
Apache SeaTunnel 新定位!邁向多模態數據集成的統一工具
在人工智能時代,數據不再是簡單的數字和表格那么簡單了。
你可能處理的是一張用戶上傳的商品圖片、一段實時語音對話、一條點擊事件日志,甚至是一段視頻中的關鍵幀。這些都屬于“多模態數據”——不同形式、不同結構、但承載著豐富語義的數據。
SeaTunnel,一個源自 Apache 的開源項目,最初只專注于結構化數據庫之間的數據同步。但如今,它已經脫胎換骨,完成了跨越式的產品升級:
從傳統 ETL 工具演化為 “面向 AI 時代的多模態數據集成工具”(Unified Multimodal Data Integration Tool)

這不僅是一個口號,而是架構的革新、插件生態的升級、以及對 AI 場景的深度適配。
本文將帶你了解:SeaTunnel 是如何一步步邁向“多模態”,又是如何賦能今天的 AI 數據體系。
為什么要支持多模態數據?
曾經我們做數據同步,只需要處理訂單表、用戶表、銷售表。
但現在呢?
- 推薦系統需要處理商品圖像、用戶評論、點擊行為。
- 工廠車間的設備監控,不僅采集溫度、電壓,還采集視頻流和圖片元信息。
- 金融風控模型,要融合用戶身份文本、日志軌跡、OCR 提取的合同文字……
這些都屬于多模態場景。結構化、非結構化、流式、向量化數據交織共存,一個統一工具來整合這些數據的需求愈發迫切。
SeaTunnel 的重新定位,就是為了解決這個問題:
無論你是 AI 工程師、數據開發者、架構師,都需要一個能吃下“所有數據形態”的接入工具。
SeaTunnel 的多模態能力從哪里來?
SeaTunnel 本質上是一個“可編排的異構數據流處理引擎”,架構上由三部分組成:
- Source:數據源輸入(Kafka、MySQL、File、WebSocket...)
- Transform:中間處理(字段映射、格式清洗、分支處理...)
- Sink:輸出目標(ClickHouse、Milvus、Kafka、對象存儲...)
我們來一個個拆開看。
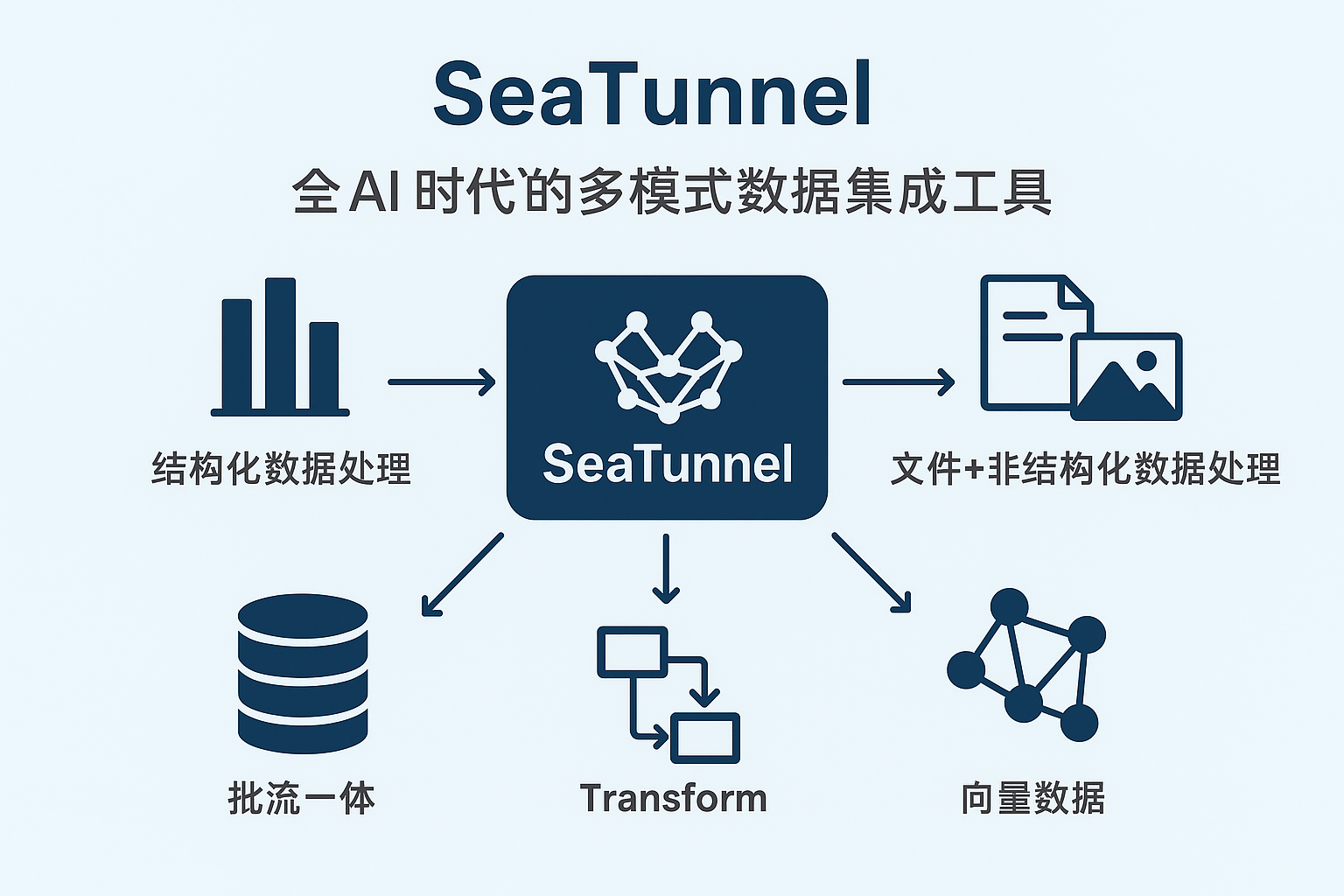
一、結構化數據?那是 SeaTunnel 的老本行
從最早的 MySQL 到如今支持超過 100 種數據源,SeaTunnel 對結構化數據的支持已經不再是問題:
- JDBC 通用支持(MySQL / PostgreSQL / Oracle / SQL Server / DB2)
- 批量和增量同步
- 支持主鍵合并、分區抽取、斷點續傳
- 支持 Iceberg / Hudi / Delta Lake 等湖格式
如果你的場景仍然是“表到表”,SeaTunnel 不輸任何一款傳統 ETL 工具。
二、文件 + 非結構化:圖像/日志/PDF 的元信息接入
SeaTunnel 支持對以下文件類型的解析:
- 文本文件(CSV、JSON、Log、INI)
- 表格類文件(Excel、Parquet、ORC)
- 二進制文件(圖像、PDF、文檔)
通過 FileSource + binary 模式,你可以輕松獲取:
- 文件名、文件路徑、上傳時間
- 文件大小、修改時間、擴展名(通過外部處理腳本提取)
這些字段雖然看起來“不起眼”,但恰恰是構建圖像搜索、日志分析等系統的元基礎。
SeaTunnel 支持通過插件方式將這些信息結構化成 SeaTunnelRow,供后續使用。
三、實時流?SeaTunnel 本就是流批一體
SeaTunnel 支持完整的流式調度架構:
- Kafka、Pulsar、RocketMQ、RabbitMQ、WebSocket 全支持
- 通過 Hazelcast 做狀態管理,支持 Exactly-Once 和斷點恢復
- 每秒處理百萬級消息不在話下
你可以同時處理 Kafka 中的點擊流、MySQL 中的訂單表、S3 中的商品圖像信息,一起構建向量檢索輸入源。
四、向量數據?SeaTunnel 已原生支持!
SeaTunnel 在 2.3 版本之后,加入了對向量數據庫的原生支持:
- Milvus Sink(支持寫入向量數據,指定維度)
- PGVector Sink(將嵌入向量寫入 PostgreSQL)
- OpenSearch Sink(寫入向量字段)
只需配置:
sink {
Milvus {
url = "http://127.0.0.1:19530"
token = "username:password"
batch_size = 1000
}
}
無需寫 SDK,無需調用 REST 接口,配置即生效。
五、Transform:靈活構建字段級語義處理鏈路
SeaTunnel 提供豐富的 Transform 插件,幫助用戶在結構化數據轉換階段完成字段標準化、內容映射、表達式增強等操作。
當前支持的 Transform 插件包括:
FieldMapper Transform:字段映射與重命名Filter Transform:條件過濾(支持 SQL 表達式)Replace Transform:字符串替換與清洗Split Transform:字段按分隔符切割JsonPath Transform:支持從嵌套 JSON 中提取字段Sql Transform:基于 SeaTunnel SQL 的表達式計算能力
通過這些插件,用戶可以完成復雜字段派生、數據標準化、類型轉換、嵌套結構展開等多種場景需求,是構建 AI 語義底座的重要組成部分。
未來版本中,SeaTunnel 社區正在積極探索更多“可編程 Transform”的插件能力,如:
- 支持與模型推理服務對接的 HTTP 調用變換
- 嵌入式表達式引擎優化
- 更高階的 Map/Reduce 類流式變換語義
這些特性將持續增強 SeaTunnel 在多模態處理中的表現力。
無論是字段清洗還是特征增強,SeaTunnel 的 Transform 插件為 AI 時代的數據預處理鏈路提供了堅實支撐。
多模態鏈路示例:圖像 + 文本 + 行為流 → 向量庫
構建圖文推薦系統,只需要三條鏈路:
商品圖像(S3) → FileSource → 預處理服務(CLIP) → MilvusSink
商品描述(MySQL)→ JDBCSource → 預處理服務(BERT)→ MilvusSink
用戶行為流(Kafka)→ KafkaSource → ClickHouseSink
最終你將得到:
- 圖像向量庫
- 文本向量庫
- 實時行為日志流
你就可以在下游實現:
- 相似圖文推薦
- 用戶向量 + 商品向量召回
- 實時熱點商品識別
全部基于 SeaTunnel 完成。
社區正在推進的下一步:全鏈路 AI 數據底座
SeaTunnel 目前已在 WhaleStudio 可視化工具中支持多模態任務配置。
未來,社區正在推進:
- 多模態數據血緣分析(來源追蹤 / AI鏈路識別)
- 多模態數據質量檢查(字段一致性 / 缺失監測)
- 與 LangChain / RAG 結合的檢索增強任務模板
- 向量庫 + 大模型雙向同步能力(向量更新 / LLM 推理)
你能想象的 AI 數據流,SeaTunnel 社區正在逐一落地。
寫在最后:SeaTunnel,為結構而生,為多模態而進化
SeaTunnel 已不再是傳統 ELT 工具。
它已經蛻變成
- 一個連接數據世界和語義世界的橋梁
- 一個低代碼、插件式、場景豐富的 AI 數據流接入工具
- 一個面向向量時代、支持多模態任務的統一引擎
官網:https://seatunnel.apache.org
GitHub:https://github.com/apache/seatunnel
如果你正在構建 AI 多模態系統,不妨看看 SeaTunnel 是不是你缺失的那塊拼圖。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號