
美國地質勘探局(United States Geological Survey,簡稱USGS),是美國內政部所屬的科學研究機構。負責對自然災害、地質、礦產資源、地理與環境、野生動植物信息等方面的科研、監測、收集、分析;對自然資源進行全國范圍的長期監測和評估。USGS地球探測器遙感數據集非常豐富,包括航空影像、AVHRR、商業影像、數字高程模型、陸地衛星、激光雷達、MODIS、雷達等。
USGS Lidar Explorer Map的創建主要是為了識別啟用了3D可視化的激光雷達項目(通過Entwine),它為用戶提供了一種通過基于網絡的可視化激光雷達的數據使用機制。同時,該網站還為用戶提供了對項目元數據的集成訪問,即可通過下載GeoPackage提供,而無需單獨下載空間元數據。此外,Lidar Explorer還提供DEM產品和源產品的下載,以便根據用戶定義的興趣區域輕松比較覆蓋范圍和下載大小。最后,USGS Lidar Explorer Map提供了一種使用云處理功能從Lidar派生產品的機制,該功能利用了公共可用的EPT Lidar數據和點數據抽象庫(PDAL)。
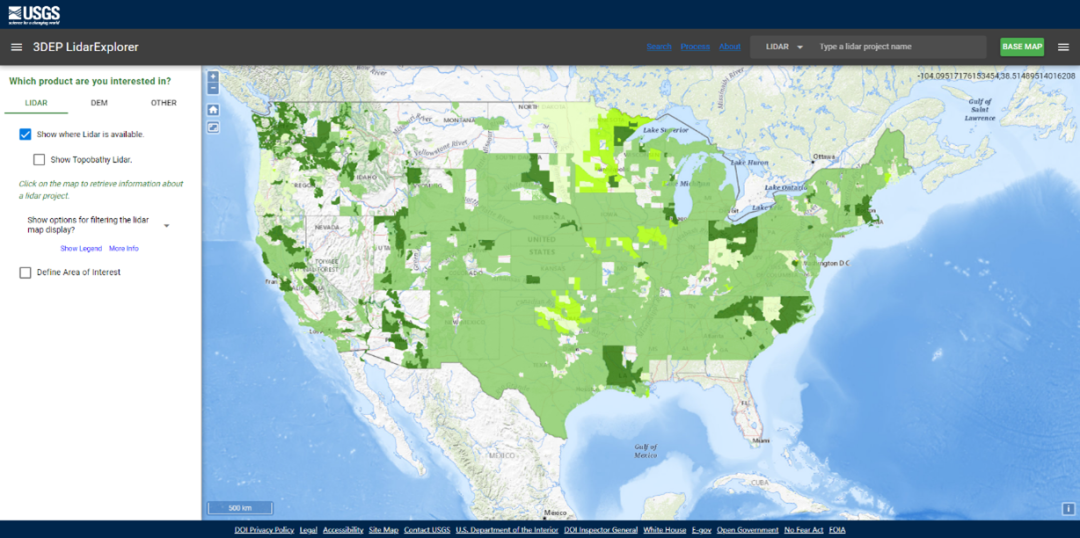
然而,由于搜索范圍廣和數據量大,Lidar數據難以快速批量下載,故以USGS Lidar Explorer Map點云數據為例,本次干貨整理了利用Python和LIDAR360等軟件,通過該網站批量下載和可視化數據的方法。
點擊圖層左上角的“Draw Area of Interest”按鈕設置感興趣的區域,可以雙擊瀏覽器來創建感興趣的區域。感興趣區域(AROI) 是限制搜索以獲取數據的地理邊界。接著,在“數據集”選項卡中選擇要下載的數據,集合之間的差異基于數據質量和處理級別。USGS已根據質量和處理級別將圖像分類為多個級別。

點擊右側數據詳情頁,如圖所示紅線范圍內即為右邊選中數據的可下載范圍,選擇Links中的LPC鏈接,點擊0_file_download_links.txt,選擇得到所有數據的url數據。由于本次實驗為示范實驗,故只選擇部分數據,其中每個url對應選中數據范圍內的一個地塊(tile)。
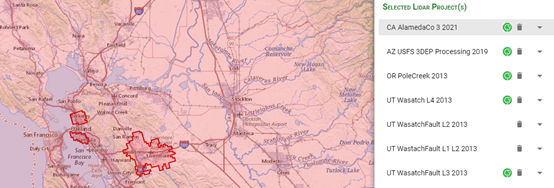
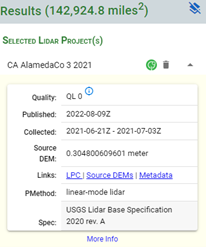
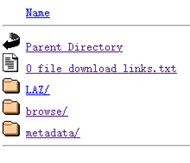
根據所需地塊名稱找到對應的url,并將需要的數據下載鏈接復制到Excel表格中(注:表格是.xls格式),具體格式如下所示。

以下是進行批量下載數據的代碼,包括數據準備,初始化命名以及數據的單線程下載和多線程下載部分。
import xlrd import requests import logging import threading import time import random [yk1] a = xlrd.open_workbook('C:/Users/WINDOWS/Desktop/download.xls', 'r') # 打開.xlsx文件,在這之前要把所有的下載鏈接都填到excel表中 sht = a.sheets()[0] # 打開表格中第一個sheet # row1 = sht.row_values(0) # 設置要下載的數據的范圍,對應于 Excel 中的行數 start = 1 # 獲取excel表的所有行數 nrows = sht.nrows; def fetch(url, filename): r = requests.get(url) url2 = url[-3:] # 根據鏈接地址獲取文件后綴 dir = r"E:\laz\\" + filename + "." + url2 # 構造完整文件名稱 with open(dir, "wb") as code: code.write(r.content) # 保存文件 print(url) # 打印當前的 URL jindu = (i - start) / (nrows - start) * 100 # 計算下載進度 print("下載進度:", jindu, "%") # 顯示下載進度 ######單進程下載######### # for i in range(start, nrows): # url = sht.cell(i, 3).value # 依次讀取每行第3列的數據,也就是 URL # if url: # logging.info(url) # f = requests.get(url) # roadName=sht.cell(i,2).value # markNo=sht.cell(i, 1).value # ii = str(roadName)+"_"+markNo # 按照下載順序(行號)構造文件名,filename # url2 = url[-3:] # 根據鏈接地址獲取文件后綴 # dir = r"G:\Mississippi\ALS Region\ALS Data\\"+ii + "." + url2 # 構造完整文件名稱 # with open(dir, "wb") as code: # code.write(f.content) # 保存文件 # print(url) # 打印當前的 URL # jindu = (i - start) / (nrows - start) * 100 # 計算下載進度 # print("下載進度:", jindu, "%") # 顯示下載進度 #######多進程下載####### t1 = time.time() t_list = [] for i in range(start, nrows): user_agent_list = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) Gecko/20100101 Firefox/61.0", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15", ] headers = {'User-Agent': random.choice(user_agent_list)} # 分配隨機user agent,避免認為是惡意攻擊 url = sht.cell(i, 2).value # 依次讀取每行第3列的數據,也就是 URL if url: logging.info(url) roadName = sht.cell(i, 1).value # markNo=sht.cell(i, 1).value # filename = str(roadName)+"_"+markNo # 按照下載順序(行號)構造文件名 filename = sht.cell(i, 1).value # filename = url.split('.')[2].split('_')[-3] t = threading.Thread(target=fetch, args=(url, filename)) t_list.append(t) t.start() for t in t_list: t.join() print("多線程版爬蟲耗時:", time.time() - t1)
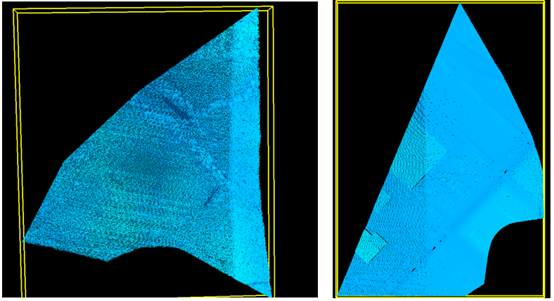
利用LIDAR360軟件顯示最終下載的點云數據,如下圖所示:


 浙公網安備 33010602011771號
浙公網安備 33010602011771號