

Bigtop 從零開始搭建大數據集群
背景
公司目前在線上環境使用的是基于 HDP 2.6.3 搭建的大數據集群,在持續使用4年之后,是否要給集群做個升級成為了一個值得思考的問題
現在集群的 Hadoop 版本是 2.7.3,繼續使用倒也沒什么問題,但一些使用痛點還是著實存在的,并且每一點都扎根于這套架構,不做大的升級也不可能解決,感受明顯的主要有三點:
-
離線數倉相關組件版本普遍較舊,HDFS 落后一個大版本,Hive 落后兩個大版本。想用新的 Hive SQL 函數或者語法,都是不支持的
-
缺乏上層應用,支持血緣分析、數據質量可視化等功能,所有數據相關的接入和分析需求都是人工對接和實現
-
組件“各自為戰”,部署和維護方式差異很大,升級時仍需要大量的人工操作
帶著這些問題,去尋找開源社區的升級解決方案,會找到以 Bigtop 作為部署工具,Ambari 作為管理平臺,是目前我們所使用的 HDP 改造成本最小的
那么什么是 Bigtop,它和大數據集群部署有什么關系,需要從 CDH 的發展歷史說起
HDP 到 CDP: 從開源到閉源
在大數據和 Hadoop 生態蓬勃發展的十幾年前,最流行的部署方案就是 HDP 和 CDH 這兩個部署套件
HDP (Hortonworks Data Platform) 最初發展于 2012 年,由幾個雅虎工程師共同創立的 Hortonworks 公司,他們旨在打造開源、安全、可擴展的 Hadoop 集群。HDFS 從 2.0 發展到 3.0 的階段,HDP 對 Hadoop 的核心功能做出了非常大的貢獻

CDH (Cloudera Distribution including Apache Hadoop) 和 HDP 一樣也是提供大數據成套組件的,它是 2008 年由來自 Google、Yahoo!、Facebook、Oracle 的大數據工程師共同創辦的 Cloudera 公司發起的項目,除了為 HDFS 此外還提供了可用于 Hive 加速查詢的引擎 impala,以及數據即席查詢服務 Hue
不過面對 AWS 及其他公有云廠商的挑戰,只往開源方向發力顯然是不夠的。到了 2018 年,CDH 收購了 HDP,并逐漸停止了對 HDP 和 CDH 的維護,現在 Cloudera 提供的 CDP (Cloudera Data Platform) 也是徹底轉向了私有云、定制化和按需收費的模式

HDP 和 CDH 走向商業化,對于大數據開源社區無疑是沖擊巨大的,特別是國內中小公司做大數據平臺的商用化的這部分業務,大部分就是基于這兩個套件做封裝和二次開發的。對于使用這些平臺的中小廠,為了保證平臺的可靠性,也更多轉向了公有云的 EMR ( 參考: CDH/HDP 何去何從 )
Ambari
在了解了 HDP 和 CDH 之后,我們來看一個非常重要的開源組件 Ambari,這也是作為大數據平臺運維必然會接觸的組件
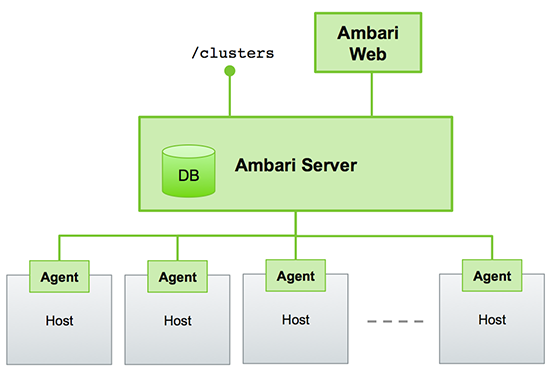
Ambari 是 Hortonworks 公司開發的用來部署和管理大數據集群的服務,它規范了組件的部署流程,通過界面,按照組件選擇、節點選擇、自定義配置、觸發后臺安裝任務的固定流程,幾分鐘就可以完成 Hadoop 集群的部署。它還對 Hadoop 組件的配置進行了一定優化,實際安裝時需要你手動修改的配置很少。另外它還開放了 restful 接口,在運維上具有一定擴展性,可以基于它再開發上層的大數據平臺,對集群和組件進行展示
除了組件安裝、組件配置、監控和故障自動重啟這些基本功能之外,最大的特點是它還集成了 Hadoop 集群運維的一些復雜的手動操作,假設我們先搭建了 namenode 單點模式的 HDFS,需要把它擴展成 HA 模式,部署兩個 namenode,完整的步驟至少需要5步(部署 journalnode -> 啟動 secondary namenode -> 初始化 share edits -> 啟動集群 -> 啟動 ZKFailoverController ),每一步都涉及到配置變更,稍有一步做錯可能集群就起不來了,操作風險很大。而 Ambari 會幫你做好大部分的動作,你只需要按它要求執行幾條指令就行,就像有一個運維專家在旁邊手把手輔助你
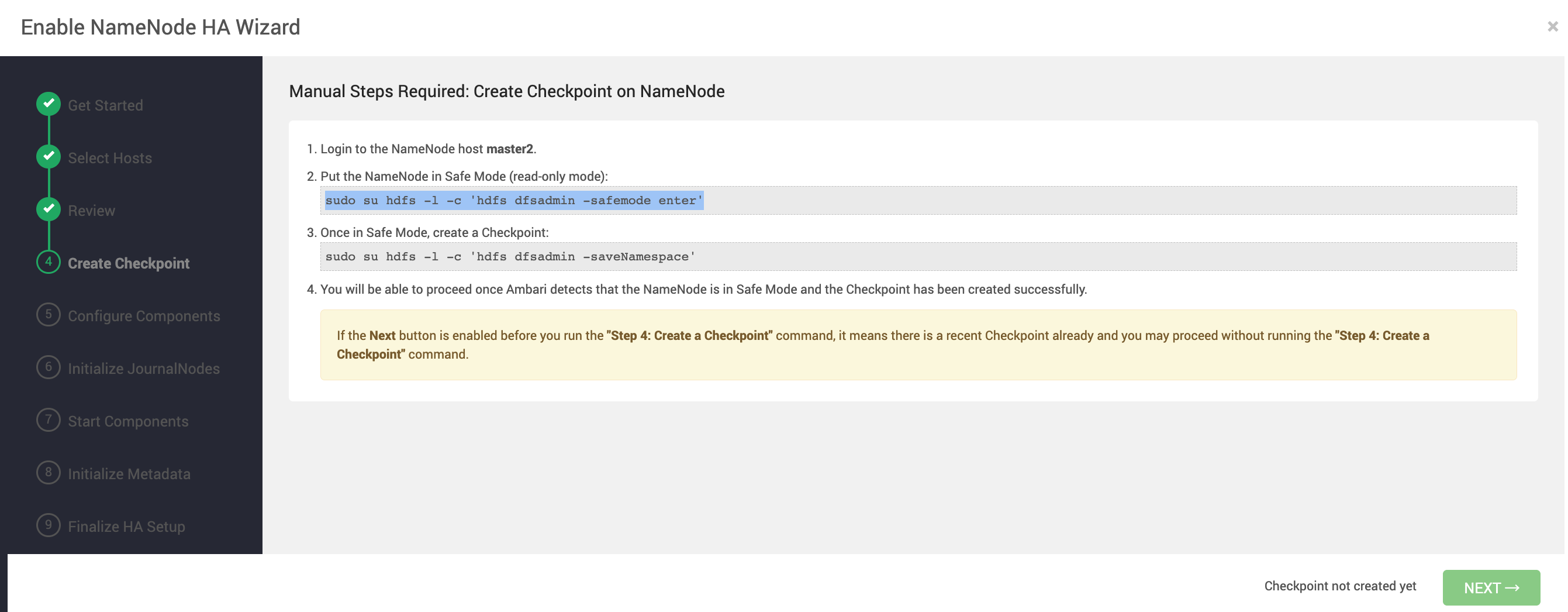
不過 Ambari 的不足也是很明顯的。首先是它對大數據組件的支持比較限定于 Hadoop 生態下的組件,像 HDFS、YARN、Hive、HBase、Zookeeper 等組件的安裝和維護功能支持是很好的,但是 Flink,Spark 這些比較年輕的組件,除了部署之外就沒有任何管理相關的功能了。獨立于 Hadoop 生態的 Jupyter 、Hue 這些就完全沒集成,要是想用 Ambari 去部署和管理這些組件,就只能按照 Ambari 的組件規范自己開發安裝腳本,工作量不小,而且這些腳本的擴展價值也不高
其次,它基于虛擬機的部署架構,也基本不可能去融合 kubernetes 的生態。對于 Hadoop 傳統組件來說,其服務架構特點決定了上云本來就是比較困難的事情,基于虛擬機部署也沒什么問題,但是放到 Flink 和 Spark 這類容錯度比較高,也可以跑在 k8s 的任務引擎,通常在前期部署架構的選型上,運維就會直接選擇 on k8s, 這也會進一步造成大數據集群部署架構上的割裂
現在只考慮部署 Hadoop 集群的話,選擇 Ambari 作為管理服務還是沒什么問題的,功能和穩定性都有基本保障
關于 Ambari 還有一段小歷史比較有趣: HDP 和 CDH 合并之后,隨著開發者投入商用版本,Ambari 在2年多的時間都是停止維護的狀態,甚至面臨從 Apache “退役”。但奈何 Ambari 實在是沒有很好的替代品。于是在眾多大數據開發者的呼聲之下,2022 年 Apache 社區投入了幾個人力,總算是重啟了 Ambari 項目,并于今年4月發布了合并眾多修復的 3.0 版本

Bigtop 和 Ambari
Apache Bigtop 項目最初是由 Cloudera 的幾個開發者在 2011 年發起,后續捐贈給 Apache 的一個開源項目,目的是開發一套大數據組件編譯、構建、部署的流程工具。它的機制是通過 gradle、shell 和 puppet 等腳本語言( 其中 puppet 本身就是組件安裝和管理編排工具,在基礎設施運維、大數據和openstack中都有用到 )定義每個組件的編譯構建啟動行為流程,讓你可以在 centos、ubuntu、debian、openeuler 等操作系統上,使用相同的指令就可以完成相同的動作。為了確保編譯過程的順利,它還將官方補丁 patch 文件保存在自己項目中,這樣所有的代碼都來自開源,所有改動都是可見的
沒有 Bigtop 的時候,如果你接了一個“構建大數據編譯部署流水線”的需求,由于每個項目之間的編譯方式和系統依賴都各有不同,基本還沒踩完編譯的坑就已經打退堂鼓了。如今有了 Bigtop 幫我們封裝編譯的所有過程,實現這個需求終于不再是一個難題

開源大數據底座平臺對比
再縱觀其他的開源大數據部署和管理平臺,會發現它們的設計思想和 Ambari+Bigtop 基本無異,因此就不針對每個平臺做詳細介紹了,直接看我們最關注的一些對比點

這些平臺目前都還不能作為 Ambari 的成熟替代品,但還是有值得關注的地方
bigtop manager 定位就是 Ambari 的替代品,為了讓 Bigtop 擺脫對 Ambari 的依賴,有自己的集群部署可視化服務。雖然它的活躍開發者不多,而且現在的基礎功能還是不完善狀態,但這個項目畢竟是在 apache 組織下,至少不會完全停止維護吧
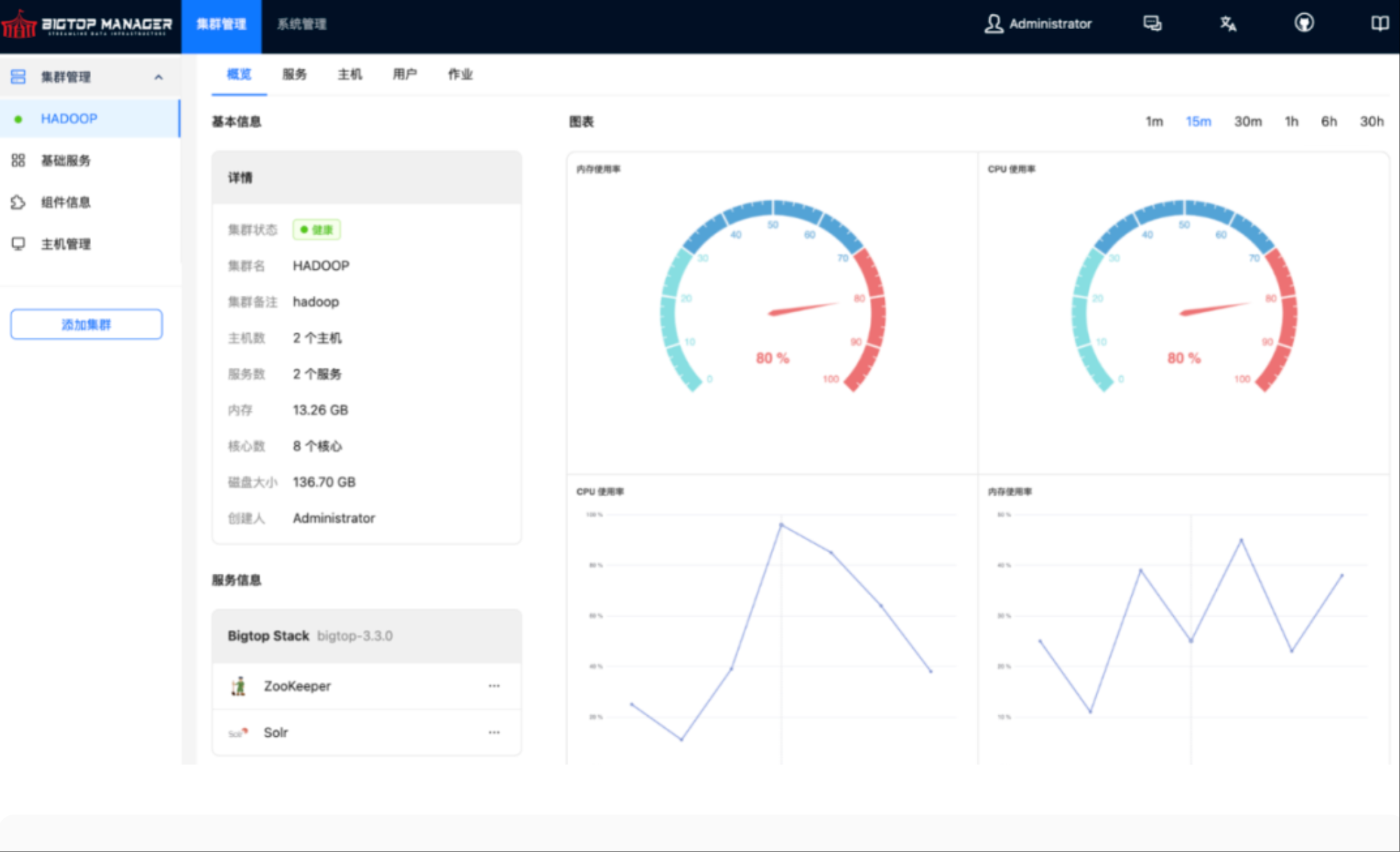
國內開發者貢獻的 CloudEon 和 datasophon 也同樣值得嘗試,它們的貢獻者主力還是來自國內開發者的用愛發電。最近更新頻率比較低。但它們的架構設計上比 Ambari 要輕量許多。如果你是大數據的初學者,想先快速搭建集群,它們或許是比 Ambari 更好的選擇


Bigtop 構建大數據集群安裝包
接下來的內容主要是介紹 Bigtop 和 Ambari 的編譯構建方式,如何從零開始搭建一套基于 Bigtop 的大數據集群
官方 repo 源
Bigtop 有兩種獲得安裝包的方式,一種是直接使用官方 yum/apt 源,還有一種是自行編譯。前者提供的最新 3.5.0 版本支持 debian, ubuntu, openeuler 等系統(3.3.0 支持 centos),直接在系統上配置軟件源,就可以安裝 Hadoop 等組件了,這也是你最快的使用 Bigtop 的方式
# 添加 ubuntu 源
wget -O /etc/apt/sources.list.d/bigtop-3.5.0.list https://dlcdn.apache.org/bigtop/bigtop-3.5.0/repos/ubuntu-24.04/bigtop.list
wget -O- https://dlcdn.apache.org/bigtop/stable/repos/GPG-KEY-Bigtop | sudo apt-key add -
# openeuler 源地址
https://dlcdn.apache.org/bigtop/bigtop-3.5.0/repos/openeuler-22.03/bigtop.repo
# centos (3.3.0) 源地址
https://mirrors.huaweicloud.com/apache/bigtop/bigtop-3.3.0/repos/centos-7/bigtop.repo
編譯 Bigtop 組件
Compiling Components for Ambari Bigtop Stack
如果你是個好奇寶寶,不想直接用官方提供的安裝包,就是想體驗一下大數據組件是怎么編譯的,那么恭喜你選擇了一條最有意思(最漫長)的路,你會了解到 Hadoop 生態下的一眾組件 hdfs, hive, hbase, zookeeper, ranger 等等的編譯過程(當然還有各種踩坑)
前面提到 Bigtop 對編譯腳本做了封裝,就在每個組件目錄下的 do-component-build 。從 Hive 的編譯腳本來看,其實編譯指令就是mvn package ,和你手動編譯沒什么區別

在項目根路徑,通過 gradlew 指令即可開始每個組件的編譯
# 列出所有操作
./gradlew tasks
# 初始化編譯環境(安裝 jdk, maven, python3 等)
# 比較費時,更建議使用官方 slave 鏡像,省略這一步
./gradlew toolchain
# 在 output 目錄下創建 yum / apt 源目錄 (下面的編譯指令也會自動創建)
./gradlew yum
./gradlew apt
# 以下是各個組件的編譯指令
# parentDir: 組件安裝父目錄
# pkgSuffix: 組件名稱中是否添加 Bigtop 的版本,比如 hive 的安裝包名字為 hive_3_3_0
# buildThreads: 是否并發編譯,將在 mvn 編譯參數中加上 -T 2C
# repo: 編譯完成后更新 yum / apt repo
# Bigtop 相關工具鏈編譯
./gradlew bigtop-select-clean bigtop-select-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
./gradlew bigtop-utils-clean bigtop-utils-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
./gradlew bigtop-jsvc-clean bigtop-jsvc-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
./gradlew bigtop-groovy-clean bigtop-groovy-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
# Hadoop
./gradlew Hadoop-clean Hadoop-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
# hive
./gradlew hive-clean hive-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
# zookeeper
./gradlew zookeeper-clean zookeeper-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
# kafka
./gradlew kafka-clean kafka-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
# hbase
./gradlew hbase-clean hbase-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo
# ranger
./gradlew ranger-clean ranger-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo

注意到所有組件的編譯指令,除了組件名其余部分都是一樣的,這就是 Bigtop 對編譯腳本的封裝起到的作用
比如 "pkg" 這個命令,從 packages.gradle 可以看到識別操作系統的邏輯,包含了執行 patches 、編譯和最后打包的動作,打包時centos 系統就執行 rpmbuild,ubuntu 就執行 debuild
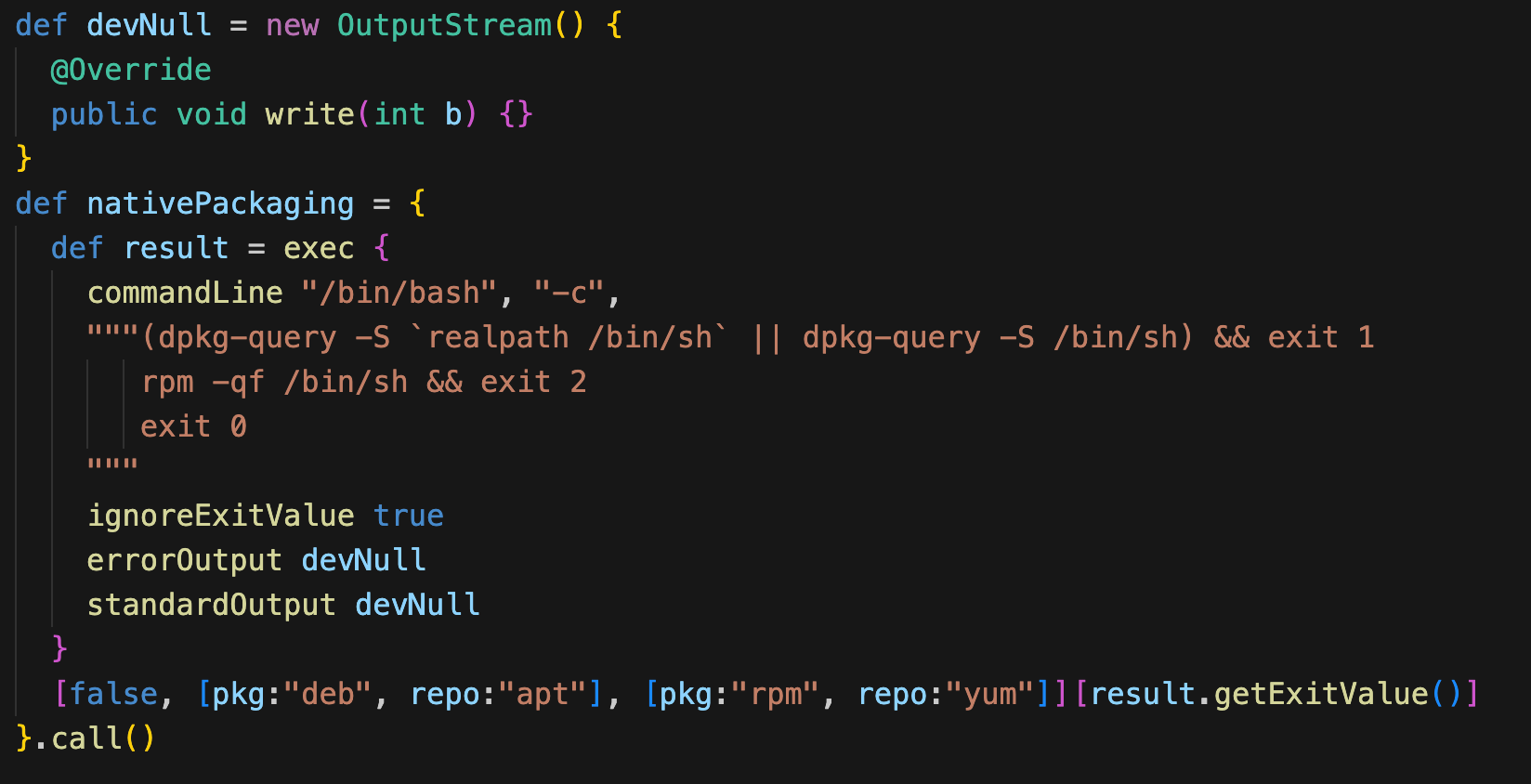
Bigtop 還提供了幾個輔助指令,比如 bigtop-select 可以用來查詢目前集群中哪些組件可以安裝,bigtop-utils 可以查找 java 安裝路徑等,這兩個指令在 Ambari 有用到
當組件編譯完成,Bigtop 源碼目錄下會生成三個目錄: dl 是源碼壓縮包的下載路徑,build 是構建中間目錄,output 則存放組件安裝包和源索引文件
在文件服務器配置自己的源
官方的 Bigtop 源的配置方式剛才提過了,那自己編譯生成的安裝包怎么配源呢,就把整個 output 目錄作為文件服務器指向的目錄就可以
比如我直接在 Bigtop 編譯機器上啟動了 httpd,配置中指定根路徑就為 bigtop/output
DocumentRoot "/opt/coding/bigtop/output"
<Directory "/opt/modules/bigtop/output">
Options Indexes FollowSymLinks
AllowOverride None
Require all granted
</Directory>
那么 yum 和 apt 源的配置方式分別為:
# centos: yum 在 output 目錄構建索引
createrepo .
# 在安裝組件的節點上配置源
echo """[BIGTOP-3.5.0-repo-1]
name=BIGTOP-3.5.0-repo-1
baseurl=http://file_server_host
path=/
enabled=1""" > /etc/yum.repos.d/ambari-bigtop-1.repo
# 刷新
yum -y update
# ubuntu: apt 在 output 目錄構建索引
dpkg-scanpackages . /dev/null | gzip -9c > Packages.gz
# 在安裝組件的節點上配置源
echo "deb [trusted=yes] http://172.16.205.157:8000/bigtop/3.5.0 ./" > /etc/apt/sources.list.d/bigtop.list
# 刷新
apt -y update
擴展: Bigtop 的工具和容器
最后再介紹一下 Bigtop 提供的容器和編譯部署工具,這些可以幫助你快速了解 Bigtop 的生態,加快構建過程
bigtop/slaves - Bigtop 官方提供的編譯鏡像, 預裝了 jdk、maven、ant、python3、以及 Hadoop 組件編譯時需要的基礎環境( puppet、protobuf、r-base 等),方便你直接編譯 Bigtop。如果你所使用的操作系統鏡像沒有提供以上的依賴,強烈建議直接使用 slave 鏡像來編譯
# 運行 bigtol slave 鏡像
# 支持編譯 Bigtop 3.3.0 的鏡像,centos7、ubuntu 和 x86 以及 arm 的架構版本都有,還是挺全的
docker run -itd --hostname dev_Bigtop --name dev_Bigtop -v /opt/coding:/opt/coding Bigtop/slaves:3.3.0-centos-7
docker run -itd --hostname dev_Bigtop --name dev_Bigtop -v /opt/coding:/opt/coding Bigtop/slaves:3.3.0-centos-7-aarch64
# ubuntu 版本
docker run -itd --hostname dev_Bigtop --name dev_Bigtop -v /opt/coding:/opt/coding Bigtop/slaves:3.5.0-ubuntu-24.04
docker run -itd --hostname dev_Bigtop --name dev_Bigtop -v /opt/coding:/opt/coding Bigtop/slaves:3.5.0-ubuntu-24.04-aarch64
bigtop/sandbox: 基于 Bigtop 編譯的 Hadoop 單點服務打包成的鏡像,可以一鍵運行單點 HDFS、HBase 和 Spark 等。不過使用方式有限,只能做個展示效果。而且在 Bigtop 1.2.1 之后,鏡像就沒有再更新了,提供的 HDFS 版本只到 2.7.3
# 啟動 hdfs
docker run -d --name dev_Bigtop_hdfs -p 50070:50070 Bigtop/sandbox:1.2.1-ubuntu-16.04-hdfs
# 啟動 hdfs + hbase
docker run -d --name dev_Bigtop_hbase -p 50070:50070 -p 16010:16010 Bigtop/sandbox:1.2.1-ubuntu-16.04-hdfs_hbase
# 啟動 hdfs + spark
docker run -d --name dev_Bigtop_spark -p 50070:50070 -p 8080:8080 -p 7077:7077 Bigtop/sandbox:1.2.1-ubuntu-16.04-hdfs_spark-standalone

最后是 bigtop/puppet,這個鏡像是 slave 的前身,它的構建代碼在 Bigtop 1.3.0 之前的版本還是有的 ( docker/bigtop-puppet/build.sh ) ,但最新代碼已經刪除了。和 slave 相比,puppet 鏡像只是把 puppetize.sh 拷貝到鏡像中,還沒有實際安裝 puppet,也沒有執行 puppet apply -e "include Bigtop_toolchain::installer" 安裝基礎依賴( slave 鏡像提供的所有依賴 ),所以唯一的作用也許就是讓你可以從真正的開頭去構建 Bigtop 鏡像,以及從 tags 可以知道 Bigtop 目前支持的操作系統,除此之外沒有其他作用
擴展: Bigtop 修復了哪些 issue
在 Bigtop 代碼中我們會看到一些組件的 patch 補丁文件,Hadoop 的 patch 是最多的(11個),這些補丁大部分來自官方 issue,為了升級或解決編譯問題。如果沒有這些 patch,編譯眾多開源服務可以說就是真正的從零開始了,遇到各種編譯問題都要自己找 issue 甚至看代碼解決
所以這里對 Hadoop 的 patch 稍作整理,看看主要是哪些問題的修復
注意: 帶有 issue 數字編號的 patch 都是來自 Hadoop 組件官方的修復,沒有編號的則是 Bigtop 為了解決編譯問題自己加的,主要關注前者
-
patch0-HADOOP-18867-branch-3.3.diff: zookeeper 3.6 已經停止維護,升級到 3.6.4 即 3.6 的最后一個小版本,為升級到 3.7 做準備
-
patch1-HADOOP-19116-3.3.6: 升級 zookeeper 到 3.8.4 以解決 zookeeper 在 watcher 機制的數據安全問題
-
patch10-HDFS-17754-branch-3.3: 添加 Hadoop native 中用到的 uriparser2 庫的相關說明
-
patch2-HADOOP-18583: native 代碼適配 openssl 3.x 版本,替換兩個加解密相關的變量名
-
patch3-fix-broken-dir-detection: Hadoop-functions.sh 腳本中增加對 HADOOP_COMMON_HOME、HADOOP_HDFS_HOME 等環境變量對應的路徑是否存在的判斷
-
patch4-HADOOP-19551 & patch9-HDFS-17226.diff: 編譯 native 時添加 gcc 參數 implicit-function-declaration,并在4個 .h 頭文件中補充 #include
已解決編譯問題 -
patch5-fix-kms-shellprofile: 這個只是把 Hadoop-kms.sh 中創建 ${HADOOP_HOME}/temp 目錄的邏輯給去掉了,估計只是為了跳過編譯中的 test error ,沒有其他實際意義
-
patch6-fix-httpfs-sh: 同上,httpfs.sh 中用到的 HADOOP_HOME 替換成 HADOOP_HDFS_HOME,無實際意義
-
patch7-remove-phantomjs-in-yarn-ui: Yarn ui 中移除 phantomjs 模塊,解決在缺少 phantomjs 的系統( 如 arm 版本的 centos )編譯失敗的問題
-
patch8-YARN-11528-triple-beam: 在 resolutions 中限定 triple-beam 的版本為 1.3 ,解決 1.4.1 版本不兼容 yarn ui 編譯使用的 v12 nodejs 的問題
-
patch9-HDFS-17287: HDFS yarn 模塊支持并行編譯,實測不指定并發的非首次編譯( maven 依賴在本地都已經下載)的時間大約30分鐘,加上4個線程并發后編譯時間縮短到15分鐘
-
patch0-KAFKA-14661: 升級 zookeeper 依賴版本從 3.6.4 到 3.8.2
-
patch3-RANGER-3206-commit-2: 修復 ranger 執行 db 初始化時報字符串變量轉換的錯誤
-
patch0-RANGER-4952: 支持 hive 4.0
Ambari 編譯和大數據集群部署
Bigtop 的安裝包我們準備好了,如何結合 Ambari 來部署大數據集群呢
第一步又是我們最喜歡的編譯環節,因為Ambari 官方是沒有提供直接的 apt 或者 rpm 安裝包的。這里建議編譯 3.0 或者最新分支( 3.0 基本是最后一個大版本了 )
Ambari 編譯和安裝
參考: Building Apache Ambari from Source
Ambari 的編譯雖然不像 Bigtop 那樣需要安裝很多依賴,只需要 java 和 python,但關于 python 版本還是需要特別提一下: 官方文檔提到 3.0 腳本是基于 python3 適配的,但其實它的一部分腳本還依賴 python2,所以編譯和運行 Ambari 的系統仍需要裝有 python2。另外它適配的 python3 版本基于 python 3.9,其用到的 imp 在 3.12 之后被移除了,所以要注意不能用最新版的 python3
# Ambari 3.0 依賴 jdk17
export JAVA_HOME=/usr/java/jdk-17.0.15+6
source /opt/modules/miniconda2/bin/activate py3
# ubuntu
mvn -Drat.skip=true -DskipTests -Dcheckstyle.skip=true package jdeb:jdeb
# ./ambari-server/target/ambari-server_3.1.0.0-SNAPSHOT-dist.deb
# ./ambari-agent/target/ambari-agent_3.1.0.0-SNAPSHOT.deb
# centos
mvn -Drat.skip=true -DskipTests -Dcheckstyle.skip=true package rpm:rpm
# ambari-server/target/rpm/ambari-server/RPMS/x86_64/ambari-server-3.1.0.0-SNAPSHOT.x86_64.rpm
# ambari-agent/target/rpm/ambari-agent/RPMS/x86_64/ambari-agent-3.1.0.0-SNAPSHOT.x86_64.rpm
編譯完成后,server 和 agent 的安裝包在各自 module 的target 目錄下。然后可以按照一個 server 、多個 agent 節點的分配方式,開始安裝 Ambari
# centos
rpm -ivh ambari-server-3.1.0.0-SNAPSHOT.x86_64.rpm
rpm -ivh ambari-agent-3.1.0.0-SNAPSHOT.x86_64.rpm
# ubuntu
dpkg -i ambari-server_3.1.0.0-SNAPSHOT-dist.deb
dpkg -i ambari-agent_3.1.0.0-SNAPSHOT.deb
# 注: agent 還需要安裝 bigtop-select 用于 Ambari 查找組件版本
yum -y install bigtop-select
apt -y install bigtop-select
Ambari 初始化和啟動
啟動 Ambari 就是啟動 server 和 agent,兩者之間通過 http 和 websocket 的方式通信,server 負責用戶交互和服務狀態管理,agent 負責處理來自 server 下發的任務
先對 Ambari server 使用的數據庫和配置做初始化
# 1. 手動下載 jdbc jar 到共享 jar 目錄
wget -O /usr/share/java/mysql-connector-java-8.0.30.jar https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar
# 2. 手動補充 server.jdbc.driver.path 配置,否則 Ambari server setup 會報錯
echo "server.jdbc.driver.path=/usr/share/java/mysql-connector-java-8.0.30.jar" >> /etc/ambari-server/conf/Ambari.properties
# 3. 初始化 server
# -s: silent mode
# --ambari-java-home: Ambari server 使用的 jdk
# --stack-java-home: Hadoop 組件使用的 jdk
# 在組件管理 py 代碼中會通過 config["AmbariLevelParams"]["java_home"] 獲取
ambari-server setup -s --ambari-java-home /usr/java/jdk-17.0.16+8 --stack-java-home=/usr/java/jdk-11.0.28+6 --database=mysql --databasehost=mysql_host --databaseport=mysql_port --databasename=mysql_db --databaseusername=mysql_user --databasepassword=mysql_pwd --jdbc-driver=/usr/share/java/mysql-connector-java-8.0.30.jar --jdbc-db=mysql
# 4. 啟動 server
systemctl restart ambari-server
啟動后打開默認 8080 端口,通過 admin/admin 默認賬號登錄

給集群起個名字之后,接下來是配置 Bigtop 版本和安裝源
上面的 version definition 是 Ambari 源碼中的 Bigtop 組件定義,目前只到 Bigtop 3.3,這個不一定和我們實際編譯的(最新到 3.5)一致,但對安裝沒有影響,實際安裝的版本以 bigtop-select 指定的版本為準
下面的 Repositories 配置你自己的文件服務器地址或者是官方源。如果你在之前已經手動添加了 repo 文件,也可以選擇 use local repo

下一步是添加 Ambari agent 節點,這里可以用 server 通過 ssh 向 agent 節點主動注冊,或者手動啟動 agent 來向 server 注冊的方式
注: Ambari 可以配置組件的自動重啟,但 server 的 agent 本身的自動重啟就需要通過系統的 systemctl enable ambari-server / ambari-agent 來開啟了
# 設置 Ambari server host 域名地址
sed -i "s#hostname=.*#hostname=Ambari_server_host#g" /etc/ambari-agent/conf/ambari-agent.ini
# 啟動 agent
systemctl restart ambari-agent
等待 agent 顯示注冊成功
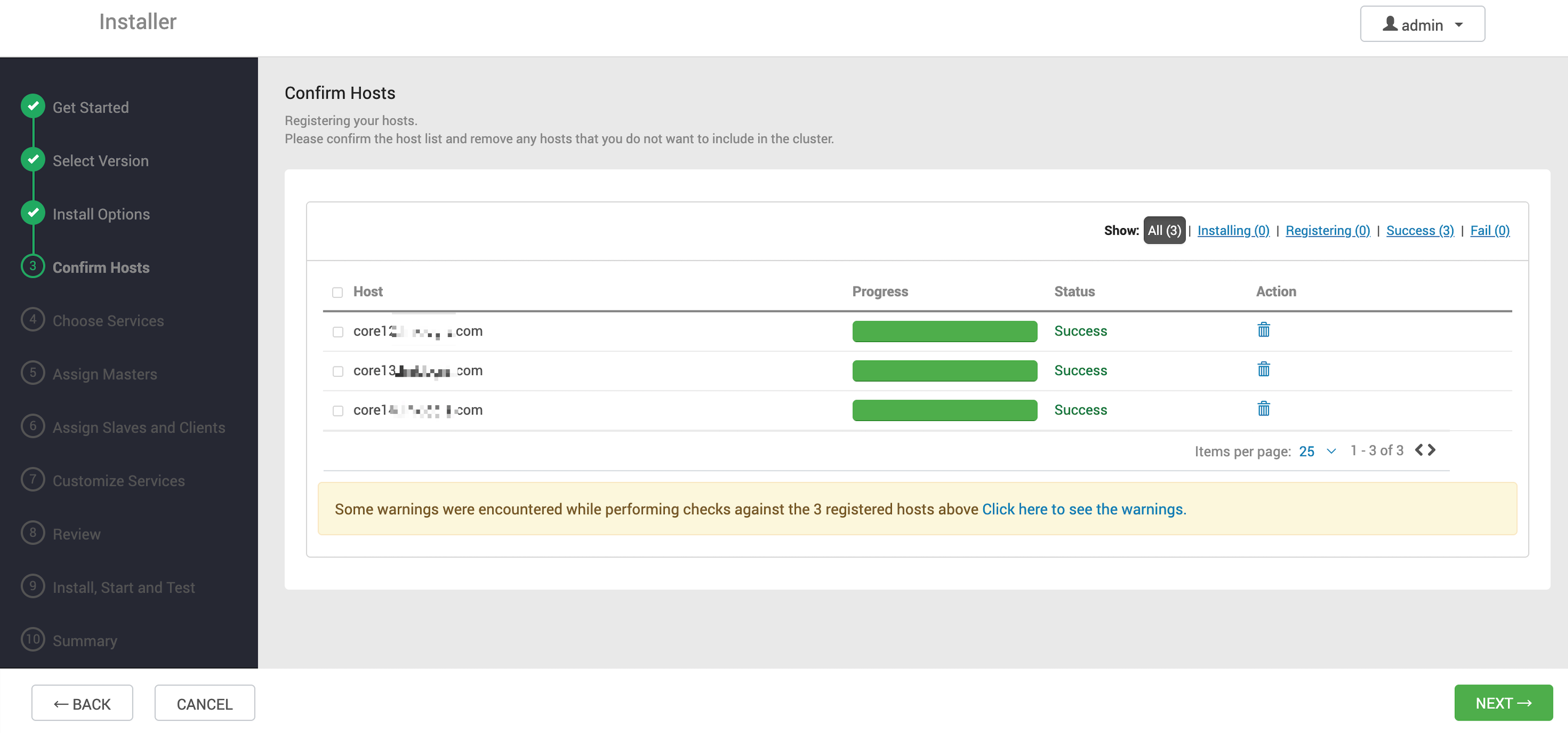
組件部署
添加了 agent 節點,下一步 choose services 就是正式安裝 Bigtop 構建的組件了
第一個組件可以選擇 zookeeper。默認會勾選所有組件,但沒必要全都安裝。zookeeper 是很多服務的依賴組件,選擇第一個安裝是合理的
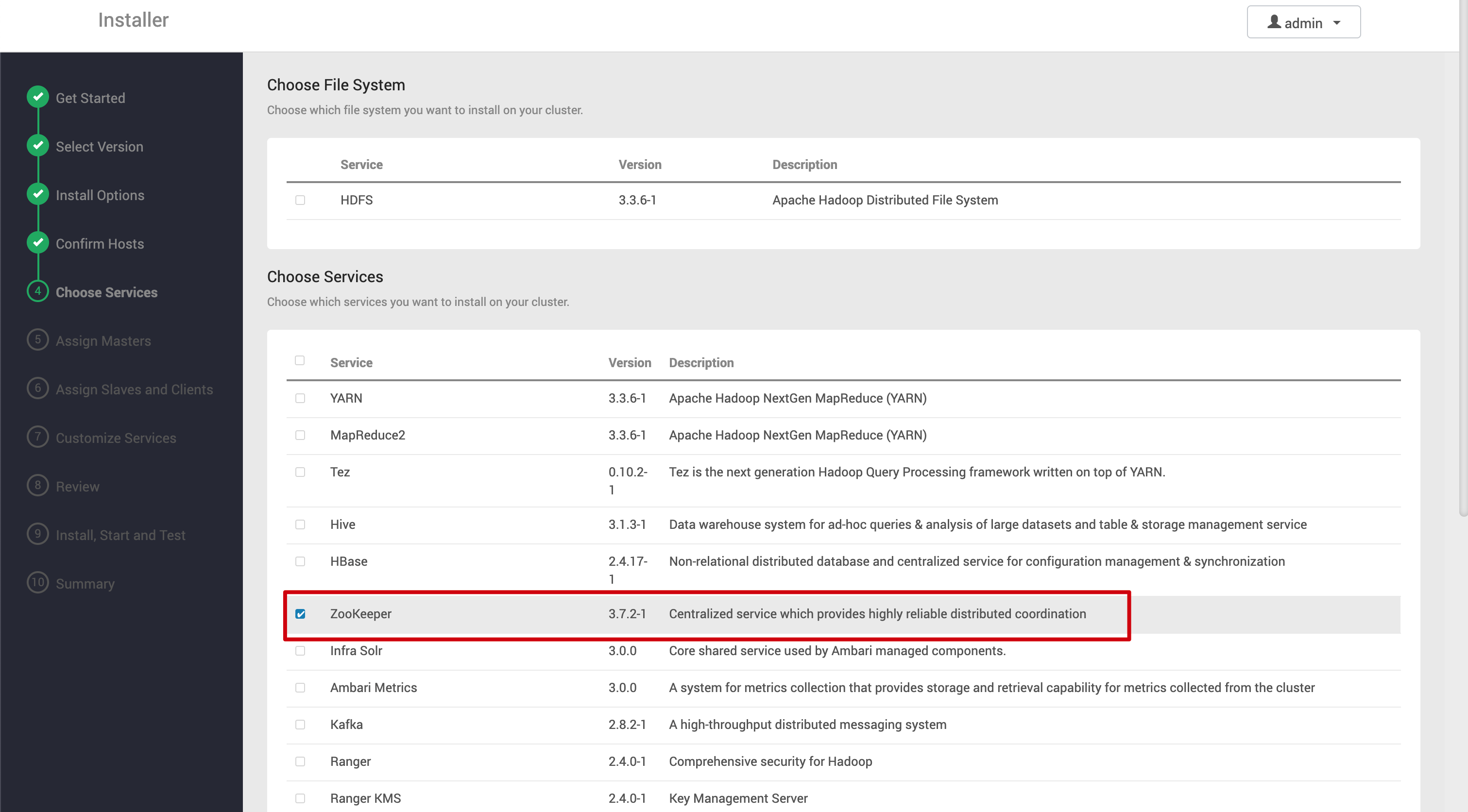
zookeeper server 和 agent 的安裝節點選擇三個

通過 Ambari 安裝組件的一大好處就是很多配置它都幫你優化好了,除了一些存儲數據路徑,或者是需要針對虛擬機規格情況特別調優的配置,需要自行確認

最后等待 zookeeper 在后臺安裝完成,回到首頁的效果
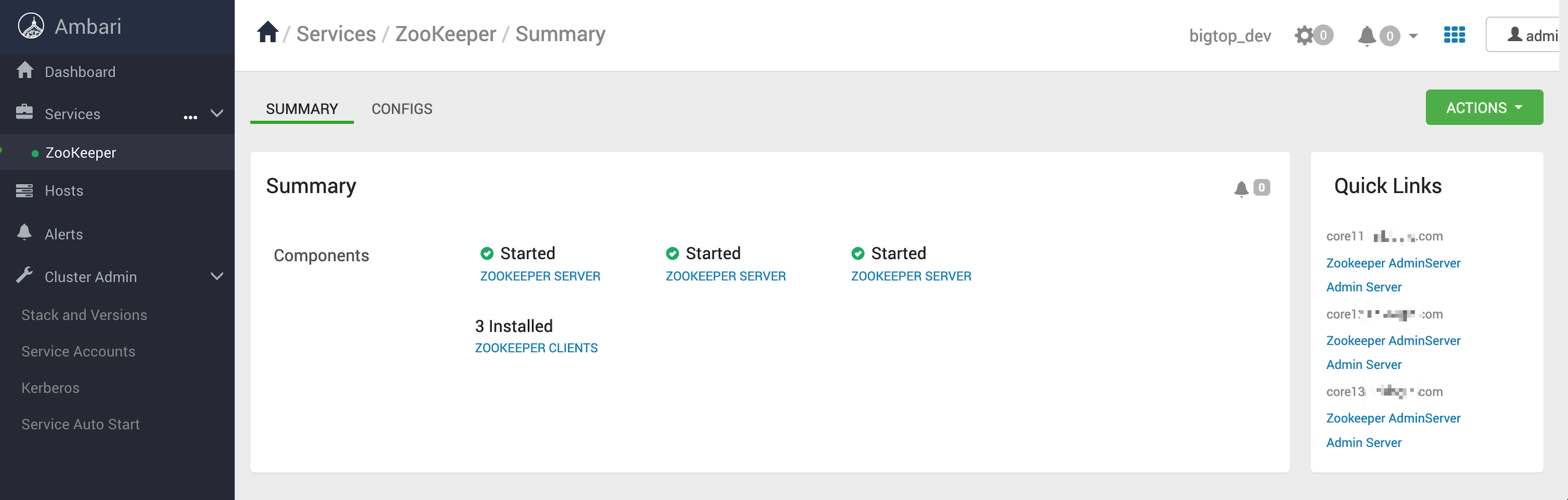
集群安裝完整事項
讓我們再來回顧一下從零開始部署一套真正可用的大數據集群的所有步驟吧
-
支持 Bigtop 構建的虛擬機, centos8、ubuntu、rockylinux、debian、openeuler 等
-
構建 Bigtop 安裝包,建議在官方 slave 容器內構建
-
Ambari 編譯
-
Ambari 安裝
-
系統配置 Bigtop yum/apt 源
-
Ambari 配置和啟動
-
可按照 zookeeper -> HDFS -> Yarn -> Hive -> Ranger -> 其他組件的順序安裝集群
-
HDFS 、Hive 等核心組件配置高可用
-
監控配置( 可基于 Ambari metrics 或 prometheus )
-
日志采集(solr)
-
基礎功能驗證
總結
shall we start now
再回到開頭的問題,對已經穩定運行幾年的集群再做大升級,這是否有必要。經過這一趟集群部署和體驗下來,現在可以明確說,當然有必要。因為這不僅是一次升級,更是可以讓我們盡可能乘上還在不斷前進的大數據開源列車。不管以后是繼續用這套開源架構,還是將大數據 deploy on k8s,又或是選擇公有云 EMR,有了這次升級的鋪墊,后面再做任何大的架構升級都會更有信心
一顆種子種下的最好時間永遠不是未來,而是現在
從 CDH 到 Bigtop 的改進點
| 組件 | 版本升級 | 特性 |
|---|---|---|
| 基礎環境 | jdk 8 -> 11 | 性能和功能提升 |
| 基礎環境 | centos 7 -> ubuntu 24 | 更安全、功能更豐富、性能更好的系統 |
| EMR 組件 | Ambari 2.6 -> 3.0 | 集群管理、維護,可調研 bigtop manager |
| EMR 組件 | HDFS 2.7.3 -> 3.3.6 | 糾刪碼、NameNode 多節點高可用、性能提升等 |
| EMR 組件 | Hive 2.1 -> 3.1.3 | SQL 增加窗口函數、復雜數據類型、性能提升等 |
| EMR 組件 | Sqoop -> Datax/seatunnel | 支持更多數據源之間同步,sqoop 已停止維護 |
| EMR 組件 | Azkaban 3.9 -> 4.0 | bug 修復,基本是最后一個 release,可調研 airflow |
| EMR 組件 | Hue 3.9 -> 4.2 | 界面功能改進、修復編譯問題 |
| EMR 組件 | Jupyter 3.6 -> 4.3 | 功能提升 |
| EMR 組件 | Flink 1.20, CDC 3.4 | 目前主要用于實時數據同步 flink cdc |
| EMR 組件 | Starrocks 3.3 | 實時數倉 |
| 集群管理工具 | emrtool | ETL任務管理, 血緣關系 |

 浙公網安備 33010602011771號
浙公網安備 33010602011771號