
布隆過濾器
布隆過濾器
譚文濤 2021-12-24
假如你在程序員的面試中碰到如下問題,你該如何回答:
1、 比如中國現(xiàn)在接種第3針加強(qiáng)針新冠疫苗的人數(shù)已超過10億,怎樣快速判斷出一位持有中國身份證的居民沒有接種第3針疫苗?
2、 因?yàn)槟愫皖I(lǐng)導(dǎo)喜歡公司同一個(gè)妹子,你的領(lǐng)導(dǎo)想辭退你,但你平時(shí)的工作和考勤表現(xiàn)都無可挑剔。于是他給你一臺(tái)內(nèi)存是2G的筆記本電腦和A,B兩個(gè)文件,每個(gè)文件各存放50億條URL,每條URL占用64字節(jié),讓你找出A,B文件所有共同的URL,你咋辦?
3、 之前被你領(lǐng)導(dǎo)排擠走的程序員非常氣憤,于是寫了個(gè)程序大批量頻繁調(diào)用公司的http接口目的是攻擊公司的數(shù)據(jù)庫。雖然公司用了redis緩存,但由于他之前在公司干過,他的接口入?yún)⑷际蔷彺嬷胁淮嬖诘模紦舸┝藃edis去訪問數(shù)據(jù)庫,領(lǐng)導(dǎo)眼看數(shù)據(jù)庫每天都蹦,正好把鍋甩給你,讓你解決這個(gè)redis被擊穿的問題,你咋處理?
其實(shí)上面三個(gè)問題的解答辦法都是同一種,那就是“布隆過濾器”——BloomFilter
。下面我們來揭開他的神秘面紗
1、什么事布隆過濾器
布隆過濾器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它實(shí)際上是由一個(gè)很長的二進(jìn)制向量和一系列隨機(jī)映射函數(shù)組成,布隆過濾器可以用于檢索一個(gè)元素是否在一個(gè)集合中。它的優(yōu)點(diǎn)是空間效率和查詢時(shí)間都遠(yuǎn)遠(yuǎn)超過一般的算法,缺點(diǎn)是有一定的誤識(shí)別率和刪除困難,但是沒有識(shí)別錯(cuò)誤的情形(即如果某個(gè)元素確實(shí)沒有在該集合中,那么Bloom Filter 是不會(huì)報(bào)告該元素存在于集合中的,所以不會(huì)漏報(bào))。
2、布隆過濾器的基本原理
如果想判斷一個(gè)元素是不是在一個(gè)集合里,一般是將集合中所有元素保存起來,然后通過比較確定。鏈表、樹、哈希表等數(shù)據(jù)結(jié)構(gòu)都是這種思路。但是隨著集合元素的增加需要的存儲(chǔ)空間越大,檢索速度也越慢。
應(yīng)該蠻多人會(huì)說用 HashMap 吧,確實(shí)可以將值映射到 HashMap 的 Key,然后可以在 O(1) 的時(shí)間復(fù)雜度內(nèi)返回結(jié)果,效率奇高。但是 HashMap 的實(shí)現(xiàn)也有缺點(diǎn),例如存儲(chǔ)容量占比高。還比如說你的數(shù)據(jù)集存儲(chǔ)在遠(yuǎn)程服務(wù)器上,本地服務(wù)接受輸入,而數(shù)據(jù)集非常大不可能一次性讀進(jìn)內(nèi)存構(gòu)建 HashMap 的時(shí)候,也會(huì)存在問題。
接下來讓我們看看“布隆過濾器”是怎么解決這個(gè)問題的:
布隆過濾器是一個(gè) bit 向量或者說 bit 數(shù)組(超長超長,記住一定要足夠長),長這樣:

我們要映射一個(gè)值到布隆過濾器中,我們需要使用多個(gè)不同的哈希函數(shù)生成多個(gè)哈希值,并對每個(gè)生成的哈希值指向的 bit 位置 1,例如針對值 “baidu” 和三個(gè)不同的哈希函數(shù)分別生成了哈希值 1、4、7,則上圖轉(zhuǎn)變?yōu)椋?/p>
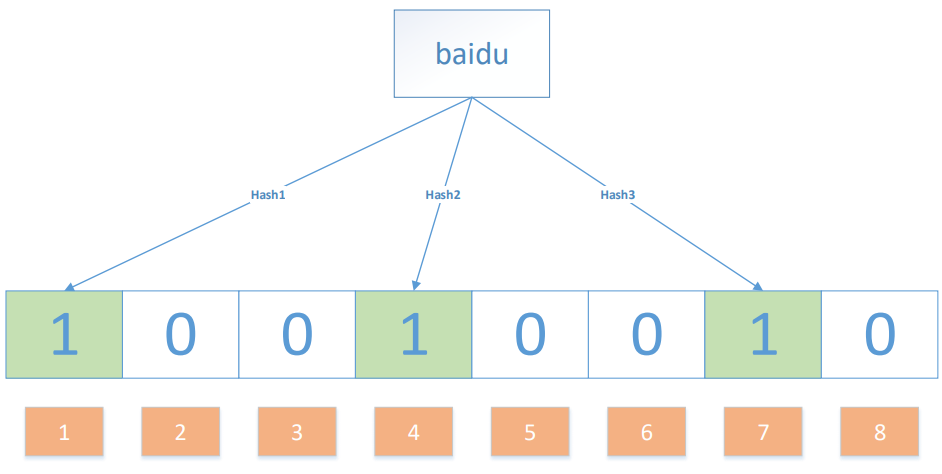
Ok,我們現(xiàn)在再存一個(gè)值 “tencent”,如果哈希函數(shù)返回 3、4、8 的話,圖繼續(xù)變?yōu)椋?/p>

值得注意的是,4 這個(gè) bit 位由于兩個(gè)值的哈希函數(shù)都返回了這個(gè) bit 位,因此它被覆蓋了。現(xiàn)在我們?nèi)绻氩樵?“dianping” 這個(gè)值是否存在,哈希函數(shù)返回了 1、5、8三個(gè)值,結(jié)果我們發(fā)現(xiàn) 5 這個(gè) bit 位上的值為 0,說明沒有任何一個(gè)值映射到這個(gè) bit 位上,因此我們可以很確定地說 “dianping” 這個(gè)值不存在。
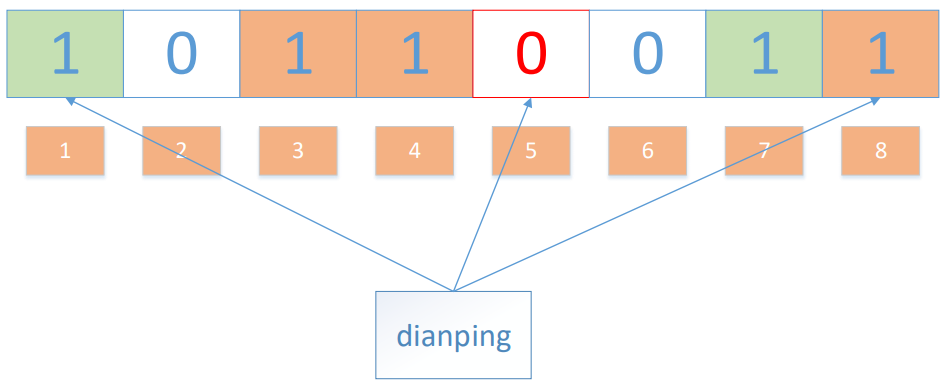
而當(dāng)我們需要查詢 “baidu” 這個(gè)值是否存在的話,那么哈希函數(shù)必然會(huì)返回 1、4、7,然后我們檢查發(fā)現(xiàn)這三個(gè) bit 位上的值均為 1,那么我們可以說 “baidu” 存在了么?答案是不可以,只能是 “baidu” 這個(gè)值可能存在。這是為什么呢?答案跟簡單,因?yàn)殡S著增加的值越來越多,被置為 1 的 bit 位也會(huì)越來越多,這樣某個(gè)值 “taobao” 即使沒有被存儲(chǔ)過,但是萬一哈希函數(shù)返回的三個(gè) bit 位都被其他值置位了 1 ,那么程序還是會(huì)判斷 “taobao” 這個(gè)值存在。
為什么我上面說布隆過濾器的bit數(shù)組要足夠長?
很顯然,過小的布隆過濾器很快所有的 bit 位均為 1,那么查詢?nèi)魏沃刀紩?huì)返回“可能存在”,起不到過濾的目的了。布隆過濾器的長度會(huì)直接影響誤報(bào)率,布隆過濾器越長其誤報(bào)率越小。
布隆過濾器的算法總結(jié):
1.初始化時(shí),需要一個(gè)長度為n比特的數(shù)組,每個(gè)比特位初始化為0;
2. 然后需要準(zhǔn)備k個(gè)hash函數(shù),每個(gè)函數(shù)可以把key散列成為1個(gè)整數(shù);
3. 某個(gè)key加入集合時(shí),用k個(gè)hash函數(shù)計(jì)算出k個(gè)散列值,并把bit數(shù)組中對應(yīng)的比特位置為1;
4. 判斷某個(gè)key是否在集合時(shí),用k個(gè)hash函數(shù)計(jì)算出k個(gè)散列值,并查詢數(shù)組中對應(yīng)的比特位,如果有比特位是0,則該key一定不在集合中。
3、布隆過濾器的典型應(yīng)用
布隆在海量數(shù)據(jù)查詢中以優(yōu)異的空間效率和低誤判率有非常廣泛的應(yīng)用,其中包括但不限于:
(1)檢查單詞拼寫正確性
(2)檢測海量名單嫌疑人
(3)垃圾郵件過濾
(4)搜索爬蟲URL去重
(5)緩存穿透過濾
世界上著名各大科技公司使用布隆過濾器的實(shí)際案例:
Google 著名的分布式數(shù)據(jù)庫 Bigtable 使用了布隆過濾器來查找不存在的行或列,以減少磁盤查找的IO次數(shù)。
Squid 網(wǎng)頁代理緩存服務(wù)器在 cache digests 中使用了也布隆過濾器。
Venti 文檔存儲(chǔ)系統(tǒng)也采用布隆過濾器來檢測先前存儲(chǔ)的數(shù)據(jù)。
SPIN 模型檢測器也使用布隆過濾器在大規(guī)模驗(yàn)證問題時(shí)跟蹤可達(dá)狀態(tài)空間。
Google Chrome瀏覽器使用了布隆過濾器加速安全瀏覽服務(wù)。
4、結(jié)語
本質(zhì)上布隆過濾器是一種數(shù)據(jù)結(jié)構(gòu),比較巧妙的概率型數(shù)據(jù)結(jié)構(gòu)(probabilistic data structure),特點(diǎn)是高效地插入和查詢,可以用來告訴你 “某樣?xùn)|西一定不存在或者可能存在”。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)