
現代CPU調優4性能分析中的術語和指標
4 性能分析中的術語和指標
與許多工程學科一樣,性能分析也大量使用特殊的術語和指標。對于初學者來說,查看 Linux perf 或 Intel VTune Profiler 等分析工具生成的配置文件可能會非常困難。這些工具使用了許多復雜的術語和指標,但是,如果你打算從事任何嚴肅的性能工程工作,這些指標都是 “必須知道的”。
既然我提到了 Linux perf,那就讓我簡單介紹一下這個工具,因為我在本章和后面的章節中有很多使用它的例子。Linux perf 是一個性能剖析器,你可以用它來查找程序中的熱點、收集各種低級 CPU 性能事件、分析調用堆棧以及其他許多事情。我將在本書中大量使用 Linux perf,因為它是最流行的性能分析工具之一。我喜歡展示 Linux perf 的另一個原因是它是開源軟件,這使熱心讀者能夠探索現代剖析工具內部的機制。這對學習本書中介紹的概念尤其有用,因為基于圖形用戶界面的工具(如 Intel? VTune? Profiler)往往會隱藏所有的復雜性。我們將在第7章對 Linux perf 進行更詳細的介紹。
本章將簡要介紹性能分析中使用的基本術語和指標。我們將首先定義一些基本術語,如已退休/已執行指令、IPC/CPI、μOPS、內核/參考時鐘、緩存未命中和分支預測錯誤。
然后,我們將了解如何測量系統的內存延遲和帶寬,并介紹一些更高級的指標。最后,我們將對四個行業工作負載進行基準測試,并查看收集到的指標。
4.1 已退休指令與已執行指令
-
已退休指令 (retired instructions):那些已經完成執行并被確認的指令。這些指令是程序真正需要的指令,它們的結果已經被寫入到寄存器或內存中。簡單來說,就是程序邏輯真正執行的指令。
- 是程序邏輯的真實反映。
- 不包括推測執行(speculative execution)中被取消的指令。
- 可以用來計算程序的實際執行時間。
-
已執行指令 (executed instructions): 所有被CPU執行過的指令,包括那些推測執行的指令,即使最終這些指令被取消了。也就是說,CPU嘗試執行過的指令,無論結果是否最終被采用。
- 包括了所有被執行過的指令,無論它們是否最終被確認。
- 可以用來衡量CPU的工作負載。
- 可能比retired instructions數量更多,因為現代CPU通常會進行推測執行。
現代處理器執行的指令通常多于程序流程所需的指令。出現這種情況的原因是某些指令是預測執行的,第 3.3.3 節對此進行了討論。對于大多數指令,CPU 會在結果可用時立即提交,而之前的所有指令都已退休。但對于推測執行的指令,CPU 會保留其結果,而不會立即提交結果。當推測結果正確時,CPU 會解鎖這些指令,并照常執行。但如果推測結果是錯誤的,CPU 就會丟棄推測指令所做的所有更改,而不會將其報廢。因此,CPU 處理的指令可以被執行,但不一定會退休。考慮到這一點,我們通常可以預期執行指令的數量會高于退役指令的數量。
但也有例外。某些指令被視為慣用指令,無需實際執行即可解決。例如第 3.8.2 節中討論的 NOP、移動消除和清零。這類指令不需要執行單元,但仍會被退休。因此,從理論上講,可能會出現退役指令數多于執行指令數的情況。
在大多數現代處理器中,都有一個性能監控計數器(PMC:performance monitoring counter)來收集退休指令的數量。目前還沒有收集已執行指令的性能事件,不過有一種方法可以收集已執行和已報廢的 μops 指令,我們很快就會看到。通過運行 Linux perf,可以輕松獲得退休指令的數量:
$ perf stat -e instructions -- ls
code my.script openpbs-23.06.06 slurm-8.out snap v23.06.06
Performance counter stats for 'ls':
1,991,109 instructions
0.002156994 seconds time elapsed
0.000000000 seconds user
0.002250000 seconds sys
4.2 CPU 利用率
CPU 利用率是指一段時間內核忙的時間百分比。從技術上講,當 CPU 沒有運行內核idle線程時,它就被認為已被利用:CPU Utilization=CPU_CLK_UNHALTED.REF_TSC/TSC。
其中 CPU_CLK_UNHALTED.REF_TSC 計算內核未處于停止狀態時的參考周期數。TSC 代表時間戳計數器(將在第 2.5 節中討論),它總是滴答作響。
如果 CPU 利用率較低,通常意味著應用程序性能較差,因為 CPU 浪費了部分時間。不過,CPU 利用率高并不總是性能好的表現。它只是表明系統正在做一些工作,但并沒有說明它在做什么:CPU 的利用率可能很高,即使它停滯在等待內存訪問。在多線程環境下,線程也可能在等待資源的同時繼續運行。稍后,我們將在第 13.1 節討論并行效率指標,尤其是過濾旋轉時間的 “CPU 有效利用率”。
Linux perf 會自動計算系統中所有 CPU 的 CPU 利用率:
# perf stat -- ls
code my.script openpbs-23.06.06 slurm-8.out snap v23.06.06
Performance counter stats for 'ls':
0.82 msec task-clock # 0.622 CPUs utilized
0 context-switches # 0.000 /sec
0 cpu-migrations # 0.000 /sec
93 page-faults # 113.459 K/sec
1,762,015 cycles # 2.150 GHz
2,005,311 instructions # 1.14 insn per cycle
371,410 branches # 453.116 M/sec
11,882 branch-misses # 3.20% of all branches
TopdownL1 # 24.4 % tma_backend_bound
# 11.8 % tma_bad_speculation
# 38.7 % tma_frontend_bound
# 25.1 % tma_retiring
0.001318194 seconds time elapsed
0.000000000 seconds user
0.001422000 seconds sys
4.3 CPI 和 IPC
這是兩個基本指標,分別代表
-
每周期指令數 (IPC Instructions Per Cycle):平均每個周期有多少指令退休:IPC = INST_RETIRED.ANY / CPU_CLK_UNHALTED.THREAD,其中 INST_RETIRED.ANY 計算退休指令數,CPU_CLK_UNHALTED.THREAD 計算線程未處于停止狀態時的內核周期數。即:IPC = 總退休指令數 / 總時鐘周期數
- 計算公式: IPC = 總指令數 / 總時鐘周期數
- IPC越高,表示CPU的并行處理能力越強。
- IPC是CPI的倒數,即 IPC = 1 / CPI。
- 理論上,理想的IPC值為1,表示每個時鐘周期都可以執行一條指令。但實際上,由于各種因素的限制,IPC值通常小于1。
-
每指令周期(CPI Cycles Per Instruction):CPI表示CPU執行一條指令所需的平均時鐘周期數。簡單來說,就是執行一條指令需要“多少個節拍”。
- 計算公式: CPI = 總時鐘周期數 / 總退休指令數。
- CPI越低,表示CPU執行指令的效率越高。
- 不同的指令有不同的CPI,例如,簡單的算術運算指令可能只需要一個時鐘周期,而復雜的浮點運算指令可能需要多個時鐘周期。
- CPI受到多種因素的影響,包括CPU微架構、指令類型、程序特性等。
我更傾向于使用 IPC,因為它更易于比較。使用 IPC 時,我們希望每個周期盡可能多地執行指令,因此 IPC 越高越好。而 CPI 則恰恰相反:我們希望每條指令的周期越少越好,因此 CPI 越低越好。使用 “越高越好 ”的指標進行比較更簡單,因為你不必每次都進行思維倒置。
IPC 與 CPU 時鐘頻率之間的關系非常有趣。從廣義上講,性能 = 工作/時間,其中我們可以用指令數來表示工作,用秒來表示時間。程序運行的秒數可以用總周期/頻率來計算:
性能 = 指令數 × 頻率 / 周期 = IPC × 頻率 我們可以看到,性能與 IPC 和頻率成正比。如果我們提高這兩個指標中的任何一個,程序的性能就會提高。
從基準測試的角度來看,IPC 和頻率是兩個獨立的指標。
我看到一些工程師錯誤地將它們混為一談,認為如果提高頻率,IPC 也會隨之提高。但事實并非如此。如果將處理器的頻率從 5 GHz 提高到 1 GHz,在許多應用中仍能獲得相同的 IPC。
不過,頻率只能告訴我們單個時鐘周期的速度,而 IPC 則計算每個周期做了多少工作。因此,從基準測試的角度來看,IPC 完全取決于處理器的設計,與頻率無關。非順序內核的 IPC 通常比順序內核高得多。當你增加 CPU 高速緩存的大小或改進分支預測時,IPC 通常會上升。
現在,如果你去問硬件架構師,他們肯定會告訴你 IPC 與頻率之間存在依賴關系。從 CPU 設計的角度來看,你可以故意降低處理器的頻率,這樣會延長每個周期的時間,并有可能在每個周期中擠出更多的工作。最終,你將獲得更高的 IPC,但頻率卻更低。硬件供應商以不同的方式處理這一性能等式。例如,英特爾和 AMD 芯片的頻率通常很高,最近推出的英特爾 13900KS 處理器開箱即可提供 6 GHz 的渦輪頻率,無需超頻。另一方面,蘋果 M1/M2 芯片的頻率較低,但 IPC 卻較高。較低的頻率有利于降低功耗。另一方面,更高的 IPC 通常需要更復雜的設計、更多的晶體管和更大的芯片尺寸。在此,我們將不再贅述所有的設計權衡,因為這些是另一本書的主題。
IPC 對于評估硬件和軟件效率都很有用。硬件工程師使用這一指標來比較不同廠商的 CPU 代次和 CPU。當降低 CPU 頻率時,內存速度相對于 CPU 會更快。這可能會掩蓋實際的內存瓶頸,人為地提高 IPC。
IPC 是衡量 CPU 微體系結構性能的標準,工程師和媒體用它來表示相對于上一代產品的性能提升。不過,要進行公平的比較,需要兩個系統以相同的頻率運行。
IPC 也是評估軟件的有用指標。它能讓你直觀地了解應用程序中的指令在 CPU 管線中的運行速度。在本章后面,您將看到幾個具有不同 IPC 的生產應用程序。內存密集型應用程序的 IPC 通常較低(0-1),而計算密集型工作負載的 IPC 通常較高(4-6)。
Linux perf 用戶可以通過運行以下命令來測量其工作負載的 IPC:
# perf stat -e cycles,instructions -- ls
code my.script openpbs-23.06.06 slurm-8.out snap v23.06.06
Performance counter stats for 'ls':
1,895,107 cycles
1,980,477 instructions # 1.05 insn per cycle
0.000726477 seconds time elapsed
0.000766000 seconds user
0.000000000 seconds sys
# 或 # perf stat -- ls
4.4 微操作(Micro-operations)
x86 架構的微處理器將復雜的 CISC 指令轉化為簡單的 RISC 微操作,簡稱 μop。ADD rax, rbx 這樣的簡單寄存器到寄存器加法指令只產生一個 μop,而 ADD rax, [mem] 這樣的復雜指令則可能產生兩個 μop:一個用于從 mem 內存位置加載到臨時(未命名)寄存器,另一個用于將其添加到 rax 寄存器。指令 ADD [mem], rax 產生三個 μops:一個用于從內存加載,一個用于加法,一個用于將結果存儲回內存。
將指令拆分為微操作的主要優勢在于 μops 可以被執行:
- 亂序執行
考慮 PUSH rbx 指令,該指令將堆棧指針遞減 8 個字節,然后將源操作數存儲到堆棧頂部。假設 PUSH rbx 在解碼后被 “破解 ”為兩個從屬的微操作:
SUB rsp, 8
STORE [rsp], rbx
通常情況下,函數序幕會通過使用多條 PUSH 指令來保存多個寄存器。在我們的例子中,下一條 PUSH 指令可以在上一條 PUSH 指令的 SUB μop 結束后開始執行,而不必等待 STORE μop,因為 STORE μop 現在可以異步執行。
- 并行:考慮 HADDPD xmm1, xmm2 指令,該指令將 xmm1 和 xmm2 中的兩個雙精度浮點數值相加(還原),并將兩個結果存儲到 xmm1 中,如下所示:
xmm1[63:0] = xmm2[127:64] + xmm2[63:0]
xmm1[127:64] = xmm1[127:64] + xmm1[63:0]
對這條指令進行微編碼的一種方法如下: 1) 縮減 xmm2 并將結果存儲到 xmm_tmp1[63:0],2) 縮減 xmm1 并將結果存儲到 xmm_tmp2[63:0],3) 將 xmm_tmp1 和 xmm_tmp2 合并到 xmm1。總共執行三個 μOP。注意步驟 1) 和 2) 是獨立的,因此可以并行執行。
盡管我們剛才討論的是如何將指令拆分成更小的部分,但有時也可以將 μops 融合在一起。現代 x86 CPU 有兩種融合方式:
-
微融合:將來自同一機器指令的 μops 融合在一起。微融合只適用于兩種組合:內存寫入操作和讀取修改操作。例如:add eax, [mem]
這條指令中有兩個 μops 1) 讀取內存位置 mem,和 2)將其添加到 eax 中。通過微融合,兩個 μops 在解碼步驟中融合為一個。 -
宏融合
融合來自不同機器指令的 μ操作。在某些情況下,解碼器可以將算術或邏輯指令與隨后的條件跳轉指令融合為一個單一的計算和分支 μop 。例如
.loop:
dec rdi
jnz .loop
通過宏融合,DEC 和 JNZ 指令中的兩個 μop 融合為一個。Zen4 微體系結構還增加了對 DIV/IDIV 和 NOP 宏融合的支持[Advanced Micro Devices,2023,第 2.9.4 和 2.9.5 節](https://www.amd.com/content/dam/amd/en/documents/epyc-technical-docs/software-optimization-guides/57647.zip)。
微融合和宏融合在從解碼到退出的流水線各個階段都能節省帶寬。融合操作共享重排緩沖區(ROB)中的一個條目。當融合 μop 只使用一個條目時,ROB 的容量能得到更好的利用。這種融合的 ROB 條目隨后會被分派到兩個不同的執行端口,但會作為一個單元再次退役。讀者可以在Fog, 2023a中了解有關 μop 融合的更多信息。
要收集一個應用程序的已發布、已執行和已退役 μop 的數量,可以使用 Linux perf,如下所示:
# perf stat -e uops_issued.any,uops_executed.thread,uops_retired.slots -- ls
code my.script openpbs-23.06.06 slurm-8.out snap v23.06.06
Performance counter stats for 'ls':
2,948,879 uops_issued.any
2,667,937 uops_executed.thread
2,218,621 uops_retired.slots
0.000702776 seconds time elapsed
0.000000000 seconds user
0.000840000 seconds sys
各代 CPU 將指令拆分為微操作的方式可能有所不同。通常,一條指令使用的 μops 數量越少,說明硬件對該指令的支持越好,延時越短,吞吐量越高。對于最新的英特爾和 AMD CPU,絕大多數指令只產生一個 μop。有關最新微體系結構 x86 指令的延遲、吞吐量、端口使用和 μop 數量,請訪問 uops.info62 網站。
4.5 Pipeline Slot(流水線槽)
一些性能工具使用的另一個重要指標是管道槽的概念。流水線槽表示處理一個 μop 所需的硬件資源。
下圖展示了 CPU 的執行流水線,每個周期有 4 個分配槽。這意味著內核每個周期可以為 4 個新的 μOP 分配執行資源(重命名為源和目標寄存器、執行端口、ROB 條目等)。
這樣的處理器通常稱為 4 寬機器。在圖中的連續 6 個周期中,只有一半的可用插槽被使用(用黃色標出)。從微體系結構的角度來看,執行這種代碼的效率只有 50%。

英特爾的 Skylake 和 AMD Zen3 內核采用 4 寬分配。英特爾的 Sunny Cove 微架構是 5 寬設計。截至 2023 年底,最新的 Golden Cove 和 Zen4 架構均采用 6 寬分配。蘋果 M1 和 M2 設計為 8 寬,蘋果 M3 為 9-μop 執行帶寬,見[蘋果,2024 年,表 4.10](https://developer.apple.com/documentation/apple-silicon/cpu-optimization-guide)。
機器的寬度為 IPC 設置了上限。例如,當你的計算顯示 Golden Cove 內核的 IPC 超過 6 時,你就應該懷疑了。
只有極少數應用能達到機器的最大 IPC。例如,英特爾 Golden Cove 內核理論上每個時鐘可執行 4 個整數加法/減法,外加 1 個加載,外加 1 個存儲(共 6 個指令),但應用程序不太可能擁有相鄰獨立指令的適當組合,以利用所有潛在并行性。
流水線槽利用率是自頂向下微體系結構分析的核心指標之一(參見第 6.1 節)。例如,“前端約束 ”和 “后端約束 ”指標用各種瓶頸導致的未利用流水線槽的百分比表示。
4.6 內核周期與參考周期
大多數 CPU 采用時鐘信號來控制其順序操作的節奏。時鐘信號由外部發生器產生,每秒提供一致的脈沖數。時鐘脈沖的頻率決定了 CPU 執行指令的速度。因此,時鐘越快,CPU 每秒執行的指令就越多。
大多數現代 CPU(包括英特爾和 AMD CPU)都沒有固定的工作頻率。相反,它們實現了動態頻率縮放。例如,宏融合比較和分支指令只需要一個流水線插槽,但被算作兩條指令。在某些極端情況下,這可能導致 IPC 大于機器寬度。在 Intel CPU 中稱為 Turbo Boost,在 AMD 處理器中稱為 Turbo Core。它能使 CPU 動態地提高或降低頻率。降低頻率可降低功耗,但會犧牲性能;提高頻率可提高性能,但會犧牲功耗。
內核時鐘周期計數器以 CPU 內核運行的實際頻率計算時鐘周期。參考時鐘事件則是以處理器運行的基準頻率來計算時鐘周期。讓我們看看在運行單線程應用程序的 Skylake i7-6000 處理器上進行的實驗,該處理器的基本頻率為 3.4 GHz:
$ perf stat -e cycles,ref-cycles ./a.exe
43340884632 cycles # 3.97 GHz
37028245322 ref-cycles # 3.39 GHz
10.899462364 seconds time elapsed
平臺上的外部時鐘頻率為 100 MHz,如果我們用時鐘乘數對其進行縮放,就能得到處理器的基本頻率。Skylake i7-6000 處理器的時鐘乘數等于34:這意味著當 CPU 以基準頻率(即 3.4 GHz)運行時,每一個外部脈沖將執行 34 個內部周期。
周期事件計算 CPU 的實際周期并考慮頻率縮放。利用上述公式,我們可以確認平均工作頻率為 43340884632 個周期/10.899 秒 = 3.97 GHz。在比較一小段代碼兩個版本的性能時,以時鐘周期為單位測量時間比以納秒為單位更好,因為這樣可以避免時鐘頻率上下波動的問題。
4.7 Cache Miss(緩存未命中)
如第 3.6 節所述,特定級別緩存中缺失的任何內存請求都必須由更高級別的緩存或 DRAM 來處理。這意味著此類內存訪問的延遲會大大增加。內存子系統組件的典型延遲如表所示。當內存請求在最后一級高速緩存(LLC)中出現錯誤并一直向下進入主內存時,性能將大受影響64: 基于 x86 平臺的內存子系統的典型延遲。

指令和數據讀取都有可能在高速緩存中失效。根據 “自頂向下微體系結構分析”(參見第 6.1 節),指令緩存(I-cache)未命中被描述為前端失速,而數據緩存(D-cache)未命中被描述為后端失速。指令緩存未命中發生在 CPU 流水線的早期,即指令獲取期間。數據緩存未命中則發生在指令執行階段的更晚些時候。
Linux perf 用戶可以通過運行以下命令來收集 L1 緩存未命中次數:
# perf stat -e mem_load_retired.fb_hit,mem_load_retired.l1_miss,mem_load_retired.l1_hit,mem_inst_retired.all_loads -- ls
code my.script openpbs-23.06.06 slurm-8.out snap test.sh t.out v23.06.06
Performance counter stats for 'ls':
10,707 mem_load_retired.fb_hit
8,884 mem_load_retired.l1_miss
473,776 mem_load_retired.l1_hit
493,197 mem_inst_retired.all_loads
0.000797134 seconds time elapsed
0.000000000 seconds user
0.000910000 seconds sys
以上是 L1 數據高速緩存和填充緩沖區的所有負載明細。負載既可能命中已分配的填充緩沖區(fb_hit),也可能命中 L1 緩存(l1_hit),或者兩者都未命中(l1_miss),因此 all_loads = fb_hit + l1_hit + l1_miss。
我們可以進一步細分 L1 數據未命中情況,并通過運行以下命令分析 L2 緩存行為:
# perf stat -e mem_load_retired.l1_miss,mem_load_retired.l2_hit,mem_load_retired.l2_miss -- ls
code my.script openpbs-23.06.06 slurm-8.out snap test.sh t.out v23.06.06
Performance counter stats for 'ls':
8,911 mem_load_retired.l1_miss
6,862 mem_load_retired.l2_hit
2,067 mem_load_retired.l2_miss
0.000760850 seconds time elapsed
0.000000000 seconds user
0.000825000 seconds sys
從這個例子中,我們可以看到 23% 在 L1 D 緩存中未命中的負載也在 L2 緩存中未命中,因此 L2 命中率為 77%。對 L3 緩存也可以進行類似的細分。
4.8 錯誤預測分支(Mispredicted Branch)
現代 CPU 會嘗試預測條件分支指令的結果(執行或不執行)。例如,當處理器看到如下代碼時:
dec eax
jz .zero
# eax 不為 0
...
zero:
# eax 為 0
在上述示例中,jz 指令是一條條件分支指令。為了提高性能,現代處理器在每次看到分支指令時都會嘗試猜測結果。這就是我們在第 3.3.3 節中討論過的 “預測執行”。例如,處理器會猜測不會執行分支指令,并執行與 eax 不為 0 的情況相對應的代碼。但是,如果猜測錯誤,這就叫做分支錯誤預測,CPU 需要撤銷最近所做的所有推測工作。
錯誤預測分支通常會帶來 10 到 25 個時鐘周期的懲罰。首先,所有根據錯誤預測獲取并執行的指令都需要從流水線中清除。之后,一些緩沖區可能需要清理,以恢復錯誤推測開始時的狀態。
Linux perf 用戶可以通過運行以下命令檢查分支錯誤預測的數量
# perf stat -e branches,branch-misses -- ls
code my.script openpbs-23.06.06 slurm-8.out snap test.sh t.out v23.06.06
Performance counter stats for 'ls':
368,465 branches
11,818 branch-misses # 3.21% of all branches
0.000705814 seconds time elapsed
0.000793000 seconds user
0.000000000 seconds sys
# 或 perf stat -- ls
4.9 性能指標(Performance Metrics)
能夠收集各種性能事件對性能分析非常有幫助。不過,有一個注意事項。比方說,你運行了一個程序,并收集了 MEM_LOAD_RETIRED.L3_MISS 事件,該事件計算 LLC 錯失的次數,結果顯示數值為 10 億。當然,這聽起來好像很多,所以你決定調查一下這些緩存未命中是從哪里來的。錯了!你確定這是一個問題嗎?如果一個程序只進行了 20 億次加載,那么是的,這是一個問題,因為有一半的加載在 LLC 中未命中。相反,如果一個程序有一萬億次加載,那么只有千分之一的加載會導致 L3 緩存缺失。
這就是為什么除了硬件性能事件外,性能工程師還經常使用建立在原始事件基礎上的指標。下表列出了英特爾第 12 代 Golden Cove 架構的指標列表以及說明和公式。該列表并不詳盡,但顯示了最重要的指標。英特爾 CPU 的完整指標列表及其計算公式請參見 TMA_metrics.xlsx。

關于這些指標的幾點說明。首先,ILP 和 MLP 指標并不代表應用程序的理論最大值;相反,它們衡量的是特定機器上應用程序的實際 ILP 和 MLP。在資源無限的理想機器上,這些數字會更高。其次,除了 “DRAM BW 使用量 ”和 “負載缺失實際延遲 ”外,所有指標都是分數;我們可以對每個指標進行相當直觀的推理,以判斷特定指標是高還是低。但是,要理解 “DRAM BW 使用情況 ”和 “負載缺失實際延遲 ”指標,我們需要將它們與上下文聯系起來。對于前者,我們想知道程序是否使內存帶寬達到飽和。對于后者,我們需要知道程序是否達到了內存帶寬飽和;而對于后者,我們需要知道緩存缺失的平均成本,除非我們知道緩存層次結構中每個組件的延遲時間,否則這本身毫無用處。我們將在下一節討論如何找出緩存延遲和峰值內存帶寬。
有些工具可以自動報告性能指標。如果不能,您也可以手動計算這些指標,因為您知道必須收集的公式和相應的性能事件。上表提供了英特爾 Golden Cove 架構的計算公式,但只要基礎性能事件可用,您也可以在其他平臺上建立類似的指標。
4.10 內存延遲和帶寬
在現代環境中,低效內存訪問通常是主要的性能瓶頸。
因此,處理器從內存子系統獲取數據的速度是決定應用性能的關鍵因素。內存性能包括兩個方面:1)CPU 從內存獲取單個字節的速度(延遲);2)每秒可獲取的字節數(帶寬)。兩者在各種情況下都很重要,我們稍后將舉例說明。在本節中,我們將重點測量內存子系統組件的峰值性能。
英特爾內存延遲檢查器(MLC) 是對 x86 平臺有幫助的工具之一,該工具在 Windows 和 Linux 上免費提供。MLC 可以使用不同的訪問模式和負載測量高速緩存和內存的延遲和帶寬。在基于 ARM 的系統上沒有類似的工具,但是用戶可以從資源中下載并構建內存延遲和帶寬基準。
此類項目的例子有 lmbench68、bandwidth和 Stream。
我們將只關注指標的一個子集,即空閑讀取延遲和讀取帶寬。讓我們從讀取延遲開始。空閑是指在我們進行測量時,系統處于空閑狀態。這將為我們提供從內存系統組件中獲取數據所需的最短時間,但當系統被其他 “內存饑渴 ”的應用加載時,訪問延遲會隨著其他 “內存饑渴 ”應用的增加而增加。但當系統被其他 “內存饑渴 ”應用加載時,訪問延遲會增加,因為在不同點上可能會有更多的資源排隊等待。MLC 通過執行依賴加載(也稱為指針追逐)來測量空閑延遲。測量線程會分配一個非常大的緩沖區,并對其進行初始化,使緩沖區內的每個(64 字節)緩存行都包含一個指向緩沖區內另一個非相鄰緩存行的指針。通過適當調整緩沖區的大小,我們可以確保幾乎所有的負載都會到達緩存或主存儲器的某個級別。
我的測試系統是一臺英特爾 Alder Lake 電腦,配備酷睿 i7-1260P 處理器和 16GB DDR4 @ 2400 MT/s 雙通道內存。該處理器具有 4P(性能)超線程和 8E(高效)內核。每個 P 核有 48 KB 的一級數據緩存和 1.25 MB 的二級緩存。每個 E 核有 32 KB 的 L1 數據高速緩存,四個 E 核組成一個集群,可訪問共享的 2 MB L2 高速緩存。系統中的所有內核都有 18 MB L3 高速緩存支持。如果使用 10 MB 的緩沖區,我們幾乎可以肯定,對該緩沖區的重復訪問將在 L2 中失誤,但在 L3 中命中。下面是 mlc 命令的示例:
$ sudo ./mlc --idle_latency -c0 -L -b10m
Intel(R) Memory Latency Checker - v3.10
Command line parameters: --idle_latency -c0 -L -b10m
Using buffer size of 10.000MiB
Each iteration took 31.1 base frequency clocks (12.5 ns)
此外,MLC 還有 --loaded_latency 選項,用于測量其他線程產生內存流量時的延遲。選項 -c0 將測量線程引向 邏輯 CPU 0(P 核)。在我們的測量中,選項 -L 支持超大頁面,以限制 TLB 的影響。選項 -b10m 可讓 MLC 使用 10MB 的緩沖區,適合我們系統的 L3 緩存。
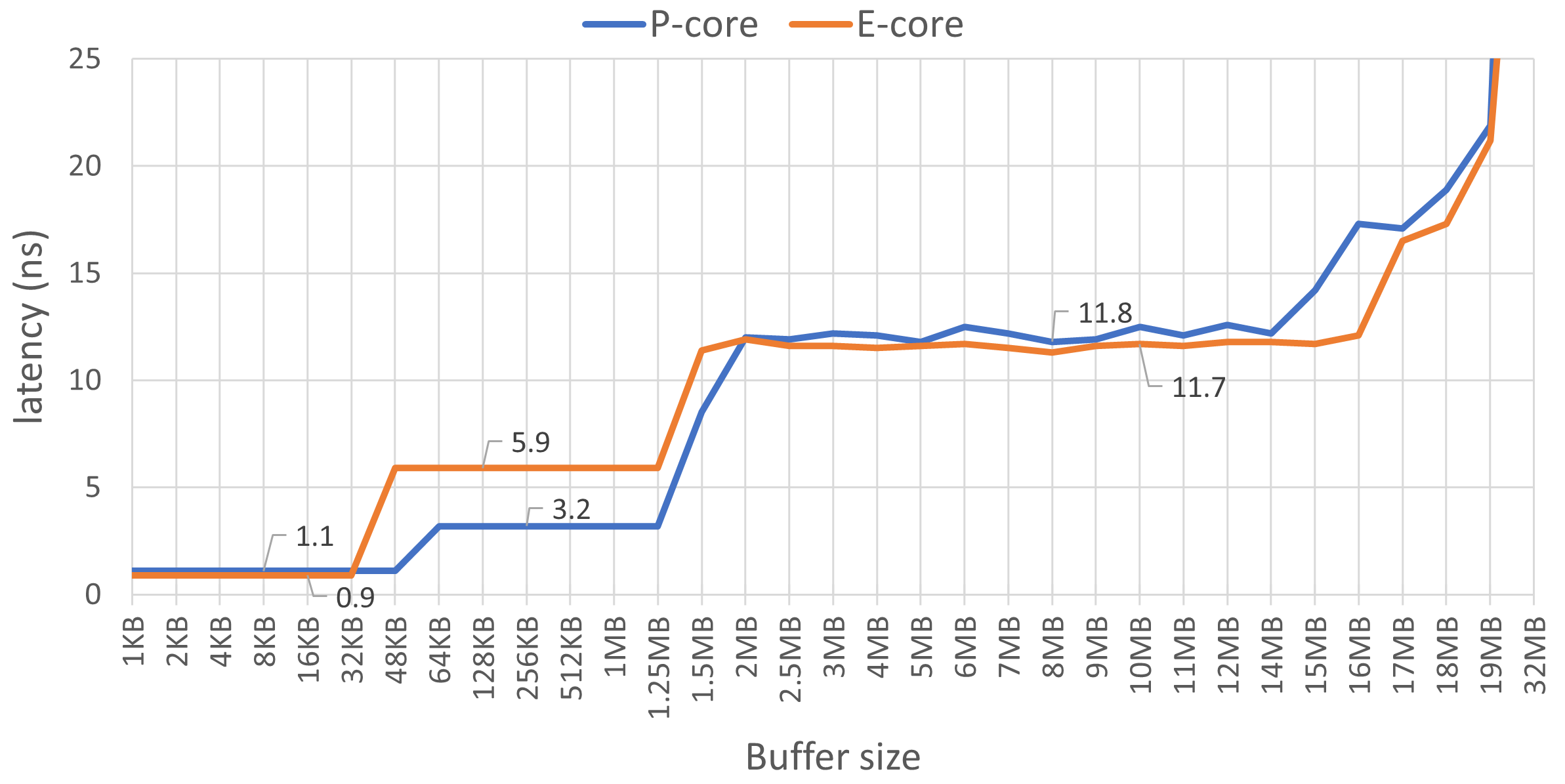
上圖顯示了 L1、L2 和 L3 緩存的讀取延遲,使用 MLC 工具測量,啟用超大頁面。。圖中有四個不同的區域。左側第一個區域從 1 KB 到 48 KB 的緩沖區大小對應于 L1 D 緩存,它是每個物理內核的私有緩存。我們可以看到 E 核的延遲為 0.9 ns,P 核略高,為 1.1 ns。此外,我們還可以使用此圖確認緩存大小。請注意,緩沖區大小超過 32 KB 后,E 核的延遲開始攀升,但 P 核的延遲在 48 KB 之前保持不變。
這證明 E 核的 L1 D 緩存大小為 32 KB,而 P 核為 48 KB。
第二個區域顯示的是二級緩存延遲,E 核的延遲幾乎是 P 核的兩倍(5.9 ns 對 3.2 ns)。對于 P 核,在緩沖區大小超過 1.25 MB 后,延遲會增加,這在意料之中。我們預計 E 核的延遲會保持不變,直到達到 2 MB,但根據我們的測量,這種情況發生得更早。
從 2 MB 到 14 MB 的第三個區域對應的是 L3 高速緩存延遲,兩種內核的延遲時間都大約為 12 ns。
系統中所有內核共享的 L3 高速緩存總大小為 18 MB。有趣的是,我們從 15 MB 開始看到一些意想不到的動態變化,而不是 18 MB。這很可能與某些訪問在 L3 中丟失并需要從主存儲器取回有關。
我沒有顯示圖表中與內存延遲相對應的部分,該部分在我們越過 18MB 邊界后開始出現。延遲開始急劇攀升,E 核為 24 MB,P 核為 64 MB。當緩沖區更大時,例如 500 MB,E 核的訪問延遲為 45ns,P 核為 90ns。由于幾乎沒有負載進入 L3 高速緩存,因此可以測量內存延遲。
利用類似的技術,我們可以測量內存層次結構中各個部分的帶寬。為了測量帶寬,MLC 會執行加載請求,其結果不會被任何后續指令使用。這樣,MLC 就能產生盡可能大的帶寬。MLC 在每個配置的邏輯處理器上生成一個軟件線程。每個線程訪問的地址是獨立的,線程之間不共享數據。與延遲實驗一樣,線程使用的緩沖區大小決定了 MLC 測量的是 L1/L2/L3 緩存帶寬還是內存帶寬。
$ sudo ./mlc --max_bandwidth -k0-15 -Y -L -u -b18m
Measuring Maximum Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 349670.42
這里有幾個新選項。-k選項指定了用于測量的CPU內核列表。Y 選項告訴 MLC 使用 AVX2 負載,即每次 32 字節。選項 使用-u 標志時,每個線程共享同一個緩沖區,不分配自己的緩沖區。必須使用該選項來測量 L3 帶寬(注意我們使用的是 18 MB 緩沖區,相當于 L3 緩存的大小)。

上圖顯示了使用英特爾 MLC 測得的測試系統的綜合延遲和帶寬數據。與共享 L3 高速緩存或主存儲器相比,內核從 L1 和 L2 等低級高速緩存汲取的帶寬要高得多。分析四個基準測試的性能指標 L3 和 E 核 L2 等高速緩存可以很好地同時滿足多個內核的請求。例如,單個 E 核 L2 帶寬為 100GB/s。在使用同一集群的兩個 E 核時,我測出的帶寬為 140GB/s,三個 E 核為 165GB/s,而所有四個 E 核都能從共享二級緩存中獲得 175GB/s 的帶寬。三級緩存也是如此,單個 P 核心的速度為 60 GB/s,而單個 E 核心的速度僅為 25 GB/s。但當所有內核都使用時,L3 高速緩存的帶寬可達 300 GB/s。從內存讀取數據的速度為 33.7 GB/s,而在我的平臺上,理論最大帶寬為 38.4 GB/s。
了解機器的主要特性是評估程序如何充分利用可用資源的基礎。我們將在第 5.5 節討論 Roofline 性能模型時再次討論這一主題。如果您經常在單一平臺上分析性能,那么最好記住內存層次結構各組成部分的延遲和帶寬,或者將它們放在手邊。這有助于建立被測系統的心智模型,從而有助于進一步的性能分析,接下來您將看到這一點。
4.11 案例研究:
分析四個基準的性能指標 為了將本章討論的所有內容結合起來,我們來看一些實際案例。我們運行了來自不同領域的四個基準,并計算了它們的性能指標。首先介紹一下這些基準。
Blender 3.4 - 一個開源的3D創建和建模軟件項目。這個測試是使用Blender的Cycles性能進行的,使用了BMW27混合文件。使用了所有的硬件線程。URL: https://download.blender.org/release。命令行:./blender -b bmw27_cpu.blend -noaudio --enable-autoexec -o output.test -x 1 -F JPEG -f 1。
Stockfish 15 - 一個先進的開源國際象棋引擎。這個測試是一個內置的stockfish基準測試。只使用了一個硬件線程。URL: https://stockfishchess.org。命令行:./stockfish bench 128 1 24 default depth。
Clang 15 自我構建 - 這個測試使用clang 15從源代碼構建clang 15編譯器。使用了所有的硬件線程。URL: https://www.llvm.org。命令行:ninja -j16 clang。
CloverLeaf 2018 - 一個拉格朗日-歐拉流體動力學基準測試。使用了所有的硬件線程。這個測試使用了clover_bm.in輸入文件(問題5)。URL: http://uk-mac.github.io/CloverLeaf。命令行:./clover_leaf。
在本練習中,我在具有以下特性的機器上運行了所有四個基準測試:
- 第 12 代 Alder Lake Intel? Core? i7-1260P CPU,主頻 2.10GHz(4.70GHz Turbo),4P+8E 內核,18MB L3 緩存
- 16 GB 內存,DDR4 @ 2400 MT/s - 256GB NVMe PCIe M.2 SSD
- 64 位 Ubuntu 22.04.1 LTS (Jammy Jellyfish)
- Clang-15 C++ 編譯器,帶以下選項:-O3 -march=core-avx2
為了收集性能指標,我使用了 Andi Kleen 的 pmutools:71 中的 toplev.py 腳本: $ ~/workspace/pmu-tools/toplev.py -m --global --no-desc -v --
表 4.3 對四個基準的性能指標進行了并列比較。通過觀察這些指標,我們可以了解這些工作負載的性質。

以下是我們對基準性能的假設:
-
Blender。工作在 P 核和 E 核之間的分配相當平均,兩種內核類型的 IPC 都不錯。每千條指令的緩存未命中次數相當低(參見 LMPKI)。分支預測錯誤是一個小瓶頸:分支錯誤預測 Misp. 比率為 2%;每 610 條指令中就有 1 條錯誤預測(參見 IpMispredict 指標),結果相當不錯。TLB 并非瓶頸,因為我們在 STLB 中很少出現缺失。我們忽略了負載缺失延遲指標,因為緩存缺失的次數非常少。ILP 相當高。
Golden Cove 是一個 6 寬架構;3.67 的 ILP 意味著該算法每個周期幾乎要使用 2/3 的內核資源。內存帶寬需求較低(僅為 1.58 GB/s),遠未達到這臺機器的理論最大值。
從 Ip 指標可以看出,Blender 是一種浮點運算(參見 IpFLOP 指標),其中很大一部分是矢量化 FP 運算(參見 IpArith AVX128)。但算法的某些部分也是非矢量標量 FP 單精度指令(IpArith Scal SP)。此外,請注意每第 90 條指令都是明確的軟件內存預取(IpSWPF);我們希望在 Blender 的源代碼中看到這些提示。初步結論
Blender 的性能受到 FP 計算的限制。 -
Stockfish 我們只使用一個硬件線程運行它,因此正如預期的那樣,E-cores 上的工作為零。L1 miss 的數量相對較高,但其中大部分都包含在 L2 和 L3 緩存中。分支錯誤預測率很高;我們每 215 條指令就要支付一次錯誤預測懲罰。我們可以估計,每 215(指令)/1.80(IPC)=120 個周期就會發生一次錯誤預測,頻率非常高。與 Blender 的推理類似,我們可以說 TLB 和 DRAM 帶寬對 Stockfish 來說不是問題。更進一步,我們可以看到工作負載中幾乎沒有 FP 操作(參見 IpFLOP 指標)。
初步結論 Stockfish 是一種整數計算工作負載,受分支錯誤預測的影響很大。 -
Clang 15 自構建。編譯 C++ 代碼是性能曲線非常平坦的任務之一,即沒有大的熱點。您將看到運行時間是由許多不同的函數決定的。我們首先發現,P-cores 比 E-cores 多做 68% 的工作,IPC 性能比 E-cores 高 42%。
IPC。但 P 核和 E 核的 IPC 都很低。L*MPKI 指標乍看起來并不令人擔憂,但結合負載未命中實際延遲(LdMissLat,以核心時鐘為單位),我們可以發現緩存未命中的平均成本相當高(約 77 個周期)。現在,當我們查看 *STLB_MPKI 指標時,我們會發現它與我們測試的其他基準有很大的不同。這是由于 Clang 編譯器(以及其他編譯器)的另一個方面造成的:二進制文件的大小相對較大(超過 100 MB)。代碼不斷跳轉到遙遠的地方,給 TLB 子系統造成很大壓力。正如您所看到的,指令(參見 Code stlb MPKI)和數據(參見 Ld stlb MPKI)都存在問題。讓我們繼續分析。DRAM 帶寬使用率高于前兩個基準測試,但仍未達到我們平臺最大內存帶寬(約 34 GB/s)的一半。
我們關注的另一個問題是每次調用(IpCall)的指令數非常少:
每次函數調用只有約 41 條指令。不幸的是,這是編譯器代碼庫的性質決定的:它有成千上萬個小函數。編譯器需要更積極地內聯所有這些函數和封裝器72 。然而,我們懷疑與函數調用相關的性能開銷仍然是 Clang 編譯器的一個問題。此外,我們還可以發現高 ipBranch 和 IpMispredict 指標。在 Clang 編譯中,通過使用鏈接時間優化(LTO),每五條指令中就有 72 個分支,每 35 個分支中就有一個分支。
分支,每 35 個分支中就有一個被錯誤預測。幾乎沒有 FP 或矢量指令,但這并不奇怪。初步結論:
Clang 擁有龐大的代碼庫、扁平的配置文件、許多小函數和 “多分支 ”代碼。
性能受到數據緩存未命中、TLB 未命中和分支預測錯誤的影響。 -
CloverLeaf 和以前一樣,我們首先分析指令和內核周期。P 核和 E 核完成的工作量大致相同,但 P 核需要更多時間來完成這些工作,因此 P 核上一個邏輯線程的 IPC 要低于一個物理 E 核。73 LMPKI 指標很高,尤其是每千條指令的 L3 缺失數。負載未命中延遲 (LdMissLat) 高得離譜,表明平均高速緩存未命中價格極高。接下來,我們看看 DRAM BW 使用指標,發現內存帶寬消耗已接近極限。這就是問題所在:系統中的所有內核共享相同的內存總線,因此它們會競爭訪問主內存,這實際上會導致執行停滯。CPU 所需的數據供應不足。更進一步,我們可以看到 CloverLeaf 不會出現預測錯誤或函數調用開銷過大的問題。指令組合以 FP 雙精度標量運算為主,代碼的某些部分被矢量化。初步結論:多線程 CloverLeaf 受內存帶寬限制。
從這項研究中可以看出,僅通過觀察指標就能了解程序的許多行為。它能回答 “是什么?”的問題,但不能告訴你 “為什么?”。為此,你需要收集性能曲線,我們將在后面的章節中介紹。在本書的第 2 部分,我們將討論如何緩解我們所分析的四個基準中存在的性能問題。
請記住,表中的性能指標摘要只能說明程序的平均行為。例如,我們可能看到 CloverLeaf 的 IPC 為 0.2,但實際上它可能從未以這樣的 IPC 運行。相反,它可能有兩個持續時間相同的階段,其中一個階段的 IPC 為 0.1,第二個階段的 IPC 為 0.3。性能工具通過報告每個指標的統計數據和平均值來解決這個問題。通常,有最小值、最大值、第 95 百分位數和變差(stdev/avg)就足以了解分布情況。此外,有些工具還允許繪制數據圖,這樣就能看到程序運行期間某個指標值的變化情況。例如,圖 4.4 顯示了 CloverLeaf 基準的 IPC、LMPKI、DRAM BW 和平均頻率的動態變化。只要添加 --xlsx 和 --xchart 選項,pmu-tools 軟件包就能自動生成這些圖表。-I 10000 選項以 10 秒為間隔匯總所收集的樣本。
$ ~/workspace/pmu-tools/toplev.py -m --global --no-desc -v --xlsx workload.xlsx -xchart -I 10000 -- ./clover_leaf 盡
管摘要中報告的平均值偏差不大,但我們可以看到工作負載并不穩定。對于 P 核心,我們可以假設工作負載沒有明顯的階段,而變化是由性能事件之間的多路復用引起的(第 5.3 節將討論)。但這只是一個假設,還需要進一步證實或推翻。
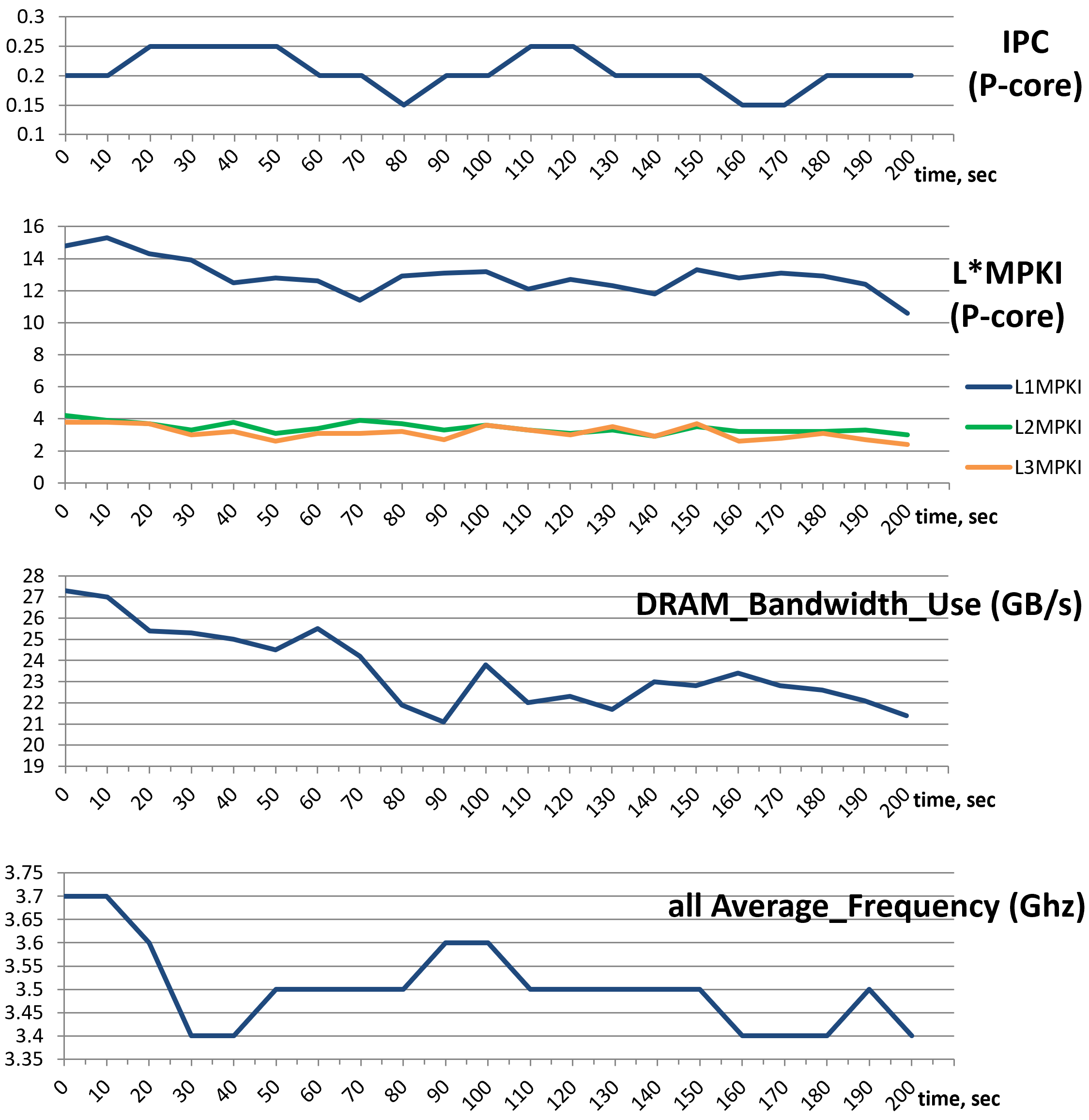
可能的方法是以更高的粒度(在我們的案例中為 10 秒)運行采集,從而收集更多的數據點。繪制 L*MPKI 的圖表顯示,所有三個指標都在平均值附近徘徊,沒有太大偏差。DRAM 帶寬利用率圖表顯示,主內存在不同時期承受著不同的壓力。最后一張圖表顯示了所有 CPU 內核的平均頻率。從圖表中可以看出,在最初的 10 秒鐘后開始出現節流現象。我建議在僅通過觀察總體數據得出結論時要小心謹慎,因為這些數據可能并不能很好地反映工作負載的行為。
請記住,收集性能指標并不能代替對代碼的研究。請始終嘗試通過檢查代碼的相關部分來解釋您所看到的數字。
總之,性能指標可幫助您建立正確的心智模型,了解程序中發生了什么和沒有發生什么。進一步分析時,這些數據將為您提供很好的幫助。
4.12 小結
- 在本章中,我們介紹了性能分析的基本指標,如退役/已執行指令、CPU 利用率、IPC/CPI、μops、流水線slot、內核/參考時鐘、緩存未命中和分支誤預測。我們展示了如何利用 Linux perf 收集這些指標。
- 對于更高級的性能分析,您還可以收集許多衍生指標。例如,每千條指令的緩存未命中率(MPKI)、每個函數調用、分支、加載等的指令數(Ip*)、ILP、MLP 等。本章的案例研究展示了如何通過分析這些指標獲得可行的見解。
- 通過觀察總體數字得出結論要謹慎。不要陷入 “Excel 性能工程 ”的陷阱,即只收集性能指標,而從不查看代碼。一定要尋找第二個數據源(如性能配置文件,稍后討論)來驗證您的想法。
- 內存帶寬和延遲是當今許多生產軟件包(包括人工智能、高性能計算、數據庫和許多通用應用程序)性能的關鍵因素。內存帶寬取決于 DRAM 速度(MT/s)和內存通道數量。現代高端服務器平臺有 8-12 個內存通道,整個系統的帶寬最高可達 500 GB/s,單線程模式下最高可達 50 GB/s。現在的內存延遲變化不大,事實上,隨著新一代 DDR4 和 DDR5 的推出,延遲會略有惡化。大多數面向客戶端的現代系統每次內存訪問的延遲時間在 70-110 ns 之間。服務器平臺的內存延遲可能更高。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號