python爬蟲獲取搜狐汽車的配置信息 和swf動態(tài)圖表的銷量數(shù)據(jù)-------詳細(xì)教學(xué)
2019-08-05 11:12 凍雨冷霧 閱讀(1927) 評論(2) 收藏 舉報
前情提要:需要爬取搜狐汽車的所有配置信息,具體配置對應(yīng)的參數(shù). 以及在動態(tài)圖表上的歷史銷量。
比如: 一汽奧迪旗下Q5L 的《40 TFSI 榮享進(jìn)取型 國VI 》的歷史銷量和該配置的參數(shù)信息。
因此整體分兩個大塊,一個是配置參數(shù),一個是歷史銷量。
下面開始正文
第一步:
首先觀察網(wǎng)頁:http://db.auto.sohu.com/home/
在搜狐汽車主頁查看源代碼,找到對應(yīng)的配置信息鏈接所在DIV:
(可以任選一個汽車的配置信息頁比如奧迪A4 發(fā)現(xiàn)鏈接為 http://db.auto.sohu.com/yiqiaudi/2374
而其配置信息的頁面為 http://db.auto.sohu.com/yiqiaudi/2374/trim.html .
故需要找的是主頁內(nèi)每一款車的具體鏈接所在的div模塊 ,有了這個每次加上trim.html 進(jìn)行循環(huán)爬取即可。)
對應(yīng)DIV模塊為:

因此利用xpath定位到具體的 a標(biāo)簽下 class="model-a"即可鎖定所有車型的鏈接,代碼如下:
import requests import pandas as pd import re from lxml import etree import numpy as np import collections import pickle # 總頁面的根據(jù)字母提取子url和對應(yīng)品牌 # treeNav brand_tit url_all='https://db.auto.sohu.com/home/' req_all=requests.get(url_all) wb_all=req_all.text; #網(wǎng)頁源碼 html_all = etree.HTML(wb_all) # model-a 先獲取所有車型鏈接反推建立上層 或根據(jù)鏈接分析建立(英文不推薦) js=html_all.xpath('//a[@class="model-a"]') h=[] for i in js: h.append(i.xpath('@href')[0])
所得到的h 即為所有子鏈接的list;
第二步:
觀察某一個車型子鏈接下配置頁面的源代碼, 尋找配置的具體參數(shù)命名和具體參數(shù)的值。 如下圖
<table id="trimArglist" cellspacing="0" cellpadding="0"> <tbody> <tr id="SIP_C_102"> <th class="th1"> <div class="th1_div"> <a href="http://db.auto.sohu.com/baike/244.shtml" target="_blank">廠商指導(dǎo)價</a>: </div> </th> <td class="th2"></td> <td class="th3"> </td> <td class="th4"> </td> <td class="th5"> </td> </tr> <tr id="SIP_C_101" class="new-energy-car"> <th class="th1">補貼后售價: </th> <td class="th2"></td> <td class="th3"> </td> <td class="th4"> </td> <td class="th5"> </td> </tr> <tr id="SIP_C_103"> <th class="th1"> <a href="http://db.auto.sohu.com/baike/247.shtml" target="_blank">4S店報價</a>: </th> <td class="th2"> </td> <td class="th3"> </td> <td class="th4"> </td> <td class="th5"> </td> </tr> <tr id="ttr_0"> <th colspan="60" class="colSpan6" style="border-top: 0px"> <span>車輛基本參數(shù)</span> <span class="sqsq">收起</span> </th> </tr> <tr id="SIP_C_105"> <th class="th1"> <a href="http://db.auto.sohu.com/baike/249.shtml" target="_blank">級別</a>: </th> <td class="th2"> </td> <td class="th3"> </td> <td class="th4"> </td> <td class="th5"> </td> </tr> <tr id="SIP_C_109"> <th class="th1"> <a href="http://db.auto.sohu.com/baike/249.shtml" target="_blank">上市時間</a>: </th> <td class="th2"> </td> <td class="th3"> </td> <td class="th4"> </td> <td class="th5"> </td> </tr>
經(jīng)過觀察上圖看到,具體的配置名稱可以通過xpath定位到 table[@id="trimArglist"] 后提取內(nèi)中所有 a標(biāo)簽的名稱。 但是此處并未有具體配置的值信息。因此只是一個配置名稱的集合。
而鏈接配置名稱與配置參數(shù)值的樞紐是他的 tr id 比如上圖 中 : 上市時間的表格 id
SIP_C_109 發(fā)現(xiàn)該值出現(xiàn)在js的一個參數(shù)里: 見下圖

即調(diào)用js的參數(shù)對表格進(jìn)行賦值。鏈接樞紐是表格id代表其物理意義。
然后我們即提取id 然后搜尋js的這個賦值參數(shù)即可。
因在js中所有配置的參數(shù)賦值本身就是字典形式,即var trim={SIP_C_103:xxx,SIP_C_104:xxx}
因此直接在python中執(zhí)行這一js賦值語句即可得到一個字典,然后再將這些
id號比如SIP_C_103對應(yīng)的網(wǎng)頁div表格下a標(biāo)簽的中文進(jìn)行替換即可
代碼如下:
# 所有車 df={} df=collections.OrderedDict() for o in h: ############################################## 整車配置 ################################################# url='https:'+o+'/trim.html' req=requests.get(url) wb_data=req.text #網(wǎng)頁源碼 # xpath定位至其js賦給車輛頁面參數(shù)的地方 html = etree.HTML(wb_data) js=html.xpath('//script[@type="text/javascript"]') # 這里有很多js 尋找js內(nèi)存在參數(shù)配置備注的這一條 k=[] for i in range(len(js)): if js[i].text!=None: if len(re.findall('// 參數(shù)配置',js[i].text))!=0: k.append(js[i]); js=k.copy() js=k.copy() sss=js[0].text # 定位到具體js的某一個變量 trimParam 順便處理js賦值中TRUE 和false在python中會報錯 因此定義為字符。 sss=sss[sss.find('trimParam'):] sss=sss.replace('false','"false"') sss=sss.replace('true','"true"') # 直接調(diào)用js的賦值. 某些車輛停售或暫未發(fā)售無參數(shù)默認(rèn)就繼續(xù)循環(huán)執(zhí)行(continue) exec(sss) if len(trimParam)==0: continue # js對參數(shù)賦值時對應(yīng)的代號的物理意義:比如 SIP_C_103的意義可能是為 續(xù)航里程,把代號換掉 c=[] TB=html.xpath('//table[@id="trimArglist"]') for i in list(trimParam[0]['SIP_T_CONF'].keys()): tbname=TB[0].xpath('//table//tr[@id=\"'+i+'\"]//th[@class="th1"]') for j in range(len(trimParam)): if len(tbname)!=0: if tbname[0].text.replace(' ','')=='\n': tbname=TB[0].xpath('//tr[@id=\"'+i+'\"]//th[@class="th1"]//a') c.append(tbname[0].text) trimParam[j]['SIP_T_CONF'][tbname[0].text] = trimParam[j]['SIP_T_CONF'].pop(i) try: trimParam[j]['SIP_T_CONF'][tbname[0].text]=trimParam[j]['SIP_T_CONF'][tbname[0].text]['v'] except: trimParam[j]['SIP_T_CONF'][tbname[0].text]=''; #車輛沒有的配置數(shù)據(jù)不進(jìn)行記錄 if (trimParam[j]['SIP_T_CONF'][tbname[0].text]=='-') | (trimParam[j]['SIP_T_CONF'][tbname[0].text]==''): # 車輛配置里-代表車無此配置廠商也無法進(jìn)行安裝此配置 del trimParam[j]['SIP_T_CONF'][tbname[0].text] else: # 某些配置在js中沒有參數(shù)進(jìn)行賦值,發(fā)現(xiàn)是一些復(fù)寫的參數(shù)比如已有長寬高的信息和參數(shù)值,但是存在名字為長的信息但沒有賦值,因此不要 c.append(np.nan) del trimParam[j]['SIP_T_CONF'][i] trimParam_dict={} for i in range(len(trimParam)): trimParam_dict[trimParam[i]['SIP_T_NAME']]=trimParam[i]; # 反推建立數(shù)據(jù)字典 if trimParam[0]['brandName'] not in df.keys(): df[trimParam[0]['brandName']]={} if trimParam[0]['subbrandName'] not in df[trimParam[0]['brandName']].keys(): df[trimParam[0]['brandName']][trimParam[0]['subbrandName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']][trimParam[0]['modelName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']][trimParam[0]['modelName']]['配置參數(shù)']=trimParam_dict
最后反推建立字典是根據(jù)配置里的品牌,子品牌,車輛配置名稱信息建立上層字典的key來定位自身。
至此配置信息的字典格式就完成了,因為訪問每一個車型時都會進(jìn)行數(shù)據(jù)處理,因此訪問間隔不會太短導(dǎo)致被反爬機制封掉。
接下來是動態(tài)圖表的銷量信息 ,我們希望承接上文,在每一個子品牌的車型旗下直接新建一個key(本來只有上文的配置參數(shù)key),讓他記錄歷史的銷量信息。
首先動態(tài)圖表的歷史數(shù)據(jù)在網(wǎng)頁源碼上搜不到,那么我們調(diào)用瀏覽器的控制臺來觀察他在動態(tài)圖表上顯示數(shù)據(jù)的整個響應(yīng)過程,通過這個來找圖表調(diào)用的數(shù)據(jù)來源是什么。
打開控制臺觀察一個車型子鏈接的銷量頁面。見下圖:

左側(cè)為動態(tài)圖表,右側(cè)為控制臺,現(xiàn)在我們點一下全部數(shù)據(jù)

響應(yīng)的信息數(shù)據(jù)出現(xiàn)了,見右側(cè)控制臺xml參數(shù),觀察xml的header(當(dāng)前是response返回的數(shù)據(jù))
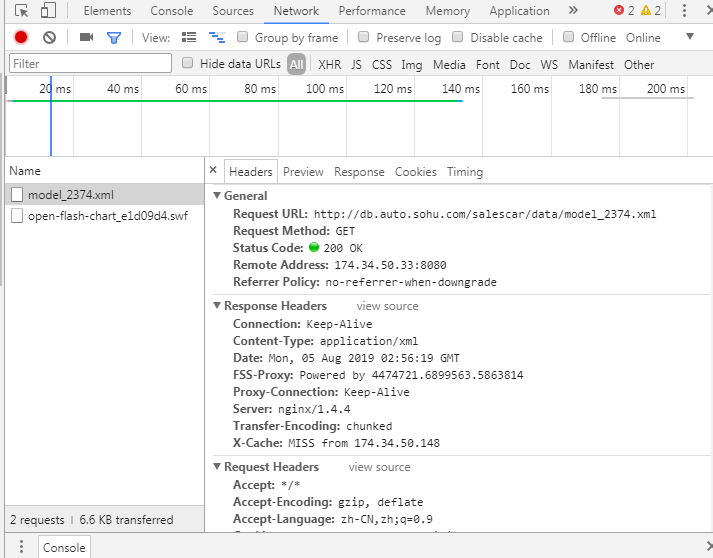
不難發(fā)現(xiàn)數(shù)據(jù)是從這個 鏈接得到的,如下圖:
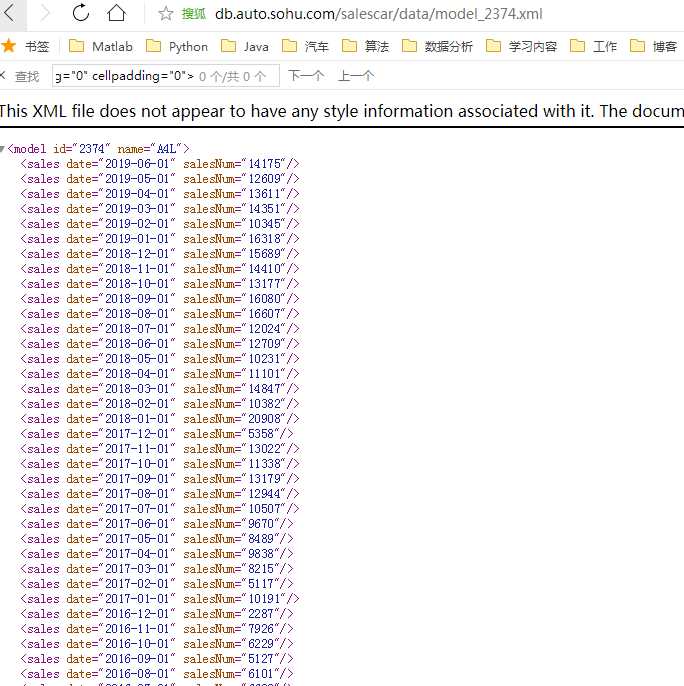
這跟我們車型的關(guān)系樞紐就是model后的那一串?dāng)?shù)字 即為車型id號的鏈接,那么每一款車型的id號知道了,就能獲取每一個銷量數(shù)據(jù)的鏈接,
車型id號 恰好我們在調(diào)用js賦值時發(fā)現(xiàn)是有的 那么在之前的循環(huán)中 提取id號 然后處理銷量數(shù)據(jù)即可,代碼如下面的銷量數(shù)據(jù)部分:
for o in h: ############################################## 整車配置 ################################################# url='https:'+o+'/trim.html' req=requests.get(url) wb_data=req.text #網(wǎng)頁源碼 # xpath定位至其js賦給車輛頁面參數(shù)的地方 html = etree.HTML(wb_data) js=html.xpath('//script[@type="text/javascript"]') # 這里有很多js 尋找js內(nèi)存在參數(shù)配置備注的這一條 k=[] for i in range(len(js)): if js[i].text!=None: if len(re.findall('// 參數(shù)配置',js[i].text))!=0: k.append(js[i]); js=k.copy() js=k.copy() sss=js[0].text # 定位到具體js的某一個變量 trimParam sss=sss[sss.find('trimParam'):] sss=sss.replace('false','"false"') sss=sss.replace('true','"true"') # 直接調(diào)用js的賦值. exec(sss) if len(trimParam)==0: continue # js對參數(shù)賦值時對應(yīng)的代號的物理意義:比如 SIP_C_103的意義可能是為 續(xù)航里程,把代號換掉 c=[] TB=html.xpath('//table[@id="trimArglist"]') for i in list(trimParam[0]['SIP_T_CONF'].keys()): tbname=TB[0].xpath('//table//tr[@id=\"'+i+'\"]//th[@class="th1"]') for j in range(len(trimParam)): if len(tbname)!=0: if tbname[0].text.replace(' ','')=='\n': tbname=TB[0].xpath('//tr[@id=\"'+i+'\"]//th[@class="th1"]//a') c.append(tbname[0].text) trimParam[j]['SIP_T_CONF'][tbname[0].text] = trimParam[j]['SIP_T_CONF'].pop(i) try: trimParam[j]['SIP_T_CONF'][tbname[0].text]=trimParam[j]['SIP_T_CONF'][tbname[0].text]['v'] except: trimParam[j]['SIP_T_CONF'][tbname[0].text]=''; #車輛沒有的配置數(shù)據(jù)不進(jìn)行記錄 if (trimParam[j]['SIP_T_CONF'][tbname[0].text]=='-') | (trimParam[j]['SIP_T_CONF'][tbname[0].text]==''): # 車輛配置里-代表車無此配置廠商也無法進(jìn)行安裝此配置 del trimParam[j]['SIP_T_CONF'][tbname[0].text] else: # 某些配置在js中沒有參數(shù)進(jìn)行賦值,發(fā)現(xiàn)是一些復(fù)寫的參數(shù)比如已有長寬高的信息和參數(shù)值,但是存在名字為長的信息但沒有賦值,因此不要 c.append(np.nan) del trimParam[j]['SIP_T_CONF'][i] trimParam_dict={} for i in range(len(trimParam)): trimParam_dict[trimParam[i]['SIP_T_NAME']]=trimParam[i]; # 反推建立數(shù)據(jù)字典 if trimParam[0]['brandName'] not in df.keys(): df[trimParam[0]['brandName']]={} if trimParam[0]['subbrandName'] not in df[trimParam[0]['brandName']].keys(): df[trimParam[0]['brandName']][trimParam[0]['subbrandName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']][trimParam[0]['modelName']]={} df[trimParam[0]['brandName']][trimParam[0]['subbrandName']][trimParam[0]['modelName']]['配置參數(shù)']=trimParam_dict ############################################## 銷量數(shù)據(jù) ################################################# vehicle_model_id= trimParam[0]['SIP_T_MODELID'] url='https://db.auto.sohu.com/cxdata/xml/sales/model/model'+str(vehicle_model_id)+'sales.xml' req=requests.get(url) wb_data=req.text #網(wǎng)頁源碼 sales=re.findall(r'(?<=<sales).*?(?=/>)',wb_data) if len(sales)==0: continue; else: df[trimParam[0]['brandName']][trimParam[0]['subbrandName']][trimParam[0]['modelName']]['歷史銷量']={} for i in sales: df[trimParam[0]['brandName']][trimParam[0]['subbrandName']][trimParam[0]['modelName']]['歷史銷量'][re.findall(r'(?<=date=").*?(?=")',i)[0]]=int(re.findall(r'(?<=salesNum=").*?(?=")',i)[0]) print(trimParam[0]['subbrandName']+trimParam[0]['modelName']+'--num'+str(h.index(o))+'--total:'+str(len(h)))
至此整個字典就定義好了,最上層為品牌,其次是子品牌,然后是配置,最后分銷量和配置信息。
接下來要么就已字典的格式利用pymongo存到mongodb里去,要么改成dataframe格式存入sql都可。 需要注意的是mongodb存入的過程中 字典key不可以出現(xiàn)" ."點的符號 因此需要替換。
給出一個替換函數(shù)供參考


# fix 字典內(nèi)keys含有.并替換 def fix_dict(data, ignore_duplicate_key=True): """ Removes dots "." from keys, as mongo doesn't like that. If the key is already there without the dot, the dot-value get's lost. This modifies the existing dict! :param ignore_duplicate_key: True: if the replacement key is already in the dict, now the dot-key value will be ignored. False: raise ValueError in that case. """ if isinstance(data, (list, tuple)): list2 = list() for e in data: list2.append(fix_dict(e)) # end if return list2 if isinstance(data, dict): # end if for key, value in data.items(): value = fix_dict(value) old_key = key if "." in key: key = old_key.replace(".", "_") if key not in data: data[key] = value else: error_msg = "Dict key {key} containing a \".\" was ignored, as {replacement} already exists".format( key=key_old, replacement=key) if force: import warnings warnings.warn(error_msg, category=RuntimeWarning) else: raise ValueError(error_msg) # end if # end if del data[old_key] # end if data[key] = value # end for return data # end if return data # end def df_2=fix_dict(df);
我這里做成一個首字母的key在品牌之前,然后按照pkl的格式保存到本地
#按照首字母檢索的字典 for letter in range(65,91): df2[chr(letter)]={} for i in df.keys(): df2[lazy_pinyin(i)[0][0].upper()][i]=df[i] #本地文件保存 output = open('soho_vehicle.pkl', 'wb') pickle.dump(df2, output) output.close()
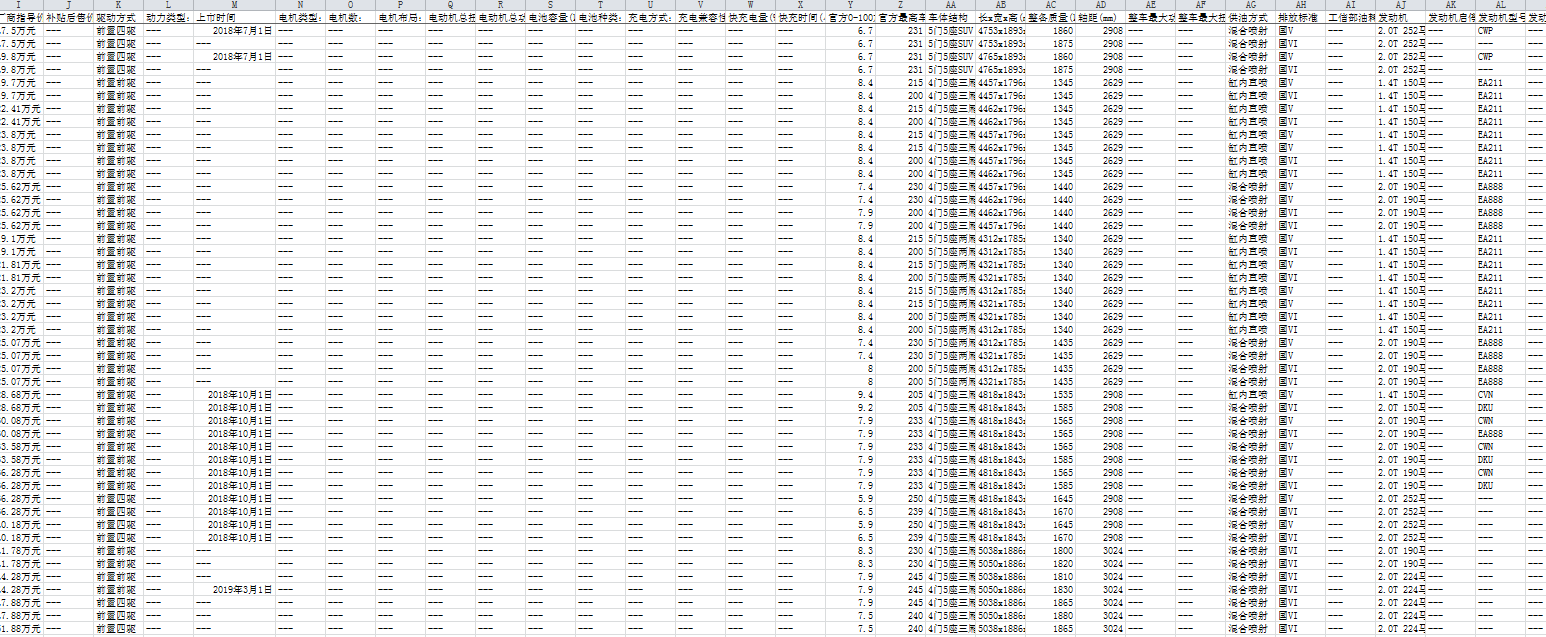
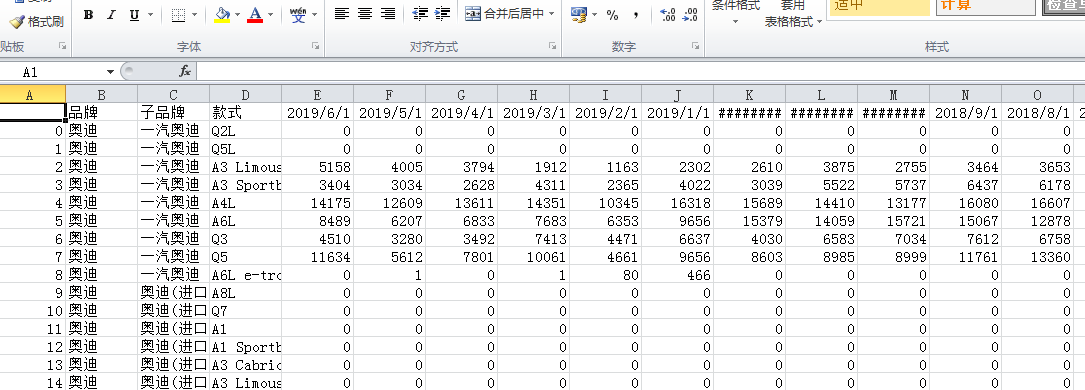
后續(xù)也可以再處理存到sql 并另存為csv或excel 用于查看。
import pandas as pd import numpy as np import pickle output = open('soho_vehicle.pkl', 'wb') df=pickle.load(output) output.close() # 配置信息整理 a=[] for o in df.keys(): for i in df[o].keys(): for j in df[o][i].keys(): for k in df[o][i][j]['配置參數(shù)'].keys(): df[o][i][j]['配置參數(shù)'][k]['SIP_T_CONF']['子品牌']=df[o][i][j]['配置參數(shù)'][k]['subbrandName'] df[o][i][j]['配置參數(shù)'][k]['SIP_T_CONF']['品牌']=df[o][i][j]['配置參數(shù)'][k]['brandName'] df[o][i][j]['配置參數(shù)'][k]['SIP_T_CONF']['款式']=df[o][i][j]['配置參數(shù)'][k]['modelName'] df[o][i][j]['配置參數(shù)'][k]['SIP_T_CONF']['配置名稱']=df[o][i][j]['配置參數(shù)'][k]['SIP_T_NAME'] df[o][i][j]['配置參數(shù)'][k]['SIP_T_CONF']['是否電動']=df[o][i][j]['配置參數(shù)'][k]['SIP_C_ISELECTRIC'] a.append(pd.Series(df[o][i][j]['配置參數(shù)'][k]['SIP_T_CONF'])) df_trim=pd.DataFrame(a) df_trim=df_trim.replace(np.nan,'---'); cols = list(df_trim) for i in cols: df_trim[i]=df_trim[i].str.strip(); df_trim[i]=df_trim[i].apply(lambda x:x.replace('m3','立方米')) df_trim[i]=df_trim[i].apply(lambda x:x.replace('\xa0',' ')) #df_trim['配置名稱']=df_trim['配置名稱'].apply(lambda x:x.replace('m3','立方米')) cols=list(pd.Series(cols).str.strip()); cols.insert(0, cols.pop(cols.index('保修政策'))) cols.insert(0, cols.pop(cols.index('車聯(lián)網(wǎng):'))) cols.insert(0, cols.pop(cols.index('自動泊車入位'))) cols.insert(0, cols.pop(cols.index('車身穩(wěn)定控制'))) cols.insert(0, cols.pop(cols.index('車載信息服務(wù)'))) cols.insert(0, cols.pop(cols.index('車道保持輔助系統(tǒng):'))) cols.insert(0, cols.pop(cols.index('車道偏離預(yù)警系統(tǒng):'))) cols.insert(0, cols.pop(cols.index('倒車車側(cè)預(yù)警系統(tǒng):'))) cols.insert(0, cols.pop(cols.index('主動剎車/主動安全系統(tǒng)'))) cols.insert(0, cols.pop(cols.index('中央差速器結(jié)構(gòu)'))) cols.insert(0, cols.pop(cols.index('底盤結(jié)構(gòu)'))) cols.insert(0, cols.pop(cols.index('轉(zhuǎn)向助力'))) cols.insert(0, cols.pop(cols.index('輪轂材料'))) cols.insert(0, cols.pop(cols.index('進(jìn)氣形式:'))) cols.insert(0, cols.pop(cols.index('每缸氣門數(shù)(個)'))) cols.insert(0, cols.pop(cols.index('氣門結(jié)構(gòu)'))) cols.insert(0, cols.pop(cols.index('汽缸容積(cc)'))) cols.insert(0, cols.pop(cols.index('汽缸排列形式'))) cols.insert(0, cols.pop(cols.index('最大馬力(ps)'))) cols.insert(0, cols.pop(cols.index('最大扭矩(N·m/rpm)'))) cols.insert(0, cols.pop(cols.index('最大功率(kW/rpm)'))) cols.insert(0, cols.pop(cols.index('擋位個數(shù)'))) cols.insert(0, cols.pop(cols.index('變速箱類型'))) cols.insert(0, cols.pop(cols.index('變速箱'))) cols.insert(0, cols.pop(cols.index('壓縮比'))) cols.insert(0, cols.pop(cols.index('發(fā)動機電子防盜'))) cols.insert(0, cols.pop(cols.index('發(fā)動機型號'))) cols.insert(0, cols.pop(cols.index('發(fā)動機啟停技術(shù)'))) cols.insert(0, cols.pop(cols.index('發(fā)動機'))) cols.insert(0, cols.pop(cols.index('工信部油耗(L/100km)'))) cols.insert(0, cols.pop(cols.index('排放標(biāo)準(zhǔn)'))) cols.insert(0, cols.pop(cols.index('供油方式'))) cols.insert(0, cols.pop(cols.index('整車最大扭矩(N·m):'))) cols.insert(0, cols.pop(cols.index('整車最大功率(kW):'))) cols.insert(0, cols.pop(cols.index('軸距(mm)'))) cols.insert(0, cols.pop(cols.index('整備質(zhì)量(kg)'))) cols.insert(0, cols.pop(cols.index('長x寬x高(mm)'))) cols.insert(0, cols.pop(cols.index('車體結(jié)構(gòu)'))) cols.insert(0, cols.pop(cols.index('官方最高車速(km/h)'))) cols.insert(0, cols.pop(cols.index('官方0-100加速(s)'))) cols.insert(0, cols.pop(cols.index('快充時間(小時):'))) cols.insert(0, cols.pop(cols.index('快充電量(%):'))) cols.insert(0, cols.pop(cols.index('充電兼容性:'))) cols.insert(0, cols.pop(cols.index('充電方式:'))) cols.insert(0, cols.pop(cols.index('電池種類:'))) cols.insert(0, cols.pop(cols.index('電池容量(kWh):'))) cols.insert(0, cols.pop(cols.index('電動機總功率(kW):'))) cols.insert(0, cols.pop(cols.index('電動機總扭矩(N·m):'))) cols.insert(0, cols.pop(cols.index('電動機總扭矩(N·m):'))) cols.insert(0, cols.pop(cols.index('電機布局:'))) cols.insert(0, cols.pop(cols.index('電機數(shù):'))) cols.insert(0, cols.pop(cols.index('電機類型:'))) cols.insert(0, cols.pop(cols.index('上市時間'))) cols.insert(0, cols.pop(cols.index('動力類型:'))) cols.insert(0, cols.pop(cols.index('驅(qū)動方式'))) cols.insert(0, cols.pop(cols.index('補貼后售價:'))) cols.insert(0, cols.pop(cols.index('4S店報價'))) cols.insert(0, cols.pop(cols.index('廠商指導(dǎo)價'))) cols.insert(0, cols.pop(cols.index('級別'))) cols.insert(0, cols.pop(cols.index('百公里耗電量(kWh/100km):'))) cols.insert(0, cols.pop(cols.index('是否電動'))) cols.insert(0, cols.pop(cols.index('配置名稱'))) cols.insert(0, cols.pop(cols.index('款式'))) cols.insert(0, cols.pop(cols.index('子品牌'))) cols.insert(0, cols.pop(cols.index('品牌'))) df_trim = df_trim.ix[:, cols] df_trim=df_trim.replace(np.nan,'---'); df_trim=df_trim.drop(['高度(mm)','長度(mm)','寬度(mm)'],axis=1) df_trim=df_trim.drop(['車門數(shù)(個)','4S店報價'],axis=1) df_trim.to_csv('soho_veh_trim_para.csv',encoding='gbk') #銷量 a=[] for o in df.keys(): for i in df[o].keys(): for j in df[o][i].keys(): try: k=list(df[o][i][j]['配置參數(shù)'].keys())[0]; df[o][i][j]['銷量']['子品牌']=df[o][i][j]['配置參數(shù)'][k]['subbrandName'] df[o][i][j]['銷量']['品牌']=df[o][i][j]['配置參數(shù)'][k]['brandName'] df[o][i][j]['銷量']['款式']=df[o][i][j]['配置參數(shù)'][k]['modelName'] a.append(pd.Series(df[o][i][j]['銷量'])) except: continue df_sales=pd.DataFrame(a) cols = list(df_sales) cols.reverse() cols.insert(0, cols.pop(cols.index('款式'))) cols.insert(0, cols.pop(cols.index('子品牌'))) cols.insert(0, cols.pop(cols.index('品牌'))) df_sales = df_sales.ix[:, cols] df_sales=df_sales.fillna(0) df_sales.to_csv('soho_veh_sales.csv',encoding='gbk') #存入 sql from sqlalchemy import create_engine import pandas as pd import numpy as np from sqlalchemy.types import VARCHAR host = '127.0.0.1' port= 3306 db = 'soho_vehicle' user = 'root' password = 'twz1478963' engine = create_engine(str(r"mysql+mysqldb://%s:" + '%s' + "@%s/%s?charset=utf8") % (user, password, host, db)) df_sales.to_sql('soho_veh_sales', con=engine, if_exists='append', index=False) #如量級過大使用chunksize df_trim=df_trim.drop(['內(nèi)飾可選顏色','車身可選顏色'],axis=1) df_trim.to_sql('soho_veh_trim', con=engine, if_exists='append', index=False) #如量級過大使用chunksize

歡迎交流!

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號