
MySQL 19 為什么我只查一行的語句,也執行這么慢?
有些情況下,“查一行”也會執行特別慢,今天就看看什么情況會出現這個現象。
如果MySQL本身有很大壓力,導致數據庫服務器CPU占有率很高或IO利用率很高,這種情況所有語句的執行都可能變慢,不在本文討論范圍內。
為了分析,構建有10萬行記錄的表,建表語句如下:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
第一類:查詢長時間不返回
比如執行語句:
select * from t where id=1;
查詢結果長時間不返回:

一般碰到這種情況,大概率是表t被鎖住。分析的時候,一般會先執行show processlist命令,查看當前語句處于什么狀態,然后再針對每種狀態分析它們產生的原因、如何復現,以及如何處理。
等MDL鎖
使用show processlist命令示意圖如下:

其中Waiting for table metadata lock狀態表示,現在有一個線程正在表t上請求或者持有MDL寫鎖,將select語句堵住了。
比如有可能是如下的情況:

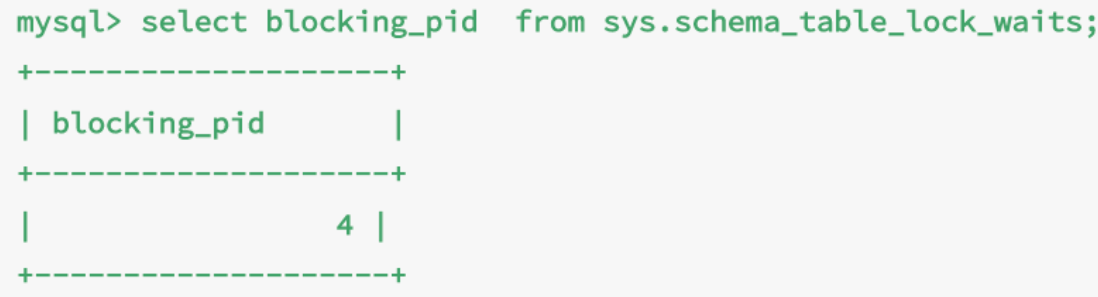
對于這種情況,可以通過查詢sys.schema_table_lock_waits表,直接找出造成阻塞的process id,然后kill這個連接。
等flush
接下來看另外一種情況:

其中Waiting for table flush狀態表示,現在有一個線程正要對表t做flush操作。MySQL里對表做flush操作的用法,一般有以下兩個:
flush tables t with read lock;
flush tables with read lock;
如果指定表t,代表只關閉表t;如果沒有指定具體的表名,則表示關閉MySQL里所有打開的表。
正常情況下,這兩個語句執行起來都很快,除非它們也被別的線程堵住了。
所以出現Waiting for table flush狀態的可能情況是:有一個flush tables命令被別的語句堵住了,然后它又堵住了select語句。可能的情況如下:

在session A中,每行都調用一次sleep(1),這樣對于10萬行的表,該語句默認執行10萬秒,在這期間表t一直被session A“打開”著。然后,session B想要關閉表t就需要等session A查詢結束,而session C會被flush命令堵住。
可以用show processlist查看process狀態,然后手動kill相關process。

等行鎖
由于訪問id=1記錄時要加讀鎖,如果這時候已經有一個事務在這行記錄上持有一個寫鎖,select語句就會被堵住:

session A啟動了事務,占有寫鎖還不提交,導致session B被堵住。
可以通過sys.innodb_lock_waits表查看是誰占著寫鎖:
select * from t sys.innodb_lock_waits where locked_table='`test`.`t`'\G
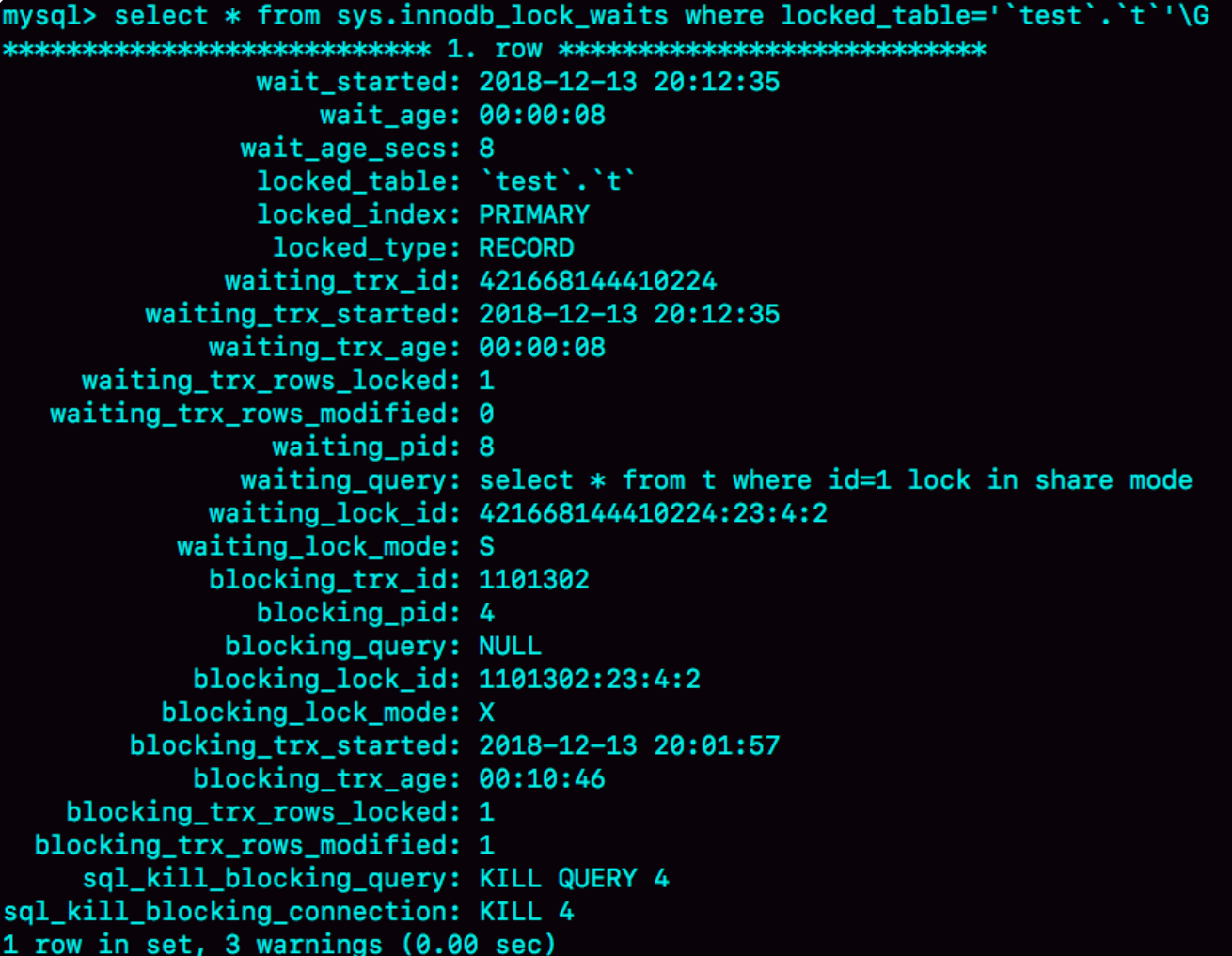
可以看到4號線程造成了堵塞,因此需要kill 4斷開連接。當連接被斷開,會自動回滾該連接里正在執行的流程,也就會釋放id=1上的行鎖。
第二類:查詢慢
看一個只掃描一行,但執行很慢的語句:
select * from t where id=1;
其slow log如下:

可以發現,雖然掃描行數是1,但執行時間卻長達800ms。
繼續看slow log下面的內容,是下一個語句,掃描行數1行,執行時間為0.2ms:

看起來有些奇怪,畢竟lock in share mode還要加鎖,按理說時間會更長。
查看這兩個語句的執行輸出結果:
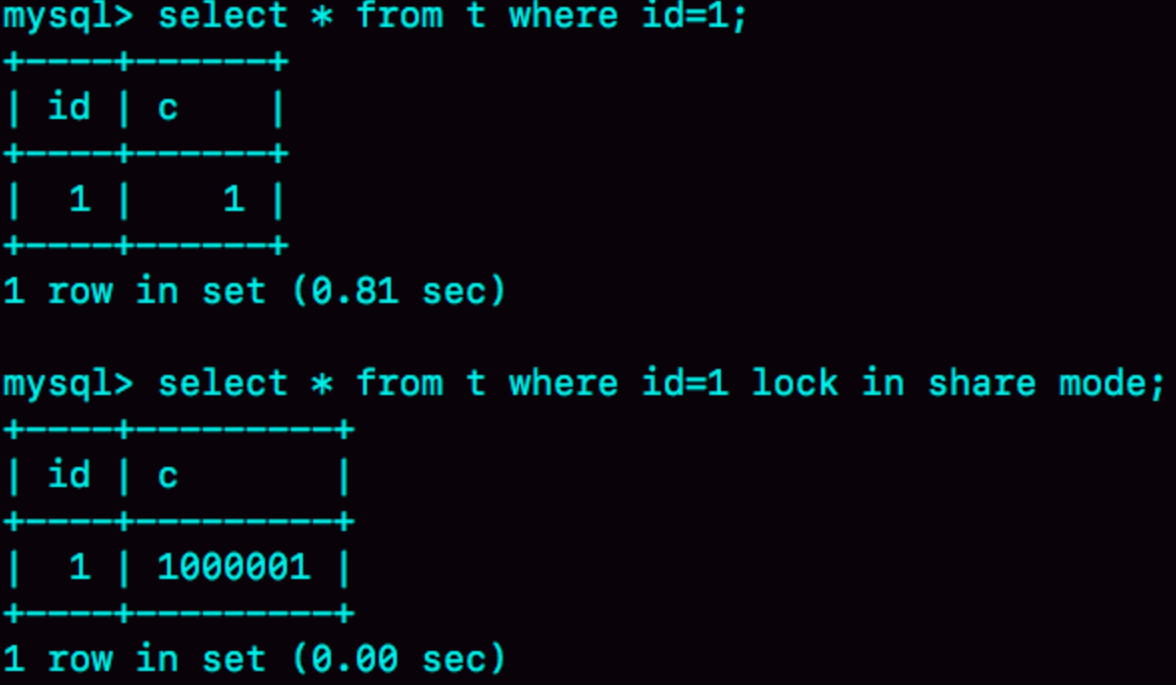
第一個語句查詢結果c=1,第二個語句查詢結果c=1000001,所以里面有對c字段的改變,實際上對應下面這種情況:

session A先啟動了事務,然后session B開始執行update語句。更新完成后,id=1對應的狀態如下:
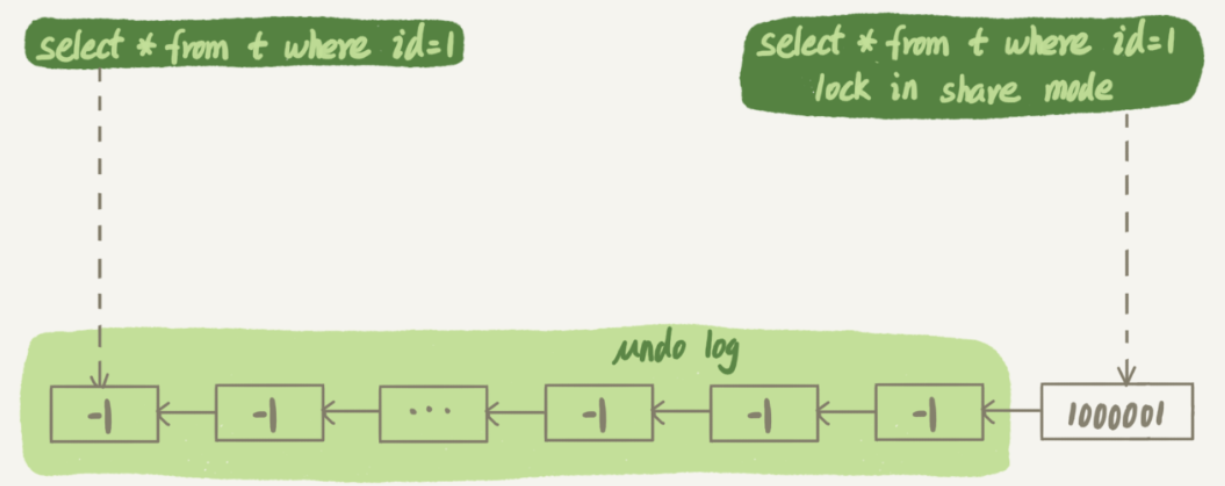
session B更新完,生成了100萬個回滾日志。
第二個查詢語句是當前讀,會直接讀到1000001這個結果,所以速度很快;而第一個查詢語句是一致性讀,需要回滾100萬次得到1這個結果,因此速度很慢。
undo log里記錄的其實是“把 2 改成 1”,“把 3 改成 2”這樣的操作邏輯,畫成減1是方便看圖。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號