為什么Raft算法是分布式系統(tǒng)的首選?
背景
當(dāng)今的數(shù)據(jù)中心和應(yīng)用程序在高度動態(tài)的環(huán)境中運(yùn)行,為了應(yīng)對高度動態(tài)的環(huán)境,它們通過額外的服務(wù)器進(jìn)行橫向擴(kuò)展,并且根據(jù)需求進(jìn)行擴(kuò)展和收縮。同時(shí),服務(wù)器和網(wǎng)絡(luò)故障也很常見。
因此,系統(tǒng)必須在正常操作期間處理服務(wù)器的上下線。它們必須對變故做出反應(yīng)并在幾秒鐘內(nèi)自動適應(yīng);對客戶來說的話,明顯的中斷通常是不可接受的。
幸運(yùn)的是,分布式共識可以幫助應(yīng)對這些挑戰(zhàn)。
拜占庭將軍
在介紹共識算法之前,先介紹一個(gè)簡化版拜占庭將軍的例子來幫助理解共識算法。
假設(shè)多位拜占庭將軍中沒有叛軍,信使的信息可靠但有可能被暗殺的情況下,將軍們?nèi)绾芜_(dá)成是否要進(jìn)攻的一致性決定?
解決方案大致可以理解成:先在所有的將軍中選出一個(gè)大將軍,用來做出所有的決定。
舉例如下:假如現(xiàn)在一共有 3 個(gè)將軍 A,B 和 C,每個(gè)將軍都有一個(gè)隨機(jī)時(shí)間的倒計(jì)時(shí)器,倒計(jì)時(shí)一結(jié)束,這個(gè)將軍就把自己當(dāng)成大將軍候選人,然后派信使傳遞選舉投票的信息給將軍 B 和 C,如果將軍 B 和 C 還沒有把自己當(dāng)作候選人(自己的倒計(jì)時(shí)還沒有結(jié)束),并且沒有把選舉票投給其他人,它們就會把票投給將軍 A,信使回到將軍 A 時(shí),將軍 A 知道自己收到了足夠的票數(shù),成為大將軍。在有了大將軍之后,是否需要進(jìn)攻就由大將軍 A 決定,然后再去派信使通知另外兩個(gè)將軍,自己已經(jīng)成為了大將軍。如果一段時(shí)間還沒收到將軍 B 和 C 的回復(fù)(信使可能會被暗殺),那就再重派一個(gè)信使,直到收到回復(fù)。
共識算法
共識是可容錯(cuò)系統(tǒng)中的一個(gè)基本問題:即使面對故障,服務(wù)器也可以在共享狀態(tài)上達(dá)成一致。
共識算法允許一組節(jié)點(diǎn)像一個(gè)整體一樣一起工作,即使其中的一些節(jié)點(diǎn)出現(xiàn)故障也能夠繼續(xù)工作下去,其正確性主要是源于復(fù)制狀態(tài)機(jī)的性質(zhì):一組Server的狀態(tài)機(jī)計(jì)算相同狀態(tài)的副本,即使有一部分的Server宕機(jī)了它們?nèi)匀荒軌蚶^續(xù)運(yùn)行。
一般通過使用復(fù)制日志來實(shí)現(xiàn)復(fù)制狀態(tài)機(jī)。每個(gè)Server存儲著一份包括命令序列的日志文件,狀態(tài)機(jī)會按順序執(zhí)行這些命令。因?yàn)槊總€(gè)日志包含相同的命令,并且順序也相同,所以每個(gè)狀態(tài)機(jī)處理相同的命令序列。由于狀態(tài)機(jī)是確定性的,所以處理相同的狀態(tài),得到相同的輸出。
因此共識算法的工作就是保持復(fù)制日志的一致性。服務(wù)器上的共識模塊從客戶端接收命令并將它們添加到日志中。它與其他服務(wù)器上的共識模塊通信,以確保即使某些服務(wù)器發(fā)生故障。每個(gè)日志最終包含相同順序的請求。一旦命令被正確地復(fù)制,它們就被稱為已提交。每個(gè)服務(wù)器的狀態(tài)機(jī)按照日志順序處理已提交的命令,并將輸出返回給客戶端,因此,這些服務(wù)器形成了一個(gè)單一的、高度可靠的狀態(tài)機(jī)。
適用于實(shí)際系統(tǒng)的共識算法通常具有以下特性:
-
安全。確保在非拜占庭條件(也就是上文中提到的簡易版拜占庭)下的安全性,包括網(wǎng)絡(luò)延遲、分區(qū)、包丟失、復(fù)制和重新排序。
-
高可用。只要大多數(shù)服務(wù)器都是可操作的,并且可以相互通信,也可以與客戶端進(jìn)行通信,那么這些服務(wù)器就可以看作完全功能可用的。因此,一個(gè)典型的由五臺服務(wù)器組成的集群可以容忍任何兩臺服務(wù)器端故障。假設(shè)服務(wù)器因停止而發(fā)生故障;它們稍后可能會從穩(wěn)定存儲上的狀態(tài)中恢復(fù)并重新加入集群。
-
一致性不依賴時(shí)序。錯(cuò)誤的時(shí)鐘和極端的消息延遲,在最壞的情況下也只會造成可用性問題,而不會產(chǎn)生一致性問題。
-
在集群中大多數(shù)服務(wù)器響應(yīng),命令就可以完成,不會被少數(shù)運(yùn)行緩慢的服務(wù)器來影響整體系統(tǒng)性能。
Raft算法是什么?
Raft 也是一個(gè) 一致性算法,和 Paxos 目標(biāo)相同。但它還有另一個(gè)名字 - 易于理解的一致性算法。Paxos 和 Raft 都是為了實(shí)現(xiàn) 一致性 產(chǎn)生的。不同于Paxos算法直接從分布式一致性問題出發(fā)推導(dǎo)出來,Raft算法則是從多副本狀態(tài)機(jī)的角度提出,用于管理多副本狀態(tài)機(jī)的日志復(fù)制。
Raft實(shí)現(xiàn)了和Paxos相同的功能,它將一致性分解為多個(gè)子問題: Leader選舉(Leader election)、日志同步(Log replication)、安全性(Safety)、日志壓縮(Log compaction)、成員變更(Membership change)等。同時(shí),Raft算法使用了更強(qiáng)的假設(shè)來減少了需要考慮的狀態(tài),使之變的易于理解和實(shí)現(xiàn)。
基礎(chǔ)
節(jié)點(diǎn)類型
一個(gè) Raft 集群包括若干服務(wù)器,以典型的 5 服務(wù)器集群舉例。在任意的時(shí)間,每個(gè)服務(wù)器一定會處于以下三個(gè)狀態(tài)中的一個(gè):
-
Leader:負(fù)責(zé)發(fā)起心跳,響應(yīng)客戶端,創(chuàng)建日志,同步日志。
-
Candidate:Leader 選舉過程中的臨時(shí)角色,由 Follower 轉(zhuǎn)化而來,發(fā)起投票參與競選。
-
Follower:接受 Leader 的心跳和日志同步數(shù)據(jù),投票給 Candidate。
在正常的情況下,只有一個(gè)服務(wù)器是 Leader,剩下的服務(wù)器是 Follower。Follower 是被動的,它們不會發(fā)送任何請求,只是響應(yīng)來自 Leader 和 Candidate 的請求。
任期
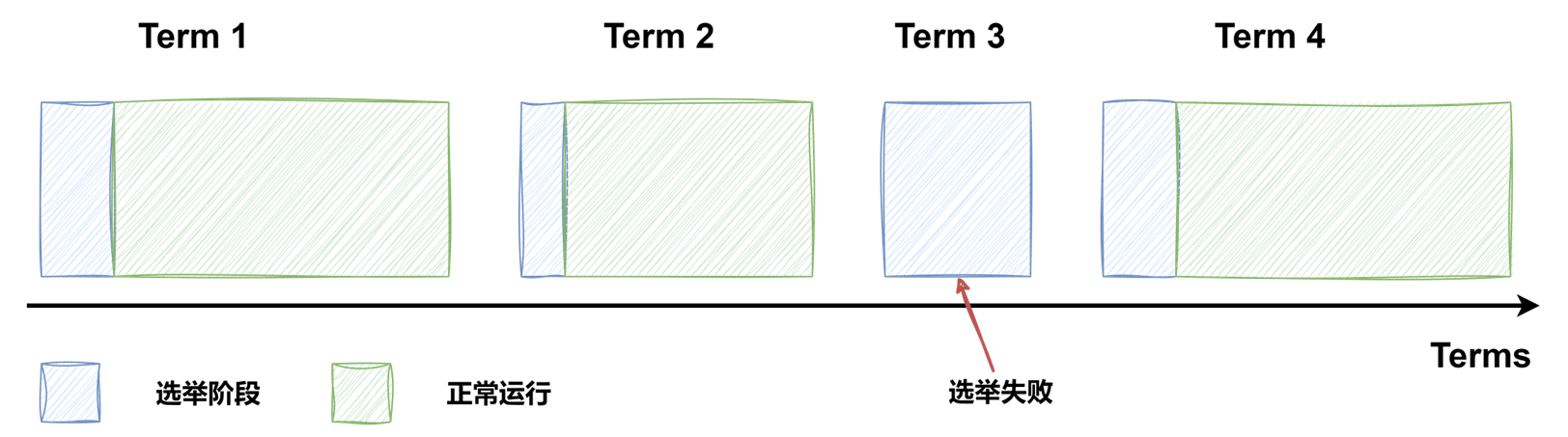
如圖所示,raft 算法將時(shí)間劃分為任意長度的任期(term),任期用連續(xù)的數(shù)字表示,看作當(dāng)前 term 號。每一個(gè)任期的開始都是一次選舉,在選舉開始時(shí),一個(gè)或多個(gè) Candidate 會嘗試成為 Leader。如果一個(gè) Candidate 贏得了選舉,它就會在該任期內(nèi)擔(dān)任 Leader。如果沒有選出 Leader,將會開啟另一個(gè)任期,并立刻開始下一次選舉。raft 算法保證在給定的一個(gè)任期最少要有一個(gè) Leader。
每個(gè)節(jié)點(diǎn)都會存儲當(dāng)前的 term 號,當(dāng)服務(wù)器之間進(jìn)行通信時(shí)會交換當(dāng)前的 term 號;如果有服務(wù)器發(fā)現(xiàn)自己的 term 號比其他人小,那么他會更新到較大的 term 值。如果一個(gè) Candidate 或者 Leader 發(fā)現(xiàn)自己的 term 過期了,他會立即退回成 Follower。如果一臺服務(wù)器收到的請求的 term 號是過期的,那么它會拒絕此次請求。
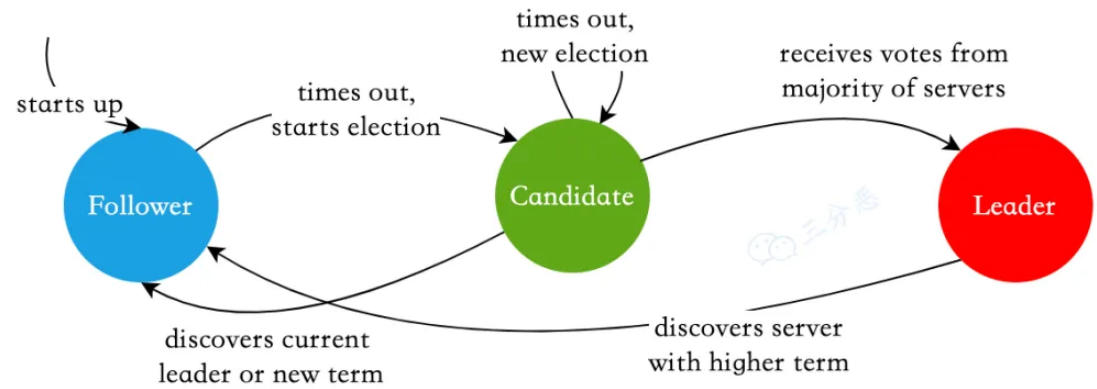
三類角色的變遷圖如下:
日志
-
entry:每一個(gè)事件成為 entry,只有 Leader 可以創(chuàng)建 entry。entry 的內(nèi)容為<term,index,cmd>其中 cmd 是可以應(yīng)用到狀態(tài)機(jī)的操作。
-
log:由 entry 構(gòu)成的數(shù)組,每一個(gè) entry 都有一個(gè)表明自己在 log 中的 index。只有 Leader 才可以改變其他節(jié)點(diǎn)的 log。entry 總是先被 Leader 添加到自己的 log 數(shù)組中,然后再發(fā)起共識請求,獲得同意后才會被 Leader 提交給狀態(tài)機(jī)。Follower 只能從 Leader 獲取新日志和當(dāng)前的 commitIndex,然后把對應(yīng)的 entry 應(yīng)用到自己的狀態(tài)機(jī)中。
Raft算法子問題
Raft實(shí)現(xiàn)了和Paxos相同的功能,它將一致性分解為多個(gè)子問題:
- Leader選舉(Leader election)
- 日志同步(Log replication)
- 安全性(Safety)
- 日志壓縮(Log compaction)
- 成員變更(Membership change)
領(lǐng)導(dǎo)人選舉
raft 使用心跳機(jī)制來觸發(fā) Leader 的選舉。當(dāng)Server啟動時(shí),初始化為Follower。Leader向所有Followers周期性發(fā)送heartbeat。如果Follower在選舉超時(shí)時(shí)間內(nèi)沒有收到Leader的heartbeat,就會等待一段隨機(jī)的時(shí)間后發(fā)起一次Leader選舉。 Follower將其當(dāng)前term加一然后轉(zhuǎn)換為Candidate。它首先給自己投票并且給集群中的其他服務(wù)器發(fā)送 RequestVote RPC 。結(jié)果有以下三種情況:
- 贏得了多數(shù)(超過1/2)的選票,成功選舉為Leader;
- 收到了Leader的消息,表示有其它服務(wù)器已經(jīng)搶先當(dāng)選了Leader;
- 沒有Server贏得多數(shù)的選票,Leader選舉失敗,等待選舉時(shí)間超時(shí)(Election Timeout)后發(fā)起下一次選舉。
在 Candidate 等待選票的時(shí)候,它可能收到其他節(jié)點(diǎn)聲明自己是 Leader 的心跳,此時(shí)有兩種情況:
-
該 Leader 的 term 號大于等于自己的 term 號,說明對方已經(jīng)成為 Leader,則自己回退為 Follower。
-
該 Leader 的 term 號小于自己的 term 號,那么會拒絕該請求并讓該節(jié)點(diǎn)更新 term。
如果一臺服務(wù)器能夠收到來自 Leader 或者 Candidate 的有效信息,那么它會一直保持為 Follower 狀態(tài),并且刷新自己的 electionElapsed,重新計(jì)時(shí)。
Leader 會向所有的 Follower 周期性發(fā)送心跳來保證自己的 Leader 地位。如果一個(gè) Follower 在一個(gè)周期內(nèi)沒有收到心跳信息,就叫做選舉超時(shí),然后它就會認(rèn)為此時(shí)沒有可用的 Leader,并且開始進(jìn)行一次選舉以選出一個(gè)新的 Leader。
由于可能同一時(shí)刻出現(xiàn)多個(gè) Candidate,導(dǎo)致沒有 Candidate 獲得大多數(shù)選票,如果沒有其他手段來重新分配選票的話,那么可能會無限重復(fù)下去。
日志復(fù)制
一旦選出了 Leader,它就開始接受客戶端的請求。每一個(gè)客戶端的請求都包含一條需要被復(fù)制狀態(tài)機(jī)(Replicated State Machine)執(zhí)行的命令。
Leader 收到客戶端請求后,會生成一個(gè) entry,包含<index,term,cmd>,再將這個(gè) entry 添加到自己的日志末尾后,向所有的節(jié)點(diǎn)廣播該 entry,要求其他服務(wù)器復(fù)制這條 entry。
如果 Follower 接受該 entry,則會將 entry 添加到自己的日志后面,同時(shí)返回給 Leader 同意。
如果 Leader 收到了多數(shù)的成功響應(yīng),Leader 會將這個(gè) entry 應(yīng)用到自己的狀態(tài)機(jī)中,之后可以成為這個(gè) entry 是 committed 的,并且向客戶端返回執(zhí)行結(jié)果。
raft 保證以下兩個(gè)性質(zhì):
-
在兩個(gè)日志里,有兩個(gè) entry 擁有相同的 index 和 term,那么它們一定有相同的 cmd,即所存儲的命令是相同的。
-
在兩個(gè)日志里,有兩個(gè) entry 擁有相同的 index 和 term,那么它們前面的 entry 也一定相同
第一條特性源于Leader在一個(gè)term內(nèi)在給定的一個(gè)log index最多創(chuàng)建一條日志條目,同時(shí)該條目在日志中的位置也從來不會改變。
第二條特性源于 AppendEntries 的一個(gè)簡單的一致性檢查。當(dāng)發(fā)送一個(gè) AppendEntries RPC 時(shí),Leader會把新日志條目緊接著之前的條目的log index和term都包含在里面。如果Follower沒有在它的日志中找到log index和term都相同的日志,它就會拒絕新的日志條目。
一般情況下,Leader和Followers的日志保持一致,因此 AppendEntries 一致性檢查通常不會失敗。然而,Leader崩潰可能會導(dǎo)致日志不一致: 舊的Leader可能沒有完全復(fù)制完日志中的所有條目。Leader 通過強(qiáng)制 Follower 復(fù)制自己的日志來處理日志的不一致。這就意味著,在 Follower 上的沖突日志會被領(lǐng)導(dǎo)者的日志覆蓋。
為了使得 Follower 的日志和自己的日志一致,Leader 需要找到 Follower 與它日志一致的地方,然后刪除 Follower 在該位置之后的日志,接著把這之后的日志發(fā)送給 Follower。
Leader 給每一個(gè)Follower 維護(hù)了一個(gè) nextIndex,它表示 Leader 將要發(fā)送給該追隨者的下一條日志條目的索引。當(dāng)一個(gè) Leader 開始掌權(quán)時(shí),它會將 nextIndex 初始化為它的最新的日志條目索引數(shù)+1。如果一個(gè) Follower 的日志和 Leader 的不一致,AppendEntries 一致性檢查會在下一次 AppendEntries RPC 時(shí)返回失敗。在失敗之后,Leader 會將 nextIndex 遞減然后重試 AppendEntries RPC。最終 nextIndex 會達(dá)到一個(gè) Leader 和 Follower 日志一致的地方。這時(shí),AppendEntries 會返回成功,F(xiàn)ollower 中沖突的日志條目都被移除了,并且添加所缺少的上了 Leader 的日志條目。一旦 AppendEntries 返回成功,F(xiàn)ollower 和 Leader 的日志就一致了,這樣的狀態(tài)會保持到該任期結(jié)束。
安全性
選舉限制
Leader 需要保證自己存儲全部已經(jīng)提交的日志條目。這樣才可以使日志條目只有一個(gè)流向:從 Leader 流向 Follower,Leader 永遠(yuǎn)不會覆蓋已經(jīng)存在的日志條目。
每個(gè) Candidate 發(fā)送 RequestVoteRPC 時(shí),都會帶上最后一個(gè) entry 的信息。所有節(jié)點(diǎn)收到投票信息時(shí),會對該 entry 進(jìn)行比較,如果發(fā)現(xiàn)自己的更新,則拒絕投票給該 Candidate。
判斷日志新舊的方式:如果兩個(gè)日志的 term 不同,term 大的更新;如果 term 相同,更長的 index 更新。
節(jié)點(diǎn)崩潰
如果 Leader 崩潰,集群中的節(jié)點(diǎn)在 electionTimeout 時(shí)間內(nèi)沒有收到 Leader 的心跳信息就會觸發(fā)新一輪的選主,在選主期間整個(gè)集群對外是不可用的。
如果 Follower 和 Candidate 崩潰,處理方式會簡單很多。之后發(fā)送給它的 RequestVoteRPC 和 AppendEntriesRPC 會失敗。由于 raft 的所有請求都是冪等的,所以失敗的話會無限的重試。如果崩潰恢復(fù)后,就可以收到新的請求,然后選擇追加或者拒絕 entry。
時(shí)間與可用性
raft 的要求之一就是安全性不依賴于時(shí)間:系統(tǒng)不能僅僅因?yàn)橐恍┦录l(fā)生的比預(yù)想的快一些或者慢一些就產(chǎn)生錯(cuò)誤。為了保證上述要求,最好能滿足以下的時(shí)間條件:
broadcastTime << electionTimeout << MTBF
-
broadcastTime:向其他節(jié)點(diǎn)并發(fā)發(fā)送消息的平均響應(yīng)時(shí)間;
-
electionTimeout:選舉超時(shí)時(shí)間;
-
MTBF(mean time between failures):單臺機(jī)器的平均健康時(shí)間;
broadcastTime應(yīng)該比electionTimeout小一個(gè)數(shù)量級,為的是使Leader能夠持續(xù)發(fā)送心跳信息(heartbeat)來阻止Follower開始選舉;
electionTimeout也要比MTBF小幾個(gè)數(shù)量級,為的是使得系統(tǒng)穩(wěn)定運(yùn)行。當(dāng)Leader崩潰時(shí),大約會在整個(gè)electionTimeout的時(shí)間內(nèi)不可用;我們希望這種情況僅占全部時(shí)間的很小一部分。
由于broadcastTime和MTBF是由系統(tǒng)決定的屬性,因此需要決定electionTimeout的時(shí)間。
一般來說,broadcastTime 一般為 0.5~20ms,electionTimeout 可以設(shè)置為 10~500ms,MTBF 一般為一兩個(gè)月。
日志壓縮
在實(shí)際的系統(tǒng)中,不能讓日志無限增長,否則系統(tǒng)重啟時(shí)需要花很長的時(shí)間進(jìn)行回放,從而影響可用性。Raft采用對整個(gè)系統(tǒng)進(jìn)行snapshot來解決,snapshot之前的日志都可以丟棄。
每個(gè)副本獨(dú)立的對自己的系統(tǒng)狀態(tài)進(jìn)行snapshot,并且只能對已經(jīng)提交的日志記錄進(jìn)行snapshot。
Snapshot中包含以下內(nèi)容:
- 日志元數(shù)據(jù)。最后一條已提交的 log entry的 log index和term。這兩個(gè)值在snapshot之后的第一條log entry的AppendEntries RPC的完整性檢查的時(shí)候會被用上。
- 系統(tǒng)當(dāng)前狀態(tài)。
當(dāng)Leader要發(fā)給某個(gè)日志落后太多的Follower的log entry被丟棄,Leader會將snapshot發(fā)給Follower。或者當(dāng)新加進(jìn)一臺機(jī)器時(shí),也會發(fā)送snapshot給它。發(fā)送snapshot使用InstalledSnapshot RPC。
做snapshot既不要做的太頻繁,否則消耗磁盤帶寬, 也不要做的太不頻繁,否則一旦節(jié)點(diǎn)重啟需要回放大量日志,影響可用性。推薦當(dāng)日志達(dá)到某個(gè)固定的大小做一次snapshot。
做一次snapshot可能耗時(shí)過長,會影響正常日志同步。可以通過使用copy-on-write技術(shù)避免snapshot過程影響正常日志同步。
成員變更
成員變更是在集群運(yùn)行過程中副本發(fā)生變化,如增加/減少副本數(shù)、節(jié)點(diǎn)替換等。
成員變更也是一個(gè)分布式一致性問題,既所有服務(wù)器對新成員達(dá)成一致。但是成員變更又有其特殊性,因?yàn)樵诔蓡T變更的一致性達(dá)成的過程中,參與投票的進(jìn)程會發(fā)生變化。
如果將成員變更當(dāng)成一般的一致性問題,直接向Leader發(fā)送成員變更請求,Leader復(fù)制成員變更日志,達(dá)成多數(shù)派之后提交,各服務(wù)器提交成員變更日志后從舊成員配置(Cold)切換到新成員配置(Cnew)。
因?yàn)楦鱾€(gè)服務(wù)器提交成員變更日志的時(shí)刻可能不同,造成各個(gè)服務(wù)器從舊成員配置(Cold)切換到新成員配置(Cnew)的時(shí)刻不同。
成員變更不能影響服務(wù)的可用性,但是成員變更過程的某一時(shí)刻,可能出現(xiàn)在Cold和Cnew中同時(shí)存在兩個(gè)不相交的多數(shù)派,進(jìn)而可能選出兩個(gè)Leader,形成不同的決議,破壞安全性。
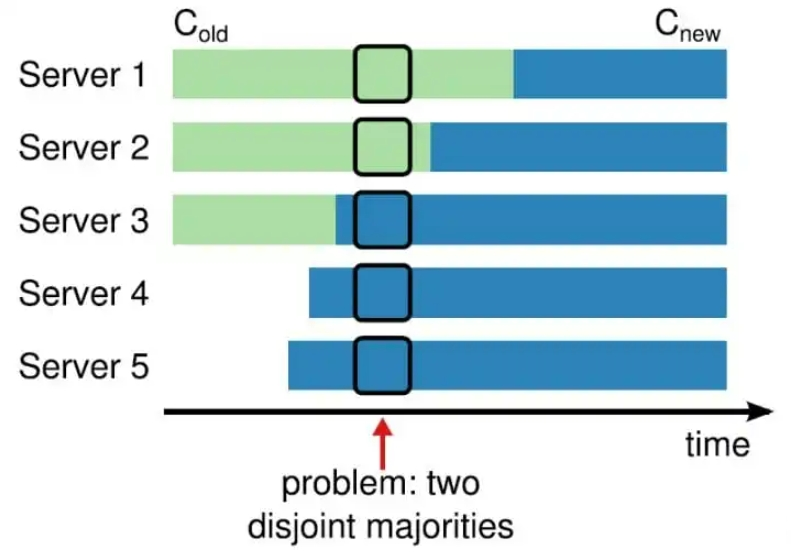
由于成員變更的這一特殊性,成員變更不能當(dāng)成一般的一致性問題去解決。
為了解決這一問題,Raft提出了兩階段的成員變更方法。集群先從舊成員配置Cold切換到一個(gè)過渡成員配置,稱為共同一致(joint consensus),共同一致是舊成員配置Cold和新成員配置Cnew的組合Cold U Cnew,一旦共同一致Cold U Cnew被提交,系統(tǒng)再切換到新成員配置Cnew。
Raft兩階段成員變更過程如下:
- Leader收到成員變更請求從Cold切成Cnew;
- Leader在本地生成一個(gè)新的log entry,其內(nèi)容是Cold∪Cnew,代表當(dāng)前時(shí)刻新舊成員配置共存,寫入本地日志,同時(shí)將該log entry復(fù)制至Cold∪Cnew中的所有副本。在此之后新的日志同步需要保證得到Cold和Cnew兩個(gè)多數(shù)派的確認(rèn);
- Follower收到Cold∪Cnew的log entry后更新本地日志,并且此時(shí)就以該配置作為自己的成員配置;
- 如果Cold和Cnew中的兩個(gè)多數(shù)派確認(rèn)了Cold U Cnew這條日志,Leader就提交這條log entry;
- 接下來Leader生成一條新的log entry,其內(nèi)容是新成員配置Cnew,同樣將該log entry寫入本地日志,同時(shí)復(fù)制到Follower上;
- Follower收到新成員配置Cnew后,將其寫入日志,并且從此刻起,就以該配置作為自己的成員配置,并且如果發(fā)現(xiàn)自己不在Cnew這個(gè)成員配置中會自動退出;
- Leader收到Cnew的多數(shù)派確認(rèn)后,表示成員變更成功,后續(xù)的日志只要得到Cnew多數(shù)派確認(rèn)即可。Leader給客戶端回復(fù)成員變更執(zhí)行成功。
異常分析:
- 如果Leader的Cold U Cnew尚未推送到Follower,Leader就掛了,此后選出的新Leader并不包含這條日志,此時(shí)新Leader依然使用Cold作為自己的成員配置。
- 如果Leader的Cold U Cnew推送到大部分的Follower后就掛了,此后選出的新Leader可能是Cold也可能是Cnew中的某個(gè)Follower。
- 如果Leader在推送Cnew配置的過程中掛了,那么同樣,新選出來的Leader可能是Cold也可能是Cnew中的某一個(gè),此后客戶端繼續(xù)執(zhí)行一次改變配置的命令即可。
- 如果大多數(shù)的Follower確認(rèn)了Cnew這個(gè)消息后,那么接下來即使Leader掛了,新選出來的Leader肯定位于Cnew中。
- 兩階段成員變更比較通用且容易理解,但是實(shí)現(xiàn)比較復(fù)雜,同時(shí)兩階段的變更協(xié)議也會在一定程度上影響變更過程中的服務(wù)可用性,因此我們期望增強(qiáng)成員變更的限制,以簡化操作流程。
兩階段成員變更,之所以分為兩個(gè)階段,是因?yàn)閷old與Cnew的關(guān)系沒有做任何假設(shè),為了避免Cold和Cnew各自形成不相交的多數(shù)派選出兩個(gè)Leader,才引入了兩階段方案。
如果增強(qiáng)成員變更的限制,假設(shè)Cold與Cnew任意的多數(shù)派交集不為空,這兩個(gè)成員配置就無法各自形成多數(shù)派,那么成員變更方案就可能簡化為一階段。
那么如何限制Cold與Cnew,使之任意的多數(shù)派交集不為空呢? 方法就是每次成員變更只允許增加或刪除一個(gè)成員。
可從數(shù)學(xué)上嚴(yán)格證明,只要每次只允許增加或刪除一個(gè)成員,Cold與Cnew不可能形成兩個(gè)不相交的多數(shù)派。
一階段成員變更:
- 成員變更限制每次只能增加或刪除一個(gè)成員(如果要變更多個(gè)成員,連續(xù)變更多次)。
- 成員變更由Leader發(fā)起,Cnew得到多數(shù)派確認(rèn)后,返回客戶端成員變更成功。
- 一次成員變更成功前不允許開始下一次成員變更,因此新任Leader在開始提供服務(wù)前要將自己本地保存的最新成員配置重新投票形成多數(shù)派確認(rèn)。
- Leader只要開始同步新成員配置,即可開始使用新的成員配置進(jìn)行日志同步。
Multi Paxos 、Raft 、ZAB 的關(guān)系與區(qū)別
以上這種把共識問題分解為“Leader Election”、“Entity Replication”和“Safety”三個(gè)問題來思考、解決的解題思路,即“Raft 算法”
ZooKeeper 的 ZAB 算法與 Raft 的思路也非常類似,這些算法都被認(rèn)為是 Multi Paxos 的等價(jià)派生實(shí)現(xiàn)。
核心原理都是一樣:
- 通過隨機(jī)超時(shí)來實(shí)現(xiàn)無活鎖的選主過程
- 通過主節(jié)點(diǎn)來發(fā)起寫操作
- 通過心跳來檢測存活性
- 通過Quorum機(jī)制來保證一致性
具體細(xì)節(jié)上可以有差異:
- 是全部節(jié)點(diǎn)都能參與選主,還是部分節(jié)點(diǎn)能參與(ZAB 分為 Leader Follower Observer 只有 Follower 能選 Leader)
- Quorum中是眾生平等還是各自帶有權(quán)重
- 怎樣表示值的方式
Paxos像民主制: 人人平等可提議, 需要反復(fù)協(xié)商, 決策過程復(fù)雜。
代表作:MySQL MGR組復(fù)制,多主模式下多個(gè)節(jié)點(diǎn)都可以寫入(需沖突檢測)。
Raft像獨(dú)裁制: 有明確的負(fù)責(zé)人(班長), 命令執(zhí)行簡單直接, 容易理解和執(zhí)行。
代表作:MongoDB副本集,只有Primary 節(jié)點(diǎn)可以接收寫入請求。
推薦網(wǎng)站
學(xué)習(xí) raft 算法,一定要看的兩個(gè)網(wǎng)站:
往期推薦
本文來自在線網(wǎng)站:seven的菜鳥成長之路,作者:seven,轉(zhuǎn)載請注明原文鏈接:www.seven97.top

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號