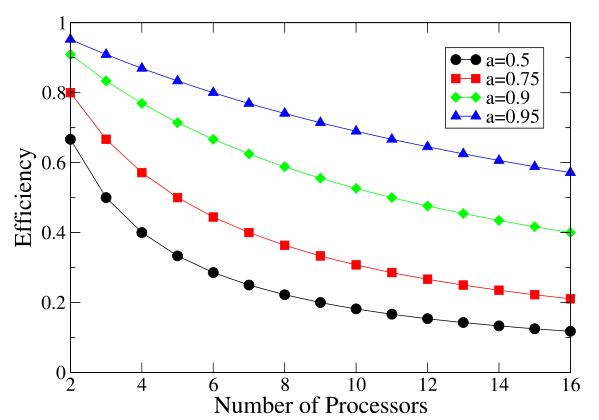
上面以簡單易記的形式解決了一個難題:并行程序能將問題解決得快多少?而且,它以一種完全抽象的方式進行計算,沒有考慮計算平臺的特性。它僅依賴于問題的特性,即 α。顯而易見的是,預測的加速比受到嚴重限制。即使對于較小的 α 值,最大加速比也很低。例如,如果 α = 0.9,則無論使用多少處理器來解決問題,加速比都小于 10。

阿姆達爾定律有一個有趣的推論,這或許就是它被提出的動機。阿姆達爾定律是在小型計算機問世的時代制定的。小型計算機比當時占主導地位的大型機便宜得多,但性能也較弱。圖 1.1 不同 α 值下的加速曲線,即應用程序中可以并行化的部分,正如阿姆達爾定律所預測的那樣。
1.5.2 Gustafson–Barsis 的反駁
阿姆達爾定律存在根本性缺陷,因為它已被反復證明無法解釋經驗數據:并行程序通常會超出預測的加速極限。
最終,在阿姆達爾定律發表二十年后,Gustafson 和 Barsis 終于從正確的角度審視了這個問題。
并行平臺的作用不僅僅是加快順序程序的執行速度。它可以容納更大的問題實例。因此,與其考察并行程序相對于順序程序的性能,不如考察如果順序機器需要解決并行程序能夠解決的相同問題,其性能會如何。
假設:
- 我們有一個并行應用程序,在 N 個 CPU 上執行需要 T 時間。
- 該應用程序在所有機器上運行的總時間中,0 ≤ α ≤ 1。剩余的 1 ? α 必須順序執行。
在順序機器上解決同一問題需要的總時間為:
Tseq = (1 ? α)T + N · α · T
那么加速比為:
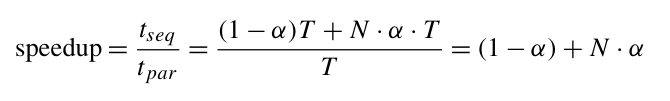
相應的效率為:

當 N 趨于無窮大時,效率的下限為 α。
上圖所示的加速曲線完全忽略了通信成本,結果顯然過于理想化,但潛力確實存在。
下圖的效率曲線仍然樂觀。即使 α = 50%,在最多 16 個 CPU 的情況下,效率也不會低于 50%。這簡直好得令人難以置信。即使對于所謂的高度并行問題,隨著 N 的增加,通信開銷也會成為一個決定性因素,導致加速增益降低,效率驟降。一般來說,在實踐中獲得 90% 以上的效率,我認為是一項值得稱道的成就。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號