
國產化Excel開發組件Spire.XLS教程:使用Python將CSV轉換為XML(處理現實數據問題)
 在本指南中,我們將探討如何使用 Spire.XLS for Python 將 CSV 文件轉換為 XML。你將學習如何將 CSV 轉換為 Excel XML 格式以及 標準 XML 。同時,我們還將介紹如何清理和預處理真實世界中的 CSV 文件——處理無效表頭、缺失值、特殊字符和嵌套字段等問題,以確保生成的 XML 輸出始終有效且結構正確。
在本指南中,我們將探討如何使用 Spire.XLS for Python 將 CSV 文件轉換為 XML。你將學習如何將 CSV 轉換為 Excel XML 格式以及 標準 XML 。同時,我們還將介紹如何清理和預處理真實世界中的 CSV 文件——處理無效表頭、缺失值、特殊字符和嵌套字段等問題,以確保生成的 XML 輸出始終有效且結構正確。
CSV 因其簡潔和跨平臺的廣泛支持,是最常見的表格數據交換格式之一。然而,當需要處理結構化應用程序、配置文件或層次化數據時,XML 通常成為首選格式,因為它能夠表示嵌套關系并提供更嚴格的數據驗證。
在本指南中,我們將探討如何使用 Spire.XLS for Python 將 CSV 文件轉換為 XML。你將學習如何將 CSV 轉換為 Excel XML 格式以及 標準 XML 。同時,我們還將介紹如何清理和預處理真實世界中的 CSV 文件——處理無效表頭、缺失值、特殊字符和嵌套字段等問題,以確保生成的 XML 輸出始終有效且結構正確。
Spire.XLS for Python試用下載,請聯系慧都科技
歡迎加入Spire技術交流Q群(125237868),與更多小伙伴一起提升文檔開發技能~
為什么要將 CSV 轉換為 XML
為什么開發者需要將 CSV 轉 XML 呢?以下是一些實際應用場景:
- 企業數據遷移 : 許多企業級應用程序(如 ERP 或 CRM 系統)在批量導入數據時要求 XML 格式。
- 配置與元數據 : XML 常用于存儲結構化元數據,而原始數據可能以 CSV 形式提供。
- 互操作性 : 某些行業(如金融、醫療、政府)仍大量依賴 XML 數據格式進行數據交換。
- 可讀性報告 :XML 可以表示層次化數據,比扁平化的 CSV 文件更具描述性。
- 數據驗證 :XML 可通過 XSD 模式驗證數據完整性,而 CSV 無法直接實現此功能。
CSV 以簡潔取勝,XML 以結構見長。通過兩者的互相轉換,你可以兼得兩種格式的優勢。
準備工作
在開始編寫代碼之前,請確保準備好以下環境:
- Python 3.7 及以上版本
- Spire.XLS for Python → 一款功能強大的專業 Excel 操作庫
- 標準 Python 庫 → xml.etree.ElementTree、csv 和 re
通過 pip 安裝 Spire.XLS(假設系統中已安裝 Python 和 pip):
pip install spire.xls此外,請準備一個測試用 CSV 文件,例如:
員工ID,姓名,部門,職位,入職日期,薪資
1001,張三,技術部,軟件工程師,2021-03-15,15000
1002,李四,市場部,市場專員,2022-07-01,12000
1003,王五,技術部,產品經理,2020-11-10,18000
1004,趙六,人力資源部,招聘經理,2019-05-22,14000將 CSV 轉換為 Excel XML 格式
第一種方法是將 CSV 轉換為 Excel 兼容的 XML 格式,也稱為 SpreadsheetML (Excel 2003 引入)。這種格式可以被 Excel 直接打開。
使用 Spire.XLS,這一過程非常簡單:
from spire.xls import *
# 創建 Workbook
workbook = Workbook()
# 加載 CSV 文件
workbook.LoadFromFile("input.csv", ",", 1, 1)
# 保存為 Excel XML格式
workbook.SaveAsXml("output.xml")
# 釋放資源
workbook.Dispose()工作原理
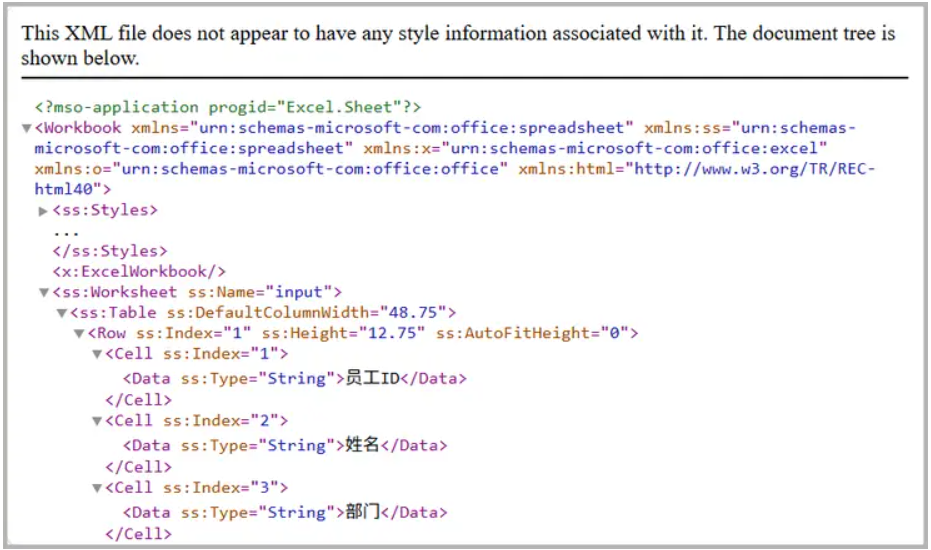
- 讀取 CSV 文件 : 使用 LoadFromFile() 方法將 CSV 文件讀取到工作簿中。
- 保存為Excel XML 格式 : 使用 SaveAsXml() 方法保存為 Excel XML 格式。
效果圖 :
將 CSV 轉換為標準 XML
更多時候,你可能需要如下所示標準的XML 結構,而不是 Excel 兼容格式:
<Employee>
<employee_id>1001</employee_id>
<name>張三</name>
<department>技術部</department>
<position>軟件工程師</position>
<hire_date>2021-03-15</hire_date>
<salary>15000</salary>
</Employee>實現方式如下:
from spire.xls import *
import xml.etree.ElementTree as ET
from xml.dom import minidom
def chinese_to_english_tag(chinese_header):
"""
將特定的中文列名轉換為英文XML標簽
"""
mapping = {
'員工ID': 'employee_id',
'姓名': 'name',
'部門': 'department',
'職位': 'position',
'入職日期': 'hire_date',
'薪資': 'salary'
}
# 去除前后空格后查找映射
cleaned_header = chinese_header.strip()
return mapping.get(cleaned_header, cleaned_header)
# Step 1: 加載 CSV 文件
workbook = Workbook()
workbook.LoadFromFile(r"C:\Users\Administrator\Desktop\input.csv", ",", 1, 1)
sheet = workbook.Worksheets[0]
# Step 2: 創建根節點
root = ET.Element("Employees")
# Step 3: 處理表頭 - 中文列名轉英文
headers = []
for col in range(1, sheet.Columns.Count + 1):
cell_value = sheet.Range[1, col].Value
if not cell_value:
break
english_tag = chinese_to_english_tag(str(cell_value))
headers.append(english_tag)
# Step 4: 添加數據行
for row in range(2, sheet.Rows.Count + 1):
if not sheet.Range[row, 1].Value:
break
employee = ET.SubElement(root, "Employee")
for col, english_header in enumerate(headers, start=1):
cell_value = sheet.Range[row, col].Value
field = ET.SubElement(employee, english_header)
field.text = str(cell_value) if cell_value is not None else ""
# Step 5: 保存為格式化的 XML 文件
xml_str = ET.tostring(root, encoding='utf-8')
pretty_xml = minidom.parseString(xml_str).toprettyxml(indent=" ")
with open("output/standard.xml", 'w', encoding='utf-8') as f:
f.write(pretty_xml)
# 釋放資源
workbook.Dispose()工作原理
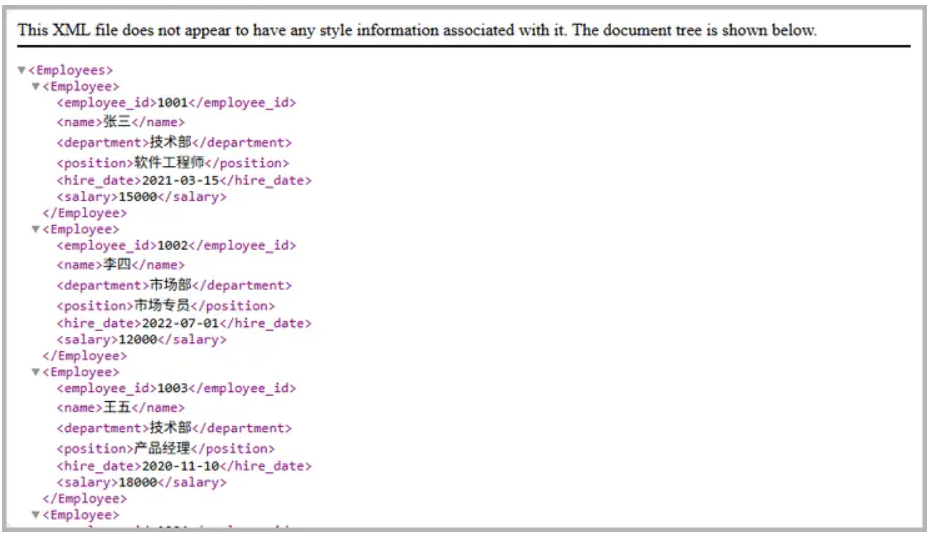
- 讀取 CSV 文件 :使用 LoadFromFile() 方法導入 CSV 數據,加載到工作表中。
- 創建 XML 根節點 :創建根節點 <Employees>,用于存放所有員工信息。
- 轉換表頭 :讀取第一行表頭,通過映射函數將中文列名轉換為對應的英文標簽,例如“員工ID”→employee_id,以確保生成的 XML 符合英文命名規范。
- 生成數據節點 :從第二行開始遍歷數據,為每一行創建 <Employee> 元素,并根據表頭生成子標簽填入數據。
- 格式化并保存 :對生成的 XML 進行縮進美化后,保存為 standard.xml 文件。
效果圖 :
處理現實 CSV 數據問題
將“完美”的 CSV 轉換為 XML 很容易,但實際 CSV 往往并不理想。以下是常見問題及對應解決方案:
- 無效的表頭名稱
- 問題:如 “Employee ID” 或 “123Name” 在 XML 中無效。
- 解決:將空格替換為下劃線 _,或為數字開頭的列名添加前綴。
- 空值或缺失值
- 問題:缺失值可能導致 XML 結構錯誤。
- 解決:將空值替換為占位符(如 NULL、Unknown、0)。
- 特殊字符
- 問題:如 <, >, & 會破壞 XML。
- 解決:使用轉義字符 <, >, &。
- CSV 中的嵌套數據
- 問題:某些單元格包含多個值,如:
OrderID,Customer,Products
1001,張三,"電腦;鼠標;鍵盤"若直接轉換,將丟失層次結構。
- 解決:檢測并拆分嵌套字段,生成層次化 XML:
<Products>
<Product>電腦</Product>
<Product>鼠標</Product>
<Product>鍵盤</Product>
</Products>中文列名轉換為英文
- 問題: XML 標簽通常要求為英文,若 CSV 文件使用中文列名(如“姓名”、“部門”),生成的 XML 標簽不符合通用標準。
- 解決: 在生成 XML 前,將中文列名映射為對應的英文標簽,例如“姓名”→“name”,“部門”→“department”。(如“將 CSV 轉換為標準 XML”部分代碼所示)
使用 clean_csv 自動清理
可使用以下輔助函數自動預處理 CSV (不包含中文列名轉換為英文):
import csv
import re
def clean_csv(input_file, output_file, nested_columns=None, nested_delimiter=";"):
if nested_columns is None:
nested_columns = []
cleaned_rows = []
# 轉義 XML 特殊字符
def escape_xml(text):
return (text.replace("&", "&")
.replace("<", "<")
.replace(">", ">")
.replace('"', """)
.replace("'", "'"))
with open(input_file, "r", encoding="utf-8") as infile:
reader = csv.reader(infile)
headers = next(reader)
# 清理表頭
cleaned_headers = []
for h in headers:
h = h.strip() # 去除首尾空格
h = re.sub(r"\s+", "_", h) # 將空格替換為下劃線
h = re.sub(r"[^a-zA-Z0-9_]", "", h) # 移除非法字符
if re.match(r"^\d", h): # 若表頭以數字開頭,則加前綴
h = "Field_" + h
cleaned_headers.append(h)
cleaned_rows.append(cleaned_headers)
# 讀取所有行數據
raw_rows = []
for row in reader:
# 將空單元格替換為 "NULL"
row = [cell if cell.strip() != "" else "NULL" for cell in row]
raw_rows.append(row)
# 處理嵌套列(如多值列)
if nested_columns:
expanded_rows = [cleaned_headers] # 保留表頭
for row in raw_rows:
row_variants = [row]
for col_name in nested_columns:
if col_name not in cleaned_headers:
continue
col_index = cleaned_headers.index(col_name)
temp = []
for variant in row_variants:
cell_value = variant[col_index]
# 僅按嵌套分隔符拆分,不影響 XML 特殊字符
if nested_delimiter in cell_value:
items = [item.strip() for item in cell_value.split(nested_delimiter)]
for item in items:
new_variant = variant.copy()
new_variant[col_index] = item
temp.append(new_variant)
else:
temp.append(variant)
row_variants = temp
expanded_rows.extend(row_variants)
cleaned_rows = expanded_rows
else:
cleaned_rows.extend(raw_rows)
# 展開后再轉義特殊字符
final_rows = [cleaned_rows[0]] # 保留表頭
for row in cleaned_rows[1:]:
final_row = [escape_xml(cell) for cell in row]
final_rows.append(final_row)
# 寫入清理后的 CSV 文件
with open(output_file, "w", newline="", encoding="utf-8") as outfile:
writer = csv.writer(outfile)
writer.writerows(final_rows)
print(f"清理后的 CSV 已保存至 {output_file}")你可以通過傳入輸入和輸出 CSV 文件路徑來調用 clean_csv 函數,并可選地指定需要展開嵌套值的列。
# 文件路徑
input_file = r"C:\Users\Administrator\Desktop\input.csv"
output_file = r"C:\Users\Administrator\Desktop\cleaned_output.csv"
# 指定可能包含嵌套值的列
nested_columns = ["Products"] # 你也可以添加更多,例如 ["Products", "Reviews"]
# 調用 clean_csv 函數
clean_csv(input_file, output_file, nested_columns=nested_columns, nested_delimiter=";")該函數可確保 CSV 在轉換為 XML 前干凈、有效,功能包括:
- 清理表頭(符合 XML 命名規則)
- 處理空單元格
- 拆分嵌套列值
- 轉義特殊字符
- 生成 UTF-8 編碼的清潔 CSV 文件
總結
使用 Spire.XLS for Python 將 CSV 轉換為 XML,不僅高效,而且具備極強的靈活性。無論是快速導出、結構化集成,還是復雜的業務數據轉換,都能輕松應對。
- 快速導出: 如果只是為了讓文件可被 Excel 直接讀取,采用 Excel XML 格式是最快捷的方式。
- 自定義結構: 若需生成具有特定標簽或層級關系的 XML,可借助 xml.etree.ElementTree 構建標準 XML 文檔,實現高度定制。
- 數據清理與增強: 面對真實環境中格式不規范或存在嵌套數據的 CSV,可先使用 clean_csv() 函數進行清洗,統一字段名、展開嵌套列,并自動轉義特殊字符,確保生成的 XML 結構規范、可解析。
從企業系統集成、報表歸檔,到舊系統的數據遷移,這一流程充分結合了 CSV 的簡潔性 與 XML 的結構化優勢 ,為數據交換與自動化處理提供了穩健、高可維護的解決方案。
常見問題(FAQs)
Q1. 可以轉換非常大的 CSV 文件嗎?
可以,但建議采用流式處理(逐行處理)以避免內存問題。
Q2. Spire.XLS 是否支持將 CSV 轉換為標準 XML?
支持。保存為 Excel XML 是內置功能,但自定義 XML 仍需代碼實現。
Q3. 如何自動處理特殊字符?
可使用 escape_xml 輔助函數或 Python 內置的 xml.sax.saxutils.escape()。
Q4. 如果 CSV 有多個嵌套列怎么辦?
調用 clean_csv 時,可在 nested_columns 參數中傳入多個列名。
Q5. 可以驗證生成的 XML 嗎?
可以。生成 XML 后,可根據 XSD 模式進行驗證。
Spire.XLS for Python試用下載,請聯系慧都科技
歡迎加入Spire技術交流Q群(125237868),與更多小伙伴一起提升文檔開發技能~

 浙公網安備 33010602011771號
浙公網安備 33010602011771號