

Unicode可以看做是一個映射,它定義了一個數字代碼,這個代碼關聯到一個字符。
早期的Unicode是16位的,1996年后,Unicode2.0的出現,使得Unicode的編碼范圍從0-10FFFF(16進制),16進制10FFFF=二進制100001111111111111111,即目前編到21位。
UTF(Unicode transformation format)是一個映射算法,它將每一個Unicode代碼映射到一個字節串。這種映射是可逆的。因此可以理解為UTF是Unicode的實現方式,UTF有多種版本,如下:

UTF8和UTF16都是變長的編碼方式,只有UTF32才是定長的編碼方式。之所以要變長方式,是因為定長方式有時會太占空間。
UTF8的編碼規則很簡單,只有二條:
1)對于單字節的符號,字節的第一位設為0,后面7位為這個符號的unicode碼。因此對于英語字母,UTF8編碼和ASCII碼是相同的。
2)對于n字節的符號(n>1),第一個字節的前n位都設為1,第n+1位設為0,后面字節的前兩位一律設為10。剩下的沒有提及的二進制位,全部為這個符號的unicode碼。
具體在換算的時候,可以根據下面的表格,對應著填寫。下面會有例子。如果文檔有很多字母,則UTF8比純粹的用UTF16節省了很多空間。

windows系統中,notepad或者其他一些軟件在保存對話框的編碼方式列表中出現“Unicode”這一個名字,這種叫法非常誤導人,使人以為unicode和UTF8是并列的關系,這其實是早期的一個稱呼(來自windows NT的早期版本的習慣,一直沿用),事實上它指的是UTF16。
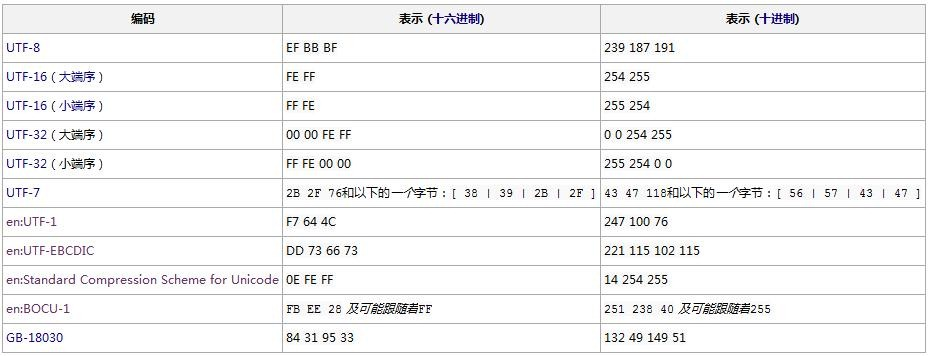
big-endian,little-endian大端序,小端序和BOM(byte-order mark)
UTF16采用UCS-2格式直接存儲。需要用兩個字節存儲,哪一個字節是高位哪一個字節是低位并沒有特別規定。因此,就產生了2種方式,比如一個unicode編碼為4E25的,存儲的時候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。UTF8由于特殊的算法,因此也不存在大端小端的說法。
這兩個古怪的名稱來自英國作家斯威夫特的《格列佛游記》。在該書中,小人國里爆發了內戰,戰爭起因是人們爭論,吃雞蛋時究竟是從大頭(Big-Endian)敲開還是從小頭(Little-Endian)敲開。為了這件事情,前后爆發了六次戰爭,一個皇帝送了命,另一個皇帝丟了王位。
計算機并不會知道這個文件是大端序還是小端序,因此要在文件頭加入標記。UTF8中,用字符EFBBBF 表示字節序,UTF16中用字符FEFF用來標示其字節序,如果出現在字節流的開頭,則用來標識該字節流的字節序,是高位在前還是低位在前。如果它出現在字節流的中間,則表達零寬度非換行空格的意義,用戶看起來就是一個空格。從Unicode3.2開始,U+FEFF只能出現在字節流的開頭,只能用于標識字節序,就如它的名稱——字節序標記——所表示的一樣;除此以外的用法已被舍棄。取而代之的是,使用U+2060來表達零寬度無斷空白。
不同編碼的字節順序標記的表示:
示例
舉個例子,對于“中”這個字,對應的unicode碼是4E2D=100111000101101
如果對其用UTF16編碼,則根據大小端的不同,有以下2種。
FE FF 4E 2D UTF16大端
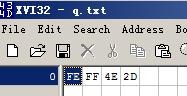
FF FE 2D 4E UTF16小端
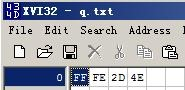
如果使用UTF8,則根據4E2D=100111000101101,有15位長,則對應
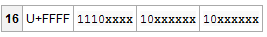

將100111000101101按照低位到高位,填補那些x,如果有不足就用0。
1110xxxx 10xxxxxx 10xxxxxx
11100100 10111000 10101101=E4B8AD
紅色的就是100111000101101填補上去的,綠色的是補足的0。
UTF8 沒有BOM
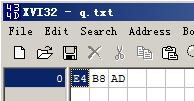
UTF8如果帶有BOM,則就是加入編碼EF BB BF
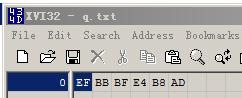
例子可以看出,如果忽略BOM,大小端。UTF16不一定會比UTF8占空間。因為UTF16和UTF8都是變長編碼UTF8是1-4個字節,UTF16是2-4個字節。
參考文檔:
http://en.wikipedia.org/wiki/Unicode
http://en.wikipedia.org/wiki/UTF-8
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
轉載:說說Unicode,UTF8,UTF16,BOM,Big endian,Little endian_一只博客的技術博客_51CTO博客

 浙公網安備 33010602011771號
浙公網安備 33010602011771號