

python 老生常談的找2個excel相同列的行,把其中一個excel行的對應的值放入到另一個excel中
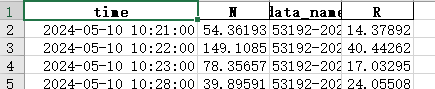
有個excel叫典型草原降水強度,還有個excel叫典型草原數濃度,這兩個excel里面time和data_name列,time列里面的數據格式是YYYY-M-D空格H:S,data_name列里面是XXXX-時間戳,53192-20240510101700-20240510105559-0_N_R_clusum_one.txt這樣的,咱們就根據前面的這個XXXXX和time列,來找相同的匹配的行,然后把典型草原降水強度excel中的找到的匹配R寫入到典型草原數濃度excel中。
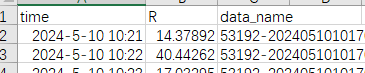
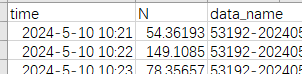
import pandas as pd import re # 讀取文件 df_intensity = pd.read_excel('/典型草原降水強度.xlsx') df_concentration = pd.read_excel('/典型草原數濃度.xlsx') # 處理時間和站號 df_intensity['time'] = pd.to_datetime(df_intensity['time']) df_concentration['time'] = pd.to_datetime(df_concentration['time']) def extract_station_id(data_name): match = re.match(r'^(\d{5})', str(data_name)) return match.group(1) if match else None df_intensity['station_id'] = df_intensity['data_name'].apply(extract_station_id) df_concentration['station_id'] = df_concentration['data_name'].apply(extract_station_id) # 匹配R值 df_intensity['match_key'] = df_intensity['station_id'] + '_' + df_intensity['time'].dt.strftime('%Y%m%d%H%M') df_concentration['match_key'] = df_concentration['station_id'] + '_' + df_concentration['time'].dt.strftime('%Y%m%d%H%M') r_map = df_intensity.set_index('match_key')['R'].to_dict() df_concentration['R'] = df_concentration['match_key'].map(r_map) # 保存結果 result_df = df_concentration.drop(['station_id', 'match_key'], axis=1) result_df.to_excel('/典型草原數濃度_添加R值.xlsx', index=False) print("匹配完成!")

 浙公網安備 33010602011771號
浙公網安備 33010602011771號