
MySQL 33 我查這么多數據,會不會把數據庫內存打爆?
有這樣一個問題:主機內存只有100G,現在要對一個200G的大表做全表掃描,會不會把數據庫主機的內存用完?想想邏輯備份,也是整庫掃描,因此對大表做全表掃描看起來是沒有問題的,那么這個流程到底是怎樣呢?
全表掃描對server層的影響
假設現在要對一個200G的InnoDB表db1.t執行全表掃描,若要把掃描結果保存在客戶端,會使用命令:
mysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file
由于數據保存在主鍵索引上,所以全表掃描實際是直接掃描主鍵索引。該語句沒有其他判斷條件,所以查到的每一行都可以直接放到結果集,然后返回給客戶端。
那么結果集是存在哪里呢?
實際上服務端并不需要保存一個完整的結果集,取數據和發數據的流程為:
-
獲取一行,寫到net_buffer中,這塊內存的大小由參數net_buffer_length定義,默認16k;
-
重復獲取行,直到net_buffer寫滿,調用網絡接口發出去;
-
如果發送成功,清空net_buffer,然后繼續取下一行并寫入net_buffer;
-
若發送函數返回EAGAIN或WSAEWOULDBLOCK,表示本地網絡棧寫滿,進入等待。直到網絡棧重新可寫,再繼續發送。
流程圖:
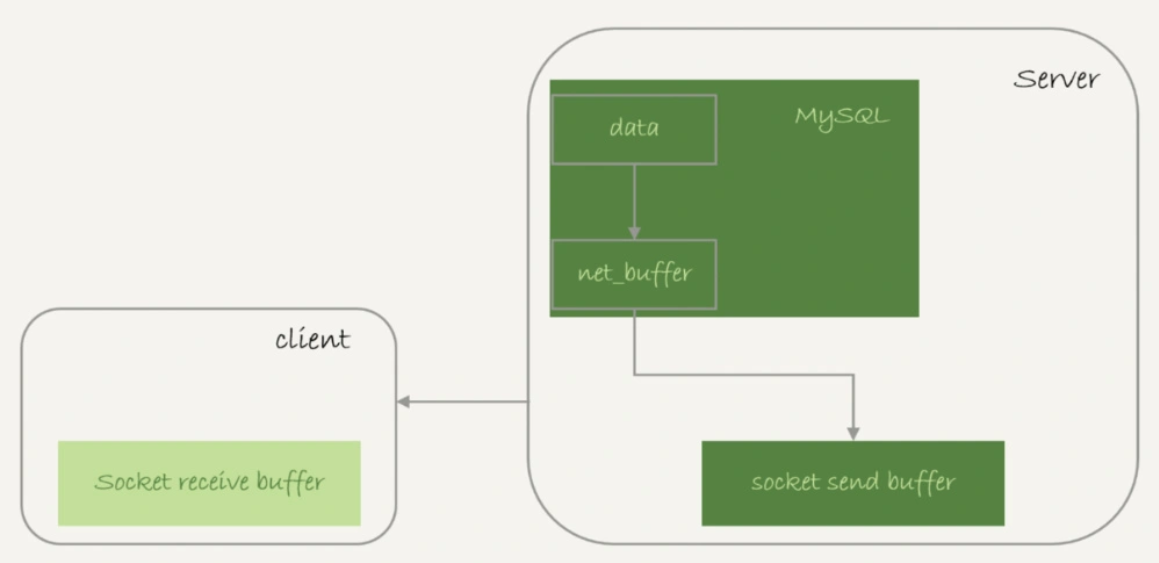
從中可以看到:
-
一個查詢在發送過程中,占用的MySQL內部的內存最大就是net_buffer_length這么大;
-
socket send buffer(大小定義/proc/sys/net/core/wmem_default)如果被寫滿,會暫停讀數據的流程。
即MySQL是邊讀邊發的,如果客戶端接收慢,會導致MySQL發不出去,事務的執行時間變長。此時如果使用show processlist命令:

state若一直處于sending to client,就表示服務器端的網絡棧寫滿了。
上一篇文章曾說到,若客戶端使用-quick參數,會使用mysql_use_result方法,該方法是讀一行處理一行。假設有一個業務的邏輯比較復雜,每讀一行要處理很久,就會導致客戶端過很久才會取下一行數據,就可能出現上圖的情況。
因此,對于正常的線上業務來說,如果一個查詢的返回結果不會很多,建議使用mysql_store_result,直接把查詢結果保存到本地內存。
如果要快速減少處于sending to client狀態的線程數量,將net_buffer_length參數設置為一個更大的值是一個可選方案。
另外有一個看起來像的狀態是sending data,有時候能看到很多查詢語句的狀態是sending data,但查看網絡沒什么問題,這是為什么?
實際上,一個查詢語句的狀態變化為:
-
MySQL查詢語句進入執行階段后,首先把狀態設置為sending data;
-
發送執行結果的列相關的信息給客戶端;
-
繼續執行語句流程;
-
執行完成,把狀態設置成空字符串。
也就是說sending data并不一定指正在發送數據,而可能是處于執行器過程中的任意階段。
那么知道了server層的處理邏輯,在InnoDB引擎里又是怎么處理的呢?
全表掃描對InnoDB的影響
之前介紹WAL機制時,分析了InnoDB內存的一個作用是保存更新結果,再配合redo log避免隨機寫盤。內存數據頁是在Buffer Pool中管理,因此在WAL里Buffer Pool起到了加速更新的作用。
實際上,Buffer Pool還有加速查詢的作用。由于有WAL機制,當事務提交時,磁盤上的數據頁是舊的,此時如果馬上有一個查詢要來讀這個數據頁,其并不需要讀磁盤,而是直接讀內存頁。而Buffer Pool對查詢的加速效果,依賴于一個重要的指標:內存命中率。
可以執行show engine innodb status命令,結果中的Buffer Pool hit rate,就表示當前的命中率。一般情況下,一個穩定的線上系統,要保證響應時間符合要求的話,內存命中率要在99%以上。若所有查詢需要的數據頁都能直接從內存得到,那命中率就是100%,但這在實際生產中很難做到。
Buffer Pool的大小由參數innodb_buffer_pool_size確定,一般建議設置成可用物理內存的60%-80%。如果一個Buffer Pool滿,而又要從磁盤讀入一個數據頁,就肯定要淘汰一個舊數據頁,InnoDB使用的是LRU算法,淘汰最久未使用的數據。
如果是平時我們理解的LRU,要全表掃描的話,會有些問題。比如要掃描一個200G大小,平時沒有業務訪問的歷史數據表。若按基礎的LRU,會把當前的Buffer Pool里的數據全部淘汰,存入掃描過程中訪問到的數據頁內容,即Buffer Pool里主要存放歷史數據表數據,那么此時會對其他業務造成很大影響,Buffer Pool的內存命中率將會急劇下降,磁盤壓力增加,SQL語句響應變慢。
因此,InnoDB對LRU算法做了改進。
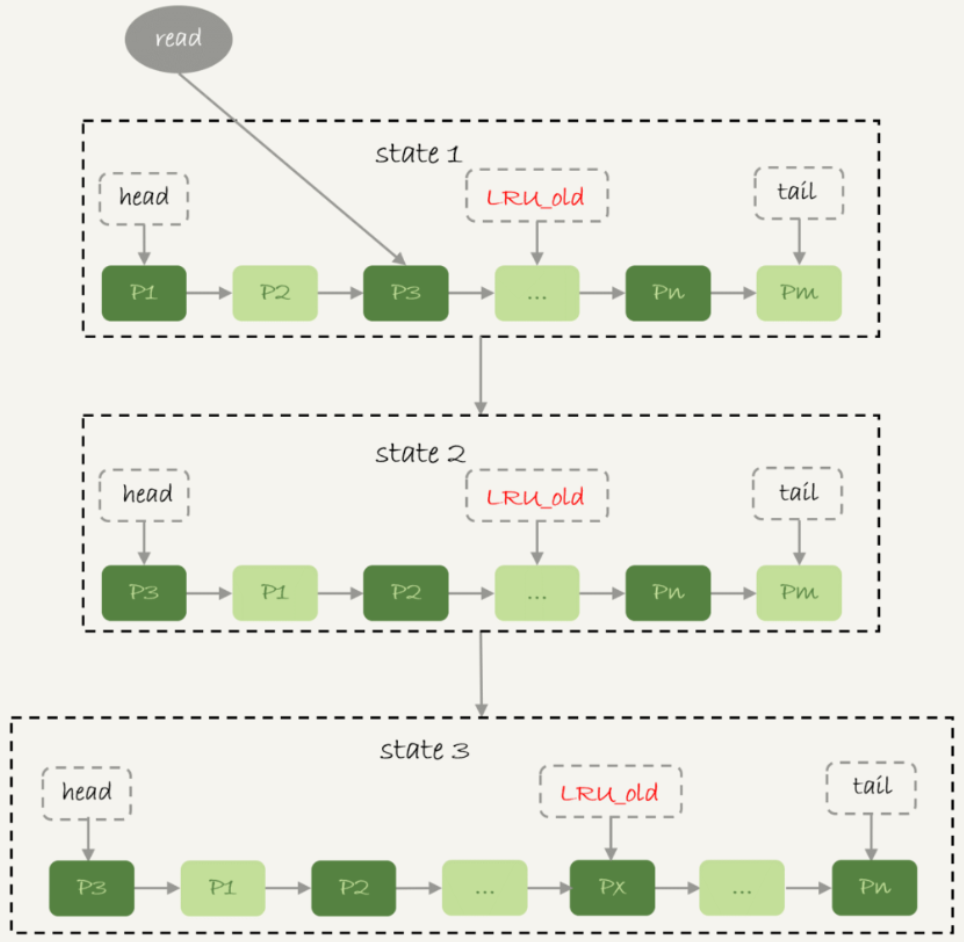
在InnoDB實現上,按照5:3比例將整個LRU鏈表分為young區域和old區域,上圖中LRU_old指向old區域的第一個位置,是整個鏈表的5/8處,即靠近鏈表head的5/8區域為yong區域,靠近鏈表tail的3/8區域是old區域。改進后的LRU算法執行流程為:
-
state 1,要訪問數據頁P3,由于P3在young區域,因此和優化前的LRU算法一樣,將其移到鏈表頭,即state 2;
-
state 3,想要訪問一個新的、不存在于當前鏈表的數據頁,此時會淘汰尾部的數據頁Pm,將新插入的數據頁Px放在LRU_old處。
-
處于old區域的數據頁,每次訪問時需要做如下判斷:
-
若該數據頁在LRU鏈表存在時間超過了1秒,就把它移到鏈表頭;
-
否則該數據頁位置保持不變。“1秒”這個時間由參數innodb_old_blocks_time控制。
-
以上策略就是為了處理類似全表掃描的操作量身定制的。以掃描200G的歷史數據表為例:
-
掃描過程中,需要新插入的數據頁都會放到old區域;
-
一個數據頁有多條記錄,由于順序掃描,這個數據頁第一次被訪問和最后一次被訪問的時間間隔不會超過1秒,因此還是會留在old區域;
-
再繼續掃描后續的數據頁,之前的數據頁由于不會再被訪問到,始終沒有機會移到head,之后很快會從old區域淘汰出去。
可以看到,該策略最大的收益是在掃描大表的過程中,雖然也用到Buffer Pool,但是對young區域完全沒有影響,從而保證Buffer Pool響應正常業務的查詢命中率。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號