

kafka的集群與可靠性
kafka做集群的目標
高并發
高可用
動態擴容
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic laoli --partitions 2 --replication-factor 2
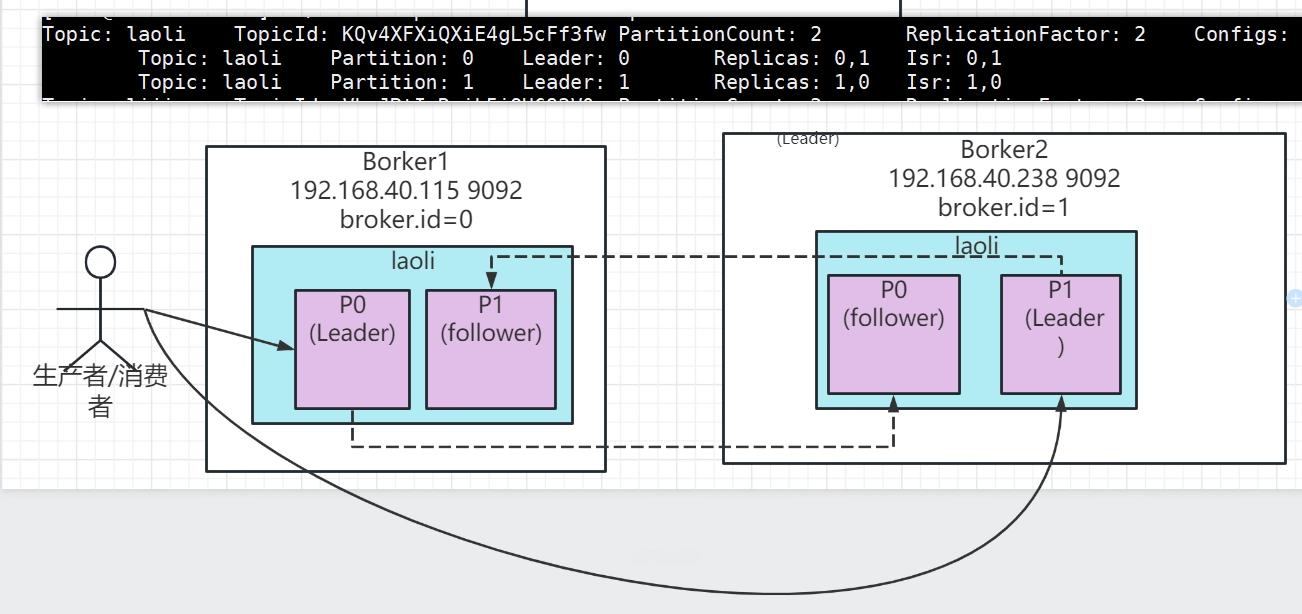
topic:創建名為laoli的主題
partitions:該主題下2個分區
replication-factor:復制因子,因為有集群,這里寫2。如果寫1的話,就不存在復制副本了。也不能寫3,因為只有兩臺服務器集群。

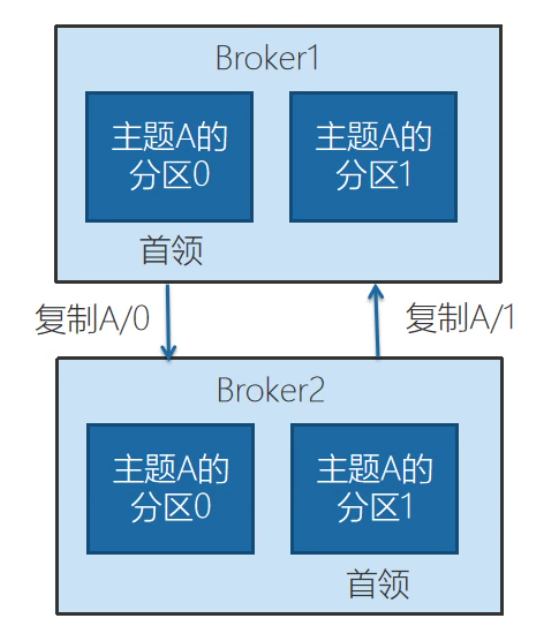
例如,一個主題下有兩個分區,做兩個復制因子,在broker1有,在broker2也有。分區0的首領是broker1,分區1的首領有可能就是broker2了。
查看topic詳細信息:

以topic為laoli為例,Leader:后面的數字表示broker的id。數據的復制都是從leader首領副本,復制到follower跟隨副本的。
創建生產者,topic名為laoli,發送消息:
./kafka-console-producer.sh --broker-list 192.168.40.115:9092 --topic laoli
創建消費者,topic名為laoli,消費消息:
./kafka-console-consumer.sh --bootstrap-server 192.168.40.115:9092 --topic laoli --from-beginning --consumer.config ../config/consumer.properties
kafka處理請求的內部機制:
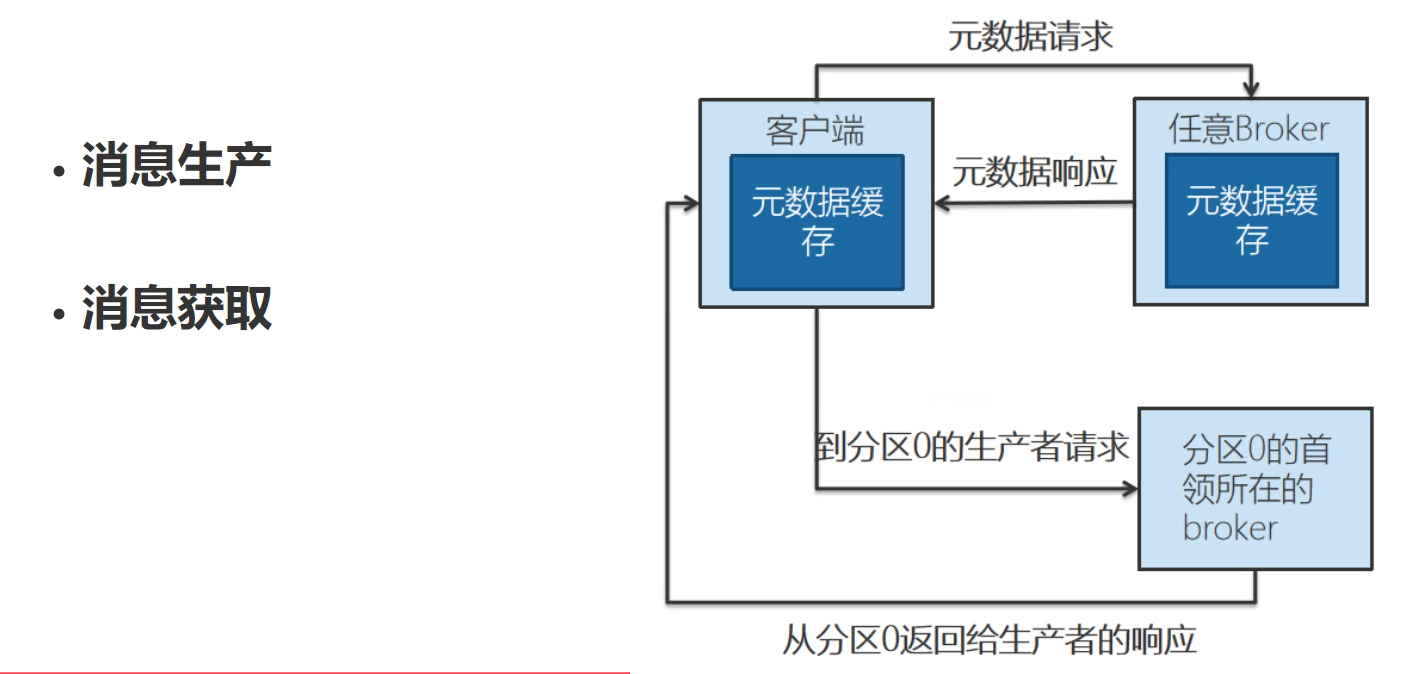
作為生產也好,作為消費也好,所有的請求,發送或者消費,都應該放在首領所在的broker,比如往分區0發,要發往首領所在的broker,任意一臺broker啟動的時候,會在客戶端獲取一個元數據,(元數據:創建的主題,哪些是首領,分區,以及分區里面哪個是首領,類似于查看topic詳細信息的這么一個元數據),并且元數據在任意一臺broker上都有。所以最終進行生產或者消費的時候,都是客戶端根據元數據緩存,發送到指定的首領所在的broker節點上來。非首領的分區上的數據來自于對應首領分區上的數據的復制。
發送確認的ACKS機制,三種模式:
1.acks=0,只要發出去了,不管確認(認為消息已經寫入kafka)
2.acks=1,寫入分區的副本數,只要寫入1個就返回確認了。(先寫到leader,然后再由leader同步到follower)
3.acks=all或-1,簡單的理解全部(min.insync.replicas參數)都收到了,就返回確認。
總結:
1.追求性能,min.insync.replicas=1,leader同步成功返回成功;(leader宕機了,必然會丟數據)
2.min.insync.replicas = 3, 3個副本,3個副本的服務器,任意一臺在發送消息時宕機了,返回發送不成功。
消費者來說,比較重要的參數:
1.group.id,消息的重復消費
2.auto.offset.reset,自動偏移量的設置,從哪里開始找,可以設置為earliest,latest,none,anything else。拉取消息的時候如果這個偏移量在broker上不存在,或者是第一次獲取消息,那從哪里offset開始找消息呢?如果配置為latest,之前的消息就收不到了。如果配置的是earliest,必然有可能之前的消息已經消費過了,又把之前最老的消息從頭再消費一次。
3.enable.auto.commit,自動提交,默認情況下自動提交的。也就是說只要消息通過poll方法拿到,拿到之后就會自動提交。但是有可能在這個過程中會發生錯誤,所以經常在確保消息不會發生丟失、重復時,盡量可以取消自動提交,交給程序進行手動提交,consumer.commitAsync()-異步,不會阻塞線程;consumer.commitSync()-同步,會阻塞線程,并且會重試。
4.auto.commit.interval.ms,和上面自動提交的參數相關,如果選擇了默認自動提交,那這個參數表示多久提交一次,3.0的kafka版本默認是5秒提交一次。當然如果你這邊消費的很快,可以設置快點,比如1ms提交一次,當然如果你提交的越頻繁的話肯定會有額外的開銷。
kafka的存儲機制
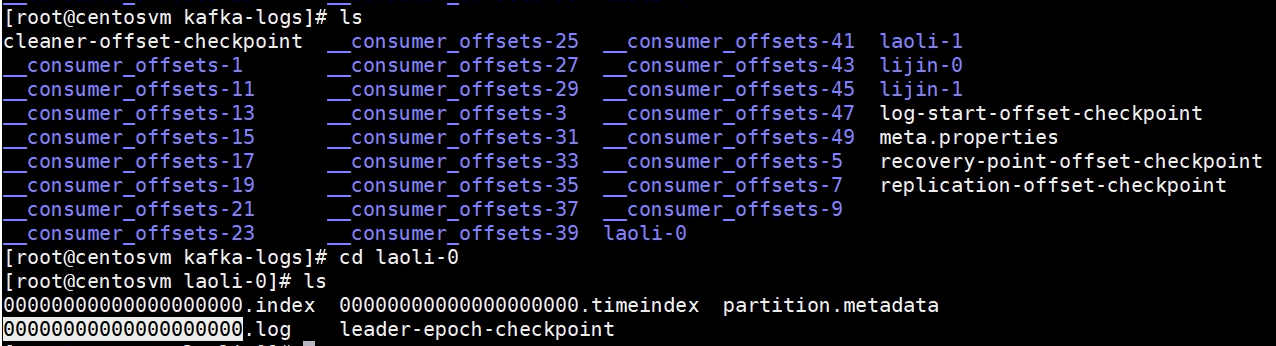
基本的存儲單位:?分區,同一個broker多個磁盤再劃分,粒度就是分區。
在server.properties中有配置:
log.dirs=/tmp/kafka-logs ?存儲路徑
--

 浙公網安備 33010602011771號
浙公網安備 33010602011771號