
深度學習中batch normalization
目錄
Batch Normalization筆記
我們將會用MNIST數據集來演示這個batch normalization的使用, 以及他所帶來的效果:
引包
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.layers import flatten
import numpy as np
import tensorflow.contrib.slim as slim
構建模型:
def model1(input, is_training, keep_prob):
input = tf.reshape(input, shape=[-1, 28, 28, 1])
batch_norm_params = {
'decay': 0.95,
'updates_collections': None
}
with slim.arg_scope([slim.batch_norm, slim.dropout], is_training=is_training):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_initializer=tf.truncated_normal_initializer(stddev=0.1),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params,
activation_fn=tf.nn.crelu):
conv1 = slim.conv2d(input, 16, 5, scope='conv1')
pool1 = slim.max_pool2d(conv1, 2, scope='pool1')
conv2 = slim.conv2d(pool1, 32, 5, scope='conv2')
pool2 = slim.max_pool2d(conv2, 2, scope='pool2')
flatten = slim.flatten(pool2)
fc = slim.fully_connected(flatten, 1024, scope='fc1')
print(fc.get_shape())
drop = slim.dropout(fc, keep_prob=keep_prob)
logits = slim.fully_connected(drop, 10, activation_fn=None, scope='logits')
return logits
def model2(input, is_training, keep_prob):
input = tf.reshape(input, shape=[-1, 28, 28, 1])
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_initializer=tf.truncated_normal_initializer(stddev=0.1),
normalizer_fn=None, activation_fn=tf.nn.crelu):
with slim.arg_scope([slim.dropout], is_training=is_training):
conv1 = slim.conv2d(input, 16, 5, scope='conv1')
pool1 = slim.max_pool2d(conv1, 2, scope='pool1')
conv2 = slim.conv2d(pool1, 32, 5, scope='conv2')
pool2 = slim.max_pool2d(conv2, 2, scope='pool2')
flatten = slim.flatten(pool2)
fc = slim.fully_connected(flatten, 1024, scope='fc1')
print(fc.get_shape())
drop = slim.dropout(fc, keep_prob=keep_prob)
logits = slim.fully_connected(drop, 10, activation_fn=None, scope='logits')
return logits
構建訓練函數
def train(model, model_path, train_log_path, test_log_path):
# 計算圖
graph = tf.Graph()
with graph.as_default():
X = tf.placeholder(dtype=tf.float32, shape=[None, 28 * 28])
Y = tf.placeholder(dtype=tf.float32, shape=[None, 10])
is_training = tf.placeholder(dtype=tf.bool)
logit = model(X, is_training, 0.7)
loss =tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logit, labels=Y))
accuray = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logit, 1), tf.argmax(Y, 1)), tf.float32))
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(0.1, global_step, 1000, 0.95, staircase=True)
optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate)
update = slim.learning.create_train_op(loss, optimizer, global_step)
mnist = input_data.read_data_sets("tmp", one_hot=True)
saver = tf.train.Saver()
tf.summary.scalar("loss", loss)
tf.summary.scalar("accuracy", accuray)
merged_summary_op = tf.summary.merge_all()
train_summary_writter = tf.summary.FileWriter(train_log_path, graph=tf.get_default_graph())
test_summary_writter = tf.summary.FileWriter(test_log_path, graph=tf.get_default_graph())
init = tf.global_variables_initializer()
iter_num = 10000
batch_size = 1024
os.environ["CUDA_VISIBLE_DEVICES"] = '2' # 選擇cuda的設備
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.2) # gpu顯存使用
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
sess.run(init)
if not os.path.exists(os.path.dirname(model_path)):
os.makedirs(os.path.dirname(model_path))
else:
try:
saver.restore(sess, model_path)
except:
pass
for i in range(iter_num):
x, y = mnist.train.next_batch(batch_size)
sess.run(update, feed_dict={X:x, Y:y, is_training:True})
if i % 100 == 0:
x_test, y_test = mnist.test.next_batch(batch_size)
print("train:", sess.run(accuray, feed_dict={X: x, Y: y, is_training:False}))
print("test:", sess.run(accuray, feed_dict={X: x_test, Y: y_test, is_training:False}))
saver.save(sess, model_path)
g, summary = sess.run([global_step, merged_summary_op], feed_dict={X: x, Y: y, is_training:False})
train_summary_writter.add_summary(summary, g)
train_summary_writter.flush()
g, summary = sess.run([global_step, merged_summary_op], feed_dict={X: x_test, Y: y_test, is_training:False})
test_summary_writter.add_summary(summary, g)
test_summary_writter.flush()
train_summary_writter.close()
test_summary_writter.close()
下面我們來進行計算:
train(model1, "model1/model", "model1_train_log", "model1_test_log")
train(model2, "model2/model", "model2_train_log", "model2_test_log")
結論
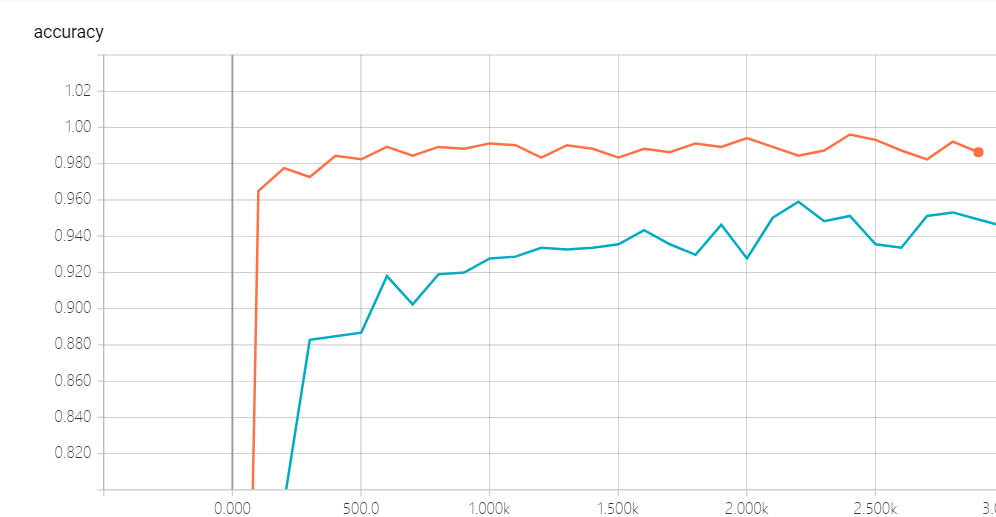
我們發現, 加了batch norm的似乎收斂的更快一些, 這個我們可以從對比上可以很清楚的看到, 所以這個bn是我們一個很好的技術, 前提是你選的參數比較適合.
以下是兩個注意點:
The keys to use batch normalization in slim are:
Set proper decay rate for BN layer. Because a BN layer uses EMA (exponential moving average) to approximate the population mean/variance, it takes sometime to warm up, i.e. to get the EMA close to real population mean/variance. The default decay rate is 0.999, which is kind of high for our little cute MNIST dataset and needs ~1000 steps to get a good estimation. In my code, decay is set to 0.95, then it learns the population statistics very quickly. However, a large value of decay does have it own advantage: it gathers information from more mini-batches thus is more stable.
Use slim.learning.create_train_op to create train op instead of tf.train.GradientDescentOptimizer(0.1).minimize(loss) or something else!.

 浙公網安備 33010602011771號
浙公網安備 33010602011771號