





mysql中explain命令詳解
前言
我們可以使用 explain 命令來查看 SQL 語句的執行計劃,從而幫助我們優化慢查詢。
使用
注意:使用的 mysql 版本為 8.0.28
數據準備
CREATE TABLE `tb_product2` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '商品ID',
`name` varchar(20) DEFAULT NULL COMMENT '商品名稱',
`en_name` varchar(20) DEFAULT NULL COMMENT '商品英文名稱',
`stock` int DEFAULT NULL COMMENT '庫存量',
PRIMARY KEY (`id`),
index `index_name`(`name`)
) ENGINE=InnoDB;
CREATE TABLE `tb_order2` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '訂單ID',
`product_id` bigint DEFAULT NULL COMMENT '商品ID',
`quantity` int DEFAULT NULL COMMENT '購買數量',
`price` decimal(10,2) DEFAULT NULL COMMENT '訂單總金額',
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO `tb_product2`( `name`, `en_name` , `stock` ) VALUES('蘋果11', 'iphone11', 10);
INSERT INTO `tb_product2`( `name`, `en_name` , `stock` ) VALUES('小米6', 'xiaomi6', 20);
INSERT INTO `tb_order2`( `product_id`, `quantity` , `price`, `create_time`) VALUES(1, 5, 100.00, now());
INSERT INTO `tb_order2`( `product_id`, `quantity` , `price` , `create_time`) VALUES(2, 3, 60.00, now());
查詢執行計劃
EXPLAIN SELECT * FROM `tb_product2` WHERE id = 1;
結果為
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | tb_product2 | null | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | null |
EXPLAIN SELECT * FROM `tb_product2` WHERE en_name = 'xiaomi6';
結果為
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | tb_product2 | null | ALL | null | null | null | null | 2 | 50.00 | Using where |
字段詳解
id
每次select查詢都會對應一個id,它代表著SQL執行的順序,如果id值越大,說明對應的SQL語句執行的優先級越高。
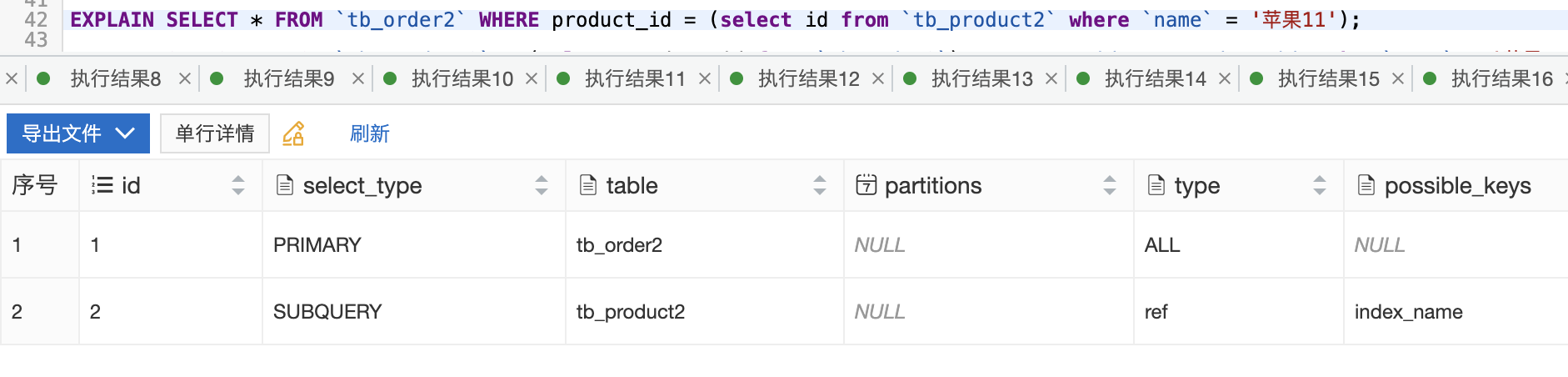
select_type
表示執行計劃對應的查詢類型,常見的查詢類型主要包括普通查詢、聯合查詢以及子查詢等。
- simple: 簡單的select查詢,沒有union或者子查詢
- primary: 有嵌套查詢時的最外層的select查詢
- derived: 用來表示包含在FROM子句的子查詢中的SELECT,MySQL會遞歸執行并將結果放到一個臨時表中。MySQL內部將其稱為是Derived table(派生表),因為該臨時表是從子查詢派生出來的
- union: union中的第二個或隨后的select查詢,不依賴于外部查詢的結果集
- dependent union: union中的第二個或隨后的select查詢,依賴于外部查詢的結果集
- subquery: 子查詢中的第一個select查詢,不依賴與外部查詢的結果集
- dependent subquery: 子查詢中的第一個select查詢,依賴于外部查詢的結果集
table
表示要查詢哪張表,當然不一定是真實的表的名稱,也可能是表的別名或者臨時表。
partitions
表示在進行查詢時,如果對應的表存在分區表,那么這里就會顯示具體的分區信息。
type
type是非常核心的屬性,需要重點掌握。它表示的是當前通過什么樣的方式對數據庫表進行訪問。
- system: 該表只有一行(相當于系統表),數據量很小,查詢速度很快,system是const類型的特例。
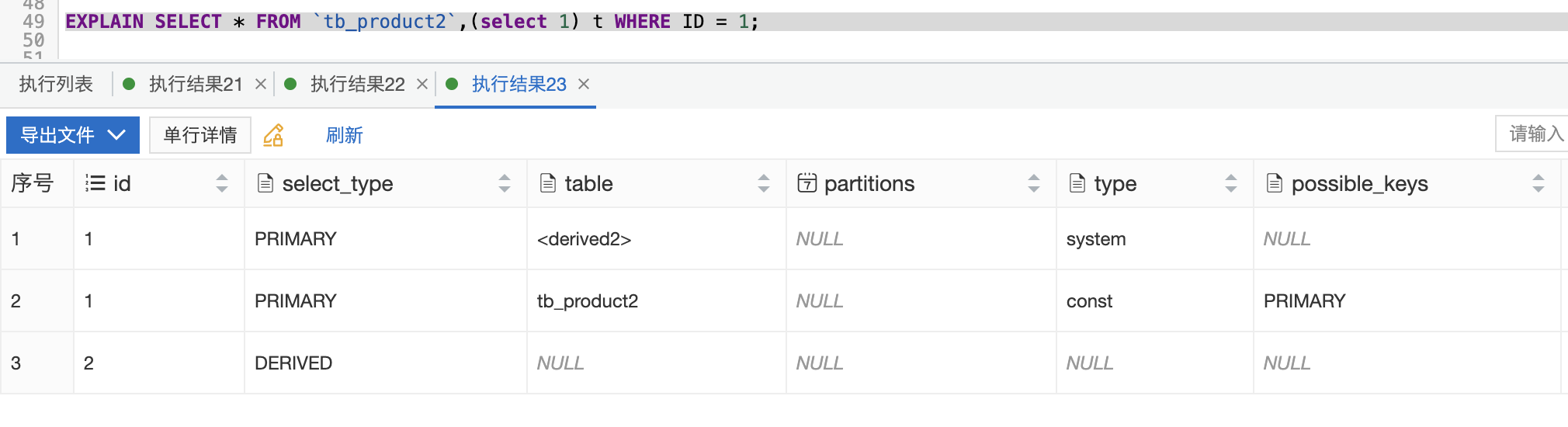
- const: 在進行數據查詢的時候,命中了primary key或唯一索引,此類數據查詢速度非常快。
- eq_ref: 對于每個來自于前面的表的行組合,從該表中讀取一行,常用在一個索引是unique key或者primary key。
- ref: 數據查詢的時候如果命中的索引是二級索引不是唯一索引,測試查詢速度也會很快,但是type是ref。另外如果是多字段的聯合索引,那么根據最左匹配原則,從聯合索引的最左側開始連續多個列的字段進行等值比較也是ref的類型。
- ref_or_null: 類似于 ref,區別在于 MySQL會額外搜索包含NULL值的行。
- unique_subquery: 在where條件中的關于in的子查詢條件集合。
- index_subquery: 區別于unique_subquery,用于非唯一索引,可以返回重復值。
- range: 使用索引進行行數據檢索,只對指定范圍內的行數據進行檢索。換句話說就是針對一個有索引的字段,在指定范圍中檢索數據。在where語句中使用 bettween...and、<、>、<=、in 等條件查詢 type 都是 range。

- all: 遍歷全表進行數據匹配,此時的數據查詢性能最差。

- index: index 與 all 其實都是讀全表,區別在于index是遍歷索引樹讀取,而ALL是從硬盤中讀取。
possible_keys
表示哪些索引可以被 MySQL 的優化器進行選擇,也就是索引候選者有哪些。
key
最終選擇使用的索引。
key_len
表示索引的長度,和實際的字段屬性以及是否為null都有關系。
ref
當使用字段進行常量等值查詢時ref此處為const,當查詢條件中使用了表達式或者函數則ref顯示為func,其他的顯示為null。
rows
表示 MySQL 認為它執行查詢時必須檢查的行數。行數越少,效率越高。
filtered
這個是一個百分比的值,表里符合條件的記錄數的百分比。簡單點說,這個字段表示存儲引擎返回的數據在經過過濾后,剩下的滿足條件的記錄數量的比例。
extra
在其他列不顯示額外信息在此列進行展示。
- Using index: 在進行數據查詢的時候,數據庫使用了覆蓋索引,就是查詢的列被索引覆蓋,使用到覆蓋索引查詢速度會非常快。

- Using where: 查詢時未找到可用的索引,進而通過where條件過濾獲取所需數據,但要注意的是并不是所有帶where語句的查詢都會顯示Using where。
- Using temporary: 表示查詢后結果需要使用臨時表來存儲,一般在排序或者分組查詢時用到。
- Using filesort: 此類型表示無法利用索引完成指定的排序操作,也就是ORDER BY的字段實際沒有索引,因此此類SQL是需要進行優化的。
參考
Mysql的explain,你真的會用嗎?
MySQL優化之EXPLAIN命令解析
全網最全 | MySQL EXPLAIN 完全解讀
Mysql中key 、primary key 、unique key 與index區別

 浙公網安備 33010602011771號
浙公網安備 33010602011771號