
tesseract-ocr 安裝、語言庫、使用 隨記
前幾日才聽說ocr的圖片識別功能。覺得很有意思。先體驗一下。
地址: GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)
1.下載exe文件進行安裝。
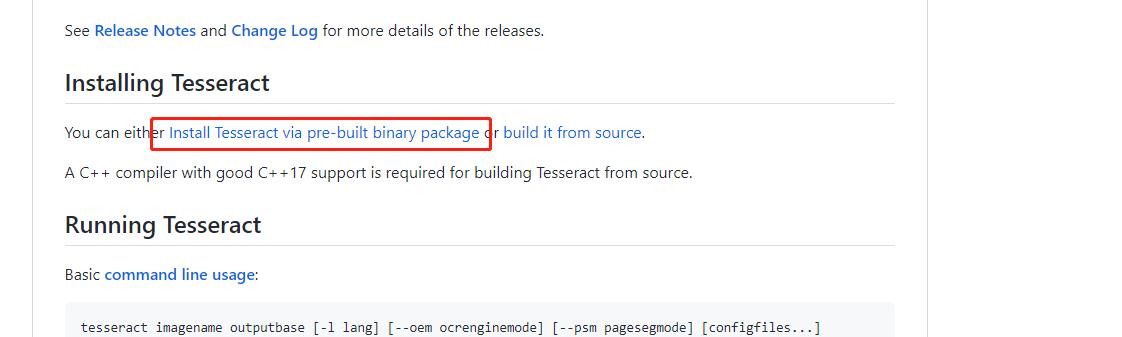
2.選擇對應版本
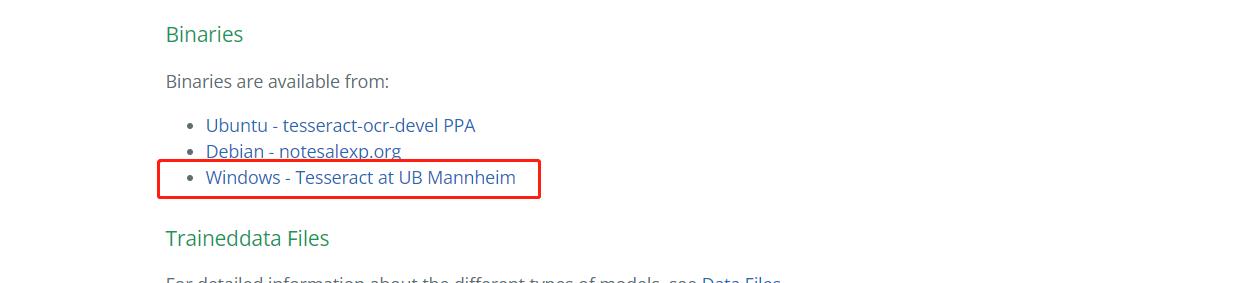
3.安裝注意
安裝過程中選擇對應的語言庫。感覺這里他們已經做的很好了。
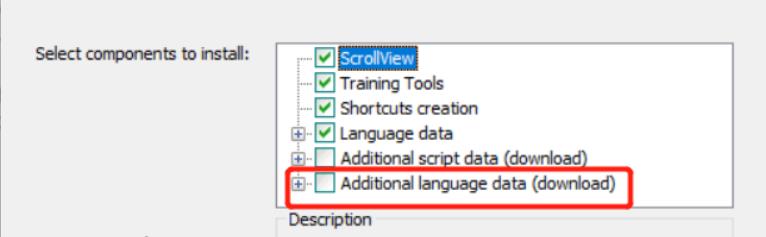
勾選3個chinese(xxx)
4.配置環境
電腦環境的path中配置對應路徑。
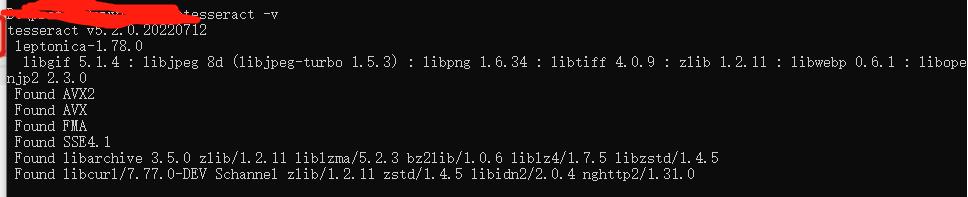
5.測試環境:
cmd 打開窗口。
用 tesseract -v
6.初使用
cmd 開始
使用命令: tesseract geci.jfif result -l chi_sim
geci.jfif 是圖片文件 result 是返回的識別結果文件名稱 -l 是選擇語言 chi_sim 是簡體中文。
demo例子: tesseract demo.png ge -l chi_sim


結束。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號