
[論文筆記] Combining Formal and Informal Information in Bayesian Program Analysis via Soft Evidences
Background Information
擺了兩三天覺得不能再開擺了,感覺至少把什么是貝葉斯方法及其名詞搞懂(雖然可能概率論學過,但是已經忘干凈了):
貝葉斯的思考方式:先驗概率 \(\pi(\theta)\) + 樣本信息 \(X\) -> 后驗概率 \(\pi(\theta | X)\) 不斷根據新的證據更新我們的信念
事件 \(A\):樣本空間 \(\Omega\) 上的一個子集
概率 \(P\):某個事件發生的概率,可以看作 \(\Omega\) 的子集到區間 \([0, 1]\) 的一個函數:\(2^{\Omega} \rightarrow [0, 1]\),且滿足規范性、非負性、有限可加性
隨機變量 \(X\):定義在樣本空間上的函數,可以看作樣本空間到數學空間的一個映射,對于拋硬幣問題,\(\{正面, 反面\}\) 可以被映射為 \(\{0, 1\}\) 引入隨機變量為了用實數來簡化表達原來的樣本空間,有個不太理解的點,隨機變量的既然是個函數,“取值”又是怎么定義的呢(\(X\) 滿足對任意取值 \(x\) \(\{\omega | X(\omega)\ <= x\} \in F\))感覺還需要好好地學習一下概率論
條件概率(后驗概率):事件 A 在事件 B 發生的情況下發生的概率 記作 \(P(A|B)\)
聯合概率:事件 A 和事件 B 同時發生的概率 記作 \(P(A, B)\) \(P(AB)\) \(P(A \cap B)\)
邊緣概率(先驗概率):事件 A 發生的概率 記作 \(P(A)\)
\(P(A|B) = \frac{P(AB)}{P(B)}\)
根據條件概率的定義可以推出 \(P(A|B) = \frac{P(B|A)P(A)}{P(B)}\)
對于隨機變量的定義類似
使用一組隨機變量 \(\{X_1, X_2, ..., X_n\}\) 刻畫事件,把問題表示為一個聯合概率分布 \(P(X_1, X_2, ..., X_n)\),假設對于一個 \(X_i\) 存在一個隨機變量的子集 \(\pi(X_i)\),使得 \(X_i\) 與不屬于該子集的所有隨機變量相互(邊緣)獨立,那么 \(P(X_i|X_1, X_2, ..., X_{i-1}) = P(X_i|\pi(X_i))\),即(根據鏈規則) \(P(X_1, X_2, ..., X_n) = \Pi P(X_i|\pi(X_i))\),可以根據 \(\pi(X_i)\) 對隨機變量刻畫一組邊結構
貝葉斯網絡的有向無環圖中的結點 \(V\) 表示隨機變量,有向邊 \(E\) 表示條件概率,假設有邊 \((X, Y)\) 那么權重為 \(P(Y|X)\)
不同的隨機變量順序會導致不同的網絡結構,建議用因果關系
既然已經把隨機變量之間的關系用圖來刻畫,那么可以用圖的方法描述隨機變量之間的關系,隨機變量之間的關系對應圖上結點的分隔,可以被劃分為三種形式:

-
順連:如果 \(Z\) 未知,那么 \(X\) 會影響 \(Z\),從而間接影響 \(Y\),這個比較好理解
-
分連:還不太理解
-
匯連:還不太理解
阻塞:根據順連、分連、匯連劃分為三種,如果一個節點的集合 \(Z\) 阻塞了 \(X\) 和 \(Y\) 之間的所有通路,那么就說 \(Z\) 有向分隔(d-分隔) \(X\) 和 \(Y\)。如果 \(Z\) 有向分隔 \(X\) 和 \(Y\),那么在 \(Z\) 確定時,\(X\) 和 \(Y\) 條件獨立。
Introduction
soft evidence:不確定的觀測信息,反映概率性觀測
soundness:程序分析是否能夠捕獲程序的所有行為(實際上學術界和工業界的分析工具/分析方法都是 unsound 的,所以還有一個 soundy/soundiness 的概念)
三個問題:
-
怎么把 soft evidence 和現有的分析工具/分析方法合并而不破壞其 soundness?
-
怎么自動化地進行上面的合并?
-
怎么提取 soft evidence?
方法:提出了一種 neural-network 的方法來解決上面的問題:
-
在現有的使用 Datalog 的分析工具中引入概率信息(Problog),把傳統的邏輯分析方法轉換成貝葉斯模型,soft evidence 會逐步增加對于某個證據的信心,但是不會破壞分析能夠捕獲的行為(只是排了個序)
-
引入神經網絡來判別程序中 informal facts 的可能性,并將其輸出編碼成 soft evidence 給貝葉斯模型使用。
結果很有效
Overview
有一個例子:一個 Java 代碼及一個 Datalog 實現的指針分析

顯然 R1 對應的類型轉換是安全的,R2 對應的類型轉換是不安全的

一開始沒太細看這個 Datalog,發現例子看不懂了,還是要看一下:
pointsTo(V, H) :- allocation(V, H)
內存分配對應指針指向,V 和 H 分別代表變量和堆(對堆建模后的一個結果?)
pointsTo(V, H) :- move(U, V), pointsTo(U, H)
如果存在兩個指針間的賦值關系,認為他們指向同一個對象
fieldPointsTo(H1, F, H2) :- putField(V, F, U), pointsTo(V, H1), pointsTo(U, H2)
pointsTo(U, H2) :- getField(V, F, U), pointsTo(V, H1), fieldPointsTo(H1, F, H2)
如果給變量 V 的字段 F 賦值變量 U,且 V 和 U 分別指向對象 H1, H2,那么認為 H1 的字段 F 指向 H2;取出字段類似
unsafeDowncast(L) :- downcast(L, T1, V), pointsTo(V, H), typeOf(H, T2), !subType(T2, T1)
不安全的類型轉換,如果位置 L 上存在一個類型轉換從變量指向的對象的原類型 T2 轉換到 T1,且 T2 不是 T1 的子類型,那么這個類型轉換是不安全的
-
流不敏感:不考慮語句的執行順序
-
上下文不敏感:不考慮運行時上下文
在流不敏感和上下文不敏感,但是字段敏感的前提下,這個指針分析會給出兩個不安全的類型轉換:unsafeDowncast(9) 和 unsafeDowncast(17),顯然 9 是個誤報,為了解決這個誤報,不得不使這個指針分析變得流敏感,這個開銷就有點大了
但是對于人類程序員來說,類型轉換的正確性是很容易被“猜測”的(作為一個證據有一定的置信度),dog 轉到 animal 看上去就很行(dog is an animal),dog 轉到 dolphin 看上去就不太行(dog is not a dolphin)。

首先把這個 Datalog 轉成 Problog,通過上面的例子發現取出字段的規則是造成誤報的原因(流不敏感),因此把它的置信度調成 0.9

為了合并 informal information,需要添加一個新的規則。通過上面的例子引入一個 ailas 規則,置信度也給 0.9:
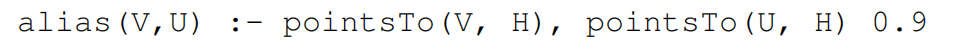
使用 GraphCodeBert + 微調(2 層全連接)判斷 ailas 作為 soft evidence 的可信度,alias(dolphin, dog1) 是 0.79。傳統方式(當作 hard evidence)是設置一個閾值(比如 0.5),超過閾值的認為它是一個 positive evidence,否則 negative evidence。但是這個閾值是很 tricky 的。
- noisy sensors:“具備噪聲的傳感器”,指的是那些可能產生不準確或不完全觀測結果的設備或機制,結果并非完全可信
virtual evidence 是 soft evidence 的一種應用形式,在貝葉斯網絡中引入一個虛擬結點 'alias
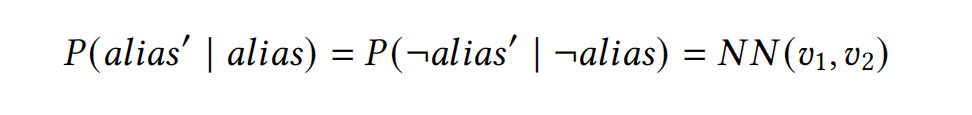
因為不懂貝葉斯網絡和概率編程,所以不太理解 alias 是怎么起作用的,為什么要引入 virtual evidence 和條件概率。先繼續看吧。
Preliminaries
介紹了一下概率程序 probabilistic program 的文法和語義:

文法比較簡單。
一個概率程序定義了一組 Datalog 程序的分布,Datalog 程序又定義了 Datalog 輸出的分布。可以通過采樣過程定義 Datalog 程序的分布。具體來說,首先,一個 probabilistic rule 會通過把變量替換為所有可能的值被轉換成一組 ground probabilistic rule,使用 \(\sigma\) 表達這種轉換。為了簡化,我們推廣 \(\sigma\) 使其也可以指代完成轉換后的某個規則。使用 \(U_{\overline{c}_p}\) 指代從某個概率程序得到的所有 ground probabilistic rule。其次,根據概率從 \(U_{\overline{c}_p}\) 中采樣一個子集 \(PGC\),這個子集的整體概率被定義為 \(P_{[[\overline{c}_p]]}_{\omega}(PGC)\)。但是,我們還要考慮 evidences(某些子集程序是不能滿足 evidence 的)。簡單來說,一個子集程序的概率為 0 當它不能推導出元組 t 當觀測到元組 t(即 \(observe(t)\))。其他滿足證據的子集程序的概率需要被 re-normalized。使用 \([[\overline{pgc}]]_D\) 指代確定性地計算一組 probabilistic rules,就是計算其對應的 Datalog(拋棄掉概率)。對于一個概率非 0 的子集程序,它的概率將和所有概率非 0 的子集程序們一起正則化。最終,一組元組 \(T\) 的概率通過加上所有能推理出 \(T\) 的子集程序的概率來得到,使用 \(P_{[[(\overline{c}_p, \overline{e})]]_w(T)}\) 來指代這個概率。對于一個元組 \(t\) 的邊緣概率 margin 可以通過累加所有包含 \(t\) 的 \(T\) 的概率得到。
這段符號有點亂飛了(可能是我太菜),但是仔細看是看得懂的。簡單來說,概率程序把 Datalog 語句(就是 rule)看作樣本。感覺還是沒太理解到符號使用的精髓,先放著吧。對貝葉斯網絡也沒什么理解說是。
Overall Framework
分為 Offline 和 Online 兩部分,Offline 關注訓練,Online 關注推理。
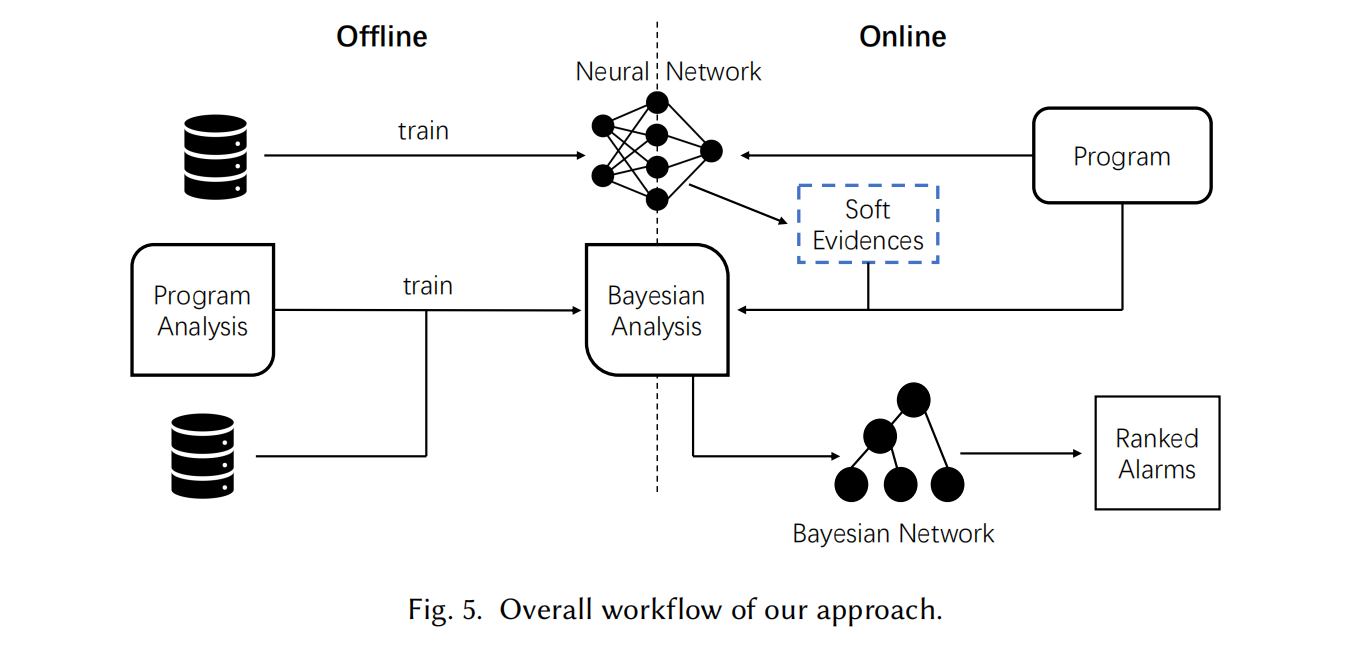
Online Inference With Soft Evidence

算法的輸入包括一個貝葉斯程序分析 \(pa\)、一個待分析的程序 \(T\)、一個關系 \(r(\bar{v})\)(其元組將通過軟證據進行觀察)以及一個神經網絡 \(NN\),用于為關系 \(r(\bar{v})\) 中的每個程序事實提供軟證據,從而指示其成立的可能性。
Definitions of Soft Evidences
-
\(Odds\):對于事件 \(\beta\) 發生相對于其不發生的信心
-
soft evidence:\(observe(\beta) \ k\),\(Odd\) 會增長 \(k\) 倍當觀測到一次 \(\beta\)
但是神經網絡不會產出關鍵參數 \(k\),而是直接產出條件概率
Encoding Soft Evidences using Conditional Probabilities
soft evidence 可以看作是對某個事件的 noisy sensor。soft evidence 不一定可靠,所以引入一個事件 \(t'\) 表示 soft evidence 的看法。事件 \(t'\) 是對事件 \(t\) 的一種觀測。
從 Bayes Factor \(k\) 導出兩個條件概率:


Compiling into a Bayesian Network
嘗試了 Problog 的推理引擎,但是在這個實驗的數據集上未能終止。所以選擇了 Bingo 這個工作的方法,通過把貝葉斯分析轉換成貝葉斯網絡得到一個近似的分析結果(\(\pi(X_i)\) 貝葉斯網絡可以提高效率)。“近似”是因為貝葉斯網絡是一個有向無環圖,分析推導過程中可能出現循環依賴,使用 Bingo 方法消除分析環路將導致結果近似。
添加兩個條件概率:
- 對于一個元組 \(t\),如果所有的 ground probabilistic rule 都不能推導出它,那么它的概率為 0;有一些可以推導出它,那么它的概率為 1
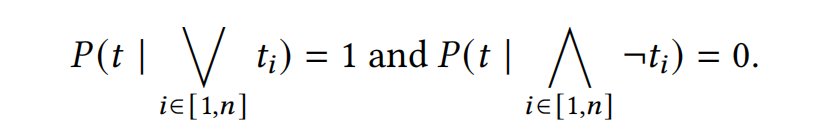
- 對于一個 rule,對于組成它的 body 的元組,所有元組都成立時,rule 的概率為 p(添加的概率),有任意一個元組不成立時,rule 的概率為 0

然后把 soft evidence 加入到貝葉斯網絡中,最后計算邊緣概率。
Offline learning
Generating a Bayesian Program Analysis
關鍵是給原來的 Datalog 中的每一個 rule 指派一個概率。可以通過有標簽的數據來訓練。使用 expectation-maximization 算法。
基于非正式信息直接對分析結果提供額外信息會比較困難,但對從分析結果進一步推導出來的事實提供信息可能會更容易。在這種情況下,需要為分析添加額外的規則以推導這些事實。新增規則的近似性應該與原始分析保持一致:如果原始分析是過近似的(may analysis),那么新增規則也應該是過近似的。如果原始分析是欠近似(must analysis)的,新增規則也應該保持欠近似。
Training a Neural Network Output to Produce Soft Evidences
用極大似然估計訓練神經網絡
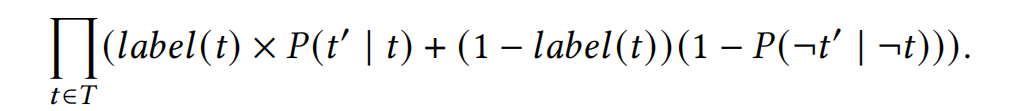
假設 \(P(t' | t) = P(\neg t' | \neg t)\) 簡化訓練目標。用預訓練的網絡提取嵌入向量,在嵌入向量后用神經網絡做微調。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號