
現代CPU調優(yōu)3: CPU 微架構
3 CPU 微架構
本章簡要概述了對軟件性能有直接影響的關鍵 CPU 微體系結構特性。本章的目的并不是要涵蓋 CPU 架構的所有細節(jié)和權衡,文獻[Hennessy & Patterson, 2017 Computer Architecture, Sixth Edition]、[Shen & Lipasti, 2013 Modern Processor Design: Fundamentals of Superscalar Processors]已經對此進行了大量論述。我將對現代處理器的特性進行回顧,以便讀者為本書接下來的內容做好準備。
3.1 指令集架構
指令集架構(ISA instruction set architecture)是軟件與硬件之間的契約,它定義了通信規(guī)則。英特爾 x86-64、Armv8-A 和 RISC-V 是當今廣泛使用的 ISA 的例子。所有這些都是 64 位架構,即所有地址計算都使用 64 位。ISA 開發(fā)人員和 CPU 架構師通常會確保符合規(guī)范的軟件或固件可以在任何使用該規(guī)范構建的處理器上執(zhí)行。廣泛部署的 ISA 通常還能確保向后兼容性,例如為 GenX 版本處理器編寫的代碼可以繼續(xù)在 GenX+i 上執(zhí)行。
大多數現代體系結構都可歸類為基于寄存器的通用加載存儲體系結構,如 RISC-V 和 ARM,在這些體系結構中,操作數是明確指定的,內存只能通過加載和存儲指令訪問。X86 ISA 是一種寄存器內存架構,可對寄存器和內存操作數進行操作。除了提供 ISA 的基本功能(如加載、存儲、控制以及使用整數和浮點進行標量運算)外,廣泛部署的體系結構還不斷增強其 ISA,以支持新的計算模式。其中包括增強型向量處理指令(如英特爾 AVX2、AVX512、ARM SVE、RISC-V “V ”向量擴展)以及矩陣/張量指令(英特爾 AMX、ARM SME)。廣泛使用這些高級指令的應用程序通常會大幅提高性能。
現代 CPU 支持 32 位和 64 位精度的浮點和整數算術運算。隨著機器學習和人工智能領域的快速發(fā)展,業(yè)界對替代數字格式重新產生了興趣,以推動性能的顯著提高。研究表明,使用更少的比特來表示變量,機器學習模型的性能同樣出色,從而節(jié)省了計算和內存帶寬。因此,除了用于算術運算的傳統 32 位和 64 位格式外,大多數主流 ISA 最近都增加了對較低精度數據類型的支持,如 8 位和 16 位整數和浮點類型(int8、fp8、fp16、bf16)。
3.2 流水線技術
流水線(Pipelining)技術是使 CPU 快速運行的一種基礎技術,在這種技術中,多條指令在執(zhí)行過程中相互重疊。流水線技術在 CPU 中的應用靈感來自汽車裝配線。指令的處理分為若干階段。各階段并行運行,處理不同指令的不同部分。DLX 是一種相對簡單的架構,由 John L. Hennessy 和 David A. Patterson 于 1994 年設計。根據[Hennessy & Patterson, 2017 Computer Architecture, Sixth Edition]中的定義,它有一個 5 級流水線,由以下部分組成:
-
- 指令取回 (IF Instruction fetch)
-
- 指令解碼 (ID Instruction decode )
-
- 執(zhí)行 (EXE Execute)
-
- 內存訪問 (MEM Memory access)
-
- 回寫 (WB Write back)
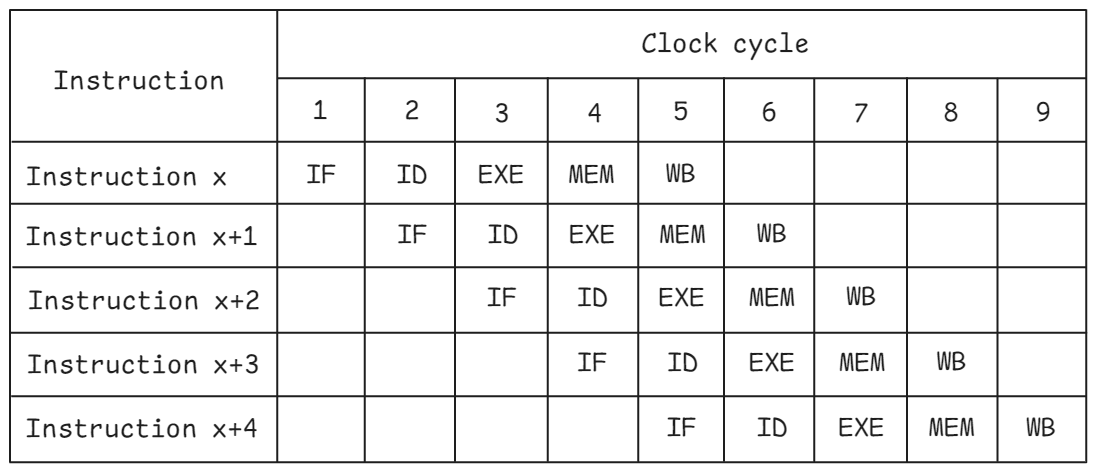
上圖顯示了 5 級流水線 CPU 的理想流水線視圖。在周期 1 中,指令 x 進入流水線的 IF 階段。在下一個周期,當指令 x 進入 ID 階段時,程序中的下一條指令進入 IF 階段,依此類推。一旦流水線滿了,如上述第 5 周期,CPU 的所有流水線階段都忙于處理不同的指令。如果沒有流水線,指令 x+1 在指令 x 完成工作后才能開始執(zhí)行。
現代高性能 CPU 有多個流水線級,通常為 10 到 20 級(有時更多),具體取決于體系結構和設計目標。這涉及到比前面介紹的簡單 5 級流水線復雜得多的設計。例如,解碼階段可能會被分成幾個新的階段。我們還可以在執(zhí)行級之前增加新的級來緩沖已解碼的指令等。
流水線 CPU 的吞吐量定義為單位時間內完成和退出流水線的指令數。任何給定指令的延遲都是通過流水線所有階段的總時間。由于流水線的所有階段都是連接在一起的,因此每個階段都必須準備就緒,以步調一致的方式進入下一條指令。將一條指令從一個階段移動到下一個階段所需的時間定義了 CPU 的基本機器周期或時鐘。為特定流水線選擇的時鐘值由流水線中最慢的階段決定。中央處理器硬件設計人員努力平衡每級可完成的工作量,因為這直接影響到中央處理器的運行頻率。
在實際應用中,流水線引入了一些限制因素,這些因素限制了流暢執(zhí)行。流水線危害會阻礙理想的流水線行為,導致停滯。危害分為結構危害、數據危害和控制危害三類。對程序員來說幸運的是,在現代 CPU 中,所有類型的危害都由硬件處理。
- 結構性冒險(資源沖突: Structural hazards)
由資源沖突引起,即有兩條指令競爭同一資源。例如,兩條 32 位加法指令準備在同一周期內執(zhí)行,但該周期內只有一個執(zhí)行單元可用。在這種情況下,我們需要選擇執(zhí)行兩條指令中的哪一條,以及哪一條將在下一周期執(zhí)行。在很大程度上,可以通過復制硬件資源來消除這些問題,例如使用多個執(zhí)行單元、指令解碼器、多端口寄存器文件等。不過,這可能會在硅片面積和功耗方面造成相當大的代價。
- 數據冒險(Data Hazards)
由程序中的數據依賴性引起,分為三種類型:
寫入后讀取(RAW read-after-write)危險要求在寫入后執(zhí)行依賴性讀取。當指令 x+1 在前一條指令 x 向源寫入之前讀取源時,就會發(fā)生這種情況,導致讀取錯誤的值。中央處理器會將數據從流水線的較后階段轉發(fā)到較早階段(稱為 “旁路”),以減輕與 RAW 危險相關的懲罰。其原理是,在指令 x 完全完成之前,指令 x 的結果可以轉發(fā)到指令 x+1。請看下面的例子
R1 = R0 ADD 1
R2 = R1 ADD 2
寄存器 R1 存在 RAW 依賴關系。如果我們在加法 R0 ADD 1 完成后(從 EXE 流水線階段)直接取值,就無需等到 WB 階段結束(此時該值將寫入寄存器文件)。旁路有助于節(jié)省幾個周期。流水線越長,旁路就越有效。
讀后寫(WAR write-after-read)危險要求在讀取后執(zhí)行從屬寫操作。當一條指令在先前指令讀取寄存器之前寫入寄存器,導致讀取錯誤的新值時,就會發(fā)生這種情況。WAR 危險不是真正的依賴關系,可以通過一種稱為寄存器重命名的技術來消除。這是一種從物理寄存器中抽象出邏輯寄存器的技術。CPU 通過保留大量物理寄存器來支持寄存器重命名。邏輯(架構)寄存器,即 ISA 定義的寄存器,只是更廣泛寄存器文件的別名。有了這種架構狀態(tài)的解耦,解決 WAR 危險就很簡單了:我們只需在寫操作中使用不同的物理寄存器即可。例如

在原始匯編代碼中,寄存器 R0 存在 WAR 依賴關系。對于左邊的代碼,我們不能重新安排指令的執(zhí)行順序,因為這可能會在 R1 中留下錯誤的值。不過,我們可以利用龐大的物理寄存器池來克服這一限制。為此,我們需要重命名從寫操作(R0 = R2 ADD 2)開始的所有 R0 寄存器,并使用空閑寄存器。重命名后,我們給這些寄存器賦予與物理寄存器相對應的新名稱,例如 R103。通過重新命名寄存器,我們消除了初始代碼中的 WAR 危險,可以安全地以任何順序執(zhí)行這兩個操作。
寫入后寫入(WAW write-after-write)危險要求在寫入后執(zhí)行從屬寫入。當一條指令寫入一個寄存器后,另一條指令才寫入同一寄存器,從而導致錯誤的值被存儲。
寄存器重命名也能消除 WAW 危險,允許兩個寫入以任何順序執(zhí)行,同時保留正確的最終結果。下面是消除 WAW 危險的示例。

你會在許多生產程序中看到類似的代碼。在我們的示例中,R1 保留 ADD 操作的臨時結果。SUB 指令完成后,R1 立即重新用于存儲 MUL 運算的結果。左側的原始代碼包含所有三種類型的數據危險。在 ADD 和 SUB 之間,R1 存在 RAW 依賴關系,并且必須在寄存器重命名后繼續(xù)使用。此外,在 MUL 操作中,同一個 R1 寄存器還存在 WAW 和 WAR 危險。同樣,我們需要對寄存器進行重命名,以消除這兩個危險。請注意,寄存器重命名后,MUL 操作有了一個新的目標寄存器(R104)。現在,我們可以安全地將 MUL 與其他兩個操作重新排序。
- 控制冒險(Control Hazards)
由程序流程的變化引起。它們產生于流水線分支和其他改變程序流程的指令。
決定分支方向(執(zhí)行與不執(zhí)行)的分支條件是在執(zhí)行流水線階段解決的。因此,除非控制危險被消除,否則下一條指令的取值無法流水線化。下一節(jié)介紹的動態(tài)分支預測和推測執(zhí)行等技術可用于緩解控制冒險。
3.3 利用指令級并行性 (ILP Instruction Level Parallelism)
程序中的大多數指令都是獨立的,因此適合流水線化并行執(zhí)行。現代 CPU 采用了大量附加硬件功能來利用這種指令級并行性 (ILP),即單條指令流內的并行性。這些硬件特性與先進的編譯器技術相結合,可顯著提高性能。
3.3.1 亂序執(zhí)行(OOO Out-Of-Order)
大多數現代 CPU 都支持無序執(zhí)行 (OOO),在這種情況下,順序指令可以按照任意順序進入執(zhí)行階段,只是受到其依賴關系和資源可用性的限制。具有 OOO 執(zhí)行功能的 CPU 仍必須提供與所有指令按程序順序執(zhí)行時相同的結果。
一條指令在最終執(zhí)行后被稱為 “退役”,其結果是正確的,并在架構狀態(tài)中可見。為確保正確性,CPU 必須按程序順序執(zhí)行所有指令。OOO 執(zhí)行主要用于避免 CPU 資源因依賴關系導致的停滯而未得到充分利用,尤其是在超標量引擎中,我們稍后將討論這一點。
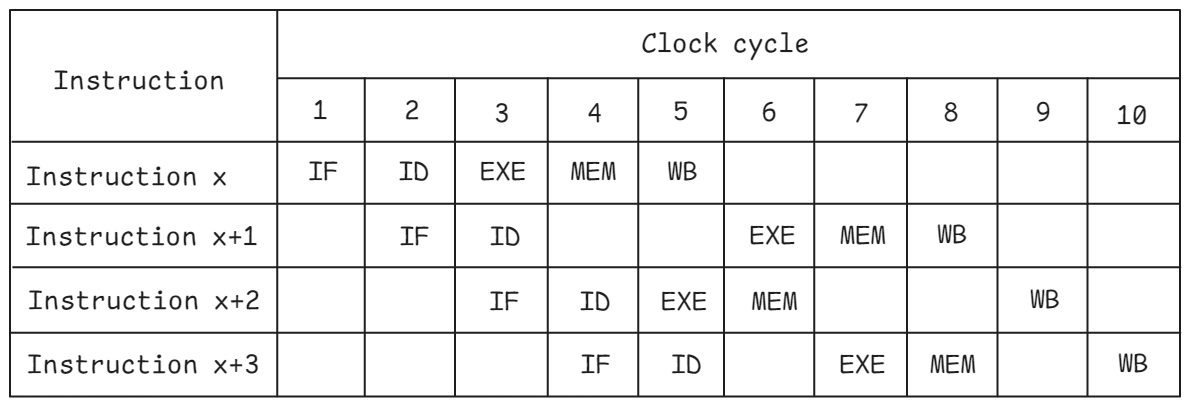
假設由于某些沖突,指令 x+1 無法在周期 4 和 5 中執(zhí)行。按順序執(zhí)行的 CPU 會阻止所有后續(xù)指令進入 EXE 流水線階段,因此指令 x+2 只能在周期 7 開始執(zhí)行。在采用 OOO 執(zhí)行方式的 CPU 中,只要不存在任何沖突(例如,指令的輸入可用,執(zhí)行單元未被占用等),指令就可以開始執(zhí)行。如圖所示,指令 x+2 在指令 x+1 之前開始執(zhí)行。指令 x+3 無法在第 6 周期進入 EXE 階段,因為它已被指令 x+1 占用。所有指令仍按順序退出,即指令按程序順序完成 WB 階段。
與按順序執(zhí)行相比,OOO 執(zhí)行通常能大幅提高性能。不過,它也會帶來額外的復雜性和功耗。
對指令重新排序的過程通常稱為指令調度。調度的目的是以最小化流水線危險和最大化 CPU 資源利用率的方式發(fā)出指令。指令調度可以在編譯時進行(靜態(tài)調度),也可以在運行時進行(動態(tài)調度)。讓我們來解讀這兩種方案。
3.3.1.1 靜態(tài)調度(Static scheduling)
Intel Itanium 就是靜態(tài)調度的一個例子。在超標量、多執(zhí)行單元機器的靜態(tài)調度中調度, 使用一種稱為 VLIW(超長指令字)的技術,將調度從硬件轉移到編譯器。其基本原理是通過要求編譯器選擇正確的指令組合來簡化硬件,從而保持機器的充分利用。
編譯器可以使用軟件流水線和循環(huán)解卷等技術,在硬件結構無法合理支持的情況下,更進一步尋找合適的 ILP。
英特爾 Itanium 一直未能取得成功,原因有幾個。其中一個原因是與 x86 代碼缺乏兼容性。另一個原因是,由于負載延遲可變,編譯器很難對指令進行調度,使 CPU 保持繁忙。x86 ISA 的 64 位擴展 (x86-64)由 AMD 在同一時間窗口推出,與 IA-32(x86 ISA 的 32 位版本)兼容,并最終成為其真正的繼承者。Itanium 處理器最終于 2021 年停產。
3.3.1.2 動態(tài)調度
為了克服靜態(tài)調度的問題,現代處理器采用了動態(tài)調度。動態(tài)調度最重要的兩種算法是Scoreboarding 計分板和Tomasulo 托馬蘇洛算法。它的主要缺點是不僅保留了真實依賴關系(RAW),還保留了虛假依賴關系(WAW 和 WAR),因此它提供了次優(yōu)的 ILP。虛假依賴性是由于架構寄存器數量較少造成的,現代 ISA 中的架構寄存器數量通常在 16 到 32 個之間。這就是所有現代處理器都采用 Tomasulo 算法進行動態(tài)調度的原因。Tomasulo 算法由 Robert Tomasulo 于 20 世紀 60 年代發(fā)明,并首次在 IBM360 91 型處理器中實現。
為了消除錯誤的依賴關系,Tomasulo 算法使用了寄存器重命名技術,我們在上一節(jié)已經討論過這一技術。因此,與計分板相比,性能大大提高。然而,帶有 RAW 依賴性的指令序列(也稱為依賴鏈)對于 OOO 執(zhí)行仍然存在問題,因為在寄存器重命名后,ILP 不會增加,因為所有 RAW 依賴性都得到了保留。依賴鏈通常出現在循環(huán)中(循環(huán)攜帶依賴),在這種情況下,當前循環(huán)迭代依賴于上一次迭代產生的結果。
實現動態(tài)調度的另外兩個關鍵組件是重排序緩沖區(qū)(ROB Reorder Buffer)和預約站(RS Reservation Station)。重排緩沖區(qū)是一個循環(huán)緩沖區(qū),用于跟蹤每條指令的狀態(tài),在現代處理器中,重排緩沖區(qū)有幾百個條目。通常情況下,ROB 的大小決定了硬件可以提前多久獨立調度指令。指令按程序順序插入 ROB,可以不按順序執(zhí)行,也可以按程序順序退出。在將指令放入 ROB 時,會對寄存器進行重命名。
指令從 ROB 插入 RS,RS 中的條目要少得多。指令一旦進入 RS,就會等待其輸入操作數可用。當輸入操作數可用時,就可以向相應的執(zhí)行單元發(fā)出指令。
因此,一旦指令的操作數可用,指令可按任何順序執(zhí)行,而不再受程序順序的限制。現代處理器越來越寬(一個周期內可執(zhí)行多條指令)、越來越深(更大的 ROB、RS 和其他緩沖區(qū)),這表明在生產應用中發(fā)現更多 ILP 的潛力巨大。
3.3.2 超標量引擎(Superscalar Engines)
大多數現代 CPU 都是超標量引擎,即在任何給定周期內都可以發(fā)出多條指令。發(fā)射寬度是指在同一周期內可發(fā)行指令的最大數量(參見第 4.5 節(jié))。2024 年主流 CPU 的典型發(fā)行寬度介于 6 到 9 之間。為了確保適當的平衡,此類超標量引擎還具有多個執(zhí)行單元和/或流水線執(zhí)行單元。CPU 還將超標量能力與深度流水線和無序執(zhí)行相結合,為特定軟件提取最大的 ILP。
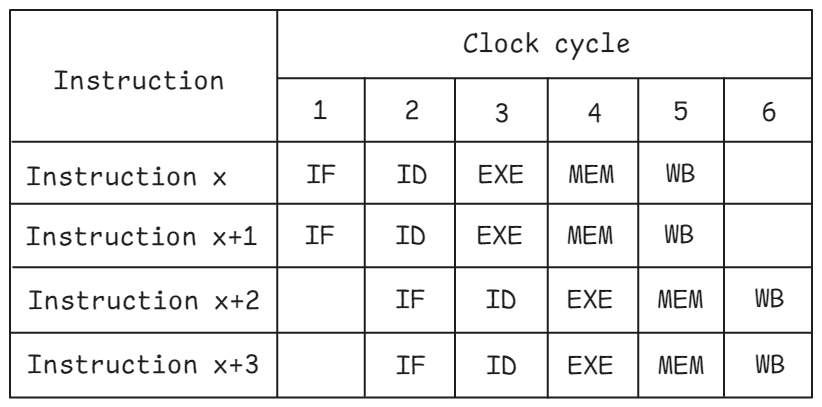
上圖顯示的是支持雙通道的 CPU 的流水線圖。請注意,每個周期的每個流水線階段都可以處理兩條指令。例如,指令 x 和 x+1 都在周期 3 開始執(zhí)行。這可能是兩條相同類型的指令(如兩條加法指令),也可能是兩條不同的指令(如一條加法指令和一條分支指令)。超標量處理器會復制執(zhí)行資源,以保持流水線中指令的流暢性,避免出現結構性沖突。例如,要同時支持兩條指令的解碼,我們需要 2 個獨立的解碼器。
3.3.3 預測執(zhí)行(Speculative Execution)
如上一節(jié)所述,如果指令在分支條件得到解決之前停滯不前,控制危險會導致流水線性能大幅下降。
避免這種性能損失的一種技術是硬件分支預測。利用這種技術,CPU 可以預測分支的可能目標,并從預測路徑開始執(zhí)行指令。
讓我們來看看清單 3.1 中的一個例子。處理器要想知道下一步應該執(zhí)行哪個函數,就必須知道條件 a < b 是假還是真。
如果不知道這一點,CPU 就會一直等待,直到確定分支指令的結果:
if (a < b)
foo();
else
bar();
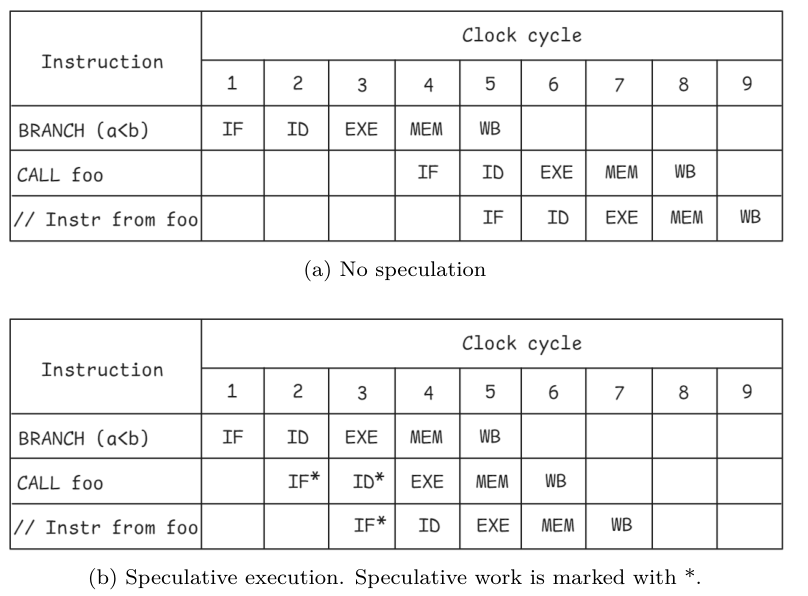
通過推測執(zhí)行,CPU 猜測分支的結果,并從所選路徑開始處理指令。假設處理器預測條件 a < b 將被評估為真。處理器不等待分支結果,直接調用函數 foo。在條件得到解決之前,機器的狀態(tài)變化不能提交,以確保機器的架構狀態(tài)絕不會受到推測執(zhí)行指令的影響。
在上例中,分支指令比較兩個標量值,速度很快。但實際上,分支指令可能取決于從內存加載的值,這可能需要數百個周期。
如果預測結果正確,就能節(jié)省大量周期。但有時預測并不正確,應該調用函數欄。在這種情況下,推測執(zhí)行的結果必須被擠壓并丟棄。
這就是我們將在第 4.8 節(jié)討論的分支錯誤預測懲罰。投機執(zhí)行的指令在 ROB 中被標記為投機指令。一旦它不再是推測性指令,就可以按程序順序退出。這里是架構狀態(tài)提交和架構寄存器更新的地方。由于推測指令的結果不會被提交,因此當發(fā)生錯誤預測時很容易回退。
3.3.4 分支預測
正如我們剛才所看到的,正確的預測可以大大提高執(zhí)行效率,因為它可以讓 CPU 在沒有先前指令結果的情況下向前推進。
然而,錯誤的預測往往會帶來代價高昂的性能損失。現代 CPU 采用了復雜的動態(tài)分支預測機制,可提供極高的準確性,并能適應分支行為的動態(tài)變化。有三類分支可以特殊方式處理:
-
無條件跳轉和直接調用:這是最容易預測的分支,因為它們每次都會跳轉,而且方向相同。
-
有條件分支:它們有兩種可能的結果:采取或不采取。采取的分支可以向前或向后。前向條件分支通常是為 if-else 語句生成的,這些語句有很大幾率不會被采用,因為它們經常代表錯誤檢查代碼。后向條件跳轉經常出現在循環(huán)中,用于進入循環(huán)的下一次迭代;此類分支通常會被采用。
-
間接調用和跳轉:它們有許多目標。間接跳轉或間接調用可以由 switch 語句、函數指針或虛擬函數調用產生。函數的返回也值得關注,因為它也有許多潛在的目標。
大多數預測算法都是基于先前的分支結果。分支預測單元(BPU)的核心是分支目標緩沖區(qū)(BTB),它緩存了每個分支的目標地址。預測算法在每個周期都會查閱 BTB,以生成下一個可提取指令的地址。CPU 使用新地址獲取下一個指令塊。如果當前取指令塊中沒有發(fā)現分支,下一個取指令地址將是下一個順序對齊的取指令塊(fall through)。
無條件分支不需要預測;我們只需在 BTB 中查找目標地址。每個周期,BPU 都需要生成下一個取指令地址,以避免流水線停滯。我們本可以只從指令編碼本身提取地址,但這樣我們就必須等到解碼階段結束,這會在流水線中引入一個氣泡,導致速度變慢。因此,必須在獲取分支時確定下一個獲取地址。
對于條件分支,我們首先需要預測分支是否會被執(zhí)行。如果不采取,那么我們就會失敗,無需查找目標地址。否則,我們將在 BTB 中查找目標地址。條件分支通常占總分支的最大部分,也是生產軟件中錯誤預測懲罰的主要來源。對于間接分支,我們需要從可能的目標中選擇一個,但預測算法可能與條件分支非常相似。
所有預測機制都試圖利用兩個重要原則,這兩個原則與我們稍后討論的緩存類似:
- 時間相關性:分支的解析方式可以很好地預測下一次執(zhí)行時的解析方式。這也被稱為局部相關性。
- 空間相關性:多個相鄰分支可能以高度相關的方式(優(yōu)先執(zhí)行路徑)解析。這也稱為全局相關性。
通常利用局部和全局相關性可以達到最佳精度。因此,我們不僅要查看當前分支的結果歷史,還要將其與相鄰分支的結果相關聯。
另一種常用技術稱為混合預測。其原理是,某些分支的行為會產生偏差。例如,如果一個條件分支在 99.9% 的時間內都會朝一個方向發(fā)展,那么就沒有必要使用復雜的預測器和污染其數據結構。相反,可以使用一種簡單得多的機制。另一個例子是循環(huán)分支。如果分支具有循環(huán)行為,則可以使用專用的循環(huán)預測器對其進行預測,該預測器將記住循環(huán)通常執(zhí)行的迭代次數。
目前,最先進的預測方法主要是類似 TAGE 的預測器 Seznec & Michaud, 2006。Championship冠軍分支預測器每 1000 條指令的錯誤預測少于 3 次。現代 CPU 在大多數工作負載上的預測率通常都能達到 95%以上。
3.4 SIMD 多處理器
另一種促進并行處理的技術稱為單指令多數據(SIMD Single Instruction Multiple Data),幾乎所有高性能處理器都采用這種技術。顧名思義,在 SIMD 處理器中,一條指令在一個周期內使用多個獨立的功能單元對多個數據元素進行操作。矢量和矩陣的運算非常適合 SIMD 架構,因為矢量或矩陣的每個元素都可以使用相同的指令進行處理。SIMD 體系結構能更有效地處理大量數據,最適合涉及矢量操作的數據并行應用。
double *a, *b, *c;
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
在傳統的單指令單數據 (SISD) 模式(也稱為標量模式)中,加法運算分別應用于數組 a 和 b 的每個元素。如果我們使用的 CPU 架構的執(zhí)行單元能夠對 256 位矢量進行運算,那么我們就可以用一條指令處理四個雙精度元素。這樣可以少發(fā) 4 倍指令,速度可能比 4 次標量計算快 4 倍。
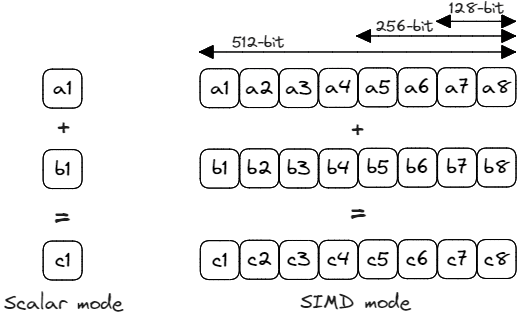
對于常規(guī)整數 SISD 指令,處理器使用通用寄存器。同樣,對于 SIMD 指令,CPU 有一組 SIMD 寄存器,以保存從內存中加載數據并存儲計算的中間結果。在我們的示例中,將從內存中加載與數組 a 和 b 相對應的兩個 256 位連續(xù)數據區(qū)域,并將其分別存儲在兩個矢量寄存器中。接下來,進行元素加法運算,并將結果存儲到一個新的 256 位矢量寄存器中。注意,數據元素可以是整數或浮點數。
矢量執(zhí)行單元在邏輯上被劃分為多個通道。在 SIMD 的背景下,車道指的是 SIMD 執(zhí)行單元內的一條獨立數據通道,用于處理向量的一個元素。在我們的例子中,每個通道處理 64 位元素(雙精度),因此 256 位寄存器中有 4 個通道。
大多數流行的 CPU 架構都具有向量指令,包括 x86、PowerPC、ARM 和 RISC-V。1996 年,英特爾發(fā)布了專為多媒體應用設計的 SIMD 指令集 MMX。繼 MMX 之后,英特爾又推出了功能更強、矢量更大的新指令集: SSE、AVX、AVX2 和 AVX-512。ARM 在其不同版本的體系結構中可選擇支持 128 位 NEON 指令集。在第 8 版(aarch64)中,這種支持成為強制性的,并增加了新的指令。
隨著新指令集的問世,軟件工程師開始著手將它們變?yōu)楝F實。利用 SIMD 指令所需的軟件更改稱為代碼矢量化。最初,SIMD 指令是用匯編程序編寫的。后來,引入了特殊的編譯器本征(intrinsics),即提供 SIMD 指令一對一映射的小函數。如今,所有主要的編譯器都支持流行處理器的自動矢量化,即可以直接從用 C/C++、Java、Rust 和其他語言編寫的高級代碼中生成 SIMD 指令。
為了使代碼能在支持不同矢量長度的系統上運行,Arm 引入了 SVE 指令集。其顯著特點是可擴展向量的概念:它們的長度在編譯時是未知的。有了 SVE,就無需將軟件移植到每一種可能的向量長度上。當新一代 CPU 中出現更寬的向量時,用戶無需重新編譯應用程序的源代碼即可利用這些向量。可擴展向量的另一個例子是 RISC-V V 擴展(RVV),該擴展于 2021 年底獲得批準。一些實現支持相當寬(2048 位)的矢量,最多可將 8 個矢量組合在一起,產生 16384 位矢量,從而大大減少了執(zhí)行指令的數量。在每次循環(huán)迭代時,SVE 代碼通常會執(zhí)行 ptr += number_of_lane,其中 number_of_lanes 在編譯時是未知的。ARM SVE 為這種依賴長度的操作提供了特殊指令,而 RVV 則使程序員能夠查詢/設置 number_of_lanees。
上例如果 N 等于 5,并且我們有一個 256 位的向量,我們就無法在一次迭代中處理所有元素。我們可以使用一條 SIMD 指令處理前四個元素,但第五個元素需要單獨處理。這就是所謂的循環(huán)余量。循環(huán)余量是循環(huán)中必須處理的元素數量少于矢量寬度的部分,需要額外的標量代碼來處理剩余的元素。可擴展矢量 ISA 擴展不存在這個問題,因為它們可以在一條指令中處理任意數量的元素。
解決循環(huán)剩余問題的另一種方法是使用掩碼,它可以根據條件有選擇地啟用或禁用 SIMD 通道。
此外,CPU 也越來越多地加速機器學習中經常使用的矩陣乘法。英特爾的 AMX 擴展自 2023 年起在服務器處理器中得到支持,可對形狀為 16x64 和 64x16 的 8 位矩陣進行乘法運算,累加為 32 位 16x16 矩陣。相比之下,蘋果 CPU 中毫不相關但名稱相同的 AMX 擴展以及 ARM 的 SME 擴展則分別計算存儲在特殊 512 位寄存器或可擴展矢量中的行和列的外乘積。
SIMD 最初由多媒體應用和科學計算驅動,但后來在許多其他領域也得到了應用。隨著時間的推移,SIMD 指令集所支持的操作集也在穩(wěn)步增加。除了直接算術運算外,SIMD 的新用例還包括
- 字符串處理:查找字符、驗證 UTF-8、解析 JSON 和 CSV;散列、隨機生成、密碼學(AES);
- 列式數據庫(位打包、過濾、連接);
- 內置類型排序(VQSort、QuickSelect);
- 機器學習和人工智能(加速 PyTorch、TensorFlow)。
3.5 利用線程級并行性
前面介紹的技術依賴于程序中可用的并行性來加快執(zhí)行速度。除此之外,CPU 還支持利用 CPU 上執(zhí)行的進程和/或線程間并行性的技術。接下來,我們將討論三種利用線程級并行性(TLP)的技術:多核系統、同步多線程和混合架構。這些技術可以最大限度地利用現有硬件資源,提高系統的吞吐量。
3.5.1 多核系統
隨著處理器設計人員開始受到半導體設計和制造的實際限制,GHz 競賽放緩,設計人員不得不將重點放在其他創(chuàng)新上,以提高 CPU 性能。多核設計是其中一個重要方向,它試圖增加每一代處理器的內核數。其想法是在單個芯片上復制多個處理器內核,讓它們同時為不同的程序服務。例如,其中一個內核可以同時運行網絡瀏覽器,另一個內核可以渲染視頻,還有一個內核可以播放音樂。對于服務器機器來說,來自不同客戶的請求可以在不同的內核上處理,這可以大大提高系統的吞吐量。
第一款面向消費者的雙核處理器是 2005 年發(fā)布的英特爾酷睿 2 雙核處理器,同年晚些時候又發(fā)布了 AMD Athlon X2 架構。多核系統導致許多軟件組件需要重新設計,并影響了我們編寫代碼的方式。如今,幾乎所有面向消費者設備的處理器都是多核 CPU。在撰寫本書時,高端筆記本電腦包含十多個物理內核,服務器處理器在一個插座上包含 100 多個內核。
這聽起來似乎非常驚人,但我們不能無限增加內核。首先,每個內核在工作時都會產生熱量,而如何安全地通過處理器封裝將熱量從內核中散發(fā)出去仍然是一個難題。這意味著當更多內核運行時,熱量很快就會超過冷卻能力。在這種情況下,多核處理器會降低時鐘速度。這就是為什么擁有大量內核的服務器芯片的頻率遠遠低于筆記本電腦和臺式機處理器的原因之一。
多核系統中的內核相互連接,并與末級高速緩存和內存控制器等共享資源相連。這種通信通道稱為互連,通常采用環(huán)形或網狀拓撲結構。CPU 設計人員面臨的另一個挑戰(zhàn)是如何在內核數量增加時保持機器的平衡。當你復制內核時,一些資源仍然是共享的,例如內存總線和末級高速緩存。除非同時解決其他共享資源的吞吐量問題,如互連帶寬、末級高速緩存大小和帶寬以及內存帶寬,否則隨著內核的增加,性能回報會越來越低。共享資源經常成為多核系統性能問題的根源。
3.5.2 同步多線程
為提高多線程性能,一種更復雜的方法是同步多線程(SMT Simultaneous Multithreading)。人們經常使用 “超線程”(Hyperthreading)來描述同一事物。該技術的目標是充分利用 CPU 管線的可用寬度。SMT 允許多個軟件線程使用共享資源在同一物理內核上同時運行。更確切地說,來自 50 個線程的指令可以在一個物理內核上同時運行。。這些線程不一定是同一進程的線程,也可以是碰巧安排在同一物理內核上的完全不同的程序。
在非 SMT 和雙路 SMT(SMT2)處理器上的執(zhí)行示例如圖。在這兩種情況下,處理器流水線的寬度都是 4,每個插槽都代表一次發(fā)布新指令的機會。機器 100% 利用率是指沒有未使用的插槽,而這在實際工作負載中從未發(fā)生過。不難看出,在非 SMT 情況下,有很多未使用的插槽,因此可用資源沒有得到很好的利用。出現這種情況可能有多種原因。例如,在周期 3 中,線程 1 無法向前推進,因為所有指令都在等待輸入可用。非 SMT 處理器只會停滯不前,而支持 SMT 的處理器則會利用這個機會安排另一個線程的有用工作。這樣做的目的是占用另一個線程未使用的插槽,以提高硬件利用率和多線程性能。
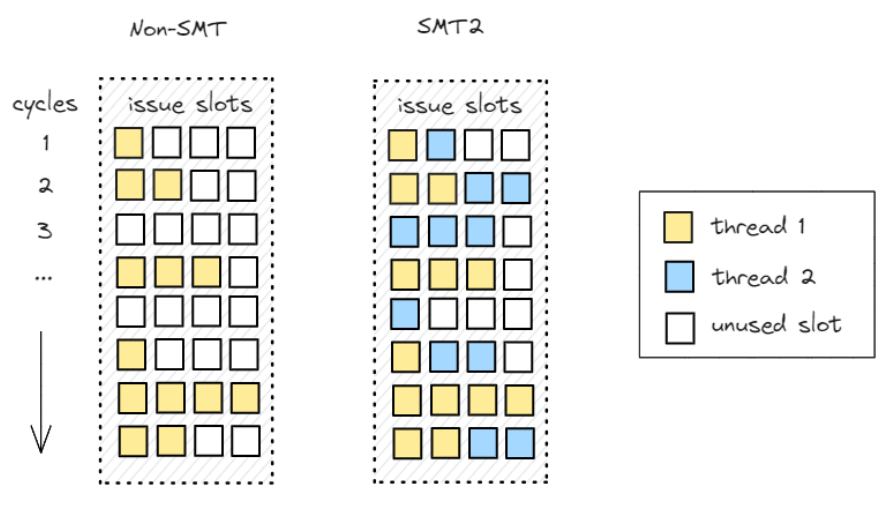
在 SMT2 實現中,每個物理內核由兩個邏輯內核表示,操作系統可將其視為兩個獨立的處理器來處理工作。假設有 16 個軟件線程可以運行,但只有 8 個物理內核。在非 SMT 系統中,只有 8 個線程同時運行,而使用 SMT2,我們可以同時執(zhí)行所有 16 個線程。在另一種假設情況下,如果兩個程序在一個支持 SMT 的內核上運行,并且每個程序只持續(xù)使用四個可用插槽中的兩個,那么它們的運行速度很有可能與單獨在該物理內核上運行時一樣快。
雖然兩個程序在同一個處理器內核上運行,但它們彼此完全分離。在支持 SMT 的處理器中,即使指令是混合的,它們也有不同的上下文,這有助于保持執(zhí)行的正確性。
為支持 SMT,CPU 必須復制架構狀態(tài)(程序計數器、寄存器)以保持線程上下文。其他 CPU 資源可以共享。在典型的實施中,緩存資源在硬件線程之間動態(tài)共享。跟蹤 OOO 和推測執(zhí)行的資源可以復制或分割。
在 SMT2 內核中,兩個邏輯內核真正同時運行。在 CPU 前端,它們以交替順序(每個周期或幾個周期)獲取指令。在后端,處理器在每個周期從所有線程中選擇要執(zhí)行的指令。指令的執(zhí)行是混合的,因為處理器會在兩個線程之間動態(tài)調度執(zhí)行單元。
因此,SMT 是一種非常靈活的設置,可以恢復未使用的 CPU 問題槽。除了多線程的優(yōu)勢外,SMT 還能提供同等的單線程性能。選擇支持 SMT 的現代 CPU 通常采用雙向(SMT2)SMT,有時也采用四向(SMT4)SMT。
SMT 也有自己的缺點。由于邏輯內核之間共享某些資源,它們最終可能會競爭使用這些資源。L1 和 L2 高速緩存的競爭最有可能造成 SMT 損失。由于這些資源由兩個邏輯內核共享,它們可能會因為緩存空間不足而強制驅逐將來會被其他線程使用的數據。
SMT 給軟件開發(fā)人員帶來了相當大的負擔,因為它使得預測和衡量在 SMT 內核上運行的應用程序的性能變得更加困難。
想象一下,你正在 SMT 內核上運行性能關鍵型代碼,而操作系統突然將另一個要求苛刻的任務放到了同級邏輯內核上。你的代碼幾乎耗盡了機器的資源,現在你需要與其他人共享資源。這個問題在云環(huán)境中尤為突出,因為你無法預測你的應用程序是否會有吵鬧的鄰居。
某些同步多線程實現也存在安全隱患。研究人員發(fā)現,一些早期的實現存在漏洞,一個應用程序可以通過這個漏洞從另一個運行在同時多線程上的應用程序中竊取關鍵信息(如加密密鑰)。
通過監(jiān)控緩存的使用情況,從運行在同一處理器的同級邏輯內核上的另一個應用程序中竊取關鍵信息(如加密密鑰)。由于硬件安全不屬于本書的討論范圍,我們將不再深入探討這一問題。
3.5.3 混合架構
計算機架構師還開發(fā)了一種混合 CPU 設計,將兩種(或多種)內核放在同一個處理器中。通常情況下,更強大的內核與相對較慢的內核相結合,以實現不同的目標。在這種系統中,大內核用于對延遲敏感的任務,而小內核則可降低功耗。此外,兩種內核還可以同時使用,以提高多線程性能。所有內核都可以訪問相同的內存,因此工作負載可以從大內核遷移到小內核,然后再返回。這樣做的目的是為了創(chuàng)建一種能更好地適應動態(tài)計算需求、耗電更少的多核處理器。例如,視頻游戲既有單線程突發(fā)執(zhí)行的部分,也有可擴展到多個內核的部分。
第一個主流混合架構是 Arm 于 2011 年 10 月推出的 big.LITTLE。其他廠商也紛紛效仿。蘋果公司在 2020 年推出了 M1 芯片,該芯片有四個高性能的 “Firestorm ”內核和四個高能效的“Icestorm ”內核。英特爾在 2021 年推出了 Alder Lake 混合架構,其頂級配置為 8 個 P 核和 8 個 E 核。
混合架構結合了兩種內核類型的優(yōu)點,但也帶來了一系列挑戰(zhàn)。首先,它要求內核完全兼容 ISA,即它們應能執(zhí)行同一套指令。否則,調度就會受到限制。例如,如果一個大內核具有一些小內核無法使用的花哨指令,那么你只能分配大內核來運行使用這些指令的工作負載。這就是為什么供應商在為混合處理器選擇 ISA 時通常使用 “最大公分母 ”方法。
即使是 ISA 兼容的內核,調度也變得非常具有挑戰(zhàn)性。不同類型的工作負載需要特定的調度方案,如突發(fā)執(zhí)行與穩(wěn)定執(zhí)行、低 IPC( Instructions Per Cycle 指令每周期) 與高 IPC、50 低重要性與高重要性等。這很快就會變得非常棘手。以下是優(yōu)化調度的幾個注意事項:
- 利用小內核節(jié)省電能。不要喚醒大內核進行后臺工作。
- 識別候選任務(低重要性、低 IPC),將其卸載到較小的內核上。
- 分配新任務時,首先使用空閑的大核心。如果是 SMT,則在兩個邏輯線程都空閑的情況下使用大內核。然后,使用空閑的小內核。然后,使用大核心的同級邏輯線程。
從程序員的角度來看,使用混合系統無需修改代碼。這種方法在面向客戶端的設備中非常流行,尤其是在智能手機中。
3.6 內存層次結構
為有效利用 CPU 中的所有硬件資源,需要在正確的時間向機器提供正確的數據。如果不能做到這一點,就需要從主存儲器中獲取變量,這需要大約 100 ns 的時間。從 CPU 的角度來看,這是一個非常長的時間。要發(fā)揮 CPU 的性能,了解內存層次結構至關重要。大多數程序都具有局部性:它們不會統一訪問所有代碼或數據。CPU 內存層次結構基于兩個基本特性:
- 時間局部性:當訪問給定內存位置時,同一位置很可能很快會再次被訪問。理想情況下,我們希望下次需要時,緩存中就有這些信息。
- 空間位置性:當訪問給定內存位置時,附近的位置可能很快也會被訪問。這是指將相關數據放在彼此靠近的位置。當程序從內存中讀取單個字節(jié)時,通常會獲取較大的內存塊(緩存行),因為通常情況下,程序很快就會需要該數據。
本節(jié)概述了現代 CPU 支持的內存分層系統的主要屬性。
3.6.1 高速緩存層次結構(Cache Hierarchy)
高速緩存是內存層次結構的第一層,用于處理從 CPU 流水線發(fā)出的任何請求(代碼或數據)。緩存是 CPU 流水線發(fā)出的任何請求(代碼或數據)的第一級內存層次結構。理想情況下,流水線的最佳性能是擁有一個訪問延遲最小的無限緩存。實際上,任何高速緩存的訪問時間都會隨其大小而增加。因此,高速緩存被組織成一個層次結構,由最靠近執(zhí)行單元的小型快速存儲塊組成,并以較大、較慢的存儲塊為后盾。高速緩存層次結構中的某一層次可專門用于代碼(指令高速緩存,I-cache)或數據(數據高速緩存,D-cache),或代碼與數據共享(統一高速緩存 unified cache)。此外,層次結構中的某些層級可為特定內核專用,而其他層級則可在內核間共享。
高速緩存以塊的形式組織,具有規(guī)定的大小,也稱為高速緩存行。現代 CPU 的典型緩存行大小為 64 字節(jié)。不過,蘋果處理器(如 M1、M2 及更高版本)的二級緩存是個明顯的例外,它采用 128B 緩存行。最接近執(zhí)行流水線的緩存大小通常在 32 KB 到 128 KB 之間。中級緩存的大小通常在 1MB 及以上。現代 CPU 的末級緩存可達幾十甚至上百兆字節(jié)。
3.6.1.1 數據在緩存中的位置。
請求的地址用于訪問緩存。在直接映射緩存中,給定的塊地址只能出現在緩存中的一個位置,并由下圖所示的映射函數定義。
直接映射高速緩存相對容易構建,訪問速度快,但錯失率高。

在完全關聯緩存中,給定塊可以放在緩存中的任何位置。這種方法涉及的硬件復雜度高,訪問時間慢,因此被認為不適合大多數使用情況。
介于直接映射和完全關聯映射之間的一種選擇是集合關聯映射。在這種高速緩存中,塊被組織成集,通常每個集包含 2、4、8 或 16 個塊。給定地址首先映射到一個集合。
在一個集合中,地址可以被放置在該集合中的任何區(qū)塊中。每組包含 m 個塊的高速緩存被稱為 m 路集關聯高速緩存。集合關聯型高速緩存的公式為

以 L1 緩存為例,其大小為 32 KB,有 64 字節(jié)緩存行、64 個集和 8 條路。該緩存的緩存行總數為 32 KB / 64 字節(jié) = 512 行。新行只能插入相應的集(64 個集之一)中。一旦集合確定,新行就可以進入該集合中的 8 種方式之一。同樣,在以后搜索該緩存行時,首先要確定該組,然后只需檢查該組中的 8 條路。
以下是 Apple M1 處理器緩存組織的另一個示例。每個性能核心內部的 L1 數據高速緩存可存儲 128 KB,有 256 個集,每個集有 8 條路,以 64 字節(jié)行運行。性能內核組成一個集群,共享二級緩存,二級緩存可存儲 12 MB,具有 12 路集合關聯,并在 128 字節(jié)行上運行。蘋果公司,2024
3.6.1.2 在緩存中查找數據。
m 路集合關聯緩存中的每個塊都有一個地址標簽。此外,標簽還包含狀態(tài)位,如用于指示數據是否有效的位。標簽還可以包含額外的位來指示訪問信息、共享信息等。

最低階地址位定義了給定塊內的偏移;塊偏移位(32 字節(jié)高速緩存行為 5 位,64 字節(jié)高速緩存行為 6 位)。根據上述公式,使用索引位選擇數據集。一旦選擇了數據集,標記位就會被用來與該數據集中的所有標記進行比較。如果其中一個標簽與輸入請求的標簽相匹配,且有效位被置位,則會產生緩存命中。與該數據塊條目相關的數據(與標簽查找同時從高速緩存的數據數組中讀出)將提供給執(zhí)行流水線。如果標簽不匹配,則會出現緩存缺失。
3.6.1.3 管理缺失(緩存缺失)
當緩存未命中時,緩存控制器必須在緩存中選擇一個要替換的塊,以分配導致未命中的地址。對于直接映射型高速緩存,由于新地址只能在單個位置上分配,因此要刪除映射到該位置的前一個條目,并在其位置上安裝新條目。而在集合關聯型高速緩存中,由于新的高速緩存塊可以放在集合中的任何一個塊中,因此需要一種替換算法。
典型的替換算法是 LRU(最近最少使用)策略,即驅逐最近訪問次數最少的數據塊,為新數據騰出空間。
另一種方法是隨機選擇一個區(qū)塊作為受害區(qū)塊。
3.6.1.4 管理寫入。
與數據讀取相比,緩存的寫入訪問頻率較低。處理緩存中的寫操作比較困難,CPU 實現使用各種技術來處理這種復雜性。軟件開發(fā)人員應特別注意硬件支持的各種寫緩存流,以確保代碼達到最佳性能。
CPU 設計使用兩種基本機制來處理命中緩存的寫操作:
- 在直通寫緩存中,命中的數據被寫入緩存中的塊和下一級層次結構。
- 在回寫緩存中,命中數據只寫入緩存。隨后,層次結構的下一級包含陳舊數據。修改行的狀態(tài)通過標簽中的臟位進行跟蹤。當修改過的緩存行最終被從緩存中剔除時,回寫操作會強制將數據寫回到下一級。
寫操作的緩存缺失可通過兩種方式處理:
- 在寫分配高速緩存中,遺漏位置的數據會從層次結構的下層加載到高速緩存中,隨后寫操作會像寫命中一樣被處理。
- 如果高速緩存采用的是不寫入-分配策略,則高速緩存未命中事務會直接發(fā)送到層次結構的下層,而不會將數據塊加載到高速緩存中。
在這些選項中,大多數設計通常會選擇使用寫分配策略來實現回寫高速緩存,因為這兩種技術都試圖將后續(xù)的寫事務轉換為高速緩存命中,而不會給層次結構的下層帶來額外的流量。直通寫緩存通常使用無寫分配策略。
3.6.1.5 其他緩存優(yōu)化技術
對于程序員來說,了解緩存層次結構的行為對于從任何應用程序中獲取性能都至關重要。從 CPU 流水線的角度來看,訪問任何請求的延遲由以下公式給出,該公式可遞歸應用于緩存層次結構的所有層級,直至主內存:平均訪問延遲 = 命中時間 + 未命中率 × 未命中懲罰
硬件設計人員通過許多新穎的微體系結構技術來減少命中時間和未命中懲罰。從根本上說,高速緩存的未命中會使流水線停滯,影響性能。任何緩存的未命中率都與緩存架構(塊大小、關聯性)和機器上運行的軟件密切相關。
3.6.1.6 硬件和軟件預取。
避免緩存未命中和后續(xù)停滯的一種方法是在流水線需要數據之前將數據預取到緩存中。其假設是,如果在流水線中足夠提前地發(fā)出預取請求,處理未命中懲罰所需的時間基本可以隱藏起來。大多數 CPU 提供基于硬件的隱式預取,并輔以程序員可以控制的顯式軟件預取。
硬件預取器會觀察運行應用程序的行為,并根據緩存缺失的重復模式啟動預取。硬件預取可以自動適應應用程序的動態(tài)行為,如變化的數據集,而且不需要優(yōu)化編譯器的支持。此外,硬件預取無需額外的地址生成和預取指令。不過,硬件預取只適用于有限的常用數據訪問模式。軟件內存預取是對硬件預取的補充。開發(fā)人員可通過專用硬件提前指定所需的內存位置參見第 8.5 節(jié))。編譯器也可以在代碼中自動添加預取指令,在需要數據之前提出請求。預取技術需要在需求和預取請求之間取得平衡,以防止預取流量拖慢需求流量。
3.6.2 主存儲器
主存儲器是層次結構的下一級,位于高速緩存的下游。加載和存儲數據的請求由內存控制器單元 (MCU Memory Controller Unit) 發(fā)起。過去,該電路位于主板上的北橋芯片中。但現在,大多數處理器都嵌入了這一組件,因此 CPU 有一條專用內存總線連接到主存儲器。
主存儲器采用 DRAM(動態(tài)隨機存取存儲器)技術,可在合理的成本范圍內支持大容量。在比較 DRAM 模塊時,人們通常會關注內存密度和內存速度,當然還有價格。內存密度是指模塊的容量,單位為 GB。顯然,可用內存越多越好,因為它是操作系統和應用程序使用的寶貴資源。
主內存的性能由延遲和帶寬來描述。內存延遲是指從發(fā)出內存訪問請求到 CPU 可以使用數據之間所經過的時間。內存帶寬是指在一定時間內可獲取多少字節(jié),通常以每秒千兆字節(jié)為單位。
3.6.2.1 DDR(雙倍數據速率)
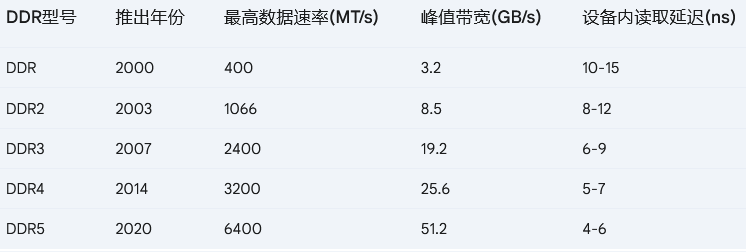
DDR(Double Data Rate)是大多數 CPU 支持的主要 DRAM 技術。從歷史上看,每一代 DRAM 的帶寬都在提高,而 DRAM 的延遲卻保持不變或有所增加。下表顯示了過去三代 DDR 技術的最高數據速率、峰值帶寬和相應的讀取延遲。數據傳輸率以每秒百萬次傳輸(MT/s)為單位。表中顯示的延遲與 DRAM 設備本身的延遲相對應。通常情況下,由于高速緩存控制器、內存控制器和片上互連中產生的額外延遲和排隊延遲,從 CPU 流水線(負載使用時的高速緩存未命中)看到的延遲會更高(在 50ns-150ns 范圍內)。您可以在第 4.10 節(jié)中看到測量觀察到的內存延遲和帶寬的示例。
值得一提的是,DRAM 芯片需要定期刷新內存單元。這是因為位值是以電荷的形式存儲在一個微小的電容器上的,因此它會隨著時間的推移而失去電荷。為了防止這種情況發(fā)生,有一種特殊的電路可以讀取每個單元并將其寫回,從而有效地恢復電容器的電荷。DRAM 芯片在刷新過程中,并不提供內存訪問請求。
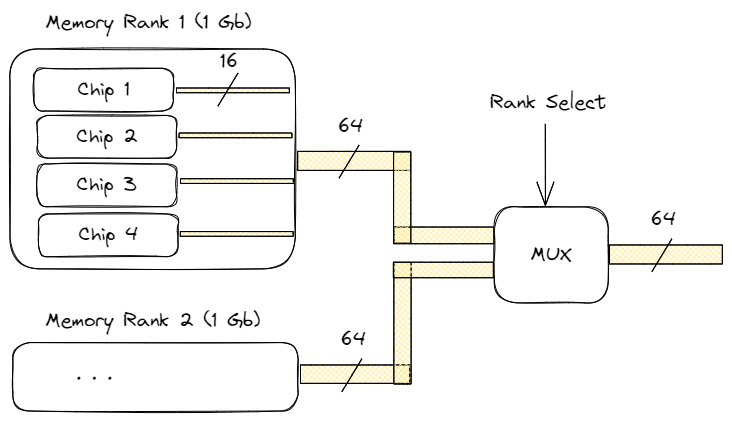
DRAM 模塊由一組 DRAM 芯片組成。內存等級是一個術語,用于描述一個模塊上有多少組 DRAM 芯片。例如,單級(1R)內存模塊包含一組 DRAM 芯片。雙通道(2R)內存模塊有兩組 DRAM 芯片,因此容量是單通道模塊的兩倍。同樣,我們還可以購買四排(4R)和八排(8R)內存模塊。
每個等級由多個 DRAM 芯片組成。內存寬度定義了每個 DRAM 芯片的總線寬度。由于每個階寬為 64 位(ECC RAM 為 72 位),因此它也定義了階內 DRAM 芯片的數量。內存寬度可以是三個值之一:x4、x8 或 x16,定義了每個芯片的總線寬度。例如,下圖顯示了總容量為 2GB 的 2Rx16 雙排 DRAM DDR4 模塊的組織結構。每級有四個芯片,總線寬度為 16 位。四個芯片的總輸出為 64 位。通過等級選擇信號一次選擇一個等級。
單排還是雙排的性能更好,并沒有直接的答案,因為這取決于應用類型。單排模塊通常發(fā)熱較少,不易出現故障。此外,多級模塊需要一個級選擇信號來從一個級切換到另一個級,這需要額外的時鐘周期,可能會增加訪問延遲。另一方面,如果一個級沒有被訪問,它可以在其他級繁忙時并行刷新周期。一旦前一個等級完成數據傳輸,下一個等級就可以立即開始傳輸。
更進一步,我們可以在系統中安裝多個 DRAM 模塊,這樣不僅可以增加內存容量,還能提高內存帶寬。多內存通道的設置可提高內存控制器與 DRAM 之間的通信速度。
單內存通道系統的 DRAM 和內存控制器之間的數據總線寬為 64 位。多通道架構增加了內存總線的寬度,允許同時訪問 DRAM 模塊。例如,雙通道架構將內存數據總線的寬度從 64 位擴展到 128 位,使可用帶寬增加了一倍。請注意,每個內存模塊仍然是 64 位設備,只是連接方式不同。如今,服務器機器通常有四個或八個內存通道。
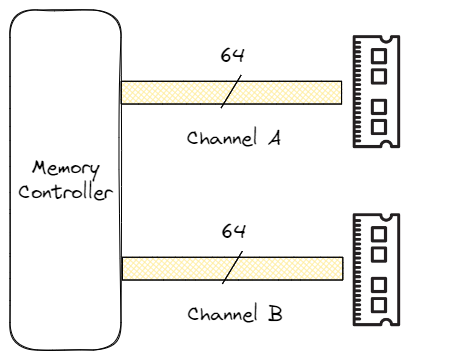
此外,你還可能遇到重復內存控制器的設置。例如,處理器可能有兩個集成內存控制器,每個都能支持多個內存通道。這兩個控制器是獨立的,只能查看各自的物理內存地址空間。我們可以使用下面的簡單公式進行快速計算,以確定特定內存技術的最大內存帶寬:最大內存帶寬=數據速率×每周期字節(jié)數
例如,對于數據速率為 2400 MT/s、每次傳輸 64 位(8 字節(jié))的單通道 DDR4 配置,最大帶寬等于 2400 * 8 = 19.2 GB/s。雙通道或雙內存控制器設置可將帶寬提高一倍,達到 38.4 GB/s。但請記住,這些數字都是理論上的最大值,假設每個內存時鐘周期都會進行一次數據傳輸,而實際上這種情況從未發(fā)生過。因此,在測量實際內存速度時,你看到的數值總是低于最大理論傳輸帶寬。
要啟用多通道配置,需要有支持這種架構的 CPU 和主板,并在主板上正確的內存插槽中安裝偶數個相同的內存模塊。在 Windows 系統上,檢查設置的最快方法是運行 CPU-Z 或 HwInfo 等硬件識別實用程序;在 Linux 系統上,可以使用 dmidecode 命令。此外,還可以運行 Intel MLC 或 Stream 等內存帶寬基準。
要利用系統中的多個內存通道,有一種技術叫做交錯。它將一個頁面內的相鄰地址分散到多個內存設備上。下圖顯示了一個用于順序內存訪問的雙向交錯實例。如前所述,我們有一個雙通道內存配置(通道 A 和 B),有兩個獨立的內存控制器。現代處理器以每四條高速緩存線(256 字節(jié))為單位進行交錯,即前四條相鄰的高速緩存線進入通道 A,然后下一組四條高速緩存線進入通道 B。
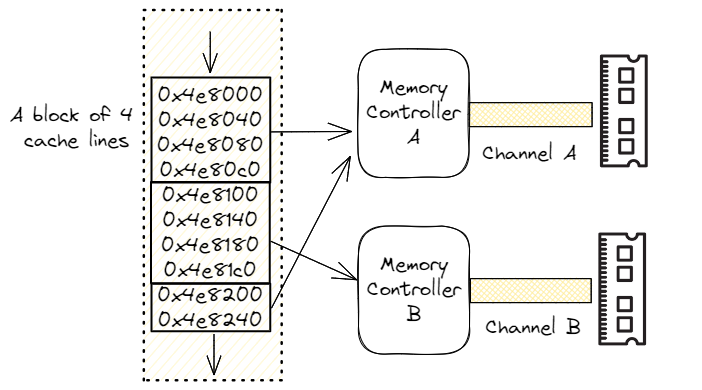
如果沒有交錯功能,連續(xù)的相鄰訪問將被發(fā)送到同一個內存控制器,無法利用第二個可用的控制器。
相比之下,交錯可實現硬件并行,從而更好地利用可用的內存帶寬。對于大多數工作負載而言,當所有通道都被填滿時,性能將達到最大化,因為這樣可以將單個內存區(qū)域盡可能地分散到更多的 DRAM 模塊上。
雖然增加內存帶寬通常是件好事,但并不總能帶來更好的系統性能,這在很大程度上取決于應用程序。另一方面,注意可用和已用內存帶寬也很重要,因為一旦內存帶寬成為主要瓶頸,應用程序就會停止擴展,也就是說,增加更多內核并不能使其運行得更快。
3.6.2.2 GDDR 和 HBM
除多通道 DDR 外,還有其他技術可用于需要更高的內存帶寬來實現更高性能的工作負載。最著名的技術是 GDDR(圖形 DDR:Graphics DDR )和 HBM(高帶寬內存:High Bandwidth Memory)。它們不僅可用于高端圖形處理、高性能計算(如氣候建模、分子動力學和物理模擬),還可用于自動駕駛,當然還有人工智能/ML。由于此類應用需要快速移動大量數據,因此它們自然而然地適用于這些領域。
GDDR 主要是為圖形設計的,如今幾乎所有高性能顯卡都使用它。雖然 GDDR 與 DDR 有一些共同特點,但也有很大不同。DRAM DDR 是為更低的延遲而設計的,而 GDDR 則是為更高的帶寬而設計的,因為它與處理器芯片本身位于同一封裝內。與 DDR 相似,GDDR 接口每個時鐘周期傳輸兩個 32 位字(共 64 位)。最新的 GDDR6X 標準可實現高達 168 GB/s 的帶寬,工作頻率相對較低,為 656 MHz。
HBM 是一種新型 CPU/GPU 內存,垂直堆疊內存芯片,也稱為 3D 堆疊。與 GDDR 相似,HBM 大幅縮短了數據到達處理器的距離。與 DDR 和 GDDR 的主要區(qū)別在于,HBM 內存總線非常寬: 每個 HBM 堆棧為 1024 位。這使得 HBM 能夠實現超高帶寬。最新的 HBM3 標準支持每個封裝高達 665 GB/s 的帶寬。它的工作頻率低至 500 MHz,每個封裝的內存密度高達 48 GB。
如果想最大限度地提高數據傳輸吞吐量,板載 HBM 的系統將是一個不錯的選擇。不過,在撰寫本文時,這項技術的價格還相當昂貴。
由于 GDDR 主要用于顯卡,HBM 可能是加速 CPU 上運行的某些工作負載的不錯選擇。事實上,第一款集成了 HBM 的 x86 通用服務器芯片現已面世。
3.7 虛擬內存
虛擬內存是與 CPU 上執(zhí)行的所有進程共享物理內存的機制。虛擬內存提供一種保護機制,防止其他進程訪問分配給特定進程的內存。虛擬內存還提供重定位功能,即在不改變程序地址的情況下,將程序加載到物理內存中的任意位置。在支持虛擬內存的 CPU 中,程序使用虛擬地址進行訪問。但是,雖然用戶代碼在虛擬地址上運行,但從內存中檢索數據卻需要物理地址。此外,為了有效管理稀缺的物理內存,內存被劃分為多個頁。因此,應用程序在操作系統提供的一組頁面上運行。

訪問數據和代碼(指令)都需要進行虛擬地址到物理地址的轉換。頁面大小為 4KB 的系統的轉換機制如上圖。虛擬地址分為兩部分。虛擬頁碼(52 個最有效位)用于索引頁表,以生成虛擬頁碼與相應物理頁之間的映射。12 個最小有效位用于在 4KB 頁面內進行偏移。這些位無需轉換,可 “按原樣 ”訪問物理內存位置。
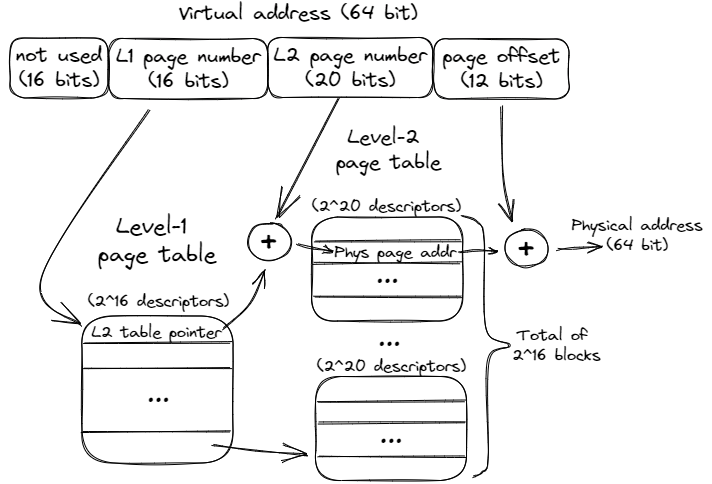
頁表可以是單層的,也可以是嵌套的。上圖顯示了雙層頁表的一個示例。請注意地址是如何被分割成更多塊的。首先要提到的是,16 個最重要位沒有被使用。這看起來像是在浪費位數,但即使使用剩余的 48 位,我們也能尋址 256 TB 的總內存(248)。有些應用程序會使用這些未使用的位來保存元數據,也就是所謂的指針標記。
嵌套頁表是一棵保留物理頁地址和一些元數據的弧度樹。要在 2 級頁表中查找轉換,我們首先使用第 32...47 位作為第 1 級頁表(也稱為頁表目錄)的索引。目錄中的每個描述符都指向 216 個二級頁表塊中的一個。找到相應的 L2 塊后,我們使用第 12...31 位查找物理頁面地址。
將其與頁面偏移量(第 0...11 位)連接,就得到了物理地址,可用來從 DRAM 中檢索數據。
頁表的具體格式由 CPU 決定,原因我們將在后面幾段討論。因此,頁表組織的變化受到 CPU 支持的限制。現代 CPU 既支持 48 位指針的 4 級頁表(總內存容量為 256 TB),也支持 57 位指針的 5 級頁表(總內存容量為 128 PB)。
將頁表分成多級并不會改變可尋址內存的總量。不過,嵌套方法不需要將整個頁表存儲為連續(xù)數組,也不會分配沒有描述符的塊。這樣可以節(jié)省內存空間,但會增加遍歷頁表時的開銷。
無法提供物理地址映射稱為頁面故障。如果請求的頁面無效或當前不在主內存中,就會發(fā)生這種故障。兩種最常見的原因是 1) 操作系統承諾分配一個頁面,但尚未用一個物理頁面來支持它,以及 2) 訪問的頁面已被交換到磁盤,當前未存儲在 RAM 中。
3.7.1 轉換后備緩沖器(TLB Translation Lookaside Buffer)
在分層頁表中進行搜索的代價可能很高,因為需要遍歷分層結構,可能要進行多次間接 訪問。這種遍歷稱為走頁。為了減少地址轉換時間,CPU 支持一種稱為轉換查找緩沖區(qū)(TLB)的硬件結構,用于緩存最近使用的轉換。與普通緩存類似,TLB 通常設計為 L1 ITLB(指令)和 L1 DTLB(數據)的層次結構,然后是共享(指令和數據)的 L2 STLB。
為了降低內存訪問延遲,L1 高速緩存的查找可以與 DTLB 的查找部分重疊,這要歸功于對高速緩存關聯性和大小的限制,它允許在沒有物理地址的情況下選擇 L1 集。然而,更高層次的高速緩存(L2 和 L3)通常也是物理索引和物理標記(PIPT)高速緩存,但無法受益于這種優(yōu)化,因此需要在高速緩存查找之前進行地址轉換。
TLB 層次結構保留了相對較大內存空間的轉換。盡管如此,TLB 的未命中代價仍然非常高昂。為了加快 TLB 未命中的處理速度,CPU 有一種稱為硬件走頁器的機制。硬件走頁器可以直接在硬件中執(zhí)行走頁操作,發(fā)出所需的指令來遍歷頁表,而不會中斷內核。這就是為什么頁表的格式由 CPU 規(guī)定,操作系統必須遵守的原因。高端處理器擁有多個硬件走頁器,可以同時處理多個 TLB 未命中。然而,即使現代 CPU 提供了所有加速功能,TLB 錯失仍會對許多應用程序造成性能瓶頸。
3.7.2 超大頁面 (Huge Pages)
較小的頁面大小可以更有效地管理可用內存并減少碎片。但缺點是需要更多的頁表項來覆蓋相同的內存區(qū)域。考慮兩種頁面大小:
4KB(x86 默認值)和 2MB 的超大頁面大小。對于操作 10MB 數據的應用程序來說,第一種情況下需要 2560 個條目,而如果將地址空間映射到超大頁上,則只需要 5 個條目。這些頁面在 Linux 中被命名為 “巨大頁面”,在 FreeBSD 中被命名為 “超級頁面”,在 Windows 中被命名為 “大型頁面”,但它們的含義是一樣的。在本書的其余部分,我們將把它們稱為巨型頁。
下圖顯示了一個指向巨頁面中數據的地址示例。就像默認頁面大小一樣,使用超大頁面時的確切地址格式是由硬件決定的,但幸運的是,作為程序員,我們通常不必擔心這個問題。

由于需要的 TLB 條目較少,使用超大頁面大大減輕了對 TLB 層次結構的壓力。這大大增加了 TLB 命中的機會。我們將在第 8.4 節(jié)和第 11.8 節(jié)討論如何使用超大頁面來降低 TLB 錯失的頻率。使用超大頁面的缺點是內存碎片,在某些情況下還會導致不確定的頁面分配延遲,因為操作系統更難管理大內存塊并確保有效利用可用內存。要在運行時滿足 2MB 的超大頁面分配請求,操作系統需要找到 2MB 的連續(xù)塊。如果找不到,操作系統就需要重新組織頁面,從而導致更長的分配延遲。
3.8 現代 CPU 設計
為了了解本章所講的所有概念在實踐中的應用,讓我們來看看英特爾于 2021 年推出的第 12 代內核 Golden Cove 的實現。該內核在 Alder Lake 和 Sapphire Rapids 平臺中用作 P 核心。下圖顯示了 Golden Cove 內核的框圖。請注意,本節(jié)只介紹單個內核,而不是整個處理器。因此,我們將跳過有關頻率、內核數、L3 高速緩存、內核互連、內存延遲和帶寬的討論。
該內核分為一個將 x86 指令獲取并解碼為 μops的順序內前端和一個 6 寬超標量順序外后端。Golden Cove 內核支持雙向 SMT。它有一個 32KB 的一級指令高速緩存(L1 I-高速緩存)和一個 48KB 的一級數據高速緩存(L1 D-高速緩存)。L1 緩存由統一的 1.25MB(服務器芯片為 2MB)L2 緩存提供支持。L1 和 L2 高速緩存對每個內核都是私有的。在本節(jié)末尾,我們還將介紹 TLB 層次結構。
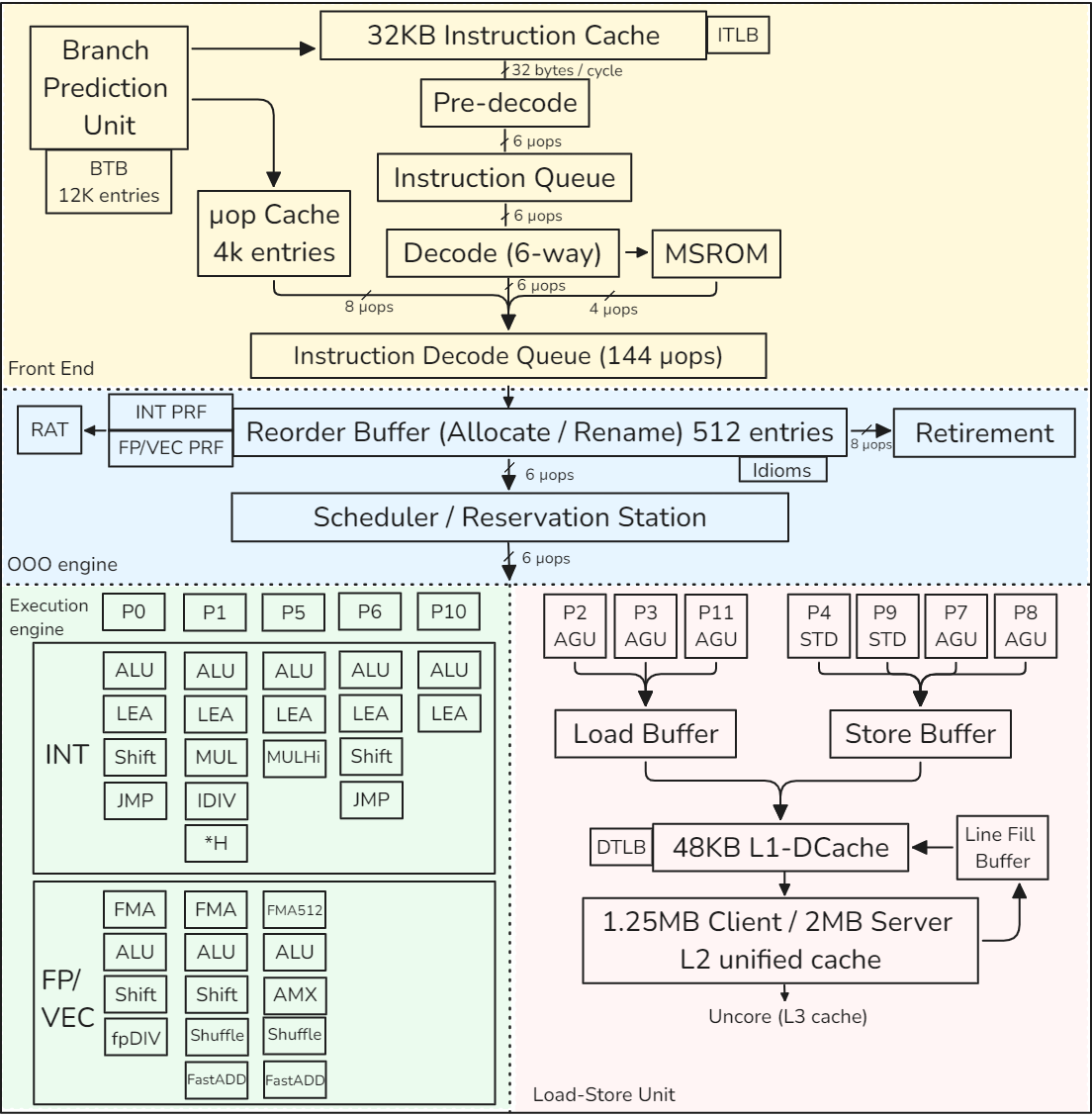
3.8.1 CPU 前端
CPU 前端由多個功能單元組成,負責從內存中獲取和解碼指令。它的主要目的是將準備好的指令送入負責實際執(zhí)行指令的 CPU 后端。
從技術上講,指令獲取是執(zhí)行指令的第一階段。但一旦程序達到穩(wěn)定狀態(tài),分支預測器單元(BPU)就會引導 CPU 前端的工作。箭頭從分支預測單元(BPU)指向指令緩存,這表明BPU預測所有分支指令的目標,并根據這個預測來控制下一步的指令獲取。
BPU 的核心是一個分支目標緩沖區(qū) (BTB),它有 12K 個條目,包含有關分支及其目標的信息。預測算法使用這些信息。每個周期,BPU 都會生成下一個取回地址,并將其傳遞給 CPU 前端。
CPU 前端每個周期從 L1 I 緩存中獲取 32 字節(jié)的 x86 指令。如果啟用 SMT,則由兩個線程共享,因此每個線程每隔一個周期獲取 32 個字節(jié)。這些都是復雜、長度可變的 x86 指令。首先,預解碼階段通過檢查塊來確定和標記可變指令的邊界。在 x86 中,指令長度范圍為 1 至 15 字節(jié)。這一階段還能識別分支指令。預解碼階段將最多 6 條指令(也稱為宏指令)移至指令隊列,該隊列由兩個線程分割。指令隊列還支持宏操作融合單元,可檢測兩個宏指令何時可融合為一個微操作(μop)。這種優(yōu)化可節(jié)省流水線其他部分的帶寬。
之后,每個周期最多有六條預解碼指令從指令隊列發(fā)送到解碼器單元。兩個 SMT 線程在每個周期交替訪問該接口。6 路解碼器將復雜的宏操作步驟轉換為固定長度的 μ 操作步驟。解碼后的 μops 排入指令解碼隊列 (IDQ Instruction Decode Queue),圖中標為 “μop 隊列”。
前端的一個主要性能提升功能是 μop 緩存。此外,人們還經常稱其為解碼流緩沖區(qū)(DSB Decoded Stream Buffer)。其目的是將宏操作數到 μops 的轉換緩存在一個獨立的結構中,該結構與 L1 I 緩存并行工作。當 BPU 生成要獲取的新地址時,也會檢查 μop 緩存,查看 μops 轉換是否可用。經常出現的宏操作將進入 μop Cache,流水線將避免重復昂貴的 32 字節(jié)捆綁預解碼和解碼操作。μop Cache 每個周期可提供 8 個 μ操作,最多可容納 4K 條目。
某些非常復雜的指令所需的 μops 可能超過解碼器的處理能力。此類指令的 μops 由微碼序列器 (MSROM Microcode Sequencer) 提供。這類指令的例子包括字符串操作、加密、同步等硬件操作支持。此外,MSROM 還保留了微代碼操作,以處理特殊情況,如分支錯誤預測(需要刷新流水線)、浮點輔助(例如,當指令使用去規(guī)范化浮點值操作時)等。MSROM 每個周期可向 IDQ 推送多達 4 μops 的指令。
指令解碼隊列(IDQ)提供了序內前端與序外后端之間的接口。IDQ 按順序排列 μops,在單線程模式下,每個邏輯處理器可容納 144 μops,在 SMT 激活時,每個線程可容納 72 μops。此時,按順序排列的 CPU 前端結束,按順序排列的 CPU 后端開始。
3.8.2 CPU 后端
CPU 后端采用一個 OOO 引擎來執(zhí)行指令和存儲結果。我在下圖中重復了描述 Golden Cove OOO 引擎的部分示意圖。
OOO 引擎的核心是 512 條目重排序緩沖區(qū)(ROB)。它有幾個作用。雖然只有 16 個通用整數寄存器和 32 個浮點/SIMD 結構寄存器,但物理寄存器的數量要多得多。整數寄存器和浮點/SIMD 寄存器有不同的 PRF。從架構可見寄存器到物理寄存器的映射關系保存在寄存器別名表(RAT)中。

其次,ROB 分配執(zhí)行資源。當指令進入 ROB 時,會分配一個新的條目,并為其分配資源,主要是執(zhí)行單元和目標物理寄存器。ROB 每個周期最多可分配 6 μops。
第三,ROB 跟蹤推測執(zhí)行。當一條指令執(zhí)行完畢后,其狀態(tài)會被更新,并一直保持到前一條指令執(zhí)行完畢。這樣做是因為指令必須按程序順序退出。一旦指令退出,其 ROB 條目就會被重新分配,指令的執(zhí)行結果也會變得可見。退行階段比分配階段更寬泛:ROB 每個周期可退行 8 條指令。
處理器會以特定方式處理某些操作,這些操作通常被稱為慣用法,無需執(zhí)行或執(zhí)行成本較低。處理器能識別這種情況,并允許它們比常規(guī)指令運行得更快。下面是其中的一些情況:
- 清零:為了給寄存器賦零,編譯器通常使用 XOR / PXOR / XORPS / XORPD 指令,例如 XOR EAX, EAX,編譯器傾向于使用這些指令,而不是等價的 MOV EAX, 0x0 指令,因為 XOR 編碼使用的編碼字節(jié)數更少。這種歸零慣用法不會像其他常規(guī)指令一樣執(zhí)行,而是在 CPU 前端解決,從而節(jié)省了執(zhí)行資源。
之后,該指令照常退出。 - 移動消除:與前一條指令類似,寄存器到寄存器的 mov 操作(如 MOV EAX、EBX)的執(zhí)行周期延遲為零。
- NOP 指令: NOP 通常用于填充或對齊目的。它只是被標記為已完成,而不分配給保留站。
- 其他旁路 CPU 架構師還優(yōu)化了某些算術運算。例如,任何數字乘以 1,結果總是相同的。任何數字除以 1 也是如此。任何數字乘以零,結果總是零,等等。有些 CPU 可以在運行時識別這種情況,并以比普通乘法或除法更短的延遲執(zhí)行它們。
調度器/預訂站"(RS)是一種結構,用于跟蹤給定 μop 的所有資源可用性,并在 μop 準備就緒后將其分派到執(zhí)行端口。執(zhí)行端口是連接調度器和執(zhí)行單元的通道。每個執(zhí)行端口可連接多個執(zhí)行單元。當指令進入 RS 時,調度器開始跟蹤其數據依賴關系。一旦所有源操作數都可用,RS 就會嘗試將 μop 發(fā)送到空閑的執(zhí)行端口。RS 的條目數55 比 ROB 少。每個周期最多可調度 6 個 μ操作。人們測得 RS 中的條目數約為 200 個,但實際條目數并未公布。
共有 12 個執(zhí)行端口:
- 端口 0、1、5、6 和 10 提供整數 (INT) 運算,其中一些端口處理浮點和矢量 (FP/VEC) 運算。
- 端口 2、3 和 11 用于地址生成 (AGU) 和加載操作。
- 端口 4 和 9 用于存儲操作 (STD)。
- 端口 7 和 8 用于地址生成。
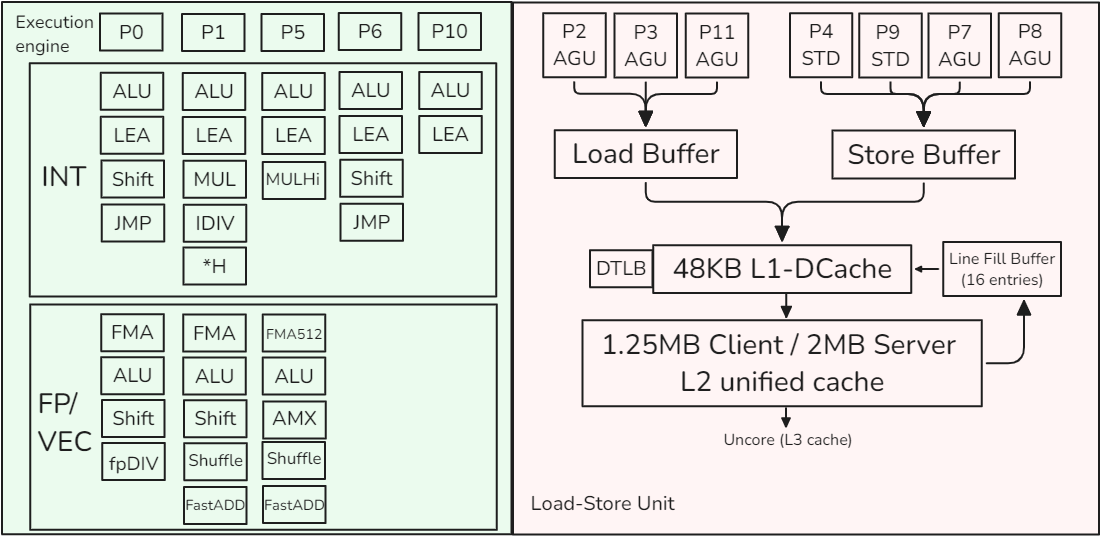
需要內存操作的指令由加載-存儲單元(端口 2、3、11、4、9、7 和 8)處理,我們將在下一節(jié)討論。如果操作不涉及加載或存儲數據,則會被分派到執(zhí)行引擎(端口 0、1、5、6 和 10)。某些指令可能需要在不同的執(zhí)行端口執(zhí)行兩個 μops,如加載和加法。
例如,整數移位操作只能被分派到端口 0 或 6,而浮點除法操作只能被分派到端口 0。 當調度程序必須分派兩個需要相同執(zhí)行端口的操作時,其中一個操作將被延遲。
FP/VEC 堆棧可執(zhí)行浮點標量和所有打包(SIMD)操作。
例如,端口 0、1 和 5 可以處理以下類型的 ALU 操作:
打包整數、打包浮點和浮點標量。整數寄存器文件和矢量/浮點寄存器文件分開存放。將數值從 INT 堆棧移至 FP/VEC 或反向移至 FP/VEC 的操作(如轉換、提取或插入)會產生額外的處罰。
3.8.3 加載-存儲單元(Load-Store Unit)
加載-存儲單元 (LSU) 負責內存操作。通過使用端口 2、3 和 11,Golden Cove 內核最多可發(fā)出三個負載(三個 256 位或兩個 512 位)。AGU 是地址生成單元的縮寫,用于訪問 68 位內存位置。
3.8 現代 CPU 設計 它還可以通過端口 4、9、7 和 8 在每個周期內發(fā)出最多兩個存儲(兩個 256 位或一個 512 位)。STD 表示存儲數據。
請注意,加載和存儲操作都需要 AGU 來執(zhí)行動態(tài)地址計算。例如,在指令 vmovss DWORD PTR [rsi+0x4],xmm0 中,AGU 將負責計算 rsi+0x4,用于存儲 xmm0 的數據。
一旦加載或存儲離開調度程序,LSU 將負責訪問數據。加載操作將獲取的值保存在寄存器中。存儲操作將寄存器中的值傳輸到內存中的某個位置。LSU 有一個加載緩沖區(qū)(又稱加載隊列)和一個存儲緩沖區(qū)(又稱存儲隊列);它們的大小未公開。
當出現內存加載請求時,LSU 會使用虛擬地址查詢 L1 緩存,并在 TLB 中查找物理地址轉換。這兩個操作同時啟動。L1 D 緩存的大小為 48KB。如果這兩個操作都命中,則加載將數據傳送到整數或浮點寄存器,并離開加載緩沖區(qū)。同樣,存儲會將數據寫入數據高速緩存,并退出存儲緩沖區(qū)。
在 L1 未命中的情況下,硬件會啟動對(私有)L2 緩存標簽的查詢。
在查詢 L2 緩存時,會分配一個 64 字節(jié)寬的填充緩沖區(qū) (FB) 條目,一旦緩存行到達,該條目將保留緩存行。Golden Cove 內核有 16 個填充緩沖區(qū)。
為了降低延遲,在進行二級緩存查詢的同時,會向三級緩存發(fā)送推測查詢。此外,如果兩個負載訪問同一緩存行,它們將撞擊同一個 FB。這兩個負載將被 “粘合 ”在一起,只啟動一個內存請求。
如果 L2 缺失得到確認,負載將繼續(xù)等待 L3 緩存的結果,這將產生更高的延遲。從這時起,請求將離開內核,進入非內核(這是有時在剖析工具中看到的術語)。超級隊列(Super Queue,圖中未顯示)會跟蹤來自內核的未處理未命中請求,最多可跟蹤 48 個非內核請求。在 L3 未命中的情況下,處理器開始設置內存訪問。更多細節(jié)不在本章討論范圍之內。
當存儲修改內存位置時,處理器需要加載完整的高速緩存行,修改后再寫回內存。如果要寫入的地址不在高速緩存中,則需要通過與加載非常相似的機制將數據引入。
在數據寫入高速緩存層次結構之前,存儲無法完成。
當然,存儲操作也有一些優(yōu)化。首先,如果我們處理的是一個或多個相鄰的存儲(也稱為流存儲)
首先,如果我們要處理的是一個或多個相鄰的存儲空間(也稱為流存儲空間),這些存儲空間會修改整個緩存行,那么就沒有必要先讀取數據,因為所有的字節(jié)都會被刪除。因此,處理器會嘗試合并寫入,以填滿整個緩存行。如果成功,則無需進行內存讀取操作。
其次,寫入組合可以將多個存儲組合在一起并進一步寫入。
在緩存層次結構中作為一個單元輸出。因此,如果多個存儲修改了同一緩存行,則只需向內存子系統發(fā)出一次內存寫入。所有這些優(yōu)化都是在存儲緩沖區(qū)內完成的。存儲指令將從寄存器寫入的數據復制到存儲緩沖區(qū)。從那里,數據可能被寫入 L1 緩存,也可能與其他存儲一起寫入同一緩存行。存儲緩沖區(qū)的容量是有限的,因此它只能將部分寫入高速緩存行的請求保留一段時間。不過,當數據在存儲緩沖區(qū)等待寫入時,其他加載指令可以直接從存儲緩沖區(qū)讀取數據(存儲到加載轉發(fā))。此外,當有一個較舊的存儲區(qū)包含所有加載字節(jié),且存儲區(qū)的數據已經生成并可在存儲隊列中使用時,LSU 也支持存儲到加載轉發(fā)。
最后,在某些情況下,我們可以通過使用所謂的非時態(tài)內存訪問來提高高速緩存的利用率。如果我們執(zhí)行部分存儲(例如,覆蓋緩存行中的 8 個字節(jié)),我們需要先讀取緩存行。新的高速緩存行將取代高速緩存中的另一行。但是,如果我們知道我們不會再需要這些數據,那么最好不要在緩存中為該行分配空間。非時態(tài)內存訪問是一種特殊的 CPU 指令,它不會將獲取的行保留在高速緩存中,而是在使用后立即將其刪除。
在一個典型的程序執(zhí)行過程中,可能會有數十次內存訪問。
在大多數高性能處理器中,加載和存儲操作的順序并不一定要求與程序順序一致,這就是所謂的弱有序內存模型。出于優(yōu)化目的,處理器可以對內存讀寫操作重新排序。考慮這樣一種情況:當一次加載遇到緩存缺失時,必須等待數據從內存中讀出。處理器允許后續(xù)負載在等待數據的負載之前進行。這樣,后面的加載可以在前面的加載之前完成,而不會不必要地阻塞執(zhí)行。這種加載/存儲重新排序使內存單元能夠并行處理多個內存訪問,從而直接轉化為更高的性能。
LSU 動態(tài)重新排列操作順序,既支持繞過舊負載的負載,也支持繞過舊的非沖突存儲的負載。不過,也有一些例外情況。
就像通過常規(guī)算術指令產生的依賴關系一樣,通過加載和存儲也會產生內存依賴關系。換句話說,加載可以依賴于較早的存儲,反之亦然。首先,存儲不能與較早的加載一起重新排序:
加載 R1、MEM_LOC_X 存儲 MEM_LOC_X、0 如果我們允許存儲先于加載,那么 R1 寄存器可能會從內存位置 MEM_LOC_X 讀取錯誤的值。
另一種有趣的情況是,加載時會消耗先前存儲的數據:
存儲 MEM_LOC,0 加載 R1,MEM_LOC 如果加載消耗了尚未完成存儲的數據,我們就不應該允許繼續(xù)加載。但如果我們還不知道存儲空間的地址呢?在這種情況下,處理器會預測加載和存儲之間是否會有任何潛在的數據轉發(fā),以及重新排序是否安全。這就是所謂的內存設計歧義。當負載開始執(zhí)行時,必須對照所有舊存儲檢查是否存在潛在的存儲轉發(fā)。有四種可能的情況:
- 預測: 不依賴;結果: 不依賴。這是一個成功的內存消歧案例,能產生最佳性能。
- 預測: 依賴;結果:不依賴。在這種情況下,處理器過于保守,沒有讓負載先于存儲。這是一次錯失的性能優(yōu)化機會。
- 預測: 不依賴;結果:依賴。這是內存順序違規(guī)。與分支預測錯誤的情況類似,處理器必須清空流水線,回滾執(zhí)行,然后重新開始。代價非常高昂。
- 預測: 依賴;結果: 依賴。加載和存儲之間存在內存依賴關系,處理器預測正確。不會錯失良機。
值得一提的是,從存儲到加載的轉發(fā)在實際代碼中經常出現。尤其是任何使用讀修改寫訪問其數據結構的代碼,都有可能引發(fā)此類問題。由于存在較大的失序窗口,CPU 很容易嘗試同時處理多個讀取-修改-寫入序列,因此一個序列的讀取可能會在前一個序列的寫入完成之前發(fā)生。第 12.2 節(jié)將介紹一個這樣的例子。
3.8.4 TLB 層次結構
回顧第 3.7.1 節(jié),虛擬地址到物理地址的轉換緩存在 TLB 中。Golden Cove 的 TLB 層次結構如下圖所示。與普通數據緩存類似,它有兩個層次,其中第 1 層有單獨的指令實例(ITLB)和數據實例(DTLB)。L1 ITLB 有 256 個條目,用于常規(guī) 4K 頁面,覆蓋 1MB 內存,而 L1 DTLB 有 96 個條目,覆蓋 384 KB 內存。
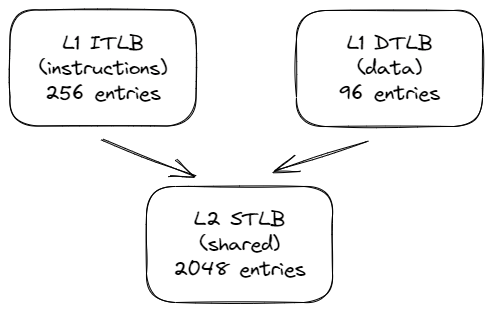
層次結構的第二級(STLB)緩存指令和數據的轉換。它是一個更大的存儲空間,用于處理在 L1 TLB 中錯過的請求。L2 STLB 可容納 2048 個最近的數據和指令頁地址轉換,總共覆蓋 8MB 內存空間。2MB 巨大頁面的可用條目較少: L1 ITLB 有 32 個條目,L1 DTLB 有 32 個條目,而 L2 STLB 只能使用 1024 個條目,這些條目也與普通 4KB 頁面共享。
如果在 TLB 層次結構中找不到翻譯,就必須通過 “走讀 ”內核頁表從 DRAM 中檢索。回想一下,頁表是以子表的弧度樹形式構建的,子表的每個條目都包含指向下一級樹的指針。
加速走頁過程的關鍵因素是一組分頁結構緩存(Paging-Structure Caches,AMD:Page Walk Caches) ,它緩存了頁表結構中的熱點條目。對于 4 級頁表,我們使用最小有效的 12 位(11:0)來表示頁偏移量(未翻譯),47:12 位表示頁碼。TLB 中的每個條目都是一個單獨的完整翻譯,而分頁結構緩存只覆蓋上面 3 層(第 47:21 位)。這樣做的目的是減少 TLB 未命中時需要執(zhí)行的加載次數。例如,如果沒有這種緩存,我們就必須執(zhí)行 4 次加載,這會增加指令完成的延遲。但在分頁結構緩存的幫助下,如果我們找到了地址第 1 層和第 2 層(第 47:30 位)的轉換,我們只需執(zhí)行剩余的 2 次加載。
Golden Cove 微體系結構有 4 個專用走頁器,可同時處理 4 個走頁。在 TLB 未命中的情況下,這些硬件單元將向內存子系統發(fā)出所需的加載,并用新條目填充 TLB 層次結構。走頁器生成的頁表加載可以進入 L1、L2 或 L3 高速緩存(細節(jié)未披露)。最后,走頁器可以預測未來的 TLB 未命中,并在未命中實際發(fā)生之前進行推測性走頁以更新 TLB 條目。
Golden Cove 規(guī)范未披露兩個 SMT 線程如何共享資源。但一般來說,緩存、TLB 和執(zhí)行單元是完全共享的,以提高這些資源的動態(tài)利用率。另一方面,用于在主要管道級之間分期執(zhí)行指令的緩沖區(qū)要么是復制的,要么是分區(qū)的。
這些緩沖區(qū)包括 IDQ、ROB、RAT、RS、加載緩沖區(qū)和存儲緩沖區(qū)。PRF 也是復制的。
參考資料
- 軟件測試精品書籍文檔下載持續(xù)更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發(fā)庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 http://www.rzrgm.cn/testing-/p/17438558.html
3.9 性能監(jiān)控單元(Performance Monitoring Unit)
每個現代 CPU 都提供監(jiān)控性能的功能,這些功能被整合到性能監(jiān)控單元 (PMU) 中。該單元包含的功能可幫助開發(fā)人員分析應用程序的性能。下圖是現代英特爾 CPU 中 PMU 的示例。大多數現代 PMU 都有一組性能監(jiān)控計數器 (PMC),可用于收集程序執(zhí)行過程中發(fā)生的各種性能事件。稍后在第 5.3 節(jié)中,我們將討論如何利用 PMC 進行性能分析。此外,PMU 還有其他增強性能分析的功能,如 LBR、PEBS 和 PT,第 6 章將專門討論這些主題。
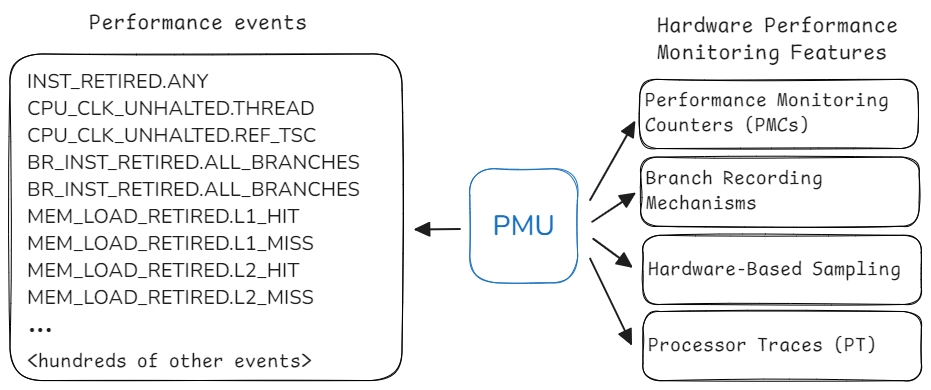
隨著 CPU 設計的更新換代,其 PMU 也在不斷發(fā)展。在 Linux 系統中,可以使用 cpuid 命令確定 CPU 中 PMU 的版本。通過檢查 dmesg 命令的輸出,也可以從內核信息緩沖區(qū)中提取類似信息。各英特爾 PMU 版本以及與前一版本相比的變化可參見 Intel, 2023, Volume 3B, Chapter 20。
...
Physical Address and Linear Address Size (0x80000008/eax):
maximum physical address bits = 0x27 (39)
maximum linear (virtual) address bits = 0x30 (48)
maximum guest physical address bits = 0x0 (0)
Extended Feature Extensions ID (0x80000008/ebx):
CLZERO instruction = false
instructions retired count support = false
always save/restore error pointers = false
INVLPGB instruction = false
RDPRU instruction = false
memory bandwidth enforcement = false
MCOMMIT instruction = false
...
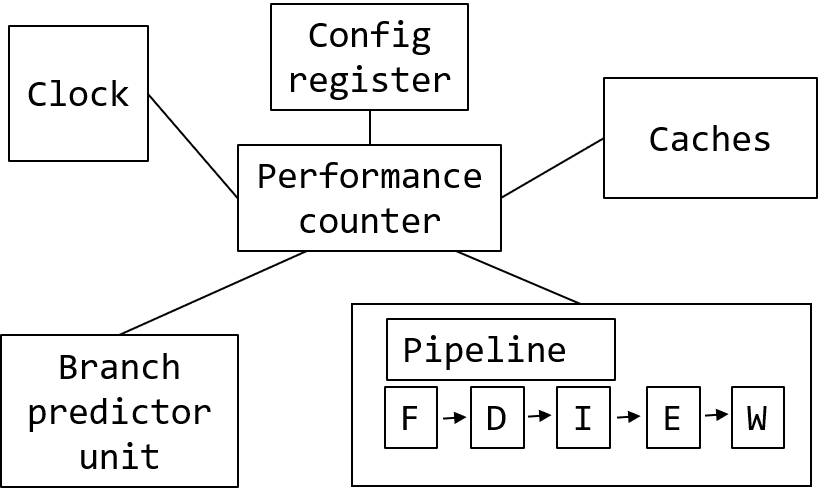
3.9.1 性能監(jiān)控計數器
如果我們想象一個簡化的處理器視圖,它可能與下圖相似。正如我們在本章前面所討論的,現代 CPU 有緩存、分支預測器、執(zhí)行流水線和其他單元。當連接到多個單元時,PMC 可以從中收集有趣的統計數據。例如,它可以計算時鐘周期的時間、執(zhí)行的指令數量、期間發(fā)生的緩存未命中或分支預測錯誤數量,以及其他性能事件。
PMC 通常為 48 位寬,這使得分析工具可以在不中斷程序執(zhí)行的情況下長時間運行。性能計數器是作為特定型號寄存器(MSR Model-Specific Register)實現的硬件寄存器,這意味著計數器的數量和寬度可能因型號而異,因此不能依賴 CPU 中相同的計數器數量。您應首先使用 cpuid 等工具進行查詢。PMC 可通過 RDMSR 和 WRMSR 指令訪問,這些計數器只能在內核空間執(zhí)行。幸運的是,只有當你是性能分析工具(如 Linux perf 或 Intel VTune profiler)的開發(fā)人員時,才需要關心這個問題。這些工具能處理 PMC 編程的所有復雜問題。
工程師在分析應用程序時,通常會收集執(zhí)行指令數和周期數。這就是某些 PMU 具有專用 PMC 來收集此類事件的原因。固定計數器總是測量 CPU 內核中的相同內容。對于可編程計數器,用戶可以自行選擇要測量的內容。
例如,在英特爾 Skylake 架構(PMU 版本 4,見清單 3.3)中,每個物理內核都有三個固定計數器和八個可編程計數器。三個固定計數器用于計算內核時鐘、參考時鐘和退役指令(有關這些指標的更多詳情,請參閱第 4 章)。AMD Zen4 和 Arm Neoverse V1 內核支持每個處理器內核 6 個可編程性能監(jiān)控計數器,沒有固定計數器。
PMU 提供 100 多個可供監(jiān)控的事件并不罕見。上上圖顯示的只是現代英特爾 CPU 上可用于監(jiān)控的性能監(jiān)控事件的一小部分。不難發(fā)現,可用 PMC 的數量遠遠少于性能事件的數量。要同時統計所有事件是不可能的,但分析工具可以通過在程序執(zhí)行過程中復用各組性能事件來解決這個問題(參見第 5.3.1 節(jié))。
- 對于英特爾 CPU,完整的性能事件列表可參見 Intel, 2023, Volume 3B, Chapter 20或 perfmon-events.intel.com 網站。
- AMD 沒有公布每款 AMD 處理器的性能監(jiān)控事件列表。好奇的讀者可以在 Linux perf 源代碼中找到一些信息。此外,您還可以使用 AMD uProf 命令行工具列出可供監(jiān)控的性能事件。有關 AMD 性能計數器的一般信息,請參閱 AMD, 2023, 13.2 性能監(jiān)控計數器。
- 對于 ARM 芯片,性能事件的定義并不明確。供應商核心采用 ARM 架構,但性能事件的含義和支持的事件各不相同。對于 Arm 自己設計的 Arm Neoverse V1 內核,性能事件列表可在 Arm, 2022b 中找到。對于 Arm Neoverse V2 和 V3 微體系結構,性能事件列表可在 Arm 網站上找到。
3.10 問題與練習
- 描述流水線、失序和投機執(zhí)行。
- 寄存器重命名如何幫助加快執(zhí)行速度?
- 描述空間和時間定位。
- 在大多數現代處理器中,高速緩存行的大小是多少?
- 說出構成 CPU 前端和后端的組件。
- 4 級頁表的組織結構是怎樣的?什么是頁面故障?
- x86 和 ARM 體系結構的默認頁面大小是多少?
- TLB(轉換旁路緩沖區(qū))起什么作用?
3.11 本章小結
- 指令集體系結構(ISA)是軟件和硬件之間的基本契約。ISA 是計算機的一個抽象模型,它定義了一系列可用的操作和數據類型、一組寄存器、內存尋址等。你可以用多種不同的方式實現特定的 ISA。例如,你可以設計一個優(yōu)先考慮節(jié)能的 “小 ”內核,也可以設計一個以高性能為目標的 “大 ”內核。
- CPU 的 “微體系結構 ”概括了實現的細節(jié)。長期以來,成千上萬的計算機科學家一直在研究這一課題。多年來,許多聰明的想法被發(fā)明出來,并在大眾市場的 CPU 中得以實現。其中最著名的有流水線、亂序執(zhí)行、超標量引擎、預測執(zhí)行和 SIMD 處理器。所有這些技術都有助于利用指令級并行性(ILP),提高單線程性能。
- 在提高單線程性能的同時,硬件設計人員也開始推動多線程性能的發(fā)展。絕大多數面向客戶端的現代設備都配備了包含多個內核的處理器。在同時多線程技術(SMT)的幫助下,一些處理器將可觀察到的 CPU 內核數量增加了一倍。SMT 可讓多個軟件線程利用共享資源在同一物理內核上同時運行。這一方向上的最新技術被稱為 “混合 ”處理器,它將不同類型的內核整合在一個封裝中,以更好地支持各種工作負載。
- 現代計算機的內存層次結構包括多個級別的高速緩存,它們反映了訪問速度與大小的不同權衡。L1 高速緩存往往最靠近內核,速度快但體積小。L3/LLC 緩存速度較慢,但也較大。DDR 是大多數平臺使用的主要 DRAM 技術。DRAM 模塊的級數和內存寬度各不相同,可能會對系統性能產生輕微影響。處理器可能有多個內存通道,可同時訪問多個 DRAM 模塊。
- 虛擬內存是與 CPU 上運行的所有進程共享物理內存的機制。程序在訪問時使用虛擬地址,然后將其轉換為物理地址。內存空間被劃分為多個頁面。x86 默認頁大小為 4KB,ARM 默認頁大小為 16KB。只有頁地址會被翻譯,頁內的偏移量則按原樣使用。操作系統將翻譯保存在頁表中,頁表以弧度樹的形式實現。有一些硬件特性可以提高地址轉換的性能:主要是轉換后備緩沖器(TLB)和硬件走頁器。此外,在某些情況下,開發(fā)人員還可以利用大頁面來降低地址轉換的成本(參見第 8.4 節(jié))。
- 我們研究了英特爾最近推出的 Golden Cove 微體系結構的設計。從邏輯上講,內核分為前端和后端。前端由分支預測單元 (BPU)、L1 I 緩存、指令獲取和解碼邏輯以及向 CPU 后端饋送指令的 IDQ 組成。后端由 OOO 引擎、執(zhí)行單元、負載存儲單元、L1 D 緩存和 TLB 層次結構組成。
- 現代處理器的性能監(jiān)控功能封裝在性能監(jiān)控單元(PMU)中。該單元以性能監(jiān)控計數器(PMC)的概念為基礎,可以觀察程序運行時發(fā)生的特定事件,如緩存未命中和分支預測錯誤。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號