
Rust從入門到精通04-數據類型
Rust 是 靜態類型(statically typed)語言,也就是說在編譯時就必須知道所有變量的類型。
在 Rust 中,每一個值都屬于某一個 數據類型(data type),分為兩大類:
①、標量(基本數據類型)(scalar):整型、浮點型、布爾類型、字符類型
②、復合(compound):元祖(tuple)、數組(array)、結構體(struct)
0、靜態類型和動態類型區別
靜態類型和動態類型是編程語言的兩種基本類型系統。如果一門語言不談數據類型,大概率是動態類型。
本質上它們主要的區別在于類型檢查發生的時間和方式。
靜態類型語言:
- 在編譯時期進行類型檢查。這意味著在你的代碼運行之前,編譯器就會檢查數據類型的正確性。如果數據類型不匹配,編譯器將引發錯誤,代碼無法編譯。
- 由于靜態類型語言在編譯時期就完成了類型檢查,因此它們通常具有更好的性能,因為運行時沒有類型檢查的開銷。
- 靜態類型語言通常需要顯式聲明變量的類型。這使得代碼更具可讀性,并且更易于維護和調試,因為類型信息可以幫助開發者理解變量和函數的行為。
- 靜態類型語言的例子包括:Java、C++、C#、Rust 等。
動態類型語言:
- 在運行時期進行類型檢查。這意味著在代碼執行時,解釋器會檢查數據類型的正確性。如果數據類型不匹配,將引發運行時錯誤。
- 動態類型語言在編寫代碼時具有更大的靈活性,因為你不需要顯式聲明變量的類型。這使得代碼更簡潔,但也可能導致類型錯誤更難檢測和調試。
- 動態類型語言的性能通常不如靜態類型語言,因為它們在運行時需要進行類型檢查。
- 動態類型語言的例子包括:Python、Ruby、JavaScript、PHP 等。
1、標量-基本數據類型 scalar
每個類型有一個單獨的值。
1.1 整型
表示沒有小數部分的數字,分為有符號(以 i 開頭)和無符號(以 u 開頭)整型。
數字類型的默認類型是 i32。
| 長度 | 有符號 | 無符號 |
|---|---|---|
| 8-bit | i8 |
u8 |
| 16-bit | i16 |
u16 |
| 32-bit | i32 |
u32 |
| 64-bit | i64 |
u64 |
| 128-bit | i128 |
u128 |
| arch | isize |
usize |
每一個有符號的整型可以儲存包含從 -($2^{n - 1}$) 到 $2^{n - 1}$ - 1 在內的數字,這里 n 是整型定義的長度。所以 i8 可以儲存從 -$2^7$到 $2^7$ - 1 在內的數字,也就是從 -128 到 127。無符號的變體可以儲存從 0 到 $2^{n - 1}$ 的數字,所以 u8 可以儲存從 0 到 $2^8 - 1$ 的數字,也就是從 0 到 255。
另外,isize 和 usize 類型依賴運行程序的計算機架構:64 位架構上它們是 64 位的, 32 位架構上它們是 32 位的。
這里我說下為啥會有這種依賴計算機架構的數據長度,主要有兩點:
①、性能優化:與系統架構直接對應,這意味著它們可以被優化以適應特定平臺的最佳性能。例如,在 64 位系統上,usize 可以高效地處理較大的數據結構,因為它能夠表示的地址空間更大。
②、跨平臺兼容:使用 usize 和 isize 可以讓同一段 Rust 代碼在不同架構的系統上運行而無需修改。這對于編寫庫或框架特別重要,因為這些庫或框架需要在各種硬件和操作系統上工作。
1.1.1 所有數字字面量,可以在任意地方添加下劃線_
①、十進制字面量 12_222,使用下劃線按三位數字一組隔開
②、十六進制字面量 0xff,使用0x開頭
③、八進制字面量 0o66,使用0o(小寫字母o)開頭
④、二進制字面量 0b1111_0000,使用0b開頭,按4位數字一組隔開
⑤、字符的字節表示 b'A',對一個ASCII字符,在其前面加b前綴,直接得到此字符的ASCII碼值
fn int_test(){
//所有數字字面量,可以在任意地方添加下劃線_
let x : u32 = 1_2_3;
let y = x + 1;
//打印結果為 124
println!("{}",y);
}
fn main() {
let i1 = 12_222;
let i2 = 0xff;
let i3 = 0o66;
let i4 = 0b1111_0000;
let i5 = b'A';
// i1=12222;i2=255;i3=54;i4=240;i5=65
println!("i1={};i2={};i3={};i4={};i5={}",i1,i2,i3,i4,i5)
}
1.1.2 字面量可以跟類型后綴,表示數字具體類型
//字面量可以跟類型后綴,表示數字具體類型
fn int_test2(){
let x = 123i32;
let y = x + 1;
//打印結果為 124
println!("{}",y);
}
1.1.3 直接對整型字面量調用函數
//直接對整型字面量調用函數
fn int_test3(){
let x : i32 = 9;
//打印結果為 729
println!("9 power 3 = {}",x.pow(3));
}
1.1.4 整數溢出
Rust 對于整數溢出的處理方式如下:
①、默認情況下,在debug模式下編譯器會自動插入整數溢出檢查,一旦發生溢出,則會引發 panic;
②、在 release 模式下(使用 --release 參數),不檢查整數溢出,而是自動舍棄高位的方式。
要顯式處理可能的溢出,可以使用標準庫針對原始數字類型提供的這些方法:
- 使用
wrapping_*方法在所有模式下都按照補碼循環溢出規則處理,例如wrapping_add - 如果使用
checked_*方法時發生溢出,則返回None值 - 使用
overflowing_*方法返回該值和一個指示是否存在溢出的布爾值 - 使用
saturating_*方法使值達到最小值或最大值
fn main() {
let a : u8 = 255;
let b = a.wrapping_add(20);
println!("{}", b); // 19
}
這里其實也體現了 rust 這門語言的安全性,大家如果有項目開發經驗,對于整數溢出導致的bug,其實是很難排查的,項目沒有任何錯誤日志,但是得到的數據就是不對,往往令人崩潰,而 rust 直接程序 panic,這樣極大的方便我們去排查問題。
1.1.5 如何選擇
通常默認類型 i32 即可,它通常是最快的,性能最好的。
isize 和 usize 的主要應用場景是用作集合的索引。
1.2 浮點
Rust 有兩個原生的 浮點數(floating-point numbers)類型,它們是帶小數點的數字。是基于 IEEE 754-2008 標準的浮點類型,分別是 f32 和 f64,分別占 32 位和 64 位。默認類型是 f64,因為在現代 CPU 中,它與 f32 速度幾乎一樣,不過精度更高。
fn float_test(){
//123.0 f32類型
let f1 = 123.0f32;
//0.1 f64類型
let f2 = 0.1f64;
}
1.2.1 浮點數陷阱
浮點數基本上是近似數表達,因為浮點數是基于二進制實現的。
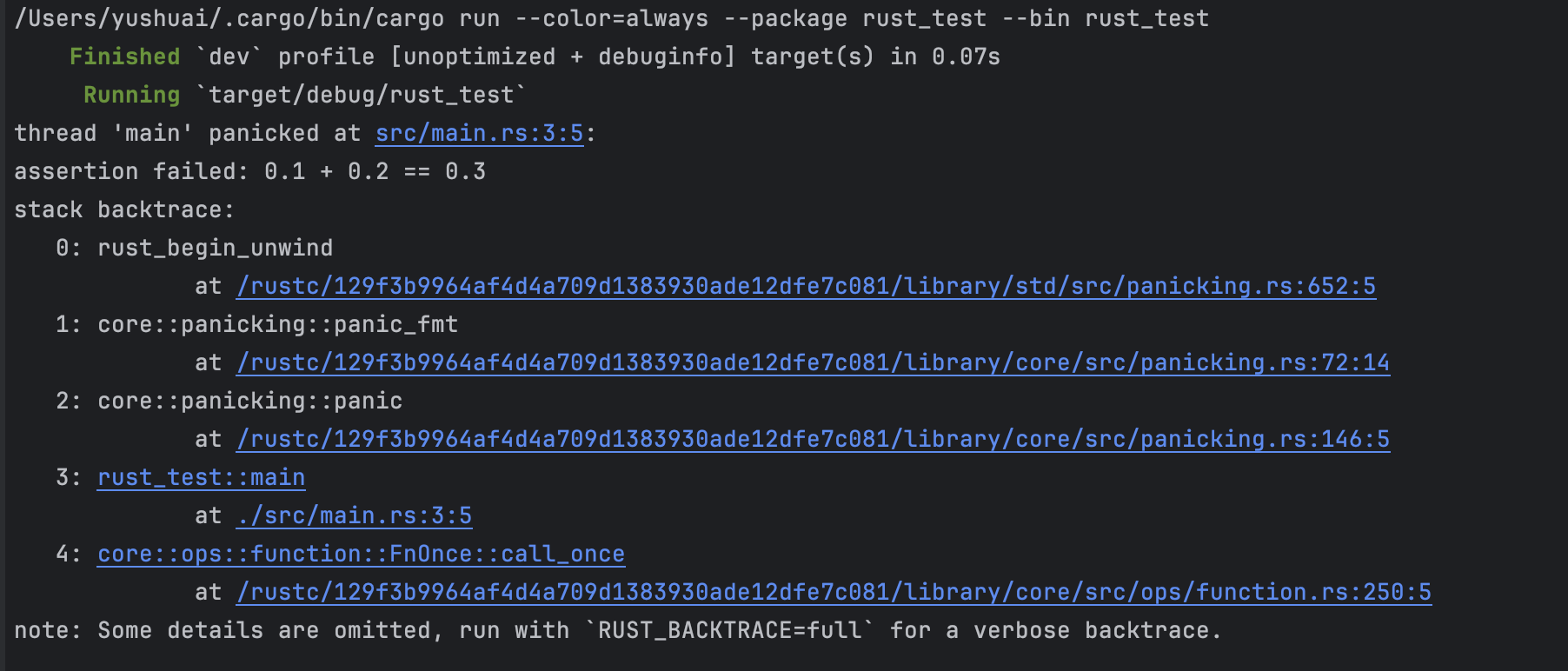
比如對于 0.1 ,在十進制是精確存在的,但是在二進制上并不存在精確的表達形式,所以要避免對浮點數進行相等性測試。
fn main() {
assert!(0.1 + 0.2 == 0.3);
}
運行報錯。因為二進制精度問題,導致了 0.1 + 0.2 并不嚴格等于 0.3,它們可能在小數點 N 位后存在誤差。
如果非要比較,考慮用這種方式 (0.1_f64 + 0.2 - 0.3).abs() < 0.00001 ,具體小于多少,取決于你對精度的需求。
1.3 布爾類型
布爾類型(bool)代表的是“是”和“否”的二值邏輯。它有兩個值:
true和false
一般用在邏輯表達式中,可以執行“與”“或”“非”等運算,常用于條件判斷和控制流操作。
布爾值占用內存的大小為 1 個字節
fn bool_test(){
let x = true;
//取反運算
let y = !x;
//邏輯與,帶短路功能
let z = x && y;
//邏輯或,帶短路功能
let z = x || y;
if x {
println!("Rust is awesome!");
}
}
1.4、字符類型
字符類型由 char 表示。它可以描述任何一個符合 unicode 標準的字符值。在代碼中,單個的字符字面量用單引號包圍(不同于字符串用雙引號):
1.4.1 4個字節字符
let heart_eyed_cat = '??';
因為 char 類型的設計目的是描述任意一個 unicode 字符,因此它占據的內存空間不是1個字節,而是 4 個字節。
這意味著它可以比 ASCII 表示更多內容。在 Rust 中,拼音字母(Accented letters),中文、日文、韓文等字符,emoji(繪文字)以及零長度的空白字符都是有效的 char 值。
Unicode 標量值包含從 U+0000 到 U+D7FF 和 U+E000 到 U+10FFFF 在內的值。
1.4.2 1個字節字符-u8
let x : u8 = 1;
對于 ASCII 字符其實只需要占據一個字節的空間,因此Rust 提供了單字節字符字面量來表示 ASCII 字符。
注意:我們還可以通過一個字母 b 在字符或者字符串前面,代表這個字面量存儲在 u8 類型數組中,這樣占用空間比 char 型數組要小一些。
let x : u8 = 1; let y : u8 = b'A';
1.5 序列(Range)
Rust 提供了一個非常簡潔的方式,用來生成連續的數值,例如 1..5,生成從 1 到 4 的連續數字,不包含 5 ;1..=5,生成從 1 到 5 的連續數字,包含 5,它的用途很簡單,常常用于循環中:
for i in 1..=5 {
println!("{}",i);
}
//打印結果
1
2
3
4
5
序列只允許用于數字或字符類型,原因是:它們可以連續,同時編譯器在編譯期可以檢查該序列是否為空,字符和數字值是 Rust 中僅有的可以用于判斷是否為空的類型。如下是一個使用字符類型序列的例子:
for i in 'a'..='z' {
println!("{}",i);
}
2、復合compound
復合類型(Compound types)可以將多個值組合成一個類型
2.1 元祖(tuple)
①、由圓括號()包含一組表達式組成;
②、長度固定,一旦聲明,其長度不會增大或縮小。
③、rust中可以存放不同類型的數據類型
2.1.2 實例
fn tuple_test1(){
//包含兩個元素:1和false
let a = (1i32,false);
//包含兩個元素:1和元祖,元祖包含兩個字符1和2
let b = (1,("1","2"));
}
2.1.3 如果元祖只有一個元素,應該添加一個逗號,用來區分括號表達式和元祖
//如果元祖只有一個元素,應該添加一個逗號,用來區分括號表達式和元祖
fn tuple_test2(){
//a 是一個元祖,只有一個元素1
let a = (1,);
//b 是一個括號表達式,它是 i32類型
let b = (1);
}
2.1.4 訪問元祖元素
①、模式匹配解構
//元祖:模式匹配
fn tup_test4(){
let tup = (1,1.1,2);
let (x,y,z) = tup;
println!("x={},y={},z={}",x,y,z);
}
②、數字索引
//元祖:數字索引
fn tup_test5(){
let tup = (1,1.1,2);
println!("x={},y={},z={}",tup.0,tup.1,tup.2);
}
2.1.5 元祖總結
元祖是長度固定,可以存放不同元素的集合。
通常用作函數的返回值,因為你想把多個不同類型的值一次返回的話,元祖就很有用了。
另外,當沒有任何元素的時候,元組退化成 (),就叫做unit類型,是Rust中一個非常重要的基礎類型和值,unit類型唯一的值實例就是(),與其類型本身的表示相同。比如一個函數沒有返回值的時候,它實際默認返回的是這個unit值。
2.2 數組(array)
①、由中括號[] 包含一組表達式組成;
②、數組中每個元素的類型必須相同(元祖tuple可以不同);
③、長度固定,一旦聲明,其長度不會增大或縮小。
可以看到,數組的長度居然不能改變,這是因為固定尺寸的數據類型是可以直接放棧上的,創建和回收都比在堆上動態分配的動態數組性能要好,Rust 出于此考慮做出了限制。
2.2.1 實例
有三種方式聲明。
//數組:實例
fn array_test1(){
//1、省略類型和長度
let a = [1,1,1,1];
//2、聲明類型和長度
let b:[i32;4] = [1,1,1,1];
//3、聲明初始值和長度
let c = [1;4];
println!("{}",a == b);//true
println!("{}",a == c);//true
println!("{}",c == b);//true
}
2.2.2 訪問數組元素
①、通過下標訪問
初始下標是0
//數組:訪問元素
fn array_test2(){
let a = [1,2,3,4];
println!("a[0]={}",a[0]);
println!("a[1]={}",a[1]);
println!("a[2]={}",a[2]);
}
②、通過 get() 方法
注意返回值是 Option
//數組:訪問元素
fn array_test3(){
let a = [1,2,3,4];
let first = a.get(0);
let last = a.get(4);
println!("{:?}",first);//Some(1)
println!("{:?}",last);//None
}
2.2.3 數組越界訪問異常
如果聲明的數組有4個,但是訪問下標大于或等于4,編譯時就會拋出異常。
//數組:訪問元素
fn array_test3(){
let a = [1,2,3,4];
println!("a[4]={}",a[4]);
}

可以想一下,為什么 rust 在編譯期間就能報錯?
就是因為我們前面說過 數組的長度是確定的,Rust在編譯時就分析并提取了這個數組類型占用空間長度的信息,因此直接阻止了你的越界訪問。
2.2.4 避免數組越界程序崩潰
如果我們不確定讀取數組的索引是否合法,上面通過索引的方式訪問就會發生異常,導致程序奔潰。
為了避免這種情況,我們可以使用 get(index) 的方法來獲取數組中的元素,其返回值是 Option
//數組:訪問元素
fn array_test3(){
let a = [1,2,3,4];
let first = a.get(0);
let last = a.get(4);
println!("{:?}",first);//Some(1)
println!("{:?}",last);//None
}
2.3 結構體(struct)
結構體和元祖類似,都可以把多個類型組合到一起,作為新的類型。
結構體又可以分為三種具體類型:
// 具名結構體
struct Name_Struct {
x : f32,
y : f32,
}
// 元祖結構體
struct Tuple_Struct(f32,f32);
// 單元結構體
struct Unit_Struct;
2.3.1 具名結構體
//結構體
fn struct_test1(){
struct Point{
x : i32,
y : i32,
}
let p = Point{x:0,y:0};
println!("{},{}",p.x,p.y);
}
①、每個元素之間采用逗號分開,最后一個逗號可以省略不寫。
②、類型依舊跟在冒號后面,但是不能使用自動類型推導功能,必須顯示指定。
局部變量和結構體變量一致,可以省略掉重復的冒號初始化
//局部變量和結構體變量一致,可以省略掉重復的冒號初始化
fn struct_test2(){
struct Point{
x : i32,
y : i32,
}
let x = 10;
let y = 20;
let p = Point{x,y};
println!("{},{}",p.x,p.y);
}
2.3.2 元祖結構體tuple struct
這是前面介紹的 tuple 和 struct 兩種類型的混合,tuple struct 結構有名字,但是成員沒有名字。
名字加圓括號,類型有單獨的名字,成員沒有單獨的名字。
fn tuple_struct(){
struct Color (
i32,
i32,
i32
);
}
訪問方法
通過下標訪問:
fn tuple_struct(){
struct Color (
i32,
i32,
i32
);
let v1 = Color(1,2,3);
println!("{},{},{}",v1.0,v1.1,v1.2)
}
2.3.3 單元結構體
// 單元結構體
struct Unit_Struct;
單元結構體不會占用任何內存空間。
3、枚舉 enum
如果說 tuple、struct、tuple struct 在 Rust 中代表的是多個類型的“與”關系,那么 enurn類型在 Rust 中代表的就是多個類型的“或”關系。
Rust 的 enum 中的每個元素的定義語法與 struct 的定義語法類似。可以像空結構體一樣,不指定它的類型;也可以像 tuple struct 一樣,用圓括號加無名成員;還可以像正常結構體一樣,用大括號加帶名字的成員。
fn main() {
let x = enum_define::Int(12);
let y = enum_define::Float(3.2);
let z = enum_define::Move {x:1,y:2};
let k = enum_define::Color(255,255,255);
match x {
enum_define::Int(i) => {
println!("{}",i);
},
enum_define::Float(f) => {
println!("{}",f);
},
enum_define::Move{x,y} => {
println!("{} {}",x,y);
},
enum_define::Color(x,y,z) => {
println!("{}{}{}",x,y,z);
}
}
}
enum enum_define{
Int(i32),
Float(f32),
Move{x:i32,y:i32},
Color(i32,i32,i32),
}
可以看到枚舉也是一種復合數據類型,但是與結構體不同,結構體類型是里面的所有字段(所有類型)同時起作用,來產生一個具體的實例,而枚舉類型是其中的一個變體起作用,來產生一個具體實例。
4、特殊數據類型
4.1 Never 類型
表示不可能返回值的數據類型。
①、類型理論中,叫做底類型,底類型不包含任何值,但它可以合一到任何其它類型;
②、Never 類型用感嘆號“!" 表示;
③、目前還未穩定,但是rust內部已經開始用了。
5、如何選擇數據類型
選擇合適的數據類型是編程中的關鍵決策之一,它涉及到正確表達數據、優化內存使用和確保代碼的正確性。
下面是一些指導原則,可以幫助我們選擇合適的數據類型:
- 理解數據的含義和特性:在選擇數據類型之前,要充分理解數據的含義、范圍和操作。考慮數據的值是否有負數、是否需要支持小數點、是否具有固定的長度等特性。這將有助于縮小選擇的范圍。
- 選擇最小且最符合需求的類型:在數據類型中,應該選擇最小的類型,以便節省內存空間和提高性能。如果數據的范圍較小,可以選擇較小的整數類型(例如
u8或i8)而不是更大的整數類型。同時,要確保所選類型可以容納數據的所有可能值。 - 平衡靈活性和類型安全:Rust 強調類型安全,但也要考慮代碼的靈活性和易用性。選擇數據類型時,需要在類型安全和靈活性之間進行權衡。更具體地說,要避免使用過于寬泛的類型(如使用
i32來表示只可能是 0 或 1 的布爾值),以免引入潛在的錯誤。 - 考慮數據的可變性:如果數據需要在使用過程中進行修改,應該選擇可變的數據類型,如使用
mut關鍵字聲明可變變量或使用可變的數據結構(如Vec或HashMap)。 - 利用復合數據類型:Rust 提供了豐富的復合數據類型,如結構體和枚舉。如果數據具有復雜的結構或多個變體,考慮使用結構體或枚舉來組織數據,以提高代碼的可讀性和可維護性。
- 考慮上下文和需求:選擇數據類型時,要考慮當前的上下文和問題的需求。例如,如果需要高性能的數值計算,可能需要選擇使用專門的數值庫。如果需要跨線程通信,可能需要選擇具備線程安全性的數據類型。
- 進行測試和驗證:選擇數據類型后,要進行充分的測試和驗證,確保所選類型能夠正確地表達數據和滿足預期的操作。
最重要的是要記住,選擇數據類型是一個根據具體情況進行的決策,并且可能隨著代碼的演進而需要進行調整和優化。
6、常見錯誤
6.1 類型轉換必須通過 as 關鍵字顯式聲明
//類型轉換必須通過 as 關鍵字顯式聲明
fn switch_test(){
let var1 : i8 = 1;
let var2 : i32 = var1;
}
報錯如下:

增加 as 關鍵字顯示聲明即可。
//類型轉換必須通過 as 關鍵字顯式聲明
fn switch_test(){
let var1 : i8 = 1;
let var2 : i32 = var1 as i32;
}
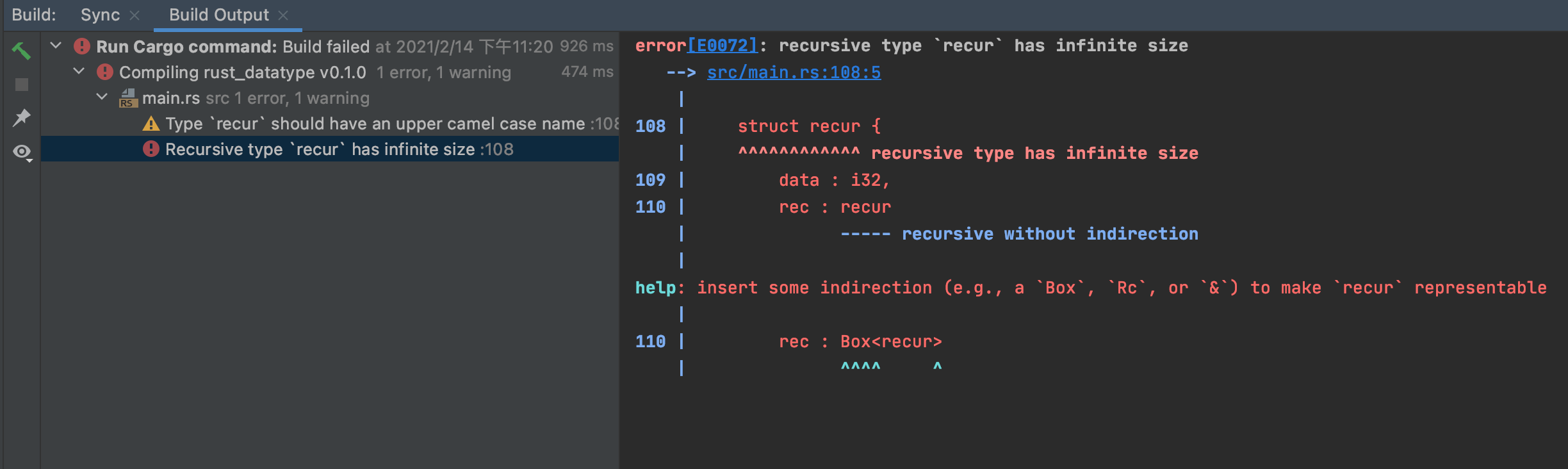
6.2 復合數據類型允許遞歸,但是不允許直接嵌套
//復合數據類型不允許直接嵌套
fn recursive(){
struct recur {
data : i32,
rec : recur
}
}
報錯如下:

 浙公網安備 33010602011771號
浙公網安備 33010602011771號