

達(dá)夢數(shù)據(jù)庫執(zhí)行計(jì)劃介紹
參考文章:
達(dá)夢數(shù)據(jù)庫執(zhí)行計(jì)劃查看
達(dá)夢數(shù)據(jù)庫 Explain 指標(biāo)分析 – 查看執(zhí)行計(jì)劃
達(dá)夢數(shù)據(jù)庫查看及解析執(zhí)行計(jì)劃
前言:??????
我們在碰到sql執(zhí)行慢的時候,需要分析sql執(zhí)行過程,看下是否走了索引等等。這時候就需要查看執(zhí)行計(jì)劃。達(dá)夢數(shù)據(jù)庫查看執(zhí)行計(jì)劃的方式有兩種:
1.explain,在待執(zhí)行的sql語句前面加上explain,再執(zhí)行
2.利用DM管理工具,選擇要查看的sql語句,點(diǎn)擊執(zhí)行計(jì)劃(P)(F9)
一、操作符說明??
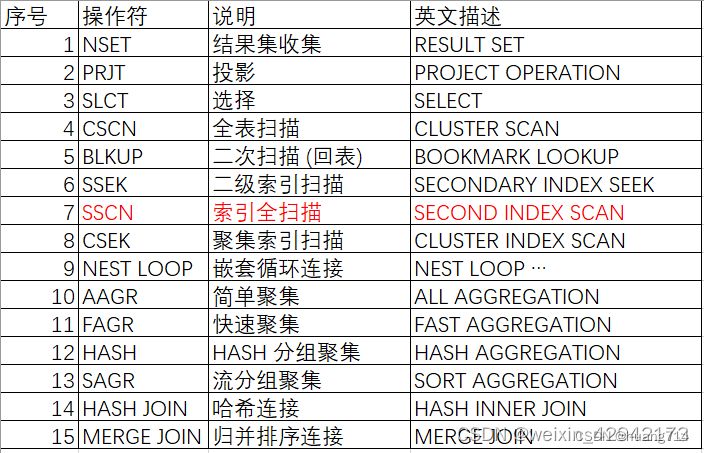
二、對于操作符說明和解釋:
本文參考于達(dá)夢官方 Explain 指標(biāo)的介紹:https://eco.dameng.com/document/dm/zh-cn/ops/performance-optimization.html 自己搜索:查看執(zhí)行計(jì)劃
一般SQL結(jié)果只要保持為 SSEK2就好了。
反面教材

explain select * from sysobjects;
--執(zhí)行計(jì)劃
1 #NSET2: [1, 986, 396]
2 #PRJT2: [1, 986, 396]; exp_num(17), is_atom(FALSE)
3 #CSCN2: [1, 986, 396]; SYSINDEXSYSOBJECTS(SYSOBJECTS as SYSOBJECTS)
結(jié)果集解釋:
1. NSET:結(jié)果集收集
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
NSET 是用于結(jié)果集收集的操作符,一般是查詢計(jì)劃的頂層節(jié)點(diǎn),優(yōu)化工作中無需對該操作符過多關(guān)注,一般沒有優(yōu)化空間。
2. PRJT:投影
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
PRJT 是關(guān)系的【投影】 (project) 運(yùn)算,用于選擇表達(dá)式項(xiàng)的計(jì)算。廣泛用于查詢,排序,函數(shù)索引創(chuàng)建等。優(yōu)化工作中無需對該操作符過多關(guān)注,一般沒有優(yōu)化空間。
3. SLCT:選擇
EXPLAIN SELECT * FROM T1 WHERE C2='TEST';
1 #NSET2: [1, 250, 156]
2 #PRJT2: [1, 250, 156]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [1, 250, 156]; T1.C2 = TEST
4 #CSCN2: [1, 10000, 156]; INDEX33556717(T1)
SLCT 是關(guān)系的【選擇】運(yùn)算,用于查詢條件的過濾。可比較返回結(jié)果集與代價估算中是否接近,如相差較大可考慮收集統(tǒng)計(jì)信息。若該過濾條件過濾性較好,可考慮在條件列增加索引。
4. AAGR:簡單聚集
EXPLAIN SELECT COUNT(*) FROM T1 WHERE C1 = 10;
1 #NSET2: [0, 1, 4]
2 #PRJT2: [0, 1, 4]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [0, 1, 4]; grp_num(0), sfun_num(1)
4 #SSEK2: [0, 1, 4]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
AAGR 用于沒有 GROUP BY 的 COUNT、SUM、AGE、MAX、MIN 等聚集函數(shù)的計(jì)算。
5. FAGR:快速聚集
EXPLAIN SELECT MAX(C1) FROM T1;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1)
FAGR 用于沒有過濾條件時,從表或索引快速獲取 MAX、MIN、COUNT 值。
6. HAGR:HASH 分組聚集
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C2;
1 #NSET2: [1, 100, 48]
2 #PRJT2: [1, 100, 48]; exp_num(1), is_atom(FALSE)
3 #HAGR2: [1, 100, 48]; grp_num(1), sfun_num(1)
4 #CSCN2: [1, 10000, 48]; INDEX33556717(T1)
HAGR 用于分組列沒有索引只能走全表掃描的分組聚集,該示例中 C2 列沒有創(chuàng)建索引。
7. SAGR:流分組聚集
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C1;
1 #NSET2: [1, 100, 4]
2 #PRJT2: [1, 100, 4]; exp_num(1), is_atom(FALSE)
3 #SAGR2: [1, 100, 4]; grp_num(1), sfun_num(1)
4 #SSCN: [1, 10000, 4]; IDX_C1_T1(T1)
SAGR 用于分組列是有序的情況下,可以使用流分組聚集,C1 列上已經(jīng)創(chuàng)建了索引,SAGR2 性能優(yōu)于 HAGR2。
8. BLKUP:二次掃描 (回表)
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
BLKUP 先使用二級索引索引定位 rowid,再根據(jù)表的主鍵、聚集索引、rowid 等信息獲取數(shù)據(jù)行中其它列。
9. CSCN:全表掃描
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
CSCN2 是 CLUSTER INDEX SCAN 的縮寫即通過聚集索引掃描全表,全表掃描是最簡單的查詢,如果沒有選擇謂詞,或者沒有索引可以利用,則系統(tǒng)一般只能做全表掃描。全表掃描 I/O 開銷較大,在一個高并發(fā)的系統(tǒng)中應(yīng)盡量避免全表掃描。
10. SSEK、CSEK、SSCN:索引掃描
-- 創(chuàng)建所需索引
CREATE CLUSTER INDEX IDX_C1_T2 ON T2(C1);
CREATE INDEX IDX_C1_C2_T1 ON T1(C1,C2);(1)SSEK
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
SSEK2 是二級索引掃描即先掃描索引,再通過主鍵、聚集索引、rowid 等信息去掃描表。
(2)CSEK
EXPLAIN SELECT * FROM T2 WHERE C1=10;
1 #NSET2: [0, 250, 156]
2 #PRJT2: [0, 250, 156]; exp_num(5), is_atom(FALSE)
3 #CSEK2: [0, 250, 156]; scan_type(ASC), IDX_C1_T2(T2), scan_range[10,10]
CSEK2 是聚集索引掃描只需要掃描索引,不需要掃描表,即無需 BLKUP 操作,如果 BLKUP 開銷較大時,可考慮創(chuàng)建聚集索引。
(3)SSCN
EXPLAIN SELECT C1,C2 FROM T1;
1 #NSET2: [1, 10000, 60]
2 #PRJT2: [1, 10000, 60]; exp_num(3), is_atom(FALSE)
3 #SSCN: [1, 10000, 60]; IDX_C1_C2_T1(T1)
SSCN 是索引全掃描,不需要掃描表。
11. NEST LOOP:嵌套循環(huán)連接
嵌套循環(huán)連接是最基礎(chǔ)的連接方式,將一張表(驅(qū)動表)的每一個值與另一張表(被驅(qū)動表)的所有值拼接,形成一個大結(jié)果集,再從大結(jié)果集中過濾出滿足條件的行。驅(qū)動表的行數(shù)就是循環(huán)的次數(shù),將在很大程度上影響執(zhí)行效率。
連接列是否有索引,都可以走 NEST LOOP,但沒有索引,執(zhí)行效率會很差,語句如下所示:
select /*+use_nl(t1,t2)*/* from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';
1 #NSET2: [17862, 24725, 296]
2 #PRJT2: [17862, 24725, 296]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [17862, 24725, 296]; T1.C1 = T2.C1
4 #NEST LOOP INNER JOIN2: [17862, 24725, 296];
5 #SLCT2: [1, 250, 148]; T1.C2 = 'A'
6 #CSCN2: [1, 10000, 148]; INDEX33555594(T1)
7 #CSCN2: [1, 10000, 148]; INDEX33555595(T2)可針對 T1 和 T2 的連接列創(chuàng)建索引,并收集統(tǒng)計(jì)信息,語句如下所示:
CREATE INDEX IDX_T1_C2 ON T1(C2);
CREATE INDEX IDX_T2_C1 ON T2(C1);
DBMS_STATS.GATHER_INDEX_STATS(USER,'IDX_T1_C2');
DBMS_STATS.GATHER_INDEX_STATS(USER,'IDX_T2_C1');再次查看執(zhí)行計(jì)劃可看出效率明顯改善,代價有顯著下降,語句如下所示:
select /*+use_nl(t1,t2)*/* from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';
1 #NSET2: [9805, 17151, 296]
2 #PRJT2: [9805, 17151, 296]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [9805, 17151, 296]; T1.C1 = T2.C1
4 #NEST LOOP INNER JOIN2: [9805, 17151, 296];
5 #BLKUP2: [1, 175, 148]; IDX_T1_C2(T1)
6 #SSEK2: [1, 175, 148]; scan_type(ASC), IDX_T1_C2(T1), scan_range['A','A']
7 #CSCN2: [1, 10000, 148]; INDEX33555585(T2)適用場景:
- 驅(qū)動表有很好的過濾條件
- 表連接條件能使用索引
- 結(jié)果集比較小
12. HASH JOIN:哈希連接
哈希連接是在沒有索引或索引無法使用情況下大多數(shù)連接的處理方式。哈希連接使用關(guān)聯(lián)列去重后結(jié)果集較小的表做成 HASH 表,另一張表的連接列在 HASH 后向 HASH 表進(jìn)行匹配,這種情況下匹配速度極快,主要開銷在于對連接表的全表掃描以及 HASH 運(yùn)算。
select * from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';
1 #NSET2: [4, 24502, 296]
2 #PRJT2: [4, 24502, 296]; exp_num(8), is_atom(FALSE)
3 #HASH2 INNER JOIN: [4, 24502, 296]; KEY_NUM(1); KEY(T1.C1=T2.C1) KEY_NULL_EQU(0)
4 #SLCT2: [1, 250, 148]; T1.C2 = 'A'
5 #CSCN2: [1, 10000, 148]; INDEX33555599(T1)
6 #CSCN2: [1, 10000, 148]; INDEX33555600(T2)哈希連接比較消耗內(nèi)存如果系統(tǒng)有很多這種連接時,需調(diào)整以下 3 個參數(shù):
|
參數(shù)名 |
說明 |
|---|---|
|
HJ_BUF_GLOBAL_SIZE |
HASH 連接操作符的數(shù)據(jù)總緩存大小 ()>=HJ_BUF_SIZE),系統(tǒng)級參數(shù),以兆為單位。有效值范圍(10~500000) |
|
HJ_BUF_SIZE |
單個哈希連接操作符的數(shù)據(jù)總緩存大小,以兆為單位。有效值范圍(2~100000) |
|
HJ_BLK_SIZE |
哈希連接操作符每次分配緩存( BLK )大小,以兆為單位,必須小于 HJ_BUF_SIZE。有效值范圍(1~50) |
13. MERGE JOIN:歸并排序連接
歸并排序連接需要兩張表的連接列都有索引,對兩張表掃描索引后按照索引順序進(jìn)行歸并。
-- 對連接列創(chuàng)建索引
CREATE INDEX IDX_T1_C1C2 ON T1(C1,C2);select /*+use_merge(t1 t2)*/t1.c1,t2.c1 from t1 inner join t2 on t1.c1=t2.c1 where t2.c2='b';
1 #NSET2: [13, 24725, 56]
2 #PRJT2: [13, 24725, 56]; exp_num(2), is_atom(FALSE)
3 #SLCT2: [13, 24725, 56]; T2.C2 = 'b'
4 #MERGE INNER JOIN3: [13, 24725, 56]; KEY_NUM(1); KEY(COL_0 = COL_0) KEY_NULL_EQU(0)
5 #SSCN: [1, 10000, 4]; IDX_C1_T1(T1)
6 #BLKUP2: [1, 10000, 52]; IDX_T2_C1(T2)
7 #SSCN: [1, 10000, 52]; IDX_T2_C1(T2)特殊說明: 上述文章均是作者實(shí)際操作后產(chǎn)出。煩請各位,請勿直接盜用!轉(zhuǎn)載記得標(biāo)注原文鏈接:www.zanglikun.com
三、操作符后面的三元組解釋:
能正常讀取執(zhí)行計(jì)劃描述的執(zhí)行順序后,我們關(guān)注下執(zhí)行計(jì)劃各個節(jié)點(diǎn)的詳細(xì)信息,執(zhí)行計(jì)劃中所有操作符的后面都會有一個三元組,如:
#CSCN2: [1, 9999, 4]
[1, 9999, 4]就是我們提到的這個三元組,3個數(shù)字分別表示該操作符的估算代價,該操作符的輸出行數(shù),該操作符涉及數(shù)據(jù)的行長。
#CSCN2: [1, 9999, 4] 表示的意義為,這是一個全表掃描操作,涉及的行數(shù)為9999,每場數(shù)據(jù)長度為4,整體代價估算為1。
我們將三元組中的第二項(xiàng)稱為估算行數(shù)(card),在復(fù)雜查詢中,估算行數(shù)對于執(zhí)行計(jì)劃以及SQL性能的影響很大。
--

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號