深度學習應用簡述
深度學習應用簡述
硬件
首先,深度學習的成功應用離不開硬件的發展。GPU由于其高內存帶寬,非常適合需要存儲很多參數、激活值及梯度值的神經網絡,而且許多神經網絡可以并行運算,GPU在這方面也優于CPU,而GPU相對于CPU有較低的時鐘速度及處理復雜計算的劣勢,由于大部分神經網絡單元并不需要復雜邏輯運算所以也并無很大影響。當然,也寫好高效的GPU上運行的代碼并不容易,值得慶幸的是,現在大部分庫如TensorFlow等都已經將這些封裝好了。另一方面,分布式計算也在飛速發展,所以有了asynchronous stochastic gradient descent,可以極大的加快訓練時模型的更新速度。同時,為了使一些模型能夠有效的運行在手機端,需要對模型進行壓縮(model compression),即用需要內存及計算量更小的模型來替代原來較昂貴的模型。硬件方面,專門為深度學習設計的硬件也在發展,例如谷歌的TPU等。
圖像處理
圖形圖像(computer vision)領域的發展,主要有物體識別,物體標記,圖像轉譯,圖像生成等等,主要應用了之前卷積神經網絡的發展及之后要講到的GAN等模型。有的時候,為了保證模型更好的工作,我們常常也需要借助傳統的圖像預處理等技術,例如normalization, dataset augmentation等等。Normalization的作用主要是減少數據間的變化,例如contrast normalization利用將數據減掉平均值并且將標準差調整到定值的方法降低對比度不同對模型造成的影響。這能夠將樣本映射到一個空間超球,類似于全連接網絡的樣本歸一化。這種空間的均勻化能夠讓神經網絡更快速的學習到特征,從而一定程度上避免了病態條件。
當然還有一種叫白化的操作,這種操作于contrast normalization不同,本質上就是批歸一化,是將樣本變為標準多維高斯分布,從而利于梯度下降算法的更新。
Dataset Augmentation利用對原數據做一些微調人為增加訓練數據的方法使得模型在微擾下更穩定,常見的方法有平移、翻轉、添加隨機噪聲等等。
語音識別
語音識別(speech recognition)也得益于深度學習。語音識別即輸入時一系列的聲音信號,輸出是對應的文字,之前常采用的是HMM(Hidden Markov)與GMM(Gaussian mixture model)相結合的辦法,而現在通常采用的是RNN模型。
n-gram
自然語言處理(Natural language processing)即將某種語言翻譯成其他語言或機器語言,通常依賴于詞組句子等的概率分布。之前采用的通常是一些概率統計模型,例如基于n-gram的模型定義了基于前n-1個詞匯時第n個詞的條件概率
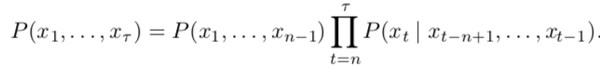
但是該模型會受到維度的詛咒,通常對于詞匯量為 \(V\) 的問題,有 \(V^n\) 種n-gram,計算量很大,而且實際上大部分n-gram并不會出現在訓練集中。
為了解決維度過高的問題,我們可以將單詞s映射到word embedding空間,可以將其想為一個更低維度的空間,并且相似的單詞在該空間中距離更近。而為了從這一表征空間重新映射到單詞,我們需要利用Softmax,而由于映射到的類是 \(V\) 的量級,普通的Softmax計算量過大,這時候可以采用Hierachical Softmax, Importance Sampling等方法。
神經網絡模型
現在效果較好的Neural Machine Translation系統通常采用Encoder-Decoder的結構,這在第十章已經介紹過,即利用Encoder將輸入的文字序列轉化為一個新的表征context,再利用Decoder將context轉化為所需要的語言文字,Encoder、Decoder通常采用RNN結構。近期發現利用Attention模型和RNN結合能取得更好的效果。其基本思想是RNN的輸出向量對于長句子來說之前的上下文會被遺忘,為了考慮整個句子的context,我們將這個信息存儲起來,并在輸出不同位置的結果時將側重點(利用不同的權重參數)放在不同的記憶元素上,即對feature vector做weighted average,這種attention方法最早被應用在圖像識別中,推廣到機器翻譯中也收獲了很好的效果。這在之前的補充章節中也已經介紹(基于注意力的RNN)。
其他的機器學習的應用還有推薦系統。推薦系統主要依賴于用戶過去的購買記錄來計算不同用戶或產品之間的相似性,這種方法叫做collaborative filtering,但這種方法對于新用戶或新商品來說由于缺乏歷史信息效果較差,通常我們會提取用戶或商品其他方面的信息,并利用神經網絡將其映射到embedding空間來尋找相似的推薦。除了監督學習模型,為了平衡exploration(嘗試獲取之前未探索過的信息)和exploitation(從已有信息盡可能高的獲利)的問題,還可以嘗試強化學習(Reinforcement Learning)的方法,因為強化學習可以同時平衡exploration和exploitation,其采用策略來進行選擇action,并從environment中獲得reward。
小結
深度學習還有很多其他方面的應用,在此主要是列舉比較有代表性的一些應用。至此,工業中實際應用的深度學習知識總結完畢,下一章開始總結處于研究階段的機器學習方法,如處理小數據以及通用機器學習模型等問題。而第三部分內容難度大,理應有大量推導,但由于花書的篇幅有限,所以其對這部分的知識描寫較為晦澀,難以理解,如果想要深入學習應該以論文為主。因此對于后面部分的筆記將會偏向于總結,待以后學習到時再進行補充。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號