
MySQL優(yōu)化方向:
在設(shè)計(jì)上:字段類(lèi)型,存儲(chǔ)引擎,范式
在功能上:索引,緩存,分庫(kù)分表
在架構(gòu)上:集群,主從復(fù)制,負(fù)載均衡,讀寫(xiě)分離
1. 大量數(shù)據(jù)采用批量插入形式
2. 事務(wù)設(shè)置手動(dòng)提交,MySQL默認(rèn)是自動(dòng)提交,意味著每寫(xiě)一個(gè)SQL事務(wù)就自動(dòng)提交,可能會(huì)頻繁的涉及事務(wù)開(kāi)始和提交,所以建議手動(dòng)提交
group by進(jìn)行分組
在分組操作時(shí),可以通過(guò)索引來(lái)提高效率,索引使用也要滿(mǎn)足左前綴原則
limit用來(lái)限制檢索數(shù)據(jù)范圍,一般用于分頁(yè)功能
比如:檢索數(shù)據(jù)為limit 2000000,10。此時(shí)需要MySQL排序前2000010記錄僅僅返回2000000-2000010間的數(shù)據(jù),其他數(shù)據(jù)丟棄,查詢(xún)排序的代價(jià)比太大
優(yōu)化思路:一般分頁(yè)查詢(xún)時(shí),通過(guò)創(chuàng)建覆蓋索引能夠比較好的提高性能,可以通過(guò)創(chuàng)建覆蓋索引加子查詢(xún)的形式進(jìn)行優(yōu)化
select * from student s,(select SID from student order by SID limit 2000000,10) s1
where s.SID=s1.SID;
覆蓋索引:
查詢(xún)列要被所有的索引覆蓋到,就是select的數(shù)據(jù)列只用從索引(只查詢(xún)一個(gè)索引樹(shù))中就能夠獲取到
select SID from student where Sname="18";//覆蓋索引
select Ssex from student where Sname="18";//非覆蓋索引
myisam存儲(chǔ)引擎是把表的總行數(shù)存儲(chǔ)在磁盤(pán)上,因此count(*)直接獲取結(jié)果,效率比較高
innodb存儲(chǔ)引擎執(zhí)行count(*),需要將數(shù)據(jù)一行一行讀取出來(lái),然后累計(jì)結(jié)果,效率較低
count()的幾種用法:
count(*),count(1),count(主鍵),count(字段)
using index:SQL所需要的返回值所有列數(shù)據(jù)均在一顆索引樹(shù)上,即無(wú)需訪問(wèn)實(shí)際的行記錄
using where:SQL使用了where過(guò)濾條件
注:使用了where條件的SQL,并不代表不需要優(yōu)化,需要進(jìn)一步判斷explain執(zhí)行計(jì)劃中type的類(lèi)型,如果type為all,表示進(jìn)行了全表掃描,則需要優(yōu)化,否則不需要優(yōu)化
using index condition:說(shuō)明檢索確實(shí)命中索引,但不是所有的列都在索引樹(shù)上,還有需要訪問(wèn)實(shí)際的行記錄,這個(gè)SQL語(yǔ)句性能也很高,但不如using index
using filesort:得到的所有的結(jié)果集,需要進(jìn)行文件排序,SQL語(yǔ)句性能很差,需要優(yōu)化
explain分析查詢(xún)SQL
索引設(shè)計(jì)需要遵循的原則:
1. 給區(qū)分度比較高的字段創(chuàng)建索引,比如:學(xué)號(hào),身份證號(hào)
2. 給經(jīng)常需要排序、分組和多表聯(lián)合操作的字段創(chuàng)建索引
3. 給經(jīng)常作為查詢(xún)條件的字段創(chuàng)建索引
4. 索引的數(shù)據(jù)不宜過(guò)多
5. 對(duì)于多列索引,優(yōu)先指定最左側(cè)的列
6. 刪除不使用或者很少使用的索引
7. 索引失效的場(chǎng)景:not in,like“%li”,<>等
分庫(kù)分表:
分庫(kù):將以前存在于一個(gè)數(shù)據(jù)庫(kù)實(shí)例中的數(shù)據(jù)拆分成多個(gè)數(shù)據(jù)庫(kù)實(shí)例,部署在不同的服務(wù)器上
分表:將以前存在于一張表上的數(shù)據(jù)拆分成多個(gè)表
分庫(kù)是為了解決服務(wù)器資源受單機(jī)限制,頂不住高并發(fā)的問(wèn)題,把請(qǐng)求分發(fā)到多臺(tái)服務(wù)器降低服務(wù)器的壓力
分表是為了解決單張表數(shù)據(jù)量過(guò)大,查詢(xún)效率慢的問(wèn)題
分庫(kù)一般按照業(yè)務(wù)劃分,比如訂單庫(kù),用戶(hù)庫(kù)

把一些不常用的大字段剝離出去
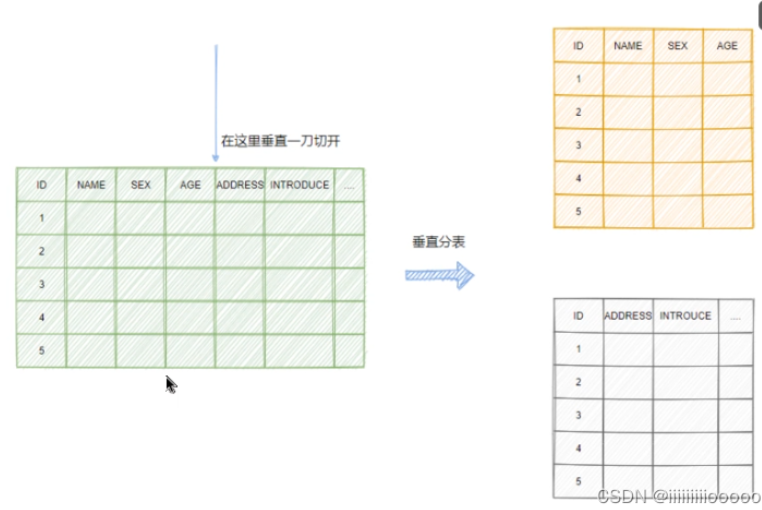
則是因?yàn)橐粡埍韮?nèi)的數(shù)據(jù)太多了,上文提到數(shù)據(jù)越多B+樹(shù)就越高,訪問(wèn)的性能越差,所以進(jìn)行水平拆分
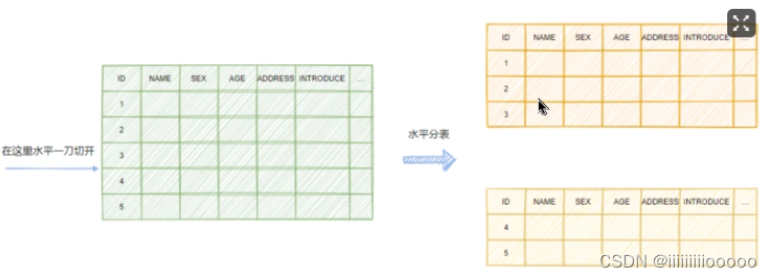
分表帶來(lái)問(wèn)題:
排序、count、分頁(yè)問(wèn)題:在業(yè)務(wù)代碼上將數(shù)據(jù)進(jìn)行排序、count、分頁(yè)處理
路由問(wèn)題:分表路由問(wèn)題:hash路由、范圍路由
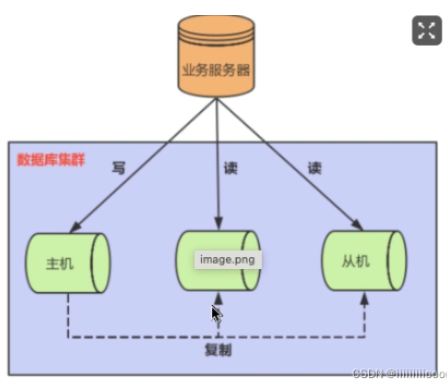
通常采用數(shù)據(jù)庫(kù)集群方案來(lái)解決高并發(fā)問(wèn)題,也滿(mǎn)足高可用,在多個(gè)數(shù)據(jù)庫(kù)上一旦一個(gè)數(shù)據(jù)庫(kù)宕機(jī)后,可以將請(qǐng)求分發(fā)到其他服務(wù)器上,可以持續(xù)提供服務(wù)
MySQL通過(guò)主從復(fù)制來(lái)實(shí)現(xiàn)讀寫(xiě)分離,負(fù)載均衡等功能
undo log 、redo log
MySQL集群中主從復(fù)制通過(guò)binlog將數(shù)據(jù)從主庫(kù)同步到從庫(kù)
binlog默認(rèn)是不開(kāi)啟的
通過(guò)命令查看
show variables like "log_%";

開(kāi)啟binlog日志,通過(guò)修改配置文件,MySQL server啟動(dòng)時(shí)會(huì)自動(dòng)加載配置文件,Windows下my.ini文件,Linux下是my.conf文件,在打開(kāi)的文件中在[mysql]上添加配置,保存并重啟MySQL server服務(wù)器,默認(rèn)就采用給定的日志文件
binglog_format=ROW
配置文件寫(xiě)完需要重啟服務(wù)器:systrmctl restart mysql
通過(guò)show variables like "log_%"命令,如果log_bin為ON則表示開(kāi)啟二進(jìn)制日志
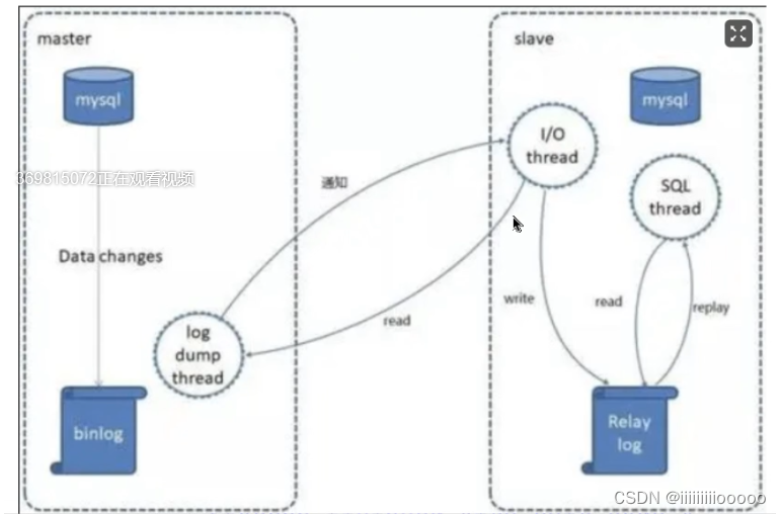
MySQL主從復(fù)制需要三個(gè)線程,master(log dump thread),slave(I/O thread,SQL thread)
master:
log dump thread:當(dāng)主庫(kù)中有數(shù)據(jù)更新時(shí),主庫(kù)就會(huì)根據(jù)按照設(shè)置的binlog格式,將此次更新的事件類(lèi)型寫(xiě)入到主庫(kù)的binlog文件中,此時(shí)主庫(kù)會(huì)創(chuàng)建log dump線程通知slave有數(shù)據(jù)更新,當(dāng)I/O線程請(qǐng)求日志內(nèi)容時(shí),會(huì)將此時(shí)的binlog名稱(chēng)和當(dāng)前更新的位置同時(shí)傳給slave的I/O線程
slave:
I/O線程:該線程會(huì)連接到master,向log dump線程請(qǐng)求一份指定binlog文件位置的副本,并將請(qǐng)求回來(lái)的binlog存到本地的relay log中,relay log 和binlog日志一樣是記錄了數(shù)據(jù)更新的事件,他也是按照遞增后綴名的方式,產(chǎn)生多個(gè)relay log(host_name_relay_bin.000001)文件,slave會(huì)使用一個(gè)index文件(host_name_relay_bin.index)來(lái)追蹤當(dāng)前正在使用的relay log文件。
SQL線程:該線程檢測(cè)到relay log有更新后,會(huì)讀取并在本地做redo操作,把發(fā)生在主庫(kù)的事件在本地重新執(zhí)行一遍,來(lái)保證主從數(shù)據(jù)同步
此外,如果有一個(gè)relay log文件中的全部事件都執(zhí)行完畢,那么SQL線程會(huì)自動(dòng)將該relay log文件刪除掉
數(shù)據(jù)庫(kù)中間件:常用的有MySQL Proxy、MyCat以及ShardingSphere等等
MySQL Proxy:是官方提供的MySQL中間件產(chǎn)品可以實(shí)現(xiàn)負(fù)載均衡,讀寫(xiě)分離等,是一個(gè)基于服務(wù)器端的代理
MyCat:是一款基于阿里開(kāi)源產(chǎn)品Cobar而研發(fā)的,基于java語(yǔ)言編寫(xiě)的開(kāi)源數(shù)據(jù)庫(kù)插件
ShardingSphere:是一套開(kāi)源的分布式數(shù)據(jù)庫(kù)中間件解決方案,它由ShardingJDBC、Sharding-Proxy、Sharding-Sidecar(計(jì)劃中)這三款相互獨(dú)立的產(chǎn)品組成

摘抄自:https://blog.csdn.net/iiiiiiiiiooooo/article/details/123583743


 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)