

關(guān)系數(shù)據(jù)的可視化
實驗名稱
關(guān)系數(shù)據(jù)可視化
實驗?zāi)康?/span>
1.掌握關(guān)系數(shù)據(jù)在大數(shù)據(jù)中的應(yīng)用
2.掌握關(guān)系數(shù)據(jù)可視化方法
3. python 程序?qū)崿F(xiàn)圖表
實驗原理
在傳統(tǒng)的觀念里面,一般都是致力于尋找一切事情發(fā)生的背后的原因。現(xiàn)在要做的是嘗試著探索事物的相關(guān)關(guān)系,而不再關(guān)注難以捉摸的因果關(guān)系。這種相關(guān)性往往不能告訴讀者事物為何產(chǎn)生,但是會給讀者一個事物正在發(fā)生的提醒。關(guān)系數(shù)據(jù)很容易通過數(shù)據(jù)進行驗證的,也可以通過圖表呈現(xiàn),然后引導(dǎo)讀者進行更加深入的研究和探討。分析數(shù)據(jù)的時候,可以從整體進行觀察,或者關(guān)注下數(shù)據(jù)的分布。數(shù)據(jù)間是否存在重疊或者是否毫不相干?也可以更寬的角度觀察各個分布數(shù)據(jù)的相關(guān)關(guān)系。其實最重要的一點,就是數(shù)據(jù)進行可視化后,呈現(xiàn)眼前的圖表,它的意義何在。是否給出讀者想要的信息還是結(jié)果讓讀者大吃一驚?
就關(guān)系數(shù)據(jù)中的關(guān)聯(lián)性,分布性。進行可視化,有散點圖,直方圖,密度分布曲線,氣泡圖,散點矩陣圖等等。本次試驗主要是直方圖,密度圖,散點圖。直方圖是反應(yīng)數(shù)據(jù)的密集程度,是數(shù)據(jù)分布范圍的描述,與莖葉圖類似,但是不會具體到某一個值,是一個整體分布的描述。密度圖可以了解到數(shù)據(jù)分布的密度情況。密度圖可以了解到數(shù)據(jù)分布的密度情況。散點圖將序列顯示為一組點。值由點在圖表中的位置表示。散點圖通常用于比較跨類別的聚合數(shù)據(jù)。
實驗環(huán)境
OS:Windows
python:v3.6
實驗步驟
數(shù)據(jù)集準(zhǔn)備:
數(shù)據(jù)源:

一、安裝Python所需要的第三方模塊
pip install seaborn
二、實驗
1.請使用 seaborn 模塊中的 jointplot 方法將散點圖,密度分布圖和直方圖合為一體,數(shù)據(jù)選取murder列及burglary列,探究兩種犯罪類型的相關(guān)關(guān)系,代碼及效果如下:
1 import pandas as pd 2 import seaborn as sns 3 import matplotlib.pyplot as plt 4 from scipy.stats import pearsonr 5 from matplotlib.ticker import MultipleLocator 6 7 # 從 CSV 文件中讀取數(shù)據(jù) 8 file_path = 'crimeRatesByState2005.csv' 9 df = pd.read_csv(file_path) 10 11 # 計算皮爾遜相關(guān)系數(shù)和 p 值 12 corr, p_value = pearsonr(df['murder'], df['burglary']) 13 14 # 使用 jointplot 繪制圖表 15 g = sns.jointplot(x='murder', y='burglary', data=df, 16 kind='reg', # 中心部分使用帶有回歸直線的散點圖 17 scatter_kws={'color': 'green'}, # 設(shè)置散點顏色為綠色 18 line_kws={'color': 'green'}, # 設(shè)置回歸直線顏色為綠色 19 marginal_kws=dict(bins=15, fill=False, color='green')) # 設(shè)置邊緣圖參數(shù),顏色為綠色 20 21 # 在圖中添加皮爾遜相關(guān)系數(shù)和 p 值的標(biāo)注 22 annotation_text = f"pearsonr = {corr:.2f}; p = {p_value:.2e}" 23 g.ax_joint.text(0.5, 0.9, annotation_text, transform=g.ax_joint.transAxes, 24 bbox=dict(facecolor='white', alpha=0.8), ha='center') 25 26 # 添加標(biāo)題 27 g.fig.suptitle('謀殺率和入室盜竊率的關(guān)系', y=1.02) 28 29 # 設(shè)置中文字體 30 plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei'] 31 plt.rcParams['axes.unicode_minus'] = False 32 33 # 設(shè)置橫軸和縱軸的刻度間距 34 x_major_locator = MultipleLocator(2.5) 35 y_major_locator = MultipleLocator(200) 36 g.ax_joint.xaxis.set_major_locator(x_major_locator) 37 g.ax_joint.yaxis.set_major_locator(y_major_locator) 38 39 # 設(shè)置坐標(biāo)軸范圍 40 g.ax_joint.set_xlim(0, 12.5) 41 g.ax_joint.set_ylim(0, 1600) 42 43 # 顯示圖表 44 plt.show()
本代碼通過一系列操作,實現(xiàn)了對犯罪數(shù)據(jù)中謀殺率和入室盜竊率關(guān)系的可視化分析與統(tǒng)計指標(biāo)計算。該分析為進一步研究犯罪類型之間的關(guān)聯(lián)提供了直觀且有價值的信息。在實際應(yīng)用中,可基于此方法拓展到更多犯罪類型之間的關(guān)系研究,或結(jié)合其他因素進行更深入的多變量分析,為犯罪預(yù)防和資源調(diào)配等決策提供數(shù)據(jù)支持。

從繪制的聯(lián)合圖及標(biāo)注信息可知:
相關(guān)性判斷:皮爾遜相關(guān)系數(shù)corr反映了謀殺率和入室盜竊率之間的線性相關(guān)程度。若corr接近 1,表明二者存在較強正相關(guān);若接近 -1,則為較強負(fù)相關(guān);若接近 0,則線性相關(guān)性較弱。具體數(shù)值需結(jié)合實際計算結(jié)果判斷。
顯著性檢驗:p 值用于判斷相關(guān)性是否顯著。一般來說,當(dāng) p 值小于 0.05 時,可認(rèn)為兩變量之間的相關(guān)性在統(tǒng)計上是顯著的,即這種相關(guān)性不太可能是偶然因素導(dǎo)致;若 p 值大于 0.05,則無法拒絕零假設(shè),即不能確定存在顯著相關(guān)性。
圖形直觀展示:聯(lián)合圖的散點分布和回歸直線斜率可輔助判斷相關(guān)性。散點越集中于回歸直線,說明線性關(guān)系越強;回歸直線斜率為正表示正相關(guān),斜率為負(fù)表示負(fù)相關(guān)。邊緣直方圖則呈現(xiàn)了兩個變量各自的分布特征,如是否存在異常值、數(shù)據(jù)的集中趨勢等。
2.動態(tài)散點
1 from pyecharts.charts import EffectScatter 2 from pyecharts import options as opts 3 import pandas as pd 4 5 try: 6 # 讀取數(shù)據(jù)集 7 crime = pd.read_csv('crimeRatesByState2005.csv') 8 # 篩選掉 "United States" 和 "District of Columbia" 這兩行數(shù)據(jù) 9 crime2 = crime[crime.state != "United States"] 10 crime2 = crime2[crime2.state != "District of Columbia"] 11 12 # 創(chuàng)建動態(tài)散點圖對象 13 es = ( 14 EffectScatter() 15 .add_xaxis(crime2['murder'].tolist()) 16 .add_yaxis( 17 series_name="arrow_sample", 18 y_axis=crime2['burglary'].tolist(), 19 symbol="arrow", 20 label_opts=opts.LabelOpts(is_show=False), # 不顯示標(biāo)簽 21 effect_opts=opts.EffectOpts(color="red") # 設(shè)置漣漪特效顏色為紅色 22 ) 23 .set_global_opts( 24 title_opts=opts.TitleOpts(title="動態(tài)散點圖示例"), 25 xaxis_opts=opts.AxisOpts(name="謀殺率"), 26 yaxis_opts=opts.AxisOpts(name="入室盜竊率"), 27 legend_opts=opts.LegendOpts(is_show=True) 28 ) 29 ) 30 31 # 渲染圖表 32 es.render("C:/Users/Administrator/Desktop/crime.html") 33 except FileNotFoundError: 34 print("未找到指定的 CSV 文件,請檢查文件路徑。") 35 except Exception as e: 36 print(f"發(fā)生未知錯誤: {e}")
本代碼利用pyecharts和pandas庫成功實現(xiàn)了對犯罪數(shù)據(jù)的讀取、處理和可視化。通過創(chuàng)建動態(tài)散點圖,能夠清晰地展示謀殺率和入室盜竊率之間的關(guān)系。代碼中的異常處理機制保證了程序在遇到常見錯誤時能夠給出明確的提示信息。在實際應(yīng)用中,可根據(jù)具體需求對代碼進行擴展,如添加更多的數(shù)據(jù)篩選條件、調(diào)整圖表的樣式和參數(shù)等,以滿足不同的分析和展示需求。
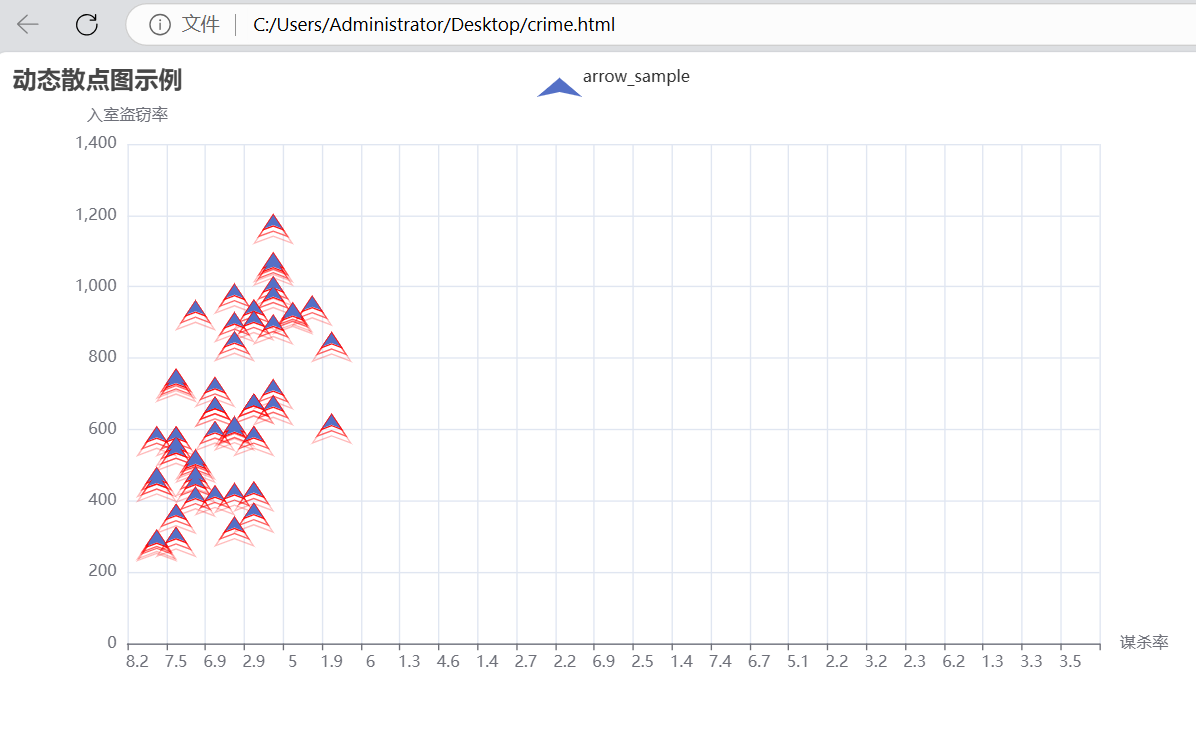
通過運行這段代碼,我們可以得到一個動態(tài)散點圖,其中每個箭頭代表一個州的謀殺率和入室盜竊率的組合。從圖中可以直觀地觀察到謀殺率和入室盜竊率之間的大致關(guān)系,例如是否存在正相關(guān)、負(fù)相關(guān)或無明顯關(guān)聯(lián)。漣漪特效的設(shè)置增加了圖表的視覺吸引力,有助于吸引用戶的注意力。同時,坐標(biāo)軸名稱和圖例的設(shè)置使圖表更易于理解。
3.請使用矩陣圖表示數(shù)據(jù)集中七種犯罪類型之間的相關(guān)關(guān)系 4 (提示:請?zhí)蕹?United States 和 District of Columbia 兩行表示均值和異常的數(shù)據(jù)),效果如下:
1 import pandas as pd 2 import seaborn as sns 3 import matplotlib.pyplot as plt 4 5 # 讀取數(shù)據(jù)集 6 df = pd.read_csv("crimeRatesByState2005.csv", index_col='state') 7 8 # 定義七種犯罪類型列名 9 crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 10 'burglary', 'larceny_theft', 'motor_vehicle_theft'] 11 df_filtered = df[crime_types] 12 13 # 設(shè)置 seaborn 樣式 14 sns.set(style="whitegrid") 15 16 # 創(chuàng)建圖形,調(diào)整圖形大小 17 plt.figure(figsize=(10, 8)) 18 19 # 創(chuàng)建散點圖矩陣 20 pairplot = sns.pairplot(df_filtered, 21 diag_kind='hist', # 對角線顯示直方圖 22 plot_kws={'alpha': 0.6, # 設(shè)置透明度 23 'edgecolor': 'w'}) 24 # 添加標(biāo)題 25 plt.suptitle('Seven Crime Types Scatterplot Matrix', y=1.03, fontsize=16) 26 27 # 調(diào)整子圖布局 28 plt.tight_layout() 29 30 # 顯示圖形 31 plt.show()
本代碼通過 pandas、seaborn 和 matplotlib 庫的協(xié)同使用,成功實現(xiàn)了對犯罪數(shù)據(jù)的可視化分析,生成了七種犯罪類型的散點圖矩陣。代碼結(jié)構(gòu)清晰,邏輯連貫,為進一步分析犯罪類型之間的關(guān)系提供了直觀的工具。在實際應(yīng)用中,可以根據(jù)需要對代碼進行擴展,例如添加更多的圖形樣式設(shè)置、計算相關(guān)性系數(shù)等,以更深入地挖掘數(shù)據(jù)背后的信息。同時,對于不同的數(shù)據(jù)集,只需修改數(shù)據(jù)文件路徑和犯罪類型列名,即可快速應(yīng)用該代碼進行分析。

通過運行這段代碼,我們得到了一個七種犯罪類型的散點圖矩陣。從圖中可以直觀地觀察到各犯罪類型之間的關(guān)系: 對角線直方圖:展示了每種犯罪類型的分布情況,例如可以看出某種犯罪類型的高發(fā)區(qū)間和集中趨勢。 非對角線散點圖:反映了不同犯罪類型之間的相關(guān)性。如果散點呈現(xiàn)出某種趨勢(如正相關(guān)或負(fù)相關(guān)),則說明這兩種犯罪類型之間可能存在一定的關(guān)聯(lián);如果散點比較分散,則說明相關(guān)性較弱。
4.請使用其它合適的可視化方法探究數(shù)據(jù)集中七種犯罪類型之間的相關(guān)關(guān)系,請給出代碼及運行結(jié)果.
1 import pandas as pd 2 import seaborn as sns 3 import matplotlib.pyplot as plt 4 import numpy as np 5 6 # 加載數(shù)據(jù) 7 data = pd.read_csv('crimeRatesByState2005.csv') 8 data.columns = ['state', 'murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft', 'population'] 9 data = data.dropna() 10 11 # 剔除 United States 和 District of Columbia 兩行數(shù)據(jù) 12 data = data[(data['state'] != 'United States') & (data['state'] != 'District of Columbia')] 13 14 # 將無窮大值替換為 NaN 15 data = data.replace([np.inf, -np.inf], np.nan) 16 17 # 刪除包含 NaN 的行 18 data = data.dropna() 19 20 # 選擇犯罪類型列 21 crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft'] 22 23 # 繪制蜂群圖(減小標(biāo)記大小) 24 sns.swarmplot(data=data[crime_types], size=7) 25 plt.title('Swarm Plot of Crime Types') 26 plt.show()
這段代碼實現(xiàn)了對犯罪數(shù)據(jù)的預(yù)處理和可視化分析。在數(shù)據(jù)預(yù)處理階段,通過刪除缺失值、無窮大值以及特殊數(shù)據(jù)行,保證了數(shù)據(jù)的質(zhì)量和分析的準(zhǔn)確性。在可視化階段,使用蜂群圖展示了七種犯罪類型的數(shù)據(jù)分布情況,通過調(diào)整標(biāo)記大小提高了圖形的可讀性。該分析有助于我們直觀地了解不同犯罪類型的發(fā)生率分布特征,為進一步的犯罪學(xué)研究、政策制定等提供了可視化依據(jù)。然而,代碼也有可以改進的地方,例如可以添加更多的圖形設(shè)置,如坐標(biāo)軸標(biāo)簽、圖例等,以增強圖形的信息傳達(dá)能力;還可以結(jié)合其他統(tǒng)計分析方法,深入挖掘不同犯罪類型之間的關(guān)系。

這段代碼主要圍繞犯罪數(shù)據(jù)集展開,先進行數(shù)據(jù)清洗,再利用蜂群圖可視化七種犯罪類型數(shù)據(jù)。以下是對結(jié)果分析的總結(jié): 數(shù)據(jù)質(zhì)量提升:通過多步數(shù)據(jù)預(yù)處理,包括處理缺失值、無窮大值,以及剔除特殊數(shù)據(jù)行,保證了數(shù)據(jù)集的完整性和準(zhǔn)確性,為后續(xù)可視化分析奠定可靠基礎(chǔ)。 蜂群圖有效展示分布:蜂群圖將七種犯罪類型的數(shù)據(jù)點逐一呈現(xiàn),借助較小的標(biāo)記大小,有效避免數(shù)據(jù)點重疊,清晰展示了每種犯罪類型數(shù)據(jù)的分布情況。從中可直觀觀察到數(shù)據(jù)的密集區(qū)域和離散程度,幫助分析不同犯罪類型發(fā)生率的集中趨勢與波動范圍。 標(biāo)題明確主題:添加的標(biāo)題 “Swarm Plot of Crime Types”,清晰點明圖形主題,使讀者能迅速了解該蜂群圖展示的是犯罪類型相關(guān)數(shù)據(jù),增強了可視化的可讀性。
實驗總結(jié)
本次實驗聚焦于關(guān)系數(shù)據(jù)可視化,借助Python編程實現(xiàn)了多種圖表繪制,以探究犯罪數(shù)據(jù)集中不同犯罪類型之間的關(guān)系,達(dá)成了實驗?zāi)康模斋@頗豐。 首先,成功掌握了關(guān)系數(shù)據(jù)在大數(shù)據(jù)分析中的應(yīng)用方式,學(xué)會運用散點圖、直方圖、密度圖、散點矩陣圖和蜂群圖等可視化方法來展示數(shù)據(jù)特征和關(guān)系。熟練使用seaborn、pyecharts、matplotlib和pandas等Python庫進行數(shù)據(jù)處理和圖表繪制,增強了數(shù)據(jù)處理和可視化的實踐能力。其次,通過對犯罪數(shù)據(jù)集的深入分析,發(fā)現(xiàn)不同犯罪類型之間存在著復(fù)雜的關(guān)聯(lián)。例如,在探究謀殺率和入室盜竊率的關(guān)系時,利用皮爾遜相關(guān)系數(shù)和聯(lián)合圖分析,發(fā)現(xiàn)二者存在一定程度的線性相關(guān),且通過顯著性檢驗確定了這種相關(guān)性并非偶然。在七種犯罪類型的整體分析中,散點圖矩陣和蜂群圖展示了各犯罪類型的分布特征和相互關(guān)系,為犯罪學(xué)研究提供了直觀的數(shù)據(jù)支持。編寫的代碼能夠有效完成數(shù)據(jù)讀取、清洗、可視化等任務(wù),但仍有優(yōu)化空間。后續(xù)可進一步完善代碼,如在數(shù)據(jù)預(yù)處理階段增加數(shù)據(jù)驗證和數(shù)據(jù)填充的方法,提高數(shù)據(jù)質(zhì)量;在可視化方面,豐富圖表的樣式設(shè)置,添加更多的交互功能,提升圖表的美觀性和實用性;結(jié)合更多的統(tǒng)計分析方法,深入挖掘數(shù)據(jù)背后的潛在規(guī)律,為犯罪預(yù)防、資源調(diào)配等實際應(yīng)用提供更具價值的決策依據(jù)。本實驗的成果不僅有助于理解關(guān)系數(shù)據(jù)可視化在犯罪學(xué)研究中的重要性,也為其他領(lǐng)域的數(shù)據(jù)探索提供了可借鑒的方法。通過可視化手段將復(fù)雜的數(shù)據(jù)轉(zhuǎn)化為直觀的圖表,能夠更高效地發(fā)現(xiàn)數(shù)據(jù)中的規(guī)律和趨勢,為相關(guān)決策提供有力支持,展現(xiàn)了數(shù)據(jù)可視化在現(xiàn)代數(shù)據(jù)分析中的關(guān)鍵作用。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號