
python模塊3
一、 timeit
timeit 是 Python 標準庫中的一個函數,用于精確測量小段代碼的執行時間。它特別適合用于性能測試,能夠準確地計算出代碼塊的運行時間,并提供有關代碼執行效率的有價值信息。
# #1 測量一行代碼的執行時間
# import timeit
# execution_time = timeit.timeit('x = sum(range(100))', number=10000)
# print(f"Execution time: {execution_time} seconds")
# #2使用 timeit 測量代碼塊的執行時間:
# import timeit
# code_to_test = '''
# result = 0
# for i in range(1000):
# result += i
# '''
# execution_time = timeit.timeit(code_to_test, number=1000)
# print(f"Execution time: {execution_time} seconds")
# #3測量函數的執行時間:
# import timeit
# def test_function():
# return sum(range(100))
# execution_time = timeit.timeit(test_function, number=10000)
# print(f"Execution time: {execution_time} seconds")
二、jieba
jieba庫主要用于中文文本內容的分詞,通過pip intall jieba 來安裝
它有3種分詞方法:
1)精確模式, 試圖將句子最精確地切開,適合文本分析:
2)全模式,把句子中所有的可以成詞的詞語都掃描出來,速度非常快,但是不能解決歧義;
3)搜索引擎模式,在精確模式的基礎上,對長詞再詞切分,提高召回率,適合用于搜索引擎分詞。
1、精確模式
它可以將結果十分精確分開,不存在多余的詞。常用函數:lcut(str) 、 cut(str)
cut()的結果是個生成器序列,lcut()和cut()使用方法一樣,不過返回的是列表。
import jieba
ss='任性的90后boy'
for i in jieba.cut(ss):
print(i)
'''
任性
的
90
后
boy<br>'''
2、全模式
它可以將結果全部展現,也就是一段話可以拆分進行組合的可能它都給列舉出來了。常用函數:lcut(str,cut_all=True) 、 cut(str,cut_all=True)
import jieba
seg_str = "好好學習,天天向上。"
print("/".join(jieba.lcut(seg_str))) # 精簡模式,返回一個列表類型的結果
print("/".join(jieba.lcut(seg_str, cut_all=True))) # 全模式,使用 'cut_all=True' 指定
print("/".join(jieba.lcut_for_search(seg_str))) # 搜索引擎模式
'''
好好學習/,/天天向上/。
好好/好好學/好好學習/好學/學習/,/天天/天天向上/向上/。
好好/好學/學習/好好學/好好學習/,/天天/向上/天天向上/。
'''
可以看到,全模式把句子中所有的可以成詞的詞語都掃描出來, 會出現一詞多用、一詞多意。精確模式將句子最精確的切分開,每個詞都只有一種含義。
3、搜索引擎模式
將結果精確分開,對比較長的詞進行二次切分。它可以將全模式的所有可能再次進行一個重組。lcut_for_search(str) 、cut_for_search(str)
import jieba
seg_list = jieba.cut_for_search("中國上海是一座美麗的國際性大都市,擁有復旦大學、上海交通大學等知名高等學府")
print(", ".join(seg_list))
'''
中國, 上海, 是, 一座, 美麗, 的, 國際, 國際性, 大都, 都市, 大都市, ,, 擁有, 復旦, 大學, 復旦大學, 、, 上海, 交通, 大學, 上海交通大學, 等, 知名, 高等, 學府, 高等學府
'''
4、jieba的其它應用
1)、添加新詞
它是將本身存在于文本中的詞進行一個重組,它可以將我設置的兩個詞連貫起來,這對于名字分詞是很有幫助的,有時候分詞會將三個字甚至是多個字的人名劃分開來,這個時候我們就需要用到添加新詞了。當然,如果你添加了文本中沒有的詞,那是沒有任何效果.
import jieba
aa=jieba.cut('任性的90后boy來自于美麗的城市湖北武漢,他曾經在長江邊游覽過')
print('/'.join(aa))
'''
任性的/90/后/boy/來自于/美麗/的/城市/湖北/武漢/,/他/曾經/在/長江/邊/游覽/過
'''
import jieba
aa=jieba.cut('任性的90后boy來自于美麗的城市湖北武漢,他曾經在長江邊游覽過')
jieba.add_word('90后')
jieba.add_word('美麗的城市')
print('/'.join(aa))
'''
任性的/90后/boy/來自于/美麗的城市/湖北/武漢/,/他/曾經/在/長江/邊/游覽/過
'''
2)、添加字典
jieba可以添加屬于自己的字典,用來切分查找關鍵詞。這樣就可以有效縮小查找范圍,從而使得匹配完成度更高,時間更短。
我們可以使用load_userdict函數來讀取自定義詞典,它需要傳入一個文件名,格式如下:
#文件一行只可寫三項參數,分別為詞語、詞頻(可省略)、詞性(可省略)空格隔開,順序不可顛倒
jieba.load_userdict(file)這樣就可以讀取到該文件中的所有文本,然后我們讓它去匹配我們要進行分詞的文本,然后利用三大模式中的一種就可以精確匹配到要查找的內容。
import jieba
jieba.load_userdict('C:\\Programs\\PythonTest3\\test.txt')
aa=jieba.cut('任性的90后boy來自于美麗的城市湖北武漢,他曾經在長江邊游覽過')
print('/'.join(aa))
'''
任性的/90后/boy/來自于/美麗的城市/湖北/武漢/,/他/曾經/在/長江/邊/游覽/過
'''
3)、刪除新詞
如果我們對自己所添加的新詞不滿意,可以直接刪除。
import jieba
jieba.load_userdict('C:\\Programs\\PythonTest3\\test.txt')
jieba.del_word('90后')
aa=jieba.cut('任性的90后boy來自于美麗的城市湖北武漢,他曾經在長江邊游覽過')
print('/'.join(aa))
'''
任性的/90/后/boy/來自于/美麗的城市/湖北/武漢/,/他/曾經/在/長江/邊/游覽/過
'''
4)、處理停用詞
在有時候我們處理大篇幅文章時,可能用不到每個詞,需要將一些詞過濾掉,這個時候我們需要處理掉這些詞,比如‘的’ ‘了’、 ‘哈哈’,這些都是可有可無的詞。
import jieba
stop=['的','了','哈哈']
aa=jieba.lcut('我再也回不到童年的美好時光了,哈哈,想想都覺得傷心了')
ss=''
for i in aa:
if i not in stop:
ss+=i
ll=jieba.cut(ss)
print('/'.join(ll))
'''
我/再也/回/不到/童年/美好時光/,/,/想想/都/覺得/傷心
'''
5)、權重分析
很多時候我們需要將關鍵詞以出現的次數頻率來排列,這個時候就需要進行權重分析函數了,它會將字符串中出現頻率最高的幾個詞按順序排列了出來,如果你想打印出這幾個詞的頻率的話,只需添加一個withWeight參數,如果想輸出指定數的詞,只需添加一個topK參數。一定要這樣導入,否則會報錯 import jieba.analyse
import jieba.analyse
text='我再也回不到童年美好的時光了,哈哈,想想都覺得傷心了,童年是我夢寐以前的美好,它帶給我太多美好'
tag=jieba.analyse.extract_tags(sentence=text,topK=5,withWeight=True)
print(tag)
'''
[('美好', 1.43198988550875), ('童年', 1.04541792312), ('我太多', 0.74717296893125), ('夢寐', 0.7189238987), ('帶給', 0.50886099238125)]
'''
6)、調節單個詞語的詞頻
在分詞過程中,我們可以將某個詞顯式進行劃分。如下,可以看到它將美和好分開了。
import jieba
aa=jieba.lcut('我再也回不到童年美好的時光了,哈哈,想想都覺得傷心了',HMM=False)
print('/'.join(aa))
jieba.suggest_freq(('美','好'),tune=True)#加上tune參數表示可以劃分
aa=jieba.lcut('我再也回不到童年美好的時光了,哈哈,想想都覺得傷心了',HMM=False)
print('/'.join(aa)) #生成新詞頻
'''
我/再也/回/不到/童年/美好/的/時光/了/,/哈哈/,/想想/都/覺得/傷心/了
我/再也/回/不到/童年/美/好/的/時光/了/,/哈哈/,/想想/都/覺得/傷心/了
'''
7)、查看文本內詞語的開始和結束位置
有時候我們為了得到某個詞的準確位置以及分布情況我們可以使用函數tokenize()來定位。
import jieba
ab=jieba.tokenize('任性的90后boy,畢業于家里蹲大學,熱愛學習,目前單身,無工作,望富婆垂憐')
for y in ab:
print(f'單詞:{y[0]}\t\t開始:{y[1]}\t\t結束:{y[2]}')
'''
單詞:任性的 開始:0 結束:3
單詞:90 開始:3 結束:5
......
'''
5、jieba 分詞簡單應用
import jieba
txt = open("三國演義.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精確模式對文本進行分詞
counts = {} # 通過鍵值對的形式存儲詞語及其出現的次數
for word in words:
if len(word) == 1: # 單個詞語不計算在內
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍歷所有詞語,每出現一次其對應的值加 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根據詞語出現的次數進行從大到小排序
for i in range(3):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))
三、pyttsx3
pyttsx3是Python中的文本到語音轉換庫。pyttsx3的安裝pip install pyttsx
1、導入pyttsx3庫后,調用speak函數即可進行語音播放。
import pyttsx3
#語音播放
pyttsx3.speak("How are you?")
pyttsx3.speak("I am fine, thank you")
2、如果我們想要修改語速、音量、語音合成器等,可以用如下方法。
import pyttsx3
engine = pyttsx3.init() #初始化語音引擎
rate = engine.getProperty('rate')
print(f'語速:{rate}')
volume = engine.getProperty('volume')
print (f'音量:{volume}')
#設置語速、音量等參數
engine.setProperty('rate', 100) #設置語速
engine.setProperty('volume',0.6) #設置音量
運行結果為:
語速:200
音量:1.0
3、查看語音合成器
voices = engine.getProperty('voices')
for voice in voices:
print(voice)
運行結果如下:
<Voice id=HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_ZH-CN_HUIHUI_11.0 name=Microsoft Huihui Desktop - Chinese (Simplified) languages=[] gender=None age=None> <Voice id=HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_EN-US_ZIRA_11.0 name=Microsoft Zira Desktop - English (United States) languages=[] gender=None age=None>
合成器的主要參數如下:
age發音人的年齡,默認為Nonegender以字符串為類型的發音人性別: male, female, or neutral.默認為Noneid關于Voice的字符串確認信息languages發音支持的語言列表,默認為一個空的列表name發音人名稱,默認為None
默認的語音合成器有兩個,兩個語音合成器均可以合成英文音頻,但只有第一個合成器能合成中文音頻。如果需要其他的語音合成器需要自行下載和設置。
import pyttsx3
engine = pyttsx3.init() #初始化語音引擎
engine.setProperty('rate', 150) #設置語速
engine.setProperty('volume',0.6) #設置音量
voices = engine.getProperty('voices')
engine.setProperty('voice',voices[0].id) #設置第一個語音合成器
engine.say("春光燦爛豬八戒")
engine.runAndWait()
engine.stop()
四、pandas_alive
Pandas_Alive,它以 matplotlib 繪圖為后端,不僅可以創建出令人驚嘆的數據動畫可視化,而且使用方法非常簡單。
#動態條形圖
import pandas as pd
import pandas_alive
#顯示中文宋體字體導入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步驟一(替換sans-serif字體,正常顯示中文)
plt.rcParams['axes.unicode_minus'] = False # 步驟二(解決坐標軸負數的負號顯示問題)
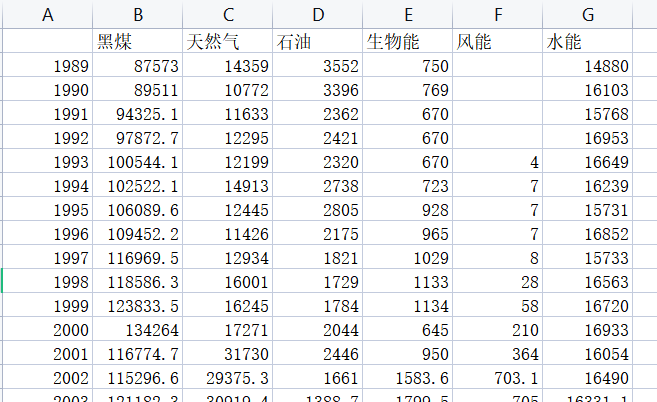
elec_df = pd.read_csv("C:/Programs/test/us_Elec_Gen_1980_2018.csv",index_col=0,parse_dates=[0],thousands=',',encoding='gb18030')
elec_df.fillna(0).plot_animated('example-electricity.gif',period_fmt="%Y",title='Australian1980-2018',n_visible = 15)

#動態柱形圖
import pandas as pd
import pandas_alive
#顯示中文宋體字體導入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步驟一(替換sans-serif字體,正常顯示中文)
plt.rcParams['axes.unicode_minus'] = False # 步驟二(解決坐標軸負數的負號顯示問題)
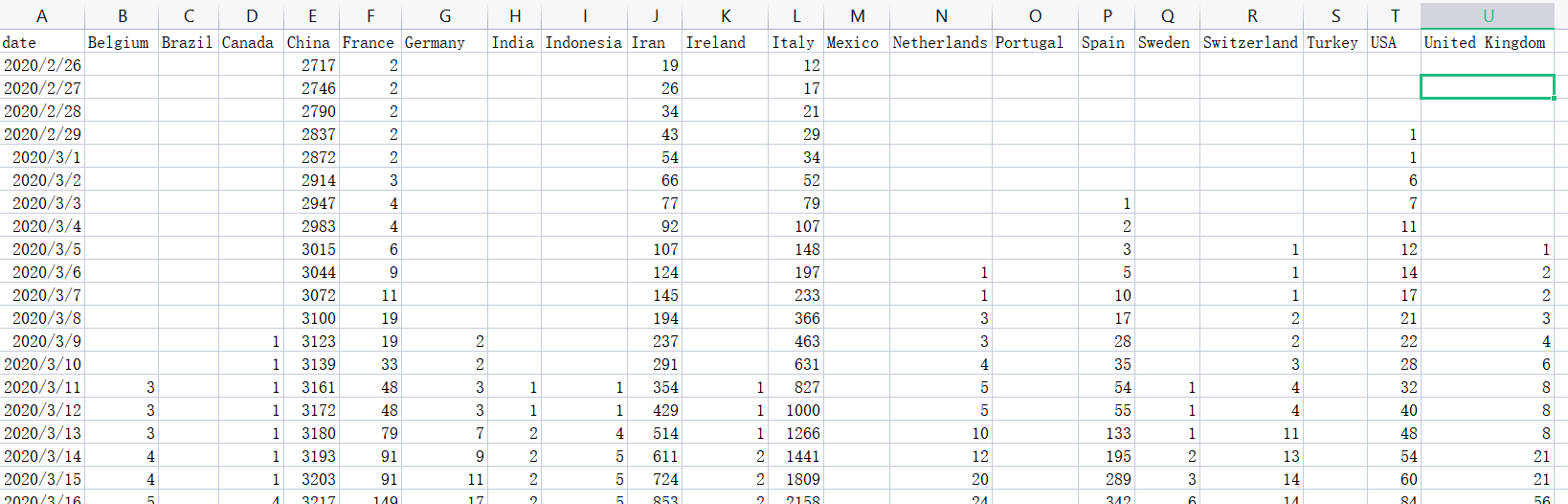
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.plot_animated(filename = 'example-barv-chart.gif',orientation='v',n_visible = 15)

#動態曲線圖
import pandas as pd
import pandas_alive
#顯示中文宋體字體導入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步驟一(替換sans-serif字體,正常顯示中文)
plt.rcParams['axes.unicode_minus'] = False # 步驟二(解決坐標軸負數的負號顯示問題)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.diff().fillna(0).plot_animated(filename = 'example-line-chart.gif',kind = 'line',period_label = { 'x': 0.25, 'y':0.9 },n_visible = 15)
#動態面積圖
import pandas as pd
import pandas_alive
#顯示中文宋體字體導入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步驟一(替換sans-serif字體,正常顯示中文)
plt.rcParams['axes.unicode_minus'] = False # 步驟二(解決坐標軸負數的負號顯示問題)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.sum(axis=1).fillna(0).plot_animated(filename='example-bar-chart.gif',kind='bar',
period_label={'x':0.1,'y':0.9},enable_progress_bar=True, steps_per_period=2, interpolate_period=True, period_length=200)

#動態餅圖
import pandas as pd
import pandas_alive
#顯示中文宋體字體導入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步驟一(替換sans-serif字體,正常顯示中文)
plt.rcParams['axes.unicode_minus'] = False # 步驟二(解決坐標軸負數的負號顯示問題)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.plot_animated(filename='example-pie-chart.gif',kind="pie",rotatelabels=True,period_label={'x':0,'y':0})

#多個圖表
import pandas_alive
import pandas as pd
#顯示中文宋體字體導入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步驟一(替換sans-serif字體,正常顯示中文)
plt.rcParams['axes.unicode_minus'] = False # 步驟二(解決坐標軸負數的負號顯示問題)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
animated_line_chart = covid_df.diff().fillna(0).plot_animated(kind='line',period_label=False,add_legend=False)
animated_bar_chart = covid_df.plot_animated(n_visible=10)
pandas_alive.animate_multiple_plots('example-bar-and-line-chart.gif',[animated_bar_chart,animated_line_chart],enable_progress_bar=True)

五、PyWebIO
PyWebIO使Python 也可以寫前端,PyWebIO 開發頁面我們不用過分關心CSS、JS等文件,全程我們只需要操作一個py腳本。也不用關心數據庫配置、前后端交互,就像上面的數據分析一樣,創建一個空白頁面,然后一行代碼添加一部分內容,內容可以實時編譯輸出。PyWebIO 提供了一系列命令式的交互函數來在瀏覽器上獲取用戶輸入和進行輸出,將瀏覽器變成了一個“富文本終端”,可以用于構建簡單的 Web 應用或基于瀏覽器的 GUI 應用。使用 PyWebIO,開發者能像編寫終端腳本一樣(基于 input 和 print 進行交互)來編寫應用,無需具備 HTML 和 JS 的相關知識;PyWebIO 還可以方便地整合進現有的 Web 服務。非常適合快速構建對 UI 要求不高的應用。安裝:pip install PyWebIO
PyWebIO一行代碼對應一個操作,例如可以調用 put_text() 、 put_image() 、 put_table() 等函數輸出文本、圖片、表格等內容到瀏覽器!
1、入門例子
我們用這個例子,來實現對數據的提交和檢驗。
from pywebio.input import *
from pywebio.output import *
from pywebio.pin import *
from pywebio import start_server
def input_input():
# input的合法性校驗
# 自定義校驗函數
def check_age(n):
if n<1:
return "Too Small!@"
if n>100:
return "Too Big!@"
else:
pass
myAge = input('please input your age:',type=NUMBER,validate=check_age,help_text='must in 1,100')
print('myAge is:',myAge)
if __name__ == '__main__':
start_server(
applications=[input_input,],
debug=True,
auto_open_webbrowser=True,
remote_access=True,
)
 效果圖
效果圖
2、input
# 輸入框
input_res = input("please input your name:")
print('browser input is:', input_res)
# 密碼框
pwd_res = input("please input your password:",type=PASSWORD)
print('password:', pwd_res)
# 下拉框
select_res = select("please select your city:",['北京','西安','成都'])
print('your city is:',select_res)
# checkbox
checkbox_res = checkbox("please confirm the checkbox:",options=['agree','disagree'])
print('checkbox:', checkbox_res)
# 文本框
text_res = textarea("please input what you want to say:",rows=3,placeholder='...')
print('what you said is:',text_res)
# 文件上傳
upload_res = file_upload("please upload what you want to upload:",accept="image/*")
with open(upload_res.get('filename'),mode='wb') as f: # 因為讀取的圖片內容是二進制,所以要以wb模式打開
f.write(upload_res.get('content'))
print('what you uploaded is:',upload_res.get('filename'))
# 滑動條
sld = slider('這是滑動條',help_text='請滑動選擇') # 缺點是不能顯示當前滑動的值
toast('提交成功')
print(sld)
# 單選選項
radio_res = radio(
'這是單選',
options=['西安','北京','成都']
)
print(radio_res)
# 更新輸入項
Country2City={
'China':['西安','北京','成都'],
'USA': ['紐約', '芝加哥', '佛羅里達'],
}
countries = list(Country2City.keys())
update_res = input_group(
"國家和城市聯動",
[
# 當國家發生變化的時候,onchange觸發input_update方法去更新name=city的選項,更新內容為Country2City[c],c代表國家的選項值
select('國家',options=countries,name='country',onchange=lambda c: input_update('city',options=Country2City[c])),
select('城市',options=Country2City[countries[0]],name='city')
]
)
print(update_res)
 輸入框
輸入框 密碼框
密碼框 選擇框
選擇框 勾選框
勾選框 文本框
文本框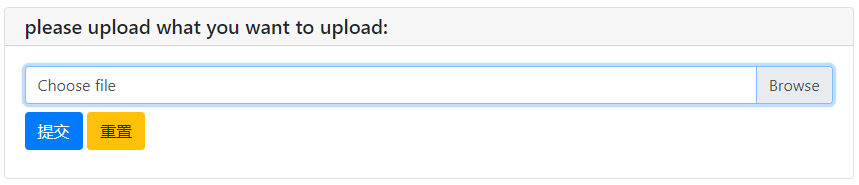 文件上傳
文件上傳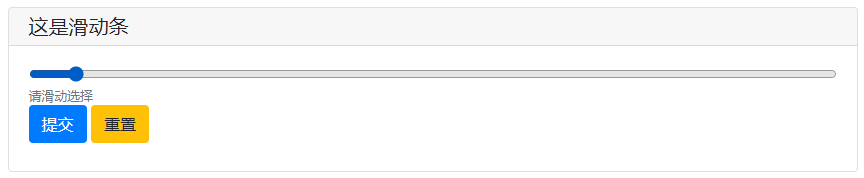 滑動條
滑動條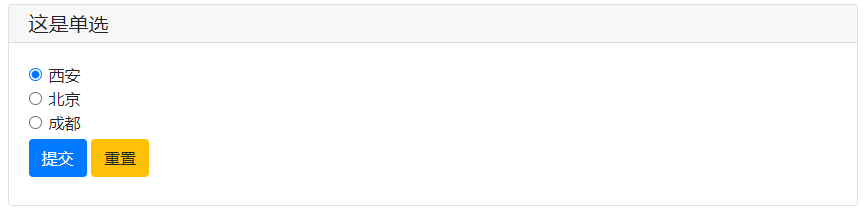 單選框
單選框 輸入框聯動-1
輸入框聯動-1 輸入框聯動-2
輸入框聯動-2
3、output
# 文本輸出
put_text('這是輸出的內容')
# 表格輸出
put_table(
tdata=[
['序號','名稱'],
[1,'中國'],
[2,'美國']
]
)
# MarkDown輸出
put_markdown('~~刪除線~~')
# 文件輸出
put_file('秘籍.txt','降龍十八掌')
# 按鈕輸出
put_buttons(
buttons=['A','B'],
onclick=toast
)

4、部分高級用法
# ========================== 1-輸入框的參數 ==============================
# input的更多參數
ipt = input(
'This is label',
type=TEXT,
placeholder='This is placeholder', # 占位
help_text='This is help text', # 提示
required=True, # 必填
datalist=['a1', 'b2', 'c3']) # 常駐輸入聯想
print('what you input is:',ipt)
# =========================== 2-輸入框自定義校驗 =============================
# input的合法性校驗
# 自定義校驗函數
def check_age(n):
if n<1:
return "Too Small!@"
if n>100:
return "Too Big!@"
else:
pass
myAge = input('please input your age:',type=NUMBER,validate=check_age,help_text='must in 1,100')
print('myAge is:',myAge)
# ============================ 3-代碼編輯 ============================
# textare的代碼模式
code = textarea(
label='這是代碼模式',
code={
'mode':'python',
'theme':'darcula',
},
value='import time\n\ntime.sleep(2)'
)
print('code is:',code)
# ============================== 4-輸入組 ==========================
def check_age(n):
if n<1:
return "Too Small!@"
if n>100:
return "Too Big!@"
else:
pass
def check_form(datas):
print(datas)
if datas.get("age")==1:
#return 'you are only one years old!'
return ('age','you are only one years old!')
if len(datas.get("name"))<=3:
return ('name','Name Too short!!!')
# 輸入組
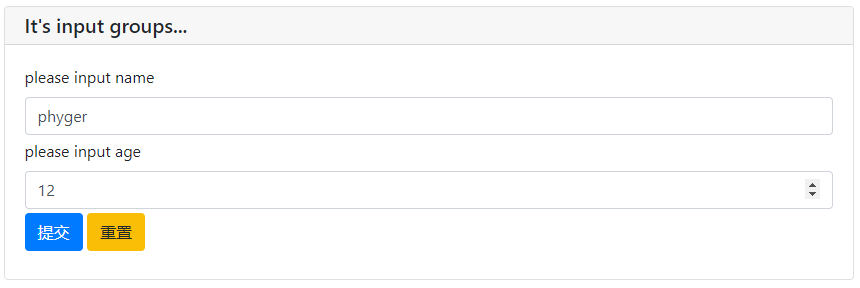
datas = input_group(
"It's input groups...",
inputs=[
input('please input name',name='name'),
input('please input age',name='age',type=NUMBER,validate=check_age)
],
validate=check_form
)
# ====================================== 5-輸入框的action =========================================
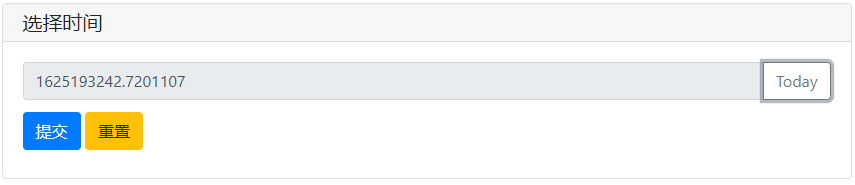
import time
def set_today(set_value):
set_value(time.time())
print(time.time())
tt = input('選擇時間',action=('Today',set_today),readonly=True)
print(tt)
# ====================================== 5-輸入框的彈窗 =========================================
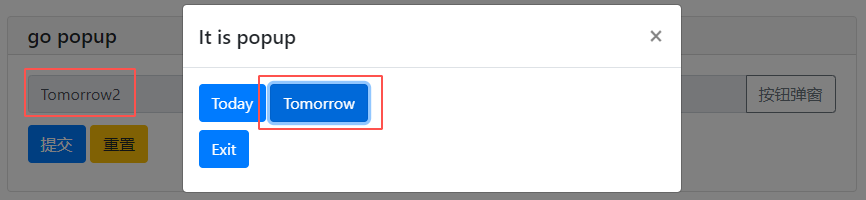
def set_some(set_value): # 此方法可以將選擇的英文轉換為中文
with popup('It is popup'): # popup 是 output 模塊中的方法
put_buttons(['Today','Tomorrow'],onclick=[lambda: set_value('今天','Today1'),lambda:set_value('明天','Tomorrow2')]) # set_value('今天','Today') 按Today的按鈕輸入Today1,實際對應:今天
put_buttons(['Exit'],onclick=lambda _: close_popup())
pp = input('go popup',type=TEXT,action=('按鈕彈窗',set_some))
print(pp)
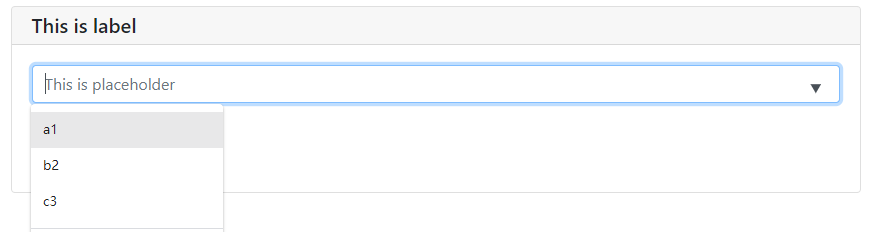
聯想詞常駐+help_text

代碼編輯模式
輸入組
輸入框的action

輸入框的彈窗
按鈕的onclick
代碼中的
六、pywebview
pywebview 是一個輕量級的 python 庫,旨在簡化桌面應用程序的開發。它利用系統的 WebView 組件,使得開發人員可以使用現代 Web 技術(HTML、CSS、JavaScript)來創建用戶界面,同時使用 python 處理業務邏輯。pywebview 使得創建跨平臺桌面應用程序變得更加簡單和高效。主要功能和特點:
- 跨平臺支持, pywebview 支持 Windows、macOS 和 Linux,確保應用程序可以在多個平臺上運行。
- 簡易集成,可以輕松地將 Web 應用嵌入到桌面應用中,無需復雜的設置
- 安全性:支持禁用本地文件訪問和執行外部腳本,提供額外的安全層。
1、安裝
# 會默認安裝基本的依賴
pip install pywebview2、pywebview默認使用系統自帶的 WebView 組件作為瀏覽器引擎
- windows 使用默認使用 Internet Explorer 11 作為 WebView 引擎。
- macOS 默認使用 WebKit 引擎,這是 macOS 自帶的 WebView 組件,基于 Safari 瀏覽器的引擎。
- Linux 默認使用 WebKitGTK,這是 Linux 上常用的 WebView 組件,基于 WebKit 引擎
如果需要其他引擎,需要單獨安裝:
3、windows中使用 CEF(Chromium Embedded Framework)作為引擎
pip install cefpython3
? 指定backend?
import webview
webview.create_window('My App', 'https://www.baidu.com/', backend='cef')
webview.start()
4、基礎使用
# demo1.py
import webview
window = webview.create_window('Woah dude!', 'https://pywebview.flowrl.com')
webview.start()
?create_window函數用于創建一個新窗口,并返回一個 window 對象實例。在調用webview.start()之前創建的窗口將在 GUI 循環啟動后立即顯示。GUI 循環啟動后創建的窗口也會立即顯示。您可以創建任意數量的窗口,所有已打開的窗口都會按創建順序存儲在webview.windows列表中。?
5、同時打開兩個窗口
import webview
first_window = webview.create_window('Woah dude!', 'https://pywebview.flowrl.com')
second_window = webview.create_window('Second window', 'https://woot.fi')
webview.start()
6、調用后臺執行
?webview.start會啟動一個 GUI 循環,并阻止進一步的代碼執行,直到最后一個窗口被銷毀。由于 GUI 循環是阻塞的,您必須在單獨的線程或進程中執行后臺邏輯。您可以通過將函數傳遞給webview.start(func, (params,))來執行后臺代碼。這將啟動一個單獨的線程,與手動啟動線程是相同的。?
# 界面打開后就會自動彈窗
import webview
def custom_logic(window):
window.toggle_fullscreen()
window.evaluate_js('alert("Nice one brother")')
window = webview.create_window('Woah dude!', html='<h1>Woah dude!<h1>')
webview.start(custom_logic, window)
? window.evaluate_js可以使用python執行js代碼?
7、js調用python
import webview
# 這里是核心,是和js中交互的關鍵
class Api():
def log(self, value):
print(value)
webview.create_window("Test", html="<button onclick='pywebview.api.log(\"Woah dude!\")'>Click me</button>", js_api=Api())
webview.start()
? 在打開的界面中點擊按鈕,后臺就可以看到log函數被調用,會把傳入的值 Woah dude! 打印到控制臺?
8、HTTP Server
? pywebview 默認使用 bottlepy 作為http 服務,默認端口是8080,前后服務也可以使用http 通信?
- demo.py
import webview
from bottle import Bottle, run, static_file
import threading
app = Bottle()
@app.route("/api/data")
def get_data():
return {"message": "Hello from the server!"}
@app.route("/")
def index():
return static_file("index.html", root=".")
# 啟動 HTTp 服務器
def start_server():
run(app, host="localhost", port=8080)
if __name__ == "__main__":
# 在單獨的線程中啟動 HTTp 服務器
server_thread = threading.Thread(target=start_server)
server_thread.daemon = True
server_thread.start()
# 創建并啟動 pywebview 窗口
webview.create_window("pywebview Example", "http://localhost:8080")
webview.start()

 浙公網安備 33010602011771號
浙公網安備 33010602011771號