
知乎爬蟲之5:爬蟲優化
本文由博主原創,轉載請注明出處
知乎爬蟲系列文章:
github爬蟲項目(源碼)地址(已完成,關注和star在哪~):https://github.com/MatrixSeven/ZhihuSpider
附贈之前爬取的數據一份(mysql): 鏈接:https://github.com/MatrixSeven/ZhihuSpider 只下載不點贊,不star,差評差評~藍瘦香菇)
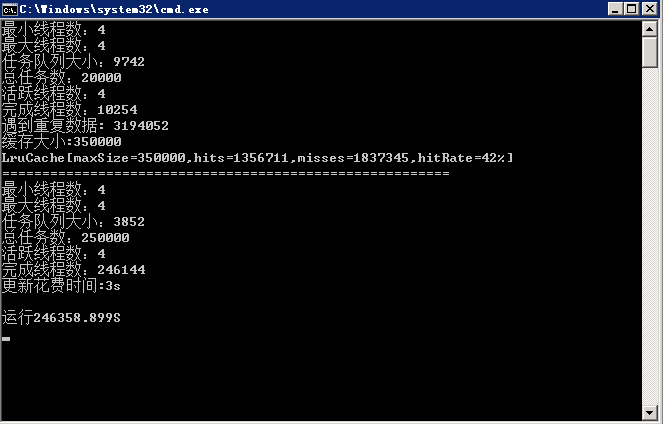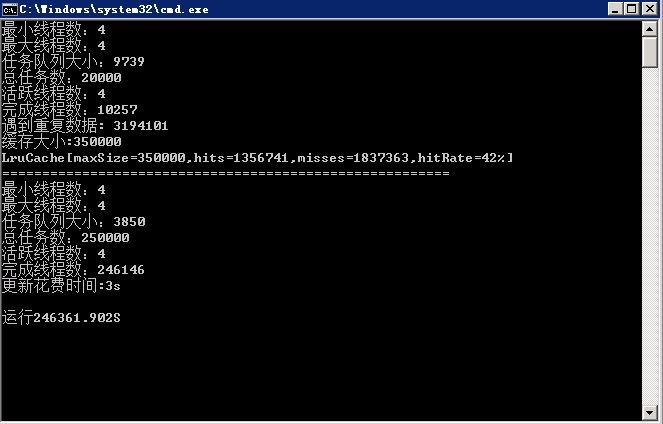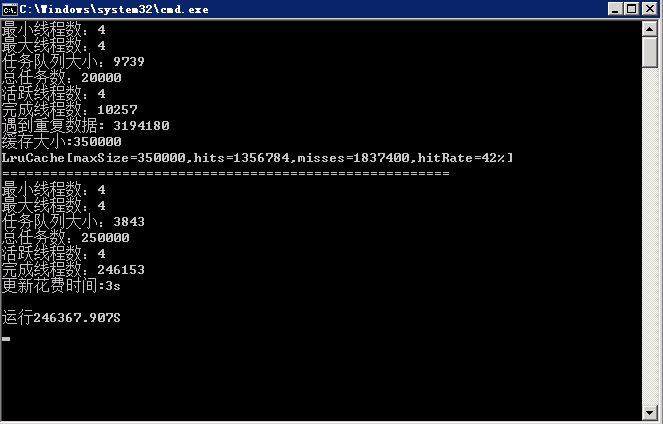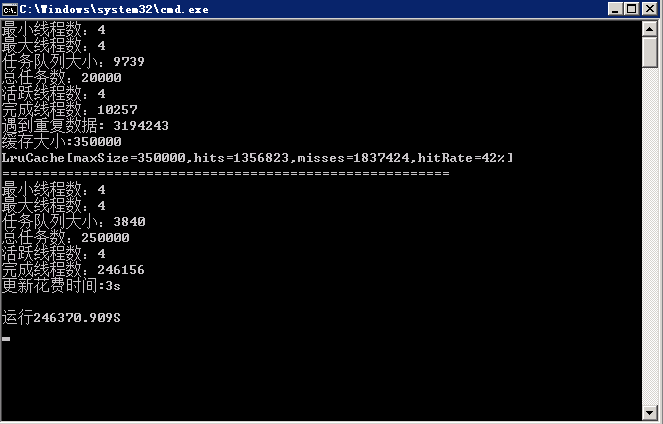
1. 使用多線程加速
什么,爬蟲爬起來數據太慢了,怎么辦?你那當然是開啟多線程了。那么多線程是什么我就不介紹了。如果還不知道的,請左移多線程百度百科。
恩,知道了多線程,但是多線程如果自己控制的話,會很不好控制,所以咱們還需要兩個線程池,一個負責拿到個人信息,一個負責獲取用戶的token。接下來讓咱們之前寫的ParserBase類實現Runnable,然后在ParserFollower里和ParserUserInfo里分別實現run方法,其實也很簡單了,就是把之前的爬去邏輯,丟到run方法里。然后咱們就開啟了多線程之旅。
但是在存取數據的時候會遇到很多問題,比如數據會重復,這就出現了臟數據,那么咱們就是適當的加鎖。來保證數據的干凈。
2. 使用隊列減少數據庫訪問
如果說數據重復的問題解決的,那么咱們還有一個大問題,因為兩次爬到的可能是同一個人,但是一份在數據庫里,一份在正在跑的內存里,怎么辦,當然是要連接下數據庫,然后判斷是數據是否已經在數據庫中存在了,那么在多線程且獲取速度很快的情況下,那么將會頻繁訪問數據庫,造成速度緩慢,數據庫鏈接數過多,cpu使用率過大,那咱們怎么除處理這個問題呢?
首先大家都一定知道,在現在內存非常大的今天,咱們完全可以把一部分數據直接緩存下載,而且程序訪問內存的代價要比訪問數據庫的代價要小的太多。
因此,咱們可以用一個list把咱們已經有的token存下來,然后每次去這個list里去做驗證,這樣,就減少了數據庫的訪問了頻率。
3. 實現LRU提高緩存命中率
如上所說,用一個list的確是起到了減少數據庫訪問的目的,但是效果好像不如想象那么好,因為數據庫里100k的數據,咱們不可能把所有數據都緩存下載,那么怎么才能在優化下呢?
這時候就要合理的處理這個list了,自己實現一個LRU緩存,來調高命中率。
那么lru是什么?y一句話LRU是Least Recently Used 近期最少使用算法,也叫淘汰算法。
具體實現和思想可見緩存淘汰算法–LRU算法。
按照這個思想,其實還有個優化,那就是根據碰撞次數和上次碰撞時間進行移除。咱們只是實現簡單的,具體實現在MatrixSeven/ZhihuSpider
========關于獲取頁面數據=======
咱們上一篇分析了知乎的登陸請求和如何拿到粉絲/關注的請求,那么咱們這篇就來研究下如何拿利用Jsoup到咱們想要的數據。
那么咱們說下,首先請求關注者和粉絲者是pcweb版本的,但是獲取頁面的是手機頁面的。
好,正題:
1.什么是Jsoup
jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作數據。
2. HttpClient請求模擬
HttpClient 是 Apache Jakarta Common 下的子項目,可以用來提供高效的、最新的、功能豐富的支持 HTTP 協議的客戶端編程工具包,并且它支持 HTTP 協議最新的版本和建議。
3.走起頁面
首先模擬手機瀏覽器的UA。就是讓咱們打開的頁面返回的是移動端的頁面效果,那么最應該怎么怎么做呢?其實服務器判定你是ie還是chrome還是firefox是根據請求頭里面的UA實現的,因此咱們要找一個手機瀏覽器的UA。。
咱們可以某度一下或者直接在瀏覽器里面直接f12,模擬移動端,然后看請求參數:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
妥妥的沒問題:
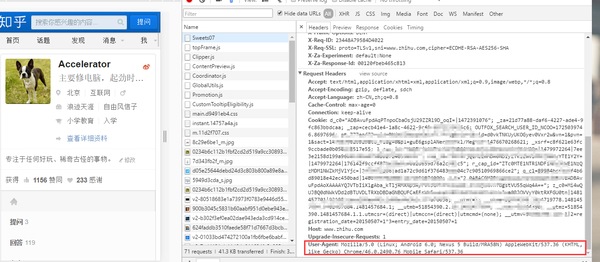
那咱們如何將這句體現到程序里面呢?
簡單,在咱們拿到get對象后直接設置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就ok了,然后咱們就可以用jsoup來拿咱們想要的元素了,jsoup的語法和jq如出一轍。
咱們直接對著頁面,右擊咱們想要的元素,選擇審查元素,然后用jq的選擇器選出來就好了。
可以參考jQuery 選擇器
4.拿到關注者
直接get咱們之前分析的請求地址
https://www.zhihu.com/api/v4/members/Sweets07/followers?per_page=10&
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
不過要記得替換用戶名字和在請求頭里加入cookie的最后一段zc_0
然后請求數據返回的是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/members/Sweets07/followers?per_page=10&include=data%5B%2A%5D.answer_count%2Carticles_count%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=10&offset=20",
"previous": "https://www.zhihu.com/api/v4/members/Sweets07/followers?per_page=10&include=data%5B%2A%5D.answer_count%2Carticles_count%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=10&offset=0",
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陳曉峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式數據庫,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
這個數據包括了下次請求地址,上次請求地址,時候是開始,時候是結束,共有多少粉絲,關注人基本信息,
因此咱們可以在一個while里來獲得所有粉絲數:
流程:
- 第一次獲取數據
- 獲取is_end字段
- 判斷is_end時候為true
- 根據is_end判斷是否繼續循環
- 如果循環,更新is_end,更新下次請求連接
一套下來,就能拿到一個用戶的所有粉絲了。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號