
GC調優在Spark應用中的實踐(轉載)
Spark是時下非常熱門的大數據計算框架,以其卓越的性能優勢、獨特的架構、易用的用戶接口和豐富的分析計算庫,正在工業界獲得越來越廣泛的應用。與Hadoop、HBase生態圈的眾多項目一樣,Spark的運行離不開JVM的支持。由于Spark立足于內存計算,常常需要在內存中存放大量數據,因此也更依賴JVM的垃圾回收機制(GC)。并且同時,它也支持兼容批處理和流式處理,對于程序吞吐量和延遲都有較高要求,因此GC參數的調優在Spark應用實踐中顯得尤為重要。本文主要講述如何針對Spark應用程序配置JVM的垃圾回收器,并從實際案例出發,剖析如何進行GC調優,進一步提升Spark應用的性能。
問題介紹
隨著Spark在工業界得到廣泛使用,Spark應用穩定性以及性能調優問題不可避免地引起了用戶的關注。由于Spark的特色在于內存計算,我們在部署Spark集群時,動輒使用超過100GB的內存作為Heap空間,這在傳統的Java應用中是比較少見的。在廣泛的合作過程中,確實有很多用戶向我們抱怨運行Spark應用時GC所帶來的各種問題。例如垃圾回收時間久、程序長時間無響應,甚至造成程序崩潰或者作業失敗。對此,我們該怎樣調試Spark應用的垃圾收集器呢?在本文中,我們從應用實例出發,結合具體問題場景,探討了Spark應用的GC調優方法。
按照經驗來說,當我們配置垃圾收集器時,主要有兩種策略——Parallel GC和CMS GC。前者注重更高的吞吐量,而后者則注重更低的延遲。兩者似乎是魚和熊掌,不能兼得。在實際應用中,我們只能根據應用對性能瓶頸的側重性,來選取合適的垃圾收集器。例如,當我們運行需要有實時響應的場景的應用時,我們一般選用CMS GC,而運行一些離線分析程序時,則選用Parallel GC。那么對于Spark這種既支持流式計算,又支持傳統的批處理運算的計算框架來說,是否存在一組通用的配置選項呢?
通常CMS GC是企業比較常用的GC配置方案,并在長期實踐中取得了比較好的效果。例如對于進程中若存在大量壽命較長的對象,Parallel GC經常帶來較大的性能下降。因此,即使是批處理的程序也能從CMS GC中獲益。不過,在從1.6開始的HOTSPOT JVM中,我們發現了一個新的GC設置項:Garbage-First GC(G1 GC)。Oracle將其定位為CMS GC的長期演進,這讓我們重燃了魚與熊掌兼得的希望!那么,我們首先了解一下GC的一些相關原理吧。
GC算法原理
在傳統JVM內存管理中,我們把Heap空間分為Young/Old兩個分區,Young分區又包括一個Eden和兩個Survivor分區,如圖1所示。新產生的對象首先會被存放在Eden區,而每次minor GC發生時,JVM一方面將Eden分區內存活的對象拷貝到一個空的Survivor分區,另一方面將另一個正在被使用的Survivor分區中的存活對象也拷貝到空的Survivor分區內。在此過程中,JVM始終保持一個Survivor分區處于全空的狀態。一個對象在兩個Survivor之間的拷貝到一定次數后,如果還是存活的,就將其拷入Old分區。當Old分區沒有足夠空間時,GC會停下所有程序線程,進行Full GC,即對Old區中的對象進行整理。這個所有線程都暫停的階段被稱為Stop-The-World(STW),也是大多數GC算法中對性能影響最大的部分。
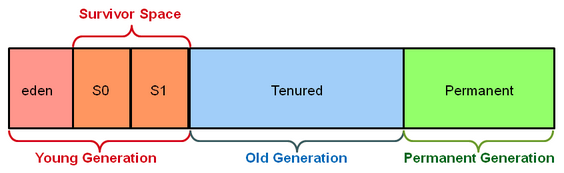
圖 1 分年代的Heap結構
而G1 GC則完全改變了這一傳統思路。它將整個Heap分為若干個預先設定的小區域塊(如圖2),每個區域塊內部不再進行新舊分區, 而是將整個區域塊標記為Eden/Survivor/Old。當創建新對象時,它首先被存放到某一個可用區塊(Region)中。當該區塊滿了,JVM就會創建新的區塊存放對象。當發生minor GC時,JVM將一個或幾個區塊中存活的對象拷貝到一個新的區塊中,并在空余的空間中選擇幾個全新區塊作為新的Eden分區。當所有區域中都有存活對象,找不到全空區塊時,才發生Full GC。而在標記存活對象時,G1使用RememberSet的概念,將每個分區外指向分區內的引用記錄在該分區的RememberSet中,避免了對整個Heap的掃描,使得各個分區的GC更加獨立。在這樣的背景下,我們可以看出G1 GC大大提高了觸發Full GC時的Heap占用率,同時也使得Minor GC的暫停時間更加可控,對于內存較大的環境非常友好。這些顛覆性的改變,將給GC性能帶來怎樣的變化呢?最簡單的方式,我們可以將老的GC設置直接遷移為G1 GC,然后觀察性能變化。
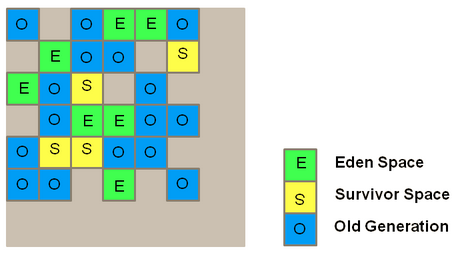
圖 2 G1 Heap結構示意
由于G1取消了對于heap空間不同新舊對象固定分區的概念,所以我們需要在GC配置選項上作相應的調整,使得應用能夠合理地運行在G1 GC收集器上。一般來說,對于原運行在Parallel GC上的應用,需要去除的參數包括-Xmn, -XX:-UseAdaptiveSizePolicy, -XX:SurvivorRatio=n等;而對于原來使用CMS GC的應用,我們需要去掉-Xmn -XX:InitialSurvivorRatio -XX:SurvivorRatio -XX:InitialTenuringThreshold -XX:MaxTenuringThreshold等參數。另外在CMS中已經調優過的-XX:ParallelGCThreads -XX:ConcGCThreads參數最好也移除掉,因為對于CMS來說性能最好的不一定是對于G1性能最好的選擇。我們先統一置為默認值,方便后期調優。此外,當應用開啟的線程較多時,最好使用-XX:-ResizePLAB來關閉PLAB()的大小調整,以避免大量的線程通信所導致的性能下降。
關于Hotspot JVM所支持的完整的GC參數列表,可以使用參數-XX:+PrintFlagsFinal打印出來,也可以參見Oracle官方的文檔中對部分參數的解釋。
Spark的內存管理
Spark的核心概念是RDD,實際運行中內存消耗都與RDD密切相關。Spark允許用戶將應用中重復使用的RDD數據持久化緩存起來,從而避免反復計算的開銷,而RDD的持久化形態之一就是將全部或者部分數據緩存在JVM的Heap中。Spark Executor會將JVM的heap空間大致分為兩個部分,一部分用來存放Spark應用中持久化到內存中的RDD數據,剩下的部分則用來作為JVM運行時的堆空間,負責RDD轉化等過程中的內存消耗。我們可以通過spark.storage.memoryFraction參數調節這兩塊內存的比例,Spark會控制緩存RDD總大小不超過heap空間體積乘以這個參數所設置的值,而這塊緩存RDD的空間中沒有使用的部分也可以為JVM運行時所用。因此,分析Spark應用GC問題時應當分別分析兩部分內存的使用情況。
而當我們觀察到GC延遲影響效率時,應當先檢查Spark應用本身是否有效利用有限的內存空間。RDD占用的內存空間比較少的話,程序運行的heap空間也會比較寬松,GC效率也會相應提高;而RDD如果占用大量空間的話,則會帶來巨大的性能損失。下面我們從一個用戶案例展開:
該應用是利用Spark的組件Bagel來實現的,其本質就是一個簡單的迭代計算。而每次迭代計算依賴于上一次的迭代結果,因此每次迭代結果都會被主動持續化到內存空間中。當運行用戶程序時,我們觀察到隨著迭代次數的增加,進程占用的內存空間不斷快速增長,GC問題越來越突出。但是,仔細分析Bagel實現機制,我們很快發現Bagel將每次迭代產生的RDD都持久化下來了,而沒有及時釋放掉不再使用的RDD,從而造成了內存空間不斷增長,觸發了更多GC執行。經過簡單的修改,我們修復了這個問題(SPARK-2661)。應用的內存空間得到了有效的控制后,迭代次數三次以后RDD大小趨于穩定,緩存空間得到有效控制(如表1所示),GC效率得以大大提高,程序總的運行時間縮短了10%~20%。
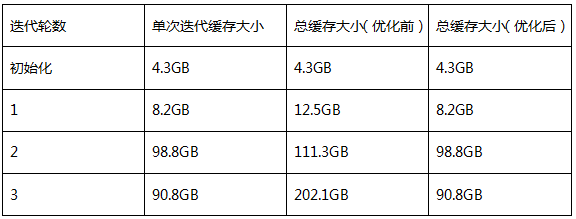
表1 三次迭代對比
小結:當觀察到GC頻繁或者延時長的情況,也可能是Spark進程或者應用中內存空間沒有有效利用。所以可以嘗試檢查是否存在RDD持久化后未得到及時釋放等情況。
選擇垃圾收集器
在解決了應用本身的問題之后,我們就要開始針對Spark應用的GC調優了。基于修復了SPARK-2661的Spark版本,我們搭建了一個4個節點的集群,給每個Executor分配88G的Heap,在Spark的Standalone模式下來進行我們的實驗。在使用默認的Parallel GC運行我們的Spark應用時,我們發現,由于Spark應用對于內存的開銷比較大,而且大部分對象并不能在一個較短的生命周期中被回收,Parallel GC也常常受困于Full GC,而每次Full GC都給性能帶來了較大的下降。而Parallel GC可以進行參數調優的空間也非常有限,我們只能通過調節一些基本參數來提高性能,如各年代分區大小比例、進入老年代前的拷貝次數等。而且這些調優策略只能推遲Full GC的到來,如果是長期運行的應用,Parallel GC調優的意義就非常有限了。因此,本文中不會再對Parallel GC進行調優。表2列出了Parallel GC的運行情況,其中CPU利用率較低的部分正是發生Full GC的時候。
| Configuration Options | -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -Xms88g -Xmx88g |
| Stage* | 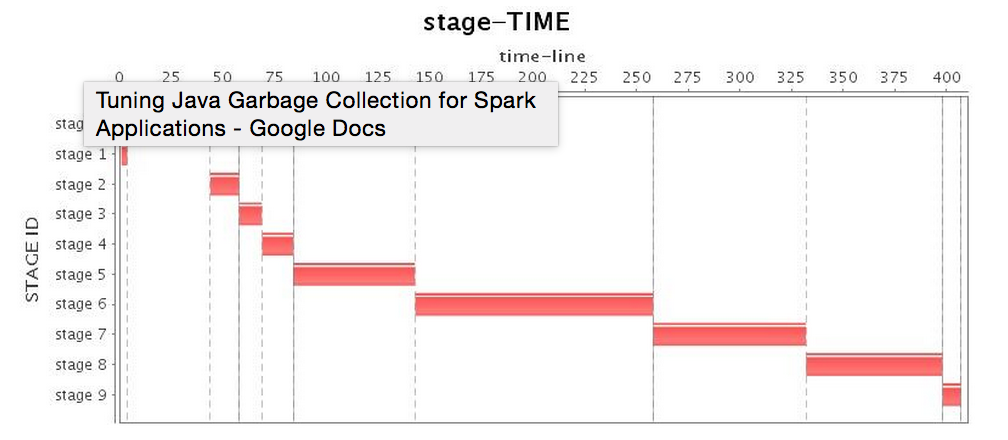 |
| Task* | 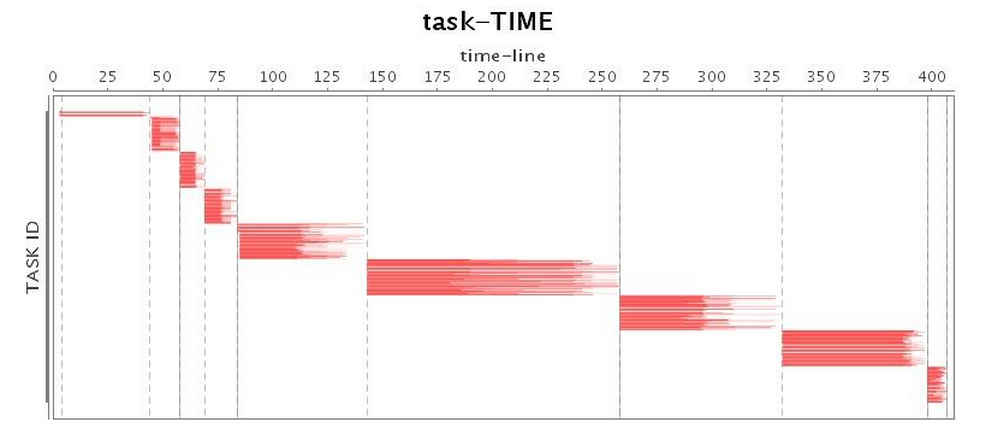 |
| CPU* |  |
| Mem* |  |
表 2 Parallel GC運行情況(未調優)
至于CMS GC,也沒有辦法消除這個Spark應用中的Full GC,而且CMS的Full GC的暫停時間遠遠超過了Parallel GC,大大拖累了該應用的吞吐量。
接下來,我們就使用最基本的G1 GC配置來運行我們的應用。實驗結果發現,G1 GC竟然也出現了不可忍受的Full GC(表3的CPU利用率圖中,可以明顯發現Job 3中出現了將近100秒的暫停),超長的暫停時間大大拖累了整個應用的運行。如表4所示,雖然總的運行時間比Parallel GC略長,不過G1 GC表現略好于CMS GC。
| Configuration Options | -XX:+UseG1GC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -Xms88g -Xmx88g |
| Stage* | 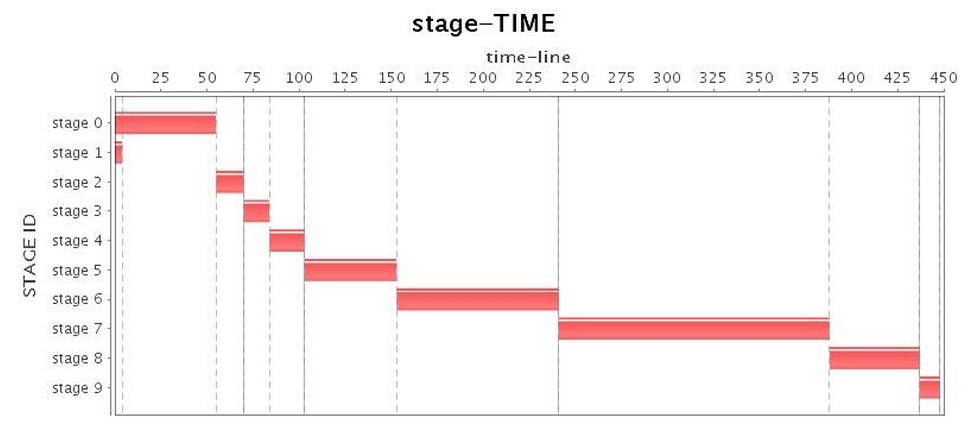 |
| Task* | 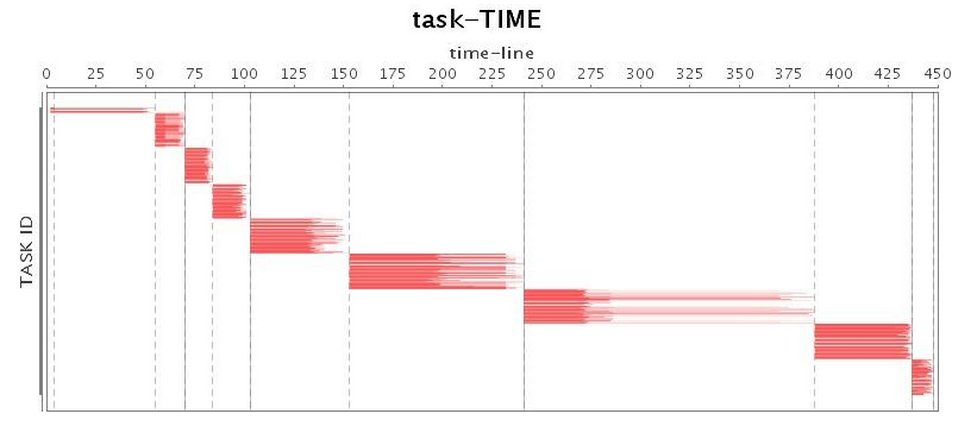 |
| CPU* | 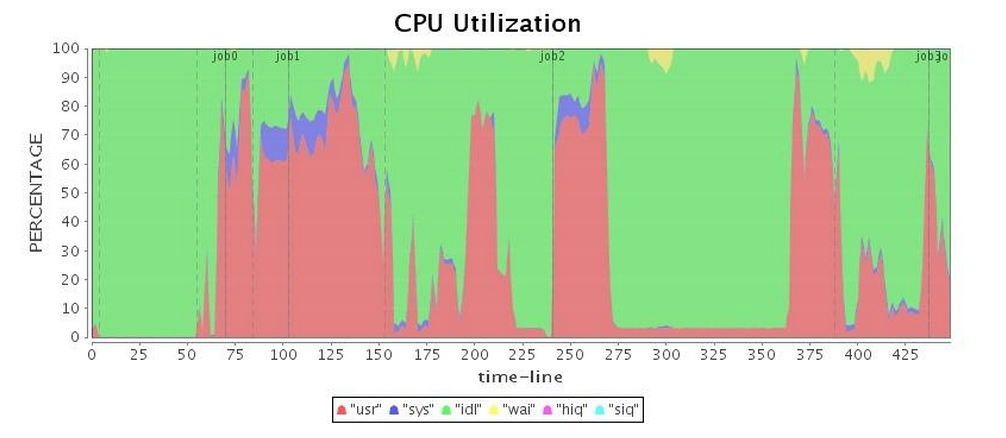 |
| Mem* | 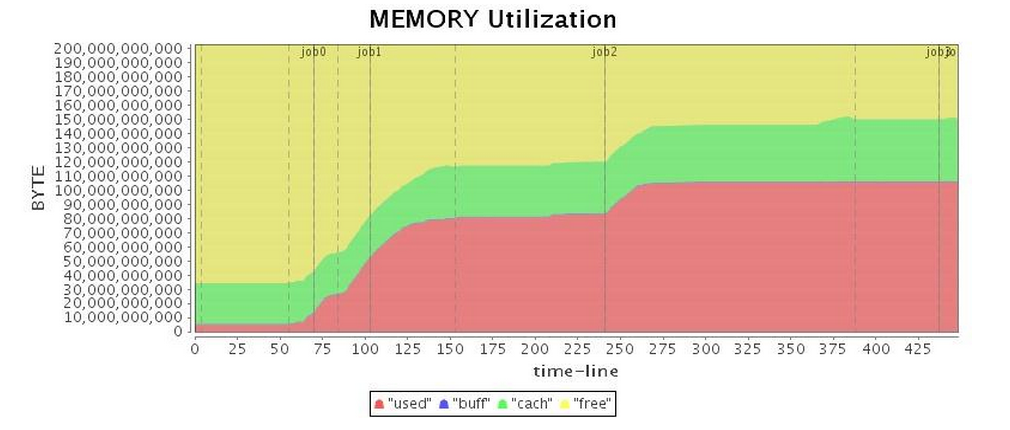 |
表 3 G1 GC運行情況(未調優)

表 4 三種垃圾收集器對應的程序運行時間比較(88GB heap未調優)
根據日志進一步調優
在讓G1 GC跑起來之后,我們下一步就是需要根據GC log,來進一步進行性能調優。首先,我們要讓JVM記錄比較詳細的GC日志. 對于Spark而言,我們需要在SPARK_JAVA_OPTS中設置參數使得Spark保留下我們需要用到的日志. 一般而言,我們需要設置這樣一串參數:
1 -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark
有了這些參數,我們就可以在SPARK的EXECUTOR日志中(默認輸出到各worker節點的$SPARK_HOME/work/$app_id/$executor_id/stdout中)讀到詳盡的GC日志以及生效的GC 參數了。接下來,我們就可以根據GC日志來分析問題,使程序獲得更優性能。我們先來了解一下G1中一次GC的日志結構。
251.354: [G1Ergonomics (Mixed GCs) continue mixed GCs, reason: candidate old regions available, candidate old regions: 363 regions, reclaimable: 9830652576 bytes (10.40 %), threshold: 10.00 %] [Parallel Time: 145.1 ms, GC Workers: 23] [GC Worker Start (ms): Min: 251176.0, Avg: 251176.4, Max: 251176.7, Diff: 0.7] [Ext Root Scanning (ms): Min: 0.8, Avg: 1.2, Max: 1.7, Diff: 0.9, Sum: 28.1] [Update RS (ms): Min: 0.0, Avg: 0.3, Max: 0.6, Diff: 0.6, Sum: 5.8] [Processed Buffers: Min: 0, Avg: 1.6, Max: 9, Diff: 9, Sum: 37] [Scan RS (ms): Min: 6.0, Avg: 6.2, Max: 6.3, Diff: 0.3, Sum: 143.0] [Object Copy (ms): Min: 136.2, Avg: 136.3, Max: 136.4, Diff: 0.3, Sum: 3133.9] [Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.3] [GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.9] [GC Worker Total (ms): Min: 143.7, Avg: 144.0, Max: 144.5, Diff: 0.8, Sum: 3313.0] [GC Worker End (ms): Min: 251320.4, Avg: 251320.5, Max: 251320.6, Diff: 0.2] [Code Root Fixup: 0.0 ms] [Clear CT: 6.6 ms] [Other: 26.8 ms] [Choose CSet: 0.2 ms] [Ref Proc: 16.6 ms] [Ref Enq: 0.9 ms] [Free CSet: 2.0 ms] [Eden: 3904.0M(3904.0M)->0.0B(4448.0M) Survivors: 576.0M->32.0M Heap: 63.7G(88.0G)->58.3G(88.0G)] [Times: user=3.43 sys=0.01, real=0.18 secs]
以G1 GC的一次mixed GC為例,從這段日志中,我們可以看到G1 GC日志的層次是非常清晰的。日志列出了這次暫停發生的時間、原因,并分級各種線程所消耗的時長以及CPU時間的均值和最值。最后,G1 GC列出了本次暫停的清理結果,以及總共消耗的時間。
而在我們現在的G1 GC運行日志中,我們明顯發現這樣一段特殊的日志:
1 (to-space exhausted), 1.0552680 secs] 2 [Parallel Time: 958.8 ms, GC Workers: 23] 3 [GC Worker Start (ms): Min: 759925.0, Avg: 759925.1, Max: 759925.3, Diff: 0.3] 4 [Ext Root Scanning (ms): Min: 1.1, Avg: 1.4, Max: 1.8, Diff: 0.6, Sum: 33.0] 5 SATB Filtering (ms): Min: 0.0, Avg: 0.0, Max: 0.3, Diff: 0.3, Sum: 0.3] 6 [Update RS (ms): Min: 0.0, Avg: 1.2, Max: 2.1, Diff: 2.1, Sum: 26.9] 7 [Processed Buffers: Min: 0, Avg: 2.8, Max: 11, Diff: 11, Sum: 65] 8 [Scan RS (ms): Min: 1.6, Avg: 2.5, Max: 3.0, Diff: 1.4, Sum: 58.0] 9 [Object Copy (ms): Min: 952.5, Avg: 953.0, Max: 954.3, Diff: 1.7, Sum: 21919.4] 10 [Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 2.2] 11 [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.6] 12 [GC Worker Total (ms): Min: 958.1, Avg: 958.3, Max: 958.4, Diff: 0.3, Sum: 22040.4] 13 [GC Worker End (ms): Min: 760883.4, Avg: 760883.4, Max: 760883.4, Diff: 0.0 14 [Code Root Fixup: 0.0 ms] 15 [Clear CT: 0.4 ms] 16 [Other: 96.0 ms] 17 [Choose CSet: 0.0 ms] 18 [Ref Proc: 0.4 ms] 19 [Ref Enq: 0.0 ms] 20 [Free CSet: 0.1 ms] 21 [Eden: 160.0M(3904.0M)->0.0B(4480.0M) Survivors: 576.0M->0.0B Heap: 87.7G(88.0G)->87.7G(88.0G)] 22 [Times: user=1.69 sys=0.24, real=1.05 secs] 23 760.981: [G1Ergonomics (Heap Sizing) attempt heap expansion, reason: allocation request failed, allocation request: 90128 bytes] 24 760.981: [G1Ergonomics (Heap Sizing) expand the heap, requested expansion amount: 33554432 bytes, attempted expansion amount: 33554432 bytes] 25 760.981: [G1Ergonomics (Heap Sizing) did not expand the heap, reason: heap expansion operation failed] 26 760.981: [Full GC 87G->36G(88G), 67.4381220 secs]
顯然最大的性能下降是這樣的Full GC導致的,我們可以在日志中看到類似To-space Exhausted或者To-space Overflow這樣的輸出(取決于不同版本的JVM,輸出略有不同)。這是G1 GC收集器在將某個需要垃圾回收的分區進行回收時,無法找到一個能將其中存活對象拷貝過去的空閑分區。這種情況被稱為Evacuation Failure,常常會引發Full GC。而且很顯然,G1 GC的Full GC效率相對于Parallel GC實在是相差太遠,我們想要獲得比Parallel GC更好的表現,一定要盡力規避Full GC的出現。對于這種情況,我們常見的處理辦法有兩種:
- 將InitiatingHeapOccupancyPercent參數調低(默認值是45),可以使G1 GC收集器更早開始Mixed GC;但另一方面,會增加GC發生頻率。
- 提高ConcGCThreads的值,在Mixed GC階段投入更多的并發線程,爭取提高每次暫停的效率。但是此參數會占用一定的有效工作線程資源。
調試這兩個參數可以有效降低Full GC出現的概率。Full GC被消除之后,最終的性能獲得了大幅提升。但是我們發現,仍然有一些地方GC產生了大量的暫停時間。比如,我們在日志中讀到很多類似這樣的片斷:
1 280.008: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 62344134656 bytes, allocation request: 46137368 bytes, threshold: 42520176225 bytes (45.00 %), source: concurrent humongous allocation]
這里就是Humongous object,一些比G1的一個分區的一半更大的對象。對于這些對象,G1會專門在Heap上開出一個個Humongous Area來存放,每個分區只放一個對象。但是申請這么大的空間是比較耗時的,而且這些區域也僅當Full GC時才進行處理,所以我們要盡量減少這樣的對象產生。或者提高G1HeapRegionSize的值減少HumongousArea的創建。不過在內存比較大的時,JVM默認把這個值設到了最大(32M),此時我們只能通過分析程序本身找到這些對象并且盡量減少這樣的對象產生。當然,相信隨著G1 GC的發展,在后期的版本中相信這個最大值也會越來越大,畢竟G1號稱是在1024~2048個Region時能夠獲得最佳性能。
接下來,我們可以分析一下單次cycle start到Mixed GC為止的時間間隔。如果這一時間過長,可以考慮進一步提升ConcGCThreads,需要注意的是,這會進一步占用一定CPU資源。
對于追求更短暫停時間的在線應用,如果觀測到較長的Mixed GC pause,我們還要把G1RSetUpdatingPauseTimePercent調低,把G1ConcRefinementThreads調高。前文提到G1 GC通過為每個分區維護RememberSet來記錄分區外對分區內的引用,G1RSetUpdatingPauseTimePercent則正是在STW階段為G1收集器指定更新RememberSet的時間占總STW時間的期望比例,默認為10。而G1ConcRefinementThreads則是在程序運行時維護RememberSet的線程數目。通過對這兩個值的對應調整,我們可以把STW階段的RememberSet更新工作壓力更多地移到Concurrent階段。
另外,對于需要長時間運行的應用,我們不妨加上AlwaysPreTouch參數,這樣JVM會在啟動時就向OS申請所有需要使用的內存,避免動態申請,也可以提高運行時性能。但是該參數也會大大延長啟動時間。
最終,經過幾輪GC參數調試,其結果如下表5所示。較之先前的結果,我們最終還是獲得了較滿意的運行效率。
| Configuration Options | -XX:+UseG1GC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -Xms88g -Xmx88g -XX:InitiatingHeapOccupancyPercent=35 -XX:ConcGCThread=20 |
| Stage* | 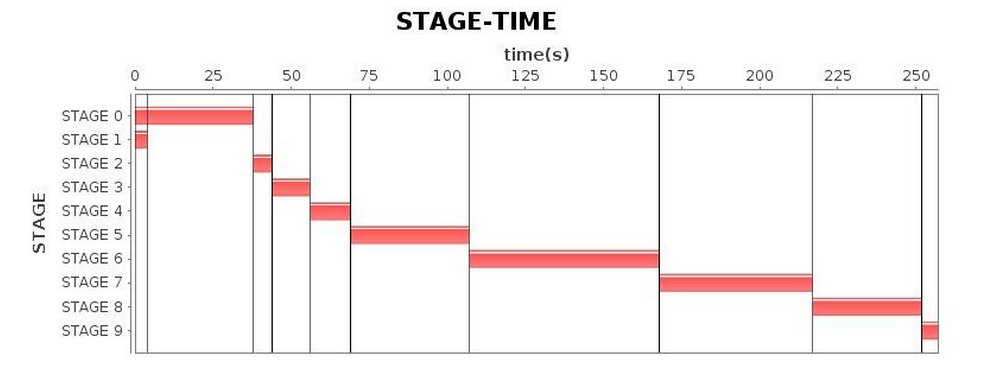 |
| Task* | 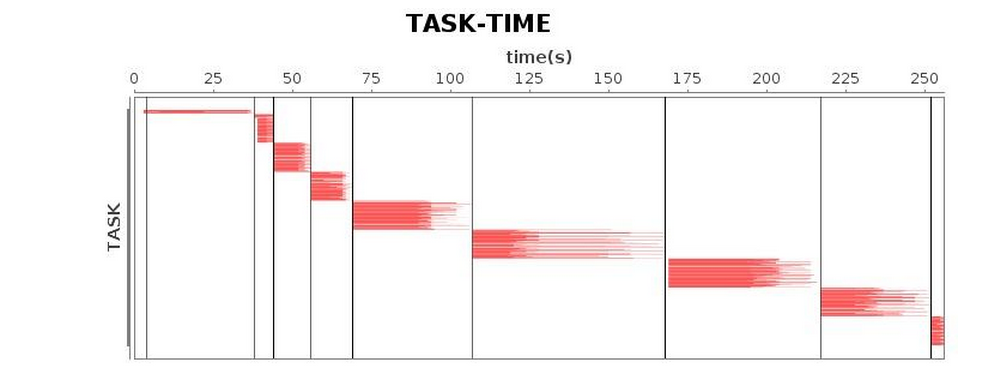 |
| CPU* | 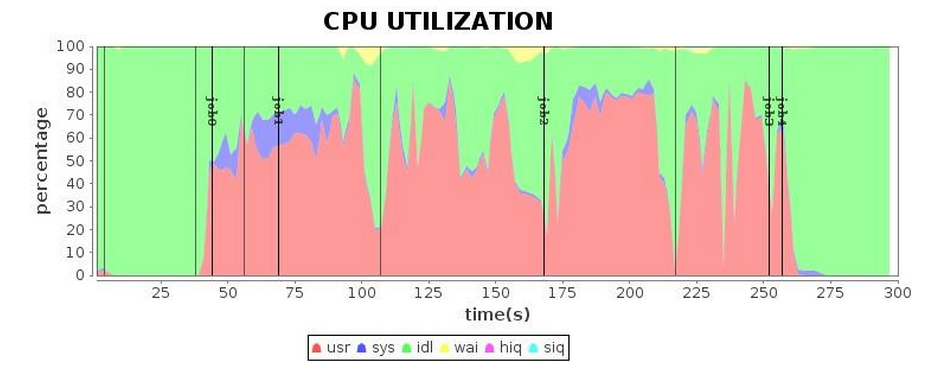 |
| Mem* | 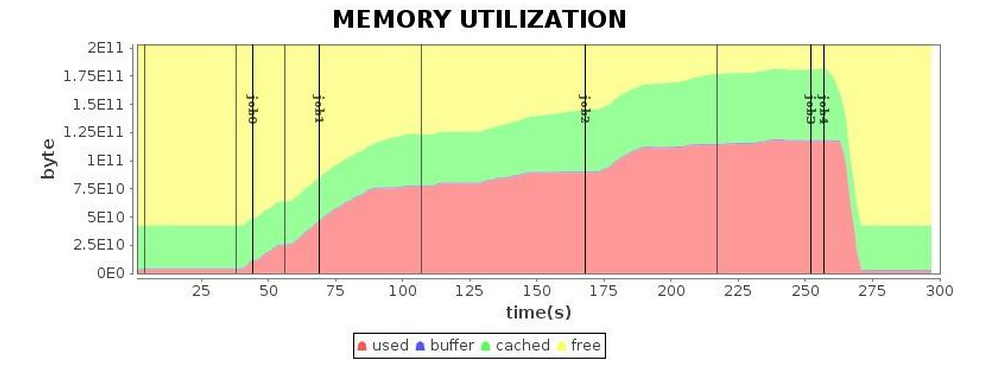 |
表 5 使用G1 GC調優完成后的表現
小結:綜合考慮G1 GC是較為推崇的默認Spark GC機制。進一步的GC日志分析,可以收獲更多的GC優化。經過上面的調優過程,我們將該應用的運行時間縮短到了4.3分鐘,相比調優之前,我們獲得了1.7倍左右的性能提升,而相比Parallel GC也獲得了1.5倍左右的性能提升。
總結
對于大量依賴于內存計算的Spark應用,GC調優顯得尤為重要。在發現GC問題的時候,不要著急調試GC。而是先考慮是否存在Spark進程內存管理的效率問題,例如RDD緩存的持久化和釋放。至于GC參數的調試,首先我們比較推薦使用G1 GC來運行Spark應用。相較于傳統的垃圾收集器,隨著G1的不斷成熟,需要配置的選項會更少,能同時滿足高吞吐量和低延遲的尋求。當然,GC的調優不是絕對的,不同的應用會有不同應用的特性,掌握根據GC日志進行調優的方法,才能以不變應萬變。最后,也不能忘了先對程序本身的邏輯和代碼編寫進行考量,例如減少中間變量的創建或者復制,控制大對象的創建,將長期存活對象放在Off-heap中等等。
轉載自 https://www.csdn.net/article/2015-06-01/2824823
英文原文參見 https://databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號