
現(xiàn)代CPU調(diào)優(yōu)5性能分析方法
5 性能分析方法
當(dāng)您正在進(jìn)行高級優(yōu)化時,例如將更好的算法集成到應(yīng)用程序中,通常很容易看出性能是否提高,因為基準(zhǔn)測試結(jié)果通常很明顯。從性能分析的角度來看,2 倍、3 倍等大幅提速相對明顯。當(dāng)你從程序中刪除大量計算時,你會期望看到運行時間的明顯差異。
但同樣,在某些情況下,當(dāng)你看到執(zhí)行時間的微小變化,比如 5% 時,你卻不知道它來自哪里。僅憑計時或吞吐量測量無法解釋性能上升或下降的原因。在這種情況下,我們需要深入了解程序是如何執(zhí)行的。在這種情況下,我們就需要進(jìn)行性能分析,以了解我們觀察到的速度變慢或變快的根本原因。
性能分析類似于偵探工作。要解開性能之謎,就需要收集所有可能的數(shù)據(jù)并嘗試形成假設(shè)。一旦有了假設(shè),就需要設(shè)計一個實驗來證明或推翻它。在找到線索之前,可能會反反復(fù)復(fù)好幾次。就像一個好偵探一樣,你要盡可能多地收集證據(jù)來證實或反駁你的假設(shè)。一旦有了足夠的線索,你就可以對觀察到的行為做出令人信服的解釋。
剛開始處理性能問題時,您可能只有測量數(shù)據(jù),例如代碼更改前后的數(shù)據(jù)。根據(jù)這些測量結(jié)果,你得出的結(jié)論是程序變慢了 X%。如果你知道程序變慢發(fā)生在某個提交之后,這可能已經(jīng)為你提供了足夠的信息來解決問題。但如果你沒有很好的參考點,那么導(dǎo)致速度變慢的可能原因就無窮無盡了,你需要收集更多的數(shù)據(jù)。收集此類數(shù)據(jù)最常用的方法之一是對應(yīng)用程序進(jìn)行剖析并查看熱點。本章將介紹這種方法以及其他幾種收集數(shù)據(jù)的方法,這些方法已被證明在性能工程中非常有用。
下一個問題來了: “有哪些可用的性能數(shù)據(jù)以及如何收集這些數(shù)據(jù)?堆棧的硬件層和軟件層都有跟蹤性能事件并在程序運行時記錄這些事件的功能。在這里,硬件指的是執(zhí)行程序的 CPU,軟件指的是操作系統(tǒng)、程序庫、應(yīng)用程序本身以及用于分析的其他工具。通常情況下,軟件棧提供時間、上下文切換次數(shù)和頁面故障等高級指標(biāo),而 CPU 則監(jiān)控緩存未命中、分支預(yù)測錯誤和其他 CPU 相關(guān)事件。根據(jù)您要解決的問題,有些指標(biāo)比其他指標(biāo)更有用。因此,這并不意味著硬件指標(biāo)總能為我們提供更精確的程序執(zhí)行概覽。它們只是不同而已。有些指標(biāo),比如上下文切換次數(shù),CPU 無法提供。性能分析工具(如 Linux perf)可以同時使用操作系統(tǒng)和 CPU 的數(shù)據(jù)。
性能工程師可能會使用數(shù)百種數(shù)據(jù)源。本章主要介紹硬件級信息的收集。我們將介紹一些最常用的性能分析技術(shù):代碼代碼插樁、跟蹤、特性分析、采樣和 Roofline 模型。我們還將討論靜態(tài)性能分析技術(shù)和編譯器優(yōu)化報告,這些技術(shù)無需運行實際應(yīng)用程序。
5.1 代碼插樁 (Code Instrumentation)
可能最早發(fā)明的性能分析方法就是代碼工具。這是一種在程序中插入額外代碼以收集特定運行時信息的技術(shù)。下面最簡單的示例:在函數(shù)開頭插入 printf 語句,以指示是否調(diào)用了該函數(shù)。然后,運行程序并計算輸出中出現(xiàn) “foo 被調(diào)用 ”的次數(shù)。也許世界上每個程序員在其職業(yè)生涯的某個階段都至少做過一次這樣的事情。
int foo(int x) {
+ printf("foo is called\n");
// function body...
}
行首的加號表示該行是添加的,在原始代碼中并不存在。一般來說,插樁代碼并不是要推送到代碼庫中,而是用于收集所需的數(shù)據(jù),之后可以刪除。
下例提供了一個更有趣的代碼插樁示例。在這個編造的代碼示例中,函數(shù) findObject 在地圖上搜索具有某些屬性 p 的對象的坐標(biāo)。所有對象最終都會被找到。函數(shù) getNewCoords 返回作為參數(shù)提供的較大區(qū)域內(nèi)的新坐標(biāo)。函數(shù) findObj 返回當(dāng)前坐標(biāo) c 找到正確對象的置信度。如果置信度高于閾值,我們會調(diào)用 zoomIn 來找到更精確的對象位置。否則,我們將獲取搜索區(qū)域內(nèi)的新坐標(biāo),以便下次嘗試搜索。
工具代碼由兩個類組成:直方圖和增量器。前者跟蹤我們感興趣的變量值及其出現(xiàn)頻率,然后在程序結(jié)束后打印直方圖。后者只是一個輔助類,用于將數(shù)值推送到直方圖對象中。在這一假設(shè)場景中,我們添加了插樁,以了解在找到對象之前放大的頻率。變量 inc.tripCount 計算循環(huán)在退出前的迭代次數(shù),變量 inc.zoomCount 計算。
+ struct histogram {
+ std::map<uint32_t, std::map<uint32_t, uint64_t>> hist;
+ ~histogram() {
+ for (auto& tripCount : hist)
+ for (auto& zoomCount : tripCount.second)
+ std::cout << "[" << tripCount.first << "]["
+ << zoomCount.first << "] : "
+ << zoomCount.second << "\n";
+ }
+ };
+ histogram h;
+ struct incrementor {
+ uint32_t tripCount = 0;
+ uint32_t zoomCount = 0;
+ ~incrementor() {
+ h.hist[tripCount][zoomCount]++;
+ }
+ };
Coords findObject(const ObjParams& p, Coords c, float searchRadius) {
+ incrementor inc;
while (true) {
+ inc.tripCount++;
float match = findObj(c, p);
if (exactMatch(match))
return c;
if (match > threshold) {
searchRadius = zoomIn(c, searchRadius);
+ inc.zoomCount++;
}
c = getNewCoords(searchRadius);
}
return c;
}
我們縮小搜索區(qū)域的次數(shù)(調(diào)用 zoomIn)。我們總是希望 inc.zoomCount 小于或等于 inc.tripCount。
findObject 函數(shù)會在各種輸入情況下被多次調(diào)用。下面是我們在運行儀器程序后可能觀察到的輸出結(jié)果:
// [tripCount][zoomCount]: occurences
[7][6]: 2
[7][5]: 6
[7][4]: 20
[7][3]: 156
[7][2]: 967
[7][1]: 3685
[7][0]: 251004
[6][5]: 2
[6][4]: 7
[6][3]: 39
[6][2]: 300
[6][1]: 1235
[6][0]: 91731
[5][4]: 9
[5][3]: 32
[5][2]: 160
[5][1]: 764
[5][0]: 34142
方括號中的第一個數(shù)字是循環(huán)的行程計數(shù),第二個數(shù)字是我們在同一循環(huán)中進(jìn)行的 zoomIns 次數(shù)。列號后的數(shù)字是該數(shù)字組合的出現(xiàn)次數(shù)。
例如,有兩次我們觀察到 7 次循環(huán)迭代和 6 次zoomIns,有 251004 次循環(huán)運行了 7 次迭代但沒有zoomIns,以此類推。然后,你可以繪制數(shù)據(jù)圖以獲得更好的可視化效果,或者采用其他統(tǒng)計方法,但我們可以得出的主要結(jié)論是,zoomIns 并不頻繁。調(diào)用 findObject 的總次數(shù)約為 40 萬次;我們可以通過對直方圖中的所有桶求和來計算。如果我們將所有 zoomCount 不為零的水桶相加,得出的結(jié)果約為 10k;這就是 zoomIn 函數(shù)被調(diào)用的次數(shù)。因此,每調(diào)用一次 zoomIn,我們就要調(diào)用 40 次 findObject 函數(shù)。
本書后面幾章將舉例說明如何利用這些信息進(jìn)行優(yōu)化。在我們的案例中,我們得出結(jié)論:findObj 經(jīng)常找不到對象。這意味著循環(huán)的下一次迭代將嘗試使用新坐標(biāo)來查找對象,但仍在同一搜索區(qū)域內(nèi)。了解到這一點后,我們可以嘗試進(jìn)行一些優(yōu)化: 1)并行運行多個搜索,如果其中任何一個搜索成功,則同步運行;2)預(yù)先計算當(dāng)前搜索區(qū)域的某些內(nèi)容,從而消除 findObj 內(nèi)部的重復(fù)工作;3)編寫一個軟件流水線,調(diào)用 getNewCoords 生成下一組所需的坐標(biāo),并從內(nèi)存中預(yù)取相應(yīng)的地圖位置。本書第二部分將更深入地探討其中的一些技術(shù)。
當(dāng)你需要具體了解程序的執(zhí)行情況時,代碼插樁可以提供非常詳細(xì)的信息。它允許我們跟蹤程序中每個變量的任何信息。
在優(yōu)化大段代碼時,使用這種方法往往能獲得最佳的洞察力,因為你可以使用一種自上而下的方法(檢測主函數(shù),然后深入到其 callees)來更好地理解應(yīng)用程序的行為。通過代碼工具,開發(fā)人員可以觀察應(yīng)用程序的架構(gòu)和流程。這種技術(shù)對于處理不熟悉代碼庫的人員尤其有幫助。
代碼插樁技術(shù)在視頻游戲和嵌入式開發(fā)等實時場景的性能分析中得到了廣泛應(yīng)用。有些剖析器將工具與其他技術(shù)(如跟蹤或采樣)相結(jié)合。我們將在第 7.7 節(jié)中介紹一種名為 Tracy 的混合剖析器。
雖然代碼插樁在很多情況下都很強(qiáng)大,但它并不能從操作系統(tǒng)或 CPU 的角度提供代碼執(zhí)行的任何信息。例如,它無法提供進(jìn)程調(diào)入和調(diào)出執(zhí)行的頻率(操作系統(tǒng)已知)或發(fā)生分支錯誤預(yù)測的次數(shù)(CPU 已知)。插樁代碼是應(yīng)用程序的一部分,擁有與應(yīng)用程序本身相同的權(quán)限。它在用戶空間運行,無法訪問內(nèi)核。
這種技術(shù)的一個更重要的缺點是,每當(dāng)有新的東西(比如說另一個變量)需要檢測時,就需要重新編譯。這會成為一種負(fù)擔(dān),并增加分析時間。不幸的是,這種方法還有其他缺點。由于您通常關(guān)心的是應(yīng)用程序中的熱點路徑,因此您需要對代碼中性能關(guān)鍵部分的內(nèi)容進(jìn)行檢測。在熱路徑中注入儀器代碼很容易導(dǎo)致整體基準(zhǔn)測試速度降低 2 倍。切記不要對插樁序進(jìn)行基準(zhǔn)測試。通過檢測代碼,您會改變程序的行為,因此您可能無法看到與之前相同的效果。
所有上述情況都會增加實驗之間的間隔時間,消耗更多的開發(fā)時間,這也是工程師們現(xiàn)在不經(jīng)常手動檢測代碼的原因。不過,編譯器仍在廣泛使用自動代碼檢測。編譯器能夠自動檢測整個程序(第三方庫除外),以收集有關(guān)執(zhí)行情況的有趣統(tǒng)計數(shù)據(jù)。最廣為人知的自動探測用例是代碼覆蓋率分析和配置文件引導(dǎo)優(yōu)化(參見第 11.7 節(jié))。
在談到插樁時,有必要提及二進(jìn)制插樁技術(shù)。二進(jìn)制工具的原理與此類似,但它是針對已構(gòu)建的可執(zhí)行文件而非源代碼進(jìn)行的。二進(jìn)制工具有兩種類型:靜態(tài)(提前完成)和動態(tài)(程序執(zhí)行時按需插入工具代碼)。動態(tài)二進(jìn)制工具的主要優(yōu)點是不需要重新編譯程序和重新鏈接。此外,使用動態(tài)檢測,可以將檢測量限制在感興趣的代碼區(qū)域,而不是檢測整個程序。
二進(jìn)制工具在性能分析和調(diào)試中非常有用。英特爾Pin是最常用的二進(jìn)制工具之一。Pin 會在出現(xiàn)有趣事件時攔截程序的執(zhí)行,并從程序中的這一點開始生成新的儀器代碼。這樣就能收集各種運行時信息。英特爾 SDE: Software Development Emulator 軟件開發(fā)仿真器是建立在 Pin 基礎(chǔ)上的最流行的工具之一。另一個著名的二進(jìn)制工具名為 DynamoRIO, 二進(jìn)制插樁工具的作用:
- 指令計數(shù)和函數(shù)調(diào)用計數(shù);
- 指令組合分析;
- 攔截應(yīng)用程序中的函數(shù)調(diào)用和任何指令的執(zhí)行;
- 內(nèi)存強(qiáng)度和占用空間(參見第 7.8.3 節(jié))。
與代碼檢測一樣,二進(jìn)制檢測只檢測用戶級代碼,速度可能非常慢。
5.2 跟蹤(Tracing)
跟蹤在概念上與插樁非常相似,但又略有不同。代碼插樁假定用戶可以完全訪問其應(yīng)用程序的源代碼。另一方面,跟蹤則依賴于現(xiàn)有的工具。例如,strace 工具能讓我們跟蹤系統(tǒng)調(diào)用,可視為 Linux 內(nèi)核的工具。英特爾處理器跟蹤工具(Intel PT,見附錄 C)可以記錄處理器執(zhí)行的指令,可視為 CPU 的工具。跟蹤可從預(yù)先進(jìn)行了適當(dāng)檢測且不會發(fā)生變化的組件中獲取。跟蹤通常被用作一種黑盒方法,即用戶不能修改應(yīng)用程序的代碼,但又想深入了解程序正在做什么。
下面提供了一個使用 Linux strace 工具跟蹤系統(tǒng)調(diào)用的示例,它顯示了運行 git status 命令時的前幾行輸出。
通過使用 strace 跟蹤系統(tǒng)調(diào)用,我們可以知道每次系統(tǒng)調(diào)用的時間戳(最左邊一列)、退出狀態(tài)(在 = 符號之后)以及每次系統(tǒng)調(diào)用的持續(xù)時間(在角括號中)。
# strace -tt -T -- git status
08:48:08.432163 execve("/usr/bin/git", ["git", "status"], 0x7fffffb9c560 /* 24 vars */) = 0 <0.001054>
08:48:08.433978 brk(NULL) = 0x5a15bffda000 <0.000014>
08:48:08.434498 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f1b82aa8000 <0.000021>
08:48:08.434664 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) <0.000019>
08:48:08.434923 openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 <0.000033>
08:48:08.435008 fstat(3, {st_mode=S_IFREG|0644, st_size=71351, ...}) = 0 <0.000019>
08:48:08.435089 mmap(NULL, 71351, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f1b82a96000 <0.000033>
08:48:08.435197 close(3) = 0 <0.000017>
08:48:08.435270 openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libpcre2-8.so.0", O_RDONLY|O_CLOEXEC) =
...
跟蹤的開銷取決于我們試圖跟蹤的具體內(nèi)容。例如,如果我們跟蹤一個很少進(jìn)行系統(tǒng)調(diào)用的程序,那么在 strace 下運行它的開銷將接近于零。另一方面,如果我們跟蹤一個嚴(yán)重依賴系統(tǒng)調(diào)用的程序,開銷可能會非常大,例如 100 倍。此外,由于跟蹤不會跳過任何樣本,因此會產(chǎn)生大量數(shù)據(jù)。為彌補(bǔ)這一不足,跟蹤工具提供了過濾器,可將數(shù)據(jù)收集限制在特定時間片或特定代碼段。與插樁類似,跟蹤也可用于探索系統(tǒng)中的異常情況。例如,您可能想確定應(yīng)用程序在 10 秒鐘無響應(yīng)期間發(fā)生了什么。正如您稍后將看到的,采樣方法并非為此而設(shè)計,但通過跟蹤,您可以了解導(dǎo)致程序無響應(yīng)的原因。例如,通過英特爾 PT,您可以重建程序的控制流,準(zhǔn)確了解執(zhí)行了哪些指令。
跟蹤對調(diào)試也非常有用。它的基本特性使 “記錄和重放 ”成為可能。Mozilla rr調(diào)試器就是這樣一個工具,它可以記錄和重放進(jìn)程,支持向后單步等。大多數(shù)跟蹤工具都能為事件加上時間戳,這樣我們就能找到事件與當(dāng)時發(fā)生的外部事件之間的關(guān)聯(lián)。也就是說,當(dāng)我們觀察到程序出現(xiàn)故障時,可以查看應(yīng)用程序的跟蹤記錄,并將故障與當(dāng)時整個系統(tǒng)中發(fā)生的事件聯(lián)系起來。
5.3 收集性能監(jiān)控事件(Performance Monitoring Events)
性能監(jiān)控計數(shù)器(PMC Performance Monitoring Counters)是一種非常重要的底層性能分析工具。它們可以提供有關(guān)程序執(zhí)行的獨特信息。PMC 通常有兩種使用模式: “計數(shù) “或 ”采樣"。計數(shù)模式主要用于計算第 4.9 節(jié)討論的各種性能指標(biāo)。采樣模式用于查找熱點,我們將很快討論這一點。
計數(shù)模式的原理非常簡單:我們要計算程序運行時某些性能監(jiān)控事件的總數(shù)。PMC 在 “自頂向下微體系結(jié)構(gòu)分析”(TMA)方法中得到了廣泛應(yīng)用,我們將在第 6.1 節(jié)詳細(xì)介紹該方法。下圖展示了從程序開始到結(jié)束的性能事件計數(shù)過程。
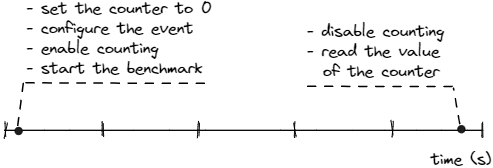
圖中概述的步驟大致代表了典型分析工具對性能事件的計數(shù)過程。perf stat 工具也有類似的過程,可用于統(tǒng)計各種硬件事件,如指令數(shù)、周期數(shù)、緩存未命中數(shù)等。下面是 perf stat 輸出的示例:
# perf stat -- ls
code my.script openpbs-23.06.06 slurm-8.out snap test.sh t.out v23.06.06
Performance counter stats for 'ls':
0.52 msec task-clock # 0.691 CPUs utilized
0 context-switches # 0.000 /sec
0 cpu-migrations # 0.000 /sec
96 page-faults # 183.560 K/sec
2,035,732 cycles # 3.892 GHz
2,029,699 instructions # 1.00 insn per cycle
375,710 branches # 718.390 M/sec
11,642 branch-misses # 3.10% of all branches
TopdownL1 # 29.8 % tma_backend_bound
# 11.2 % tma_bad_speculation
# 36.3 % tma_frontend_bound
# 22.7 % tma_retiring
0.000756947 seconds time elapsed
0.000790000 seconds user
0.000000000 seconds sys
這些數(shù)據(jù)可能非常有用。首先,它能讓我們迅速發(fā)現(xiàn)一些異常情況,如分支預(yù)測錯誤率過高或 IPC 過低。此外,當(dāng)你修改了代碼,并想驗證修改是否提高了性能時,這些數(shù)據(jù)也會派上用場。查看相關(guān)事件可能會幫助你證明或拒絕代碼變更。perf stat 實用程序可用作輕量級基準(zhǔn)包裝器。它可以作為性能調(diào)查的第一步。有時可以立即發(fā)現(xiàn)異常,從而節(jié)省分析時間。
使用 perf list 可以查看可用事件名稱的完整列表:
# perf list
List of pre-defined events (to be used in -e or -M):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
alignment-faults [Software event]
bpf-output [Software event]
cgroup-switches [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
duration_time [Tool event]
user_time [Tool event]
system_time [Tool event]
cpu:
L1-dcache-loads OR cpu/L1-dcache-loads/
L1-dcache-load-misses OR cpu/L1-dcache-load-misses/
L1-dcache-stores OR cpu/L1-dcache-stores/
...
現(xiàn)代 CPU 有數(shù)百個可觀察到的性能事件。要記住所有這些事件及其含義非常困難。了解何時使用特定事件更是難上加難。這就是為什么我一般不建議手動收集特定事件,除非你真的知道自己在做什么。相反,我建議使用英特爾 VTune Profiler 等工具,它們可以自動收集所需的事件來計算各種指標(biāo)。
由于訪問 PMC 需要 root 訪問權(quán)限,而在虛擬化環(huán)境中運行的應(yīng)用程序通常不具備 root 訪問權(quán)限,因此性能事件并非在每個環(huán)境中都可用。對于在公共云中執(zhí)行的程序,如果虛擬機(jī)(VM)管理器沒有將 PMU 編程接口正確地暴露給客戶機(jī),那么直接在客戶機(jī)容器中運行基于 PMU 的剖析器就不會產(chǎn)生有用的輸出結(jié)果。因此,基于 CPU 性能監(jiān)控計數(shù)器的剖析器在虛擬化和云環(huán)境中并不能很好地工作Du 等人,2010 ,盡管情況正在改善。VMware? 是首批啟用虛擬性能監(jiān)控計數(shù)器(vPMC virtual Performance Monitoring Counters )的虛擬機(jī)管理器之一。AWS EC2云也為專用主機(jī)啟用了PMC。
5.3.1 多路復(fù)用和擴(kuò)展事件
有時候,我們需要同時對多個不同的事件進(jìn)行計數(shù)。然而,一個計數(shù)器一次只能計數(shù)一個事件。這就是 PMU 包含多個計數(shù)器的原因(在英特爾最新的 Golden Cove 微體系結(jié)構(gòu)中,有 12 個可編程 PMC,每個硬件線程 6 個)。即便如此,固定計數(shù)器和可編程計數(shù)器的數(shù)量也并不總是足夠的。自上而下的微體系結(jié)構(gòu)分析(TMA Top-down Microarchitecture Analysis)方法需要在程序的單次執(zhí)行中收集多達(dá) 100 個不同的性能事件。現(xiàn)代 CPU 沒有這么多計數(shù)器,這就是多路復(fù)用發(fā)揮作用的地方。
如果需要收集的事件數(shù)量超過可用 PMC 的數(shù)量,分析工具就會使用時間多路復(fù)用,讓每個事件都有機(jī)會訪問監(jiān)控硬件。

采用多路復(fù)用后,一個事件不會一直被測量,而是只在部分時間內(nèi)被測量。運行結(jié)束時,剖析工具需要根據(jù)啟用的總時間縮放原始計數(shù):最終計數(shù) = 原始計數(shù) × (運行時間/啟用時間) 。
假設(shè)在剖析過程中,我們可以在三個時間間隔內(nèi)測量組 1 中的一個事件。每個測量時間間隔持續(xù) 100 毫秒(啟用時間)。程序運行時間為 500 毫秒(運行時間)。經(jīng)測量,該計數(shù)器的事件總數(shù)為 10,000 個(原始計數(shù))。因此,最終計數(shù)需要按以下方式縮放:最終計數(shù) = 10,000 × (500ms/(100ms × 3)) = 16,666
這是在整個運行過程中對事件進(jìn)行測量時的估計計數(shù)。重要的是要明白,這仍然是一個估計值,而不是實際計數(shù)。在長時間間隔內(nèi)執(zhí)行相同代碼的穩(wěn)定工作負(fù)載上,可以安全地使用多路復(fù)用和縮放。但是,如果程序經(jīng)常在不同的熱點(即不同的階段)之間跳轉(zhuǎn),就會出現(xiàn)盲點,從而在縮放過程中引入錯誤。為避免縮放,可將事件數(shù)減少到不超過可用物理 PMC 的數(shù)量。不過,您必須多次運行基準(zhǔn)才能測量所有事件。
5.3.2 使用標(biāo)記 API
在某些情況下,我們可能會對分析特定代碼區(qū)域而非整個應(yīng)用程序的性能感興趣。這種情況可能是您正在開發(fā)一段新代碼,并希望只關(guān)注該代碼。當(dāng)然,您也希望跟蹤優(yōu)化進(jìn)度并捕獲更多性能數(shù)據(jù),以便在優(yōu)化過程中對您有所幫助。大多數(shù)性能分析工具都提供了特定的標(biāo)記 API,可以讓您做到這一點。下面是兩個例子:
- Intel VTune 有 __itt_task_begin / __itt_task_end 函數(shù)。
- AMD uProf 有 amdProfileResume / amdProfilePause 函數(shù)。
這種混合方法結(jié)合了儀器和性能事件計數(shù)的優(yōu)點。與測量整個程序不同,標(biāo)記 API 允許我們將性能統(tǒng)計歸因于代碼區(qū)域(循環(huán)、函數(shù))或功能片段(遠(yuǎn)程過程調(diào)用 (RPC)、輸入事件等)。您所獲得的數(shù)據(jù)質(zhì)量很容易證明您的努力是值得的。例如,在調(diào)查僅在特定類型的 RPC 中發(fā)生的性能錯誤時,可以僅針對該類型的 RPC 啟用監(jiān)控。
下面我們將提供一個使用 libpfm4 的基本示例,libpfm4 是用于收集性能監(jiān)控事件的流行 Linux 庫之一。它建立在 Linux perf_events 子系統(tǒng)之上,可讓您直接訪問性能事件計數(shù)器。perf_events 子系統(tǒng)相當(dāng)?shù)图墸虼?libpfm4 軟件包在此非常有用,因為它既添加了一個用于識別 CPU 上可用事件的發(fā)現(xiàn)工具,也是原始 perf_event_open 系統(tǒng)調(diào)用的封裝庫。下面的代碼列表展示了如何使用 libpfm4 來檢測 C-Ray基準(zhǔn)的渲染函數(shù)。
+#include <perfmon/pfmlib.h>
+#include <perfmon/pfmlib_perf_event.h>
...
/* render a frame of xsz/ysz dimensions into the provided framebuffer */
void render(int xsz, int ysz, uint32_t *fb, int samples) {
...
+ pfm_initialize();
+ struct perf_event_attr perf_attr;
+ memset(&perf_attr, 0, sizeof(perf_attr));
+ perf_attr.size = sizeof(struct perf_event_attr);
+ perf_attr.read_format = PERF_FORMAT_TOTAL_TIME_ENABLED |
+ PERF_FORMAT_TOTAL_TIME_RUNNING | PERF_FORMAT_GROUP;
+
+ pfm_perf_encode_arg_t arg;
+ memset(&arg, 0, sizeof(pfm_perf_encode_arg_t));
+ arg.size = sizeof(pfm_perf_encode_arg_t);
+ arg.attr = &perf_attr;
+
+ pfm_get_os_event_encoding("instructions", PFM_PLM3, PFM_OS_PERF_EVENT_EXT, &arg);
+ int leader_fd = perf_event_open(&perf_attr, 0, -1, -1, 0);
+ pfm_get_os_event_encoding("cycles", PFM_PLM3, PFM_OS_PERF_EVENT_EXT, &arg);
+ int event_fd = perf_event_open(&perf_attr, 0, -1, leader_fd, 0);
+ pfm_get_os_event_encoding("branches", PFM_PLM3, PFM_OS_PERF_EVENT_EXT, &arg);
+ event_fd = perf_event_open(&perf_attr, 0, -1, leader_fd, 0);
+ pfm_get_os_event_encoding("branch-misses", PFM_PLM3, PFM_OS_PERF_EVENT_EXT, &arg);
+ event_fd = perf_event_open(&perf_attr, 0, -1, leader_fd, 0);
+
+ struct read_format { uint64_t nr, time_enabled, time_running, values[4]; };
+ struct read_format before, after;
for(j=0; j<ysz; j++) {
for(i=0; i<xsz; i++) {
double r = 0.0, g = 0.0, b = 0.0;
+ // capture counters before ray tracing
+ read(event_fd, &before, sizeof(struct read_format));
for(s=0; s<samples; s++) {
struct vec3 col = trace(get_primary_ray(i, j, s), 0);
r += col.x;
g += col.y;
b += col.z;
}
+ // capture counters after ray tracing
+ read(event_fd, &after, sizeof(struct read_format));
+ // save deltas in separate arrays
+ nanosecs[j * xsz + i] = after.time_running - before.time_running;
+ instrs [j * xsz + i] = after.values[0] - before.values[0];
+ cycles [j * xsz + i] = after.values[1] - before.values[1];
+ branches[j * xsz + i] = after.values[2] - before.values[2];
+ br_misps[j * xsz + i] = after.values[3] - before.values[3];
*fb++ = ((uint32_t)(MIN(r * rcp_samples, 1.0) * 255.0) & 0xff) << RSHIFT |
((uint32_t)(MIN(g * rcp_samples, 1.0) * 255.0) & 0xff) << GSHIFT |
((uint32_t)(MIN(b * rcp_samples, 1.0) * 255.0) & 0xff) << BSHIFT;
} }
+ // aggregate statistics and print it
...
}
在本代碼示例中,我們首先初始化 libpfm 庫,然后配置性能事件和讀取這些事件的格式。在 C-Ray 基準(zhǔn)中,渲染函數(shù)只被調(diào)用一次。在您自己的代碼中,請注意不要多次初始化 libpfm。
然后,我們選擇要分析的代碼區(qū)域。在我們的例子中,它是一個內(nèi)部帶有跟蹤函數(shù)調(diào)用的循環(huán)。我們在該代碼區(qū)域周圍使用兩個讀取系統(tǒng)調(diào)用來捕獲循環(huán)前后的性能計數(shù)器值。然后,我們保存脫鉤值,以便稍后處理。在本例中,我們通過計算平均值、第 90 百分位數(shù)和最大值對其進(jìn)行了匯總(代碼未顯示)。在英特爾 Alder Lake 處理器上運行,得到的輸出結(jié)果如下所示。讀取某個線程的計數(shù)器時,數(shù)值僅針對該線程。可以選擇包含歸屬于該線程的內(nèi)核代碼。
$ ./c-ray-f -s 1024x768 -r 2 -i sphfract -o output.ppm
Per-pixel ray tracing stats:
avg p90 max
-------------------------------------------------
nanoseconds | 4571 | 6139 | 25567
instructions | 71927 | 96172 | 165608
cycles | 20474 | 27837 | 118921
branches | 5283 | 7061 | 12149
branch-misses | 18 | 35 | 146
請記住,我們的儀器測量的是每個像素的光線跟蹤統(tǒng)計數(shù)據(jù)。用平均值乘以像素數(shù)(1024x768),就能大致得出程序的總統(tǒng)計信息。在這種情況下,運行 perf stat 并比較我們收集到的 C-Ray 性能事件的總體統(tǒng)計數(shù)據(jù),是一種很好的理智檢查方法。
C-Ray 基準(zhǔn)主要強(qiáng)調(diào) CPU 內(nèi)核的浮點運算性能,這通常不會導(dǎo)致測量結(jié)果出現(xiàn)較大差異,換句話說,我們希望所有測量結(jié)果都非常接近。然而,我們看到的情況并非如此,p90 值是平均值的 1.33 倍,而最大值比平均值慢 5 倍。這里最有可能的解釋是,對于某些像素,算法遇到了轉(zhuǎn)角情況,執(zhí)行了更多的指令,因此運行時間更長。
不過,通過研究源代碼或擴(kuò)展插樁來捕捉 “慢 ”像素的更多數(shù)據(jù),以確認(rèn)假設(shè)總是有好處的。
在我們的示例中,額外的檢測代碼會導(dǎo)致 17% 的開銷,這對于本地實驗來說還算可以,但如果在生產(chǎn)中運行,開銷就相當(dāng)大了。大多數(shù)大型分布式系統(tǒng)都希望開銷小于 1%,對于某些系統(tǒng)來說,5% 的開銷也是可以忍受的,但用戶不太可能對 17% 的減速感到滿意。插樁的開銷至關(guān)重要,尤其是在生產(chǎn)環(huán)境。
開銷可以用單位時間或工作(RPC、數(shù)據(jù)庫查詢、循環(huán)迭代等)的發(fā)生率來計算。如果在我們的系統(tǒng)中,讀取系統(tǒng)調(diào)用大約需要 1.6 微秒的 CPU 時間,而我們?yōu)槊總€像素調(diào)用兩次(外循環(huán)迭代),那么每個像素的開銷就是 3.2 微秒的 CPU 時間。
有許多策略可以降低開銷。
一般來說,插樁調(diào)用應(yīng)始終有固定成本,例如確定性系統(tǒng)調(diào)用,而不是列表遍歷或動態(tài)內(nèi)存分配。否則會干擾測量。儀器代碼有三個邏輯部分:收集信息、存儲信息和報告信息。為了降低第一部分(收集)的開銷,我們可以降低采樣率,例如,對每 10 個 RPC 進(jìn)行采樣,跳過其余的。對于長期運行的應(yīng)用程序,可以采用相對便宜的隨機(jī)取樣方法來監(jiān)控性能,即隨機(jī)選擇每次取樣要監(jiān)控的 RPC。這些方法犧牲了收集的準(zhǔn)確性,但仍能很好地估計整體性能特征,而且開銷極低。
對于第二和第三部分(存儲和聚合),建議只收集、處理和保留了解系統(tǒng)性能所需的數(shù)據(jù)。通過使用 “在線 ”算法計算平均值、方差、最小值、最大值和其他指標(biāo),可以避免在內(nèi)存中存儲每個樣本。這將大大減少儀器的內(nèi)存占用。例如,可使用 Knuth 的在線方差算法計算方差和標(biāo)準(zhǔn)差。一個好的實現(xiàn)使用不到 50 字節(jié)的內(nèi)存。
對于較長的例程,可以在開始和結(jié)束時收集計數(shù)器,并在中間收集部分計數(shù)器。在連續(xù)運行過程中,可以二進(jìn)制搜索例程中性能最差的部分,并對其進(jìn)行優(yōu)化。重復(fù)上述操作,直到去掉所有性能最差的部分。如果尾部延遲是主要問題,那么在特別慢的運行中發(fā)出日志信息可以提供有用的見解。
在我們的示例中,雖然 CPU 有 6 個可編程計數(shù)器,但我們同時收集了 4 個事件。您可以打開其他組,啟用不同的事件集。內(nèi)核會選擇不同的組同時運行。time_enabled 和 time_running 字段表示多路復(fù)用。它們都表示以納秒為單位的持續(xù)時間。time_enabled 字段表示事件組已啟用多少納秒。time_running(運行時間)字段表示在啟用的時間內(nèi)收集了多少事件。如果同時啟用了兩個事件組,而這兩個事件組在硬件計數(shù)器上無法同時顯示,那么兩個事件組的運行時間可能會趨近于 time_running = 0.5 * time_enabled。
同時捕獲多個事件可以計算我們在第 4 章中討論過的各種指標(biāo)。例如,捕獲 INSTRUCTIONS_RETIRED 和 UNHALTED_CLOCK_CYCLES 就可以測量 IPC。通過比較 CPU 周期(UNHALTED_CORE_CYCLES)和固定頻率參考時鐘(UNHALTED_REFERENCE_CYCLES),我們可以觀察到頻率縮放的影響。通過請求消耗的 CPU 周期(UNHALTED_CORE_CYCLES,僅在線程運行時計數(shù))并將其與掛鐘時間進(jìn)行比較,可以檢測線程何時未運行。此外,我們還可以對數(shù)字進(jìn)行歸一化處理,以獲得每秒/時鐘/指令的事件發(fā)生率。例如,通過測量 MEM_LOAD_RETIRED.L3_MISS 和 INSTRUCTIONS_RETIRED,我們可以得到 L3MPKI 指標(biāo)。如您所見,這提供了很大的靈活性。
對事件進(jìn)行分組的重要特性是,計數(shù)器將在同一讀取系統(tǒng)調(diào)用下以原子方式提供。這些原子捆綁非常有用。
首先,它允許我們將每個組內(nèi)的事件關(guān)聯(lián)起來。例如,假設(shè)我們測量了某個代碼區(qū)域的 IPC,發(fā)現(xiàn)它非常低。在這種情況下,我們可以將兩個事件(指令和周期)與第三個事件(如 L3 緩存未命中)配對,以檢查該事件是否導(dǎo)致了我們正在處理的低 IPC 問題。如果不是,我們可以使用其他事件繼續(xù)進(jìn)行因子分析。其次,事件分組有助于在工作負(fù)載具有不同階段時減少偏差。由于組內(nèi)的所有事件都是在同一時間測量的,因此它們總是捕捉到相同的階段。
在某些情況下,插樁可能會成為功能或特性的一部分。例如,開發(fā)人員可以實施一種儀器邏輯,用于檢測 IPC 的下降(例如,當(dāng)有一個繁忙的同級硬件線程在運行時)或 CPU 頻率的下降(例如,由于負(fù)載過重導(dǎo)致系統(tǒng)節(jié)流)。發(fā)生這種情況時,應(yīng)用程序會自動推遲低優(yōu)先級工作,以補(bǔ)償暫時增加的負(fù)載。
5.4 采樣
采樣是最常用的性能分析方法。人們通常將其與查找程序中的熱點聯(lián)系起來。廣義地說,抽樣有助于找到代碼中導(dǎo)致某些性能事件發(fā)生次數(shù)最多的地方。如果我們想找到熱點,問題可以重新表述為 “找到代碼中消耗 CPU 周期最多的地方"。人們經(jīng)常使用剖析profiling這一術(shù)語來描述技術(shù)上所謂的采樣(sampling)收集數(shù)據(jù)的技術(shù),包括取樣、代碼工具、跟蹤等。
最簡單的取樣剖析器就是調(diào)試器。事實上,你可以通過以下方法識別熱點:a) 在調(diào)試器下運行程序;b) 每 10 秒暫停程序;c) 記錄程序停止的位置。如果多次重復(fù) b) 和 c),就能從收集到的樣本中繪制出直方圖。停止次數(shù)最多的代碼行將是程序中最熱的地方。當(dāng)然,這并不是查找熱點的有效方法,我們也不建議這樣做。這只是為了說明概念。不過,這只是對真實剖析工具工作原理的簡化描述。現(xiàn)代剖析器每秒能收集數(shù)千個樣本,因此能非常準(zhǔn)確地估計出程序中最熱的地方。
與調(diào)試器的示例一樣,每采集到一個新樣本,就會中斷被分析程序的執(zhí)行。中斷時,剖析器會收集程序狀態(tài)快照,即一個樣本。每個樣本收集的信息可能包括中斷時執(zhí)行的指令地址、寄存器狀態(tài)、調(diào)用堆棧(參見第 5.4.3 節(jié))等。收集的樣本存儲在轉(zhuǎn)儲文件中,可用于顯示程序中最耗時的部分、調(diào)用圖等。
5.4.1 用戶模式和基于硬件事件的采樣
采樣可通過兩種不同模式進(jìn)行,即使用用戶模式或基于硬件事件的采樣 (EBS event-based sampling)。用戶模式采樣是一種純軟件方法,將代理庫嵌入到剖析應(yīng)用程序中。代理為應(yīng)用程序中的每個線程設(shè)置一個操作系統(tǒng)定時器。定時器到期時,應(yīng)用程序會收到代理處理的 SIGPROF 信號。EBS 使用硬件 PMC 觸發(fā)中斷。特別是 PMU 的計數(shù)器溢出功能,我們稍后將討論。
用戶模式采樣只能用于識別熱點,而 EBS 可用于涉及 PMC 的其他分析類型,如緩存遺漏采樣、自頂向下微架構(gòu)分析(見第 6.1 節(jié))等。與 EBS 相比,用戶模式采樣會產(chǎn)生更高的運行時開銷。當(dāng)采樣間隔為 10ms 時,用戶模式采樣的平均開銷約為 5%,而 EBS 的開銷不到 1%。由于 EBS 的開銷較小,因此可以使用更高的采樣率,從而獲得更準(zhǔn)確的數(shù)據(jù)。不過,用戶模式采樣產(chǎn)生的要分析的數(shù)據(jù)更少,處理時間也更短。
5.4.2 尋找熱點
在本節(jié)中,我們將討論將 PMC 與 EBS 配合使用的機(jī)制。下圖展示了 PMU 的計數(shù)器溢出功能,該功能用于觸發(fā)性能監(jiān)控中斷 (PMI),也稱為 SIGPROF。 在基準(zhǔn)測試開始時,我們配置要采樣的事件。對周期進(jìn)行采樣是許多剖析工具的默認(rèn)設(shè)置,因為我們想知道程序的大部分時間都花在了哪里。不過,這并不一定是嚴(yán)格的規(guī)則;我們可以對任何性能事件進(jìn)行采樣。例如,如果我們想知道程序在哪個位置發(fā)生了最多的 L3 緩存未命中,我們就會對相應(yīng)的事件(即 MEM_LOAD_RETIRED.L3_MISS)進(jìn)行采樣。
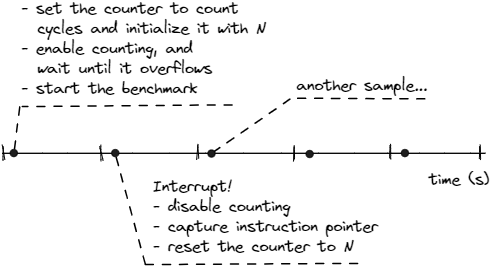
初始化寄存器后,我們開始計數(shù)并讓基準(zhǔn)運行。由于我們配置了 PMC 來計算周期,因此它將在每個周期內(nèi)遞增。
最終,它將溢出。當(dāng)寄存器溢出時,硬件將觸發(fā) PMI。剖析工具被配置為捕獲 PMI,并有一個處理 PMI 的中斷服務(wù)例程(ISR Interrupt Service Routine)。我們在 ISR 中執(zhí)行多個步驟:首先,禁止計數(shù);然后,記錄計數(shù)器溢出時 CPU 執(zhí)行的指令;然后,將計數(shù)器重置為 N,并恢復(fù)基準(zhǔn)測試。
現(xiàn)在,讓我們回到 N 值。利用該值,我們可以控制獲得新中斷的頻率。假設(shè)我們想要更精細(xì)的粒度,每 100 萬個周期采樣一次。為此,我們可以將計數(shù)器設(shè)置為(無符號)-1,000,000,這樣它就會在每 100 萬個周期后溢出。這個值也被稱為采樣后值。
我們要多次重復(fù)這一過程,以建立足夠的樣本集合。如果我們稍后匯總這些樣本,就能繪制出程序中最熱位置的直方圖,就像下面 Linux perf 記錄/報告輸出中顯示的那樣。這為我們提供了按降序(熱點)排序的程序功能開銷明細(xì)。下圖是對 Phoronix 測試套件中的 x264基準(zhǔn)進(jìn)行采樣的示例:
$ time -p perf record -F 1000 -- ./x264 -o /dev/null --slow --threads 1 ../Bosphorus_1920x1080_120fps_420_8bit_YUV.y4m
[ perf record: Captured and wrote 1.625 MB perf.data (35035 samples) ]
real 36.20 sec
$ perf report -n --stdio
# Samples: 35K of event 'cpu_core/cycles/'
# Event count (approx.): 156756064947
# Overhead Samples Shared Object Symbol
# ........ ....... ............. ........................................
7.50% 2620 x264 [.] x264_8_me_search_ref
7.38% 2577 x264 [.] refine_subpel.lto_priv.0
6.51% 2281 x264 [.] x264_8_pixel_satd_8x8_internal_avx2
6.29% 2212 x264 [.] get_ref_avx2.lto_priv.0
5.07% 1787 x264 [.] x264_8_pixel_avg2_w16_sse2
3.26% 1145 x264 [.] x264_8_mc_chroma_avx2
2.88% 1013 x264 [.] x264_8_pixel_satd_16x8_internal_avx2
2.87% 1006 x264 [.] x264_8_pixel_avg2_w8_mmx2
2.58% 904 x264 [.] x264_8_pixel_satd_8x8_avx2
2.51% 882 x264 [.] x264_8_pixel_sad_16x16_sse2
...
Linux perf 收集了 35,035 個樣本,這意味著有相同數(shù)量的進(jìn)程中斷。我們還使用了 -F 1000,將采樣率設(shè)置為每秒 1000 個樣本。這與 36.2 秒的總體運行時間大致吻合。請注意,Linux perf 提供了總運行周期的大致數(shù)字。如果用它除以采樣次數(shù),我們將得到 156756064947 個周期/35035 個采樣 =每個樣本消耗 450 萬個周期。也就是說,Linux perf 將 N 設(shè)置為大約 4500000,每秒就能采集 1000 個樣本。Linux perf 可以根據(jù)實際 CPU 頻率動態(tài)調(diào)整 N。
當(dāng)然,對我們來說最有價值的是按每個函數(shù)的樣本數(shù)量排序的熱點列表。知道了最熱門的函數(shù)之后,我們可能還想再深入研究一下:每個函數(shù)內(nèi)部有哪些熱門代碼部分?要查看內(nèi)聯(lián)函數(shù)的剖析數(shù)據(jù)以及特定源代碼區(qū)域生成的匯編代碼,我們需要使用調(diào)試信息(-g 編譯器標(biāo)志)構(gòu)建應(yīng)用程序。
Linux perf 沒有豐富的圖形支持,因此查看源代碼的熱點部分不是很方便,但還是可以做到的。Linux perf 將源代碼與生成的程序集混合在一起,如下所示:
# snippet of annotating source code of 'x264_8_me_search_ref' function
$ perf annotate x264_8_me_search_ref --stdio
Percent | Source code & Disassembly of x264 for cycles:ppp
----------------------------------------------------------
...
: bmx += square1[bcost&15][0]; <== source code
1.43 : 4eb10d: movsx ecx,BYTE PTR [r8+rdx*2] <== corresponding machine code
: bmy += square1[bcost&15][1];
0.36 : 4eb112: movsx r12d,BYTE PTR [r8+rdx*2+0x1]
: bmx += square1[bcost&15][0];
0.63 : 4eb118: add DWORD PTR [rsp+0x38],ecx
: bmy += square1[bcost&15][1];
...
大多數(shù)帶有圖形用戶界面(GUI)的剖析器(如 Intel VTune Profiler)都能并排顯示源代碼和相關(guān)程序集。此外,還有一些工具可以通過類似 Intel VTune 和其他工具的豐富圖形界面,將 Linux perf 原始數(shù)據(jù)的輸出可視化。你將在第 7 章中看到更多細(xì)節(jié)。
采樣可以很好地統(tǒng)計程序的執(zhí)行情況,但這種技術(shù)的缺點之一是存在盲點,不適合檢測異常行為。每個樣本都代表了程序執(zhí)行過程中的一部分聚合視圖。聚合并不能為我們提供足夠的細(xì)節(jié),讓我們了解該時間間隔內(nèi)到底發(fā)生了什么。我們無法放大樣本以了解更多執(zhí)行的細(xì)微差別。當(dāng)我們將時間間隔壓縮成樣本時,就會丟失有價值的信息,而且對于分析持續(xù)時間很短的事件也毫無用處。
例如,對一個會對網(wǎng)絡(luò)數(shù)據(jù)包做出反應(yīng)的程序(如股票交易軟件)進(jìn)行剖析可能信息量不大,因為它會將大部分樣本歸因于繁忙的等待循環(huán)。增加采樣間隔,例如每秒采樣 1000 次以上,可能會獲得更好的圖像,但可能仍然不夠。作為一種解決方案,您應(yīng)該使用跟蹤,因為它不會跳過感興趣的事件。
5.4.3 收集調(diào)用棧
通常在采樣時,我們可能會遇到程序中最熱的函數(shù)被多個函數(shù)調(diào)用的情況。下圖是這種情況的一個示例。剖析工具的輸出可能會顯示 foo 是程序中最熱的函數(shù)之一,但如果它有多個調(diào)用者,我們就想知道哪個調(diào)用者調(diào)用 foo 的次數(shù)最多。這是應(yīng)用程序中出現(xiàn) memcpy 或 sqrt 等庫函數(shù)熱點的典型情況。要了解某個函數(shù)成為熱點的原因,我們需要知道是程序控制流圖 (CFG) 中的哪條路徑造成的。
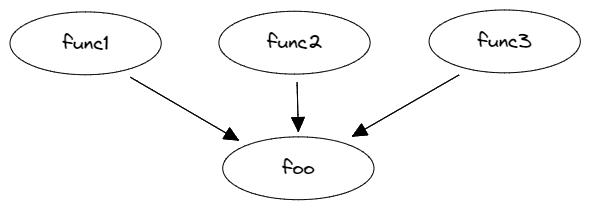
分析 foo 所有調(diào)用者的源代碼可能非常耗時。我們只想關(guān)注那些導(dǎo)致 foo 成為熱點的調(diào)用者。換句話說,我們要找出程序 CFG 中最熱門的路徑。剖析工具通過在收集性能樣本時捕獲進(jìn)程的調(diào)用堆棧和其他信息來實現(xiàn)這一目的。然后,對所有收集到的堆棧進(jìn)行分組,讓我們看到通往特定函數(shù)的最熱路徑。
在 Linux perf 中收集調(diào)用堆棧有三種方法:
-
- 幀指針(perf record --call-graph fp)。它要求使用 --fno-omit-frame-pointer 構(gòu)建二進(jìn)制文件。從歷史上看,幀指針(RBP 寄存器)被用于調(diào)試,因為它能讓我們在不彈出堆棧中所有參數(shù)的情況下獲取調(diào)用堆棧(也稱為 “堆棧解卷”)。
幀指針可以立即顯示返回地址。幀指針能以非常低廉的成本實現(xiàn)堆棧解卷,從而減少剖析開銷,不過,僅為此目的就需要消耗一個額外的寄存器。在架構(gòu)寄存器數(shù)量較少的時候,使用幀指針在運行時性能方面代價高昂。如今,Linux 社區(qū)正在重新使用幀指針,因為它提供了質(zhì)量更好的調(diào)用堆棧和較低的剖析開銷。
- 幀指針(perf record --call-graph fp)。它要求使用 --fno-omit-frame-pointer 構(gòu)建二進(jìn)制文件。從歷史上看,幀指針(RBP 寄存器)被用于調(diào)試,因為它能讓我們在不彈出堆棧中所有參數(shù)的情況下獲取調(diào)用堆棧(也稱為 “堆棧解卷”)。
-
- DWARF 調(diào)試信息(perf record --call-graph dwarf)。它要求二進(jìn)制文件在構(gòu)建時包含 DWARF 調(diào)試信息 (-g)。它還可以通過堆棧解卷過程獲取調(diào)用堆棧,但這種方法比使用幀指針更昂貴。
-
- 英特爾最后分支記錄(LBR)。這種方法利用了硬件特性,使用以下命令即可訪問: perf record --call-graph lbr。
它通過解析 LBR 堆棧(一組硬件寄存器)來獲取調(diào)用堆棧。生成的調(diào)用圖沒有前兩種方法生成的調(diào)用圖深。有關(guān) LBR 調(diào)用棧模式的更多信息,請參見第 6.2 節(jié)。
- 英特爾最后分支記錄(LBR)。這種方法利用了硬件特性,使用以下命令即可訪問: perf record --call-graph lbr。
下面是一個使用 LBR 在程序中收集調(diào)用堆棧的示例。通過查看輸出結(jié)果,我們可以知道 55% 的時間 foo 是由 func1 調(diào)用的,33% 的時間是由 func2 調(diào)用的,11% 的時間是由 fun3 調(diào)用的。我們可以清楚地看到 foo 的調(diào)用者之間的開銷分布,現(xiàn)在可以把注意力集中在程序 CFG 中最熱的一條邊上,即 func1 → foo,但我們或許也應(yīng)該關(guān)注一下 func2 → foo 這一條邊。
$ perf record --call-graph lbr -- ./a.out
$ perf report -n --stdio --no-children
# Samples: 65K of event 'cycles:ppp'
# Event count (approx.): 61363317007
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................ ......................
99.96% 65217 a.out a.out [.] foo
|
--99.96%--foo
|
|--55.52%--func1
| main
| __libc_start_main
| _start
|
|--33.32%--func2
| main
| __libc_start_main
| _start
|
--11.12%--func3
main
__libc_start_main
_start
使用英特爾 VTune Profiler 時,在配置分析時選中相應(yīng)的 “收集堆棧 ”框,即可收集調(diào)用堆棧數(shù)據(jù)。使用命令行界面時,指定 -knob enable-stack-collection=true 選項。
5.5 Roofline 性能模型
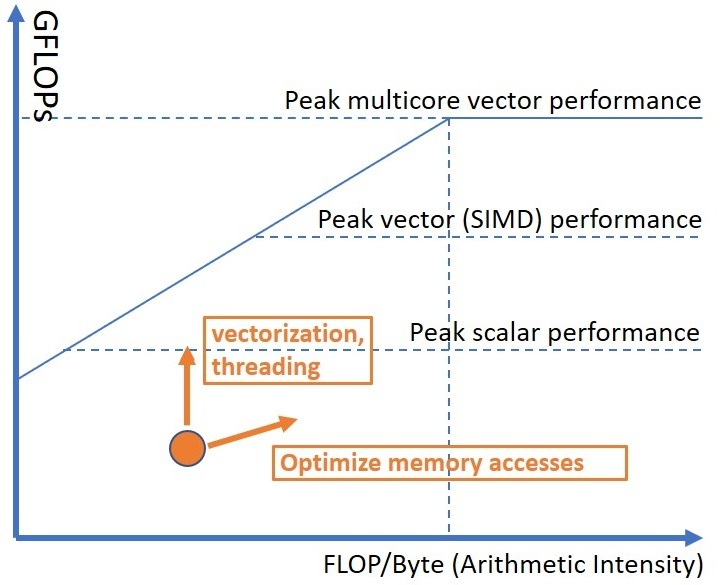
Roofline 性能模型是一種面向吞吐量的性能模型,在高性能計算領(lǐng)域得到廣泛應(yīng)用。它于 2009 年在加州大學(xué)伯克利分校開發(fā)Williams 等人,2009。該模型中的 “topline ”一詞表示應(yīng)用程序的性能不能超過機(jī)器的能力。程序中的每個函數(shù)和每個循環(huán)都受限于機(jī)器的計算能力或內(nèi)存帶寬。這一概念如圖所示。應(yīng)用程序的性能總會受到某個 “屋頂線 ”函數(shù)的限制。
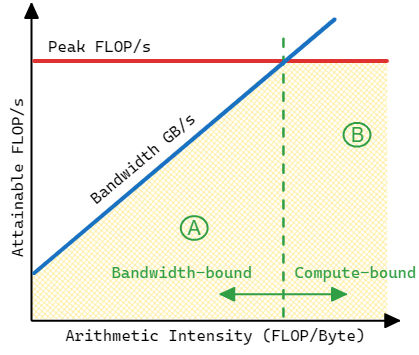
應(yīng)用程序的最高性能受限于峰值 FLOPS(水平線)與平臺帶寬乘以算術(shù)強(qiáng)度(對角線)之間的最小值。
硬件有兩個主要限制:計算速度(峰值計算性能,F(xiàn)LOPS)和數(shù)據(jù)移動速度(峰值內(nèi)存帶寬,GB/s)。應(yīng)用程序的最高性能受限于 FLOPS 峰值(水平線)與平臺帶寬乘以算術(shù)強(qiáng)度(對角線)之間的最小值。屋頂線圖顯示了兩個應(yīng)用程序 A 和 B 的性能與硬件限制之間的關(guān)系。應(yīng)用程序 A 的算術(shù)強(qiáng)度較低,其性能受到內(nèi)存帶寬的限制,而應(yīng)用程序 B 的計算強(qiáng)度較高,不會受到內(nèi)存瓶頸的影響。與此類似,A 和 B 可以代表程序中的兩個不同功能,并具有不同的性能特征。Roofline 性能模型考慮到了這一點,可以在同一圖表上顯示應(yīng)用程序的多個功能和循環(huán)。不過,請記住,Roofline 性能模型主要適用于計算密集型循環(huán)較少的 HPC 應(yīng)用程序。我不建議將其用于通用應(yīng)用程序,如編譯器、網(wǎng)絡(luò)瀏覽器或數(shù)據(jù)庫。
算術(shù)強(qiáng)度是浮點運算(FLOPs)88 與字節(jié)數(shù)之間的比率,可以為程序中的每個循環(huán)計算。讓我們來計算下面中代碼的算術(shù)強(qiáng)度。在最內(nèi)層的循環(huán)體中,我們有一個浮點加法和一個乘法,因此有 2 個 FLOP。此外,我們還進(jìn)行了三次讀操作和一次寫操作;因此,我們傳輸了 4 個操作 * 4 個字節(jié) = 16 個字節(jié)。該代碼的算術(shù)強(qiáng)度為 2 / 16 = 0.125。算術(shù)強(qiáng)度是 “屋頂線 ”圖表上的 X 軸,而 Y 軸則用來衡量特定程序的性能。
void matmul(int N, float a[][2048], float b[][2048], float c[][2048]) {
#pragma omp parallel for
for(int i = 0; i < N; i++) {
for(int j = 0; j < N; j++) {
for(int k = 0; k < N; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}
加快應(yīng)用程序性能的傳統(tǒng)方法是充分利用機(jī)器的 SIMD 和多核功能。通常,我們需要對多個方面進(jìn)行優(yōu)化:
矢量化、內(nèi)存和線程。屋頂線方法可以幫助評估應(yīng)用程序的這些特性。在屋頂線圖上,我們可以繪制標(biāo)量單核、SIMD 單核和 SIMD 多核性能的理論最大值(見下圖)。這將使我們了解提高應(yīng)用程序性能的空間。如果我們發(fā)現(xiàn)自己的應(yīng)用程序?qū)儆谟嬎慵s束型(即算術(shù)強(qiáng)度高),并且低于標(biāo)量單核性能峰值,我們就應(yīng)該考慮強(qiáng)制矢量化(見第 9.4 節(jié)),并將工作分配給多個線程。相反,如果應(yīng)用的算術(shù)強(qiáng)度較低,我們就應(yīng)該設(shè)法改善內(nèi)存訪問(參見第 8 章)。使用 “屋頂線 ”模型優(yōu)化性能的最終目標(biāo)是將圖表上的點向上移動。
矢量化和線程化會使點向上移動,而通過提高算術(shù)強(qiáng)度來優(yōu)化內(nèi)存訪問則會使點向右移動,也有可能提高性能。
理論最大值(頂線)通常在設(shè)備規(guī)格書中列出,很容易查找。此外,理論最大值還可以根據(jù)所使用機(jī)器的特性計算出來。通常,只要知道機(jī)器的參數(shù),就不難計算。對于英特爾酷睿 i5-8259U 處理器,使用 AVX2 和 2 Fused Multiply 時的最大 FLOPS(單精度浮點運算)數(shù)為添加 (FMA) 單元的計算公式為:
添加 (FMA) 單元的計算公式為

我用于實驗的英特爾 NUC 套件 NUC8i5BEH 的最大內(nèi)存帶寬計算如下。請記住,DDR 技術(shù)允許每次內(nèi)存訪問傳輸 64 位或 8 字節(jié)。

Empirical Roofline Tool 和 Intel Advisor 等自動化工具能夠通過運行一組準(zhǔn)備好的基準(zhǔn),根據(jù)經(jīng)驗確定理論最大值。如果計算可以重復(fù)使用高速緩存中的數(shù)據(jù),就有可能獲得更高的 FLOP 速率。
Roofline 可以通過為每一級內(nèi)存層次結(jié)構(gòu)引入專用的屋頂線來考慮這一點。
確定硬件限制后,我們就可以開始根據(jù)屋頂線評估應(yīng)用程序的性能。英特爾顧問會自動繪制屋頂線圖,并為特定循環(huán)的性能優(yōu)化提供提示。下圖是英特爾顧問生成的屋頂線圖示例。請注意,屋頂線圖采用對數(shù)刻度。下圖使用 Clang 10 編譯器在配備 8GB 內(nèi)存的英特爾 NUC 套件 NUC8i5BEH 上對矩陣乘法 “之前 ”和 “之后 ”版本進(jìn)行的 Roofline 分析。
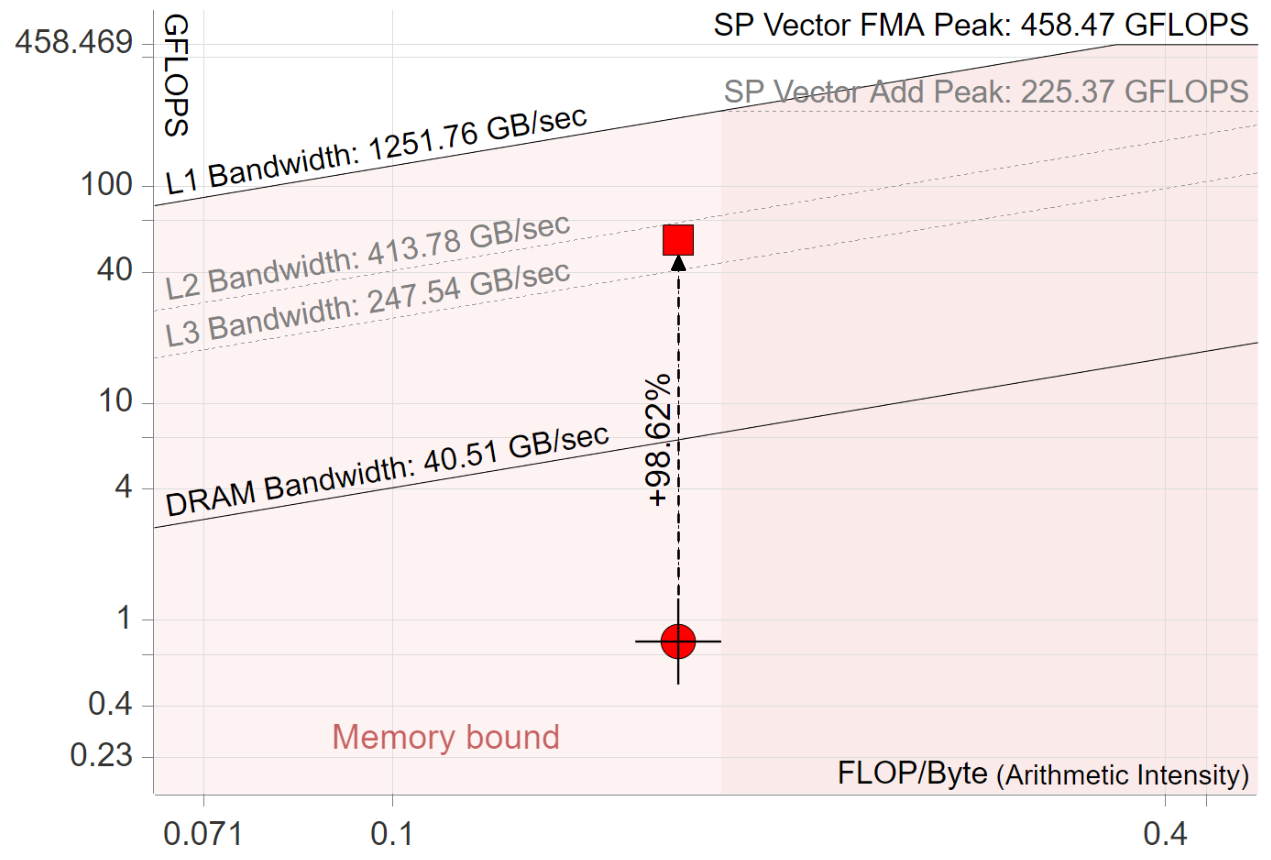
Roofline 方法通過在同一圖表上繪制 “之前 ”和 “之后 ”的點來跟蹤優(yōu)化進(jìn)度。因此,這是一個迭代過程,可指導(dǎo)開發(fā)人員幫助其應(yīng)用程序充分利用硬件功能。上圖顯示對對上面代碼進(jìn)行以下兩處修改后的性能提升:
- 交換最內(nèi)層的兩個循環(huán)(交換行 4 和 5)。這樣可以實現(xiàn)高速緩沖存儲器訪問(參見第 8 章)。
- 使用 AVX2 指令啟用最內(nèi)層循環(huán)的自動矢量化。
總之,Roofline 性能模型有助于 - 識別性能瓶頸。
- 指導(dǎo)軟件優(yōu)化。
- 確定何時完成優(yōu)化。
- 評估相對于機(jī)器能力的性能。
5.6 靜態(tài)性能分析
如今,我們擁有大量的靜態(tài)代碼分析工具。對于 C 和 C++ 語言,我們有 Clang static analyzer、Klocwork、Cppcheck 等著名工具。這些工具旨在檢查代碼的正確性和語義。同樣,有些工具也試圖解決代碼性能方面的問題。靜態(tài)性能分析器不執(zhí)行程序,也不對程序進(jìn)行剖析。相反,它們會模擬代碼在真實硬件上的執(zhí)行情況。靜態(tài)預(yù)測性能幾乎是不可能的,因此這類分析有很多局限性。
首先,靜態(tài)分析 C/C++ 代碼的性能是不可能的,因為我們不知道它將被編譯成何種機(jī)器代碼。因此,靜態(tài)性能分析適用于匯編代碼。其次,靜態(tài)分析工具模擬工作負(fù)載,而不是執(zhí)行工作負(fù)載。這顯然非常緩慢,因此不可能對整個程序進(jìn)行靜態(tài)分析。相反,工具會截取一段匯編代碼,并嘗試預(yù)測它在真實硬件上的表現(xiàn)。用戶應(yīng)選擇特定的匯編指令(通常是一個小循環(huán))進(jìn)行分析。因此,靜態(tài)性能分析的范圍非常狹窄。
靜態(tài)性能分析器的輸出相當(dāng)?shù)图墸ǔ?zhí)行分解為 CPU 周期。通常,開發(fā)人員將其用于對關(guān)鍵代碼區(qū)域進(jìn)行細(xì)粒度調(diào)整,在該區(qū)域中,每個 CPU 周期都很重要。
- 靜態(tài)分析與動態(tài)分析
靜態(tài)工具: 它們不運行實際代碼,而是嘗試模擬執(zhí)行,盡可能多地保留微體系結(jié)構(gòu)細(xì)節(jié)。由于不運行代碼,它們無法進(jìn)行實際測量(執(zhí)行時間、性能計數(shù)器)。這樣做的好處是,你不需要真正的硬件,就可以在不同世代的 CPU 上模擬代碼。另一個好處是,您無需擔(dān)心結(jié)果的一致性:靜態(tài)分析儀將始終為您提供確定的輸出結(jié)果,因為模擬(與在真實硬件上的執(zhí)行相比)不存在任何偏差。靜態(tài)工具的缺點在于,它們通常無法預(yù)測和模擬現(xiàn)代 CPU 內(nèi)部的一切:它們所基于的模型可能存在缺陷和局限性。靜態(tài)性能分析儀的例子有 UICA91 和 llvm-mca。
動態(tài)工具:它們基于在真實硬件上運行代碼,并收集執(zhí)行過程中的各種信息。這是證明任何性能假設(shè)的唯一 100% 可靠方法。但缺點是,收集 PMC 等低級性能數(shù)據(jù)通常需要一定的訪問權(quán)限。要編寫一個好的基準(zhǔn)并測量你想測量的東西并非易事。最后,您還需要過濾噪音和噪聲。最后,還需要過濾噪聲和各種副作用。nanoBench 和 uarch-bench 是動態(tài)微體系結(jié)構(gòu)性能分析工具的兩個例子。這里有更多的靜態(tài)和動態(tài)微體系結(jié)構(gòu)性能分析工具。
5.6.1 案例研究:使用 UICA 優(yōu)化 FMA 吞吐量
開發(fā)人員經(jīng)常問的問題之一是:"最新的處理器有 10+ 的吞吐量?“最新的處理器有 10 多個執(zhí)行單元,我該如何編寫代碼才能讓它們一直忙個不停?這的確是最難解決的問題之一。有時,這需要在顯微鏡下觀察程序是如何運行的。UICA 模擬器就是這樣一個顯微鏡,它可以幫助你深入了解代碼是如何在現(xiàn)代處理器中運行的。
讓我們來看代碼。我有意讓示例盡可能簡單。當(dāng)然,實際代碼通常比這更復(fù)雜。代碼用浮點數(shù)值 B 對數(shù)組 a 的每個元素進(jìn)行縮放,并將乘積累加為總和。右圖是 Clang-16 在使用 -O3 -ffast-math -march=core-avx2 編譯時生成的循環(huán)機(jī)器碼。
float foo(float * a, float B, int N){ │ .loop:
float sum = 0; │ vfmadd231ps ymm2, ymm1, ymmword [rdi + rsi]
for (int i = 0; i < N; i++) │ vfmadd231ps ymm3, ymm1, ymmword [rdi + rsi + 32]
sum += a[i] * B; │ vfmadd231ps ymm4, ymm1, ymmword [rdi + rsi + 64]
return sum; │ vfmadd231ps ymm5, ymm1, ymmword [rdi + rsi + 96]
} │ sub rsi, -128
│ cmp rdx, rsi
│ jne .loop
這是一個還原循環(huán),即我們需要將所有乘積相加,最后返回一個浮點數(shù)值。這段代碼的寫法是,在 sum 上有一個循環(huán)攜帶依賴關(guān)系。在累加前一個乘積之前,不能覆蓋 sum。要實現(xiàn)并行化,一種聰明的方法是使用多個累加器,最后將它們累加起來。因此,我們可以用 sum1 來累加偶數(shù)迭代的結(jié)果,用 sum2 來累加奇數(shù)迭代的結(jié)果,而不是單個 sum。
Clang-16 就是這樣做的:它有 4 個矢量(ymm2-ymm5),每個矢量有 8 個浮點累加器,另外它還使用 FMA 將乘法和加法合并為一條指令。常數(shù) B 被廣播到 ymm1 寄存器中。-ffast-math選項允許編譯器重新關(guān)聯(lián)浮點運算;我們將在第9.4.96節(jié)討論該選項如何幫助優(yōu)化代碼。讓我們一探究竟。我們將清單 5.5 中的匯編代碼段移植到 UICA 中并進(jìn)行了仿真。在撰寫本文時,UICA 尚不支持 Alder Lake(基于 Golden Cove 的英特爾第 12 代處理器),因此我們在最新的 Rocket Lake(基于 Sunny Cove 的英特爾第 11 代處理器)上運行了它。
雖然架構(gòu)不同,但本實驗所暴露的問題在兩種架構(gòu)上都同樣明顯。模擬結(jié)果如圖所示。這是一個流水線圖,與我們在第 3 章中展示的類似。我們跳過了前兩次迭代,只顯示了迭代 2 和 3(最左列 “It”)。此時執(zhí)行達(dá)到穩(wěn)定狀態(tài),所有后續(xù)迭代看起來都非常相似。
UICA 是實際 CPU 流水線的一個非常簡化的模型。例如,你可能會注意到指令獲取和解碼階段缺失了。此外,UICA 也沒有考慮緩存未命中和分支預(yù)測錯誤的情況,因此它假定所有內(nèi)存訪問總是命中 L1 緩存,分支預(yù)測總是正確,而我們知道現(xiàn)代處理器的情況并非如此。同樣,這與我們的實驗無關(guān),因為我們?nèi)匀豢梢岳梅抡娼Y(jié)果找到改進(jìn)代碼的方法。
你能看出性能問題嗎?讓我們來看看圖表。首先,每 96 個元素中就有一個元素是 “a”,而不是 “B”。這是程序員的疏忽,但希望編譯器將來能處理好這個問題。
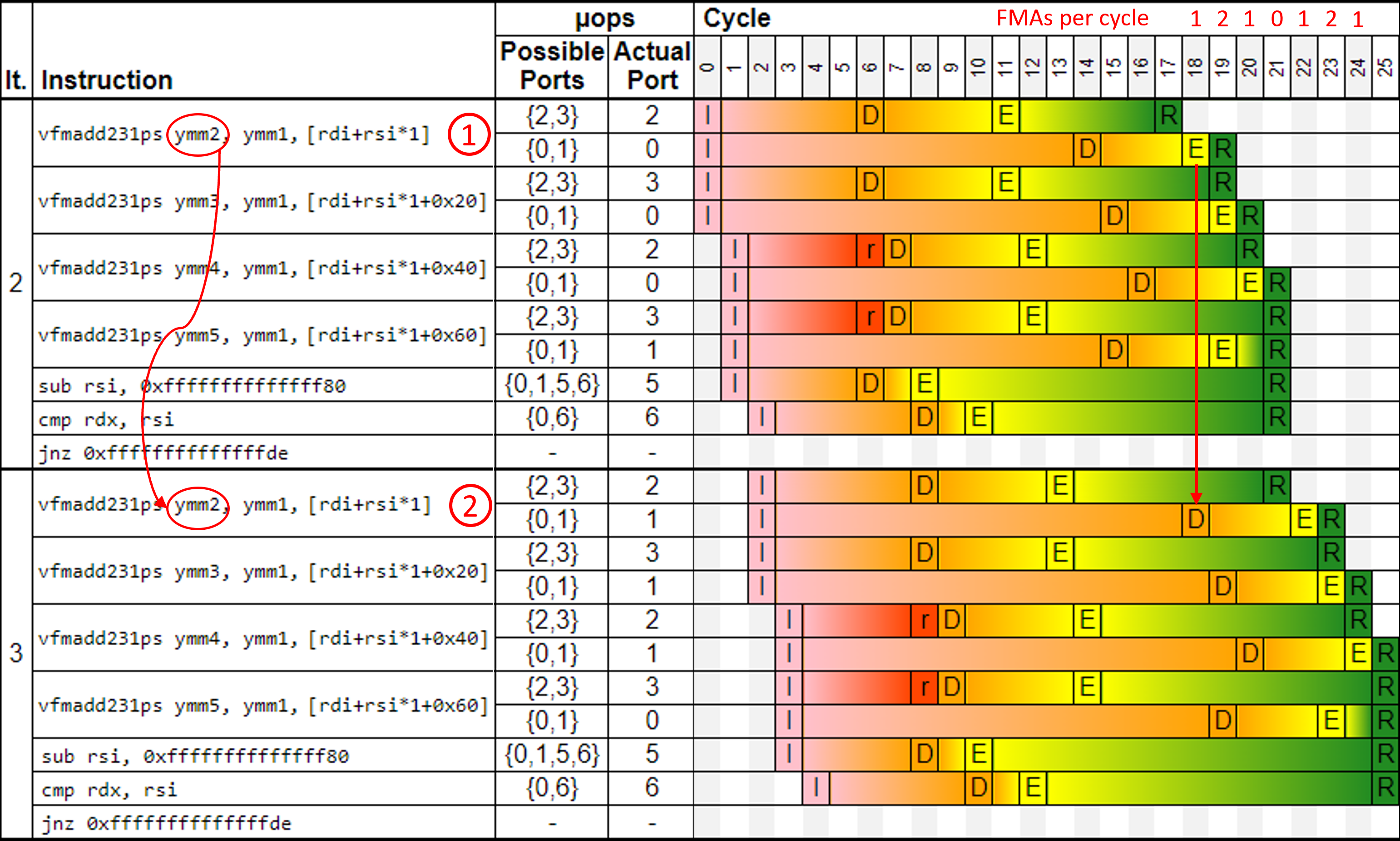
UICA 流水線圖 I = issued, r = ready for dispatch, D = dispatched, E = executed, R = retired.
FMA 指令分為兩個 μop:一個是進(jìn)入端口 {2,3} 的加載 μop,另一個是可以進(jìn)入端口 {0,1} 的 FMA μop。負(fù)載 μop 的延遲時間為 5 個周期:從周期 7 開始,到周期 11 結(jié)束。FMA μop 的延遲時間為 4 個周期:從周期 15 開始,到周期 18 結(jié)束。如圖所示,所有 FMA μops 都依賴于負(fù)載 μops: FMA μops 總是在相應(yīng)的負(fù)載 μop 結(jié)束后啟動。現(xiàn)在,在周期 6 找到兩個 r 單元,它們已準(zhǔn)備好被分派,但 Rocket Lake 只有兩個負(fù)載端口,而且在同一周期內(nèi)這兩個端口都已被占用。因此,這兩個負(fù)載將在下一個周期發(fā)出。
該循環(huán)對 ymm2-ymm5 有四個交叉迭代依賴關(guān)系。指令 2 中寫入 ymm2 的 FMA μop 不能在上一次迭代的指令 1 執(zhí)行完畢之前開始執(zhí)行。請注意,指令 2 中的 FMA μop 是在指令 1 執(zhí)行完畢后的第 18 周期派發(fā)的。指令 1 和指令 2 之間存在數(shù)據(jù)依賴關(guān)系。您還可以在其他 FMA 指令中觀察到這種模式。那么,你會問 "問題出在哪里?請看圖像的右上角。
在每個周期中,我們添加了執(zhí)行的 FMA μops 數(shù)量(UICA 不會打印)。結(jié)果是 1,2,1,0,1,2,1,.....,即平均每個周期執(zhí)行一個 FMA μoop。
大多數(shù)最新的英特爾處理器都有兩個 FMA 執(zhí)行單元,因此每個周期可以執(zhí)行兩個 FMA μOP。因此,我們只利用了可用 FMA 執(zhí)行吞吐量的一半。圖中清楚地顯示了這一差距,因為每隔四個周期就沒有 FMA 執(zhí)行。正如我們之前發(fā)現(xiàn)的那樣,由于 FMA μops 的輸入(ymm2-ymm5)尚未準(zhǔn)備就緒,因此無法派發(fā) FMA μops。
要將 FMA 執(zhí)行單元的利用率從 50%提高到 100%,我們需要將累加器數(shù)量翻倍,從 4 個增加到 8 個,從而有效地將循環(huán)展開 2 倍。我們將有 8 個獨立的數(shù)據(jù)流鏈,而不是 4 個。我不會在這里展示解卷版本的仿真結(jié)果,你可以自己進(jìn)行實驗。
相反,讓我們通過在真實硬件上運行這兩個版本來證實假設(shè)。
順便說一句,驗證總是個好主意,因為像 UICA 這樣的靜態(tài)性能分析器并不是精確的模型。下面,我們將展示在 Alder Lake 處理器上運行的兩個 nanoBench 測試的輸出結(jié)果。該工具使用提供的匯編指令(-asm 選項)創(chuàng)建基準(zhǔn)內(nèi)核。讀者可以在 nanoBench 文檔中查找其他參數(shù)的含義。左側(cè)的原始代碼在 4 個周期內(nèi)執(zhí)行 4 條指令,而改進(jìn)后的版本可以在 4 個周期內(nèi)執(zhí)行 8 條指令。現(xiàn)在我們可以確定我們已經(jīng)最大限度地提高了 FMA 的執(zhí)行吞吐量,因為右邊的代碼讓 FMA 單元一直處于忙碌狀態(tài)。
在英特爾酷睿 i7-1260P (Alder Lake) 上運行

指令退役 8.00 內(nèi)核周期 4.00 作為經(jīng)驗法則,在這種情況下,循環(huán)必須以 T * L 的系數(shù)展開,其中 T 是指令的吞吐量,L 是指令的延遲。在我們的例子中,由于 Alder Lake 上 FMA 的吞吐量為 2,而 FMA 的延遲為 4 個周期,因此我們應(yīng)將其展開 2 * 4 = 8,以實現(xiàn) FMA 端口的最大利用率。這樣就創(chuàng)建了 8 個可獨立執(zhí)行的數(shù)據(jù)流鏈。
值得一提的是,在實際應(yīng)用中,你并不總能看到 2 倍的速度提升。這只能在 UICA 或 nanoBench 等理想化環(huán)境中實現(xiàn)。在實際應(yīng)用中,即使你最大限度地提高了 FMA 的執(zhí)行吞吐量,但最終的緩存缺失和其他流水線危險可能會阻礙其收益。當(dāng)出現(xiàn)這種情況時,緩存未命中的影響會超過 FMA 端口利用率未達(dá)到最佳狀態(tài)的影響,這很容易導(dǎo)致 5% 的速度提升令人失望。不過不用擔(dān)心,你還是做對了。
最后,讓我們提醒您,UICA 或其他靜態(tài)性能分析器并不適合分析大段代碼。但它們非常適合用于探索微架構(gòu)效應(yīng)。此外,它們還能幫助您建立 CPU 工作原理的心智模型。UICA 的另一個重要用例是查找循環(huán)中的關(guān)鍵依賴鏈,這在 Easyperf 博客的一篇文章中有所描述。
5.7 編譯器優(yōu)化報告
如今,軟件開發(fā)在很大程度上依賴于編譯器進(jìn)行性能優(yōu)化。編譯器在加快軟件速度方面發(fā)揮著至關(guān)重要的作用。大多數(shù)開發(fā)人員將優(yōu)化代碼的工作交給編譯器,只有當(dāng)他們發(fā)現(xiàn)有機(jī)會改進(jìn)編譯器無法完成的工作時,才會進(jìn)行干預(yù)。可以說,這是一種很好的默認(rèn)策略。但是,當(dāng)你希望盡可能獲得最佳性能時,這種策略就不太管用了。如果編譯器未能執(zhí)行關(guān)鍵的優(yōu)化,比如對循環(huán)進(jìn)行矢量化呢?你怎么知道呢?幸運的是,所有主流編譯器都提供優(yōu)化報告,我們現(xiàn)在就來討論一下。
假設(shè)你想知道一個臨界循環(huán)是否解卷。如果是解卷,解卷因子是多少?有一個很難知道的方法:研究生成的匯編指令。遺憾的是,并不是所有人都能自如地閱讀匯編語言。如果函數(shù)很大,調(diào)用了其他函數(shù),或者有很多也被矢量化的循環(huán),或者編譯器為同一個循環(huán)創(chuàng)建了多個版本,那么閱讀起來就會特別困難。大多數(shù)編譯器(包括 GCC、Clang、Intel 編譯器和 MSVC98)都提供了優(yōu)化報告,以檢查對特定代碼進(jìn)行了哪些優(yōu)化。
下例為未被 clang 16.0 向量化的循環(huán)示例。
void foo(float* __restrict__ a,
float* __restrict__ b,
float* __restrict__ c,
unsigned N) {
for (unsigned i = 1; i < N; i++) {
a[i] = c[i-1]; // value is carried over from previous iteration
c[i] = b[i];
}
}
要在 Clang 編譯器中發(fā)布優(yōu)化報告,需要使用 -Rpass* 標(biāo)志:
$ clang -O3 -Rpass-analysis=.* -Rpass=.* -Rpass-missed=.* a.c -c
a.c:5:3: remark: loop not vectorized [-Rpass-missed=loop-vectorize]
for (unsigned i = 1; i < N; i++) {
^
a.c:5:3: remark: unrolled loop by a factor of 8 with run-time trip count [-Rpass=loop-unroll]
for (unsigned i = 1; i < N; i++) {
^
通過查看上面的優(yōu)化報告,我們可以發(fā)現(xiàn)該循環(huán)沒有被矢量化,而是被展開了。
對于開發(fā)人員來說,要識別循環(huán)依賴關(guān)系并非易事。c[i-1] 加載的值取決于上一次迭代的存儲(。通過手動展開循環(huán)的前幾次迭代,可以發(fā)現(xiàn)這種依賴關(guān)系:
// iteration 1
a[1] = c[0];
c[1] = b[1]; // writing the value to c[1]
// iteration 2
a[2] = c[1]; // reading the value of c[1]
c[2] = b[2];

如果我們對進(jìn)行矢量化,將導(dǎo)致在數(shù)組 a 中寫入錯誤的值。假定 CPU SIMD 單元每次可以處理四個浮點數(shù),我們將得到可以用以下偽代碼表示的代碼:
// iteration 1
a[1..4] = c[0..3]; // oops!, a[2..4] get wrong values
c[1..4] = b[1..4];
...
上面代碼不能矢量化,因為循環(huán)內(nèi)部的操作順序很重要。可以通過對調(diào)第 6 行和第 7 行來修正此示例。這不會改變代碼的語義,因此是完全合法的修改。或者,也可以通過將循環(huán)拆分成兩個獨立的循環(huán)來改進(jìn)代碼。這樣做會使循環(huán)開銷增加一倍,但矢量化帶來的性能提升將抵消這一缺點。
void foo(float* __restrict__ a,
float* __restrict__ b,
float* __restrict__ c,
unsigned N) {
for (unsigned i = 1; i < N; i++) {
c[i] = b[i];
a[i] = c[i-1];
}
}
在優(yōu)化報告中,我們現(xiàn)在可以看到該循環(huán)已成功矢量化:
$ clang -O3 -Rpass-analysis=.* -Rpass=.* -Rpass-missed=.* a.c -c
a.cpp:5:3: remark: vectorized loop (vectorization width: 8, interleaved count: 4) [-Rpass=loop-vectorize]
for (unsigned i = 1; i < N; i++) {
^
這只是使用優(yōu)化報告的一個示例;我們將在第 9.4.2 節(jié)中提供更多示例,討論如何發(fā)現(xiàn)矢量化機(jī)會。
編譯器優(yōu)化報告可以幫助您發(fā)現(xiàn)遺漏的優(yōu)化機(jī)會,并了解遺漏的原因。此外,編譯器優(yōu)化報告還有助于測試假設(shè)。編譯器通常會根據(jù)成本模型分析來決定某種轉(zhuǎn)換是否有益。但編譯器并不總能做出最優(yōu)選擇。一旦在報告中發(fā)現(xiàn)關(guān)鍵的優(yōu)化缺失,就可以嘗試通過修改源代碼或以 #pragma、屬性、編譯器內(nèi)置等形式向編譯器提供提示來加以糾正。與往常一樣,請在實際環(huán)境中測量驗證您的假設(shè)。
編譯器報告可能相當(dāng)龐大,每個源代碼文件都會生成單獨的報告。有時,在輸出文件中找到相關(guān)記錄可能成為一項挑戰(zhàn)。我們應(yīng)該提到,最初這些報告的設(shè)計明確供編譯器編寫者用于改進(jìn)優(yōu)化過程。多年來,已經(jīng)出現(xiàn)了一些工具,使它們更易于應(yīng)用程序開發(fā)人員訪問和操作。最值得注意的是 opt-viewer 和 optview2。此外,Compiler Explorer 網(wǎng)站還為基于 LLVM 的編譯器提供了“優(yōu)化輸出”工具,當(dāng)您將鼠標(biāo)懸停在源代碼相應(yīng)行上時,它會報告執(zhí)行的轉(zhuǎn)換。所有這些工具都幫助可視化基于 LLVM 的編譯器成功的和失敗的代碼轉(zhuǎn)換。
在鏈接時優(yōu)化 (LTO)模式中,某些優(yōu)化是在鏈接階段進(jìn)行的。要同時從編譯和鏈接階段生成編譯器報告,應(yīng)向編譯器和鏈接器傳遞專用選項。更多信息,請參見 LLVM “備注 ”指南。
英特爾? ISPC 編譯器采用了略有不同的方式來報告缺失的優(yōu)化。它會對編譯成相對低效代碼的代碼結(jié)構(gòu)發(fā)出警告。無論如何,編譯器優(yōu)化報告都應(yīng)該是您工具箱中的重要工具之一。它們可以快速檢查針對特定熱點進(jìn)行了哪些優(yōu)化,并查看一些重要的優(yōu)化是否失敗。通過編譯器優(yōu)化報告,我發(fā)現(xiàn)了很多改進(jìn)的機(jī)會。
5.8 本章小結(jié)
- 延遲和吞吐量通常是衡量程序性能的最終指標(biāo)。在尋求改進(jìn)方法時,我們需要獲得更多有關(guān)應(yīng)用程序執(zhí)行方式的詳細(xì)信息。硬件和軟件都能提供用于性能監(jiān)控的數(shù)據(jù)。
- 代碼工具能讓我們跟蹤程序中的許多事情,但在開發(fā)和運行時都會造成相對較大的開銷。雖然大多數(shù)開發(fā)人員都沒有手動檢測代碼的習(xí)慣,但這種方法仍適用于自動化流程,例如配置文件引導(dǎo)優(yōu)化(PGO)。
- 跟蹤在概念上與儀表化類似,對于探索系統(tǒng)中的異常情況非常有用。跟蹤使我們能夠捕捉到事件的整個序列,每個事件都附有時間戳。
- 性能監(jiān)控計數(shù)器是一種非常重要的底層性能分析工具。它們通常有兩種使用模式: “計數(shù) “或 ”采樣"。計數(shù)模式主要用于計算各種性能指標(biāo)。
- 采樣跳過程序執(zhí)行的大部分時間,只采樣一次,以代表整個時間間隔。盡管如此,采樣通常會產(chǎn)生足夠精確的分布。最著名的采樣應(yīng)用案例是查找程序中的熱點。采樣是最流行的分析方法,因為它不需要重新編譯程序,運行時開銷也很小。
- 一般來說,計數(shù)和采樣的運行時開銷都很低(通常低于 2%)。一旦開始在不同事件之間進(jìn)行多路復(fù)用,計數(shù)就會變得越來越昂貴(5%-15% 的開銷),而采樣則會隨著采樣頻率的增加而變得越來越昂貴[Nowak & Bitzes,2014]。
- 屋頂線性能模型是一種面向吞吐量的性能模型,在高性能計算(HPC)領(lǐng)域得到廣泛應(yīng)用。它根據(jù)硬件限制可視化應(yīng)用程序的性能。屋頂線模型有助于識別性能瓶頸、指導(dǎo)軟件優(yōu)化并跟蹤優(yōu)化進(jìn)度。
- 有一些工具可以靜態(tài)分析代碼的性能。這類工具模擬一段代碼,而不是執(zhí)行它。這種方法有很多限制和約束,但你會得到一份非常詳細(xì)和低級的報告。
- 編譯器優(yōu)化報告有助于發(fā)現(xiàn)編譯器優(yōu)化的缺失。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號