AI換臉實戰教學(FaceSwap的使用)---------第二步Tools:處理輸入數據集。
2023-01-19 14:21 凍雨冷霧 閱讀(8849) 評論(9) 收藏 舉報續上篇:http://www.rzrgm.cn/techs-wenzhe/p/12936809.html
第一步中已經提取出了源視頻的人臉照片以及對應人臉遮罩(landmark以及其他自選遮罩)
第二步:利用Tools處理提取號好的數據集,使其對模型的訓練產生正向收益。
步驟1:剔除不需要的人臉
首先,我們需要剔除不需要的人臉(對齊識別錯誤以及非想要換臉的目標),做法是對生成的人臉進行聚類,排序。之后把不需要的類別的人臉刪除掉。
這一步的目的是:我們都知道訓練一個模型輸入參數的正確性決定了算法的精確度,這一步就是為了去除所有錯誤的,不恰當的輸入數據(圖片)集。我們需要給模型一個清晰,明了的可學習對象。
PS:如果你的輸入數據集(人臉圖片很多)過大,請拆分成多個,需要分多次聚類排序。因為這些操作會在RAM中進行,例如:大約22k 張人臉對應大約8G RAM,30k對應11G(還要考慮其他內存使用,瀏覽器什么的==). 根據你電腦的RAM能力,選擇分幾次來處理即可。
GUI的設置如下:
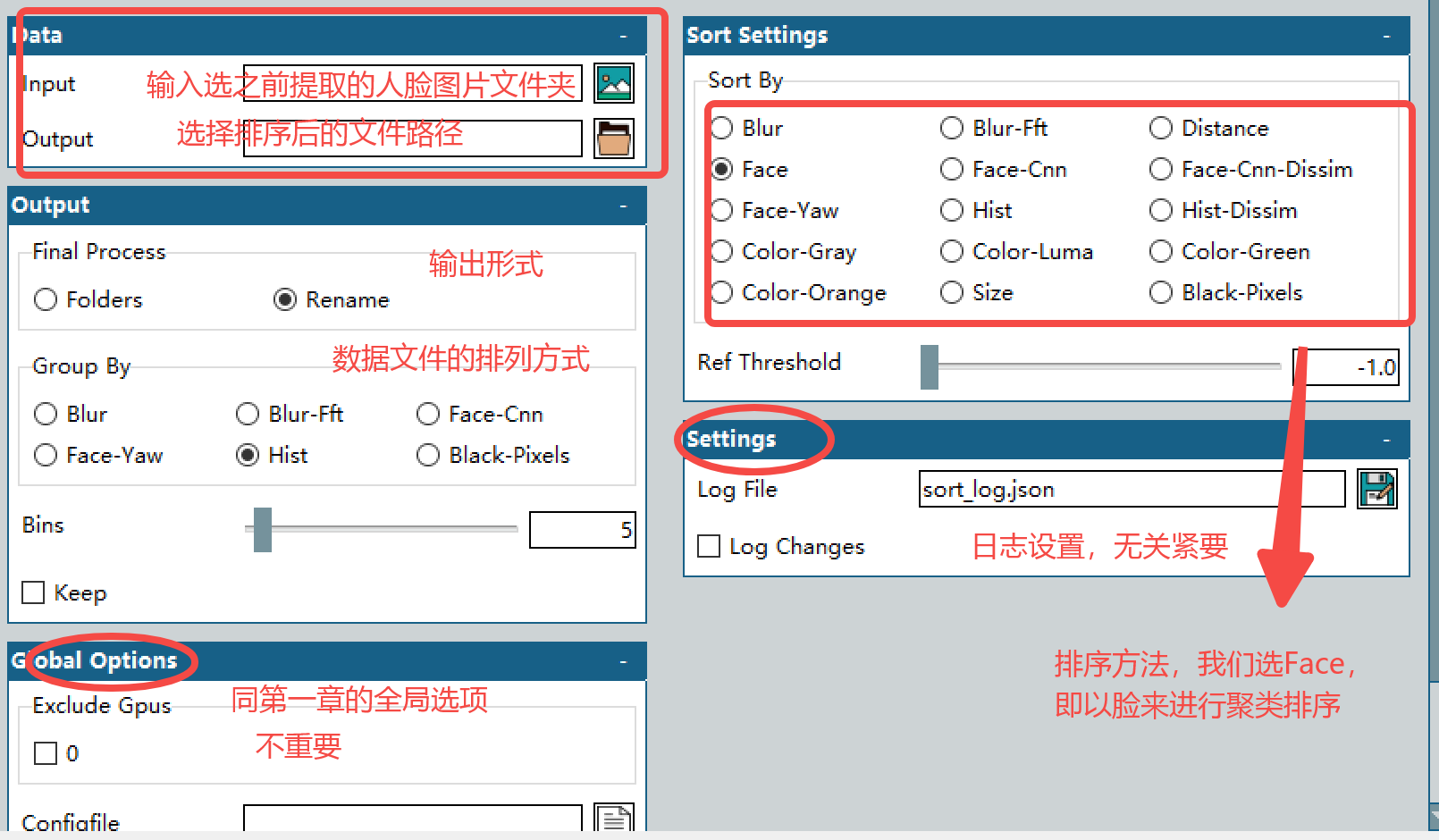
PS: 實際根據有啥模型就用啥,筆者自己辦公用的機器有Face-cnn,所以就選了用這個模型排序,選face的話得需要vggface2_resnet50_v2.zip模型在對應目錄下才行。
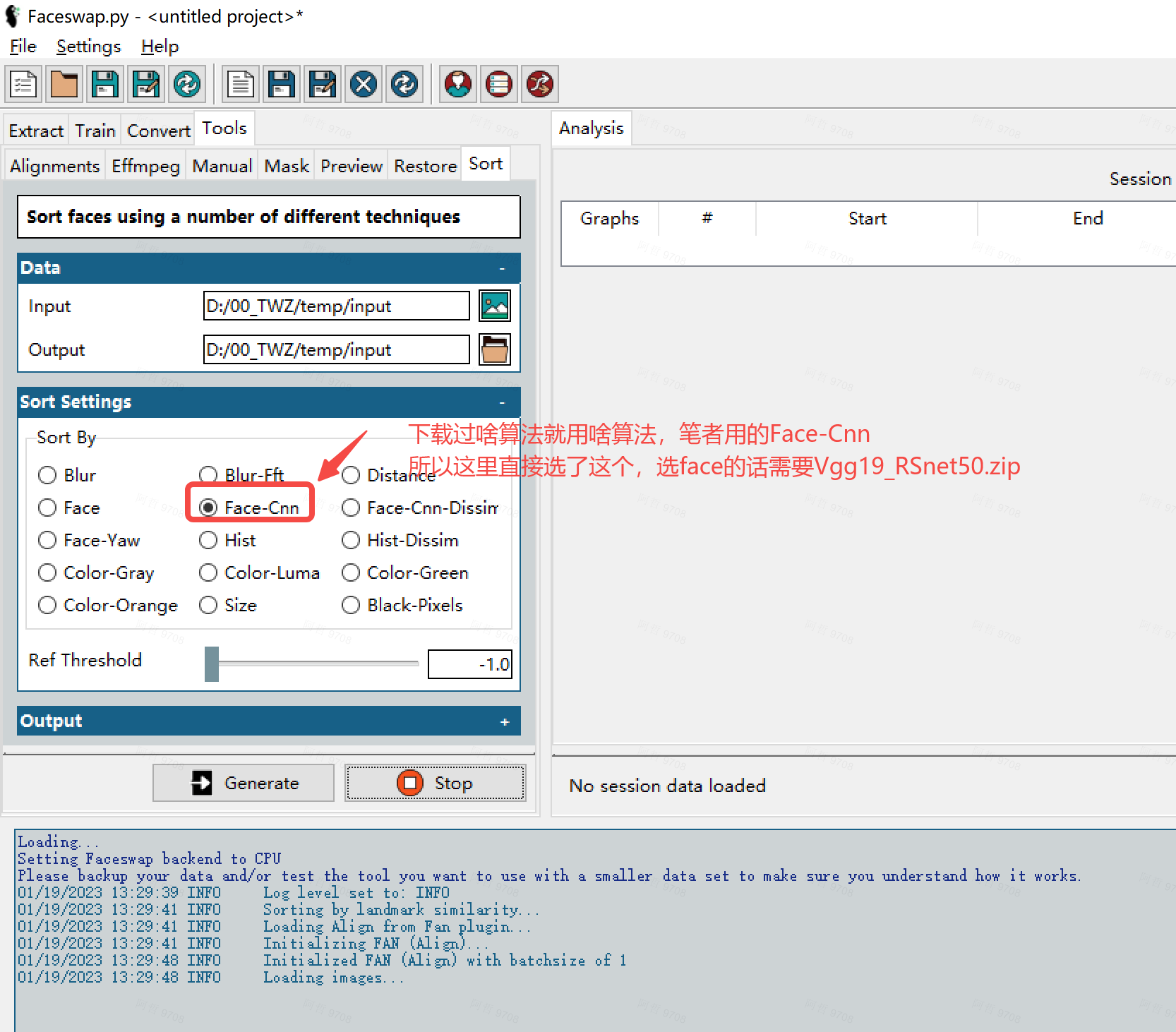
1.1 Data模塊:
-
Input:輸入包含上一步提取的人臉的文件夾。
-
Output:留空則基于輸入的文件內直接排序。
1.2 Sort Settings模塊:
-
Sort by:排序的方式,這里直接選face即可。意思是根據人臉相似度進行排序。當然還有其他排序方式(如基于landmark的Face-CNN,基于模糊度的Blur,基于聚類距離-識別錯誤對齊的distance,基于顏色的Color系列,基于大小的Size系列),實測還是face最有效。
-
Ref Threshold:Sort by內特殊幾種算法(face-CNN, Hist)的調節,同樣的值越高越嚴格。(推薦設置為-1即可,代表自動設置默認值) ,face-CNN 7.2就足夠了,設置為4會有較高識別度。Hist 0.3就足夠,設置為0.2 會有較高的識別度
1.3 Output模塊:這里不需要設置任何東西(此部分已完全棄用,并將在未來的更新中刪除。這里不需要設置任何東西。
選好模型,選好數據集(圖片)所在文件夾,選好輸出文件夾,點擊sort等待結果即可。

可看到是提取圖片中的landmark,根據直方圖分類。
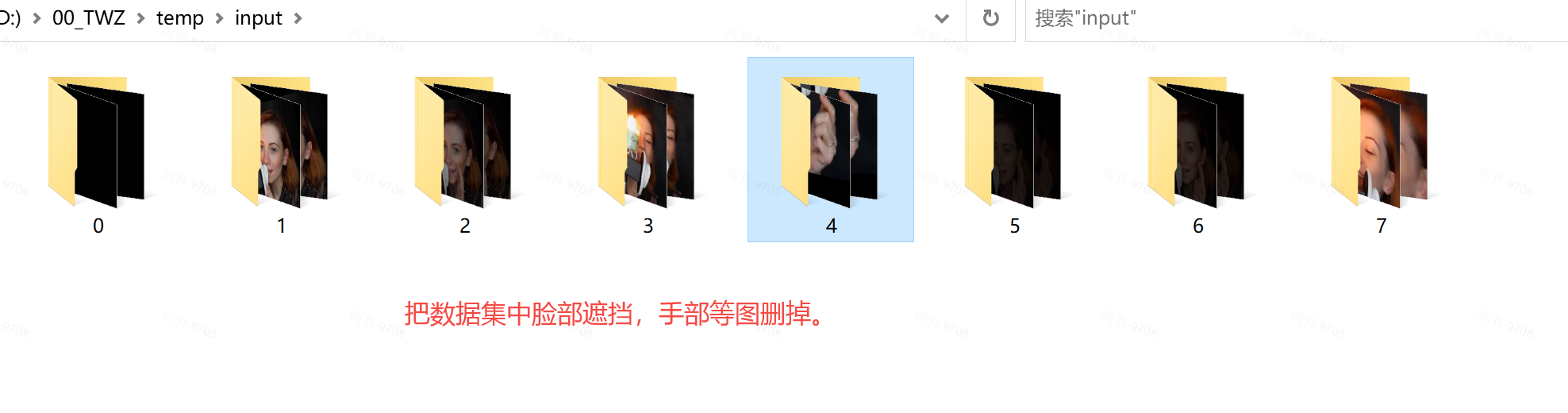
一旦完成,你應該發現 99% 的面孔被分類在一起,所有垃圾也一起分類,現在只需瀏覽每個垃圾箱(子文件夾),刪除那些您不想保留的面孔/文件夾,然后將您想要保留的任何面孔移回父文件夾。
至此,排序完畢,接下來要清理對齊-alignments文件
步驟2:清理對齊文件
現在我們已經刪除了所有不需要的面孔,只剩下一組了,接下來要做的是清理對齊文件(對齊文件中包含了每張圖片對應的五官所在位置的數據)。因為所有關于不需要的面孔的信息仍然在文件中(剛才排序步驟刪除的那些),這很可能在將來給我們帶來麻煩。所以需要刪除不需要圖片的對齊文件。 使用集成工具清理對齊文件還有一個額外的好處,可以將我們的面孔重命名回它們的原始文件名。
步驟如下,找到Tools->Alignments文件:
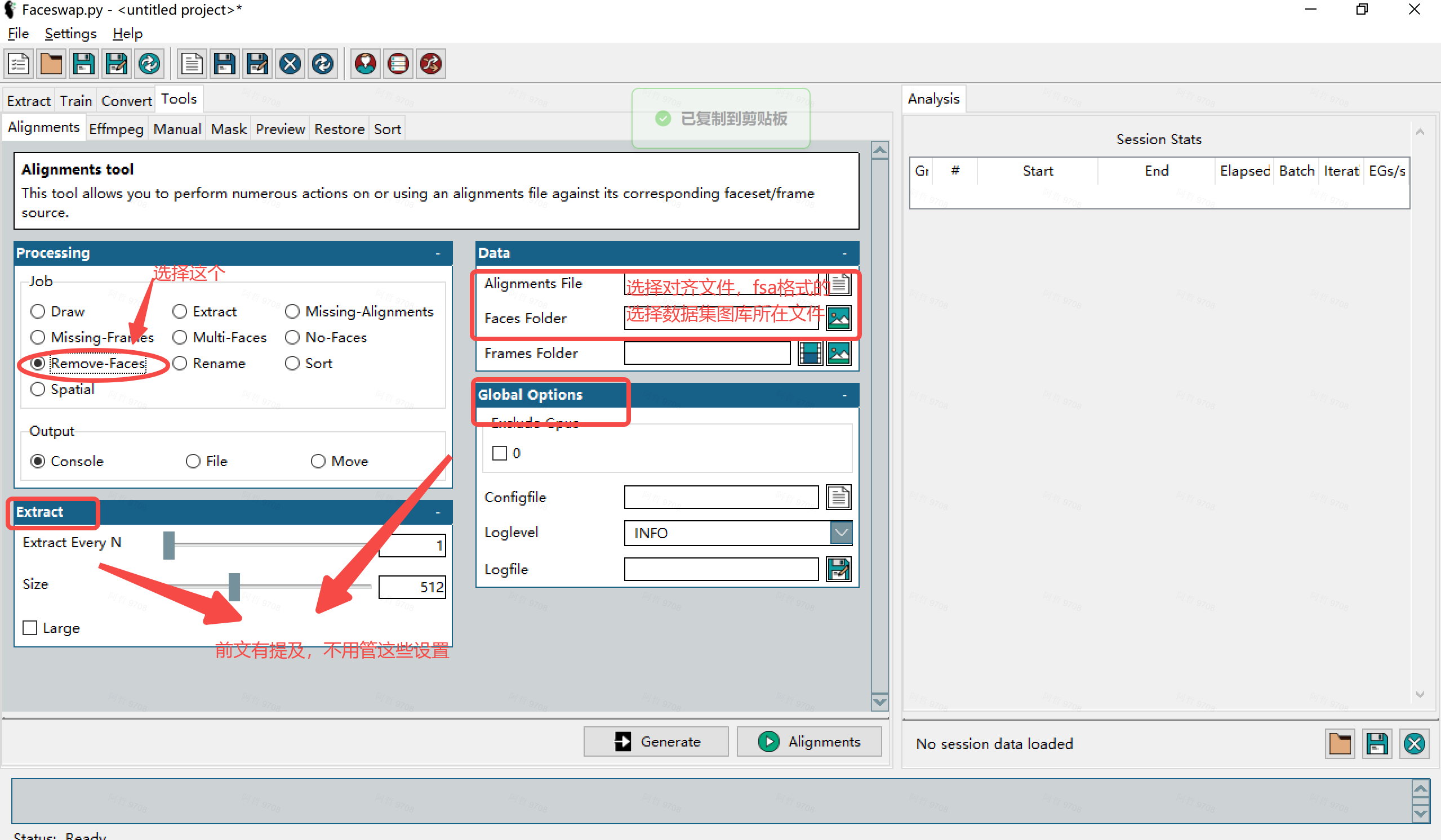
根據上圖設置后,點擊alignments,完成后面孔將被重新命名為默認名稱,并且所有不需要的面孔就會從對齊文件中刪除。
該過程將備份舊對齊文件并將其放在新創建的文件旁邊的原始位置。它將與您清理過的對齊文件同名,但在其末尾附加“backup_<timestamp>”。如果對新的對齊文件正確無誤感到滿意,則可以安全地刪除此備份文件。
此時,如果正在提取以進行轉換(或者該集合將用于轉換和訓練),那么可以完全刪除faces 文件夾。不再需要這些面孔。如果您需要重新生成面部集,則可以使用對齊工具的extract來完成。
執行完對齊文件的清理后,留下來的對齊文件就是想要訓練的有效數據集(臉)對應的對齊文件了。
手動清理對齊文件就不介紹了,詳情參照:https://forum.faceswap.dev/viewtopic.php?f=5&t=27
步驟3:從對齊文件中提取訓練集
現在已經清理了對齊文件,需要拉出其中的一些臉用于作為訓練集。
導航到工具選項卡,然后導航到對齊子選項卡:
-
Processing
此部分允許我們選擇我們希望執行的操作,以及設置任何輸出處理。我們只對Job部分感興趣。- Job:這是工具中可用的所有不同對齊工作的列表。
- 選擇extract。
- Output:忽略此部分,因為extract不會生成任何輸出
- Job:這是工具中可用的所有不同對齊工作的列表。
-
Data
我們要處理的資源所在的位置。- Alignments File:選擇上一步清理后生成的alignments文件。
- Faces Folder:選擇一個空文件夾,將輸出的面孔放在其中。
- Frames Folder:選擇提取過程輸入的視頻或幀文件夾
- 將此部分中的任何其他選項留空,因為此步驟不需要它們。
- Alignments File:選擇上一步清理后生成的alignments文件。
-
Extract
這些是從路線文件中提取人臉的選項- Extract Every N: 這將取決于您輸入的每秒幀數。然而,對于 25fps 的視頻,合理的值在大約 12 - 25 之間(即每半秒到一秒)。任何不足,你最終可能會得到太多相似的面孔。值得牢記的是,您為訓練集從中提取了多少來源,您希望在最終訓練集中擁有多少張面孔,以及您的來源有多長。這些都將根據具體情況而有所不同。
- Size:這是包含提取的人臉的圖像的大小。目前沒有模型支持 256px 以上,所以保持默認
- Large:啟用此選項將僅提取尚未放大到輸出大小的面孔。例如,如果提取大小設置為512px,而在幀中找到的人臉為480px,則不會提取。如果它是 520px,它會。
-
運行
將所有其他選項保留為默認值。準備好檢查選項,并將訓練集從清理過的對齊文件中提取到我們選擇的文件夾中。- 最終設置如下圖
- 點擊Alignments按鈕以提取面孔。
- 最終設置如下圖
完成后,將所有人臉數據集放入同一個文件夾中。訓練集已準備就緒。后續第三章將介紹訓練部分。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號