為什么要有 Buffer Pool?Mysql緩存能否替代Redis?
查詢緩存的作用?
執(zhí)行查詢語句的時候,會先查詢緩存。不過,MySQL 8.0 版本后移除,因為這個功能不太實用
開啟查詢緩存后在同樣的查詢條件以及數(shù)據(jù)情況下,會直接在緩存中返回結果。這里的查詢條件包括查詢本身、當前要查詢的數(shù)據(jù)庫、客戶端協(xié)議版本號等一些可能影響結果的信息。
查詢緩存不命中的情況:
- 任何兩個查詢在任何字符上的不同都會導致緩存不命中。
- 如果查詢中包含任何用戶自定義函數(shù)、存儲函數(shù)、用戶變量、臨時表、MySQL 庫中的系統(tǒng)表,其查詢結果也不會被緩存。
- 緩存建立之后,MySQL 的查詢緩存系統(tǒng)會跟蹤查詢中涉及的每張表,如果這些表(數(shù)據(jù)或結構)發(fā)生變化,那么和這張表相關的所有緩存數(shù)據(jù)都將失效。
為什么 8.0 版本后移除了?緩存雖然能夠提升數(shù)據(jù)庫的查詢性能,但是緩存同時也帶來了額外的開銷,每次查詢后都要做一次緩存操作,失效后還要銷毀。 因此,開啟查詢緩存要謹慎,尤其對于寫密集的應用來說更是如此。
為什么要有 Buffer Pool?
雖然說 MySQL 的數(shù)據(jù)是存儲在磁盤里的,但是也不能每次都從磁盤里面讀取數(shù)據(jù),這樣性能是極差的。
要想提升查詢性能,那就加個緩存。所以,當數(shù)據(jù)從磁盤中取出后,緩存內存中,下次查詢同樣的數(shù)據(jù)的時候,直接從內存中讀取。
為此,Innodb 存儲引擎設計了一個緩沖池(Buffer Pool),來提高數(shù)據(jù)庫的讀寫性能。
- 當讀取數(shù)據(jù)時,如果數(shù)據(jù)存在于 Buffer Pool 中,客戶端就會直接讀取 Buffer Pool 中的數(shù)據(jù),否則再去磁盤中讀取。
- 當修改數(shù)據(jù)時,首先是修改 Buffer Pool 中數(shù)據(jù)所在的頁,然后將其頁設置為臟頁,最后由后臺線程將臟頁寫入到磁盤。
Buffer Pool里有什么
InnoDB 會把存儲的數(shù)據(jù)劃分為若干個頁,以頁作為磁盤和內存交互的基本單位,一個頁的默認大小為 16KB。因此,Buffer Pool 同樣需要按頁來劃分。
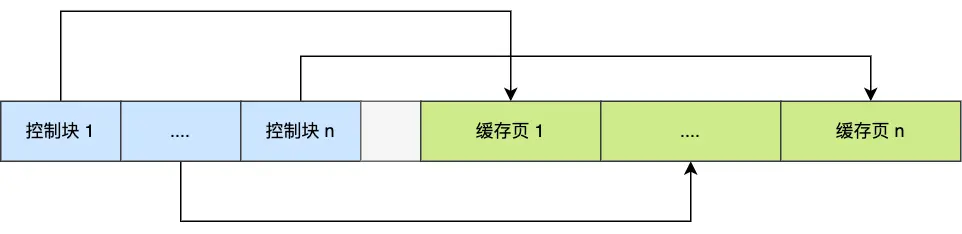
Buffer Pool里面包含很多個緩存頁,同時每個緩存頁還有一個描述數(shù)據(jù),也可以叫做是控制數(shù)據(jù),也可以叫做描述數(shù)據(jù),或者緩存頁的元數(shù)據(jù)。控制塊數(shù)據(jù),控制數(shù)據(jù)包括「緩存頁的表空間、頁號、緩存頁地址、鏈表節(jié)點」等等,控制塊數(shù)據(jù)就是為了更好的管理Buffer Pool中的緩存頁的。
控制塊也是占有內存空間的,它是放在 Buffer Pool 的最前面,接著才是緩存頁,如下圖:
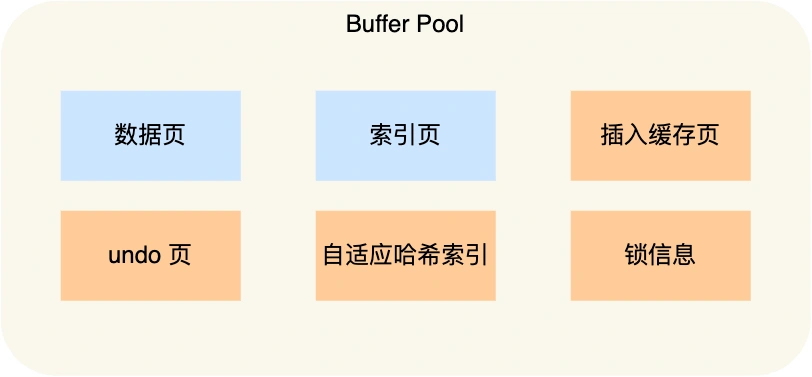
Buffer Pool 除了緩存「索引頁」和「數(shù)據(jù)頁」,還包括了 undo 頁,插入緩存、自適應哈希索引、鎖信息等等。
數(shù)據(jù)庫啟動的時候,是如何初始化Buffer Pool的
數(shù)據(jù)庫只要一啟動,就會按照設置的Buffer Pool大小,稍微再加大一點,去找操作系統(tǒng)申請一塊內存區(qū)域,作為Buffer Pool的內存區(qū)域。
當內存區(qū)域申請完畢之后,數(shù)據(jù)庫就會按照默認的緩存頁的16KB的大小以及對應的800個字節(jié)左右的描述數(shù)據(jù)的大小,在Buffer Pool中劃分出來一個一個的緩存頁和一個一個的他們對應的描述數(shù)據(jù)。
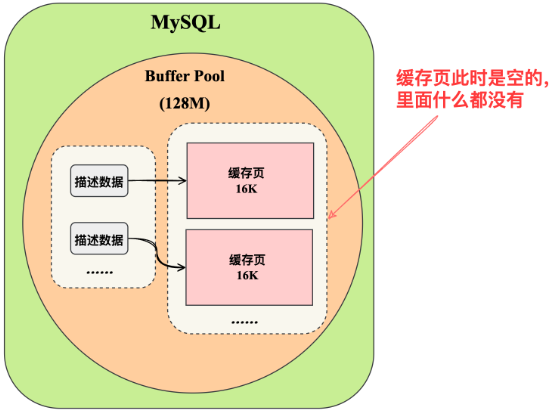
只不過這個時候,Buffer Pool中的一個一個的緩存頁都是空的,里面什么都沒有,要等數(shù)據(jù)庫運行起來之后,當對數(shù)據(jù)執(zhí)行增刪改查的操作的時候,才會把數(shù)據(jù)對應的頁從磁盤文件里讀取出來,放入Buffer Pool中的緩存頁中。
一次查詢大量數(shù)據(jù)對Buffer Pool的影響?
Buffer Pool 命中率(Hit Ratio)
- 當執(zhí)行一個大查詢時,MySQL 需要加載大量的數(shù)據(jù)頁到 Buffer Pool 中。如果這些數(shù)據(jù)頁之前沒有被緩存,它們將從磁盤讀取并替換掉 Buffer Pool 中已有的頁面。
- 這種行為可能導致頻繁使用的數(shù)據(jù)頁被擠出(evicted),進而降低 Buffer Pool 的命中率。低命中率意味著更多的磁盤 I/O 操作,這會顯著減慢查詢速度和整體數(shù)據(jù)庫性能。
InnoDB 緩沖池刷新:InnoDB 存儲引擎通過后臺線程定期刷新臟頁(即已經(jīng)被修改但尚未寫入磁盤的數(shù)據(jù)頁)。當有大量的新頁被加載到 Buffer Pool 中時,為了騰出空間,InnoDB 可能需要更積極地進行臟頁刷新操作,這同樣會消耗額外的 I/O 資源,并且在高負載下可能導致性能瓶頸
Mysql緩存能否替代Redis
- Redis緩存支持的場景更多。
- 實際工作中緩存的結果不單單是Mysql Select語句返回的結果,有可能是在此基礎上又加工的結果;而Mysql緩存的是Select語句的結果
- Redis可以提供更豐富的數(shù)據(jù)類型的訪問,如List、Set、Map、ZSet
- Redis緩存命中率要遠高于Mysql緩存。
- Mysql選擇要緩存的語句的方式不是根據(jù)訪問頻率,主要是根據(jù)select語句里邊是否包含動態(tài)變化的值,沒有動態(tài)變化值的則緩存,比如用了now函數(shù)就不會緩存。Redis是由客戶端自主根據(jù)訪問頻率高進行緩存。
- Redis豐富的數(shù)據(jù)結構使得緩存復用率更高,比如緩存的是List,可以隨意訪問List中的部分元素,比如分頁需求
- Mysql緩存的失效粒度很粗,只要表有更新,涉及該表的所有緩存(不管更新是否會影響緩存)都失效,這樣使得緩存的利用率會很低,只是適用更新很少的表
- 當存在主從結點,并且會從多個結點讀取數(shù)據(jù)時,各個結點的緩存不會同步3. 性能:Redis的查詢性能要遠高于Mysql緩存,最主要的原因是Redis是全部放在內存的,但是因為mysql緩存的命中率問題使得Mysql無法全部放到內存中。Redis性能好也還有一些其他原因
- Redis的存儲結構有利于讀寫性能Redis是IO多路復用,可以支持更大的吞吐,Mysql的數(shù)據(jù)特征使得做成IO多路復用絕大多數(shù)情況下也沒有意義
- 數(shù)據(jù)更新時會同時將該表的所有緩存失效,會使得數(shù)據(jù)更新的速度變慢。
什么是change_buffer
change_buffer 使 buffer_pool 里的一塊內容
Change Buffer是 MySQLInnoDB 存儲引擎中的一個機制,用于暫存對二級索引的插入和更新操作的變更,而不立即執(zhí)行這些操作,隨后,當InnoDB 進行合適的條件時(如頁被讀取或 Flush 操作)會將這些變更寫入到二級索引中
如果當前表 針對 name 有一個二級索引。假設執(zhí)行一條 update table set name ='yes' where id = 1(這條語句需要修改 name這個二級索引中的數(shù)據(jù)),此時bufferpool 并沒有對應二級索引的索引頁數(shù)據(jù)。
這個時候需要把索引頁加載才內存中立即執(zhí)行修改嗎?不是的,這時候 change buffer 就上場了。
如果當前二級索引頁不在 bufferpool 中,那么innodb會把更新保作緩存到 change buffer中,當下次訪問到這條教據(jù)后,會把索引頁加到 bufferpool 中,并且應用上 changebuffer 里面的變更,這樣就保證了數(shù)據(jù)的一致性。上述 SQL 中,change buffer 中會存儲 name 字段的舊索引值刪除操作和新索引值插入操作。
作用:
- 提高寫入性能:通過將對二級索引的變更暫存,可以減少對磁盤的頻繁寫入,提升插入和更新操作的性能。當二級索引頁不在 bufferpool 中時,change buffer可以避免立即從磁盤讀取對應索引頁導致的昂貴的隨機I/O ,對應的更改可以在后面當二級索引頁讀入 bufferpool 時候被批量應用。
- 批量處理:Change Buffer 可以在后續(xù)的操作中批量處理這些變更,減少了隨機寫入的開銷。
change buffer 只能用于二級索引的更改,不適用于主鍵索引,空間索引以及全文索引。還有,唯一索引也不行,因為唯一索引需要讀取數(shù)據(jù)然后檢查數(shù)據(jù)的一致性
更改先緩存在 change buffer 中,假如數(shù)據(jù)庫掛了,更改不是丟了嗎? change buffer也是要落盤存儲的, change bufer 會落盤到系統(tǒng)表空間里面,然后 redo log 也會記錄 change buffer 的修改來保證數(shù)據(jù)一致性。
Doublewrite Buffer 是什么?它有什么作用?
MhSOL 的 Doublewite Bufer是 InnoDB 存儲引擎中的一個機制,用于確保數(shù)據(jù)的安全性和一致性,其作用是將數(shù)據(jù)首先寫入一個內存緩中區(qū)(雙寫緩中區(qū)),然后再將其寫入數(shù)據(jù)文件。這種方式可以防止在寫入過程中因崩潰或故障導致數(shù)據(jù)損壞,確保數(shù)據(jù)的一致性和完整性。
工作原理簡述:
- 寫入流程:當事務提交時 InnoDB 首先將數(shù)據(jù)寫入Doubewrite Bufer,再從該緩沖區(qū)將數(shù)據(jù)寫入磁盤的實際數(shù)據(jù)文件。
- 恢復機制:在崩潰恢復時,InnoDB 會使用 Doublewrite Buffer 中的數(shù)據(jù)來修復損壞的頁,保證數(shù)據(jù)不丟失
Log Buffer 是什么?它有什么作用?
MySQL 中的 Log Buffer 是一個內存區(qū)域,用于暫時存儲事務日志(redo log)的數(shù)據(jù)。在InnoDB 存儲引擎中,它的主要作用是提高性能,通過批量寫入操作將日志數(shù)據(jù)從內存中寫入磁盤,減少磁盤 I/0 操作的頻率.。
擴展知識——Mysql使如何管理 Buffer Pool的
管理空閑頁-free鏈表
如何知道哪些緩存頁是空的
當數(shù)據(jù)庫運行起來之后,系統(tǒng)肯定會不停的執(zhí)行增刪改查的操作,此時就需要不停的從磁盤上讀取一個一個的數(shù)據(jù)頁放入Buffer Pool中的對應的緩存頁里去,把數(shù)據(jù)緩存起來,那么以后就可以在內存里對這個數(shù)據(jù)執(zhí)行增刪改查了。
但是此時在從磁盤上讀取數(shù)據(jù)頁放入Buffer Pool中的緩存頁的時候,必然涉及到一個問題,那就是哪些緩存頁是空閑的?
因為默認情況下磁盤上的數(shù)據(jù)頁和緩存頁是一 一對應起來的,都是16KB,一個數(shù)據(jù)頁對應一個緩存頁。數(shù)據(jù)頁只能加載到空閑的緩存頁里,所以MySql必須要知道Buffer Pool中哪些緩存頁是空閑的狀態(tài)?
MySQL數(shù)據(jù)庫會為Buffer Pool設計了一個free鏈表,是一個雙向鏈表數(shù)據(jù)結構,這個free鏈表里,每個節(jié)點就是一個空閑的緩存頁的描述數(shù)據(jù)塊的地址,也就是說,只要你一個緩存頁是空閑的,那么它的描述數(shù)據(jù)塊就會被放入這個free鏈表中。
剛開始數(shù)據(jù)庫啟動的時候,所有的緩存頁都是空閑的,因為此時可能是一個空的數(shù)據(jù)庫,一條數(shù)據(jù)都沒有,所以此時所有緩存頁的描述數(shù)據(jù)塊,都會被放入這個free鏈表中。
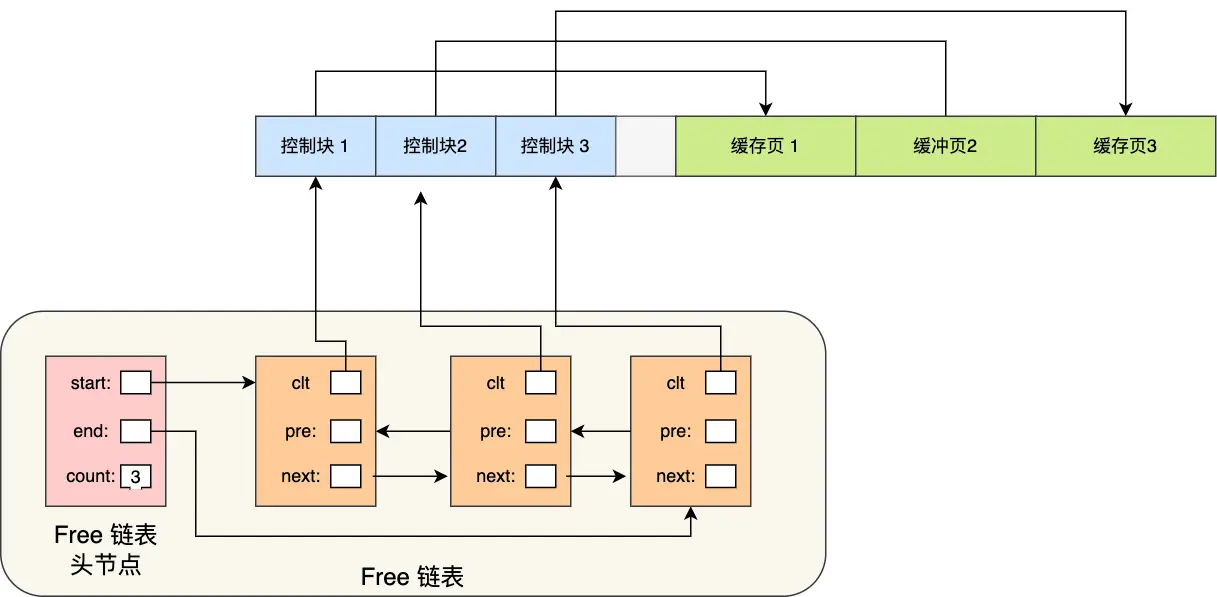
這個free鏈表里面就是各個緩存頁的控制塊,只要緩存頁是空閑的,那么他們對應的控制塊就會加入到這個free鏈表中,每個節(jié)點都會雙向鏈接自己的前后節(jié)點,組成一個雙向鏈表。
除此之外,這個free鏈表有一個基礎節(jié)點,它會引用鏈表的頭節(jié)點和尾節(jié)點,里面還存儲了鏈表中當前有多少個節(jié)點,也就是鏈表中有多少個控制塊的節(jié)點,也就是有多少個空閑的緩存頁。
磁盤上的頁如何讀取到Buffer Pool的緩存頁中去?
- 首先,需要從free鏈表里獲取一個控制塊,然后就可以獲取到這個控制塊對應的空閑緩存頁;
- 接著就可以把磁盤上的數(shù)據(jù)頁讀取到對應的緩存頁里去,同時把相關的一些數(shù)據(jù)寫入控制塊里去,比如這個數(shù)據(jù)頁所屬的表空間之類的信息
- 最后把那個控制塊從free鏈表里去除就可以了。
MySQL怎么知道某個數(shù)據(jù)頁已經(jīng)被緩存了
- 在執(zhí)行增刪改查的時候,肯定是先看看這個數(shù)據(jù)頁有沒有被緩存,如果沒被緩存就走上面的邏輯,從free鏈表中找到一個空閑的緩存頁,從磁盤上讀取數(shù)據(jù)頁寫入緩存頁,寫入控制數(shù)據(jù),從free鏈表中移除這個控制塊。
- 但是如果數(shù)據(jù)頁已經(jīng)被緩存了,那么就會直接使用了。所以其實數(shù)據(jù)庫還會有一個哈希表數(shù)據(jù)結構,他會用表空間號+ 數(shù)據(jù)頁號,作為一個key,然后緩存頁的地址作為value。當你要使用一個數(shù)據(jù)頁的時候,通過“表空間號+數(shù)據(jù)頁號”作為key去這個哈希表里查一下,如果沒有就讀取數(shù)據(jù)頁,如果已經(jīng)有了,就說明數(shù)據(jù)頁已經(jīng)被緩存了
MySQL引入了一個數(shù)據(jù)頁緩存哈希表的結構,也就是說,每次你讀取一個數(shù)據(jù)頁到緩存之后,都會在這個哈希表中寫入一個key-value對,key就是表空間號+數(shù)據(jù)頁號,value就是緩存頁的地址,那么下次如果你再使用這個數(shù)據(jù)頁,就可以從哈希表里直接讀取出來它已經(jīng)被放入一個緩存頁了。
管理臟頁-flush鏈表
為什么會有臟頁
如果你要更新的數(shù)據(jù)頁都會在Buffer Pool的緩存頁里,供你在內存中直接執(zhí)行增刪改的操作。mysql此時一旦更新了緩存頁中的數(shù)據(jù),那么緩存頁里的數(shù)據(jù)和磁盤上的數(shù)據(jù)頁里的數(shù)據(jù),就不一致了,那么就說這個緩存頁是臟頁。
臟頁怎么刷回磁盤
為了能快速知道哪些緩存頁是臟的,于是就設計出 Flush 鏈表,它跟 Free 鏈表類似的,鏈表的節(jié)點也是控制塊,區(qū)別在于 Flush 鏈表的元素都是臟頁。
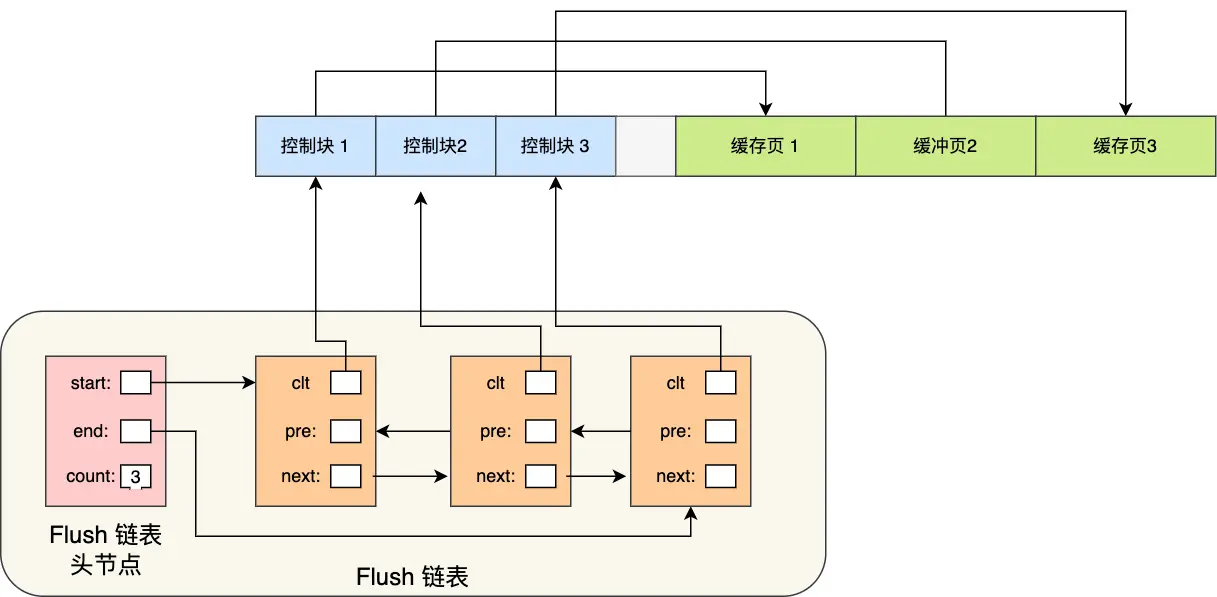
有了 Flush 鏈表后,后臺線程就可以遍歷 Flush 鏈表,將臟頁寫入到磁盤。
提高緩存命中率-LRU鏈表
Buffer Pool 的大小是有限的,對于一些頻繁訪問的數(shù)據(jù)希望可以一直留在 Buffer Pool 中,而一些很少訪問的數(shù)據(jù)希望可以在某些時機可以淘汰掉,從而保證 Buffer Pool 不會因為滿了而導致無法再緩存新的數(shù)據(jù),同時還能保證常用數(shù)據(jù)留在 Buffer Pool 中。
緩存命中率是什么?
假設現(xiàn)在有兩個緩存頁,一個緩存頁的數(shù)據(jù),經(jīng)常會被修改和查詢,比如在100次請求中,有30次都是在查詢和修改這個緩存頁里的數(shù)據(jù)。那么此時我們可以說這種情況下,緩存命中率很高,為什么呢?因為100次請求中,30次都可以操作緩存,不需要從磁盤加載數(shù)據(jù),這個緩存命中率就比較高了。
另外一個緩存頁里的數(shù)據(jù),就是剛從磁盤加載到緩存頁之后,被修改和查詢過1次,之后100次請求中沒有一次是修改和查詢這個緩存頁的數(shù)據(jù)的,那么此時我們就說緩存命中率有點低,因為大部分請求可能還需要走磁盤查詢數(shù)據(jù),他們要操作的數(shù)據(jù)不在緩存中。
所以針對上述兩個緩存頁,當緩存頁都滿了的時候,第一個緩存頁命中率很高,因此肯定是選擇將第二個緩存頁刷入磁盤中,從而釋放緩存頁。
因此就引入LRU鏈表來判斷哪些緩存頁是不常用的。Least Recently Used,最近最少使用。整體思想就是,鏈表頭部的節(jié)點是最近使用的,而鏈表末尾的節(jié)點是最久沒被使用的。那么,當空間不夠了,就淘汰最久沒被使用的節(jié)點,從而騰出空間。
簡單版的LRU鏈表
- 當訪問的頁在 Buffer Pool 里,就直接把該頁對應的 LRU 鏈表節(jié)點移動到鏈表的頭部。
- 當訪問的頁不在 Buffer Pool 里,除了要把頁放入到 LRU 鏈表的頭部,還要淘汰 LRU 鏈表末尾的節(jié)點。
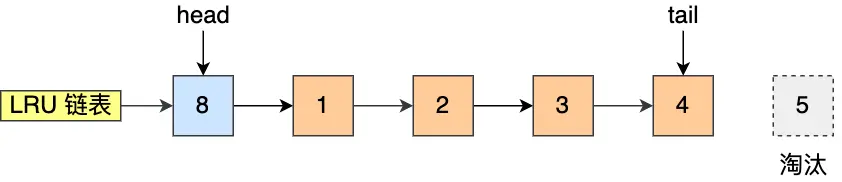
比如下圖,假設 LRU 鏈表長度為 5,LRU 鏈表從左到右有 1,2,3,4,5 的頁。

如果訪問了 3 號的頁,因為 3 號頁在 Buffer Pool 里,所以把 3 號頁移動到頭部即可。

而如果接下來,訪問了 8 號頁,因為 8 號頁不在 Buffer Pool 里,所以需要先淘汰末尾的 5 號頁,然后再將 8 號頁加入到頭部。
簡單版的LRU鏈表存在兩個問題
- 預讀失效
- Buffer Pool 污染;
什么是預讀失效?
MySQL 的預讀機制:程序是有空間局部性的,靠近當前被訪問數(shù)據(jù)的數(shù)據(jù),在未來很大概率會被訪問到。所以,MySQL 在加載數(shù)據(jù)頁時,會提前把它相鄰的數(shù)據(jù)頁一并加載進來,目的是為了減少磁盤 IO。
但是可能這些被提前加載進來的數(shù)據(jù)頁,并沒有被訪問,相當于這個預讀是白做了,這個就是預讀失效。
如果使用簡單的 LRU 算法,就會把預讀頁放到 LRU 鏈表頭部,而當 Buffer Pool空間不夠的時候,還需要把末尾的頁淘汰掉。
如果這些預讀頁如果一直不會被訪問到,就會出現(xiàn)一個很奇怪的問題,不會被訪問的預讀頁卻占用了 LRU 鏈表前排的位置,而末尾淘汰的頁,可能是頻繁訪問的頁,這樣就大大降低了緩存命中率。
如何解決
首先不能害怕預讀失效就把預讀機制去了,空間局部性原理在大部分場景下是成立且有效的
而要避免預讀失效帶來影響,最好就是讓預讀的頁停留在 Buffer Pool 里的時間要盡可能的短,讓真正被訪問的頁才移動到 LRU 鏈表的頭部,從而保證真正被讀取的熱數(shù)據(jù)留在 Buffer Pool 里的時間盡可能長。
Mysql將LRU鏈表劃分成了兩個區(qū)域:old 區(qū)域 和 young 區(qū)域。
young 區(qū)域在 LRU 鏈表的前半部分,old 區(qū)域則是在后半部分
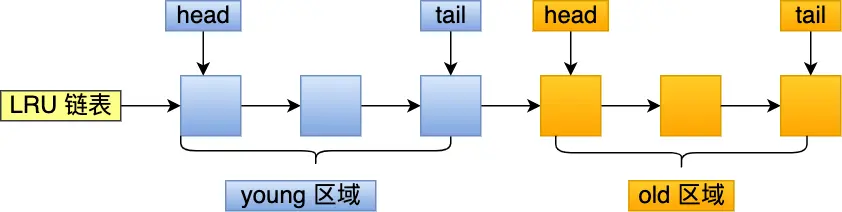
劃分這兩個區(qū)域后,預讀的頁就只需要加入到 old 區(qū)域的頭部,當頁被真正訪問的時候,才將頁插入 young 區(qū)域的頭部。如果預讀的頁一直沒有被訪問,就會從 old 區(qū)域移除,這樣就不會影響 young 區(qū)域中的熱點數(shù)據(jù)。
什么是 Buffer Pool 污染?
即使有了以上劃分young區(qū)的old區(qū)的鏈表也會存在這個問題。
當某一個 SQL 語句掃描了大量的數(shù)據(jù)時,因為被讀取了,這些數(shù)據(jù)就都會放在young區(qū)的頭部,那么由于 Buffer Pool 空間有限,就有可能會將 Buffer Pool 里的所有頁都替換出去,導致LRU的young區(qū)域的大量熱數(shù)據(jù)被淘汰,等這些熱數(shù)據(jù)又被再次訪問的時候,由于緩存未命中,就會產生大量的磁盤 IO,MySQL 性能就會急劇下降,這個過程被稱為 Buffer Pool 污染。
如何解決
MySQL 將進入到 young 區(qū)域條件增加了一個停留在 old 區(qū)域的時間判斷。
Mysql在對某個處在 old 區(qū)域的緩存頁進行第一次訪問時,就在它對應的控制塊中記錄下來這個訪問時間:
- 如果后續(xù)的訪問時間與第一次訪問的時間在某個時間間隔內,那么該緩存頁就不會被從 old 區(qū)域移動到 young 區(qū)域的頭部;如果在時間窗口內被多次訪問,該頁仍會保留在old區(qū)域
- 如果后續(xù)的訪問時間與第一次訪問的時間不在某個時間間隔內,那么該緩存頁移動到 young 區(qū)域的頭部;
對于全表掃描等操作,由于數(shù)據(jù)頁通常在短時間內被連續(xù)訪問(遠小于1秒),它們會保持在old區(qū)域而不會污染young區(qū)域。這樣就能保證只有真正被頻繁訪問(間隔超過1秒)的數(shù)據(jù)頁才會進入young區(qū)域
本文來自在線網(wǎng)站:seven的菜鳥成長之路,作者:seven,轉載請注明原文鏈接:www.seven97.top

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號