Prometheus 入門
測試環境
prometheus-2.26.0.linux-amd64.tar.gz
prometheus-2.54.1.linux-amd64.tar.gz
CentOS 7.9
下載并運行Prometheus
# wget https://github.com/prometheus/prometheus/releases/download/v2.26.0/prometheus-2.26.0.linux-amd64.tar.gz
# tar xvzf prometheus-2.26.0.linux-amd64.tar.gz
# cd prometheus-2.26.0.linux-amd64
# ls
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool
開始運行之前,先對它進行配置。
配置Prometheus自身監控
Prometheus通過抓取度量HTTP端點來從目標收集指標。由于Prometheus以同樣的方式暴露自己的數據,它也可以搜集和監控自己的健康狀況。
雖然只收集自身數據的Prometheus服務器不是很有用,但它是一個很好的開始示例。保存以下Prometheus基礎配置到一個名為prometheus.yml的文件(安裝包自動解壓后,解壓目錄下,默認就就有一個名為prometheus.yml的文件)
global:
scrape_interval: 15s # 默認,每15秒采樣一次目標
# 與其它外部系統(比如federation, remote storage, Alertmanager)交互時,會附加這些標簽到時序數據或者報警
external_labels:
monitor: 'codelab-monitor'
# 一份采樣配置僅包含一個 endpoint 來做采樣
# 下面是 Prometheus 本身的endpoint:
scrape_configs:
# job_name 將被被當作一個標簽 `job=<job_name>`添加到該配置的任意時序采樣.
- job_name: 'prometheus'
# 覆蓋全局默認值,從該job每5秒對目標采樣一次
scrape_interval: 5s
static_configs:
# 如果需要遠程訪問, localhost 也可以替換為具體IP,比如10.118.71.170
- targets: ['localhost:9090']
有關配置選項的完整說明,請參閱配置文檔。
啟動Prometheus
使用新創建的配置文件來啟動 Prometheus,切換到包含 Prometheus 二進制文件的目錄并運行
# 啟動 Prometheus.
# 默認地, Prometheus 在 ./data 路徑下存儲其數據庫 (flag --storage.tsdb.path).
# ./prometheus --config.file=prometheus.yml
通過訪問 localhost:9000 來瀏覽狀態頁。等待幾秒讓他從自己的 HTTP metric endpoint 來收集數據。
還可以通過訪問到其 metrics endpoint(http://localhost:9090/metrics) 來驗證 Prometheus 是否正在提供有關其自身的 metrics
開放防火墻端口
# firewall-cmd --permanent --zone=public --add-port=9090/tcp
success
# firewall-cmd --reload
success
使用expressin browser
使用 Prometheus 內置的expressin browser訪問 localhost:9090/graph,選擇 Graph 導航菜單下的 Table tab頁 (Classic UI下為Console tab頁)。
通過查看localhost:9090/metrics 頁面內容可知,Prometheus 導出了關于其自身的一個名為 prometheus_target_interval_length_seconds指標(目標采樣之間的實際間隔)。將其作為搜索表達式,輸入到表達式搜索框中,點擊 Execute 按鈕,如下,將返回多個不同的時間序列(以及每個時間序列的最新值),所有時間序列的 metric 名稱均為 prometheus_target_interval_length_seconds,但具有不同的標簽。 這些標簽具有不同的延遲百分比和目標組間隔(target group intervals)。
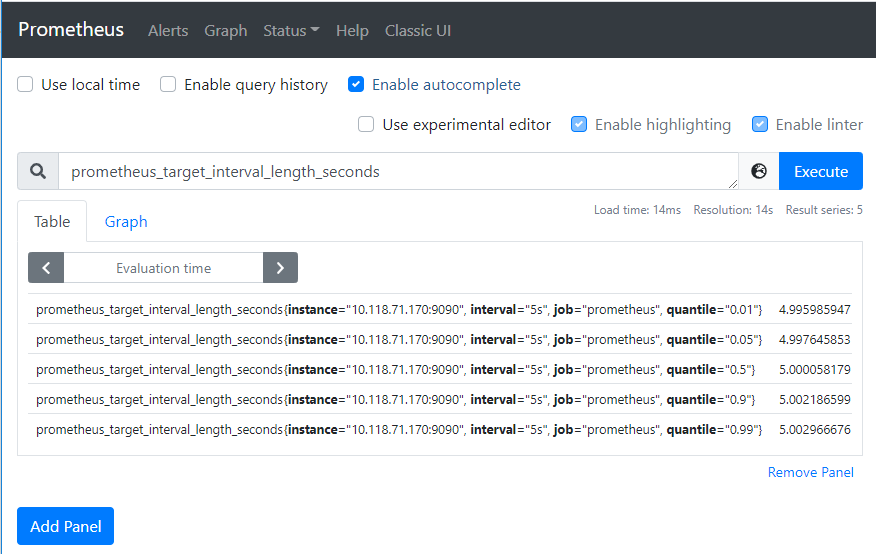
如果我們只對第 99 個百分位延遲感興趣,則可以使用以下查詢來檢索該信息:
prometheus_target_interval_length_seconds{quantile="0.99"}
如果需要計算返回的時間序列數,可以修改查詢如下:
count(prometheus_target_interval_length_seconds)
更多有關 expression language 的更多信息,請查看 expression language 文檔。
使用繪圖界面
要繪制圖形表達式,請使用 “Graph” 選項卡。
例如,輸入以下表達式以繪制在自采樣的 Prometheus 中每秒創建 chunk 的速率:
rate(prometheus_tsdb_head_chunks_created_total[1m])
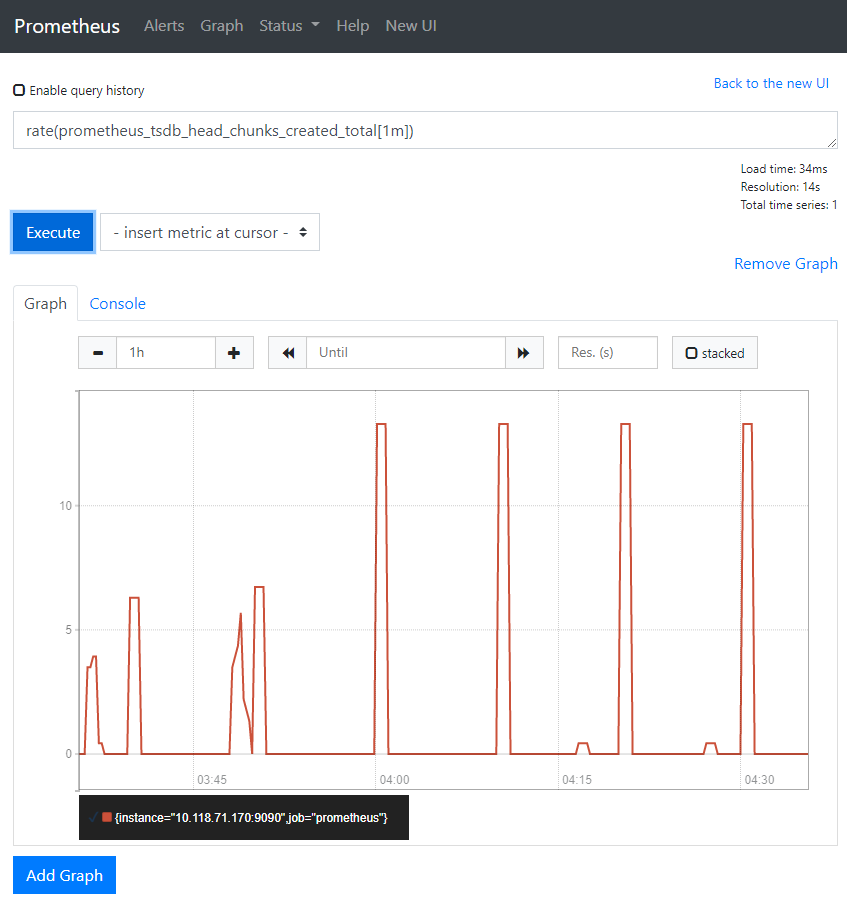
啟動一些采樣目標
現在讓我們增加一些采樣目標供 Prometheus 進行采樣。
使用Node Exporter作為采樣目標,多關于它的使用請查閱
# wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz
# tar -xvzf node_exporter-1.1.2.linux-amd64.tar.gz
# ./node_exporter --web.listen-address 127.0.0.1:8001
# ./node_exporter --web.listen-address 127.0.0.1:8002
# ./node_exporter --web.listen-address 127.0.0.1:8003
現在,應該存在監聽 http://localhost:8080/metrics, http://localhost:8081/metrics 和http://localhost:8082/metrics的示例目標
配置 Prometheus 來監控示例目標
現在,我們將配置 Prometheus 來采樣這些新目標。 讓我們將所有三個 endpoint 分組為一個稱為 “node” 的 job。 但是,假設前兩個 endpoint 是生產目標,而第三個 endpoint 代表金絲雀實例。 為了在 Prometheus 中對此建模,我們可以將多個端組添加到單個 job 中,并為每個目標組添加額外的標簽。 在此示例中,我們將 group=“ production” 標簽添加到第一個目標組,同時將 group=“ canary” 添加到第二個目標。
為此,請將以下job定義添加到 prometheus.yml 中的 scrape_configs 部分,然后重新啟動 Prometheus 實例。修改后的 prometheus.yml內容如下
global:
scrape_interval: 15s # 默認,每15秒采樣一次目標
# 與其它外部系統(比如federation, remote storage, Alertmanager)交互時,會附加這些標簽到時序數據或者報警
external_labels:
monitor: 'codelab-monitor'
# 一份采樣配置僅包含一個 endpoint 來做采樣
# 下面是 Prometheus 本身的endpoint:
scrape_configs:
# job_name 將被被當作一個標簽 `job=<job_name>`添加到該配置的任意時序采樣.
- job_name: 'prometheus'
# 覆蓋全局默認值,從該job每5秒對目標采樣一次
scrape_interval: 5s
static_configs:
- targets: ['10.118.71.170:9090']
- job_name: 'node'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:8001', 'localhost:8002']
labels:
group: 'production'
- targets: ['localhost:8003']
labels:
group: 'canary'
查看Targets(Status -> Targets)
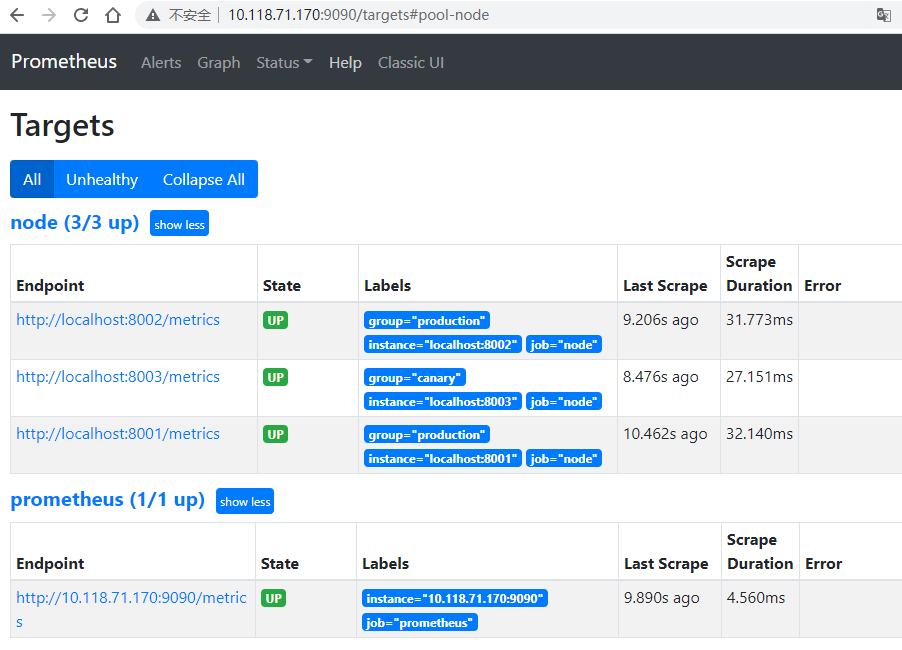
Graph查詢
配置規則以將采樣的數據聚合到新的時間序列
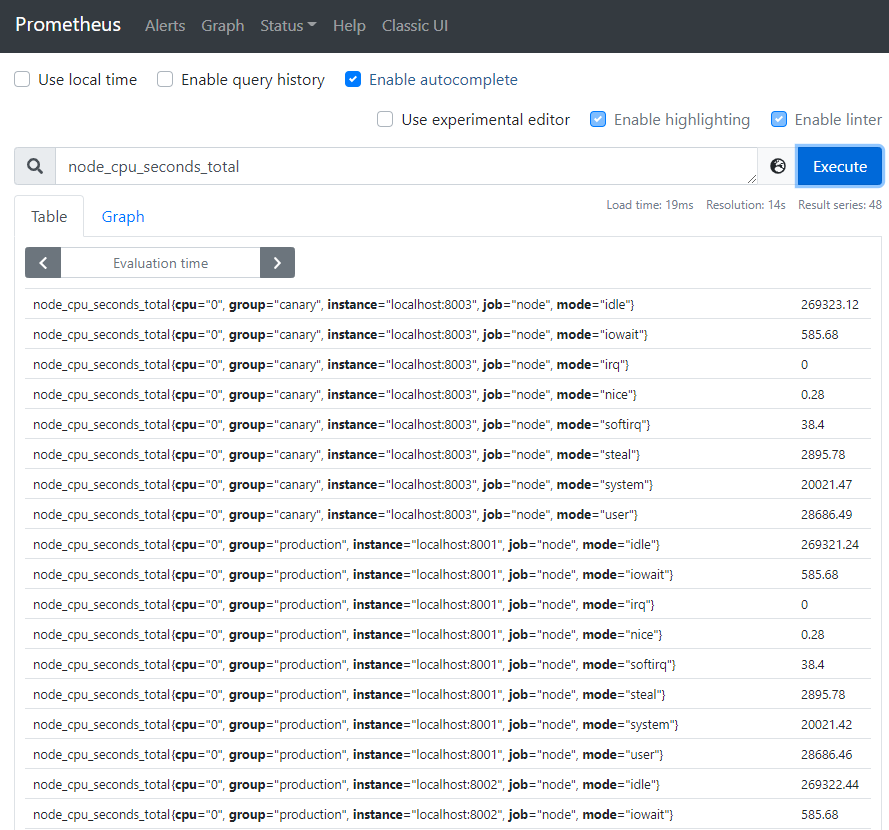
盡管在我們的示例中并不會有問題,但是在聚集了數千個時間序列中查詢時可能會變慢。 為了提高效率,Prometheus 允許通過配置的記錄規則將表達式預記錄到全新的持久化的時間序列中。 假設我們感興趣的是 5 分鐘的窗口內測得的每個實例的所有cpu上平均的cpu時間(node_cpu_seconds_total,保留 Job,instance,和mode 維度))。 我們可以這樣寫:
avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
Graph中執行查詢,結果如下
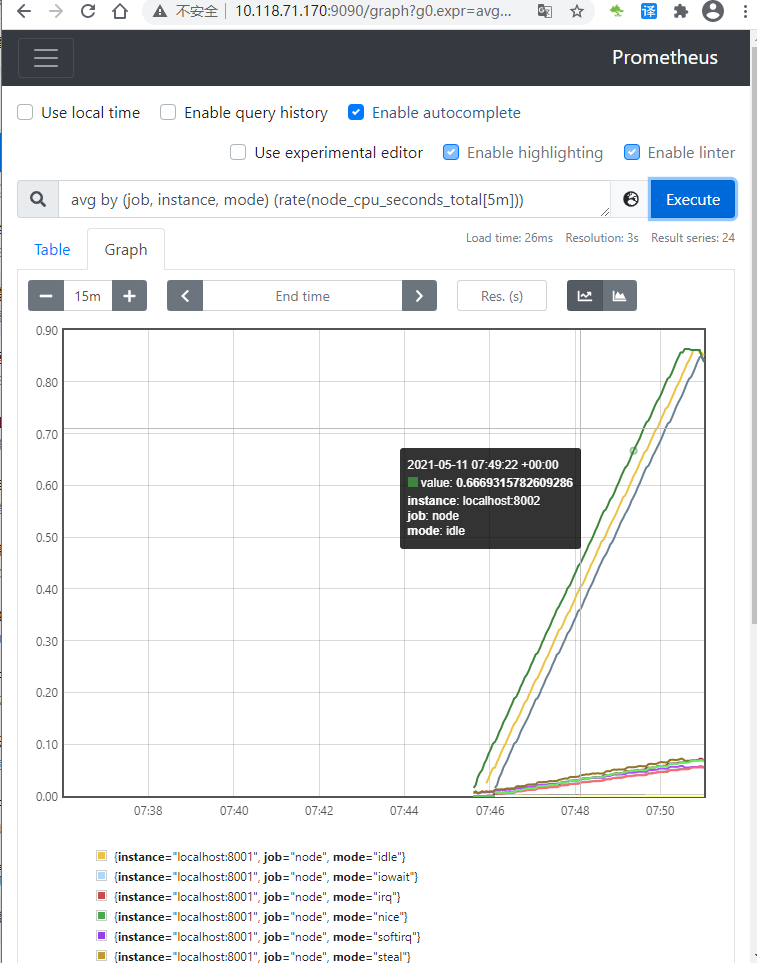
現在,要將由該表達式產生的時間序列記錄到一個名為:job_instance_mode:node_cpu_seconds:avg_rate5m 的新指標,使用以下記錄規則創建文件并將其保存 prometheus.rules.yml
groups:
- name: cpu-node
rules:
- record: job_instance_mode:node_cpu_seconds:avg_rate5m
expr: avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
在 prometheus.yml 中添加 rule_files 語句,以便 Prometheus 選擇此新規則。 現在,prometheus.yml配置應如下所示:
global:
scrape_interval: 15s # 默認,每15秒采樣一次目標
# 與其它外部系統(比如federation, remote storage, Alertmanager)交互時,會附加這些標簽到時序數據或者報警
external_labels:
monitor: 'codelab-monitor'
rule_files:
- 'prometheus.rules.yml'
# 一份采樣配置僅包含一個 endpoint 來做采樣
# 下面是 Prometheus 本身的endpoint:
scrape_configs:
# job_name 將被被當作一個標簽 `job=<job_name>`添加到該配置的任意時序采樣.
- job_name: 'prometheus'
# 覆蓋全局默認值,從該job每5秒對目標采樣一次
scrape_interval: 5s
static_configs:
- targets: ['10.118.71.170:9090']
- job_name: 'node'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:8001', 'localhost:8002']
labels:
group: 'production'
- targets: ['localhost:8003']
labels:
group: 'canary'
通過新的配置重新啟動 Prometheus,并通過expression brower查詢 job_instance_mode:node_cpu_seconds:avg_rate5m,結果如下
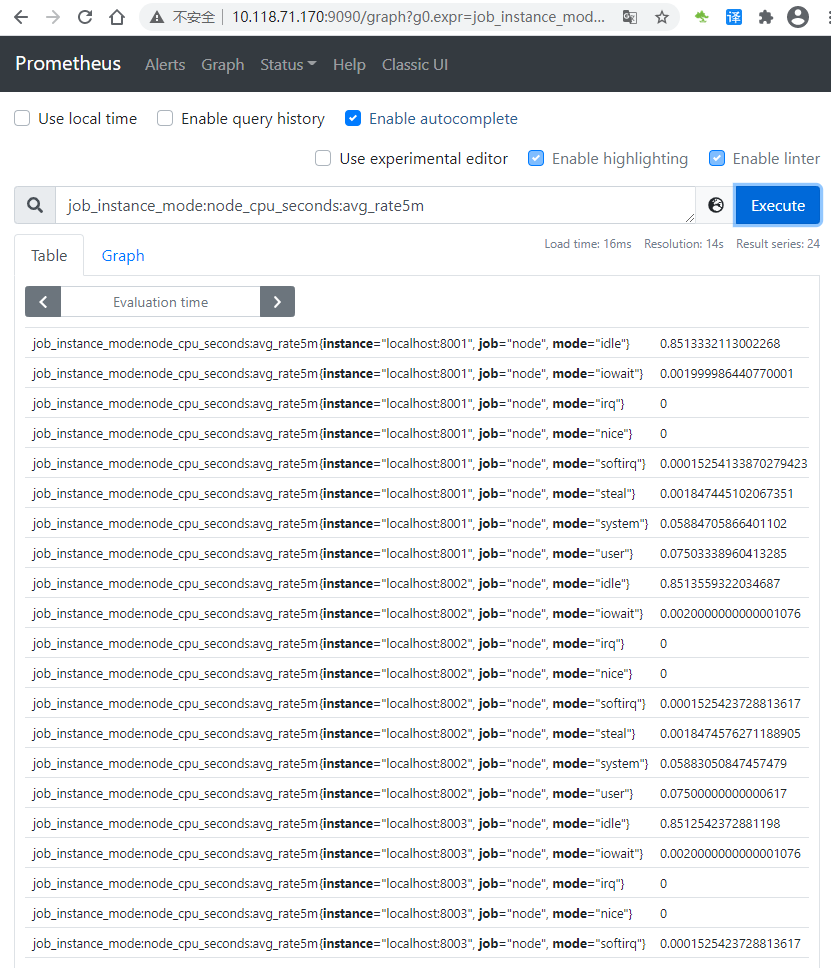
參考連接
https://www.kancloud.cn/nicefo71/prometheus-doc-zh/1331204
https://prometheus.io/docs/prometheus/latest/getting_started/
作者:授客
微信/QQ:1033553122
全國軟件測試QQ交流群:7156436
Git地址:https://gitee.com/ishouke
友情提示:限于時間倉促,文中可能存在錯誤,歡迎指正、評論!
作者五行缺錢,如果覺得文章對您有幫助,請掃描下邊的二維碼打賞作者,金額隨意,您的支持將是我繼續創作的源動力,打賞后如有任何疑問,請聯系我!!!
微信打賞
支付寶打賞 全國軟件測試交流QQ群




 浙公網安備 33010602011771號
浙公網安備 33010602011771號