語義相似度模型在測試需求變更中的應(yīng)用
 語義相似度模型在測試需求變更場景中展現(xiàn)出巨大潛力,正在成為現(xiàn)代測試流程中“感知變更、判斷影響、優(yōu)化測試”的關(guān)鍵驅(qū)動因素。通過引入該技術(shù),企業(yè)能夠構(gòu)建更智能、更敏捷、更具洞察力的測試體系,為軟件質(zhì)量提供強有力的保障。
語義相似度模型在測試需求變更場景中展現(xiàn)出巨大潛力,正在成為現(xiàn)代測試流程中“感知變更、判斷影響、優(yōu)化測試”的關(guān)鍵驅(qū)動因素。通過引入該技術(shù),企業(yè)能夠構(gòu)建更智能、更敏捷、更具洞察力的測試體系,為軟件質(zhì)量提供強有力的保障。
?

在軟件開發(fā)的整個生命周期中,需求變更無處不在。特別是在敏捷與DevOps環(huán)境下,迭代頻繁、需求多變,給測試團隊帶來了巨大挑戰(zhàn):
-
如何第一時間感知需求的變化?
-
如何判斷變更影響哪些已有測試用例?
-
如何避免冗余測試與遺漏測試?
-
如何在變更中保持測試覆蓋與質(zhì)量?
傳統(tǒng)測試流程往往依賴人工比對、經(jīng)驗判斷,這在復(fù)雜項目中效率低、風(fēng)險高。而隨著自然語言處理(NLP)與深度學(xué)習(xí)的發(fā)展,語義相似度模型正日益成為應(yīng)對需求變更挑戰(zhàn)的關(guān)鍵利器。
本文將系統(tǒng)闡述語義相似度模型在測試需求變更中的核心應(yīng)用邏輯、技術(shù)路徑與落地實踐,幫助企業(yè)構(gòu)建更具韌性與智能感知能力的測試體系。
一、測試需求變更帶來的挑戰(zhàn)
1. 變更頻繁但粒度多樣
-
有的變更是術(shù)語調(diào)整、說明優(yōu)化;
-
有的是邏輯擴展、新功能添加;
-
更嚴(yán)重的如角色變更、邊界條件變化。
傳統(tǒng)處理方式:
-
以需求版本為維度手動比對 → 費時費力
-
依賴業(yè)務(wù)專家判斷變更影響 → 結(jié)果不一致
2. 測試用例響應(yīng)機制滯后
-
無法自動識別哪些用例受影響;
-
可能對未變化的部分重新測試,浪費資源;
-
也可能遺漏關(guān)鍵路徑,造成回歸風(fēng)險。
二、什么是語義相似度模型?
1. 基本定義
語義相似度模型旨在衡量兩個文本之間“語義上有多接近”,而非表面關(guān)鍵詞是否一致。
舉例:
A: 用戶登錄時應(yīng)驗證用戶名和密碼是否匹配。
B: 系統(tǒng)需校驗登錄憑據(jù)的有效性。盡管字面不同,但語義非常接近。傳統(tǒng)匹配方法難以判斷,而語義模型可以精準(zhǔn)捕捉到這種“深層相似性”。
2. 主流技術(shù)路線
| 模型類型 | 特點 |
|---|---|
| TF-IDF/詞袋模型 | 快速但僅捕捉詞級相似性,語義弱 |
| Word2Vec、GloVe | 詞向量級別的語義理解 |
| BERT、RoBERTa | 基于Transformer的預(yù)訓(xùn)練語言模型,句子級理解 |
| SimCSE、SBERT | 專門優(yōu)化句子相似度的模型,性能領(lǐng)先 |
| 中文語義模型 | 如Langboat, Chinese-BERT, C-BERT-wwm-ext,適用于中文測試場景 |
? 建議使用適合測試領(lǐng)域語料微調(diào)過的模型(如使用企業(yè)歷史需求-用例對數(shù)據(jù))
三、語義相似度模型在需求變更中的核心應(yīng)用場景
場景1:需求變更影響測試用例識別
輸入:新版需求項
目標(biāo):找出與之語義接近的舊測試用例 → 判斷是否需要更新/刪除/重寫
示例:
舊需求: “管理員可以通過后臺重置用戶密碼”
變更后: “管理員僅在用戶身份驗證通過后才能重置密碼”
模型輸出最相似用例(Top 5):
- 用例1:測試管理員如何在控制臺操作密碼重置(得分0.93)
用例2:測試用戶身份驗證模塊(得分0.88)
...
? 得分 > 0.85 的用例標(biāo)記為“可能受影響”,納入回歸驗證范圍。
場景2:輔助用例自動生成與對齊
新需求變更后,可基于高相似歷史需求-用例對,借助LLM模板+語義檢索快速生成草案。
語義模型檢索 → LLM生成用例草案 → 測試人員驗證修改
場景3:需求覆蓋追蹤中的智能對齊
測試覆蓋分析時,將測試用例與變更后的需求進行語義比對:
-
若覆蓋度下降,提示用例缺失;
-
若多用例高相似同一需求,提示合并優(yōu)化。
四、系統(tǒng)設(shè)計
1. 系統(tǒng)架構(gòu)圖
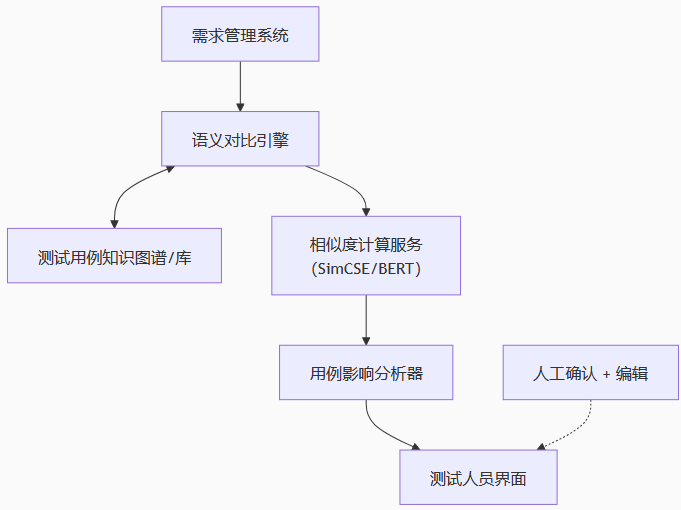
2. 核心模塊說明
| 模塊 | 功能 |
|---|---|
| 語義對比引擎 | 輸入新舊需求/用例,調(diào)用模型輸出相似度 |
| 相似度模型 | 支持句向量提取(SimCSE/BERT),支持fine-tune |
| 用例圖譜 | 結(jié)構(gòu)化存儲歷史用例、模塊歸屬、執(zhí)行記錄等 |
| 影響分析器 | 設(shè)定閾值判斷影響范圍,生成推薦清單 |
| 人機協(xié)同界面 | 展示Top-N相似用例,支持人工確認(rèn) |
五、實踐案例
技術(shù)選型
-
模型:
hfl/chinese-roberta-wwm-ext + SimCSE -
相似度計算庫:
SentenceTransformers -
后端服務(wù):
FastAPI -
圖譜庫:
Neo4j(存放用例關(guān)系)
示例代碼片段
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer('shibing624/text2vec-base-chinese')
def compute_similarity(query, candidates):
query_emb = model.encode(query, convert_to_tensor=True)
cand_emb = model.encode(candidates, convert_to_tensor=True)
scores = util.cos_sim(query_emb, cand_emb)
return scores
效果展示
| 新需求變更 | 最相似測試用例 | 相似度 |
|---|---|---|
| 登錄增加手機驗證碼驗證 | 測試登錄驗證碼輸入正確跳轉(zhuǎn)流程 | 0.92 |
| 文件上傳限制調(diào)整 | 測試上傳大小限制邏輯 | 0.89 |
結(jié)合評分閾值(如0.85),可生成“測試用例變更清單”供測試負(fù)責(zé)人審核。
六、優(yōu)勢與挑戰(zhàn)分析
優(yōu)勢
-
快速識別需求變更對測試的潛在影響
-
降低冗余回歸測試成本
-
保障變更后需求的測試覆蓋完整性
-
可與知識圖譜、RAG等技術(shù)協(xié)同增強智能度
面臨挑戰(zhàn)
-
中文測試語料有限,模型微調(diào)數(shù)據(jù)缺乏
-
不同項目術(shù)語不一致,需歸一化預(yù)處理
-
語義相似 ≠ 完全匹配,仍需人工參與
七、未來展望
-
構(gòu)建測試智能體,實時監(jiān)聽需求變化 → 自動判斷影響范圍 → 觸發(fā)用例推薦與執(zhí)行計劃調(diào)整
-
在CI/CD流程中集成語義感知模塊,實現(xiàn)測試資源動態(tài)調(diào)度
-
結(jié)合RAG和知識圖譜,提升“用例生成+變更響應(yīng)+缺陷定位”的自動化閉環(huán)能力
結(jié)語
語義相似度模型在測試需求變更場景中展現(xiàn)出巨大潛力,正在成為現(xiàn)代測試流程中“感知變更、判斷影響、優(yōu)化測試”的關(guān)鍵驅(qū)動因素。通過引入該技術(shù),企業(yè)能夠構(gòu)建更智能、更敏捷、更具洞察力的測試體系,為軟件質(zhì)量提供強有力的保障。
“讓測試不再被動響應(yīng)變更,而是主動感知、精準(zhǔn)應(yīng)對,這是智能測試的未來方向。”
?


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號