
Databricks緩存提升Spark性能--為什么NVMe固態硬盤能夠提升10倍緩存性能(原創翻譯)
我們興奮的宣布Databricks緩存的通用可用性,作為統一分析平臺一部分的 Databricks 運行時特性,它可以將Spark工作負載的掃描速度提升10倍,并且這種改變無需任何代碼修改。
1、在本博客中,我們將介紹這個新特性的兩個主要特點:易用性和性能。
2、不同于Spark顯示緩存,Databricks緩存能夠自動地為用戶緩存熱輸入數據,并且在集群中負載均衡。利用NVMe SSD硬件的先進性能和最先進的壓縮技術,它能夠將交互式和報告工作的負載性能提升10倍。更重要的是它緩存的數據量是Spark的緩存數量的30多倍。
Spark顯式緩存
Spark中一個關鍵特性是顯式緩存。它是一個多功能的工具,因為它可以用于存放任意計算結果(包括輸入和中間結果),以便它們可以重復使用。例如,迭代機器學習算法的實現可以選擇緩存特征化數據,并且每次迭代將從內存中讀取這些數據。
一種特別重要和廣泛使用的方式就是緩存掃描操作的結果。通過這種方式可以避免用戶低速率地讀取遠程數據。因此,許多打算重復運行相同或類似工作量的用戶決定花費額外的開發時間來手動優化他們的應用程序,通過指示Spark確切緩存什么文件以及何時進行緩存,從而實現“顯式緩存”。
對于Spark緩存有如上功能,它還有一些缺點。首先,把數據保存在主內存中時,它需要占用內存空間,而這些空間能夠更好用于其他用途,例如,用于Shuffle或者哈希表。其次,當數據緩存在磁盤,讀取需要反序列化--該過程太慢以至于無法充分利用NVMe SSD通常所提供的高讀取帶寬。
最后,由于需要提前并詳細指定需要緩存的數據,這個對于那些想交互地導出數據或者創建報告是一個挑戰。雖然Spark緩存提供數據工程師所有調優開關,數據科學經常發現推斷這些內存太困難了,特別是在多租戶的設置中,工程師仍然需要盡快返回結果以保證迭代時間更短。
NVMe SSD面臨的調整
固態硬盤或者SSD已經成為標準存儲技術。盡管最初以其隨機搜索低延遲聞名,但在過去的幾年中,SSD也大幅度提供了讀寫吞吐量。
NVMe接口創建用于克服SATA和ARCI設計的極限,并且允許最大可能使用現代SSD所提供出色的性能。這包括利用基于閃存存儲設置的內部并行性和極低讀延遲的能力。NVMe使用多種長命令隊列以及其他增強功能,允許驅動器高效處理海量并發請求。這種面向并行的架構完美地補充了現代多核CPU和如Spark數據處理系統的并行線。
通過NVMe接口,SSD比低速磁盤驅動器在屬性和性能上更加接近主內存。因此它們是存儲緩存數據的理想地方。
然而為完全利用NVMe SSD的潛力,僅僅把遠程數據復制到本地存儲是遠遠不夠。我們在AWS i3實例所進行的實驗表明當從本地SSD讀取常用文件格式時,它只是使用一部分可用的I/O帶寬。
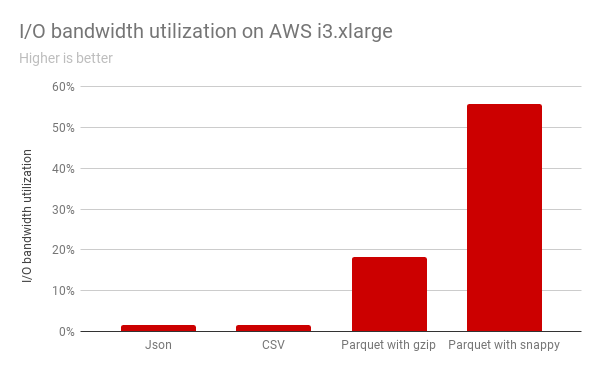
上圖顯示了在Spark針對EC2 i3實例類型的本地NVMe SSD的I/O帶寬利用率。根據圖示,現有數據格式不能充分利用I/O帶寬,CPU密集解碼速度無法跟上SSD的速度。
自適應運行
當設計Databricks緩存時,我們不僅關注于實現優化的讀性能,并且關注于創建一種“自適應運行”的方案,該方案無需用戶任何參與。該緩存考慮到:
1、自動選擇數據緩存----無論何時訪問遠程文件時,該數據轉碼副本會立即存放到緩存中
2、替換長時間未使用的數據----當磁盤空間不足時,緩存自動刪除最近最少使用的數據
3、負載均衡----緩存的數據均勻地分發到集群的所有節點上,并且自動擴展和/或調整不同節點不均勻使用情況
4、數據安全----在緩存數據通過同樣的方式與臨時文件保持加密,例如Shuffle文件
5、數據更新----緩存能夠自動發現在遠程地方文件的增加和刪除,并且顯示數據最新的狀態
從Databricks運行時3.3以來,在AWS i3實例類型中所有集群都預置并默認啟用Databricks內存。由于這種實例類型具有較高的寫入吞吐量,數據能夠轉碼并保存在緩存中,而無需降低讀取遠程數據的查詢性能。喜歡選擇其他類型工作節點的用戶可以使用Spark配置來啟用緩存(請參考文檔以了解更多細節)。
對于那些需預先緩存所需要數據的用戶,我們實現了CACHE SELECT命令。它將提供選擇部分數據裝載到緩存中。用戶可以指定垂直(如:選擇列)或者水平(如:滿足查詢條件的行)切片數據保存在緩存中。
性能
為了充分利用NVMe SSD,不是采取直接緩存輸入的“原始數據”,而是新功能會自動將數據轉換為高度優化新的臨時磁盤緩存格式,該功能提供了出色的解碼速度,從而獲得了更佳的I/O帶寬利用率。這種轉碼是異步操作,從而把數據加載到緩存的查詢開銷降低到最小。
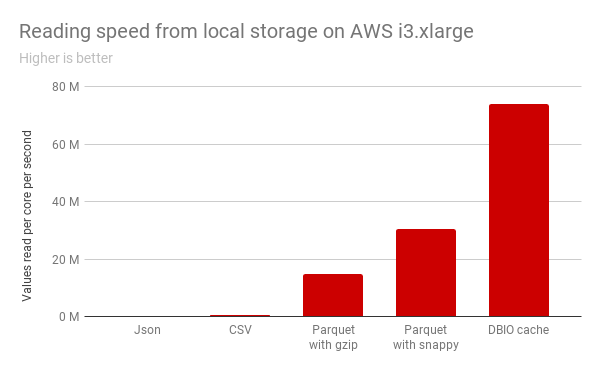
增強讀取性能(在前面所提到的通常在訪問遠程數據避免高延遲的能力)導致了各種查詢速度取得了顯著的提升。例如,在如下TPC-DS查詢的子集,相對于從AWS S3讀取Parquet數據,我們看到在每個簡單查詢都取得了持續的改進,并且在查詢53中速度有5.7倍的提升。
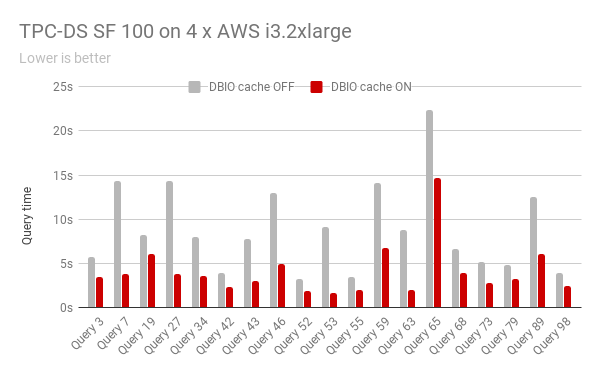
來自于我們私人測試程序的一些客戶工作中,我們看到性能有10倍的提升。
對比Spark緩存和Databricks緩存
Spark緩存和Databricks緩存可以搭配使用,事實上,它們之間相得益彰:Spark緩存提供存儲任意中間計算結果數據的能力,而Databricks緩存提供了對輸入數據提供自動和出色的性能。
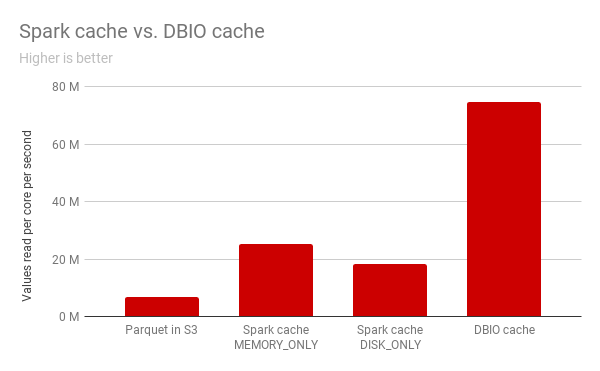
在我們的實驗中,Databricks緩存相對于Spark緩存的DISK_ONLY讀模式達到了4倍的速度。對比MEMORY_ONLY模式,Databricks緩存仍然提供了3倍的加速,而且還保持了較小的內存占用。
Databricks緩存配置
對于運行Databricks運行時3.3+版本的所欲AWS i3實例類型,對于所有Parquet文件緩存選擇默認開啟,并且緩存功能也可以與Databricks delta無縫協作。
要在其他Azure或AWS實例類型中使用新緩存,在集群配置中需要設置如下配置參數:
1 spark.databricks.io.cache.enabled true
2 spark.databricks.io.cache.maxDiskUsage "{DISK SPACE PER NODE RESERVED FOR CACHED DATA}"
3 spark.databricks.io.cache.maxMetaDataCache "{DISK SPACE PER NODE RESERVED FOR CACHED METADATA}"
結論
Databricks緩存為Databricks用戶提供了大量好處--無論是易用性還是查詢性能。它可以與Spark緩存進行混合搭配結合,使用最優的工具來完成任務。隨著即將更進一步的性能提升和對其他數據格式的支持,Databricks緩存將成為各種工作負載的主要工具。
將來,我們講發布更多性能提升和擴展支持其他文件格式的功能。
要嘗試此新功能,請立即在我們統一分析平臺選擇一個i3實例類型的集群。
本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利。如果覺得還有幫助的話,可以點一下右下角的【推薦】,希望能夠持續的為大家帶來好的技術文章!想跟我一起進步么?那就【關注】我吧。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號