Day3 《機器學習》第三章學習筆記
這一章也是本書基本理論的一章,我對這章后面有些公式看的比較模糊,這一會章涉及線性代數和概率論基礎知識,講了幾種經典的線性模型,回歸,分類(二分類和多分類)任務。
3.1 基本形式
給定由d個屬性描述的示例 x =(x1;x2;… ;xd),其中xi是x在第i個屬性上的取值,線性模型(linear model)試圖學得一個通過屬性的線性組合來進行預測的函數,即:
f(x) = w1x1 + w2x2 + … + wdxd + b
一般用向量形式寫成:
f(x) = wTx + b
其中x =(x1;x2;… ;xd),w和d學得之后,模型就得以確定。
線性模型,形式簡單、易于建模,蘊含著機器學習中一些重要的基本思想,許多功能更為強大的非線性模型(nonlinear model)可在線性模型的基礎上通過引入層級結構或高維映射而得,此外,由于w直觀表達了各屬性在預測中的重要性,因此線性模型有很好的可解釋性(comprehensibility)。例如在西瓜問題中學得“f好瓜(x) = 0.2*x色澤 + 0.5*x根蒂 + 0.3*x敲聲 + 1”。
3.2 線性回歸
給定數據集 D = {(x1, y1), (x2, y2), … , (xm, ym)},其中xi = (xi1;xi2;… ;xid),yi ∈ R。“線性回歸(linear regression)”試圖學得一個線性模型盡可能地預測實值輸出標記。
線性回歸試圖學得
![]()
我們要去確定w和b,在2.3節介紹過,均方誤差(2.2)是回歸任務中最常用的性能度量,因此我們可試圖讓均方誤差最小化,即:
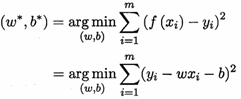
w*, b* 表示w和b的解。
均方誤差,有非常好的幾何意義,對應了常用的歐幾里得距離或簡稱“歐氏距離(Euclidean method)”,在線性回歸中,最小二乘法就是試圖找到一條直線,使所有樣本到直線上的歐式距離之和最小。
求解w和b使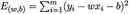 最小化的過程,叫做線性回歸模型的最小二乘“參數估計(parameter estimate)”,然后E(w, b)分別對w和b求導,得到:
最小化的過程,叫做線性回歸模型的最小二乘“參數估計(parameter estimate)”,然后E(w, b)分別對w和b求導,得到:
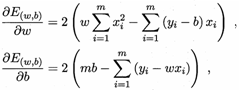
然后令上面兩個式子為零,求得w和b最優解的閉式(closed-form)解:
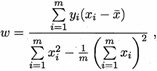
其中 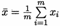 為x的均值。
為x的均值。
更一般的,數據集D,樣本由d個屬性描述,此時我們試圖學得:
![]()
這稱為“多元線性回歸(multivariate linear regression)”(這部分涉及公式教繁,線性代數知識具體推導書上)
我們希望線性模型的預測值逼近真實標記y時,就得到了線性回歸模型,為便于觀察,寫作:
![]()
我們要讓輸出標記y在指數尺度上變化,可做變化:
![]()
這就是“對數線性回歸(log-linear regression)”,它實際上是在試圖讓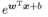 逼近y,下圖很明了:
逼近y,下圖很明了:
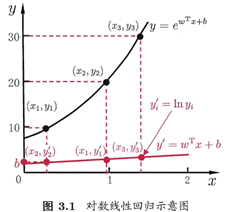
更一般的,考慮單調可微函數g(*),令:
![]()
這樣得到的模型稱為“廣義線性模型(generalized linear model)”,其中函數g(*),稱為“聯系函數(link function)”。顯然,對數線性回歸是廣義線性模型在g(*) = ln(*)時的特例。
3.3 對數線性回歸
考慮二分類任務,其輸出標記y∈{0, 1},而線性回歸模型產生的預測值 是實值,于是,我們需將實值轉換為0/1值,最理想是“單位階躍函數(unit-step function)”
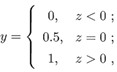
即若預測值z大于零就判為正例,小于零就判為反例,預測值為臨界值零則可任意判別,如下圖:
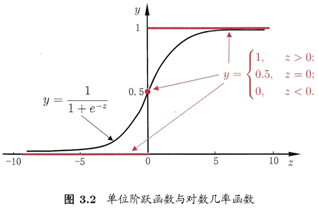
對數幾率函數(logistic function)是這樣一個常用的替代函數:
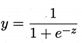
將對數幾率函數作為g-(*)帶入,得:
![]()
整理一下:
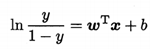
若將y視為樣本x作為正例的可能性,則1-y是其反例可能性,兩者比值:
![]()
稱為“幾率(odds)”,反映了樣本x作為正例的相對可能性,然后對幾率取對數得“對數幾率(log odds,也稱logit)”:
由此看出,實際上面在用線性回歸模型的預測結果去逼近真實標記的對數幾率,因此,其對應的模型稱為“對數幾率回歸(logistic regression,也稱logit regression)”。要注意的是,雖然它的名字是“回歸”,但實際上確實一種分類學習方法。
3.4 線性判別分析
線性判別分析(Linear Discriminant Analysis,簡稱LDA)是一種經典的線性學習方法,在二分類問題上最早由[Fisher, 1936]提出,所以也叫做“Fisher判別分析”。
LDA的思想非常樸素:給定訓練樣例集,設法將樣例投影到一條直線上,使得同類樣例的投影點盡可能接近、異類樣例的投影點盡可能遠離,下面這個圖就一目了然:
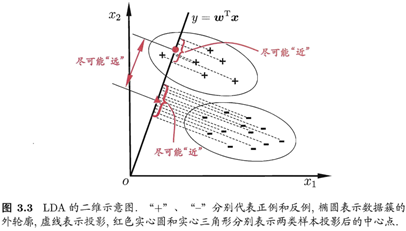
后續推導過程在書上。
3.5 多分類學習
現實中常見遇到多分類任務。有些二分類學習方法可直接推廣到多分類。但多數情況下,要基于一些基本策略,利用二分類學習器來解決多分類問題。
不失一般性,考慮N個類別C1, C2, … , CN,多分類學習的基本思路是“拆解法”,即將多分類任務拆分為若干個二分類任務求解。最經典的拆分策略有三種:“一對一(One vs. One,簡稱OvO)”、“一對余(One vs. Rest,簡稱OvR)”和“多對多(Many vs. Many,簡稱MvM)”。
3.6 類別不平衡問題
(閱讀后續章節,待續)
-------------------------------------------
個性簽名:獨學而無友,則孤陋而寡聞。做一個靈魂有趣的人!
如果覺得這篇文章對你有小小的幫助的話,記得在右下角點個 [推薦]哦,博主在此感謝!
萬水千山總是情,打賞一分行不行,所以如果你心情還比較高興,也是可以掃碼打賞博主,哈哈哈(っ??ω??)っ???!



 浙公網安備 33010602011771號
浙公網安備 33010602011771號