

web實質
1 一個最簡單版的web服務
web服務端是一個socket服務,瀏覽器是一個socket客戶端,通過瀏覽器訪問指定網頁,其實就是一個socket客戶端跟socket服務端的通信過程,代碼如下:
# socket服務端,實現在瀏覽器頁面上顯示'hello python'
import socket
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
while True:
conn, _ = server.accept()
data = conn.recv(1024)
print(data.decode('utf-8'))
conn.send(b'HTTP/1.1 200 ok\r\n\r\nhello python') # http的返回格式+返回數據,可分開寫
# conn.send(b'HTTP/1.1 200 ok\r\n\r\n') # 將http格式和數據分開寫,http格式內容
# conn.send(b'hello python') # 將http格式和數據分開寫,數據內容
conn.close()
server.close()
此時,我們在瀏覽器中輸入IP地址和端口(127.0.0.1:9001)就可以看到發送的socket服務端發送過來的數據'hello python'了,截圖如下:

2 訪問磁盤中文件的web服務
網頁中顯示的內容,一般是存儲在文件中,下面我們展示如何把存儲在服務器上的文件顯示在瀏覽器頁面中。
通過上面的最簡化版的web服務我們可以知道,要實現將文件test.txt的信息展示在瀏覽器頁面上,只需要socket服務端讀取文件test.txt內容,然后將讀取到的test.txt的內容發送到瀏覽器即可。
文件內容如下:
# 文件名:test.txt
God helps those who help themselves.
socket服務端代碼如下:
import socket
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
while True:
conn, _ = server.accept()
data = conn.recv(1024)
print(data.decode('utf-8'))
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('test.txt', 'rb') as f: # 讀文件
data = f.read()
conn.send(data) # 發送文件中的內容到瀏覽器
conn.close()
server.close()
瀏覽器訪問后,截圖如下:

3. 在瀏覽器中展示html文件
接下來,我們將展示如何將html文件(html文件也是個文件,因此跟上面將普通文件顯示在瀏覽器中毫無區別)顯示在瀏覽器中
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1 style="color:red">web文件</h1>
<p style="color:green">這是一個簡單的html文件,將顯示在瀏覽器中</p>
</body>
</html>
socket服務端代碼如下:
import socket
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
while True:
conn, _ = server.accept()
data = conn.recv(1024)
print(data.decode('utf-8'))
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('index.html', 'rb') as f: # 只需要將文件名修改成html文件即可
data = f.read()
conn.send(data)
conn.close()
server.close()
運行代碼后,打開瀏覽器,訪問結果如下:

在上面的代碼運行過程中,我們打印了瀏覽器請求的信息,截圖如下:

4. 通過在瀏覽器中輸入不同url,返回不同的頁面內容
我們在使用瀏覽器訪問服務器的時候,會看到不同得url路經,不同的url路經將顯示不同的頁面內容,下面我們將實驗使用的一個test.txt文件index.html文件分別顯示出來,由于將要顯示不同路經下的兩個文件,因此我們可以通過if判斷進行區別,并將放回的頁面信息封裝到函數中
import socket
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
def test(conn):
with open('test.txt', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def index(conn):
with open('index.html', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def err():
err = b'404 not found!'
conn.send(err)
conn.close()
while True:
conn, addr = server.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
# 將客戶端發送的請求信息進行分割,獲取到瀏覽器訪問的文件路徑,再通過路徑判斷將用戶請求頁面返回
print('path>>>', path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(from_b_msg)
if path == '/index.html':
index(conn)
elif path == '/test.txt':
test(conn)
else:
err()
訪問html文件,結果如下:

訪問txt文件,結果如下:

訪問其他路徑地址,則顯示錯誤提示,結果如下:
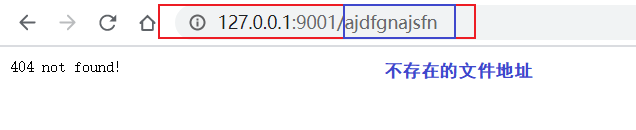
5 多線程版的web框架:
import socket
from threading import Thread
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
def test(conn):
with open('test.txt', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def index(conn):
with open('index.html', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def err():
err = b'404 not found!'
conn.send(err)
conn.close()
while True:
conn, addr = server.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>', path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(str_msg)
if path == '/index.html':
t = Thread(target=index, args=(conn,))
t.start()
elif path == '/test.txt':
t = Thread(target=test, args=(conn,))
t.start()
else:
err()
上面的代碼雖然能實現功能,但是,如果有成百上千的文件,是否要寫成百上千個if判斷呢?因此代碼還可以進行如下的優化
import socket
from threading import Thread
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
def test(conn):
with open('test.txt', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def index(conn):
with open('index.html', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
path_list = [
('/index.html', index),
('/test.txt', test)
]
def fun(path, conn):
for url in path_list:
if path == url[0]:
t = Thread(target=url[1], args=(conn,))
t.start()
while True:
conn, _ = server.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>', path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(str_msg)
fun(path, conn)
經過這樣的優化后,以后有新的文件,只需要將文件信息添加到path_list列表中了,不用再寫if判斷了。
6 展示動態web頁面
該案例中,我們將在瀏覽器中顯示當前時間,用戶不斷刷新瀏覽器,瀏覽器將自動更新當前時間
import socket, time
from threading import Thread
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
def test(conn):
with open('test.txt', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def index(conn):
time_flag = str(time.strftime("%Y-%m-%d %H:%M:%S")) # 先將當前時間拿到
with open('index.html', 'r', encoding="utf8") as f:
data = f.read()
data = data.replace('web文件', '北京實時時間') # 將html的文件內容做替換
data = data.replace('這是一個簡單的html文件,將顯示在瀏覽器中', time_flag).encode('utf-8') # 將html的文件內容做替換,顯示我們指定的內容
conn.send(data)
conn.close()
path_list = [
('/index.html', index),
('/test.txt', test)
]
def fun(path, conn):
for url in path_list:
if path == url[0]:
t = Thread(target=url[1], args=(conn,))
t.start()
while True:
conn, _ = server.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>', path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(str_msg)
fun(path, conn)
運行代碼后,刷新頁面將顯示當前實時時間

再次刷新,頁面如下:
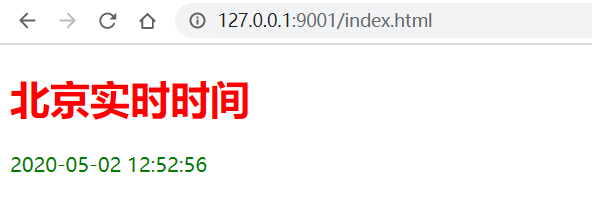
7 從數據庫讀取數據并返回到瀏覽器
接下來的案例,我們將展示,連接MySQL數據庫,將MySQL數據庫中的信息展示到瀏覽器頁面上
首先連接到數據庫,獲取到test數據庫userinfo表中的內容
# 連接數據庫文件 connectDB.py
import pymysql
def show_db():
db = pymysql.connect(host='127.0.0.1',
user='root',
password="2048",
database='test',
port=13306)
cursor = db.cursor(pymysql.cursors.DictCursor)
sql = 'select name,age from userinfo;'
cursor.execute(sql)
db_data = cursor.fetchall() # 獲取到test數據庫中userinfo表中的name和age的數據
cursor.close()
db.close()
content_list = [] # 定義一個列表,用于存放我們修改過后的表數據
for row in db_data: # 將userinfo表中的每一行內容取到
tp = '<tr><td>%s</td><td>%s</td></tr>' % (row['name'], row['age']) # 將userinfo表中的name和age字段替換成html指定的顯示格式
content_list.append(tp)
content = ''.join(content_list)
return content
新建一個用于用戶訪問的html文件模板,只定義表頭信息(如果不定義表頭的話,也可以使用特定字符串,再socket服務端將這些字符串替換成將要顯示的表頭信息即可,這里為了容易理解,因此將表頭信息定義出來),表數據信息用特殊字符串4個'@'代替,便于socket客戶端替換
# 瀏覽器訪問的頁面文件index.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<table border="1">
<thead>
<tr>
<td>姓名</td>
<td>年齡</td>
</tr>
</thead>
<tbody>
@@@@
</tbody>
</table>
</body>
</html>
socket客戶端需要做三件事:
- 連接到數據庫,拿到數據庫中userinfo表的所有信息
- 用數據庫中表的信息替換掉html模板中的信息
- 將替換掉的數據返回給瀏覽器
# socket服務端
import socket
from threading import Thread
from connectDB import show_db
server = socket.socket()
server.bind(('127.0.0.1', 9001))
server.listen()
def test(conn):
with open('test.txt', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def index(conn):
userinfo_data = show_db()
with open('db.html', 'r', encoding="utf8") as f:
data = f.read()
data = data.replace('@@@@', userinfo_data).encode('utf-8')
conn.send(data)
conn.close()
path_list = [
('/index.html', index),
('/test.txt', test)
]
def fun(path, conn):
for url in path_list:
if path == url[0]:
t = Thread(target=url[1], args=(conn,))
t.start()
while True:
conn, _ = server.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>', path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(str_msg)
fun(path, conn)
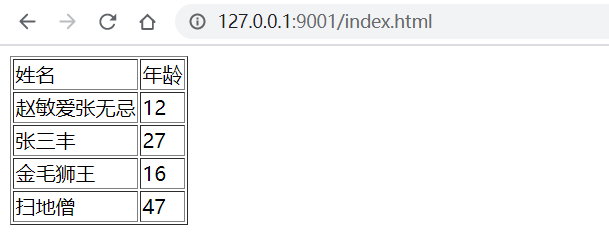
訪問瀏覽器,截圖如下:
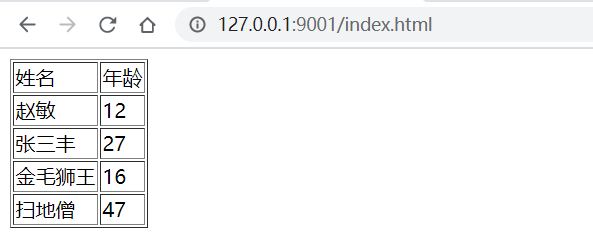
修改數據庫數據數據
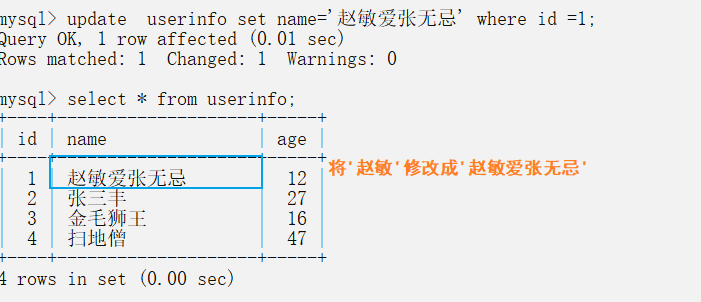
重新訪問瀏覽器
8 使用jinja2模板渲染的web框架案例
上文中從數據庫中取出數據,然后通過字符串替換,再顯示到瀏覽器頁面上,字符串替換的過程可以使用現成的模塊jinja2來完成,代碼如下。
from wsgiref.simple_server import make_server
from jinja2 import Template
import pymysql
def show_db():
db = pymysql.connect(host='127.0.0.1',
user='root',
password="2048",
database='test',
port=13306)
cursor = db.cursor(pymysql.cursors.DictCursor)
sql = 'select name,age from userinfo;'
cursor.execute(sql)
db_data = cursor.fetchall()
cursor.close()
db.close()
return db_data
def index():
userinfo_data = show_db()
print(userinfo_data)
with open('JINJA2.html', 'r', encoding="utf-8") as f:
data = f.read()
template = Template(data)
print(template)
data = template.render({'user_list': userinfo_data})
return [bytes(data, encoding="utf8"), ]
path_list = [
('/index.html', index),
]
def run_server(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
url = environ['PATH_INFO']
func = None
for item in path_list:
if item[0] == url:
func = item[1]
break
if func:
return func()
else:
return [bytes("404 not found", encoding="utf8"), ]
if __name__ == '__main__':
httpd = make_server('', 9001, run_server)
print("Serving HTTP on port 9001...")
httpd.serve_forever()
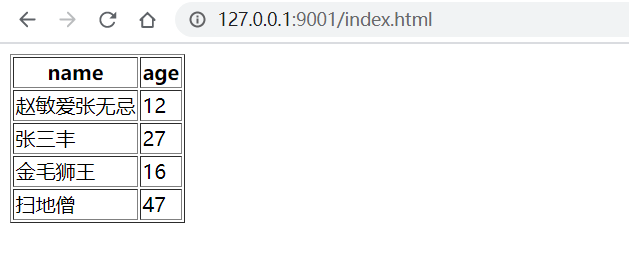
html模板文件如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table border="1">
<thead>
<tr>
<th>name</th>
<th>age</th>
</tr>
</thead>
<tbody>
{% for i in user_list %}
<tr>
<td>{{ i['name'] }}</td>
<td>{{ i['age'] }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>
瀏覽器訪問后,顯示內容如下:

 浙公網安備 33010602011771號
浙公網安備 33010602011771號