
速看!用 Apache SeaTunnel 輕松實現數據到 S3 Tables 的快速集成
業務技術背景
在當今數字化轉型浪潮下,企業正面臨著海量數據的爆炸式增長,尤其在構建數據湖業務、BI分析以及AI/ML數據準備等關鍵場景中,需要高效、可擴展的大規模大數據存儲解決方案。這些場景往往要求數據存儲系統不僅能處理PB級甚至EB級的數據規模,還必須支持事務性操作,以確保數據一致性、原子性和隔離性,從而避免數據混亂或丟失的風險。
正因如此,Apache Iceberg作為一種先進的開源數據湖格式,應運而生并迅速崛起。它提供了可靠的元數據管理、快照隔離和模式演化功能,被眾多科技巨頭如Netflix、Apple和Adobe廣泛采納,已然確立了在數據湖領域的領導地位。根據行業報告,Iceberg的采用率在過去幾年內持續攀升,成為構建現代數據基礎設施的首選標準。
盡管Iceberg本身強大,但企業在實際部署中往往面臨運維復雜性、擴展管理和資源開銷的挑戰,這就需要托管解決方案來簡化操作。 亞馬遜云科技在2024年re:Invent推出的S3 Tables特性,進一步強化了Iceberg的托管能力。這一創新功能允許用戶直接在Amazon S3上構建和管理Iceberg表,可以將Iceberg表直接構建和管理在云存儲上,無需額外的基礎設施投資,從而顯著降低運維成本和復雜度,同時充分利用云平臺的全球可用性、耐久性和無限擴展性,提升數據處理的彈性和性能。這種托管方式特別適用于需要高可用性和無縫集成的場景,為企業提供云原生數據湖體驗,確保數據湖在高并發讀寫下的穩定性。
在眾多業務場景中,數據同步尤其是CDC(Change Data Capture)扮演關鍵角色,它支持實時捕獲源數據庫的變化并同步到目標系統,如數據湖或倉庫。實時數據同步適用于對時效性要求高的場景,例如金融交易平臺的欺詐檢測、零售庫存實時更新或醫療系統的患者記錄即時共享,確保決策基于最新數據;而離線(或批量)數據同步則更適合非實時需求,如日常備份、歷史數據歸檔或定時報表生成,避免資源浪費并處理大批量數據。
通過這些同步機制,企業能高效實現CDC數據攝入和批量同步,滿足從實時分析到離線處理的多樣化需求。
本文將介紹如何使用 Apache SeaTunnel ,一個高性能、分布式的大規模數據集成工具,通過兼容 Iceberg rest catalog 的實現對接 S3 Tables 實現實時和批量數據集成。
架構及核心組件
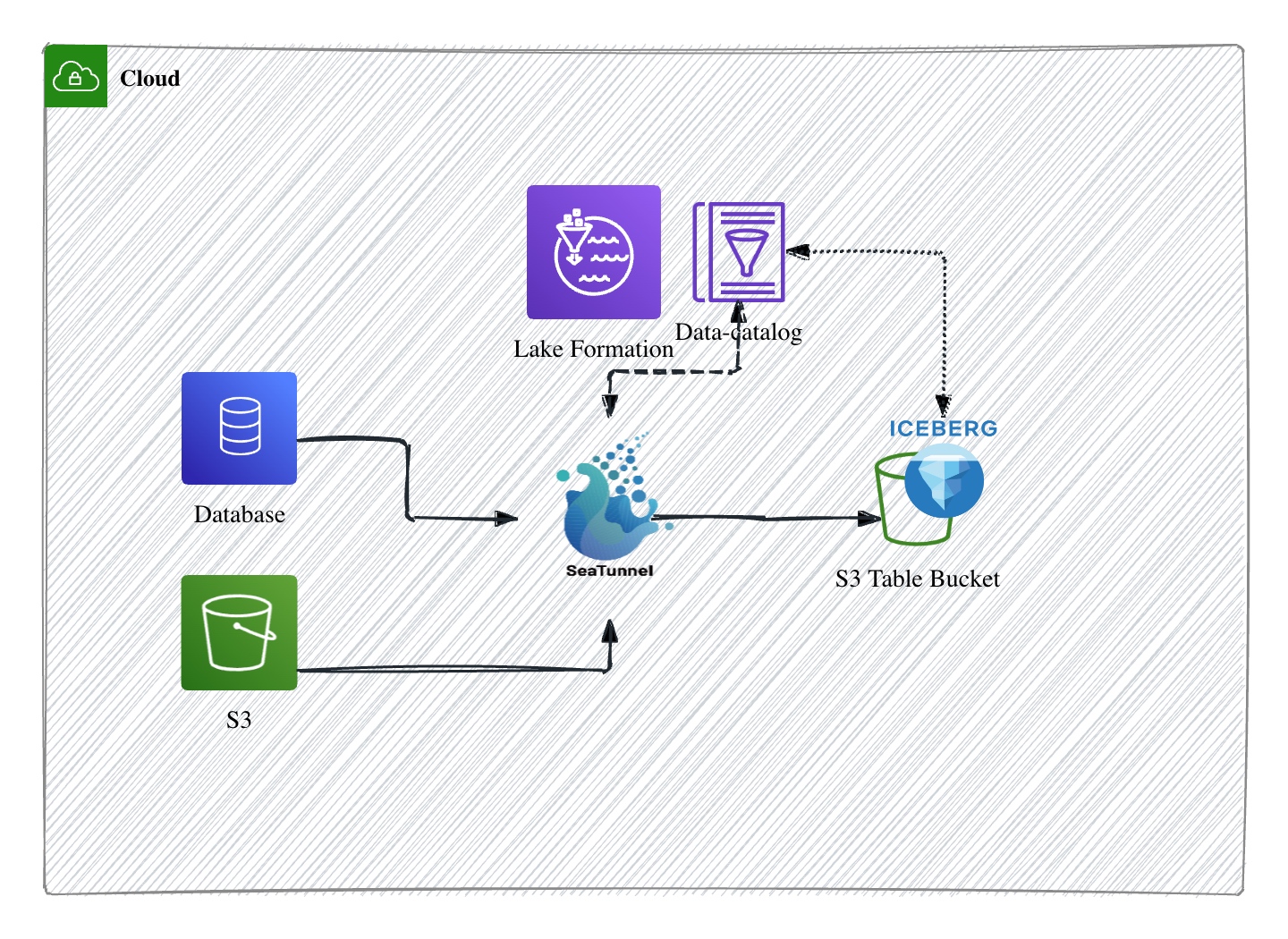
- 通過SeaTunnel 支持 Iceberg REST Catalog 對接,SeaTunnel 原生實現對 Apache Iceberg REST Catalog 的接入能力。Iceberg 的 REST Catalog 允許以標準化接口對元數據進行讀寫和管理,極大簡化了客戶端與 Catalog 交互的復雜度。
通過對 REST Catalog 的兼容,SeaTunnel 可以直接、無縫地將作業產出的表元數據同步注冊到 Iceberg Catalog, 而無需研發自定義插件或手動維護元數據同步流程。這為數據湖的自動化運維和架構解耦創造了技術基礎。 - 云原生數據湖能力:S3 Tables + REST Endpoint ,隨著 S3 Tables的發布,S3 Tables 內置提供了 Iceberg REST Catalog Endpoint。SeaTunnel 能夠直接對接S3 Tables,無需額外改造,即可將批量或流式數據流動寫入到 S3 上的 Iceberg 表,并通過 S3 Tables 的 REST Endpoint 管理元數據和表結構。
這種原生對接極大降低了云上數據湖落地和擴展成本,實現了云原生、Serverless 的數據湖架構,管理和查詢端都變得標準化、敏捷和易于演化。 - 數據與 Catalog 的流轉閉環,高效支持 CDC 及全量離線同步,如圖所示,數據同步鏈路基于 SeaTunnel 完成整合:無論是數據庫(如OLTP/OLAP)、S3 離線分區還是流式變更(CDC 數據),都先統一接入 SeaTunnel,通過 SeaTunnel Sink 能力實時或批量寫入 S3 Table Bucket。與此同時,Iceberg 表的元數據通過 REST Catalog 即時注冊到 Data Catalog 服務(如 Lake Formation),實現業務表、元數據、訪問權限等一站式協同。
CDC 實時場景下,數據庫的變更可以低延遲同步,保證數據的鮮活性;而在批量同步或歷史歸檔場景,也能穩定高效地將數據注入 S3 Table,并由統一 Catalog 發現和管理,適配數據湖/數據倉庫混合查詢模式。
綜上,該架構的核心創新在于,SeaTunnel 通過 Iceberg REST Catalog 標準化了數據與元數據的流轉方式,AWS S3 Tables 的 REST Endpoint 實現云原生、托管化部署,而 CDC 與離線數據同步能力讓大規模數據湖具備了高效、靈活、實時的一站式數據流通機制。
數據集成演示
- 離線數據集成
- 以SeaTunnel 提供的fake 數據源測試批量數據寫入 S3 Tables,首先編輯 SeaTunnel任務配置文件,Sink 配置為 Iceberg 連接器的 rest catalog,認證方式選擇aws ,配置 rest uri 及 warehouse為 S3 Tables 的 endpoint 。如下示例:
env {
parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
parallelism = 1
result_table_name = "fake"
row.num = 100
schema = {
fields {
id = "int"
name = "string"
age = "int"
email = "string"
}
}
}
}
sink {
Iceberg {
catalog_name = "s3_tables_catalog"
namespace = "s3_tables_catalog"
table = "user_data"
iceberg.catalog.config = {
type: "rest"
warehouse: "arn:aws:s3tables:<Region>:<accountID>:bucket/<bucketname>"
uri: "https://s3tables.<Region>.amazonaws.com/iceberg"
rest.sigv4-enabled: "true"
rest.signing-name: "s3tables"
rest.signing-region: "<Region>"
}
}
}
- 啟動SeaTunnel 任務
# 以 local model 測試
./bin/seatunnel.sh --config batch.conf -m local
- 查看任務運行日志

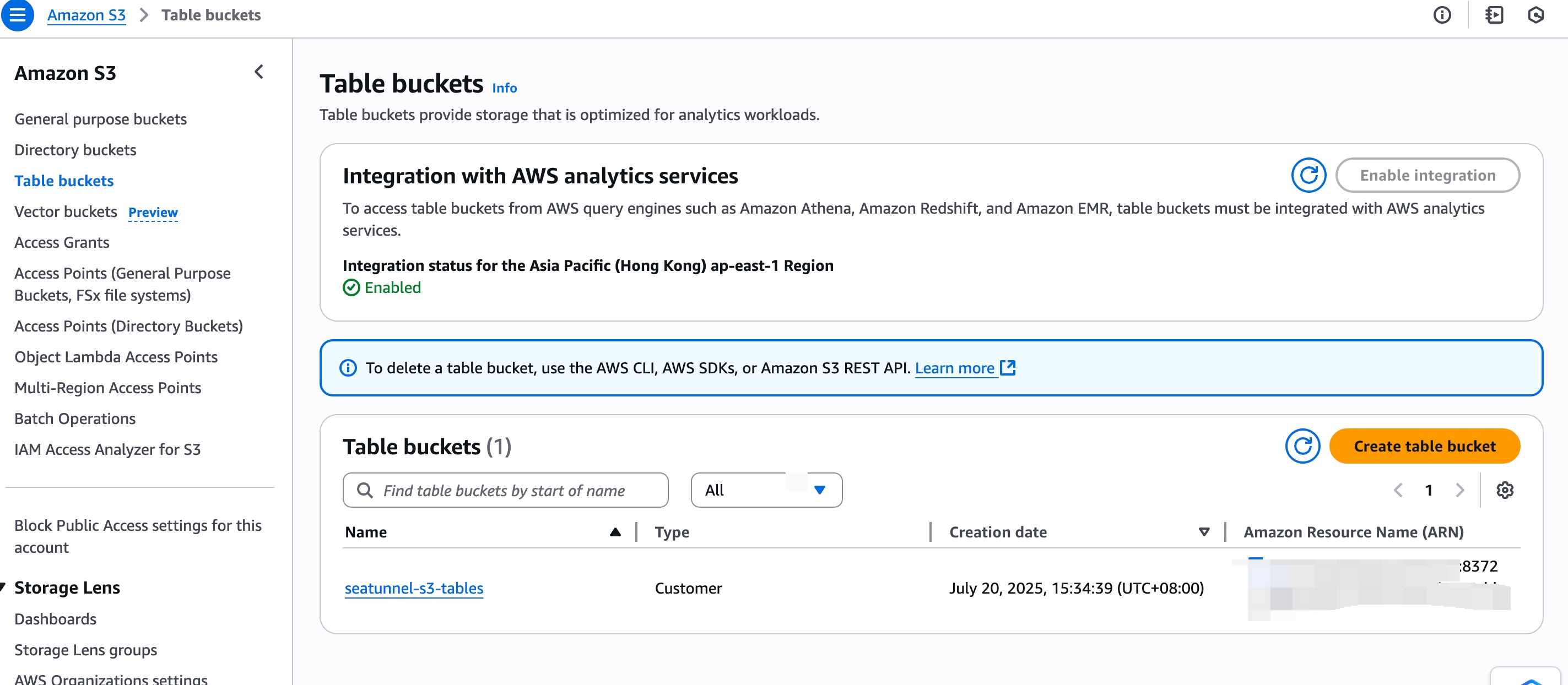
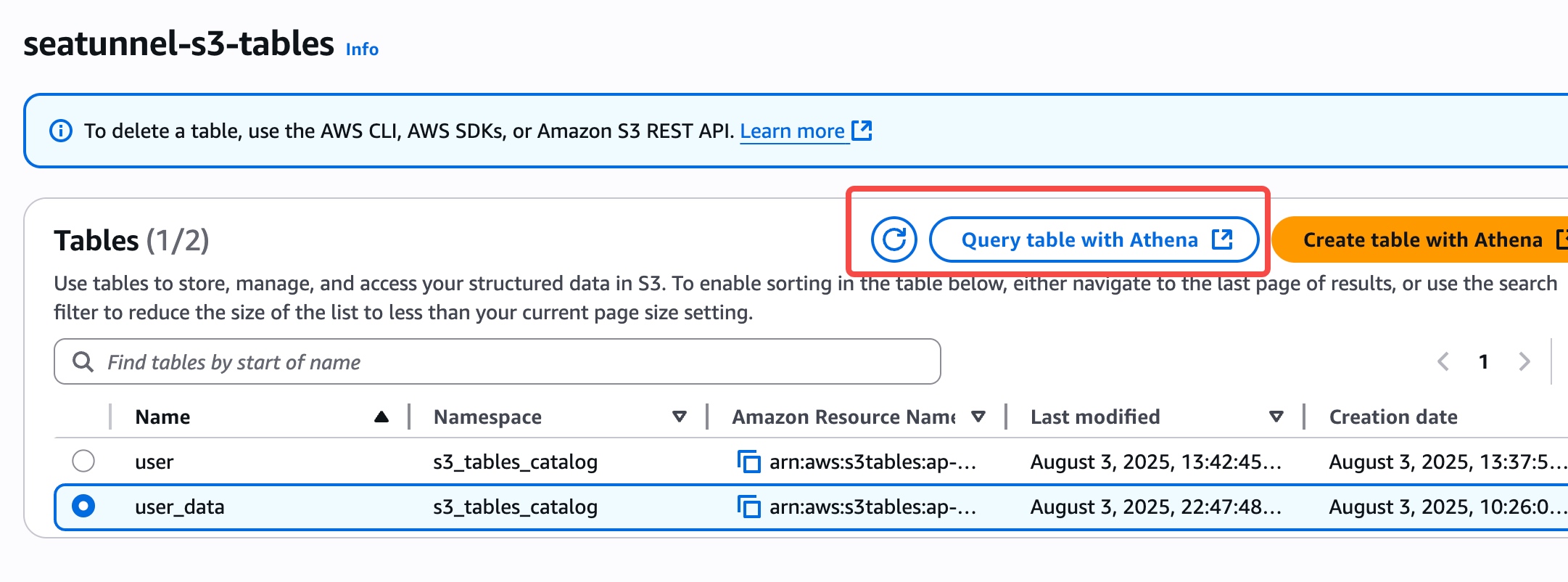
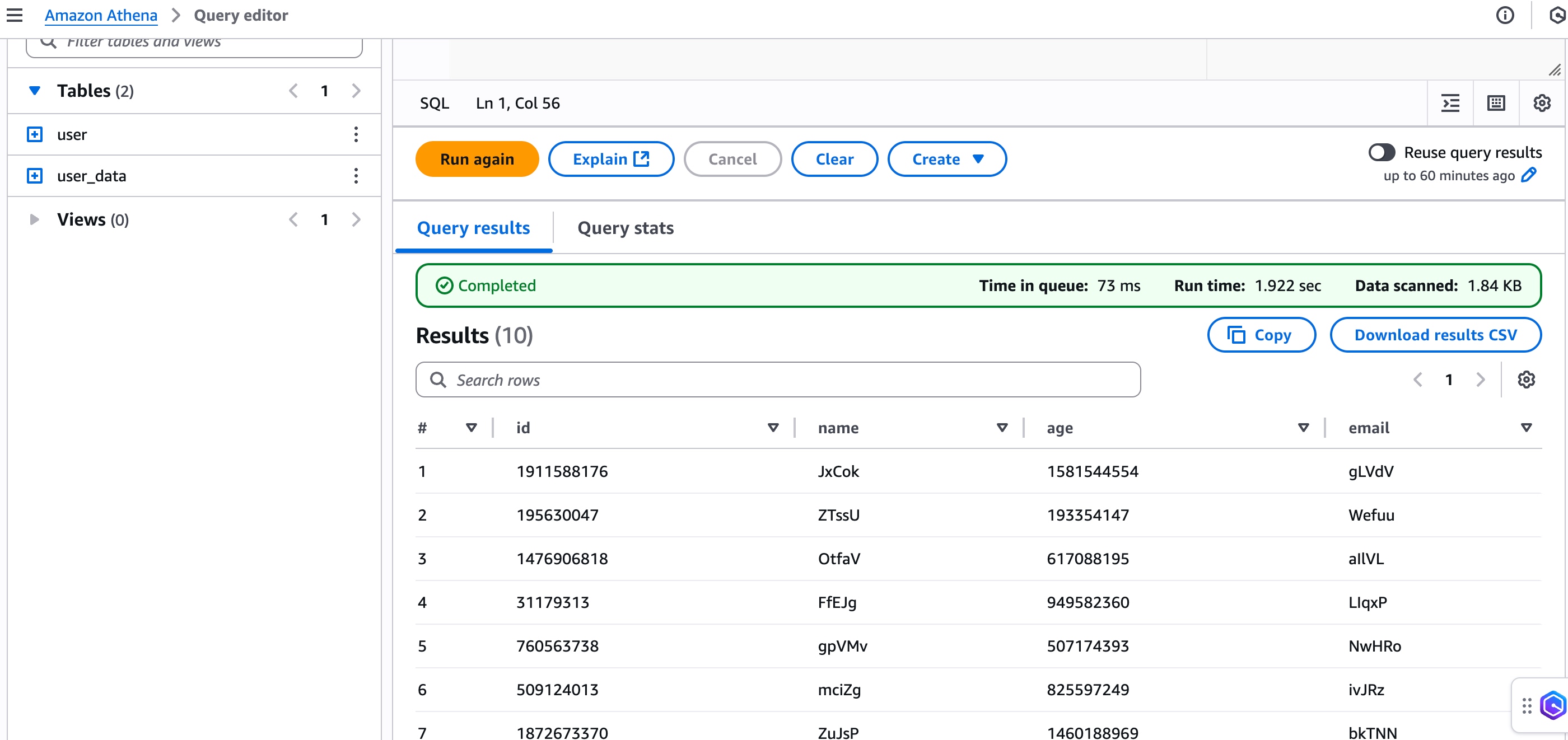
- 在 S3 Tables bucket 查看表,在 Athena 進行數據查詢
- 實時 CDC 數據集成
- 以MySQL cdc 數據源測試流式量數據寫入 S3 Tables,首先編輯 SeaTunnel任務配置文件,Sink 配置為 Iceberg 連接器的 rest catalog,認證方式選擇aws ,配置 rest uri 及 warehouse為 S3 Tables 的 endpoint 。如下示例:
env {
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 5000
}
source {
MySQL-CDC {
parallelism = 1
result_table_name = "users"
server-id = 1234
hostname = "database-1.{your_RDS}.ap-east-1.rds.amazonaws.com"
port = 3306
username = ""
password = ""
database-names = ["test_st"]
table-names = ["test_st.users"]
base-url = "jdbc:mysql://database-1.{your_RDS}.ap-east-1.rds.amazonaws.com:3306/test_st"
startup.mode = "initial" # 可選:initial/earliest/latest/specific
}
}
sink {
Iceberg {
catalog_name = "s3_tables_catalog"
namespace = "s3_tables_catalog"
table = "user_data"
iceberg.catalog.config = {
type: "rest"
warehouse: "arn:aws:s3tables:<Region>:<accountID>:bucket/<bucketname>"
uri: "https://s3tables.<Region>.amazonaws.com/iceberg"
rest.sigv4-enabled: "true"
rest.signing-name: "s3tables"
rest.signing-region: "<Region>"
}
}
}
~
- 啟動SeaTunnel 任務
# 以 local model 測試
./bin/seatunnel.sh --config streaming.conf -m local
-
查看任務運行日志,可以看到 cdc 完成一次快照拉取數據后在監聽數據并進行數據攝入
![]()
-
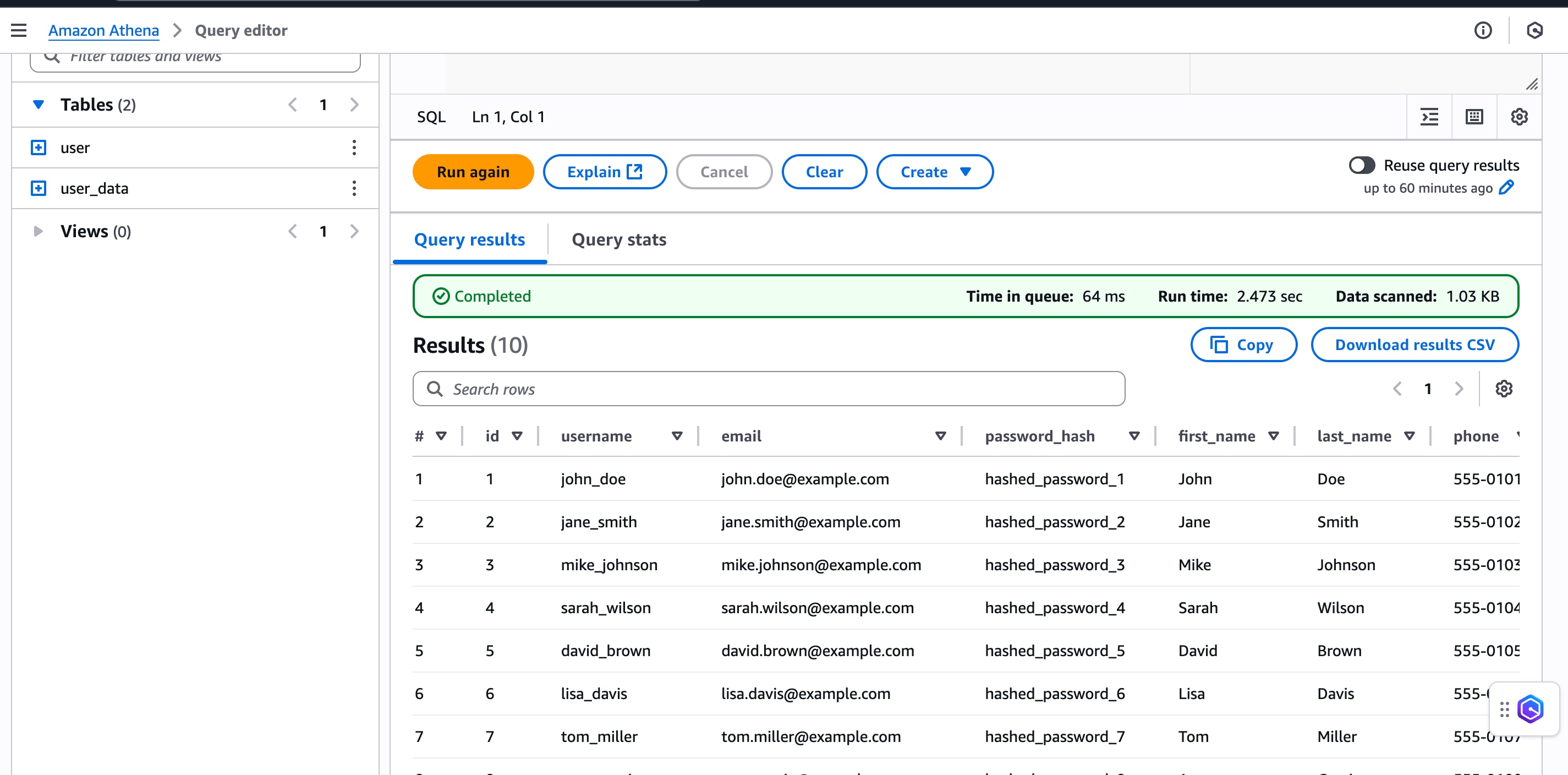
同樣可以在 Athena 查看數據
![]()

總結展望
隨著Apache SeaTunnel對Iceberg和AWS S3 Tables的深度集成,企業數據湖架構將迎來更廣闊的應用前景。
未來,在數據湖構建過程中,生產環境可以引入SeaTunnel的監控措施,如集成Prometheus和Grafana進行實時指標監控(包括任務執行狀態、數據吞吐率和錯誤日志),確保及時發現并響應潛在問題。
同時,通過Kubernetes或Docker Swarm的彈性部署策略,實現SeaTunnel作業的自動縮放和故障轉移,支持動態資源分配(如基于負載的Pod擴展),從而保證數據ETL流程的穩定性和高可用性。這不僅能減少手動干預,還能應對突發數據峰值,維持生產級別的可靠運行。
此外,結合AWS的高級功能如Athena查詢引擎或Glue Crawler的自動化發現,企業可以進一步優化Iceberg表的查詢性能,例如啟用S3的智能分層存儲來降低成本,或集成Lake Formation的安全治理來強化數據訪問控制。這些優化將使數據湖在BI分析和AI/ML準備中更具彈性,支持PB級數據的低延遲查詢和模型訓練。
前述特定亞馬遜云科技生成式人工智能相關的服務目前在亞馬遜云科技海外區域可用。亞馬遜云科技中國區域相關云服務由西云數據和光環新網運營,具體信息以中國區域官網為準。
作者

張鑫,亞馬遜云科技解決方案架構師,負責基于亞馬遜云科技的解決方案咨詢和架構設計,在軟件系統架構、數倉和實時及離線計算領域有豐富的研發和架構經驗。致力于結合數據開源軟件與亞馬遜云科技云原生服務組件構建高可用數據架構的實踐探索。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號