
10.手工備份恢復--導入導出(練習15.16.17)
到目前為止介紹的備份和恢復活動都是物理操作,如果只希望把數據庫的數據和對象拷入或拷出Oracle數據庫,又如何處理呢?Oracle應用程序Export(導出)和Impot(導出)可以把一個數據庫的邏輯內容拷貝到一個Oracle二進制格式的轉儲文件中,并把該文件保存在磁盤或者磁帶上,當需要時可以把該二進制文件內容讀入一個Oracle數據庫庫中以創建其中包含的對象。這樣的邏輯轉移可以在同一個數據庫上進行,也可以在不同的Oracle數據庫之間進行,即使這些數據庫位于硬件和軟件配置不同的平臺上。
當在一個Oracle數據庫上運行Export時,所有的非數據字典對象(如:表)都提取到一個文件中,Imort應用程序從一個Export轉出文件中讀取對象定義以及表數據,并在Oracle數據庫中創建這些對象。導出文件可以作為除正常的物理備份之外的備份。使用Export/Import需要注意的要點:
- 導入操作只能由Oracle導入應用程序讀取;
- 導入應用程序的版本不能比用于創建轉儲文件的導出應用程序的版本老;
- 在運行導入或導出應用程序時數據庫必須打開;
- 導出和導入應用程序可以在任何Net8客戶機上運行;所處理的文件常常存放在客戶機上,NET8導出或導入會引起額外的網絡通信開銷。
Export/Import有四種模式:
- 完整數據庫模式(Full database mode):導出數據庫的內容寫入到一個文件中,但某些用戶對象(SYS、ORDSYS、CTXSYS、MDSYS、ORDPLUGINS)并不導出,定義用戶模式的導入參數是FULL=Y;
- 用戶模式(User mode) :屬于特定用戶的所有數據庫對象寫到一個文件中,該用戶的所有表、索引、視圖、觸發器、同義詞、數據庫鏈接、對象、存儲代碼等,導入用戶是在FROMUSER參數中定義;
- 表模式(Table mode) :單個表以及相關的對象(例如:索引、約束、觸發器、授權)寫入到一個文件中,每個表用TABLES參數命名;
- 表空間模式(Tablespace mode) :對應所選表空間以及這些表空間中包括所有對象元數據寫入一個文件中,實際的表數據(行)并不寫入到導出文件中。產生的導出文件連同表空間數據文件一個從源數據庫拷貝到目標數據庫,在導入過程中表空間和對象元數據添加到目標數據庫上。
Oracle導出和導入應用程序參數說明:
|
參數 |
描 述 |
|
Userid |
Userid參數為運行導出/導入應用程序的用戶提供數據庫用戶的id和口令,如果以SCOTT身份連接數據庫,應輸入: Userid=scott/tiger 如果準備在NET8連接,應該輸入: Userid=scott/tiger@pracitce 如果必須以SYSDBA身份運行導出或導入程序,應該輸入: Userid=”scott/tiger as SYSDBA” |
|
File |
參數file定義導出應用程序將要創建的或者導入應用程序將要讀取的文件名稱,可以完整給出路徑名稱;如果只提供文件名稱,文件將創建到當前目錄下或從當前目錄下讀取;如果沒有提供文件名稱,這兩種應用程序在當前工作目錄下尋找expdat.dmp文件 |
|
Log |
導出/導入屏幕數據可以捕捉到參數log定義的一個文件中。可以完整地給出路徑名稱,如果僅提供文件名稱,文件將在當前目錄下創建 |
|
Help |
在命令提示符下可以鍵入help=y來獲取導出和導入應用程序的所有參數的一個簡要列表,當用HELP參數列出導出的參數時,部分參數在簡單的描述后面都會給出默認值 |
|
Parfile |
導出/導入應用程序的參數可以從一個參數文件的文件中讀取 |
|
Tables |
導出時提取表列表中的那些表或在導入包含在導出文件中的表 |
|
Rows |
表示提取每個導出表的行或指示導入應用程序插入每個導入表中的行 |
導出/導入應用程序少數參數在導出和導入之間是公用的,但意義和內涵不同:
- Full 完整導出一位這提取整個數據庫的所有內容,并創建他們;
- Owner和Fromuser/Touser Owner參數在導出時提取擁有者的所有對象。如果導出文件中對象的擁有者在導入時需要更改,Fromuser將指定導出文件中包含的源對象擁有者,Touser指定創建和擁有導入對象的新模式。例如:可以導出Stephan的對象,并希望把他們按照Kenny模式導入,可以使用如下導入參數:FROMUSER=STEPHAN TOUSER=KENNY
Oracle的導出/導入應用程序有許多有價值的功能和特性:
- 備份和恢復 導出和導入對于應用開發、數據庫轉移和可遷移表空間是很有用的,它們可以方面用于除備份和恢復策略外的各種DBA任務。因為導出是表的一個快照,如果丟失一個表或者數據文件,加入表本質上是動態的,那么用導出文件和導入應用程序來替換所有的數據將十分困難。但是導出對于擴展實際的備份和恢復有用;
- 數據塊損壞 可以導出整個數據庫或關鍵的表,以此發現表中損壞的數據塊,導出過程會對導出的表進行完全掃描,強制讀取每一個數據塊,檢查介質損壞的情況;
- 數據庫版本交叉 可以將某一版本的Oracle源數據庫上的模式和數據拷貝到不同的版本的一個目標Oracle數據庫,當從源數據庫導出數據時,使用兩個數據庫中較早版本進行導出,向目標數據庫導入數據時,使用目標數據庫的導入版本;
- 操作系統交叉 可以用導出/導入將數據從某個操作系統的一個Oracle數據庫轉移到相同或者不同操作系統上的另一個Oracle數據庫中;
- 字符集支持 Oracle的NLS(本地語言支持)特性提供了適合支持本地語言的字符、數字、符號、日期等。如果在導出或導入過程中看到POSSIBLE CHARSET CONVERSION字樣時,應該留心。請注意導出和導入客戶機的字符集,必要時要調整NLS_LANG環境變量設置;
練習15:導出完整的數據庫
本練習將創建PRACTICE數據庫的一個完整數據庫導出。
步驟一:交互導出完整的數據庫
在此任務中,可以通過交互運行導出應用程序創建一個完整數據庫導出文件。在操作系統的提示符下,鍵入exp啟動導出程序,按下回車鍵,會出現相關問題:
- username 指要執行導出用戶的名稱。任何用戶都可以導出他們自己的模式。在此練習中,以SYS身份連接,如果希望在NET8上連接數據庫,在服務臺(sys/system@practice)后面添加用戶名;
- password 給出第1步輸入用戶的口令;
- buffer size 以字節為單位,制定用于提取行緩沖區的大小,接受默認值;
- export file 導出應用程序創建一個二進制文件,其中包含了版本信息、運行細節、對象創建命令和表插入語句等,接受默認文件名expdat.dmp;
- entire database 定義導出的范圍,可以導出整個數據庫、一個或多個用戶,一個或多個表,選擇“1”進行完整數據庫導出;
- grants 決定導出應用程序是否導出對象授權,完整數據庫導出時,所有的對象授權都導出,選擇“YES”;
- table data 導出表是可以帶表數據,也可以不帶表數據,因為我們希望整個數據庫內容包含在內,選擇“YES”;
- extents 如果壓縮域,那么在導入時建立的對象創建命令會將所有的數據合并到一個初始域中,如果沒有壓縮域,對象按照他們在導出已有的域設置創建,選擇“NO”;
當導出開始運行時,屏幕會顯示正在運行的工作,當導出結束時,在導出命令運行的目錄下將創建一個名為expdat.dmp文件,該文件包含了除SYS、ORDSYS、CTXSYS、MDSYS和ORDPLUGINS以外每個用戶所擁有全部模式對象的一個副本。
步驟二:通過命令行導出完整的數據庫
可以把命令行參數放在一行,提供導出應用程序所需的全部信息,如果未能給出所需的某個參數,導出應用程序會提示輸入參數值。為了用命令行參數將整個數據庫導出到一個指定文件中,給出USERID、FILE和FULL參數如下:
每一個關鍵字后面跟一個或一組值,可以省略userid關鍵字,如下所示:
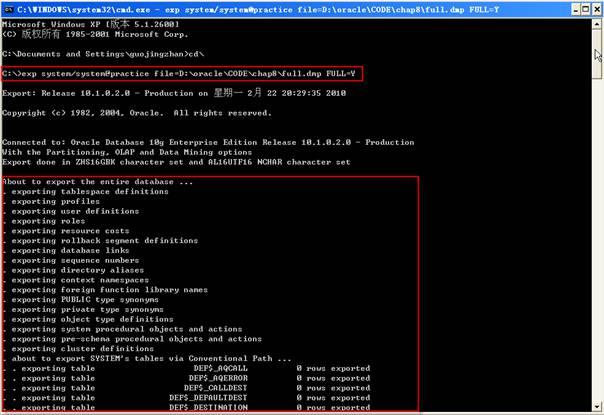
由該命令創建的文件為D:\oracle\CODE\chap8\full.dmp。
步驟三:通過參數文件導出完整的數據庫
如果不希望以命令行參數形式提供關鍵字的值,可以提供一個導出應用程序能夠讀取的參數文件,為了向導出提供一個參數文件名,在parfile關鍵字后面包含命令的一個文件名:
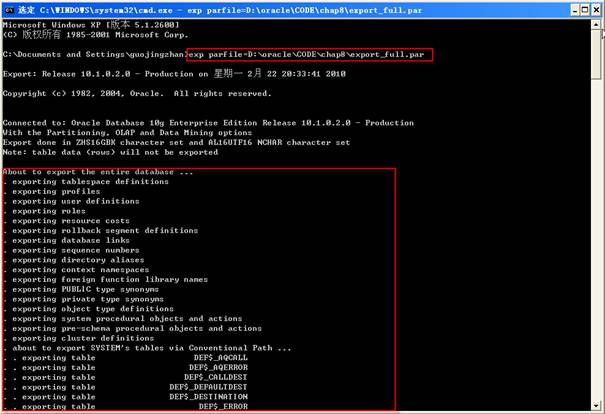
該參數文件export_full.par內容如下:
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 ROWS=N
6 BUFFER=10000
7 COMPRESS=N
關鍵字USERID、FILE和FULL與前一步驟命令行一樣,同時還添加其他參數:
- Log 導出執行的全部輸出結果寫入一個名為D:\oracle\CODE\chap8\full.log的文件中;
- Buffer 用于提取行的緩沖區大小為10000字節,適當的設置該參數有助于大型導出更快地運行;
- Rows 數據行成為導出文件內容的主要部分,設置ROWS=N,導出應用程序只導出對象定義,不到處數據行;
- Compress 壓縮會導致導入時創建的各個對象使用初始域,這個域大小足以容納整個對象。
步驟四:以直接模式導出完整的數據庫
導出缺省方式是用SQL SELECT語句從表中提取數據,這種方式數據塊從磁盤的數據文件中讀取出來,經由數據庫緩沖池,計算出數據量寫入導出文件中。
直接路徑導出幾乎完全拋開了緩沖池,數據是直接從數據文件中讀取,避開了數據庫緩沖池(某些數據塊,例如段的頭部以及可能的一致讀取數據仍要經過緩沖池),因此在大型表上直接路徑導出的運行速度更快。
對于小型的PRACTICE數據庫,通過直接路徑導出速度上不會有顯著提高,但對于大型數據庫,直接路徑導出比常規導出要快好幾倍。下面給出這個參數文件運行完整的數據庫導出:
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 COMPRESS=N
6 DIRECT=Y
技巧:如果需要導出大量的數據,可以為每個導出文件指出最大文件大小,給出多個需要創建的文件名,例如:如果操作系統的文件大小限制為2GB,可以指定FILESIZE=2000M,并在FILE參數中給出一列文件名(FILE=exp1.dmp,exp2.dmp,exp3.dmp),每個文件最大可以為2GB。
步驟五:導入整個數據庫用于顯示
導入應用程序利用導出文件把對象和數據拷貝到數據庫中,也可以用導入應用程序來顯示一個導出文件的內容,創建輸出且不改變數據庫的兩個參數是SHOW和INDEXFILE。
利用SHOW參數來顯示導入的輸出結果,如下所示,創建另一個名為import_full.par的參數文件,在該參數文件設置如下參數值:
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 LOG=D:\oracle\CODE\chap8\full.log
4 FULL=Y
5 SHOW= Y
以在操作系統命令行用imp可執行程序運行這個文件:
導出文件的內容在屏幕上飛速滾動,同時被寫入到由LOGOS參數制定的文件中,利用編輯器,打開屏幕輸出的日志文件,查看內容:
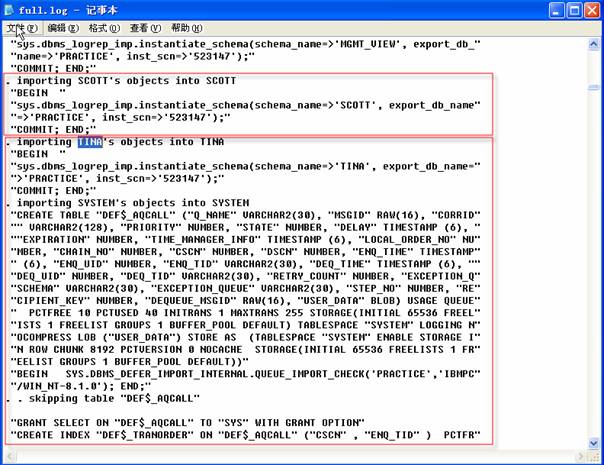
- 數據庫對象導出和導入的順序,表在索引之前導入,存儲過程在Oracle作業之前;?
- 日志文件中的文本定義隱藏在字詞中,利用顯示文件輸出重新創建存儲代碼需要有效的編輯。
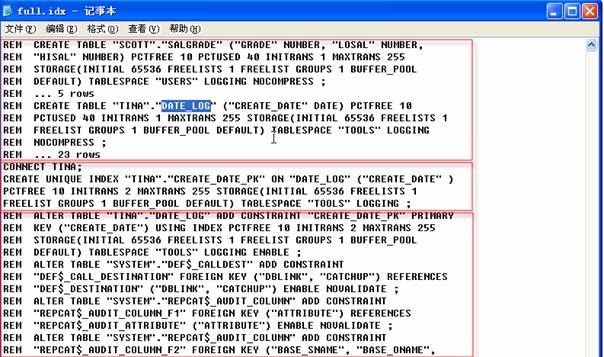
如果只希望在導出文件中包含表和索引定義,那么可以使用INDEXFILE參數,來創建一個只包含表和索引的文件,如下所示:
2 FILE=D:\oracle\CODE\chap8\full.dmp
3 INDEXFILE=D:\oracle\CODE\chap8\full.idx
4 FULL=Y
查看生成的索引文件,可以看到表的定義已經注釋了,可以刪除注釋部分,通過運行這個文件重新創建表。
練習16:替換并克隆數據庫Scott
本練習中將把用戶Scott的數據庫對象對象導出到一個單獨文件中,利用該文件,可以把該用戶復制到數據庫,然后利用這個導出文件創建另一個用戶。具體的步驟是首先創建一個導出文件,該文件包含了用戶Scott所有數據庫對象,刪除用戶Scott后重新創建該用戶,并導入所有對象,最后把Scott擁有的數據庫對象復制給名為Scott的用戶。
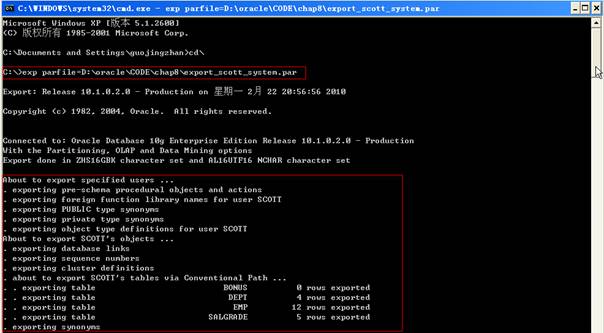
步驟一:導出用戶Scott
利用下面給出的參數文件導出名為Scott用戶的所有對象:
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 OWNER=SCOTT
關鍵字“OWNER”決定了該文件包含屬于Scott的數據對象,如果希望導出多個用戶,在圓括號列出這些所有者,并以逗號分隔。可以查看用LOG關鍵字定義的日志文件,將看到在導出過程中所創建的屏幕輸出。
2 USERID=scott/tiger@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
當以Scott身份連接數據庫運行導出時,無需提供OWNER參數。因為Scott只能導出自己的數據對象,導出應用程序默認,如果不指定某個表就導出自己的整個模式。如果希望導出某個用戶的模式,可以用那位用戶的身份來運行導出,并給出用戶口令。如果需要導出一個或多位用戶的模式,而不知用戶的口令,可以授權DBA用戶的身份運行導出,使用參數OWNER,作為一個授權用戶,可以一次導出多個用戶模式。
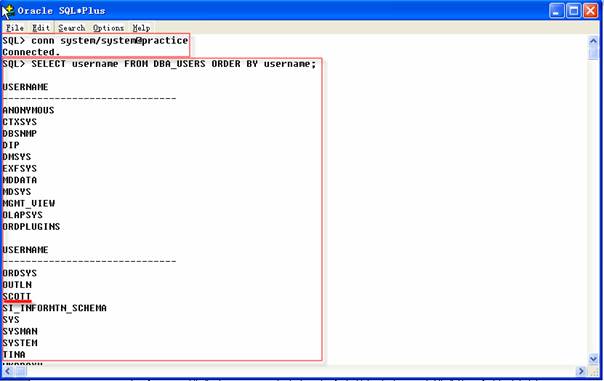
步驟二:刪除用戶Scott
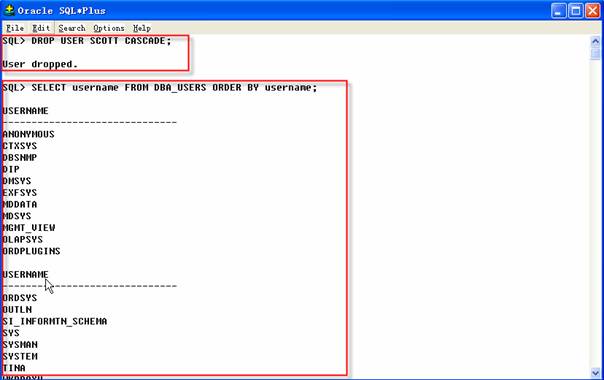
可以用如下DROP USER命令來刪除用戶Scott:
2 SQL>SELECT username FROM DBA_USERS ORDER BY username;
3 SQL>DROP USER SCOTT CASCADE;
4 SQL>SELECT username FROM DBA_USERS ORDER BY username;
DROP USER命令刪除一位用戶和屬于該用戶的所有對象,名為DBA_USERS的數據字典視圖包含了數據庫當前全部用戶的一個列表。如果在使用輸出命令之前提取該視圖的數據將看到Scott數據庫的一位用戶,刪除用戶之后,數據字典視圖就看到不到用戶Scott了。
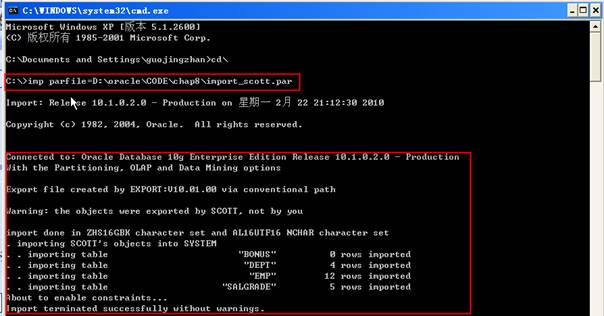
步驟三:導入用戶Scott
到導入Scott模式時,Scott用戶賬戶已經存在數據庫中,用戶模式的導入并不會創建導入的用戶,只會創建用戶對象:
2 SQL>ALTER USER SCOTT DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP;
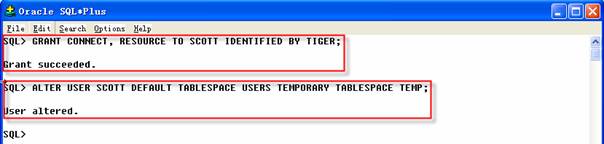
在創建用戶后可以導入對象。導入與導出有相同的參數,如:USERID、FILE、LOG和PARFILE,但沒有關鍵字OWNER。在導出時,使用OWNER關鍵字來執行用戶模式,作為DBA使用FROMUSER關鍵字執行用戶模式的導入,如下所示:
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 FROMUSER=SCOTT
作為用戶Scott,可以將一個文件導入自己的模式中,而無需使用關鍵字FROMUSER,如下所示:
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
步驟四:導入用戶Scotty
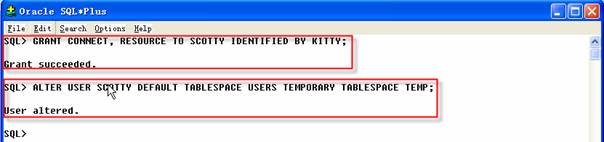
用戶Scott告訴你他需要一些空的表來測試新應用程序,他希望你將所有他的模式對象復制到一個名為Scotty的新模式中,為此,你可以從任務1的導出中把Scotty的模式導入到另一個新創建的用戶中。
2 SQL>ALTER USER SCOTTY DEFAULT TABLESPACE USERS TEMPORARY TABLESPACE TEMP;
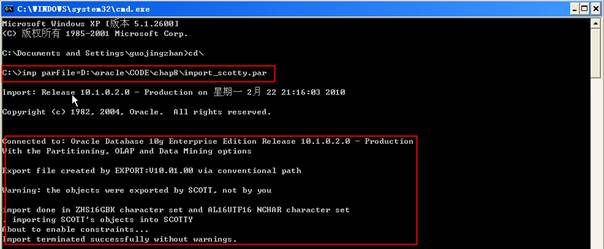
在創建新的用戶后,可以把Scott的對象導入到Scotty模式中。這次不需要導入數據,只導入對象,如下所示:
2 USERID=system/system@practice
3 FILE=D:\oracle\CODE\chap8\export_user_scott.dmp
4 LOG=D:\oracle\CODE\chap8\export_user_scott.log
5 FROMUSER=SCOTT
6 TOUSER=SCOTTY
7 ROWS=N
練習17:導出一個數據表
該練習中將創建一個文件,該文件包含了PRACTICE數據庫中TINA模式的一個表。按照查詢參數使用where子句來導出TINA.DATE_LOG表,查詢參數允許從一個只包含滿足查詢子句中謂詞的數據行的表進行導出,在截短TINA.DATE_LOG表之后,將從導出文件導入這個表,最后,當從TINA.DATE_LOG中提取數據時,該表中將只有導出過程中創建的那些行。
步驟一:導出表
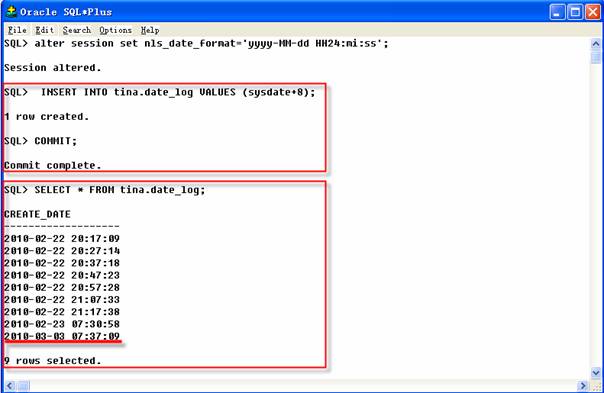
在從PRACTICE數據庫中導出部分表之前向TINA.DATE_LOG表中插入一些將來時間的行,可以向該表插入“SYSDATE+8”,這樣表中將包含比今天更大的日期值,插入后提交COMMIT命令。
2 SQL>COMMIT;
利用一個參數文件創建三個表的導出:

具體內容如下:
2 FILE=D:\oracle\CODE\chap8\export_date_log.dmp
3 LOG=D:\oracle\CODE\chap8\export_date_log.log
4 TABLES=(TINA.DATE_LOG)
5 QUERY="WHERE create_date < SYSDATE"
7 DIRECT=N
導出文件將包含TINA.DATE_LOG定義和表中滿足where子句條件的行。
步驟二:截短表
利用TRUNCATE TABLE命令,可以快速地從TINA.DATE_LOG表中刪除所有數據,刪除數據不會打斷創建該表中行的作業和存儲過程。
2 SQL>SELECT count(*) FROM TINA.DATE_LOG WHERE create_date > SYSDATE;
3 SQL>TRUNCATE TABLE TINA.DATE_LOG;
4 SQL>SELECT count(*) FROM TINA.DATE_LOG;

步驟三:導入表
可以用導出文件中的數據來替換表TINA.DATE_LOG中的行,為執行表的導入,使用“TABLES”關鍵字,指定想要插入的行,如下所示:
2 FILE=D:\oracle\CODE\chap8\export_date_log.dmp
3 LOG=D:\oracle\CODE\chap8\import_date_log.log
4 FROMUSER=TINA
5 TABLES=(DATE_LOG)
6 FROMUSER=TINA
7 IGNORE=Y
關鍵字“IGNORE”指示導入程序向任何已經存在表插入數據行,如果不指定這個關鍵字,對任何已經存在表的導入都會引起錯誤,同時該表的行也不會導入。
在操作系統命令行使用如下語句執行導入操作:
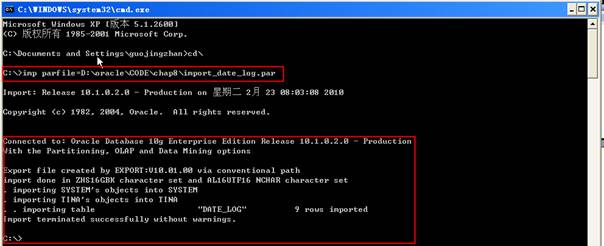
行導入之后,查看確認這些行在表中,同時沒有那些的值大于SYSDATE。
2 SQL>SELECT count(*) FROM TINA.DATE_LOG WHERE create_date>SYSDATE;
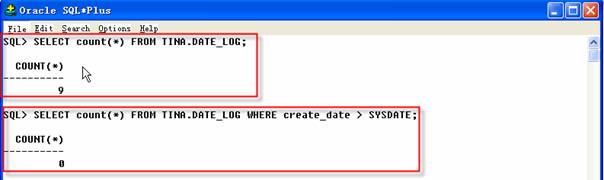
現在表TINA.DATE_LOG中大量的行,但沒有一行的日期比今天的大。注意:如果使用查詢參數創建一個導出文件后,查詢條件并不寫入導入文件中,當導入這個文件時,如法判斷導入的文件是否包含整個表的內容。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號